Rust dasturlash tili
Steve Klabnik va Carol Nicholsning, Rust hamjamiyatining hissasi bilan
Kitobning ushbu versiyasi siz Rust 1.67.1 (2023-02-09-da chiqarilgan) yoki undan keyingi versiyasidan foydalanayotganingizni taxmin qiladi. Rustni o'rnatish yoki yangilash uchun 1-bobning ”O'rnatish” bo'limiga qarang.
HTML formati https://doc.rust-lang.org/stable/book/ saytida va oflayn rejimda rustup bilan qilingan Rust o'rnatishlari mavjud; ochish uchun rustup docs --book ni ishga tushiring.
Bir nechta hamjamiyat tarjimalari ham mavjud.
Ushbu kitob qog'oz va elektron kitob formatida No Starch Press nashrida mavjud.
🚨 Ko'proq interaktiv o'rganishni xohlaysizmi? Rust Bookning boshqa versiyasini sinab koʻring: viktorinalar, alohida chizilgan belgilashlar, vizualizatsiya va boshqalar: https://rust-book.cs.brown.edu
Muqaddima
Bu har doim ham unchalik aniq bo'lmagan, lekin Rust dasturlash tili asosan imkoniyatlarni kengaytirishga qaratilgan: hozir qanday kod yozayotganingizdan qat'iy nazar, Rust sizga oldinga qaraganda kengroq domenlarda ishonch bilan dasturlash imkonini beradi.
Masalan, memory managementning low-leveldagi tafsilotlari, ma'lumotlarni taqdim etish va parallellik bilan shug'ullanadigan "systems-leveldagi" ishni olaylik. An'anaga ko'ra, dasturlashning bu sohasi sirli bo'lib ko'rinadi, unga faqat o'zining dahshatli tuzoqlaridan qochish uchun zarur yillarini o'rganishga bag'ishlagan tanlanganlargina foydalanishi mumkin. Va hatto buni amalda qo'llayotganlar ham, ularning kodi ekspluatatsiyalar, buzilishlar yoki korruptsiyaga ochiq bo'lmasligi uchun buni ehtiyotkorlik bilan bajaradilar.
Rust eski tuzoqlarni yo'q qilish va sizga yordam berish uchun do'stona, sayqallangan vositalar to'plamini taqdim etish orqali bu to'siqlarni yo'q qiladi. Low-leveldagi boshqaruvga ”pastga tushishi” kerak bo'lgan dasturchilar buni Rust bilan odatiy holga tushib qolish xavfi yoki xavfsizlik teshiklarisiz va o'zgaruvchan toolchainning nozik tomonlarini o'rganmasdan amalga oshirishlari mumkin. Yaxshisi, bu til sizni tabiiy ravishda tezlik va xotiradan foydalanish jihatidan samarali bo'lgan ishonchli kodga yo'naltirish uchun mo'ljallangan.
Low leveldagi kod bilan ishlayotgan dasturchilar o'zlarining bilimlarini oshirish uchun Rust-dan foydalanishlari mumkin. Masalan, Rust-da parallelizmni joriy qilish nisbatan low-riskli operatsiya: kompilyator siz uchun klassik xatolarni aniqlaydi. Va siz tasodifan nosozliklar yoki zaifliklarni kiritmasligingizga ishonch bilan kodingizdagi yanada tajovuzkor optimallashtirishlarni hal qilishingiz mumkin.
Ammo Rust low-leveldagi tizimlarni dasturlash bilan cheklanmaydi. Bu CLI ilovalari, veb-serverlar va boshqa ko'plab turdagi kodlarni yozishni juda yoqimli qilish uchun yetarlicha ifodali va samarador - siz ikkalasining oddiy misollarini keyinroq kitobda topasiz. Rust bilan ishlash sizga bir domendan boshqasiga o'tadigan ko'nikmalarni shakllantirish imkonini beradi; veb-ilovani yozish orqali Rustni o'rganishingiz mumkin, so'ngra Raspberry Pi-ni nishonga olish uchun xuddi shu ko'nikmalarni qo'llashingiz mumkin.
Ushbu kitob o'z foydalanuvchilarini kuchaytirish uchun Rust imkoniyatlarini to'liq qamrab oladi. Bu sizga nafaqat Rust haqidagi bilimingizni, balki umuman dasturchi sifatidagi ishonchingizni oshirishga yordam beradigan samimiy va qulay kitob. Shunday qilib, sho'ng'ing, o'rganishga tayyor bo'ling va Rust hamjamiyatiga xush kelibsiz!
— Nicholas Matsakis va Aaron Turon
Kirish
Eslatma: Kitobning ushbu nashri No Starch Press-dan bosma va elektron kitob formatida mavjud bo'lgan Rust dasturlash tili bilan bir xil.
Rust dasturlash tiliga xush kelibsiz, Rust haqida kirish kitobi. Rust dasturlash tili tezroq va ishonchli dasturlarni yozishga yordam beradi. Yuqori darajadagi samaradorlik va low-leveldagi boshqaruv ko'pincha dasturlash tilini loyihalashda bir-biriga zid keladi; Rust bu ziddiyatga qarshi turadi. Kuchli texnik imkoniyatlar va ishlab chiquvchilarning ajoyib tajribasini muvozanatlash orqali Rust sizga an'anaviy ravishda bunday nazorat bilan bog'liq bo'lgan barcha qiyinchiliklarsiz low-leveldagi tafsilotlarni (masalan, xotiradan foydalanish) boshqarish imkoniyatini beradi.
Rust kim uchun
Rust turli sabablarga ko'ra ko'p odamlar uchun idealdir. Keling, eng muhim guruhlarning bir nechtasini ko'rib chiqaylik.
Dasturchilar jamoalari
Rust turli darajadagi tizimlarni dasturlash bo'yicha bilimga ega bo'lgan yirik ishlab chiquvchilar guruhlari o'rtasida hamkorlik qilish uchun samarali vosita ekanligini isbotlamoqda. Low-leveldagi kod turli xil nozik xatolarga moyil bo'lib, ko'pchilik boshqa tillarda ularni faqat keng ko'lamli sinov va tajribali ishlab chiquvchilar tomonidan sinchkovlik bilan tekshirish orqali aniqlash mumkin.Rust-da kompilyator ushbu qiyin xatolar, jumladan, parallellik xatolari bilan kodni kompilyatsiya qilishni rad etib, darvozabon rolini o'ynaydi. Kompilyator bilan birga ishlash orqali jamoa xatolarni ta'qib qilishdan ko'ra, vaqtini dastur mantig'iga qaratishga sarflashi mumkin.
Rust shuningdek, tizim dasturlash dunyosiga zamonaviy ishlab chiquvchilar vositalarini olib keladi:
- Cargo dependency menejeri va build toolni o'z ichiga oladi, Rust ekotizimida bog'liqliklarni qo'shish, kompilyatsiya qilish va boshqarishni qiyinchiliksiz va davomli qiladi.
- Rustfmt formatlash vositasi ishlab chiquvchilar orasida barqaror kodlash uslubini ta'minlaydi.
- Rust Language Server kodni toʻldirish va inline xato xabarlari uchun Integrated Development Environment (IDE) integratsiyasini quvvatlaydi.
Rust ekotizimidagi ushbu va boshqa vositalardan foydalangan holda, ishlab chiquvchilar tizim darajasidagi kodni yozishda samarali bo'lishi mumkin.
Talabalar
Rust talabalar va tizim tushunchalarini o'rganishga qiziquvchilar uchun. Rust-dan foydalanib, ko'p odamlar operatsion tizimlarni ishlab chiqish kabi mavzular haqida bilib oldilar. Jamiyat juda mehmondo'st va talabalar savollariga javob berishdan xursand. Ushbu kitob kabi sa'y-harakatlar orqali Rust guruhlari tizim tushunchalarini ko'proq odamlar, ayniqsa dasturlash uchun yangi bo'lganlar uchun qulayroq qilishni xohlashadi.
Kompaniyalar
Yuzlab yirik va kichik kompaniyalar ishlab chiqarishda Rust-dan CLI dasturlar, veb-xizmatlar, DevOps toollari, embedded qurilmalar, audio va video tahlillari va transkodlar, kriptovalyutalar, bioinformatika, qidiruv tizimlari, Internet of Things ilovalari kabi turli vazifalar uchun foydalanadilar. , machine learning va hatto Firefox veb-brauzerining asosiy qismlari.
Open Source dasturchilar
Rust Rust dasturlash tilini, hamjamiyatini, ishlab chiquvchilar vositalarini va kutubxonalarini yaratmoqchi bo'lgan odamlar uchundir. Rust tiliga o'z hissangizni qo'shishingizni istardik.
Tezlik va barqarorlikni qadrlaydigan odamlar
Rust dasturlash tili tezlik va barqarorlikni xohlaydigan odamlar uchundir. Tezlik deganda biz Rust kodi qanchalik tez ishlashini va Rust sizga dasturlar yozish imkonini beradigan tezligini nazarda tutamiz. Rust kompilyatorining tekshiruvlari qo'shimcha funksiyalar va refaktoring orqali barqarorlikni ta'minlaydi. Bu ishlab chiquvchilar ko'pincha o'zgartirishdan qo'rqadigan ushbu tekshiruvlarsiz tillardagi mo'rt eski koddan farqli o'laroq. Nol xarajatli abstraktsiyalarga, qo'lda yozilgan kod kabi tezroq lower-leveldagi kodni kompilyatsiya qiladigan higher-leveldagi funktsiyalarga intilish orqali Rust xavfsiz kodni ham tezkor kod qilishga intiladi.
Rust tili boshqa ko'plab foydalanuvchilarni ham qo'llab-quvvatlashga umid qiladi; Bu yerda tilga olinganlar faqat eng katta manfaatdor tomonlardan biri hisoblanadi. Umuman olganda, Rustning eng katta ambitsiyalari xavfsizlik va unumdorlik, tezlik va samaradorlikni ta'minlash orqali dasturchilar o'nlab yillar davomida qabul qilgan kelishuvlarni yo'q qilishdir. Rust-ni sinab ko'ring va uning tanlovlari sizga mos keladimi yoki yo'qligini tekshiring.
Bu kitob kim uchun
Ushbu kitobda siz boshqa dasturlash tilida kod yozgansiz deb taxmin qilinadi, lekin qaysi biri haqida hech qanday taxminlar yo'q. Biz materialni turli xil dasturlash tajribasiga ega bo'lganlar uchun keng foydalanishga harakat qildik. Biz dasturlash nima ekanligi yoki u haqida qanday fikr yuritish haqida gapirishga ko'p vaqt sarflamaymiz. Agar siz dasturlashda mutlaqo yangi bo'lsangiz, dasturlash bilan tanishishni ta'minlaydigan kitobni o'qisangiz yaxshi bo'lardi.
Ushbu kitobdan qanday foydalanish kerak
Umuman olganda, bu kitob siz uni oldindan orqaga ketma-ket o'qiyotganingizni taxmin qiladi. Keyingi boblar oldingi boblardagi tushunchalarga asoslanadi va oldingi boblar ma'lum bir mavzu bo'yicha tafsilotlarni o'rganmasligi mumkin, lekin keyingi bobda mavzuni qayta ko'rib chiqadi.
Ushbu kitobda siz ikki xil bo'limni topasiz: kontseptsiya bo'limlari va loyiha bo'limlari. Kontseptsiya boblarida siz Rustning bir tomoni haqida bilib olasiz. Loyiha bo'limlarida biz hozirgacha o'rganganlaringizni qo'llagan holda kichik dasturlarni birgalikda tuzamiz. 2, 12 va 20-boblar loyiha boblari; qolganlari kontseptsiya boblari.
1-bobda Rustni qanday o'rnatish, "Hello, world!" dasturi va Cargo, Rust paket menejeri va build tooldan qanday foydalanishni ko'rib chiqamiz. 2-bob Rustda dastur yozish bo'yicha amaliy kirish bo'lib, siz raqamlarni taxmin qilish o'yinini tuzasiz. Bu yerda biz tushunchalarni yuqori darajada yoritamiz va keyingi boblarda qo'shimcha tafsilotlar beriladi. Agar siz darhol qo'llaringizni ifloslantirmoqchi bo'lsangiz, 2-bob buning uchun joy. 3-bobda boshqa dasturlash tillariga oʻxshash Rust funksiyalari yoritilgan va 4-bobda siz Rustning ownershp tizimi haqida bilib olasiz. Agar siz keyingisiga o‘tishdan oldin har bir tafsilotni o‘rganishni ma’qul ko‘radigan, ayniqsa sinchkov o‘quvchi bo‘lsangiz, 2-bobni o‘tkazib yuborib, to‘g‘ridan-to‘g‘ri 3-bobga o‘tishingiz va loyiha ustida ishlashni hohlaganingizda 2-bobga qaytishingiz mumkin. siz o'rgangan tafsilotlar.
5-bobda structlar va metodlar muhokama qilinadi, 6-bob esa enumlar, match expressionlari va if let control flow konstruksiyasini qamrab oladi. Rust-da maxsus turlarni yaratish uchun struclar va enumlardan foydalanasiz.
7-bobda siz Rust modul tizimi va kodingizni va uning umumiy amaliy dasturlash interfeysini (API) tashkil qilish uchun maxfiylik qoidalari haqida bilib olasiz. 8-bobda standart kutubxona taqdim etadigan vektorlar, stringlar va hash maplar kabi umumiy yig'ish ma'lumotlar tuzilmalari muhokama qilinadi. 9-bob Rustning xatolarni hal qilish falsafasi va usullarini o'rganadi.
10-bob generiklar, traitlar va lifetimeni o'rganadi, bu sizga bir nechta turlarga tegishli kodni aniqlash imkoniyatini beradi. 11-bob sinovdan o'tadi, bu hatto Rustning xavfsizlik kafolatlari bilan ham dasturingiz mantig'ining to'g'riligini ta'minlash uchun zarurdir. 12-bobda biz fayllar ichidagi matnni qidiradigan grep buyruq qatori vositasidan o'zimizning funksiyalar to'plamini yaratamiz. Buning uchun biz oldingi boblarda muhokama qilgan ko'plab tushunchalardan foydalanamiz.
13-bob yopilishlar va iteratorlarni o'rganadi: Rustning funktsional dasturlash tillaridan kelib chiqadigan xususiyatlari. 14-bobda biz Cargolarni chuqurroq ko'rib chiqamiz va kutubxonalaringizni boshqalar bilan baham ko'rishning eng yaxshi amaliyotlari haqida gaplashamiz. 15-bobda standart kutubxona taqdim etadigan smart pointerlar va ularning funksionalligini ta'minlaydigan traitlar muhokama qilinadi.
16-bobda biz bir vaqtning o'zida dasturlashning turli modellarini ko'rib chiqamiz va Rust sizga bir nechta mavzularda qo'rqmasdan dasturlashda qanday yordam berishi haqida gaplashamiz. 17-bobda Rust idiomlari sizga tanish bo'lishi mumkin bo'lgan obyektga yo'naltirilgan(OOP) dasturlash tamoyillari bilan qanday taqqoslanishi ko'rib chiqiladi.
18-bobda Rust dasturlari bo'ylab g'oyalarni ifodalashning kuchli usullari bo'lgan patternlar va patternlarni moslashtirish haqida ma'lumot berilgan. 19-bobda ilg'or qiziqarli mavzular, jumladan xavfli Rust, makroslar va boshqa ko'p narsalar mavjud.
20-bobda biz low-leveldagi ko'p tarmoqli veb-serverni amalga oshiradigan loyihani yakunlaymiz!
Va nihoyat, ba'zi qo'shimchalarda til haqida foydali ma'lumotlar ko'proq mos yozuvlar formatida mavjud. A ilovasida Rustning kalit so'zlari, B ilovasida Rust operatorlari va belgilari, C ilovasi standart kutubxona tomonidan taqdim etilgan hosila traitlarini o'z ichiga oladi, D ilovasi ba'zi foydali ishlab chiqish vositalarini qamrab oladi va E ilovasida Rust nashrlari tushuntiriladi. F ilovasida siz kitobning tarjimalarini topishingiz mumkin, G ilovasida esa Rust qanday qilinganligi va nightlyli Rust nima ekanligini ko'rib chiqamiz.
Ushbu kitobni o'qishning noto'g'ri usuli yo'q: agar siz oldinga o'tmoqchi bo'lsangiz, unga boring! Agar chalkashliklarga duch kelsangiz, avvalgi boblarga qaytishingiz kerak bo'lishi mumkin. Lekin siz uchun nima ish qilsa, shuni qiling.
Rustni o'rganish jarayonining muhim qismi kompilyator ko'rsatadigan xato xabarlarini o'qishni o'rganishdir: ular sizni ish kodiga yo'naltiradi. Shunday qilib, biz kompilyator har bir vaziyatda sizga ko'rsatadigan xato xabari bilan birga kompilyatsiya qilinmaydigan ko'plab misollarni keltiramiz. Bilingki, agar siz tasodifiy misol kiritsangiz va ishlatsangiz, u kompilyatsiya qilinmasligi mumkin! Ishlamoqchi bo'lgan misol xato uchun mo'ljallanganligini bilish uchun atrofdagi matnni o'qiganingizga ishonch hosil qiling. Ferris, shuningdek, ishlash uchun mo'ljallanmagan kodni ajratishga yordam beradi:
| Ferris | Ma'nosi |
|---|---|
 | Bu kod kompilyatsiya qilinmaydi! |
 | Bu kod panic! |
 | Ushbu kod kerakli xatti-harakatni keltirib chiqarmaydi. |
Aksariyat hollarda biz sizni kompilyatsiya qilinmagan har qanday kodning to'g'ri versiyasiga olib boramiz.
Manba kodi
Ushbu kitob yaratilgan manba fayllarni GitHubda topish mumkin.
Ishni boshlash
Rust sayohatingizni boshlaymiz! O'rganish uchun ko'p narsa bor, lekin har bir sayohat bir joydan boshlanadi. Ushbu bobda biz muhokama qilamiz:
- Rustni Linux, macOS va Windows-ga o'rnatish
Hello, world!ni chop etuvchi dasturni yozishcargodan foydalanib, Rust paketlar menejeri va build systemdan foydalanish
O'rnatish
Birinchi qadam Rustni o'rnatishdir.Rustni Rust versiyalari va tegishli vositalarni boshqarish uchun buyruq qatori vositasi bo‘lgan rustup orqali yuklab olamiz. Yuklab olish uchun sizga internet ulanishi kerak bo'ladi.
Eslatma: Agar biron sababga ko'ra
rustupdan foydalanmaslikni xohlasangiz, boshqa variantlar uchun Rustni o'rnatishning boshqa usullari sahifasiga qarang.
Quyidagi qadamlar Rust kompilyatorining so'nggi barqaror versiyasini o'rnatadi. Rustning barqarorligi kafolati kitobdagi kompilyatsiya qilingan barcha misollar Rustning yangi versiyalari bilan kompilyatsiya qilishda davom etishini ta'minlaydi. Chiqish versiyalar orasida biroz farq qilishi mumkin, chunki Rust ko'pincha xato xabarlari va ogohlantirishlarni yaxshilaydi. Boshqacha qilib aytadigan bo'lsak, ushbu qadamlar yordamida o'rnatgan har qanday yangi, barqaror Rust versiyasi ushbu kitob mazmuni bilan kutilganidek ishlashi kerak.
Buyruqlar qatori yozuvi
Ushbu bobda va butun kitobda biz terminalda ishlatiladigan ba'zi buyruqlarni ko'rsatamiz. Terminalga kiritishingiz kerak bo'lgan barcha qatorlar
$bilan boshlanadi.$belgisini kiritishingiz shart emas; bu har bir buyruqning boshlanishini ko'rsatish uchun ko'rsatilgan buyruq qatori.$bilan boshlanmagan qatorlar odatda oldingi buyruqning natijasini ko'rsatadi. Bundan tashqari, PowerShell-ga xos misollarda$emas,>ishlatiladi.
Linux yoki macOS-ga rustup o'rnatish
Agar siz Linux yoki macOS dan foydalansangiz, terminalni oching va quyidagi buyruqni kiriting:
$ curl --proto '=https' --tlsv1.2 https://sh.rustup.rs -sSf | sh
Buyruq skriptni yuklab oladi va Rustning eng so'nggi barqaror versiyasini o'rnatadigan rustup vositasini o'rnatishni boshlaydi. Sizdan parol so'ralishi mumkin. O'rnatish muvaffaqiyatli bo'lsa, quyidagi qator paydo bo'ladi:
Rust is installed now. Great!
Shuningdek, sizga linker, kerak bo'ladi, ya'ni Rust o'zining kompilyatsiya qilingan natijalarini bitta faylga birlashtirish uchun foydalanadigan dastur. Ehtimol,bu sizda allaqachon mavjud. Agar linker xatolarga duch kelsangiz, odatda linkerni o'z ichiga olgan C kompilyatorini o'rnatishingiz kerak. C kompilyatori ham foydalidir, chunki ba'zi umumiy Rust paketlari C kodiga bog'liq va C kompilyatoriga muhtoj bo'ladi.
MacOS-da siz C kompilyatorini ishga tushirish orqali olishingiz mumkin:
$ xcode-select --install
Linux foydalanuvchilari odatda distributiv texnik hujjatlariga muvofiq GCC yoki Clang o'rnatishlari kerak. Misol uchun, agar siz Ubuntu'dan foydalansangiz, build-essential paketini o'rnatishingiz mumkin.
Windows-ga rustup o'rnatish
Windows tizimida https://www.rust-lang.org/tools/install saytiga o'ting va Rustni o'rnatish bo'yicha ko'rsatmalarga amal qiling. O'rnatishning bir nuqtasida sizga Visual Studio 2013 yoki undan keyingi versiyalari uchun MSVC yaratish vositalari kerakligi haqida xabar keladi.
Build toolsini olish uchun Visual Studio 2022 ni o'rnatishingiz kerak bo'ladi. Qaysi ish dasturlarini o'rnatish kerakligi so'ralganda, quyidagilarni kiriting:
- “Desktop Development with C++”
- TWindows 10 yoki 11 SDK
- Ingliz tili to'plami komponenti va siz tanlagan boshqa tillar to'plami
Ushbu kitobning qolgan qismi cmd.exe va PowerShell da ishlaydigan buyruqlardan foydalanadi. Agar aniq farqlar bo'lsa, qaysi birini ishlatishni tushuntiramiz.
Muammolarni bartaraf etish
Rust to'g'ri o'rnatilganligini tekshirish uchun shellni oching va quyidagi qatorni kiriting:
$ rustc --version
Quyidagi formatda chiqarilgan so‘nggi barqaror versiya uchun versiya raqami, xesh va tasdiqlangan sanani ko‘rishingiz kerak:
rustc x.y.z (abcabcabc yyyy-mm-dd)
Agar siz ushbu ma'lumotni ko'rsangiz, Rustni muvaffaqiyatli o'rnatdingiz! Agar siz ushbu ma'lumotni ko'rmasangiz, Rust %PATH% tizim o'zgaruvchingizda quyidagi tarzda ekanligini tekshiring.
Windows CMD-da quyidagilardan foydalaning:
> echo %PATH%
PowerShell-da foydalaning:
> echo $env:Path
Linux va macOS-da quyidagilardan foydalaning:
$ echo $PATH
Agar hammasi to'g'ri bo'lsa va Rust hali ham ishlamasa, yordam olishingiz mumkin bo'lgan bir qancha joylar mavjud. Boshqa Rustaceanlar (biz o'zimizni chaqiradigan ahmoqona taxallus) bilan qanday bog'lanishni hamjamiyat sahifasida bilib oling.
Yangilash va o'chirish
Rust rustup orqali o'rnatilgandan so'ng, yangi chiqarilgan versiyaga yangilash oson. Shelldan quyidagi yangilash skriptini ishga tushiring:
$ rustup update
Rust va rustup-ni o'chirish uchun shelldan quyidagi o'chirish skriptini ishga tushiring:
$ rustup self uninstall
Mahalliy texnik hujjatlar
Rust-ning o'rnatilishi texnik hujjatlarning mahalliy nusxasini ham o'z ichiga oladi, shunda siz uni oflayn rejimda o'qishingiz mumkin. Brauzeringizda mahalliy texnik hujjatlarni ochish uchun rustup doc dasturini ishga tushiring.
Istalgan vaqtda standart kutubxona tomonidan tur yoki funksiya taqdim etilsa va siz u nima qilishini yoki undan qanday foydalanishni bilmasangiz, bilish uchun amaliy dasturlash interfeysi (API) texnik hujjatlaridan foydalaning!
Hello, World!
Endi siz Rustni o'rnatdingiz, hozir sizning birinchi Rust dasturingizni yozishning ayni vaqti.
Yangi dasturlash tilini o'rganishda Hello, World! matnini ekranga chop etuvchi kichik va sodda
dastur tuzish an'anaga aylangan, shunday ekan biz ham sinab ko'ramiz!
Eslatma: Bu kitob terminal bilan ishlay olishning boshlang'ich ko'nikmalarini talab qiladi. Rust sizning kod muxarriringiz foydalanadigan asboblaringiz va kodingizni qayerda joylayishi bo'yicha talablar qo'ymaydi, shuning uchun agar siz terminal o'rniga integratsiyalashgan ishlab chiqish muhitidan (IDE) foydalanishni afzal ko'rsangiz, o'zingizning sevimli IDE-dan foydalaning. Ko'pgina IDElar endi ma'lum darajada Rust-ni qo'llab-quvvatlaydi; tafsilotlar uchun IDE hujjatlarini tekshiring. Rust jamoasi
rust-analyzerorqali ajoyib IDE yordamini ta'minlashga e'tibor qaratdi. Batafsil ma’lumot uchun D ilovasini ko'zdan kechiring.
Loyiha jildini yaratish
Siz ishni Rust kodingizni joylaytirish uchun jild yaratishdan boshlaysiz. Rust uchun sizning kodingiz qayerda joylashining ahamiyati yo'q, lekin biz bu kitobdagi mashq va loyihalarni joylash uchun projects nomli jild yaratishingizni maslahat beramiz.
Terminalni oching va projects jildini yaratish va uning ichidan “Hello, world!” loyihasi jildini yaratish uchun quyidagi buyruqlarni kiriting.
Linux, macOS va Windows Powershell uchun:
$ mkdir ~/projects
$ cd ~/projects
$ mkdir hello_world
$ cd hello_world
Windows CMD uchun:
> mkdir "%USERPROFILE%\projects"
> cd /d "%USERPROFILE%\projects"
> mkdir hello_world
> cd hello_world
Rust dasturi yozish va ishga tushirish.
Endi, main.rs nomli yangi fayl yarating. Rust kodlar har doim .rs kengaytmasi bilan tugaydi. Agar fayl nomida bir nechta so'zlardan foydalansangiz, ularni ajratish uchun pastki chiziqdan foydalanish shart. Masalan, helloworld.rs o'rniga hello_world.rs dan foydalaning.
Endi hozirgina yaratgan main.rs faylingizni kod muharririda oching.
Fayl nomi: main.rs
fn main() { println!("Hello, world!"); }
Ro'yxat 1-1: Hello, world! ni chop etuvchi dastur
Faylni saqlang va Terminalda ~/projects/hello_world jildiga qayting. Linux yoki macOS da faylni kompilyatsiya qilish va ishga tushirish uchun quyidagi buyruqlarni kiriting:
$ rustc main.rs
$ ./main
Hello, world!
Windowsda ./main ning o'rniga .\main.exe buyrug'ini kiriting:
> rustc main.rs
> .\main.exe
Hello, world!
Operatsion tizimingizdan qat'i nazar, terminalda Hello, world! qatori chop etilishi kerak.Agar siz ushbu chiqishni ko'rmasangiz, yordam olish usullari uchun O'rnatish bo'limining ”Muammolarni bartaraf etish” bo'limiga qayting.
Agar Hello, world! chop etilgan bo'lsa, tabriklaymiz! Siz rasmiy ravishda Rust dasturini yozdingiz. Bu sizni Rust dasturchisiga aylantiradi - xush kelibsiz!
Rust dasturining tuzilishi.
Keling "Hello, world!" dasturiga chuqurroq nazar solamiz. Boshqotirmaning 1-qismi:
fn main() { }
Bu qatorlar main nomli funksiyani e'lon qiladi. main funksiyasi alohida: u har doim bajariladigan Rust dasturida ishlaydigan birinchi koddir. Bu yerda birinchi satr hech qanday parametrga ega boʻlmagan va hech narsani qaytarmaydigan main funksiyasini eʼlon qiladi.
Agar parametrlar mavjud bo'lsa, ular () qavslar ichiga kiradi.
Funksiyasing tanasi {} bilan o'ralgan. Rust har bir funksiyalarda e'lon qilishda
{} dan foydalanishni talab qiladi.
Eslatma: Agar siz Rust loyihalarda standart usulda kod yozmoqchi bo'lsangiz kodingizni maʼlum bir uslubda formatlash uchun
rustfmtnomli avtomatik formatlash vositasidan foydalanishingiz mumkin (batafsilroqrustfmtD ilovasi -da) Rust jamoasi ushbu vositani standart Rust distributiviga kiritdi, chunkirustckabi, u allaqachon kompyuteringizga o'rnatilgan bo'lishi kerak!
main funksiyaning tanasi quyidagi kodni o'z ichiga oladi:
#![allow(unused)] fn main() { println!("Hello, world!"); }
Shu bir qator kod shu kichik dasturdagi barcha ishni amalga oshiardi: u matnni ekranga chop etadi.Bu yerda ahamiyat qaratish zarur bo'lgan to'rtta muhim narsalar bor.
Birinchidan, Rust style to'rtta bo'shliqdan iborat tab emas
Ikkinchidan, println! Rust makrosini chaqiradi. Agar u funktsiyani o'rniga chaqirgan bo'lsa, u println (! belgisiz) sifatida kiritiladi. Biz Rust makrolari haqida 19-bobda batafsilroq muhokama qilamiz.Hozircha siz shuni bilishingiz kerakki, ! belgisidan foydalanish oddiy funksiya o‘rniga makrosni chaqirayotganingizni anglatadi va makrolar har doim ham funksiyalar bilan bir xil qoidalarga amal qilmaydi.
Uchinchidan, siz "Hello, world!" qatorini ko'rasiz. Bu satrni argument sifatida println! ga uzatamiz va satr ekranga chop etiladi.
To'rtinchidan, satrni nuqtali vergul (;) bilan tugatamiz, bu esa bu ifoda tugaganligini va keyingisi boshlashga tayyorligini bildiradi. Rust kodining aksariyat satrlari nuqtali vergul bilan tugaydi.
Kompilyatsiya va ishga tushirish alohida bosqichlardir
Siz yangi yaratilgan dasturni ishga tushirdingiz, shuning uchun jarayonning har bir bosqichini ko'rib chiqamiz.
Rust dasturini ishga tushirishdan oldin uni Rust kompilyatoridan foydalanib, rustc buyrug‘ini kiritib, unga manba faylingiz nomini quyidagi tarzda kiritishingiz kerak:
$ rustc main.rs
Agar siz C yoki C++ bilan ishlagan bo'lsangiz, bu gcc yoki clang ga o'xshashligini sezasiz. Muvaffaqiyatli kompilyatsiyadan so'ng Rust binary bajariladigan faylni chiqaradi.
Linux, macOS va Windows-dagi PowerShell-da siz shelldagi ls buyrug'ini kiritish orqali bajariladigan faylni ko'rishingiz mumkin:
$ ls
main main.rs
Linux va macOS-da siz ikkita faylni ko'rasiz. Windows-dagi PowerShell bilan siz CMD-dan foydalangan holda ko'rgan uchta faylni ko'rasiz. Windows-da CMD bilan siz quyidagilarni kiritasiz:
> dir /B %= the /B faqat fayl nomlarini ko'rsatishni aytadi =%
main.exe
main.pdb
main.rs
Bu sizga .rs kengaytmali kod faylini, bajariluvchi faylni(Windowsda main.exe
boshqa barcha tizimlarda main), va Windowsdan foydalanayotganingizda, debugging
ma'lumotlarini o'z ichida saqlovchi .pdb kengaytmali faylni ko'rsatadi.
Bu yerdan siz main yoki main.exe faylini ishga tushirasiz, masalan:
$ ./main # or .\Windows-da main.exe
Agar sizning main.rs faylingiz “Hello, world!” dasturi bo'lsa, bu dastur
ekranga Hello, world! matnini chop etadi.
Agar siz Ruby, Python yoki JavaScript kabi dinamik tilni yaxshi bilsangiz, dasturni alohida bosqichlar sifatida kompilyatsiya qilish va ishga tushirishga odatlanmagan bo'lishingiz mumkin. Rust - bu oldindan tuzilgan kompilyatsiya tili, ya'ni siz dasturni kompilyatsiya qilishingiz va bajariladigan faylni boshqa birovga berishingiz mumkin va ular Rustni o'rnatmasdan ham uni ishga tushirishlari mumkin.Agar siz kimgadir .rb, .py yoki .js faylini bersangiz, ularda Ruby, Python yoki JavaScript ilovasi oʻrnatilgan boʻlishi kerak (mos ravishda). Ammo bu tillarda dasturni kompilyatsiya qilish va ishga tushirish uchun faqat bitta buyruq kerak bo'ladi. Til dizaynida hamma narsa o'zaro kelishuvdir.
Oddiy dasturlar uchun rustc bilan kompilyatsiya qilish juda mos keladi, lekin loyihangiz o'sib borishi bilan siz barcha variantlarni boshqarishni va kodingizni almashishni osonlashtirishni xohlaysiz.
Endi, biz siz bilan haqiqiy Rust dasturlarini tuzishda qulaylik yaratuvchi
Cargo yordamchisi bilan tanishamiz.
Hello, Cargo!
Cargo - bu Rustning build tizimi va paketlar menejeri. Aksariyat Rustaceanlar o'zlarining Rust loyihalarini boshqarish uchun ushbu vositadan foydalanadilar, chunki Cargo siz uchun kodni yaratish, kodingizga bog'liq kutubxonalarni yuklab olish va ushbu kutubxonalarni yaratish kabi ko'plab vazifalarni bajaradi.(Biz sizning kodingizga kerak bo'lgan kutubxonalarni chaqiramiz dependencies.)
Eng oddiy Rust dasturlari, biz hozirgacha yozganimiz kabi, hech qanday dependencylarga ega emas. Agar biz “Hello, world!” Cargo bilan loyiha bo'lsa, u faqat sizning kodingizni yaratish bilan shug'ullanadigan Cargo qismidan foydalanadi. Murakkab Rust dasturlarini yozganingizda, siz dependencylarni qo'shasiz va agar siz Cargo yordamida loyihani boshlasangiz, dependencylarni qo'shish osonroq bo'ladi.
Rust loyihalarining aksariyati Cargolardan foydalanganligi sababli, ushbu kitobning qolgan qismida siz ham Cargodan foydalanasiz deb taxmin qilinadi. O'rnatish bo'limida muhokama qilingan rasmiy o'rnatuvchilardan foydalansangiz, Cargo Rust bilan birga keladi. Agar siz Rust-ni boshqa vositalar orqali o'rnatgan bo'lsangiz, terminalingizga quyidagilarni kiritish orqali Cargo o'rnatilganligini tekshiring:
$ cargo --version
Agar siz versiya raqamini ko'rsangiz, sizda bor! Agar siz command not found kabi xatolikni ko'rsangiz, Cargoni qanday qilib alohida o'rnatish bo'yicha texnik hujjatlarni ko'rib chiqing.
Cargo bilan loyiha yaratish
Keling, Cargo-dan foydalanib yangi loyiha yarataylik va u bizning asl “Hello, world!” loyihadan qanday farq qilishini ko'rib chiqaylik. O'zingizning projects jildigiga (yoki kodingizni saqlashga qaror qilgan joyingizga) qayting. Keyin istalgan operatsion tizimda quyidagilarni bajaring:
$ cargo new hello_cargo
$ cd hello_cargo
Birinchi buyruq hello_cargo nomli yangi jild va loyihani yaratadi. Biz loyihamizga hello_cargo deb nom berdik va Cargo o'z fayllarini xuddi shu nomdagi jildda yaratadi.
hello_cargo jildiga o'ting va fayllar ro'yxatini ko'ring.Cargo biz uchun ikkita fayl va bitta jild yaratganini ko'rasiz: Cargo.toml fayli va ichida main.rs fayli bo'lgan src jildi.
Shuningdek, u .gitignore fayli bilan birga yangi Git repositoryni ishga tushirdi. Mavjud Git repositoryda cargo new ni ishga tushirsangiz, Git fayllari yaratilmaydi; cargo new - vcs=git yordamida bu xatti-harakatni bekor qilishingiz mumkin.
Eslatma: Git keng tarqalgan versiya boshqaruv tizimidir. Siz
--vcsbuyrugʻi yordamidacargo newni boshqa versiyani boshqarish tizimidan foydalanishga yoki versiyani boshqarish tizimisiz foydalanishga oʻzgartirishingiz mumkin. Mavjud variantlarni ko'rish uchuncargo new --helpni ishga tushiring.
Siz tanlagan matn muharririda Cargo.tomlni oching. U 1-2 ro'yxatdagi kodga o'xshash bo'lishi kerak.
Fayl nomi: Cargo.toml
[package]
name = "hello_cargo"
version = "0.1.0"
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
Ro'yxat 1-2: cargo new tomonidan yaratilgan Cargo.toml tarkibi
Bu fayl TOML da (Tom’s Obvious, Minimal Language) formati, bu Cargo konfiguratsiya formati.
Birinchi qator, [package], bo'lim sarlavhasi bo'lib, quyidagi iboralar paketni sozlayotganligini bildiradi.Ushbu faylga qo'shimcha ma'lumot qo'shsak, biz boshqa bo'limlarni qo'shamiz.
Keyingi uchta qatorda Cargo dasturingizni kompilyatsiya qilish uchun kerak bo'lgan konfiguratsiya ma'lumotlarini o'rnatadi: Rustning nomi, versiyasi va foydalanish uchun nashri.
E ilovasida edition kaliti haqida gaplashamiz.
Oxirgi qator, [dependencies], loyihangizning har qanday dependencylarini ro'yxatlash uchun bo'limning boshlanishi. Rustda kod paketlari crates deb ataladi. Ushbu loyiha uchun bizga boshqa cratelar kerak bo'lmaydi, lekin biz 2-bobdagi birinchi loyihada bo'lamiz, shuning uchun biz ushbu dependencies bo'limidan foydalanamiz.
Endi src/main.rs oching va qarang:
Fayl nomi: src/main.rs
fn main() { println!("Hello, world!"); }
Cargo “Hello, world!” siz uchun dastur, xuddi biz Ro'yxat 1-1 da yozganimiz kabi! Hozircha, bizning loyihamiz va yaratilgan Cargo loyihasi o'rtasidagi farq shundaki, Cargo kodni src jildiga joylashtirgan va bizda yuqori jildda Cargo.toml konfiguratsiya fayli mavjud.
Cargo sizning manba fayllaringiz src jildida turishini kutadi. Yuqori darajadagi loyiha jildi faqat README fayllari, litsenziya maʼlumotlari, konfiguratsiya fayllari va kodingizga aloqador boʻlmagan boshqa narsalar uchun moʻljallangan. Cargo-dan foydalanish loyihalaringizni tartibga solishga yordam beradi. Hamma narsaning o'rni bor va hamma narsa o'z o'rnida.
Agar siz “Hello, world!” bilan qilganimizdek, Cargo-dan foydalanmaydigan loyihani boshlagan bo'lsangiz, uni Cargo-dan foydalanadigan loyihaga aylantirishingiz mumkin. Loyiha kodini src jildiga o'tkazing va tegishli Cargo.toml faylini yarating.
Cargo loyihasini qurish va ishga tushirish
Keling, “Hello, world!” ni qurish va ishga tushirishda nima farq qilishini ko'rib chiqaylik. Cargo bilan dasturni hello_cargo jildidan quyidagi buyruqni kiritish orqali loyihangizni build qiling:
$ cargo build
Compiling hello_cargo v0.1.0 (file:///projects/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 2.85 secs
Ushbu buyruq bajariladigan faylni joriy jildingizda emas, balki target/debug/hello_cargo da (yoki Windowsda target\debug\hello_cargo.exe)da yaratadi. Odatiy tuzilish debug tuzilishi bo'lgani uchun Cargo binary faylni debug nomli jildga joylashtiradi. Ushbu buyruq bilan bajariladigan faylni ishga tushirishingiz mumkin:
$ ./target/debug/hello_cargo # yoki .\target\debug\hello_cargo.exe Windowsda
Hello, world!
Agar hammasi yaxshi bo'lsa, Hello, world! terminalga chop etilishi kerak.cargo build ni birinchi marta ishga tushirish ham Cargoning yuqori darajadagi yangi faylni yaratishiga olib keladi: Cargo.lock. Ushbu fayl loyihangizdagi dependencylarning aniq versiyalarini kuzatib boradi. Ushbu loyihada dependencylar yo'q, shuning uchun faylda kod biroz kam. Siz hech qachon ushbu faylni qo'lda o'zgartirishingiz shart emas; Cargo uning tarkibini siz uchun boshqaradi.
Biz hozirgina cargo build orqali loyihasini build qildik va uni ./target/debug/hello_cargo bilan ishga tushirdik, lekin kodni kompilyatsiya qilish uchun cargo run dan ham foydalanishimiz va natijada bajariladigan faylni bitta buyruqda ishga tushirishimiz mumkin:
$ cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.0 secs
Running `target/debug/hello_cargo`
Hello, world!
cargo run dan foydalanish cargo build ni ishga tushirishdan ko'ra qulayroqdir va keyin binary yo'lni to'liq ishlatadi, shuning uchun ko'pchilik ishlab chiquvchilar cargo run dan foydalanadilar.
E'tibor bering, bu safar biz Hello_cargo ni kompilyatsiya qilayotganini ko'rsatadigan natijani ko'rmadik. Cargo fayllar o'zgarmaganligini aniqladi, shuning uchun u qayta tiklanmadi, balki binary faylni ishga tushirdi. Agar siz manba kodingizni o'zgartirgan bo'lsangiz, Cargo loyihani ishga tushirishdan oldin uni qayta build qilgan bo'lar edi va siz ushbu natijani ko'rgan bo'lar edingiz:
$ cargo run
Compiling hello_cargo v0.1.0 (file:///projects/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 0.33 secs
Running `target/debug/hello_cargo`
Hello, world!
Cargo shuningdek, cargo check deb nomlangan buyruqni taqdim etadi. Bu buyruq kompilyatsiya qilish uchun kodingizni tezda tekshiradi, lekin bajariladigan fayl yaratmaydi:
$ cargo check
Checking hello_cargo v0.1.0 (file:///projects/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 0.32 secs
Nima uchun bajariladigan faylni xohlamaysiz? Ko'pincha cargo check cargo builddan ko'ra tezroq bo'ladi,, chunki u bajariladigan faylni yaratish bosqichini o'tkazib yuboradi. Agar siz kod yozish paytida ishingizni doimiy ravishda tekshirayotgan bo'lsangiz, cargo check dan foydalanish loyihangiz hali ham kompilyatsiya qilinayotganligini bildirish jarayonini tezlashtiradi! Shunday qilib, ko'plab Rustaceanlar vaqti-vaqti bilan cargo check ni amalga oshiradilar, chunki ular o'z dasturlarini kompilyatsiya qilishiga ishonch hosil qilish uchun yozadilar. Keyin ular bajariladigan fayldan foydalanishga tayyor bo'lgach, cargo build ni ishga tushiradilar.
Cargo haqida shu paytgacha o'rganganlarimizni takrorlaymiz:
- Biz
cargo newyordamida loyiha yaratamiz. cargo buildyordamida loyihani build qilishimiz mumkin.- Biz
cargo runyordamida bir bosqichda loyiha build qilishimiz va ishga tushirishimiz mumkin. cargo checkyordamida xatolarni tekshirish uchun binary ishlab chiqarmasdan loyihani build qilishimiz mumkin.- Build natijasini bizning kodimiz bilan bir xil jildda saqlash o'rniga, Cargo uni target/debug jildida saqlaydi.
Cargo-dan foydalanishning qo'shimcha afzalligi shundaki, qaysi operatsion tizimda ishlayotganingizdan qat'i nazar, buyruqlar bir xil bo'ladi. Shunday qilib, biz endi Linux va MacOS uchun Windows-ga nisbatan maxsus ko'rsatmalar bermaymiz.
Loyihani Reliz qilish
Loyihangiz nihoyat relizga tayyor bo'lgach, uni optimallashtirish bilan kompilyatsiya qilish uchun cargo build --release dan foydalanishingiz mumkin. Ushbu buyruq target/debug o'rniga target/release da bajariladigan fayl yaratadi. Optimizatsiya Rust kodingizni tezroq ishga tushiradi, lekin bu kompilyatsiya vaqtini uzaytiradi. Shuning uchun ikkita turli profil mavjud: biri tez va tez-tez qayta tiklamoqchi bo'lganingizda ishlab chiqish uchun, ikkinchisi esa oxirgi dasturni yaratish uchun siz foydalanuvchiga qayta tiklanmaydigan va mkon qadar tez ishlaydigan oxirgi dastur. Agar siz kodingizning ishlash vaqtini solishtirmoqchi bo'lsangiz, cargo build --release dasturini ishga tushiring va target/release da bajariladigan fayl bilan taqqoslang.
Konventsiya sifatida Cargo
Oddiy loyihalar bilan Cargo rustc dan foydalanishdan ko'ra unchalik katta foyda keltirmaydi, ammo dasturlaringiz yanada murakkablashgani sayin u o'z qiymatini isbotlaydi.
Dasturlar bir nechta fayllarga ko'payib rivojlanganda yoki ularga dependency kerak bo'lsa, Cargo-ga buildni muvofiqlashtirishga ruxsat berish ancha oson bo'ladi.
hello_cargo loyihasi oddiy bo'lsa ham, u endi Rust karyerangizning qolgan qismida foydalanadigan haqiqiy asboblarning ko'p qismini ishlatadi. Haqiqatan ham, mavjud loyihalar ustida ishlash uchun siz Git yordamida kodni tekshirish, ushbu loyiha jildiga oʻzgartirish va build qilish uchun quyidagi buyruqlardan foydalanishingiz mumkin:
$ git clone github.com/birorta-loyiha
$ cd birorta-loyiha
$ cargo build
Cargo haqida ko'proq ma'lumot olish uchun uning texnik hujjatlarini tekshiring.
Xulosa
Siz allaqachon Rust sayohatingizni ajoyib boshladingiz! Ushbu bobda siz quyidagilarni o'rgandingiz:
- Rust-ning so'nggi barqaror versiyasini
rustupyordamida o'rnatish - Rustning yangi versiyasiga yangilash
- Mahalliy o'rnatilgan texnik hujjatlarni ochish
- “Hello, world!” deb yozing va ishga tushiring. to'g'ridan-to'g'ri
rustcdan foydalangan holda dastur - Cargo konventsiyalaridan foydalangan holda yangi loyiha yaratish va ishga tushirish
Bu Rust kodini o'qish va yozishga odatlanish uchun yanada muhimroq dastur yaratish uchun ajoyib vaqt. Shunday qilib, 2-bobda biz taxminiy o'yin dasturini tuzamiz. Agar siz Rust-da umumiy dasturlash tushunchalari qanday ishlashini o'rganishni afzal ko'rsangiz, 3-bobga qarang va keyin 2-bobga qayting.
Taxmin qilish o'yinini dasturlash
Keling, birgalikda amaliy loyiha orqali Rustga o'taylik! Ushbu bob sizni bir nechta umumiy Rust tushunchalari bilan tanishtirib, ulardan haqiqiy dasturda qanday foydalanishni ko'rsatib beradi. Siz let, match, metodlari, bog'langan funksiyalar, external cratelardan foydalanish va boshqalar haqida bilib olasiz! Keyingi boblarda biz ushbu fikrlarni batafsilroq ko'rib chiqamiz. Ushbu bobda siz faqat asoslarni mashq qilasiz.
Biz klassik boshlang'ich dasturlash muammosini amalga oshiramiz: taxmin qilish o'yini. Bu qanday ishlaydi: dastur 1 dan 100 gacha tasodifiy butun son hosil qiladi. Keyin u o'yinchini taxmin qilishni taklif qiladi.Tahmin kiritilgandan so'ng, dastur taxmin kichik yoki katta ekanligini ko'rsatadi. Agar taxmin to'g'ri bo'lsa, o'yin tabrik xabarini chop etadi va chiqadi.
Yangi loyiha yaratish
Yangi loyihani o'rnatish uchun 1-bobda yaratgan projects jildiga o'ting va Cargo-dan foydalanib yangi loyiha yarating, masalan:
$ cargo new taxminiy_raqam
$ cd taxminiy_raqam
Birinchi cargo new buyrug'i birinchi argument sifatida loyiha nomini (taxminiy_raqam)ni oladi. Ikkinchi buyruq yangi loyiha jildiga kiradi.
Yaratilgan Cargo.toml fayliga qarang:
Fayl nomi: Cargo.toml
[package]
name = "taxminiy_raqam"
version = "0.1.0"
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
1-bobda ko'rganingizdek, cargo new siz uchun “Hello, world!” so'zini chop etadigan dastur yaratadi. src/main.rs faylini tekshiring:
Fayl nomi: src/main.rs
fn main() { println!("Hello, world!"); }
Keling, ushbu "Hello, world!" dasturni yarating va cargo run buyrug'i yordamida ishga tushiring :
$ cargo run
Compiling taxminiy_raqam v0.1.0 (file:///projects/taxminiy_raqam)
Finished dev [unoptimized + debuginfo] target(s) in 1.50s
Running `target/debug/taxminiy_raqam`
Hello, world!
run buyrug‘i loyihani tezda takrorlash kerak bo‘lganda foydali bo‘ladi, biz bu o‘yinda qilganimizdek, keyingisiga o‘tishdan oldin har bir iteratsiyani tezda sinab ko‘ramiz.
src/main.rs faylini qayta oching. Siz ushbu fayldagi barcha kodlarni yozasiz.
Taxmin qilish o'yiniga ishlov berish
Taxmin qilish o'yini dasturining birinchi qismi foydalanuvchi kiritishini so'raydi, ushbu kiritishni qayta ishlaydi va kirish kutilgan shaklda ekanligini tekshiradi. Boshlash uchun biz o'yinchiga taxmin kiritishga ruxsat beramiz. 2-1 ro'yxatdagi kodni src/main.rs ichiga kiriting.
Fayl nomi: src/main.rs
use std::io;
fn main() {
println!("Raqamni topish o'yini!");
println!("Iltimos, taxminingizni kiriting.");
let mut taxmin = String::new();
io::stdin()
.read_line(&mut taxmin)
.expect("Satrni o‘qib bo‘lmadi");
println!("Sizning taxminingiz: {taxmin}");
}Ro'yxat 2-1: Foydalanuvchi tomonidan taxmin qilinadigan va uni chop etadigan kod
Ushbu kod juda ko'p ma'lumotlarni o'z ichiga oladi, shuning uchun uni satrga o'tkazamiz. Foydalanuvchi kiritishini olish va natijani chiqish sifatida chop etish uchun biz io input/output kutubxonasini qamrab olishimiz kerak. io kutubxonasi std deb nomlanuvchi standart kutubxonadan keladi:
use std::io;Odatda, Rust standart kutubxonada belgilangan elementlar to'plamiga ega bo'lib, u har bir dastur doirasiga kiradi. Ushbu to'plam prelude deb ataladi va siz undagi hamma narsani standart kutubxona texnik hujjatlarida ko'rishingiz mumkin.
Agar siz foydalanmoqchi bo'lgan tur preludeda bo'lmasa, siz ushbu turni use iborasi bilan aniq kiritishingiz kerak. std::io kutubxonasidan foydalanish sizga bir qator foydali xususiyatlarni, jumladan, foydalanuvchi kiritishini qabul qilish imkoniyatini beradi.
1-bobda ko'rganingizdek, main funksiya dasturga kirish nuqtasidir:
use std::io;
fn main() {
println!("Raqamni topish o'yini!");
println!("Iltimos, taxminingizni kiriting.");
let mut taxmin = String::new();
io::stdin()
.read_line(&mut taxmin)
.expect("Satrni o‘qib bo‘lmadi");
println!("Sizning taxminingiz: {taxmin}");
}fn sintaksisi yangi funktsiyani e'lon qiladi; Qavslar, (), hech qanday parametr yo'qligini bildiradi; va jingalak qavs, {, funksiyaning asosiy qismini boshlaydi.
1-bobda ham bilib olganingizdek, println! bu ekranga satrni chop etuvchi makros:
use std::io;
fn main() {
println!("Raqamni topish o'yini!");
println!("Iltimos, taxminingizni kiriting.");
let mut taxmin = String::new();
io::stdin()
.read_line(&mut taxmin)
.expect("Satrni o‘qib bo‘lmadi");
println!("Sizning taxminingiz: {taxmin}");
}Ushbu kod o'yin nima ekanligini ko'rsatuvchi va foydalanuvchidan ma'lumot so'rashni chop etadi.
O'zgaruvchilar bilan qiymatlarni saqlash
Keyinchalik, foydalanuvchi ma'lumotlarini saqlash uchun o'zgaruvchi yaratamiz, masalan:
use std::io;
fn main() {
println!("Raqamni topish o'yini!");
println!("Iltimos, taxminingizni kiriting.");
let mut taxmin = String::new();
io::stdin()
.read_line(&mut taxmin)
.expect("Satrni o‘qib bo‘lmadi");
println!("Sizning taxminingiz: {taxmin}");
}Endi dastur qiziqarli bo'lib bormoqda! Bu kichik satrda juda ko'p narsa bor. O'zgaruvchini yaratish uchun let iborasidan foydalanamiz. Mana yana bir misol:
let olmalar = 5;Bu qator olmalar nomli yangi o‘zgaruvchini yaratadi va uni 5 qiymatiga bog‘laydi. Rustda o'zgaruvchilar standard bo'yicha o'zgarmasdir, ya'ni o'zgaruvchiga qiymat berganimizdan keyin qiymat o'zgarmaydi.Biz ushbu kontseptsiyani 3-bobdagi ”O'zgaruvchilar va O'zgaruvchanlik” bo'limida batafsil muhokama qilamiz. Oʻzgaruvchini oʻzgaruvchan qilish uchun oʻzgaruvchi nomidan oldin mut qoʻshamiz:
let olmalar = 5; // o'zgarmas
let mut bananlar = 5; // o'zgaruvchanEslatma:
//sintaksisi satr oxirigacha davom etadigan izohni boshlaydi. Rust izohlarda hamma narsani e'tiborsiz qoldiradi. Izohlarni 3-bobda batafsilroq muhokama qilamiz.
Taxmin qilish o'yin dasturiga qaytsak, endi bilasizki, let mut taxmin taxmin nomli o'zgaruvchan o'zgaruvchini kiritadi. Teng belgisi (=) Rustga biz hozir biror narsani oʻzgaruvchiga bogʻlamoqchi ekanligimizni bildiradi. Tenglik belgisining o'ng tomonida taxmin bog'langan qiymat joylashgan bo'lib, u String::new funksiyasini chaqirish natijasidir, bu Stringning yangi nusxasini qaytaradi.
String standart kutubxona tomonidan taqdim etilgan string turi bo'lib, u rivojlantirib boriladigan, UTF-8 kodlangan matn bitidir.
::new qatoridagi :: sintaksisi new String tipidagi bog'langan funksiya ekanligini bildiradi. Assosiatsiyalangan funksiya bu funksiya
turida amalga oshiriladi, bu holda String. Ushbu new funksiya yangi, bo'sh qatorni yaratadi. Siz ko'p turdagi new funksiyani topasiz, chunki u qandaydir yangi qiymatni yaratadigan funksiyaning umumiy nomi.
To'liq let mut taxmin = String::new(); qatori hozirda String ning yangi, bo'sh nusxasiga bog'langan o'zgaruvchan o'zgaruvchini yaratadi.
Foydalanuvchi ma'lumotlarini qabul qilish
Eslatib o'tamiz, biz dasturning birinchi qatoriga use std::io; bilan standart kutubxonadan input/output funksiyasini kiritgan edik. Endi biz io modulidan stdin funksiyasini chaqiramiz, bu bizga foydalanuvchi kiritishini boshqarish imkonini beradi:
use std::io;
fn main() {
println!("Raqamni topish o'yini!");
println!("Iltimos, taxminingizni kiriting.");
let mut taxmin = String::new();
io::stdin()
.read_line(&mut taxmin)
.expect("Satrni o‘qib bo‘lmadi");
println!("Sizning taxminingiz: {taxmin}");
}Agar biz dasturning boshida use std::io; bilan io kutubxonasini import qilmagan bo'lsak, biz ushbu funktsiya chaqiruvini std::io::stdin sifatida yozish orqali funksiyadan foydalanishimiz xam mumkin. stdin funksiyasi std::io::Stdin misolini qaytaradi, bu sizning terminalingiz uchun standart kirish uchun asosni ifodalovchi tur.
Keyinchalik, .read_line(&mut taxmin) qatori foydalanuvchidan ma'lumot olish uchun standart kiritish nuqtasidagi read_line metodini chaqiradi.
Shuningdek, foydalanuvchi kiritgan maʼlumotlarni qaysi qatorda saqlash kerakligini aytish uchun read_line ga argument sifatida &mut taxmin ni oʻtkazamiz. read_line ning toʻliq vazifasi foydalanuvchi nima yozganidan qatʼiy nazar standart kiritishga olish va uni satrga qoʻshishdir (uning mazmunini qayta yozmasdan), shuning uchun biz bu qatorni argument sifatida beramiz. String argumenti o'zgaruvchan bo'lishi kerak, shuning uchun metod string tarkibini o'zgartirishi mumkin.
& bu argument reference(havola) ekanligini bildiradi, bu sizga kodingizning bir nechta qismlariga ushbu ma'lumotni xotiraga bir necha marta nusxalash kerak bo'lmasdan bitta ma'lumotga kirish imkonini beradi. Referencelar murakkab xususiyat bo'lib, Rustning asosiy afzalliklaridan biri havolalardan foydalanish qanchalik xavfsiz va oson ekanligidir. Ushbu dasturni tugatish uchun ko'p bilimlrga ega bo'lishingiz shart emas. Hozircha siz bilishingiz kerak bo'lgan narsa shundaki, o'zgaruvchilar singari, havolalar ham standard bo'yicha o'zgarmasdir. Demak, uni oʻzgaruvchan qilish uchun &taxmin oʻrniga &mut taxmin yozish kerak. (4-bobda havolalar ko'proq va yaxshiroq tushuntiriladi)
Potensial nosozlikni Result turi bilan hal qilish
Biz hali ham ushbu kod qatori ustida ishlayapmiz. Biz hozir matnning uchinchi qatorini muhokama qilmoqdamiz, lekin u hali ham bitta mantiqiy kod qatorining bir qismi ekanligini unutmang. Keyingi qism bu metod:
use std::io;
fn main() {
println!("Raqamni topish o'yini!");
println!("Iltimos, taxminingizni kiriting.");
let mut taxmin = String::new();
io::stdin()
.read_line(&mut taxmin)
.expect("Satrni o‘qib bo‘lmadi");
println!("Sizning taxminingiz: {taxmin}");
}Biz ushbu kodni quyidagicha yozishimiz mumkin edi:
io::stdin().read_line(&mut taxmin).expect("Satrni o‘qib bo‘lmadi");Biroq, bitta uzun qatorni o'qish qiyin, shuning uchun uni bo'lish yaxshidir. .method_name() sintaksisi bilan metodni chaqirganda uzun qatorlarni ajratishga yordam berish uchun yangi qator va boshqa bo'shliqlarni kiritish ko'pincha oqilona. Endi bu kod nima qilishini muhokama qilaylik.
Yuqorida aytib o'tilganidek, read_line foydalanuvchi kiritgan narsani biz unga o'tkazadigan qatorga qo'yadi, lekin u Result qiymatini ham qaytaradi. Result - ko'pincha enum deb ataladigan enumeration, bu bir nechta mumkin bo'lgan holatlardan birida bo'lishi mumkin bo'lgan tur. Har bir mumkin bo'lgan holatni variant deb ataymiz.
6-bobda enumlar batafsilroq yoritiladi. Ushbu Result turlarining maqsadi xatolarni qayta ishlash ma'lumotlarini kodlashdir.
Result variantlari Ok va Err. Ok varianti operatsiya muvaffaqiyatli bo'lganligini bildiradi va Ok ichida muvaffaqiyatli yaratilgan qiymat.
Err varianti operatsiya bajarilmaganligini bildiradi va Err operatsiya qanday yoki nima uchun bajarilmagani haqida maʼlumotni oʻz ichiga oladi.
Result turidagi qiymatlar, har qanday turdagi qiymatlar kabi, ularda aniqlangan metodlarga ega. Result misolida siz murojat qilishingiz mumkin bo'lgan expect metodi mavjud. Agar Result ning ushbu namunasi Err qiymati bo'lsa, expect dasturning ishlamay qolishiga olib keladi va expect ga argument sifatida siz uzatgan xabarni ko'rsatadi. Agar read_line metodi Errni qaytarsa, bu asosiy operatsion tizimdan kelgan xato natijasi bo'lishi mumkin.
Agar Resultning ushbu namunasi Ok qiymati bo‘lsa, expect Ok ushlab turgan qaytarish qiymatini oladi va siz undan foydalanishingiz uchun aynan shu qiymatni sizga qaytaradi.
Bunday holda, bu qiymat foydalanuvchi kiritishidagi baytlar soni.
Agar siz expect ga murojat qilmasangiz, dastur kompilyatsiya qilinadi, lekin siz ogohlantirish olasiz:
$ cargo build
Compiling taxminiy_raqam v0.1.0 (file:///projects/taxminiy_raqam)
warning: unused `Result` that must be used
--> src/main.rs:10:5
|
10 | io::stdin().read_line(&mut taxmin);
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: this `Result` may be an `Err` variant, which should be handled
= note: `#[warn(unused_must_use)]` on by default
warning: `taxminiy_raqam` (bin "taxminiy_raqam") generated 1 warning
Finished dev [unoptimized + debuginfo] target(s) in 0.59s
Rust read_line dan qaytarilgan Result qiymatini ishlatmaganligingiz haqida ogohlantiradi, bu dastur mumkin bo'lgan xatoni hal qilmaganligini ko'rsatadi.
Ogohlantirishni yo'qotishning to'g'ri yo'li aslida xatolarni qayta ishlash kodini yozishdir, ammo bizning holatlarimizda muammo yuzaga kelganda biz ushbu dasturni ishdan chiqarishni xohlaymiz, shuning uchun biz expect dan foydalanishimiz mumkin. Xatolarni tiklash haqida [9-bobda]recover] bilib olasiz.
Qiymatlarni println! bilan chop etish
Yopuvchi jingalak qavsdan tashqari, kodda hozirgacha muhokama qilinadigan yana bitta satr mavjud:
use std::io;
fn main() {
println!("Raqamni topish o'yini!");
println!("Iltimos, taxminingizni kiriting.");
let mut taxmin = String::new();
io::stdin()
.read_line(&mut taxmin)
.expect("Satrni o‘qib bo‘lmadi");
println!("Sizning taxminingiz: {taxmin}");
}Ushbu satr foydalanuvchi kiritishini o'z ichiga olgan qatorni chop etadi. {} jingalak qavslar to'plami o'rnini egallaydi: {} qiymatini joyida ushlab turadigan qisqichbaqa qisqichlari deb tasavvur qiling. O'zgaruvchining qiymatini chop etishda o'zgaruvchi nomi jingalak qavslar ichiga kirishi mumkin. Ifodani baholash natijasini chop etishda format satriga bo'sh jingalak qavslarni joylashtiring, so'ngra har bir bo'sh jingalak qavs o'rnini egallagan holda bir xil tartibda chop etish uchun vergul bilan ajratilgan iboralar ro'yxati bilan format qatoriga amal qiling. O‘zgaruvchini va ifoda natijasini println! ga bitta chaqiruvda chop etish quyidagicha ko‘rinadi:
#![allow(unused)] fn main() { let x = 5; let y = 10; println!("x = {x} va y + 2 = {}", y + 2); }
Bu kod x = 5 va y + 2 = 12 ni chop etadi.
Birinchi qismni sinovdan o'tkazish
Keling, taxmin qilish o'yinining birinchi qismini sinab ko'raylik. Uni cargo run yordamida ishga tushiring:
$ cargo run
Compiling taxminiy_raqam v0.1.0 (file:///projects/taxminiy_raqam)
Finished dev [unoptimized + debuginfo] target(s) in 6.44s
Running `target/debug/taxminiy_raqam`
Raqamni topish o'yini!
Iltimos, taxminingizni kiriting.
6
Sizni taxminingiz: 6
Shu nuqtada, o'yinning birinchi qismi tugadi: biz klaviaturadan ma'lumotlarni olamiz va keyin uni chop etamiz.
Yashirin raqam yaratish
Keyinchalik, foydalanuvchi taxmin qilishga harakat qiladigan maxfiy raqamni yaratishimiz kerak. Yashirin raqam har safar boshqacha bo'lishi kerak, shuning uchun o'yinni bir necha marta o'ynash qiziqarli bo'ladi. O'yin juda qiyin bo'lmasligi uchun biz 1 dan 100 gacha bo'lgan tasodifiy raqamdan foydalanamiz. Rust hali o'zining standart kutubxonasida tasodifiy raqamlar funksiyasini o'z ichiga olmaydi. Biroq, Rust jamoasi ushbu funksiyaga rand cratei taqdim etadi.
Ko'proq funksionallikka ega bo'lish uchun Cratedan foydalanish
Esda tutingki, crate Rust manba kodi fayllari to'plamidir. Biz qurayotgan loyiha binary crate bo'lib, u bajariladigan. rand crate boshqa dasturlarda foydalanish uchun moʻljallangan va mustaqil ravishda bajarib boʻlmaydigan kodni oʻz ichiga olgan library crate.
Cargoning tashqi cratelarni muvofiqlashtirishi bu erda Cargp haqiqatan ham ishlaydi. rand dan foydalanadigan kodni yozishdan oldin, biz Cargo.toml faylini rand cratesini dependency sifatida qo‘shish uchun o‘zgartirishimiz kerak. Hozir o‘sha faylni oching va Cargo siz uchun yaratgan[dependencies] bo‘limi sarlavhasi ostiga quyidagi qatorni qo‘shing.rand ni aynan bizda boʻlganidek, ushbu versiya raqami bilan belgilaganingizga ishonch hosil qiling, aks holda ushbu qoʻllanmadagi kod misollari ishlamasligi mumkin:
Fayl nomi: Cargo.toml
[dependencies]
rand = "0.8.5"
Cargo.toml faylida sarlavhadan keyingi hamma narsa boshqa bo'lim boshlanmaguncha davom etadigan bo'limning bir qismidir. [dependencies] da siz Cargo loyihangiz qaysi tashqi cratelarga bog'liqligini va bu cratelarning qaysi versiyalari kerakligini aytasiz. Bunday holda, biz rand crateni 0.8.5 semantik versiya spetsifikatsiyasi bilan belgilaymiz. Cargo versiya raqamlarini yozish uchun standart bo'lgan Semantic Versioningni (ba'zan SemVer deb ataladi) tushunadi. 0.8.5 spetsifikatsiyasi aslida ^0.8.5 ning qisqartmasi boʻlib, kamida 0.8.5, lekin 0.9.0 dan past boʻlgan har qanday versiyani bildiradi.
Cargo ushbu versiyalarni 0.8.5 versiyasiga mos keladigan umumiy API-larga ega deb hisoblaydi va bu spetsifikatsiya sizga ushbu bobdagi kod bilan tuziladigan so‘nggi patch versiyasini olishingizni kafolatlaydi. 0.9.0 yoki undan kattaroq versiyalar quyidagi misollar ishlatadigan API bilan bir xil bo'lishi kafolatlanmaydi.
Endi, hech qanday kodni o'zgartirmasdan, 2-2 ro'yxatda ko'rsatilganidek, loyihani build qilaylik.
$ cargo build
Updating crates.io index
Downloaded rand v0.8.5
Downloaded libc v0.2.127
Downloaded getrandom v0.2.7
Downloaded cfg-if v1.0.0
Downloaded ppv-lite86 v0.2.16
Downloaded rand_chacha v0.3.1
Downloaded rand_core v0.6.3
Compiling libc v0.2.127
Compiling getrandom v0.2.7
Compiling cfg-if v1.0.0
Compiling ppv-lite86 v0.2.16
Compiling rand_core v0.6.3
Compiling rand_chacha v0.3.1
Compiling rand v0.8.5
Compiling taxminiy_raqam v0.1.0 (file:///projects/taxminiy_raqam)
Finished dev [unoptimized + debuginfo] target(s) in 2.53s
Ro'yxat 2-2: rand cratesini dependency sifatida qo'shgandan so'ng cargo build dan olingan natija
Siz turli xil versiya raqamlarini (lekin ularning barchasi SemVer tufayli kod bilan mos keladi!) va turli xil satrlarni (operatsion tizimga qarab) ko'rishingiz mumkin va satrlar boshqa tartibda bo'lishi mumkin.
Biz tashqi dependency qo'shganimizda, Cargo Crates.io ma'lumotlarining nusxasi bo'lgan registry dan dependency uchun zarur bo'lgan barcha narsalarning so'nggi versiyalarini oladi.Crates.io - bu Rust ekotizimidagi odamlar o'zlarining ochiq manbali Rust loyihalarini boshqalar foydalanishi uchun joylashtiradigan joy.
registrni yangilagandan so'ng, Cargo [dependencies] bo'limini tekshiradi va ro'yxatda hali yuklab olinmagan cratelarni yuklab oladi. Bu holatda, garchi biz faqat rand ni dependency sifatida ko'rsatgan bo'lsak-da, Cargo rand ishlashga bog'liq bo'lgan boshqa cratelarni ham oldi. Cratelarni yuklab olgandan so'ng, Rust ularni kompilyatsiya qiladi va keyin mavjud bo'lgan dependency bilan loyihani tuzadi.
Agar siz hech qanday o'zgartirishlarsiz darhol cargo build ni qayta ishga tushirsangiz, Finished qatoridan boshqa hech qanday natija olmaysiz. Cargo allaqachon dependencylarni yuklab olganini va kompilyatsiya qilganini biladi va siz Cargo.toml faylida ular haqida hech narsani o'zgartirmagansiz. Cargo, shuningdek, kodingiz haqida hech narsani o'zgartirmaganligingizni biladi, shuning uchun u ham uni qayta kompilyatsiya qilmaydi. Hech narsa qilmasdan, u shunchaki chiqib ketadi.
Agar siz src/main.rs faylini ochsangiz, ahamiyatsiz o'zgarishlarni amalga oshirsangiz va keyin uni saqlab va qayta build qilsangiz, siz faqat ikkita chiqish qatorini ko'rasiz:
$ cargo build
Compiling taxminiy_raqam v0.1.0 (file:///projects/taxminiy_raqam)
Finished dev [unoptimized + debuginfo] target(s) in 2.53 secs
Bu satrlar shuni ko'rsatadiki, Cargo faqat src/main.rs fayliga kichik o'zgartirishingiz bilan buildni yangilaydi. Sizning dependencylaringiz o'zgarmadi, shuning uchun Cargo allaqachon yuklab olingan va ular uchun tuzilgan narsadan qayta foydalanishi mumkinligini biladi..
Cargo.lock fayli bilan qayta tiklanadigan tuzilmalarni ta'minlash
Cargoda siz yoki boshqa birov kodingizni har safar yaratganingizda bir xil artefaktni qayta tiklashingiz mumkinligini ta'minlaydigan mexanizm mavjud: Siz aksini ko'rsatmaguningizcha, cargo faqat siz ko'rsatgan dependency versiyalaridan foydalanadi. Masalan, kelasi hafta rand cratening 0.8.6 versiyasi chiqadi va bu versiyada muhim xatoliklar tuzatilgan, lekin u sizning kodingizni buzadigan regressiyani ham o‘z ichiga oladi. Buni hal qilish uchun Rust birinchi marta cargo build dasturini ishga tushirganingizda Cargo.lock faylini yaratadi, shuning uchun biz endi bu guessing_game jildida mavjud.
Loyihani birinchi marta yaratganingizda, Cargo mezonlarga mos keladigan dependencylarning barcha versiyalarini aniqlaydi va keyin ularni Cargo.lock fayliga yozadi. Keyingi loyihangizni yaratganingizda, Cargo Cargo.lock fayli mavjudligini ko'radi va versiyalarni qayta aniqlash uchun barcha ishlarni bajarishdan ko'ra, u erda ko'rsatilgan versiyalardan foydalanadi. Bu sizga avtomatik ravishda takrorlanadigan tuzilishga ega bo'lish imkonini beradi. Boshqacha qilib aytganda, Cargo.lock fayli tufayli loyihangiz aniq yangilanmaguningizcha 0.8.5 da qoladi. Cargo.lock fayli qayta tiklanadigan tuzilmalar uchun muhim bo'lgani uchun u ko'pincha loyihangizdagi kodning qolgan qismi bilan manba nazoratida tekshiriladi.
Yangi versiyani olish uchun Crateni yangilash
Crateni yangilamoqchi bo'lsangiz, Cargo update buyrug'ini beradi, bu buyruq Cargo.lock faylini e'tiborsiz qoldiradi va Cargo.toml dagi texnik xususiyatlaringizga mos keladigan barcha so'nggi versiyalarni aniqlaydi. Keyin Cargo ushbu versiyalarni Cargo.lock fayliga yozadi. Aks holda, standart bo'yicha, Cargo faqat 0.8.5 dan katta va 0.9.0 dan kichik versiyalarni qidiradi. Agar rand cratesi ikkita yangi 0.8.6 va 0.9.0 versiyalarini chiqargan bo'lsa, cargo update ni ishga tushirgan bo'lsangiz, quyidagilarni ko'rasiz:
$ cargo update
Updating crates.io index
Updating rand v0.8.5 -> v0.8.6
Cargo 0.9.0 versiyasiga e'tibor bermaydi. Bu vaqtda siz Cargo.lock faylingizda oʻzgarishlarni ham sezasiz, bunda siz hozir foydalanayotgan rand cratesi versiyasi 0.8.6. rand 0.9.0 versiyasidan yoki 0.9.x seriyasining istalgan versiyasidan foydalanish uchun Cargo.toml faylini quyidagi koʻrinishda yangilashingiz kerak boʻladi:
[dependencies]
rand = "0.9.0"
Keyingi safar cargo buildni ishga tushirganingizda, Cargo mavjud cratelar reestrini yangilaydi va siz ko‘rsatgan yangi versiyaga muvofiq rand talablaringizni qayta baholaydi.
Cargo va uning ekotizimlari haqida ko'p gapirish mumkin, biz ularni 14-bobda muhokama qilamiz, ammo hozircha bilishingiz kerak bo'lgan narsa shu. Cargo kutubxonalarni qayta ishlatishni juda osonlashtiradi, shuning uchun Rustaceans bir nechta paketlardan yig'ilgan kichikroq loyihalarni yozishga qodir.
Tasodifiy raqamni yaratish
Keling, taxmin qilish uchun raqam yaratishda rand dan foydalanishni boshlaylik. Keyingi qadam 2-3 ro'yxatda ko'rsatilganidek src/main.rs ni yangilashdir.
Fayl nomi: src/main.rs
use std::io;
use rand::Rng;
fn main() {
println!("Raqamni topish o'yini!");
let yashirin_raqam = rand::rng().random_range(1..=100);
println!("Yashirin raqam: {yashirin_raqam}");
println!("Iltimos, taxminingizni kiriting.");
let mut taxmin = String::new();
io::stdin()
.read_line(&mut taxmin)
.expect("Satrni o‘qib bo‘lmadi");
println!("Sizning taxminingiz: {taxmin}");
}Ro'yxat 2-3: Tasodifiy raqam yaratish uchun kod qo'shiladi
Avval use rand::Rng; qatorini qo'shamiz. Rng traiti tasodifiy sonlar generatorlari qo'llaydigan metodlarni belgilaydi va biz ushbu usullardan foydalanishimiz uchun bu trait mos bo'lishi kerak. 10-bobda traitlar batafsil yoritiladi.
Keyin o'rtada ikkita qator qo'shamiz. Birinchi qatorda biz rand::thread_rng funksiyasini chaqiramiz, bu bizga biz foydalanmoqchi bo'lgan tasodifiy sonlar generatorini beradi: joriy bajarilish oqimi uchun mahalliy bo'lgan va operatsion tizim tomonidan ekilgan. Keyin tasodifiy sonlar generatorida gen_range metodini chaqiramiz. Bu metod biz use rand::Rng; iborasi bilan qamrab olgan Rng traiti bilan aniqlanadi. gen_range metodi argument sifatida diapazon ifodasini oladi va diapazonda tasodifiy son hosil qiladi. Biz bu yerda foydalanayotgan diapazon ifodasi turi start..=end shaklini oladi va pastki va yuqori chegaralarni qamrab oladi, shuning uchun biz 1 va 100 oralig‘idagi raqamni so‘rash uchun 1..=100 ni belgilashimiz kerak. .
Eslatma: Siz faqat qaysi traitlardan foydalanishni va qaysi metodlar va funktsiyalarni cratedan chaqirishni bila olmaysiz, shuning uchun har bir crateda foydalanish bo'yicha ko'rsatmalar mavjud. Cargo-ning yana bir qulay xususiyati shundaki,
cargo doc --openbuyrug'ini ishga tushirish sizning barcha dependencylar tomonidan taqdim etilgan texnik hujjatlarni mahalliy sifatida tuzadi va uni brauzeringizda ochadi. Agar sizrandcratedagi boshqa funksiyalarga qiziqsangiz, masalan,cargo doc --openni ishga tushiring va chap tomondagi yon paneldagirandtugmasini bosing.
Ikkinchi yangi qator maxfiy raqamni chop etadi. Bu dasturni ishlab chiqishda uni sinab ko'rishimiz uchun foydalidir, lekin biz uni oxirgi versiyadan o'chirib tashlaymiz. Agar dastur boshlanishi bilanoq javobni chop etsa, bu unchalik o'yin emas!
Dasturni bir necha marta ishga tushirishga harakat qiling:
$ cargo run
Compiling taxminiy_raqam v0.1.0 (file:///projects/taxminiy_raqam)
Finished dev [unoptimized + debuginfo] target(s) in 2.53s
Running `target/debug/taxminiy_raqam`
Raqamni topish o'yini!
Yashirin raqam: 7
Iltimos, taxminingizni kiriting.
4
Siznig taxminingiz: 4
$ cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.02s
Running `target/debug/taxminiy_raqam`
Raqamni topish o'yini!
Yashirin raqam: 83
Iltimos, taxminingizni kiriting.
5
Siznig taxminingiz: 5
Siz turli xil tasodifiy raqamlarni olishingiz kerak va ularning barchasi 1 dan 100 gacha raqamlar bo'lishi kerak. Ajoyib ish!
Taxminni maxfiy raqam bilan solishtirish
Endi bizda foydalanuvchi kiritishi va tasodifiy raqam bor, biz ularni solishtirishimiz mumkin. Ushbu qadam 2-4 ro'yxatda ko'rsatilgan. E'tibor bering, bu kod hozircha kompilatsiya bo'lmaydi, biz tushuntiramiz.
Fayl nomi: src/main.rs
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
// --snip--
println!("Raqamni topish o'yini!");
let yashirin_raqam = rand::thread_rng().gen_range(1..=100);
println!("Yashirin raqam: {yashirin_raqam}");
println!("Iltimos, taxminingizni kiriting.");
let mut taxmin = String::new();
io::stdin()
.read_line(&mut taxmin)
.expect("Satrni o‘qib bo‘lmadi");
println!("Sizning taxminingiz: {taxmin}");
match taxmin.cmp(&yashirin_raqam) {
Ordering::Less => println!("Raqam Kichik!"),
Ordering::Greater => println!("Raqam katta!"),
Ordering::Equal => println!("Siz yutdingiz!"),
}
}Ro'yxat 2-4: Ikki raqamni solishtirishning mumkin bo'lgan qaytish qiymatlarini boshqarish
Avval biz standart kutubxonadan std::cmp::Ording deb nomlangan turni olib keladigan yana bir use iborasini qo'shamiz. Ordering turi boshqa raqam boʻlib, Less, Greater va Equal variantlariga ega. Bu ikkita qiymatni solishtirganda mumkin bo'lgan uchta natijadir.
Keyin pastki qismida Ordering turidan foydalanadigan beshta yangi qator qo'shamiz. cmp metodi ikkita qiymatni solishtiradi va uni solishtirish mumkin bo'lgan har qanday narsani chaqirish mumkin. Siz solishtirmoqchi bo'lgan narsaga reference kerak: bu yerda taxmin bilan yashirin_raqam solishtiriladi. Keyin u biz use iborasi bilan qamrab olgan Ordering raqamining variantini qaytaradi. Biz taxmin va yashirin_raqam qiymatlari bilan cmp ga murojatdan Ordering ning qaysi varianti qaytarilganiga qarab, keyin nima qilish kerakligini hal qilish uchun match ifodasidan foydalanamiz.
Match ifodasi arms dan tuzilgan. Arm mos keladigan pattern va agar match ga berilgan qiymat armning patterniga mos kelsa, bajarilishi kerak bo'lgan koddan iborat. Rust match ga berilgan qiymatni oladi va har bir armning patternini o'z navbatida ko'rib chiqadi. Patternlar va match konstruksiyasi Rust-ning kuchli xususiyatlari hisoblanadi: ular sizning kodingiz duch kelishi mumkin bo'lgan turli vaziyatlarni ifodalash imkonini beradi va ularning barchasini boshqarishingizga ishonch hosil qiladi. Bu xususiyatlar mos ravishda 6-bobda va 18-bobda batafsil yoritiladi.
Keling, bu yerda ishlatadigan match iborasi bilan bir misolni ko'rib chiqaylik. Aytaylik, foydalanuvchi 50 ni taxmin qilgan va bu safar tasodifiy yaratilgan maxfiy raqam 38 ni tashkil qiladi.
Kod 50 ni 38 ga solishtirganda, cmp metodi Ordering::Greater ni qaytaradi, chunki 50 38 dan katta. match ifodasi Ordering::Greater qiymatini oladi va har bir armning patternini tekshirishni boshlaydi. U birinchi armning Ordering::Less patternini koʻrib chiqadi va Ordering::Greater qiymati Ordering::Less qiymatiga mos kelmasligini koʻradi, shuning uchun u armdagi kodga eʼtibor bermaydi va keyingi armga oʻtadi. Keyingi armning namunasi Ordering::Greater boʻlib, Ordering::Greater bilan does match keladi! Oʻsha armdagi bogʻlangan kod ishga tushadi va ekranga Raqam katta! deb chop etiladi. match iborasi birinchi muvaffaqiyatli o'yindan keyin tugaydi, shuning uchun bu senariydagi oxirgi armni ko'rib chiqmaydi.
Biroq, 2-4 ro'yxatdagi kod hali kompilyatsiya qilinmaydi. Keling, sinab ko'raylik:
$ cargo build
Compiling libc v0.2.86
Compiling getrandom v0.2.2
Compiling cfg-if v1.0.0
Compiling ppv-lite86 v0.2.10
Compiling rand_core v0.6.2
Compiling rand_chacha v0.3.0
Compiling rand v0.8.5
Compiling taxminiy_raqam v0.1.0 (file:///projects/taxminiy_raqam)
error[E0308]: mismatched types
--> src/main.rs:22:21
|
22 | match taxmin.cmp(&yashirin_raqam) {
| --- ^^^^^^^^^^^^^^ expected struct `String`, found integer
| |
| arguments to this function are incorrect
|
= note: expected reference `&String`
found reference `&{integer}`
note: associated function defined here
--> /rustc/d5a82bbd26e1ad8b7401f6a718a9c57c96905483/library/core/src/cmp.rs:783:8
For more information about this error, try `rustc --explain E0308`.
error: could not compile `taxminiy_raqame` due to previous error
Xatoning asosi mos kelmaydigan turlar mavjudligini bildiradi. Rust kuchli, statik turdagi tizimga ega. Biroq, u ham turdagi inference ega. Biz let mut taxmin = String::new() deb yozganimizda, Rust taxmin String bo'lishi kerak degan xulosaga keldi va bizni turni yozishga majburlamadi. Boshqa tomondan, yashirin_raqam raqam turidir. Rust raqamlarining bir nechta turlari 1 dan 100 gacha qiymatga ega bo'lishi mumkin: i32, 32 bitli raqam; u32, unsigned 32-bitli raqam; i64, 64-bitli raqam; boshqalar kabi. Agar boshqacha koʻrsatilmagan boʻlsa, Rust standart boʻyicha i32 ga oʻrnatiladi, bu yashirin_raqam turiga, agar siz Rustning boshqa raqamli turini chiqarishiga olib keladigan turdagi maʼlumotlarni boshqa joyga qoʻshmasangiz. Xatoning sababi shundaki, Rust string va raqam turini taqqoslay olmaydi.
Oxir-oqibat, biz dastur tomonidan kiritilgan String ni haqiqiy son turiga aylantirmoqchimiz, shuning uchun uni raqamli raqam bilan yashirin raqam bilan solishtirishimiz mumkin.Buni main funksiya tanasiga ushbu qatorni qo'shish orqali qilamiz:
Fayl nomi: src/main.rs
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Raqamni topish o'yini!");
let yashirin_raqam = rand::thread_rng().gen_range(1..=100);
println!("Yashirin raqam: {yashirin_raqam}");
println!("Iltimos, taxminingizni kiriting.");
// --snip--
let mut taxmin = String::new();
io::stdin()
.read_line(&mut taxmin)
.expect("Satrni o‘qib bo‘lmadi");
let taxmin: u32 = taxmin.trim().parse().expect("Iltimos, raqam yozing!");
println!("Sizning taxminingiz: {taxmin}");
match taxmin.cmp(&yashirin_raqam) {
Ordering::Less => println!("Raqam Kichik!"),
Ordering::Greater => println!("Raqam katta!"),
Ordering::Equal => println!("Siz yutdingiz!"),
}
}Satr
let taxmin: u32 = taxmin.trim().parse().expect("Iltimos, raqam yozing!");Biz taxmin nomli o'zgaruvchini yaratamiz. Ammo shoshilmang, dasturda allaqachon taxmin nomli o'zgaruvchi mavjud emasmi? Bu shunday, lekin foydali Rust bizga taxmin ning oldingi qiymatini yangisi bilan ergashtirish imkonini beradi. Shadowing bizga ikkita noyob oʻzgaruvchini yaratish oʻrniga, taxmin oʻzgaruvchi nomidan qayta foydalanish imkonini beradi, masalan, taxmin_str va taxmin. Biz buni 3-bobda batafsil ko'rib chiqamiz, ammo hozircha shuni bilingki, bu xususiyat ko'pincha qiymatni bir turdan boshqa turga aylantirmoqchi bo'lganingizda ishlatiladi.
Biz bu yangi o'zgaruvchini taxmin.trim().parse() ifodasiga bog'laymiz. Ifodadagi taxmin matni qator sifatida kiritilgan asl taxmin o'zgaruvchisiga ishora qiladi. String misolidagi trim metodi boshida va oxiridagi har qanday bo‘shliqni yo‘q qiladi, bu qatorni faqat raqamli ma’lumotlarni o‘z ichiga olishi mumkin bo‘lgan u32 bilan solishtirishimiz uchun buni qilishimiz kerak. Foydalanuvchi read_line ni to'ldirish uchun entertugmasini bosib, ularni kiritishi kerak
satrga yangi satr belgisini qo'shadigan taxmin. Masalan, agar foydalanuvchi 5 raqamini kiritsa va va enter tugmasini bossa taxmin shunday ko'rinadi: 5\n.
\n “yangi qator”ni bildiradi. (Windows tizimida enter tugmasini bosish natijasida carriage qaytariladi va yangi qator \r\n chiqadi.)
trim metodi \n yoki \r\nni yo'q qiladi, natijada atigi 5 bo`ladi.
Satrlardagi parse metodi qatorni boshqa turga aylantiradi.
Bu yerda biz uni stringdan raqamga aylantirish uchun foydalanamiz. Biz Rustga let taxmin: u32 yordamida kerakli raqam turini aytishimiz kerak. taxmin dan keyin ikki nuqta (:) Rustga o'zgaruvchining turiga izoh berishimizni aytadi. Rust bir nechta o'rnatilgan raqam turlariga ega; Bu yerda koʻrilgan u32 unsigned, 32-bitli butun son.
Bu kichik ijobiy raqam uchun yaxshi standart tanlovdir. Boshqa raqamlar turlari haqida 3-bobda bilib olasiz.
Bundan tashqari, ushbu misol dasturidagi u32 annotation va yashirin_raqam bilan taqqoslash Rust yashirin_raqam ham u32 bo'lishi kerak degan xulosaga keladi. Shunday qilib, endi taqqoslash bir xil turdagi ikkita qiymat o'rtasida bo'ladi!
parse metodii faqat mantiqiy ravishda raqamlarga aylantirilishi mumkin bo'lgan belgilarda ishlaydi va shuning uchun osongina xatolarga olib kelishi mumkin. Agar, masalan, satrda A👍% bo'lsa, uni raqamga aylantirishning hech qanday metodi bo'lmaydi. Muvaffaqiyatsiz bo'lishi mumkinligi sababli, parse metodii read_line metodi kabi Result turini qaytaradi (oldingi ["Result bilan potentsial muvaffaqiyatsizlikni ko'rib chiqish"] bo'limida muhokama qilingan)(#handling-potential-failure-with-result)). Biz ushbu Result ga yana expect metodini qo'llash orqali xuddi shunday munosabatda bo'lamiz. Agar parse qatordan raqam yarata olmagani uchun Err Result variantini qaytarsa, expect chaqiruvi o‘yinni buzadi va biz bergan xabarni chop etadi.
Agar parse qatorni raqamga muvaffaqiyatli aylantira olsa, u Resultning Ok variantini qaytaradi va expect biz xohlagan raqamni Ok qiymatidan qaytaradi.
Endi dasturni ishga tushiramiz:
$ cargo run
Compiling taxminiy_raqam v0.1.0 (file:///projects/taxminiy_raqam)
Finished dev [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/taxminiy_raqam`
Raqamni topish o'yini!
Yashirin raqam: 58
Iltimos, taxminingizni kiriting.
76
Sizning taxminingiz: 76
Raqam katta!
Yaxshi! Tahmindan oldin bo'shliqlar qo'shilgan bo'lsa ham, dastur foydalanuvchi 76 ni taxmin qilganini aniqladi. Har xil turdagi kirishlar bilan turli xatti-harakatlarni tekshirish uchun dasturni bir necha marta ishga tushiring: raqamni to'g'ri taxmin qiling, katta raqamni taxmin qiling va kichik raqamni taxmin qiling.
Hozir bizda o'yinning ko'p qismi ishlayapti, lekin foydalanuvchi faqat bitta taxmin qila oladi. Keling, buni loop qo'shish orqali o'zgartiraylik!
Loop bilan bir nechta taxminlarga ruxsat berish
loop kalit so'zi cheksiz tsiklni yaratadi. Biz foydalanuvchilarga raqamni taxmin qilishda ko'proq imkoniyat berish uchun tsikl qo'shamiz:
Fayl nomi: src/main.rs
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Raqamni topish o'yini!");
let yashirin_raqam = rand::thread_rng().gen_range(1..=100);
// --snip--
println!("Yashirin raqam: {yashirin_raqam}");
loop {
println!("Iltimos, taxminingizni kiriting.");
// --snip--
let mut taxmin = String::new();
io::stdin()
.read_line(&mut taxmin)
.expect("Satrni o‘qib bo‘lmadi");
let taxmin: u32 = taxmin.trim().parse().expect("Iltimos, raqam yozing!");
println!("Sizning taxminingiz: {taxmin}");
match taxmin.cmp(&yashirin_raqam) {
Ordering::Less => println!("Raqam Kichik!"),
Ordering::Greater => println!("Raqam katta!"),
Ordering::Equal => println!("Siz yutdingiz!"),
}
}
}Ko'rib turganingizdek, biz hamma narsani taxminiy kiritish so'rovidan boshlab tsiklga o'tkazdik. Ilova ichidagi satrlarni har birida yana to'rtta bo'sh joydan o'tkazganingizga ishonch hosil qiling va dasturni qayta ishga tushiring. Dastur endi boshqa bir taxminni abadiy yani har doim so'raydi, bu aslida yangi muammoni keltirib chiqaradi. Foydalanuvchi chiqa olmaydiganga o'xshaydi!
Foydalanuvchi har doim ctrl-c klaviatura yorlig'i yordamida dasturni to'xtatishi mumkin. Ammo bu to'yib bo'lmaydigan yirtqich hayvondan qochishning yana bir yo'li bor, “Taxminni maxfiy raqam bilan solishtirish“: mavzusidagi parse muhokamasida aytib o'tilganidek, agar foydalanuvchi raqam bo'lmagan javobni kiritsa, dastur buziladi. Bu yerda ko'rsatilganidek, foydalanuvchiga chiqishga ruxsat berish uchun undan foydalanishimiz mumkin
$ cargo run
Compiling taxminiy_raqam v0.1.0 (file:///projects/taxminiy_raqam)
Finished dev [unoptimized + debuginfo] target(s) in 1.50s
Running `target/debug/taxminiy_raqam`
Raqamni topish o'yini!
Yashirin raqam: 59
Iltimos, taxminingizni kiriting.
45
Sizning taxminingiz: 45
Raqam Kichik!
Iltimos, taxminingizni kiriting.
60
Sizning taxminingiz: 60
Raqam katta!
Iltimos, taxminingizni kiriting.
59
Sizning taxminingiz: 59
Siz yutdingiz!
Iltimos, taxminingizni kiriting.
quit
thread 'main' panicked at 'Please type a number!: ParseIntError { kind: InvalidDigit }', src/main.rs:28:47
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
quit deb yozsangiz, o‘yin tugaydi, lekin siz ko‘rganingizdek, boshqa raqam bo‘lmagan ma’lumotlarni kiritish ham shunday bo‘ladi. Bu, eng kamida, suboptimaldir; Biz to'g'ri raqam taxmin qilinganda ham o'yin to'xtashini xohlaymiz.
To'g'ri taxmindan keyin chiqish
Keling, foydalanuvchi g'alaba qozonganida break iborasini qo'shish orqali o'yinni to'xtatish uchun dasturlashtiramiz:
Fayl nomi: src/main.rs
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Raqamni topish o'yini!");
let yashirin_raqam = rand::thread_rng().gen_range(1..=100);
println!("Yashirin raqam: {yashirin_raqam}");
loop {
println!("Iltimos, taxminingizni kiriting.");
let mut taxmin = String::new();
io::stdin()
.read_line(&mut taxmin)
.expect("Satrni o‘qib bo‘lmadi");
let taxmin: u32 = taxmin.trim().parse().expect("Iltimos, raqam yozing!");
println!("Sizning taxminingiz: {taxmin}");
// --snip--
match taxmin.cmp(&yashirin_raqam) {
Ordering::Less => println!("Raqam Kichik!"),
Ordering::Greater => println!("Raqam katta!"),
Ordering::Equal => {
println!("Siz yutdingiz!");
break;
}
}
}
}Siz yutdingiz! so‘ng break qatorini qo‘shish foydalanuvchi maxfiy raqamni to‘g‘ri taxmin qilganda dasturni tsikldan chiqadi. Loopdan chiqish dasturdan chiqishni ham anglatadi, chunki sikl main ning oxirgi qismidir.
Noto'g'ri kiritish
O'yinning xatti-harakatlarini yanada yaxshilash uchun, foydalanuvchi raqamlardan boshqa belgilar kiritganda dasturni ishdan chiqargandan ko'ra, foydalanuvchi taxmin qilishni davom ettirishi uchun o'yinni raqam bo'lmagan belgilarga e'tibor bermaslikka harakat qildiraylik. Buni 2-5 roʻyxatda koʻrsatilganidek, taxmin satrdan u32 ga aylantirilgan qatorni oʻzgartirish orqali amalga oshirishimiz mumkin.
Fayl nomi: src/main.rs
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Raqamni topish o'yini!");
let yashirin_raqam = rand::thread_rng().gen_range(1..=100);
println!("Yashirin raqam: {yashirin_raqam}");
loop {
println!("Iltimos, taxminingizni kiriting.");
let mut taxmin = String::new();
// --snip--
io::stdin()
.read_line(&mut taxmin)
.expect("Satrni o‘qib bo‘lmadi");
let taxmin: u32 = match taxmin.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("Sizning taxminingiz: {taxmin}");
// --snip--
match taxmin.cmp(&yashirin_raqam) {
Ordering::Less => println!("Raqam Kichik!"),
Ordering::Greater => println!("Raqam katta!"),
Ordering::Equal => {
println!("Siz yutdingiz!");
break;
}
}
}
}Ro'yxat 2-5: Raqamsiz taxminga e'tibor bermaslik va dasturni ishdan chiqarish o'rniga boshqa taxminni so'rash
Xato ustida ishlamay qolishdan xatoni hal qilishga o‘tish uchun biz expect chaqiruvidan match ifodasiga o‘tamiz. Esda tutingki, parse Result turini qaytaradi, Result esa Ok va Err variantlariga ega bo'lgan raqamdir. Biz bu yerda cmp metodining Ordering natijasi bilan bo‘lgani kabi match ifodasidan foydalanmoqdamiz.
Agar parse qatorni raqamga muvaffaqiyatli aylantira olsa, natijada olingan raqamni o'z ichiga olgan Ok qiymatini qaytaradi. Bu Ok qiymati birinchi armning patterniga mos keladi va match ifodasi parse ishlab chiqarilgan va Ok qiymatiga qo'ygan num qiymatini qaytaradi. Bu raqam biz yaratayotgan yangi taxmin o'zgaruvchisida biz xohlagan joyda tugaydi
Agar parse satrni raqamga aylantira olmasa xato haqida qo'shimcha ma'lumotni o'z ichiga olgan Err qiymatini qaytaradi. Err qiymati birinchi match bo‘limidagi Ok(num) patterniga mos kelmaydi, lekin ikkinchi armdagi Err(_) patterniga mos keladi. Pastki chiziq, _, diqqatga sazovor qiymatdir; bu misolda biz barcha Err qiymatlariga, ular ichida qanday ma'lumotlar bo'lishidan qat'iy nazar, mos kelmoqchimiz deymiz. Shunday qilib, dastur ikkinchi armning continue kodini bajaradi, bu dasturga loop ning keyingi iteratsiyasiga o'tishni va boshqa taxminni so'rashni aytadi. Shunday qilib, dastur parse duch kelishi mumkin bo'lgan barcha xatolarga e'tibor bermaydi!
Endi dasturdagi hamma narsa kutilganidek ishlashi kerak. Keling, sinab ko'raylik:
$ cargo run
Compiling taxminiy_raqam v0.1.0 (file:///projects/taxminiy_raqam)
Finished dev [unoptimized + debuginfo] target(s) in 4.45s
Running `target/debug/taxminiy_raqam`
Raqamni topish o'yini!
Yashirin raqam: 61
Iltimos, taxminingizni kiriting.
10
Sizning taxminingiz: 10
Raqam Kichik!
Iltimos, taxminingizni kiriting.
99
Sizning taxminingiz: 99
Raqam katta!
Iltimos, taxminingizni kiriting.
foo
Iltimos, taxminingizni kiriting.
61
Sizning taxminingiz: 61
Siz yutdingiz!
Ajoyib! Bitta kichik so'nggi tweak bilan biz taxmin qilish o'yinini tugatamiz. Eslatib o'tamiz, dastur hali ham maxfiy raqamni chop etmoqda. Bu sinov uchun yaxshi ishladi, lekin o'yinni buzadi. Maxfiy raqamni chiqaradigan println!ni o'chirib tashlaymiz. 2-6 ro'yxat yakuniy kodni ko'rishingiz mumkin.
Fayl nomi: src/main.rs
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Raqamni topish o'yini!");
let yashirin_raqam = rand::thread_rng().gen_range(1..=100);
loop {
println!("Iltimos, taxminingizni kiriting.");
let mut taxmin = String::new();
io::stdin()
.read_line(&mut taxmin)
.expect("Satrni o‘qib bo‘lmadi");
let taxmin: u32 = match taxmin.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("Sizning taxminingiz: {taxmin}");
match taxmin.cmp(&yashirin_raqam) {
Ordering::Less => println!("Raqam Kichik!"),
Ordering::Greater => println!("Raqam katta!"),
Ordering::Equal => {
println!("Siz yutdingiz!");
break;
}
}
}
}Ro'yxat 2-6: To'liq taxmin qilish o'yin kodini
Shu nuqtada, siz taxmin qilish o'yinini muvaffaqiyatli yaratdingiz. Tabriklaymiz!
Xulosa
Ushbu loyiha sizni Rustning ko'plab yangi tushunchalari bilan tanishtirishning amaliy usuli bo'ldi: let, match, funktsiyalar, tashqi cratelardan foydalanish va boshqalar. Keyingi bir necha boblarda siz ushbu tushunchalar haqida batafsilroq bilib olasiz. 3-bob ko'pchilik dasturlash tillarida mavjud bo'lgan o'zgaruvchilar, ma'lumotlar turlari va funktsiyalari kabi tushunchalarni qamrab oladi va ulardan Rustda qanday foydalanishni ko'rsatadi. 4-bobda Rust tilini boshqa tillardan ajratib turadigan egalik huquqi o‘rganiladi. 5-bobda tuzilmalar va metodlar sintaksisi muhokama qilinadi va 6-bobda enumlar qanday ishlashi tushuntiriladi.
Umumiy dasturlash tushunchalari
Ushbu bob deyarli barcha dasturlash tillarida paydo bo'ladigan tushunchalarni va ular Rustda qanday ishlashini o'z ichiga oladi. Ko'pgina dasturlash tillari o'rtasida juda ko'p umumiylik mavjud. Ushbu bobda keltirilgan tushunchalarning hech biri Rustga xos emas, lekin biz ularni Rust kontekstida ko'rib chiqamiz va ushbu tushunchalardan foydalanish bo'yicha konventsiyalarni tushuntiramiz.
Xususan, siz o'zgaruvchilar, asosiy turlar, funktsiyalar, izohlar va control flow haqida bilib olasiz. Ushbu asoslar har bir Rust dasturida bo'ladi va ularni erta o'rganish sizga boshlash uchun kuchli asos bo'ladi.
Kalit so'zlar
Rust dasturlash tilida boshqa tillardagi kabi faqat til tomonidan foydalanish uchun ajratilgan kalit so'zlar to'plami mavjud. Shuni yodda tutingki, siz ushbu so'zlarni o'zgaruvchilar yoki funksiyalar nomi sifatida ishlata olmaysiz. Kalit so'zlarning aksariyati maxsus ma'noga ega va siz ulardan Rust dasturlarida turli vazifalarni bajarish uchun foydalanasiz; ba'zilarida ular bilan bog'liq bo'lgan joriy funksionallik yo'q, lekin kelajakda Rustga qo'shilishi mumkin bo'lgan funksiyalar uchun ajratilgan. Kalit so'zlar ro'yxatini A ilovasida. topishingiz mumkin.
O'zgaruvchilar va o'zgaruvchanlik
”O'zgaruvchilar bilan qiymatlarni saqlash” bo'limida aytib o'tilganidek, standart bo'yicha o'zgaruvchilar o'zgarmasdir.Rust sizga o'z kodingizni Rust taqdim etgan xavfsizlik va qulay parallellikdan foydalanadigan tarzda yozish uchun beradigan ko'plab qulayliklardan biridir. Biroq, siz hali ham o'zgaruvchilaringizni o'zgaruvchan qilish imkoniyatiga egasiz. Keling, Rust sizni qanday qilib va nima uchun o'zgarmaslikni afzal ko'rishga undashini va nega ba'zan siz undan voz kechishingiz mumkinligini bilib olaylik.
Agar o'zgaruvchi o'zgarmas bo'lsa, qiymat nomga bog'langandan keyin siz bu qiymatni o'zgartira olmaysiz. Buni ko'rsatish uchun cargo new variables yordamida projects jildingizda variables nomli yangi loyihani yarating.
Keyin, yangi variables jildida src/main.rs ni oching va uning kodini quyidagi kod bilan almashtiring. Bu kod hozircha kompilyatsiya qilinmaydi, biz avval o'zgarmaslik xatosini ko'rib chiqamiz.
Fayl nomi: src/main.rs
fn main() {
let x = 5;
println!("x qiymati: {x}");
x = 6;
println!("x qiymati: {x}");
}Kodni saqlang va dasturni cargo run yordamida ishga tushiring. Ushbu chiqishda ko'rsatilganidek, o'zgarmaslik xatosi haqida xato xabarini olishingiz kerak:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
error[E0384]: cannot assign twice to immutable variable `x`
--> src/main.rs:4:5
|
2 | let x = 5;
| -
| |
| first assignment to `x`
| help: consider making this binding mutable: `mut x`
3 | println!("x qiymati: {x}");
4 | x = 6;
| ^^^^^ cannot assign twice to immutable variable
For more information about this error, try `rustc --explain E0384`.
error: could not compile `variables` due to previous error
Ushbu misol kompilyator sizning dasturlaringizdagi xatolarni topishga qanday yordam berishini ko'rsatadi. Kompilyatordagi xatolar sizni asabiylashtirishi mumkin, lekin aslida ular sizning dasturingiz hali siz xohlagan narsani xavfsiz bajarmayotganligini anglatadi; ular sizning yaxshi dasturchi emasligingizni bildirmaydi! Tajribali Rustaceanlar hali ham kompilyator xatolariga duch kelishadi.
Siz oʻzgarmas x oʻzgaruvchisiga ikkinchi qiymatni belgilashga harakat qilganingiz uchun ````x` oʻzgaruvchisiga ikki marta tayinlab boʻlmaydi``` xato xabarini oldingiz.
O'zgarmas deb belgilangan qiymatni o'zgartirishga urinayotganda kompilyatsiya vaqtida xatolarga duch kelishimiz muhim, chunki bu holat xatolarga olib kelishi mumkin.Agar bizning kodimizning bir qismi qiymat hech qachon o'zgarmasligi haqidagi faraz asosida ishlayotgan bo'lsa va kodimizning boshqa qismi bu qiymatni o'zgartirsa, kodning birinchi qismi uni bajarish uchun mo'ljallangan narsani qilmasligi mumkin. Bunday xatoning sababini aniqlash qiyin bo'lishi mumkin, ayniqsa kodning ikkinchi qismi faqat ba'zan qiymatini o'zgartirganda. Rust kompilyatori qiymat o'zgarmasligini bildirganingizda, u haqiqatan ham o'zgarmasligini kafolatlaydi, shuning uchun uni o'zingiz kuzatib borishingiz shart emas. Shunday qilib, kodingizni tushunish osonroq.
Ammo o'zgaruvchanlik juda foydali bo'lishi mumkin va kodni yozishni qulayroq qilishi mumkin.
Garchi oʻzgaruvchilar standart boʻyicha oʻzgarmas boʻlsa-da, 2-bobda boʻlgani kabi oʻzgaruvchi nomi oldiga mut qoʻshish orqali ularni oʻzgaruvchan qilish mumkin. mut qo'shilishi, shuningdek, kodning boshqa qismlari ushbu o'zgaruvchining qiymatini o'zgartirishini ko'rsatib, kelajakdagi kod o'quvchilariga niyatni bildiradi.
Masalan, src/main.rs ni quyidagiga o'zgartiramiz:
Fayl nomi: src/main.rs
fn main() { let mut x = 5; println!("x qiymati: {x}"); x = 6; println!("x qiymati: {x}"); }
Dasturni hozir ishga tushirganimizda, biz quyidagilarni olamiz:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
Finished dev [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/variables`
x qiymati: 5
x qiymati: 6
mut ishlatilganda x ga bog‘langan qiymatni 5 dan 6 ga o‘zgartirishga ruxsat beriladi. Oxir oqibat, o'zgaruvchanlikni qo'llash yoki qilmaslikni hal qilish sizga bog'liq va bu vaziyatda eng aniq deb o'ylagan narsangizga bog'liq.
Konstantalar
O'zgarmas o'zgaruvchilar singari, konstantalar nomga bog'langan va o'zgarishi mumkin bo'lmagan qiymatlardir, lekin konstantalar va o'zgaruvchilar o'rtasida bir nechta farqlar mavjud.
Birinchidan, mut dan konstantalar bilan foydalanishga ruxsat berilmagan. Konstantalar standart bo'yicha shunchaki o'zgarmas emas - ular har doim o'zgarmasdir.Siz konstantalarni let kalit so'zi o'rniga const kalit so'zidan foydalanib e'lon qilasiz va qiymat turiga annotatsiya qilinishi kerak. Biz turlar va izohlarni keyingi "Ma'lumotlar turlari" bo'limida ko'rib chiqamiz, shuning uchun hozir tafsilotlar haqida qayg'urmang. Bilingki, siz har doim turga annotate qo'yishingiz kerak.
Konstantalar har qanday miqyosda, shu jumladan global miqyosda e'lon qilinishi mumkin, bu ularni kodning ko'p qismlari bilishi kerak bo'lgan qiymatlar uchun foydali qiladi.
Oxirgi farq shundaki, konstantalar faqat ish vaqtida hisoblanishi mumkin bo'lgan qiymatning natijasi emas, balki faqat konstanta ifodaga o'rnatilishi mumkin.
Mana konstanta deklaratsiyaga misol:
#![allow(unused)] fn main() { const SONIYADA_UCH_SOAT: u32 = 60 * 60 * 3; }
Konstanta nomi SONIYADA_UCH_SOAT va uning qiymati 60 ni (bir daqiqadagi soniyalar soni) 60 ga (bir soatdagi daqiqalar soni) 3 ga (biz hisoblamoqchi bo'lgan soatlar soni) ko'paytirish natijasiga o'rnatiladi. Rustning konstantalar uchun nomlash konventsiyasi so'zlar orasida barcha bosh harflarni pastki chiziq bilan ishlatishdir. Kompilyator kompilyatsiya vaqtida cheklangan operatsiyalar to'plamini baholashga qodir, bu bizga ushbu qiymatni 10,800 qiymatiga o'rnatmasdan, tushunish va tekshirish osonroq bo'lgan tarzda yozishni tanlash imkonini beradi.
Konstantalarni e'lon qilishda qanday operatsiyalardan foydalanish mumkinligi haqida qo'shimcha ma'lumot olish
Rust Referencening konstantalar bo'limiga qarang
Konstantalar dastur ishlayotgan butun vaqt davomida, ular e'lon qilingan doirada amal qiladi. Bu xususiyat dasturning bir nechta qismlari bilishi kerak bo'lgan, masalan, o'yinning har qanday o'yinchisi olishi mumkin bo'lgan maksimal ball soni yoki yorug'lik tezligi kabi, ilova domeningizdagi qiymatlar uchun foydali konstantalarni qiladi.
Dasturingiz davomida ishlatiladigan qattiq kodlangan qiymatlarni konstantalar sifatida nomlash ushbu qiymatning ma'nosini kodning kelajakdagi maintainerlariga yetkazishda foydalidir. Bu, shuningdek, kodingizda faqat bitta joyga ega bo'lishga yordam beradi, agar kelajakda qattiq kodlangan qiymat yangilanishi kerak bo'lsa, o'zgartirishingiz kerak bo'ladi.
Shadowing
2-bobdagi Taxmin qilish oʻyini boʻyicha qoʻllanmada koʻrganingizdek, oldingi oʻzgaruvchi bilan bir xil nomli yangi oʻzgaruvchini eʼlon qilishingiz mumkin.Rustaceanlarning aytishicha, birinchi o'zgaruvchi ikkinchi o'zgaruvchi tomonidan shadow qilingan ya'ni ikkinchi o'zgaruvchi o'zgaruvchi nomidan foydalanganda kompilyator ko'radigan narsadir.
Darhaqiqat, ikkinchi o'zgaruvchi birinchisiga shadow qilib, o'zgaruvchi nomidan har qanday foydalanishni uning o'zi shadowli bo'lmaguncha yoki doirasi tugaguncha oladi.
Biz bir xil oʻzgaruvchining nomidan foydalanib, let kalit soʻzidan foydalanishni quyidagi tarzda takrorlash orqali oʻzgaruvchini shadow qilishimiz mumkin:
Fayl nomi: src/main.rs
fn main() { let x = 5; let x = x + 1; { let x = x * 2; println!("x ning ichki doiradagi qiymati: {x}"); } println!("x qiymati: {x}"); }
Bu dastur avval x ni 5 qiymatiga bog'laydi. Keyin u let x = ni takrorlab, asl qiymatni olib, 1 qo'shish orqali yangi x o'zgaruvchisini yaratadi, shunda x qiymati 6 bo'ladi. Keyin, jingalak qavslar bilan yaratilgan ichki doirada uchinchi let iborasi ham x ga shadow qiladi va yangi o'zgaruvchini yaratadi va oldingi qiymatni 2 ga ko'paytirib, x ga 12 qiymatini beradi.
Bu doira tugagach, ichki shadow tugaydi va x 6 ga qaytadi.
Ushbu dasturni ishga tushirganimizda, u quyidagilarni chiqaradi:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
Finished dev [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/variables`
x ning ichki doiradagi qiymati: 12
x qiymati: 6
Shadowing o‘zgaruvchini mut deb belgilashdan farq qiladi, chunki let kalit so‘zidan foydalanmasdan tasodifan ushbu o‘zgaruvchiga qayta tayinlashga harakat qilsak, kompilyatsiya vaqtida xatolikka yo‘l qo‘yamiz. let dan foydalanib, biz qiymat bo'yicha bir nechta o'zgarishlarni amalga oshirishimiz mumkin, lekin bu o'zgarishlar tugagandan so'ng o'zgaruvchi o'zgarmas bo'lishi mumkin.
Mut va shadow o'rtasidagi boshqa farq shundaki, biz let kalit so'zini qayta ishlatganimizda yangi o'zgaruvchini samarali yaratayotganimiz sababli, qiymat turini o`zgartirishimiz mumkin, lekin bir xil nomni qayta ishlatishimiz ham mumkin. Misol uchun, bizning dasturimiz foydalanuvchidan bo'sh joy belgilarini kiritish orqali ba'zi matnlar orasida qancha bo'sh joy bo'lishini ko'rsatishni so'raydi va biz ushbu kiritishni raqam sifatida saqlamoqchimiz:
fn main() { let joylar = " "; let joylar = joylar.len(); }
Birinchi joylar o'zgaruvchisi satr turi, ikkinchi joylar o'zgaruvchisi esa raqam turi. Shadowing shu tariqa bizni turli nomlar bilan chiqishdan saqlaydi, masalan, joylar_str va joylar_num; Buning o'rniga biz oddiyroq joylar nomini qayta ishlatishimiz mumkin. Biroq, bu erda ko'rsatilganidek, buning uchun mut dan foydalanmoqchi bo'lsak, kompilyatsiya vaqtida xatoga duch kelamiz:
fn main() {
let mut joylar = " ";
joylar = joylar.len();
}Xato bizga o'zgaruvchining turini mutatsiyaga o'tkazishga ruxsat yo'qligini aytadi:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
error[E0308]: mismatched types
--> src/main.rs:3:14
|
2 | let mut joylar = " ";
| ----- expected due to this value
3 | joylar = joylar.len();
| ^^^^^^^^^^^^ expected `&str`, found `usize`
For more information about this error, try `rustc --explain E0308`.
error: could not compile `variables` due to previous error
Endi biz o'zgaruvchilar qanday ishlashini o'rganib chiqdik, keling, ular bo'lishi mumkin bo'lgan ko'proq ma'lumotlar turlarini ko'rib chiqaylik.
Ma'lumotlar turlari
Rust-dagi har bir qiymat ma'lum bir ma'lumot turiga tegishli bo'lib, Rustga qanday ma'lumotlar ko'rsatilayotganligini bildiradi, shuning uchun u ushbu ma'lumotlar bilan qanday ishlashni biladi. Biz ikkita ma'lumotlar turini ko'rib chiqamiz: skalyar va birikma.
Esda tutingki, Rust statik tarzda yozilgan tildir, ya'ni kompilyatsiya vaqtida barcha o'zgaruvchilarning turlarini bilishi kerak. Kompilyator odatda qiymat va uni qanday ishlatishimiz asosida biz qaysi turdan foydalanmoqchi ekanligimiz haqida xulosa chiqarishi mumkin.
Ko‘p turlar mumkin bo‘lgan hollarda, masalan, 2-bobdagi “Tahminni maxfiy raqam bilan solishtirish” bo‘limidagi parse yordamida Stringni raqamli turga o‘zgartirganimizda, quyidagi turdagi izohni qo‘shishimiz kerak:
#![allow(unused)] fn main() { let taxmin: u32 = "42".parse().expect("Raqam emas!"); }
Oldingi kodda ko'rsatilgan : u32 turidagi izohni qo'shmasak, Rust quyidagi xatoni ko'rsatadi, ya'ni kompilyator bizdan qaysi turdan foydalanishni xohlayotganimizni bilish uchun qo'shimcha ma'lumotga muhtoj:
$ cargo build
Compiling no_type_annotations v0.1.0 (file:///projects/no_type_annotations)
error[E0282]: type annotations needed
--> src/main.rs:2:9
|
2 | let taxmin = "42".parse().expect("Raqam emas!");
| ^^^^^
|
help: consider giving `taxmin` an explicit type
|
2 | let taxmin: _ = "42".parse().expect("Raqam emas!");
| +++
For more information about this error, try `rustc --explain E0282`.
error: could not compile `no_type_annotations` due to previous error
Boshqa ma'lumotlar turlari uchun turli turdagi izohlarni ko'rasiz.
Skalyar Turlar
Skalyar turi bitta qiymatni ifodalaydi. Rust to'rtta asosiy skalyar turga ega: integerlar, floating-point number, boolean va belgilar. Siz ularni boshqa dasturlash tillaridan bilishingiz mumkin. Keling, ularning Rustda qanday ishlashini ko'rib chiqaylik.
Integer Turlari
Integer kasr komponenti bo‘lmagan sondir. Biz 2-bobda u32 tipidagi bitta integer sonni ishlatdik. Ushbu turdagi deklaratsiya u bilan bog'langan qiymat 32 bit bo'sh joyni egallagan belgisiz butun son bo'lishi kerakligini bildiradi (Signed integer sonlar u o'rniga i bilan boshlanadi). 3-1-jadvalda Rust-da o'rnatilgan integer son turlari ko'rsatilgan. Integer son qiymatining turini e'lon qilish uchun biz ushbu variantlardan foydalanishimiz mumkin.
3-1-jadval: Rustdagi Integer sonlar turlari
| Uzunlik | Signed | Unsigned |
|---|---|---|
| 8-bit | i8 | u8 |
| 16-bit | i16 | u16 |
| 32-bit | i32 | u32 |
| 64-bit | i64 | u64 |
| 128-bit | i128 | u128 |
| arch | isize | usize |
Signedlar kichkina i harfi bilan boshlanadi, Unsigned esa kichik u harfi bilan boshlanadi.
Har bir variant signed yoki unsigned bo'lishi mumkin va aniq o'lchamga ega. Signed va Unsigned raqam manfiy boʻlishi mumkinmi yoki yoʻqligini anglatadi, boshqacha qilib aytganda, raqam u bilan birga belgiga ega boʻlishi (signed) boʻlishi kerakmi yoki u faqat ijobiy bo'ladimi va shuning uchun belgisiz (unsigned) ifodalanishi mumkinmi. Bu raqamlarni qog'ozga yozishga o'xshaydi: belgi muhim bo'lsa, raqam ortiqcha yoki minus belgisi bilan ko'rsatiladi; ammo, agar raqamni ijobiy deb hisoblash xavfsiz bo'lsa, u hech qanday belgisiz ko'rsatiladi. Signed raqamlar ikkita to'ldiruvchi ko'rinish yordamida saqlanadi.
Har bir signed variant -(2n - 1) dan 2n -
1 -1 gacha bo'lgan raqamlarni saqlashi mumkin, bu erda n variant foydalanadigan bitlar soni.
Shunday qilib, i8 -(27) dan 27 - 1, gacha bo'lgan raqamlarni saqlashi mumkin, bu tengdir -128 dan 127 gacha.
Unsigned variantlar 0 dan 2n - 1 gacha raqamlarni saqlashi mumkin, shuning uchun u8 0 dan 28 - 1 gacha bo'lgan raqamlarni saqlashi mumkin, bu 0 dan 255 gacha.
Bundan tashqari, isize va usize turlari dasturingiz ishlayotgan kompyuterning arxitekturasiga bog'liq bo'lib, u jadvalda “arch” sifatida ko'rsatilgan: agar siz 64 bitli arxitekturada bo'lsangiz 64 bit va 32 bitli arxitekturada bo'lsangiz 32 bit.
Integer sonlarni 3-2-jadvalda ko'rsatilgan istalgan shaklda yozishingiz mumkin. E'tibor bering, bir nechta raqamli turlar bo'lishi mumkin bo'lgan son harflari turni belgilash uchun 57u8 kabi tur qo'shimchasiga ruxsat beradi. Raqamni o'qishni osonlashtirish uchun _ dan raqamli harflar ham foydalanishi mumkin, masalan, 1_000, siz 1000 ni ko'rsatganingizdek bir xil qiymatga ega bo'ladi.
3-2-jadval: Rustdagi Integer literallar
| Raqamli harflar | Misol |
|---|---|
| O'nlik | 98_222 |
| O'n oltilik | 0xff |
| Sakkizlik | 0o77 |
| Ikkilik | 0b1111_0000 |
| Bayt (faqat "u8") | b'A' |
Xo'sh, qaysi turdagi integer sonni ishlatishni qanday bilasiz? Agar ishonchingiz komil bo'lmasa, Rustning standart sozlamalari odatda boshlash uchun yaxshi joylardir: integer son turlari standart bo'yicha i32 dir. isize yoki usize dan foydalanadigan asosiy holat to'plamning bir turini indekslashdir.
Integer Overflow
Aytaylik, sizda 0 dan 255 gacha bo'lgan qiymatlarni ushlab turadigan
u8tipidagi o'zgaruvchi bor. Agar siz o'zgaruvchini ushbu diapazondan tashqaridagi qiymatga o'zgartirishga harakat qilsangiz, masalan, 256, integer overflow sodir bo'ladi, bu ikki xatti-harakatdan biriga olib kelishi mumkin. Debug mode rejimida kompilyatsiya qilayotganingizda, Rust butun sonlarning to'lib ketishini tekshirishni o'z ichiga oladi, bu esa dasturni ishga tushirish vaqtida panic chiqaradi. Rust dastur xato bilan chiqqanda panicking atamasini ishlatadi; Biz panic haqida 9-bobdagi “panicbilan tuzatib bo'lmaydigan xatolar” bo'limda batafsil ko'rib chiqamiz
--releasebuyrug'i bilan reliz rejimida kompilyatsiya qilayotganingizda, Rust panic keltirib chiqaradigan butun sonlarni tekshirishni o'z ichiga olmaydi. overflow occur sodir bo'ladi Rust ikkitasini to'ldiruvchi wrapni bajaradi. Qisqa qilib aytganda, turdagi maksimal qiymatdan kattaroq qiymatlar, tur ushlab turishi mumkin bo'lgan minimal qiymatlargacha "wrap" ni tashkil qiladi.u8holatida 256 qiymati 0 ga, 257 qiymati 1 ga aylanadi va hokazo. Dastur panic qo'ymaydi, lekin o'zgaruvchi siz kutgan qiymatga ega bo'lmaydi. Butun sonlarni wrapga tayanish xato hisoblanadi. Owerflow ehtimolini aniq ko'rib chiqish uchun siz prime sonlar uchun standart kutubxona tomonidan taqdim etilgan ushbu metodlar oilalaridan foydalanishingiz mumkin:
- Barcha modelarni
wrapping_*metodlari bilan oʻrash, masalan,wrapping_add.- Agar
checked_*metodlari owerflow boʻlsa,Noneqiymatini qaytaring.- Qiymat va boolean qiymatni qaytaring, bu
overflowing_*metodlari bilan overflow bo'lganini ko'rsatadi.- Qiymatning minimal yoki maksimal qiymatlarida
saturating_*metodllari bilan saturate bo'lgan.
Floating-Point Turlari
Rust shuningdek floating-point raqamlar uchun ikkita primitive turga ega, ular kasrli raqamlardir.
Rust-ning floating-point turlari f32 va f64 bo'lib, ular mos ravishda 32 bit va 64 bit o'lchamga ega.
Standart tur f64 dir, chunki zamonaviy protsessorlarda u f32 bilan bir xil tezlikda, lekin aniqroq bo'lishga qodir.
Barcha floating-point turlari signeddir.
Bu yerda harakatdagi floating-point raqamlarni ko'rsatadigan misol:
Fayl nomi: src/main.rs
fn main() { let x = 2.0; // f64 let y: f32 = 3.0; // f32 }
Floating-point raqamlari IEEE-754 standartiga muvofiq taqdim etiladi. f32 turi bitta aniqlikdagi floatdir va f64 ikki tomonlama aniqlikka ega.
Raqamli operatsiyalar
Rust barcha turdagi raqamlar uchun kutilgan asosiy matematik operatsiyalarni qo'llab-quvvatlaydi: qo'shish, ayirish, ko'paytirish, bo'lish va qoldiq. Butun sonni bo'lish noldan eng yaqin butun songa qisqaradi. Quyidagi kod let iborasida har bir raqamli operatsiyadan qanday foydalanishni ko'rsatadi:
Fayl nomi: src/main.rs
fn main() { // qo'shish let qoshish = 5 + 10; // ayirish let ayrish = 95.5 - 4.3; // ko'paytirish let kopaytirish = 4 * 30; // bo'lish let bolish = 56.7 / 32.2; let manfiy = -5 / 3; // Natijalar -1 // qoldiq let qoldiq = 43 % 5; }
Ushbu bayonotlardagi har bir ifoda matematik operatordan foydalanadi va bitta qiymatga baholanadi, keyin esa o'zgaruvchiga bog'lanadi. B ilovasi da Rust taqdim etgan barcha operatorlar ro'yxati mavjud.
Boolean turi
Ko'pgina boshqa dasturlash tillarida bo'lgani kabi, Rust-da ham Boolean turi ikkita mumkin bo'lgan qiymatga ega: true va false. Boolean hajmi bir baytga teng.
Rustdagi boolean turi bool yordamida belgilanadi. Misol uchun:
Fayl nomi: src/main.rs
fn main() { let t = true; let f: bool = false; // aniq turdagi izoh bilan }
Boolean qiymatlardan foydalanishning asosiy metodi shartlardir, masalan, if ifodasidir. Rustda if iboralari qanday ishlashini “Control Flow” bo‘limida ko‘rib chiqamiz.
Belgilar(Character) turi
Rustning char turi tilning eng primitive alifbo turidir. Mana char qiymatlarini e'lon qilishning ba`zi misollari:
Fayl nomi: src/main.rs
fn main() { let c = 'z'; let z: char = 'ℤ'; // aniq turdagi izoh bilan let yurak_kozli_mushuk = '😻'; }
E'tibor bering, biz qo'sh tirnoq ishlatadigan satr harflaridan farqli o'laroq, char harflarini bitta tirnoq bilan belgilaymiz. Rustning char turi to'rt bayt o'lchamga ega va Unicode Scalar qiymatini ifodalaydi, ya'ni u ASCIIdan ko'ra ko'proq narsani anglatishi mumkin.
Urg'uli harflar; Xitoy, yapon va koreys belgilar; emoji; va nol kenglikdagi boʻshliqlar Rust-dagi barcha haqiqiy char qiymatlaridir. Unicode Scalar qiymatlari U+0000dan U+D7FFgacha va U+E000dan U+10FFFFgacha.
Biroq, “character” aslida Unicode-da tushuncha emas, shuning uchun “character” nima ekanligi haqidagi Rustdagi char bilan mos kelmasligi mumkin. Biz ushbu mavzuni 8-bobdagi “UTF-8 kodlangan matnni satrlar bilan saqlash” bo'limida batafsil muhokama qilamiz.
Murakkab turlar
Murakkab turlar bir nechta qiymatlarni bir turga to'plashi mumkin.Rust ikkita primitive birikma turiga ega: tuplelar va arraylar.
Tuple turi
tuple - bu turli xil turlarga ega bo'lgan bir qator qiymatlarni bitta qo'shma turga birlashtirishning umumiy metodi.Tuplelar belgilangan uzunlikka ega: bir marta e'lon qilingandan so'ng, ular o'sishi yoki kichrayishi mumkin emas.
Qavslar ichida vergul bilan ajratilgan qiymatlar ro'yxatini yozish orqali tuple yaratamiz. Tupledagi har bir pozitsiya o'z turiga ega va tupledagi turli qiymatlarning turlari bir xil bo'lishi shart emas. Ushbu misolda biz ixtiyoriy turdagi izohlarni qo'shdik:
Fayl nomi: src/main.rs
fn main() { let tup: (i32, f64, u8) = (500, 6.4, 1); }
tup o'zgaruvchisi butun tuplega bog'lanadi, chunki tuple bitta birikma element hisoblanadi. Tupledan individual qiymatlarni olish uchun biz tuple qiymatini buzish uchun pattern moslashuvidan foydalanishimiz mumkin, masalan:
Fayl nomi: src/main.rs
fn main() { let tup = (500, 6.4, 1); let (x, y, z) = tup; println!("y qiymati: {y}"); }
Bu dastur avval tuple yaratadi va uni tup o'zgaruvchisiga bog'laydi.Keyin u tupni olish va uni uchta alohida o‘zgaruvchiga, x, y va z ga aylantirish uchun let bilan pattern ishlatadi. Bu destruktura deb ataladi, chunki u bitta tupleni uch qismga ajratadi. Nihoyat, dastur y qiymatini chop etadi, bu 6,4.
Shuningdek, biz to'g'ridan-to'g'ri nuqta (.) va undan keyin kirishni xohlagan qiymat indeksidan foydalanib, tuple elementiga kirishimiz mumkin. Misol uchun:
Fayl nomi: src/main.rs
fn main() { let x: (i32, f64, u8) = (500, 6.4, 1); let besh_yuz = x.0; let olti_butun_tort= x.1; let bir = x.2; }
Bu dastur x tuplesini yaratadi va so'ngra o'z indekslari yordamida tuplening har bir elementiga kiradi. Ko'pgina dasturlash tillarida bo'lgani kabi, tupledagi birinchi indeks 0 ga teng.
Hech qanday qiymatsiz tuple maxsus nomga, unit ega. Bu qiymat va unga mos keladigan tur () yoziladi va bo'sh qiymat yoki bo'sh qaytish turini ifodalaydi. Ifodalar, agar ular boshqa qiymatni qaytarmasa, bilvosita birlik qiymatini qaytaradi.
Array Turi
Bir nechta qiymatlar to'plamiga ega bo'lishning yana bir usuli arraydir. Tupledan farqli o'laroq, arrayning har bir elementi bir xil turdagi bo'lishi kerak. Ba'zi boshqa tillardagi arraylardan farqli o'laroq, Rustdagi arraylar belgilangan uzunlikka ega.
Biz arraydagi qiymatlarni kvadrat qavslar ichida vergul bilan ajratilgan ro'yxat sifatida yozamiz:
Fayl nomi: src/main.rs
fn main() { let a = [1, 2, 3, 4, 5]; }
Arraylar maʼlumotlaringizni toʻplamga emas, balki stekga ajratishni istasangiz foydali boʻladi (biz 4-bobda) stek va toʻplam haqida koʻproq gaplashamiz yoki sizda har doim maʼlum miqdordagi elementlar mavjudligini taʼminlashni istasangiz). Array vektor turi kabi moslashuvchan emas. Vektor standart kutubxona tomonidan taqdim etilgan o'xshash to'plam turi bo'lib, uning hajmini o'stirish yoki kichraytirishi mumkin. Agar array yoki vektordan foydalanishga ishonchingiz komil bo'lmasa, vektordan foydalanishingiz mumkin. 8-bobda vektorlar batafsilroq muhokama qilinadi.
Biroq, agar elementlar sonini o'zgartirish kerak bo'lmasligini bilsangiz, arraylar foydaliroq bo'ladi. Misol uchun, agar siz dasturda oy nomlaridan foydalansangiz, vektordan ko'ra massivdan foydalanar edingiz, chunki u har doim 12 ta elementdan iborat bo'lishini bilasiz:
#![allow(unused)] fn main() { let oylar = ["Yanvar", "Fevral", "Mart", "Aprel", "May", "Iyun", "Iyul", "Avgust", "Setabr", "Oktabr", "Noyabr", "Dekabr"]; }
Siz har bir element turi, nuqta-vergul va arraydagi elementlar soni bilan kvadrat qavslar yordamida array turini yozasiz, masalan:
#![allow(unused)] fn main() { let a: [i32; 5] = [1, 2, 3, 4, 5]; }
Bu erda i32 har bir elementning turi. Nuqtali verguldan keyin 5 raqami array beshta elementdan iboratligini bildiradi.
Bundan tashqari, har bir element uchun bir xil qiymatni o'z ichiga olgan arrayni boshlang'ich qiymatdan keyin nuqta-vergul qo'yib, so'ngra bu yerda ko'rsatilgandek kvadrat qavs ichida array uzunligini belgilash orqali ishga tushirishingiz mumkin:
#![allow(unused)] fn main() { let a = [3; 5]; }
a nomli array dastlab 3 qiymatiga o'rnatiladigan 5 elementni o'z ichiga oladi. Bu let a = [3, 3, 3, 3, 3]; yozish bilan bir xil, ammo qisqaroq tarzda.
Array elementlariga kirish
Array - bu stekda taqsimlanishi mumkin bo'lgan ma'lum, qat'iy o'lchamdagi xotiraning bitta bo'lagi. Siz indekslash yordamida array elementlariga kirishingiz mumkin, masalan:
Fayl nomi: src/main.rs
fn main() { let a = [1, 2, 3, 4, 5]; let birinchi = a[0]; let ikkinchi = a[1]; }
Bu misolda birinchi deb nomlangan o‘zgaruvchi 1 qiymatini oladi, chunki bu arraydagi [0] indeksidagi qiymatdir. ikkinchi deb nomlangan ozgaruvchi arraydagi [1] indeksidan 2 qiymatini oladi.
Yaroqsiz Array elementlariga kirish
Keling, array oxiridan o‘tgan array elementiga kirishga harakat qilsangiz nima bo‘lishini ko‘rib chiqamiz. Aytaylik, foydalanuvchidan array indeksini olish uchun 2-bobdagi taxminiy o‘yinga o‘xshash ushbu kodni ishlatasiz:
Fayl nomi: src/main.rs
use std::io;
fn main() {
let a = [1, 2, 3, 4, 5];
println!("Iltimos, array indeksini kiriting.");
let mut index = String::new();
io::stdin()
.read_line(&mut index)
.expect("Satrni o‘qib bo‘lmadi");
let index: usize = index
.trim()
.parse()
.expect("Kiritilgan indeks raqam emas");
let element = a[index];
println!("{index} indeksidagi elementning qiymati: {element}");
}Ushbu kod muvaffaqiyatli kompilyatsiya qilinadi.Agar siz ushbu kodni cargo run yordamida ishga tushirsangiz va 0, 1, 2, 3 yoki 4 kiritsangiz, dastur arraydagi ushbu indeksdagi mos qiymatni chop etadi. Buning o'rniga array oxiridan o'tgan raqamni kiritsangiz, masalan, 10, siz shunday chiqishni ko'rasiz:
thread 'main' panicked at 'index out of bounds: the len is 5 but the index is 10', src/main.rs:19:19
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Dastur indekslash operatsiyasida yaroqsiz qiymatdan foydalanish nuqtasida runtime xatosiga olib keldi. Dastur xato xabari bilan chiqdi va yakuniy println! bayonotini bajarmadi. Indekslash yordamida elementga kirishga harakat qilganingizda, Rust siz ko'rsatgan indeks array uzunligidan kamroq ekanligini tekshiradi. Agar indeks uzunlikdan kattaroq yoki unga teng bo'lsa, Rust panic chiqaradi. Bu tekshirish runtimeda amalga oshirilishi kerak, ayniqsa bu holatda, chunki kompilyator foydalanuvchi kodni keyinroq ishga tushirganda qanday qiymat kiritishini bila olmaydi.
Bu Rustning xotira xavfsizligi tamoyillarining amaldagi namunasidir. Ko'pgina low-leveldagi tillarda bunday tekshirish amalga oshirilmaydi va noto'g'ri indeksni taqdim etganingizda, yaroqsiz xotiraga kirish mumkin. Rust xotiraga kirishga ruxsat berish va davom ettirish o'rniga darhol chiqish orqali sizni bunday xatolardan himoya qiladi. 9-bobda Rust-ning xatolarini qanday hal qilish va siz panic qo'ymaydigan va yaroqsiz xotiraga kirishga ruxsat bermaydigan o'qilishi mumkin bo'lgan xavfsiz kodni qanday yozishingiz mumkinligi muhokama qilinadi.
Funksiyalar
Funksiyalar Rust kodida keng tarqalgan. Siz allaqachon tildagi eng muhim funksiyalardan birini ko'rgansiz: ko'plab dasturlarning kirish nuqtasi bo'lgan main funksiya. Siz yangi funksiyalarni e'lon qilish imkonini beruvchi fn kalit so'zini ham ko'rdingiz.
Rust kodi funksiya va oʻzgaruvchilar nomlari uchun anʼanaviy uslub sifatida snake case dan foydalanadi, unda barcha harflar kichik va alohida soʻzlarning tagiga chiziladi. Mana, misol funksiya ta'rifini o'z ichiga olgan dastur:
Fayl nomi: src/main.rs
fn main() { println!("Hello, world!"); boshqa_funksiya(); } fn boshqa_funksiya() { println!("Boshqa funksiya."); }
Rust-da funksiyani fn so'ng funksiya nomi va qavslar to'plamini kiritish orqali aniqlaymiz. Jingalak qavslar kompilyatorga funksiya tanasi qayerda boshlanishi va tugashini bildiradi.
Biz belgilagan har qanday funksiyani uning nomidan keyin qavslar to'plamini kiritish orqali chaqirishimiz mumkin. Dasturda boshqa_funksiya ni aniqlanganligi sababli uni main funksiya ichidan chaqirish mumkin. E'tibor bering, biz boshqa_funksiya ni manba kodidagi main funksiyadan keyin belgilaganmiz; uni avval ham belgilashimiz mumkin edi. Rust sizning funksiyalaringizni qayerda belgilashingizning ahamiyati yo'q, faqat ular so'rov yuboruvchi tomonidan ko'rinadigan doirada aniqlangan.
Keling, funksiyalarni ko'proq o'rganish uchun funksiyalar nomli yangi binary loyihani boshlaylik. boshqa_funksiya misolini src/main.rs ga joylashtiring va uni ishga tushiring.Quyidagi chiqishni ko'rishingiz kerak:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished dev [unoptimized + debuginfo] target(s) in 0.28s
Running `target/debug/functions`
Hello, world!
Boshqa funksiya.
Qatorlar main funksiyada paydo bo'ladigan tartibda bajariladi.
Avvaliga "Hello, world!" xabar chop etiladi, keyin boshqa_funksiya chaqiriladi va uning xabari chop etiladi.
Parametrlar
Biz funksiyalarni parametrlari bo'lishi uchun belgilashimiz mumkin, ular funksiya imzosining bir qismi bo'lgan maxsus o'zgaruvchilardir. Agar funksiya parametrlarga ega bo'lsa, siz unga ushbu parametrlar uchun aniq qiymatlarni berishingiz mumkin. Texnik jihatdan aniq qiymatlar argumentlar deb ataladi, ammo tasodifiy suhbatda odamlar funksiya taʼrifidagi oʻzgaruvchilar yoki funksiyani chaqirganingizda qabul qilingan aniq qiymatlar uchun parametr va argument soʻzlarini bir-birining oʻrniga ishlatishga moyildirlar.
boshqa_funksiya ning ushbu versiyasida biz parametr qo'shamiz:
Fayl nomi: src/main.rs
fn main() { boshqa_funksiya(5); } fn boshqa_funksiya(x: i32) { println!("x qiymati: {x}"); }
Ushbu dasturni ishga tushirishga harakat qiling; quyidagi chiqishni olishingiz kerak:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished dev [unoptimized + debuginfo] target(s) in 1.21s
Running `target/debug/functions`
x qiymati: 5
boshqa_funksiya deklaratsiyasi x nomli bitta parametrga ega. x turi i32 sifatida belgilangan. Biz 5ni boshqa_funksiyaga o‘tkazganimizda, println! makros 5 ni xni o‘z ichiga olgan jingalak qavslar juftligi format satrida joylashgan joyga qo‘yadi.
Funksiya signaturelarda siz har bir parametr turini e'lon qilishingiz kerak. Bu Rust dizaynidagi ataylab qabul qilingan qaror: funksiya taʼriflarida turdagi izohlarni talab qilish kompilyatorga qaysi turni nazarda tutayotganingizni tushunish uchun ularni kodning boshqa joylarida ishlatishingizga deyarli hech qachon ehtiyoj sezmasligini anglatadi. Kompilyator, shuningdek, funksiya qanday turlarni kutayotganini bilsa, yanada foydali xato xabarlarini berishi mumkin.
Bir nechta parametrlarni belgilashda parametr deklaratsiyasini vergul bilan ajrating, masalan:
Fayl nomi: src/main.rs
fn main() { belgilangan_vaqt(5, 'h'); } fn belgilangan_vaqt(value: i32, unit_label: char) { println!("Belgilangan Vaqt: {value}{unit_label}"); }
Ushbu misol ikkita parametrli belgilangan_vaqt nomli funksiyani yaratadi. Birinchi parametr value deb nomlangan va i32 dir. Ikkinchisi unit_label deb nomlanadi va char turidir. Keyin funksiya value va ``unit_label` ni o‘z ichiga olgan matnni chop etadi.
Keling, ushbu kodni ishga tushirishga harakat qilaylik. Hozirda funksiyalar loyihangizning src/main.rs faylidagi dasturni oldingi misol bilan almashtiring va uni cargo run yordamida ishga tushiring:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished dev [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/functions`
Belgilangan Vaqt: 5h
Biz funksiyani value qiymati sifatida 5 va unit_label qiymati sifatida 'h' deb ataganimiz sababli, dastur chiqishi ushbu qiymatlarni o`z ichiga oladi.
Statementlar va Expressionlar
Funksiya qismlari ixtiyoriy ravishda statement bilan tugaydigan bir qator expressionlardan iborat. Hozircha biz ko'rib chiqqan funksiyalar yakuniy expressionni o'z ichiga olmagan, lekin siz expressionni statementning bir qismi sifatida ko'rdingiz. Rust expressionga asoslangan til bo'lganligi sababli, bu tushunish uchun muhim farqdir. Boshqa tillar bir xil farqlarga ega emas, shuning uchun keling, qanday statementlar va expressionlar ekanligini va ularning farqlari funksiyalar tanasiga qanday ta'sir qilishini ko'rib chiqaylik.
- Statementlar ba'zi amallarni bajaradigan va qiymat qaytarmaydigan ko'rsatmalardir.
- Expressionlar qiymatga baholanadi. Keling, ba'zi misollarni ko'rib chiqaylik.
Biz allaqachon statementlar va expressionlarni ishlatganmiz. O'zgaruvchini yaratish va unga let kalit so'zi bilan qiymat berish - bu statement. 3-1 ro'yxatda let y = 6; - bu statement.
Fayl nomi: src/main.rs
fn main() { let y = 6; }
Ro'yxat 3-1: Bitta statementni o'z ichiga olgan main funksiya deklaratsiyasi
Funksiya definitionlari ham statementlardir; oldingi misol o'z-o'zidan bir statementdir.
Statementlar qiymatlarni qaytarmaydi. Shuning uchun siz boshqa o'zgaruvchiga let iborasini tayinlay olmaysiz, chunki quyidagi kod bunga harakat qiladi; siz xatoga duch kelasiz:
Fayl nomi: src/main.rs
fn main() {
let x = (let y = 6);
}Ushbu dasturni ishga tushirganingizda, sizda paydo bo'ladigan xato quyidagicha ko'rinadi:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
error: expected expression, found `let` statement
--> src/main.rs:2:14
|
2 | let x = (let y = 6);
| ^^^
error: expected expression, found statement (`let`)
--> src/main.rs:2:14
|
2 | let x = (let y = 6);
| ^^^^^^^^^
|
= note: variable declaration using `let` is a statement
error[E0658]: `let` expressions in this position are unstable
--> src/main.rs:2:14
|
2 | let x = (let y = 6);
| ^^^^^^^^^
|
= note: see issue #53667 <https://github.com/rust-lang/rust/issues/53667> for more information
warning: unnecessary parentheses around assigned value
--> src/main.rs:2:13
|
2 | let x = (let y = 6);
| ^ ^
|
= note: `#[warn(unused_parens)]` on by default
help: remove these parentheses
|
2 - let x = (let y = 6);
2 + let x = let y = 6;
|
For more information about this error, try `rustc --explain E0658`.
warning: `functions` (bin "functions") generated 1 warning
error: could not compile `functions` due to 3 previous errors; 1 warning emitted
let y = 6 statementi qiymat qaytarmaydi, shuning uchun x bog'lanishi uchun hech narsa yo'q. Bu boshqa tillarda sodir bo'ladigan narsadan farq qiladi, masalan, C va Ruby, bu yerda assignment assignmentning qiymatini qaytaradi. Bu tillarda siz x = y = 6 yozishingiz mumkin va x va y ham 6 qiymatiga ega; Rustda bunday emas.
Expressionlar qiymatga baholanadi va siz Rust-da yozadigan kodning qolgan qismini tashkil qiladi. 5 + 6 kabi matematik amalni ko'rib chiqing, bu 11 qiymatini beruvchi expressiondir. Expressionlar statementlarning bir qismi bo'lishi mumkin: 3-1 ro'yxatdagi let y = 6; ifodasidagi 6, 6 qiymatini beruvchi expressiondir. Funksiyani chaqirish expressiondir. Makroni chaqirish expressiondir. Jingalak qavslar bilan yaratilgan yangi qamrov bloki expressiondir, masalan:
Fayl nomi: src/main.rs
fn main() { let y = { let x = 3; x + 1 }; println!("y qiymati: {y}"); }
Bu expression:
{
let x = 3;
x + 1
}blok bo'lib, bu holda 4 ga evaluate bo'ladi. Bu qiymat let statementining bir qismi sifatida y ga bog'lanadi. E'tibor bering, "x + 1 qatorining oxirida nuqta-vergul yo'q, bu siz ko'rgan ko'pgina qatorlardan farqli o'laroq. Expressionlar yakuniy nuqtali vergullarni o'z ichiga olmaydi. Ifodaning oxiriga nuqtali vergul qo'shsangiz, uni statementga aylantirasiz va u keyinchalik qiymatni qaytarmaydi. Keyingi funksiyani qaytarish qiymatlari va expressionlarini o'rganayotganda buni yodda tuting.
Return qiymatlari bilan funksiyalar
Funksiyalar qiymatlarni ularni chaqiradigan kodga return qaytarishi mumkin. Return qiymatlarini nomlamaymiz, lekin ularning turini o'qdan keyin e'lon qilishimiz kerak (->). Rustda funksiyaning return qiymati funksiya tanasi blokidagi yakuniy ifodaning qiymati bilan sinonimdir. Siz return kalit so'zidan foydalanib va qiymatni belgilash orqali funksiyadan erta qaytishingiz mumkin, lekin ko'pchilik funksiyalar oxirgi expressionni bevosita qaytaradi. Mana qiymatni return qiladigan funksiyaga misol:
Fayl nomi: src/main.rs
fn besh() -> i32 { 5 } fn main() { let x = besh(); println!("x qiymati: {x}"); }
besh funksiyasida funksiya chaqiruvlari, makroslar va hatto let iboralari ham yo‘q – faqat 5 raqamining o‘zi. Bu Rust-da juda to'g'ri funksiya. Funksiyaning return turi ham -> i32 sifatida ko'rsatilganligini unutmang.Ushbu kodni ishga tushirishga harakat qiling; chiqish quyidagicha ko'rinishi kerak:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished dev [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/functions`
x qiymati: 5
besh dagi 5 funksiyaning return qiymatidir, shuning uchun return turi i32dir. Keling, buni batafsilroq ko'rib chiqaylik. Ikkita muhim bit mavjud: birinchidan, let x = besh(); qatori biz o'zgaruvchini ishga tushirish uchun funksiyaning return qiymatidan foydalanayotganimizni ko'rsatadi. Chunki besh funksiyasi 5ni qaytaradi, bu qator quyidagi bilan bir xil:
#![allow(unused)] fn main() { let x = 5; }
Ikkinchidan, besh funksiyasi hech qanday parametrga ega emas va return qiladigan qiymat turini belgilaydi, lekin funksiyaning tanasi nuqta-vergulsiz yolg‘iz 5 bo‘ladi, chunki bu biz qiymatini qaytarmoqchi bo‘lgan ifodadir.
Keling, yana bir misolni ko'rib chiqaylik:
Fayl nomi: src/main.rs
fn main() { let x = qoshilgan_bir(5); println!("x qiymati: {x}"); } fn qoshilgan_bir(x: i32) -> i32 { x + 1 }
Ushbu kodni ishga tushirish x qiymati: 6 ni chop etadi. Ammo, agar biz x + 1 bo'lgan satr oxiriga nuqta-vergul qo'ysak, uni expressiondan statementga o'zgartirsak, xatoga yo'l qo'yamiz:
Fayl nomi: src/main.rs
fn main() {
let x = qoshilgan_bir(5);
println!("x qiymati: {x}");
}
fn qoshilgan_bir(x: i32) -> i32 {
x + 1;
}Ushbu kodni kompilyatsiya qilish quyidagi kabi xatoga olib keladi:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
error[E0308]: mismatched types
--> src/main.rs:7:24
|
7 | fn qoshilgan_bir(x: i32) -> i32 {
| -------- ^^^ expected `i32`, found `()`
| |
| implicitly returns `()` as its body has no tail or `return` expression
8 | x + 1;
| - help: remove this semicolon to return this value
For more information about this error, try `rustc --explain E0308`.
error: could not compile `functions` due to previous error
Asosiy xato xabari, mismatched types(mos kelmaydigan turlar) ushbu kod bilan bog'liq asosiy muammoni ochib beradi. qoshilgan_bir funksiyasining taʼrifida aytilishicha, u i32 ni qaytaradi, lekin statementlar birlik turi boʻlgan () bilan expression bo'lgan qiymatga evaluate bo'lmaydi. Shuning uchun, hech narsa return qilinmaydi, bu funksiya definitioniga zid keladi va xatolikka olib keladi. Ushbu chiqishda Rust bu muammoni tuzatishga yordam beradigan xabarni taqdim etadi: u nuqta-vergulni olib tashlashni taklif qiladi, bu xatoni tuzatadi.
Izohlar
Barcha dasturchilar o'z kodlarini tushunishni osonlashtirishga harakat qilishadi, lekin ba'zida qo'shimcha tushuntirish kerak. Bunday hollarda dasturchilar o'zlarining manba kodlarida izohlar qoldiradilar, ularni kompilyator e'tiborsiz qoldiradi, ammo manba kodini o'qiyotgan odamlar uchun foydali bo'lishi mumkin.
Mana oddiy izoh:
#![allow(unused)] fn main() { // hello, world }
Rustda idiomatik izoh uslubi izohni ikki qiyshiq chiziq bilan boshlaydi va izoh satr oxirigacha davom etadi. Bitta satrdan tashqariga chiqadigan izohlar uchun har bir satrga // qo'shishingiz kerak bo'ladi, masalan:
#![allow(unused)] fn main() { // Shunday qilib, biz bu erda murakkab ish qilyapmiz, // bizga bir nechta izohlar kerak bo'ladi! Vou! Umid qilamanki, // bu izoh nima bo'layotganini tushuntiradi. }
Izohlar, shuningdek, kodni o'z ichiga olgan qatorlar oxirida joylashtirilishi mumkin:
Fayl nomi: src/main.rs
fn main() { let omadli_raqam = 7; // Bugun o'zimni omadli his qilyapman }
Ammo siz ularni ushbu formatda ko'proq ko'rasiz, izohli kod ustidagi alohida satrda izoh bilan:
Fayl nomi: src/main.rs
fn main() { // Bugun o'zimni omadli his qilyapman let omadli_raqam = 7; }
Rustda yana bir turdagi izohlar, hujjatlar izohlari mavjud, biz ularni 14-bobning “Crates.io-ga crateni nashr qilish“ bo'limida muhokama qilamiz.
Control Flow
Shartning true yoki yo'qligiga qarab ba'zi kodlarni ishga tushirish va shart true bo'lganda ba'zi kodlarni qayta-qayta ishga tushirish qobiliyati ko'pchilik dasturlash tillarida asosiy building bloklari hisoblanadi. Rust kodining bajarilishini nazorat qilish imkonini beruvchi eng keng tarqalgan konstruksiyalar if expressionlari va looplaridir.
if ifodalari
if ifodasi shartlarga qarab kodingizni branchga ajratish imkonini beradi. Siz shartni taqdim etasiz va keyin shunday deb aytasiz: “Agar bu shart bajarilsa, ushbu kod blokini ishga tushiring. Agar shart bajarilmasa, ushbu kod blokini ishga tushirmang."
If ifodasini oʻrganish uchun loyihalar jildingizda branchlar nomli yangi loyiha yarating. src/main.rs faylida quyidagilarni kiriting:
Fayl nomi: src/main.rs
fn main() { let raqam = 3; if raqam < 5 { println!("shart true edi"); } else { println!("shart true edi"); } }
Barcha if expressionlari if kalit so‘zidan boshlanadi, undan keyin shart keladi. Bunday holda, shart raqam o'zgaruvchisi 5 dan kichik qiymatga ega yoki yo'qligini tekshiradi. Agar shart true bo'lsa, biz kod blokini shartdan keyin darhol jingalak qavslar ichiga joylashtiramiz.
if expressionlaridagi shartlar bilan bog‘langan kod bloklari ba’zan arms deb ataladi, xuddi biz 2-bobning “Tahminni maxfiy raqam bilan solishtirish” bo‘limida muhokama qilgan match expressionlaridagi qurollar kabi.
Ixtiyoriy ravishda, agar shart false deb baholansa, dasturga bajarilishi uchun muqobil kod blokini berish uchun biz tanlagan else expressionini ham kiritishimiz mumkin. Agar else ifodasini bermasangiz va shart false bo‘lsa, dastur shunchaki if blokini o‘tkazib yuboradi va kodning keyingi bitiga o‘tadi.
Ushbu kodni ishga tushirishga harakat qiling; quyidagi chiqishni ko'rishingiz kerak:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branchlar)
Finished dev [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/branchlar`
shart true edi
Keling, nima sodir bo'lishini ko'rish uchun raqam qiymatini shartni false qiladigan qiymatga o'zgartirib ko'raylik:
fn main() {
let raqam = 7;
if raqam < 5 {
println!("shart true edi");
} else {
println!("shart false edi");
}
}Dasturni qayta ishga tushiring va natijaga qarang:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished dev [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/branches`
shart false edi
Shuni ham ta'kidlash kerakki, ushbu koddagi shart bool bo'lishi kerak. Agar shart bool bo'lmasa, biz xatoga yo'l qo'yamiz. Masalan, quyidagi kodni ishga tushirishga harakat qiling:
Fayl nomi: src/main.rs
fn main() {
let raqam = 3;
if raqam {
println!("raqam uchta edi");
}
}if sharti bu safar 3 qiymatiga teng bo'ladi va Rust xato qiladi:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
error[E0308]: mismatched types
--> src/main.rs:4:8
|
4 | if raqam {
| ^^^^^^ expected `bool`, found integer
For more information about this error, try `rustc --explain E0308`.
error: could not compile `branches` due to previous error
Xato shuni ko'rsatadiki, Rust bool kutgan, lekin integer(butun) son olgan. Ruby va JavaScript kabi tillardan farqli o'laroq, Rust boolean bo'lmagan turlarni boolean tilga o'zgartirishga avtomatik ravishda urinmaydi. Siz aniq bo'lishingiz va har doim if ni mantiqiy shart sifatida ko'rsatishingiz kerak. Agar biz if kod bloki faqat raqam 0 ga teng bo‘lmaganda ishlashini istasak, masalan, if ifodasini quyidagiga o‘zgartirishimiz mumkin:
Fayl nomi: src/main.rs
fn main() { let raqam = 3; if raqam != 0 { println!("raqam noldan boshqa narsa edi"); } }
Ushbu kodni ishga tushirish raqam noldan boshqa narsa edi chop etiladi.
else if bilan bir nechta shartlarni boshqarish
if va else ni else if ifodasida birlashtirib, bir nechta shartlardan foydalanishingiz mumkin.Misol uchun:
Fayl nomi: src/main.rs
fn main() { let raqam = 6; if raqam % 4 == 0 { println!("raqam 4 ga bo'linadi"); } else if raqam % 3 == 0 { println!("raqam 3 ga bo'linadi"); } else if raqam % 2 == 0 { println!("raqam 2 ga bo'linadi"); } else { println!("raqam 4, 3 yoki 2 ga bo'linmaydi"); } }
Ushbu dasturda to'rtta yo'l bor. Uni ishga tushirgandan so'ng siz quyidagi chiqishni ko'rishingiz kerak:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished dev [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/branches`
raqam 3 ga bo'linadi
Ushbu dastur bajarilganda, u har bir if expressionni navbatma-navbat tekshiradi va shart true deb baholanadigan birinchi tanani bajaradi. E'tibor bering 6, 2 ga bo'linsa ham, biz son 2 ga bo'linmaydi chiqishini ko'rmayapmiz va else blokidagi raqam 4, 3 yoki 2 ga bo'linmaydi matnini ko'rmaymiz.Buning sababi, Rust faqat birinchi true shart uchun blokni bajaradi va bir marta topilsa, qolganlarini ham tekshirmaydi.
Juda ko'p else if expressionlaridan foydalanish kodingizni buzishi mumkin, shuning uchun sizda bir nechta bo'lsa, kodingizni qayta tahrirlashni xohlashingiz mumkin. 6-bobda bu holatlar uchun match deb nomlangan kuchli Rust tarmoqli konstruksiyasi tasvirlangan.
let statementida if dan foydalanish
if expression bo‘lganligi sababli, biz 3-2-listdagi kabi natijani o‘zgaruvchiga belgilash uchun let statementining o‘ng tomonida foydalanishimiz mumkin.
Fayl nomi: src/main.rs
fn main() { let shart = true; let raqam = if shart { 5 } else { 6 }; println!("Raqamning qiymati: {raqam}"); }
Ro'yxat 3-2: if expressioni natijasini o‘zgaruvchiga tayinlash
raqam o'zgaruvchisi if expressioni natijasiga asoslangan qiymatga bog'lanadi. Nima sodir bo'lishini ko'rish uchun ushbu kodni ishga tushiring:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished dev [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/branches`
Raqamning qiymati: 5
Esda tutingki, kod bloklari ulardagi oxirgi expressiongacha evaluate qilianadi va raqamlar o'zlari ham expressionlardir. Bu holda butun if expressionning qiymati qaysi kod bloki bajarilishiga bog'liq. Bu if ning har bir armidan result bo'lish potentsialiga ega bo'lgan qiymatlar bir xil turdagi bo'lishi kerakligini anglatadi; 3-2 ro'yxatda if va else armllarining natijalari i32 butun sonlari edi. Agar turlar mos kelmasa(mismatched), quyidagi misolda bo'lgani kabi, biz xatoga duch kelamiz:
Fayl nomi: src/main.rs
fn main() {
let shart = true;
let raqam = if shart { 5 } else { "olti" };
println!("Raqamning qiymati: {raqam}");
}Ushbu kodni kompilyatsiya qilmoqchi bo'lganimizda, biz xatoga duch kelamiz. if va else armllari mos kelmaydigan qiymat turlariga ega va Rust muammoni dasturda qayerdan topish mumkinligini aniq ko'rsatadi:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
error[E0308]: `if` and `else` have incompatible types
--> src/main.rs:4:44
|
4 | let raqam = if shart { 5 } else { "olti" };
| - ^^^^^ expected integer, found `&str`
| |
| expected because of this
For more information about this error, try `rustc --explain E0308`.
error: could not compile `branches` due to previous error
if blokidagi expression butun songa, else blokidagi expression esa satrga baholanadi. Bu ishlamaydi, chunki oʻzgaruvchilar bitta turga ega boʻlishi kerak va Rust kompilyatsiya vaqtida raqam oʻzgaruvchisi qaysi turini aniq bilishi kerak. raqam turini bilish kompilyatorga ushbu tur biz raqam ishlatadigan hamma joyda yaroqliligini tekshirish imkonini beradi. Agar raqam turi faqat runtimeda aniqlangan bo'lsa, Rust buni qila olmaydi; kompilyator murakkabroq bo'lar edi va agar u har qanday o'zgaruvchi uchun bir nechta gipotetik turlarni kuzatib borishi kerak bo'lsa, kod haqida kamroq kafolatlar beradi.
Looplar bilan takrorlash
Ko'pincha kod blokini bir necha marta bajarish foydali bo'ladi. Ushbu vazifani bajarish uchun Rust bir nechta looplarni taqdim etadi, ular sikl tanasi ichidagi kod orqali oxirigacha ishlaydi va keyin darhol boshida boshlanadi. Looplar bilan tajriba o'tkazish uchun keling, looplar deb nomlangan yangi loyiha yarataylik.
Rustda uch xil looplar mavjud: loop, while va for. Keling, har birini sinab ko'raylik.
Kodni loop bilan takrorlash
loop kalit so'zi Rustga kod blokini abadiy qayta-qayta bajarishni yoki uni to'xtatishni aniq aytmaguningizcha bajarishni aytadi.
Misol tariqasida, looplar jildingizdagi src/main.rs faylini quyidagicha o'zgartiring:
Fayl nomi: src/main.rs
fn main() {
loop {
println!("yana!");
}
}Ushbu dasturni ishga tushirganimizda, dasturni qo'lda to'xtatmagunimizcha, yana! so'zi doimiy ravishda chop etilishini ko'ramiz.Aksariyat terminallar uzluksiz siklda ishlab qolgan dasturni to'xtatish uchun ctrl-c klaviatura yorliqlarini qo'llab-quvvatlaydi.
Sinab ko'ring:
$ cargo run
Compiling loops v0.1.0 (file:///projects/looplar)
Finished dev [unoptimized + debuginfo] target(s) in 0.29s
Running `target/debug/looplar`
yana!
yana!
yana!
yana!
^Cyana!
^C belgisi ctrl-c tugmalarini bosgan joyni bildiradi. Kod uzilish signalini qabul qilganda siklning qayerda bo'lganiga qarab, ^C dan keyin chop etilgan yana! so'zini ko'rishingiz yoki ko'rmasligingiz mumkin.
Yaxshiyamki, Rust kod yordamida loopdan chiqish yo'lini ham taqdim etadi. Siz dasturga siklni bajarishni qachon to'xtatish kerakligini aytish uchun break kalit so'zini siklga qo'yishingiz mumkin.
Eslatib o'tamiz, biz buni 2-bobning ”To'g'ri taxmindan keyin chiqish” bo'limidagi taxminiy o'yinda, foydalanuvchi to'g'ri raqamni taxmin qilish orqali o'yinda g'alaba qozonganida dasturdan chiqish uchun qilganmiz.
Shuningdek, biz taxmin qilish o'yinida continue dan foydalandik, bu siklda dasturga siklning ushbu iteratsiyasida qolgan har qanday kodni o'tkazib yuborish va keyingi iteratsiyaga o'tishni aytadi.
Looplardan qiymatlarni qaytarish(return)
loop dan foydalanishdan biri bu ish bajarilmasligi mumkin bo'lgan operatsiyani qaytadan urinish, masalan, thread o'z ishini tugatganligini tekshirish. Bundan tashqari, ushbu operatsiya natijasini kodingizning qolgan qismiga sikldan o'tkazishingiz kerak bo'lishi mumkin. Buning uchun siklni toʻxtatish uchun foydalanadigan break ifodasidan keyin return qilinishi kerak boʻlgan qiymatni qoʻshishingiz mumkin; bu qiymat loopdan qaytariladi, shuning uchun uni bu yerda ko'rsatilganidek ishlatishingiz mumkin:
fn main() { let mut hisoblagich = 0; let natija = loop { hisoblagich += 1; if hisoblagich == 10 { break hisoblagich * 2; } }; println!("Natija: {natija}"); }
Loopdan oldin biz hisoblagich nomli o‘zgaruvchini e’lon qilamiz va uni 0 ga ishga tushiramiz. Keyin sikldan qaytarilgan qiymatni ushlab turish uchun natija nomli o'zgaruvchini e'lon qilamiz. Loopning har bir iteratsiyasida biz hisoblagich o‘zgaruvchisiga 1 qo‘shamiz va keyin hisoblagich 10 ga teng yoki yo‘qligini tekshiramiz. Bu bo'lganda, biz hisoblagich * 2 qiymati bilan break kalit so'zidan foydalanamiz. Loopdan so'ng biz natija qiymatini belgilaydigan statementni tugatish uchun nuqta-verguldan foydalanamiz. Nihoyat, biz qiymatni natijada chop qilamiz, bu holda 20.
Bir nechta looplar orasidagi farqni ajratish uchun loop labellari
Agar sizda looplar ichida looplaringiz bo'lsa, o'sha nuqtada eng ichki loopga break va continue amallari qo'llaniladi. Siz ixtiyoriy ravishda siklda loop label belgilashingiz mumkin, undan so‘ng break yoki continue bilan o‘sha kalit so‘zlar eng ichki loop o‘rniga belgilangan loopga qo‘llanilishini belgilashingiz mumkin. Loop labellari bitta tirnoqcha bilan boshlanishi kerak. Mana ikkita ichki loop bilan bir misol:
fn main() { let mut hisob = 0; 'hisoblash: loop { println!("hisob = {hisob}"); let mut qolgan = 10; loop { println!("qolgan = {qolgan}"); if qolgan == 9 { break; } if hisob == 2 { break 'hisoblash; } qolgan -= 1; } hisob += 1; } println!("Yakuniy hisob = {hisob}"); }
Tashqi loopda 'hisoblash labeli bor va u 0 dan 2 gacha hisoblanadi.
Labelsiz ichki loop 10 dan 9 gacha hisoblanadi. Label ko'rsatilmagan birinchi break faqat ichki sikldan chiqadi. break 'hisoblash; statementi tashqi sikldan chiqadi. Keling kodni run qilib ko'ramiz:
$ cargo run
Compiling loops v0.1.0 (file:///projects/loops)
Finished dev [unoptimized + debuginfo] target(s) in 0.58s
Running `target/debug/loops`
hisob = 0
qolgan = 10
qolgan = 9
hisob = 1
qolgan = 10
qolgan = 9
hisob = 2
qolgan = 10
Yakuniy hisob = 2
while bilan shartli looplar
Dastur ko'pincha loop ichidagi shartni evaluate qilishi kerak bo'ladi. Shart true bo'lsa-da, loop ishlaydi. Shart true bo'lishni to'xtatganda, dastur loopni to'xtatib, break ni chaqiradi. Bu kabi xatti-harakatlarni loop, if, else va break kombinatsiyasidan foydalanib amalga oshirish mumkin; Agar xohlasangiz, buni hozir dasturda sinab ko'rishingiz mumkin. Biroq, bu pattern shunchalik keng tarqalganki, Rustda buning uchun while sikli deb ataladigan o'rnatilgan til konstruktsiyasi mavjud. 3-3 ro'yxatda biz dasturni uch marta aylanish uchun while dan foydalanamiz, har safar sanab chiqamiz, so'ngra sikldan so'ng xabarni chop etamiz va chiqamiz.
Fayl nomi: src/main.rs
fn main() { let mut raqam = 3; while raqam != 0 { println!("{raqam}!"); raqam -= 1; } println!("LIFTOFF!!!"); }
Ro'yxat 3-3: Shart to'g'ri bo'lganda kodni ishga tushirish uchun while siklidan foydalanish
Bu konstruksiya loop, if, else va break dan foydalansangiz, zarur bo'ladigan ko'plab joylashtirishlarni yo'q qiladi va bu aniqroq bo'ladi. Shart true deb baholansa, kod ishlaydi; aks holda, u loopdan chiqadi.
for bilan to'plam bo'ylab aylanish
Siz while konstruksiyasidan array kabi to‘plam elementlari ustidan aylanishni tanlashingiz mumkin. Masalan, 3-4 ro'yxatdagi sikl a arrayidagi har bir elementni chop etadi.
Fayl nomi: src/main.rs
fn main() { let a = [10, 20, 30, 40, 50]; let mut index = 0; while index < 5 { println!("qiymati: {}", a[index]); index += 1; } }
Ro'yxat 3-4: while sikli yordamida to‘plamning har bir elementi bo‘ylab aylanish
Bu erda kod arraydagi elementlar orqali hisoblanadi. U 0 indeksidan boshlanadi va keyin arraydagi yakuniy indeksga yetguncha (ya'ni, index < 5 endi true bo`lmaganda) sikl davom etadi. Ushbu kodni ishga tushirish arraydagi har bir elementni chop etadi:
$ cargo run
Compiling looplar v0.1.0 (file:///projects/looplar)
Finished dev [unoptimized + debuginfo] target(s) in 0.32s
Running `target/debug/looplar`
qiymati: 10
qiymati: 20
qiymati: 30
qiymati: 40
qiymati: 50
Barcha besh array qiymatlari kutilganidek terminalda paydo bo'ladi. Garchi index bir nuqtada 5 qiymatiga yetsa ham, arraydan oltinchi qiymatni olishga urinishdan oldin sikl ishlashni to‘xtatadi.
Biroq, bu yondashuv xatoga moyil; Agar indeks qiymati yoki test holati noto'g'ri bo'lsa, biz dasturni panic qo'yishimiz mumkin. Misol uchun, agar siz a arrayining ta'rifini to'rtta elementga o'zgartirsangiz, lekin shartni while index < 4 bo'lganda yangilashni unutgan bo'lsangiz, kod panic qo'zg'atadi. Bu ham sekin, chunki kompilyator sikl orqali har bir iteratsiyada indeks array chegaralarida ekanligini shartli tekshirish uchun runtime kodini qo‘shadi.
Aniqroq variant sifatida, siz for siklidan foydalanishingiz va to'plamdagi har bir element uchun ba'zi kodlarni bajarishingiz mumkin. for sikli 3-5-ro'yxatdagi kodga o'xshaydi.
Fayl nomi: src/main.rs
fn main() { let a = [10, 20, 30, 40, 50]; for element in a { println!("qiymati: {element}"); } }
Ro'yxat 3-5: for `sikli yordamida to'plamning har bir elementi bo'ylab aylanish
Ushbu kodni ishga tushirganimizda, biz 3-4 ro'yxatdagi kabi natijani ko'ramiz. Eng muhimi, biz kodning xavfsizligini oshirdik va arrayning oxiridan tashqariga chiqish yoki yetarlicha uzoqqa bormaslik va ba'zi elementlarni yetishmayotganligi sababli paydo bo'lishi mumkin bo'lgan xatolar ehtimolini yo'q qildik.
for siklidan foydalanib, agar siz 3-4 roʻyxatda qoʻllanilgan metodda boʻlgani kabi arraydagi qiymatlar sonini oʻzgartirsangiz, boshqa kodni oʻzgartirishni eslab qolishingiz shart emas.
for looplarining xavfsizligi va ixchamligi ularni Rustda eng ko‘p ishlatiladigan loop konstruksiyasiga aylantiradi. 3-3 ro'yxatdagi while siklidan foydalanilgan ortga hisoblash misolida bo'lgani kabi, ma'lum bir necha marta kodni ishlatmoqchi bo'lgan vaziyatlarda ham ko'pchilik Rustaceanlar for siklidan foydalanadilar. Buning yo'li standart kutubxona tomonidan taqdim etilgan Range dan foydalanish bo'lib, bir raqamdan boshlanib, boshqa raqamdan oldin tugaydigan barcha raqamlarni ketma-ketlikda hosil qiladi.
Ortga hisoblash for sikli va biz hali u to‘g‘risida gapirmagan boshqa metod – rev yordamida diapazonni teskari tomonga o‘zgartirishga o‘xshaydi:
Fayl nomi: src/main.rs
fn main() { for raqam in (1..4).rev() { println!("{raqam}!"); } println!("LIFTOFF!!!"); }
Bu kod biroz chiroyliroq, shunday emasmi?
Xulosa
Siz erishdingiz! Bu juda katta bob bo'ldi: siz o'zgaruvchilar, skalyar va compound ma'lumotlar turlari, funksiyalar, izohlar, if expressionlari va sikllar haqida bilib oldingiz! Ushbu bobda muhokama qilingan tushunchalar bilan mashq qilish uchun quyidagilarni amalga oshirish uchun dasturlar yaratishga harakat qiling:
- Haroratni Farengeyt va Selsiy o'rtasida o'zgartiring.
- nta Fibonachchi raqamini yarating.
- Qo'shiqning takrorlanishidan foydalanib, “Rojdestvoning o'n ikki kuni“ Rojdestvo qo'shig'ining so'zlarini chop eting.
Davom etishga tayyor bo'lganingizda, Rustda boshqa dasturlash tillarida odatda mavjud bo'lmagan ownership(egalik) tushunchasi haqida gaplashamiz.
Ownershipni tushunish (Egalik)
Ownership Rustning eng noyob xususiyati bo'lib, tilning qolgan qismiga chuqur ta'sir ko'rsatadi. Bu Rust-ga garbage collectorga muhtoj bo'lmasdan xotira xavfsizligini kafolatlash imkonini beradi, shuning uchun ownership qanday ishlashini tushunish muhimdir. Ushbu bobda biz ownership huquqi, shuningdek, bir nechta tegishli xususiyatlar haqida gapiramiz: borrowing, slices va Rust ma'lumotlarni xotirada qanday joylashtirishi.
Ownership Nima?
Ownership(Egalik) bu Rust dasturi xotirani qanday boshqarishini boshqaradigan qoidalar to'plami. Barcha dasturlar ishlayotgan vaqtda kompyuter xotirasidan qanday foydalanishini boshqarishi kerak. Ba'zi tillarda axlat yig'ish(garbage collection) mavjud bo'lib, ular dastur ishlayotgan paytda ishlatilmaydigan xotirani muntazam ravishda qidiradi; boshqa tillarda dasturchi xotirani aniq ajratishi va bo'shatishi kerak. Rust uchinchi yondashuvdan foydalanadi: xotira kompilyator tekshiradigan qoidalar to'plamiga ownership tizimi orqali boshqariladi. Agar biron bir qoidalar buzilgan bo'lsa, dastur kompilatsiya qilinmaydi. Ownership xususiyatlarining hech biri dasturingiz ishlayotgan vaqtda sekinlashtirmaydi.
Ownership ko'plab dasturchilar uchun yangi tushuncha bo'lganligi sababli, unga ko'nikish uchun biroz vaqt kerak bo'ladi. Yaxshi xabar shundaki, siz Rust va ownership tizimi qoidalari bilan qanchalik tajribali bo'lsangiz, xavfsiz va samarali kodni tabiiy ravishda ishlab chiqish osonroq bo'ladi. Unda davom etamiz!
Ownershipni tushunganingizda, Rustni noyob qiladigan xususiyatlarni tushunish uchun mustahkam asosga ega bo'lasiz. Ushbu bobda, siz juda keng tarqalgan ma'lumotlar tuzilishiga qaratilgan ba'zi misollarni orqali ownershipni ishlashini o'rganasiz: string.
Stack va Heap
Ko'pgina dasturlash tillari stack va heap haqida tez-tez o'ylashingizni talab qilmaydi. Ammo Rust kabi tizim dasturlash tilida qiymat stackda yoki heapda bo'ladimi, til o'zini qanday tutishiga ta'sir qiladi va nima uchun siz ma'lum qarorlar qabul qilishingiz kerak. Ownershipning qismlari stack va heapga nisbatan keyinchalik ushbu bobda tasvirlanadi, shuning uchun bu yerda tayyorgarlik jarayonida qisqacha tushuntirish berilgan.
Stack ham, heap ham runtimeda foydalanish uchun kodingiz uchun mavjud bo'lgan xotira qismlaridir, lekin ular turli yo'llar bilan tuzilgan. Stack qiymatlarni ularni olgan tartibda saqlaydi va qiymatlarni teskari tartibda o'chiradi Bu oxirgi kelgan, birinchi chiqqan deb ataladi. Plitalar stackini o'ylab ko'ring: ko'proq plastinka qo'shsangiz, ularni qoziqning ustiga qo'yasiz va plastinka kerak bo'lganda, siz yuqoridan birini olib qo'yasiz. Plitalarni o'rtadan yoki pastdan qo'shish yoki olib tashlash ham ishlamaydi! Ma'lumotlarni qo'shish stackga qo'shish, ma'lumotlarni olib tashlash esa stackdan o'chirish deb ataladi. Stackda saqlangan barcha ma'lumotlar ma'lum, qat'iy belgilangan hajmga ega bo'lishi kerak. Kompilyatsiya vaqtida noma'lum o'lchamli yoki o'zgarishi mumkin bo'lgan o'lchamdagi ma'lumotlar esa heapda saqlanishi kerak.
heap kamroq tartibga solingan: ma'lumotlarni heapga qo'yganingizda, ma'lum miqdorda bo'sh joy talab qilasiz. Xotira ajratuvchisi(memory allocator) heapda yetarlicha katta bo'lgan bo'sh joyni topadi, uni ishlatilayotgan deb belgilaydi va o'sha joyning manzili bo'lgan pointerni ni qaytaradi. Bu jarayon heap allocating deb ataladi va ba'zan faqat allocating deb qisqartiriladi (qiymatlarni stackga qo'shish ajratish hisoblanmaydi). Heapga pointer ma'lum, qat'iy o'lcham bo'lgani uchun siz pointerni stackda saqlashingiz mumkin, lekin yaroqli ma'lumotlarni olishni istasangiz, pointergaga amal qilishingiz kerak. Restoranda o'tirganingizni o'ylab ko'ring. Kirish paytida siz guruhingizdagi odamlar sonini bildirasiz va uy egasi hammaga mos keladigan bo'sh stol topadi va sizni u yerga olib boradi. Agar guruhingizdagi kimdir kechikib kelsa, sizni topish uchun qayerda o'tirganingizni so'rashi mumkin.
stackga qo'shish heapda allocating qilishdan tezroq bo'ladi, chunki allacator hech qachon yangi ma'lumotlarni saqlash uchun joy izlamasligi kerak; bu joy har doim stackning yuqori qismida joylashgan. Nisbatan, heapda bo'sh joy ajratish ko'proq mehnat talab qiladi, chunki allacator avval ma'lumotlarni saqlash uchun yetarlicha katta joy topishi va keyingi allocatinga tayyorgarlik ko'rish uchun buxgalteriya hisobini amalga oshirishi kerak.
Heapdagi ma'lumotlarga kirish stackdagi ma'lumotlarga kirishdan ko'ra sekinroq, chunki u yerga borish uchun pointerga amal qilishingiz kerak. Zamonaviy protsessorlar xotirada kamroq o'tishsa, tezroq ishlaydi. O'xshashlikni davom ettirib, ko'plab jadvallardan buyurtmalarni qabul qiladigan restoran serverini ko'rib chiqing. Keyingi stolga o'tishdan oldin barcha buyurtmalarni bitta stolda olish eng samarali hisoblanadi. A jadvalidan buyurtma olish, keyin B jadvalidan buyurtma olish, keyin yana A dan va yana B dan bitta buyurtma olish ancha sekinroq jarayon bo'ladi. Xuddi shu qoidaga ko'ra, protsessor uzoqroqda emas (u heapda bo'lishi mumkin) emas, balki boshqa ma'lumotlarga yaqin (stackdagi kabi) ma'lumotlarda ishlasa, o'z ishini yaxshiroq bajarishi mumkin.
Sizning kodingiz funksiyani chaqirganda, funksiyaga o'tgan qiymatlar (shu jumladan, potentsial, heapdagi ma'lumotlarga pointerlar) va funksiyaning mahalliy o'zgaruvchilari stackga qo'shiladi. Funktsiya tugagach, bu qiymatlar stackdan chiqariladi.
Kodning qaysi qismlari heapda qaysi ma'lumotlardan foydalanayotganini kuzatib borish, heapdagi takroriy ma'lumotlar miqdorini minimallashtirish va bo'sh joy qolmasligi uchun heapdagi foydalanilmagan ma'lumotlarni tozalash - bularning barchasi ownership hal qiladigan muammolardir. Ownershipni tushunganingizdan so'ng, stack va heap haqida tez-tez o'ylashingiz shart emas, lekin ownership qilishning asosiy maqsadi heap ma'lumotlarni boshqarish ekanligini bilish uning nima uchun shunday ishlashini tushuntirishga yordam beradi.
Ownership qoidalari
Birinchidan, ownership qoidalarini ko'rib chiqaylik.Biz ularni ko'rsatadigan misollar bilan ishlashda ushbu qoidalarni yodda tuting:
- Rust-dagi har bir qiymat ownerga ega.
- Bir vaqtning o'zida faqat bitta owneri bo'lishi mumkin.
- Owneri amaldan tashqariga chiqsa, qiymat o'chiriladi.
O'zgaruvchan Scope
Endi biz Rustning asosiy sintaksisidan o‘tganimiz uchun, biz barcha fn main() { kodini misollarga kiritmaymiz, shuning uchun agar kuzatib boradigan bo‘lsangiz, quyidagi misollarni main funksiyasiga qo‘lda kiritganingizga ishonch hosil qiling. Natijada, bizning misollarimiz biroz ixchamroq bo'ladi, bu bizga boilerplate kodiga emas, balki haqiqiy tafsilotlarga e'tibor berishga imkon beradi.
Ownershipning birinchi misoli sifatida biz ba'zi o'zgaruvchilarning scopeni ko'rib chiqamiz. Scope - dastur doirasidagi element amal qiladigan diapazon. Quyidagi o'zgaruvchini oling:
#![allow(unused)] fn main() { let s = "salom"; }
s o'zgaruvchisi satr literaliga ishora qiladi, bu yerda satr qiymati dasturimiz matniga qattiq kodlangan. O'zgaruvchi e'lon qilingan paytdan boshlab joriy scopning oxirigacha amal qiladi. 4-1 ro'yxatida s o'zgaruvchisi qayerda to'g'ri bo'lishini izohlovchi izohlar bilan dastur ko'rsatilgan.
fn main() { { // s bu erda haqiqiy emas, u hali e'lon qilinmagan let s = "salom"; // s shu nuqtadan boshlab amal qiladi // s bilan ish bajaring } // bu scope endi tugadi va s endi haqiqiy emas }
Ro'yxat 4-1: O'zgaruvchi va uning amal qiladigan doirasi
Boshqacha qilib aytganda, bu yerda ikkita muhim nuqta bor:
- Qachonki
sscopega kirsa, u amal qiladi. - U scopedan tashqariga chiqmaguncha amal qiladi.
Ushbu nuqtada, scopelar va o'zgaruvchilarning yaroqliligi o'rtasidagi munosabatlar boshqa dasturlash tillaridagiga o'xshaydi. Endi biz String turini joriy qilish orqali ushbu tushunchaga asoslanamiz.
String turi
Ownership qoidalarini tasvirlash uchun bizga 3-bobning ”Ma'lumotlar turlari”
bo'limida ko'rib chiqilganlarga qaraganda murakkabroq ma'lumotlar turi kerak. Oldin ko'rib chiqilgan turlar ma'lum o'lchamga ega bo'lib, ular stackda saqlanishi va qo'llanilish doirasi tugagach, stackdan o'chirilishi mumkin va agar kodning boshqa qismi foydalanishi kerak bo'lsa yangi, mustaqil misol yaratish uchun tez va ahamiyatsiz nusxa ko'chirilishi mumkin kodning boshqa qismi bir xil qiymatni boshqa doirada ishlatishi kerak. Ammo biz heapda saqlangan ma'lumotlarni ko'rib chiqmoqchimiz va Rust bu ma'lumotlarni qachon tozalashni bilishini o'rganmoqchimiz va String turi ajoyib misoldir.
Biz String ning ownership bilan bog'liq qismlariga e'tibor qaratamiz. Ushbu jihatlar standart kutubxona tomonidan taqdim etilganmi yoki siz yaratganmi, boshqa murakkab ma'lumotlar turlariga ham tegishli.
Biz 8-bobda Stringni chuqurroq muhokama qilamiz.
Biz allaqachon string literallarini ko'rdik, bu yerda string qiymati bizning dasturimizga qattiq kodlangan. String literallari qulay, ammo ular biz matndan foydalanmoqchi bo'lgan har qanday vaziyatga mos kelmaydi. Buning sabablaridan biri shundaki, ular o'zgarmasdir. Yana bir narsa shundaki, biz kodni yozganimizda har bir satr qiymatini bilish mumkin emas: masalan, agar biz foydalanuvchi ma'lumotlarini olib, uni saqlamoqchi bo'lsak-chi? Bunday holatlar uchun Rust ikkinchi string turiga ega, String. Bu tur heapda ajratilgan ma'lumotlarni boshqaradi va shuning uchun kompilyatsiya vaqtida bizga noma'lum bo'lgan matn miqdorini saqlashi mumkin. Siz from funksiyasidan foydalanib satr literalidan String yaratishingiz mumkin, masalan:
#![allow(unused)] fn main() { let s = String::from("salom"); }
Ikki nuqtali :: operatori bizga string_from kabi qandaydir nomdan foydalanish o'rniga String turi ostida ushbu from funksiyasini nom maydoniga qo`yish imkonini beradi.
Biz ushbu sintaksisni 5-bobning ”Metod sintaksisi” bo'limida ko'proq muhokama qilamiz va 7-bobdagi ”Modul treedagi elementga murojaat qilish yo'llari” da modullar bilan nomlar oralig'i haqida gapiramiz.
Ushbu turdagi string mutatsiyaga uchragan bo'lishi mumkin:
fn main() { let mut s = String::from("salom"); s.push_str(", dunyo!"); // push_str() satrga literal qo'shadi println!("{}", s); // Bu “salom, dunyo!” deb chop etiladi }
Xo'sh, bu yerda qanday farq bor? Nima uchun String ni mutatsiyaga solish mumkin, lekin harflarni o'zgartirish mumkin emas? Farqi bu ikki turning xotira bilan qanday munosabatda bo'lishida.
Xotira va Taqsimlash(Allocation)
String literalida biz kompilyatsiya vaqtida tarkibni bilamiz, shuning uchun matn to'g'ridan-to'g'ri yakuniy bajariladigan faylga qattiq kodlangan.Shuning uchun string literallari tez va samarali. Ammo bu xususiyatlar faqat satr literalining o'zgarmasligidan kelib chiqadi. Afsuski, kompilyatsiya vaqtida hajmi noma'lum bo'lgan va dasturni ishga tushirishda hajmi o'zgarishi mumkin bo'lgan har bir matn bo'lagi uchun biz binary faylga bir bo'lak xotira qo'ya olmaymiz.
String turida o'zgaruvchan, o'sib boradigan matn qismini qo'llab-quvvatlash uchun tarkibni saqlash uchun kompilyatsiya vaqtida noma'lum bo'lgan xotira hajmini yig'ishda ajratishimiz kerak. Buning ma'nosi:
- Xotira runtimeda xotira allactoridan so'ralishi kerak.
Stringbilan ishlashni tugatgandan so'ng, bizga ushbu xotirani allacatoriga qaytarish usuli kerak.
Bu birinchi qism biz tomonimizdan amalga oshiriladi: biz String::from deb chaqirganimizda, uni implementi kerakli xotirani talab qiladi. Bu dasturlash tillarida deyarli universaldir.
Biroq, ikkinchi qism boshqacha. Garbage Collector (GC) bo'lgan tillarda GC endi ishlatilmayotgan xotirani kuzatib boradi va tozalaydi va bu haqda o'ylashimiz shart emas. Ko'pgina tillarda GC bo'lmaganda, xotiradan qachon foydalanilmayotganini aniqlash va uni aniq bo'shatish uchun kodni chaqirish, xuddi biz so'raganimizdek, bizning burchimizdir. Buni to'g'ri bajarish tarixan qiyin dasturlash muammosi bo'lgan. Agar unutsak, xotirani behuda sarflaymiz. Agar biz buni juda erta qilsak, bizda noto'g'ri o'zgaruvchi bo'ladi. Agar buni ikki marta qilsak, bu ham xato. Aynan bitta allocateni bitta bo'sh bilan birlashtirishimiz kerak.
Rust boshqa yo'lni egallaydi: unga ega bo'lgan o'zgaruvchi amaldan tashqariga chiqqandan so'ng xotira avtomatik ravishda qaytariladi. Bu yerda 4-1 roʻyxatdagi misolimiz satr harfi oʻrniga String yordamida berilgan:
fn main() { { let s = String::from("salom"); // s shu nuqtadan boshlab amal qiladi // s bilan ish bajaring } // bu scope endi tugadi va s yo'q // uzoqroq amal qiladi }
Biz String kerak bo'lgan xotirani ajratuvchiga qaytarishimiz mumkin bo'lgan tabiiy nuqta bor: s scopedan chiqib ketganda. O'zgaruvchi scopedan chiqib ketganda, Rust biz uchun maxsus funksiyani chaqiradi.Ushbu funktsiya drop deb ataladi va u yerda String muallifi xotirani qaytarish uchun kodni qo'yishi mumkin. Rust yopilgan jingalak qavsda avtomatik ravishda drop ni chaqiradi.
Eslatma: C++ da, elementning ishlash muddati oxirida resurslarni taqsimlashning bunday sxemasi ba'zan Resource Acquisition Is Initialization (RAII)(Resurslarni yig'ish - ishga tushirish (RAII) deb ataladi. Agar siz RAII patternlaridan foydalangan bo'lsangiz, Rust-dagi
dropfunksiyasi sizga tanish bo'ladi.
Ushbu pattern Rust kodini yozish usuliga chuqur ta'sir qiladi. Bu hozir oddiy bo'lib tuyulishi mumkin, ammo biz bir nechta o'zgaruvchilar biz yig'ilgan ma'lumotlardan foydalanishni xohlayotganimizda, murakkabroq holatlarda kodning harakati kutilmagan bo'lishi mumkin. Keling, ushbu vaziyatlarning ba'zilarini ko'rib chiqaylik.
Move bilan o'zaro ta'sir qiluvchi o'zgaruvchilar va ma'lumotlar
Rustda bir nechta o'zgaruvchilar bir xil ma'lumotlar bilan turli yo'llar bilan o'zaro ta'sir qilishi mumkin. 4-2 ro'yxatda integer sondan foydalanish misolini ko'rib chiqaylik.
fn main() { let x = 5; let y = x; }
4-2 roʻyxat: x oʻzgaruvchisining butun qiymatini y ga belgilash
Bu nima qilayotganini taxmin qilishimiz mumkin: 5 qiymatini x ga bog‘lang; keyin x dagi qiymatdan nusxa oling va uni y ga bog'lang. Endi bizda ikkita o'zgaruvchi bor, x va y va ikkalasi ham 5 ga teng. Bu haqiqatan ham sodir bo'lmoqda, chunki butun sonlar ma'lum, qat'iy o'lchamga ega oddiy qiymatlardir va bu ikkita 5 qiymat stackga qo'shiladi.
Endi String versiyasini ko'rib chiqamiz:
fn main() { let s1 = String::from("salom"); let s2 = s1; }
Bu juda o'xshash ko'rinadi, shuning uchun biz uning ishlash metodi bir xil bo'ladi deb taxmin qilishimiz mumkin: ya'ni ikkinchi qator s1 qiymatining nusxasini yaratadi va uni s2 bilan bog'laydi. Ammo bu sodir bo'ladigan narsa emas.
Qopqoq ostidagi String bilan nima sodir bo'layotganini ko'rish uchun 4-1-rasmga qarang. String chap tomonda ko'rsatilgan uchta qismdan iborat: satr tarkibini saqlaydigan xotiraga ko'rsatgich, uzunlik(len) va sig'im(capacity).
Ushbu ma'lumotlar guruhi stackda saqlanadi. O'ng tomonda tarkibni saqlaydigan heap xotira joylashgan.
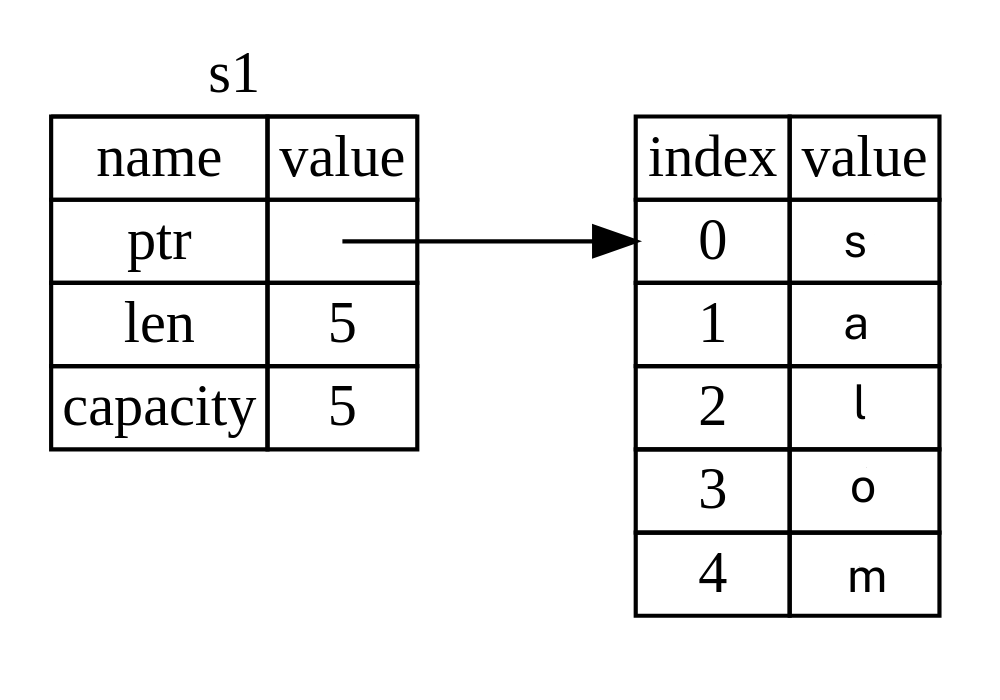
4-1-rasm: s1 ga bog‘langan salom qiymatiga ega String xotirasidagi tasvir
Uzunlik - String mazmuni hozirda qancha xotira, baytlarda foydalanayotganligi. Sig'im(capacity) - bu String allacatordan olgan xotiraning umumiy hajmi, baytlarda. Uzunlik va si'gimlar o'rtasidagi farq muhim, ammo bu kontekstda emas, shuning uchun hozircha si'gimlarni e'tiborsiz qoldirish yaxshi.
s1 ni s2 ga belgilaganimizda, String ma'lumotlari nusxalanadi, ya'ni biz stackdagi pointer, uzunlik va sig`imdan nusxa olamiz. Biz pointer(ko'rsatkich) ko'rsatgan to'plamdagi ma'lumotlarni ko'chirmaymiz. Boshqacha qilib aytganda, ma'lumotlarning xotirada ko'rinishi 4-2-rasmga o'xshaydi.
4-2-rasm: s1 pointeri, uzunligi va sigʻimi nusxasiga ega s2 oʻzgaruvchisi xotirasida koʻrsatilishi
Tasvir 4-3-rasmga o'xshamaydi, agar Rust o'rniga heap ma'lumotlarni ko'chirsa, xotira qanday ko'rinishga ega bo'lardi. Agar Rust buni amalga oshirgan bo'lsa, s2 = s1 operatsiyasi, agar heapdagi ma'lumotlar katta bo'lsa, runtimening ishlashi nuqtai nazaridan juda qimmat bo'lishi mumkin.
4-3-rasm: Rust heap ma'lumotlarni ham nusxalagan bo'lsa, s2 = s1 nima qilishi mumkin bo'lgan yana bir imkoniyat
Avvalroq biz aytgan edikki, o‘zgaruvchi qo‘llanish doirasidan chiqib ketganda, Rust avtomatik ravishda drop funksiyasini chaqiradi va bu o‘zgaruvchi uchun heap xotirani tozalaydi. Ammo 4-2-rasmda ikkala ma'lumot pointeri bir xil joyga ishora qiladi. Bu muammo: s2 va s1 scopedan chiqib ketganda, ikkalasi ham bir xil xotirani bo'shatishga harakat qiladi. Bu double free(ikki marta bo'sh)xato sifatida tanilgan va biz avval aytib o'tgan xotira xavfsizligi xatolaridan biridir. Xotirani ikki marta bo'shatish xotira buzilishiga olib kelishi mumkin, bu esa xavfsizlik zaifliklariga olib kelishi mumkin.
Xotira xavfsizligini ta'minlash uchun let s2 = s1; qatoridan keyin Rust s1 ni endi yaroqsiz deb hisoblaydi. Shuning uchun, s1 qo'llanilgandan tashqariga chiqqanda Rust hech narsani bo'shatishi shart emas. s2 yaratilgandan keyin s1 dan foydalanmoqchi bo'lganingizda nima sodir bo`lishini tekshiring; u ishlamaydi:
fn main() {
let s1 = String::from("salom");
let s2 = s1;
println!("{}, dunyo!", s1);
}Siz shunday xatoga yo'l qo'yasiz, chunki Rust bekor qilingan havoladan foydalanishga to'sqinlik qiladi:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0382]: borrow of moved value: `s1`
--> src/main.rs:5:28
|
2 | let s1 = String::from("salom");
| -- move occurs because `s1` has type `String`, which does not implement the `Copy` trait
3 | let s2 = s1;
| -- value moved here
4 |
5 | println!("{}, dunyo!", s1);
| ^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
help: consider cloning the value if the performance cost is acceptable
|
3 | let s2 = s1.clone();
| ++++++++
For more information about this error, try `rustc --explain E0382`.
error: could not compile `ownership` due to previous error
Agar siz boshqa tillar bilan ishlashda shallow copy va deep copy so‘zlarini eshitgan bo‘lsangiz, pointerni nusxalash tushunchasi, ma'lumotlardan nusxa ko'chirmasdan uzunligi va sig'imi olish, ehtimol shallow copy kabi eshitiladi. Ammo Rust birinchi o'zgaruvchini ham bekor qilganligi sababli, shallow copy deb nomlanish o'rniga u move(ko'chirish) deb nomlanadi. Bu misolda s1 s2 ga ko'chirilgan deb aytamiz. Shunday qilib, aslida nima sodir bo'lishi 4-4-rasmda ko'rsatilgan.
4-4-rasm: s1 dan keyin xotiradagi ko`rinish bekor qilingan
Bu bizning muammomizni hal qiladi! Faqatgina s2 amal qilganda, u scopedan tashqariga chiqsa, u faqat xotirani bo'shatadi va biz tugatdik.
Bundan tashqari, dizayn tanlovi ham mavjud: Rust hech qachon avtomatik ravishda ma'lumotlaringizning "deep copyni" yaratmaydi. Shuning uchun, har qanday avtomatik nusxa ko'chirish runtimening ishlashi nuqtai nazaridan arzon deb taxmin qilish mumkin.
Clone bilan o'zaro ta'sir qiluvchi o'zgaruvchilar va ma'lumotlar
Agar biz faqat stack ma'lumotlarini emas, balki String ning heap ma'lumotlarini deeply copyni istasak, clone deb nomlangan umumiy metoddan foydalanishimiz mumkin. Metod sintaksisini 5-bobda muhokama qilamiz, lekin metodlar ko‘p dasturlash tillarida umumiy xususiyat bo‘lgani uchun siz ularni avval ko‘rgan bo‘lsangiz kerak.
Mana amaldagi clone metodiga misol:
fn main() { let s1 = String::from("salom"); let s2 = s1.clone(); println!("s1 = {}, s2 = {}", s1, s2); }
Bu juda yaxshi ishlaydi va 4-3-rasmda ko'rsatilgan xatti-harakatni aniq ishlab chiqaradi, bu yerda heap ma'lumotlar nusxalanadi.
clone ga murojatni ko'rsangiz, ba'zi bir ixtiyoriy kod bajarilayotganini va bu kod qimmat bo'lishi mumkinligini bilasiz. Bu boshqa narsa sodir bo'layotganining vizual ko'rsatkichidir.
Faqat stack ma'lumotlari: nusxalash
Biz hali gapirmagan yana bir narsa bor. Integer sonlardan foydalanadigan ushbu kod - bir qismi 4-2 ro'yxatda ko'rsatilgan - ishlaydi va amal qiladi:
fn main() { let x = 5; let y = x; println!("x = {}, y = {}", x, y); }
Ammo bu kod biz bilib olgan narsaga zid ko'rinadi: bizda clone uchun murojat yo'q, lekin x hali ham amal qiladi va y ga o'tkazilmagan.
Sababi, kompilyatsiya vaqtida ma'lum o'lchamga ega bo'lgan integer sonlar kabi turlar to'liq stackda saqlanadi, shuning uchun haqiqiy qiymatlarning nusxalari tezda tayyorlanadi. Bu shuni anglatadiki, biz y o'zgaruvchisini yaratganimizdan keyin x ning haqiqiy bo'lishiga to'sqinlik qilish uchun hech qanday sabab yo'q. Boshqacha qilib aytadigan bo'lsak, bu yerda deep va shallow nusxa ko'chirish o'rtasida farq yo'q, shuning uchun clone ni chaqirish odatdagi shallow copydan farq qilmaydi va biz uni tark etishimiz mumkin.
Rust Copy traiti deb nomlangan maxsus annotationga ega bo'lib, uni butun sonlar kabi stackda saqlanadigan turlarga joylashtirishimiz mumkin (biz 10-bobda traitlar haqida ko'proq gaplashamiz). Agar tur Copy traitini amalga oshirsa, undan foydalanadigan o‘zgaruvchilar harakatlanmaydi, aksincha, ahamiyatsiz tarzda ko‘chiriladi, bu esa boshqa o‘zgaruvchiga tayinlangandan keyin ham amal qiladi.
Rust turi yoki uning biron bir qismi Drop traitini qo‘llagan bo‘lsa, Copy bilan turga annotation qo‘yishimizga ruxsat bermaydi. Qiymat doirasidan chiqib ketganda turga maxsus biror narsa kerak bo'lsa va biz ushbu turga Copy annotationni qo'shsak, biz kompilyatsiya vaqtida xatolikni olamiz. Traitni amalga oshirish uchun turingizga Copy annotationni qanday qo‘shish haqida bilish uchun C ilovasidagi “Derivable Traitlar”ga qarang.
Xo'sh, Copy traitini qaysi turlar amalga oshiradi? Ishonch hosil qilish uchun berilgan tur uchun texnik hujjatlarni tekshirishingiz mumkin, lekin umumiy qoida sifatida har qanday oddiy skalyar qiymatlar guruhi Copy ni amalga oshirishi mumkin va ajratishni talab qiladigan yoki biron bir manba shakli bo‘lgan hech narsa Copy ni amalga oshira olmaydi. Copy ni amalga oshiradigan ba'zi turlar:
u32kabi barcha integer turlari.- Boolean turi,
bool,truevafalseqiymatlari bilan. - Barcha floating-point turlari, masalan,
f64. - Belgi turi,
char. - Tuplelar, agar ular faqat
Copyni ham implement qiladigan turlarni o'z ichiga olsa. Masalan,(i32, i32)Copyni implement qiladi, lekin(i32, String)bajarmaydi.
Ownership va Funksiyalar
Funksiyaga qiymat berish mexanikasi o'zgaruvchiga qiymat berish mexanikasiga o'xshaydi. O'zgaruvchini funksiyaga o'tkazish, xuddi assignment kabi ko'chiriladi yoki nusxalanadi. 4-3 ro'yxatda o'zgaruvchilarning qayerga kirishi va tashqariga chiqishini ko'rsatadigan ba'zi izohlar bilan misol mavjud.
Fayl nomi: src/main.rs
fn main() { let s = String::from("salom"); // s scopega kiradi ownershiplik_qiladi(s); // s qiymati funksiyaga o'tadi ... // ... va shuning uchun bu yerda endi amal qilmaydi let x = 5; // x scopega kiradi nusxasini_yaratadi(x); // x funksiyaga o'tadi, // lekin i32 nusxa ko'chirish, shuning uchun tinch qo'yish yaxshidir // keyin x dan foydalaning } // Bu erda x scopedan chiqib ketadi, keyin s. Lekin s qiymati ko'chirilganligi sababli, hech // qanday maxsus narsa sodir bo'lmaydi. fn ownershiplik_qiladi(some_string: String) { // some_string scopega kiradi println!("{}", some_string); } // Bu yerda some_string scopedan chiqib ketadi va `drop` deb ataladi. Qo'llab-quvvatlovchi // xotira bo'shatiladi. fn nusxasini_yaratadi(some_integer: i32) { // some_integer scopega kiradi println!("{}", some_integer); } // Bu erda some_integer scopedan tashqariga chiqadi. Hech qanday maxsus narsa bo'lmaydi.
Ro'yxat 4-3: ownership va scope izohlangan funksiyalar
Agar biz ownershiplik_qiladi chaqiruvidan keyin s dan foydalanmoqchi bo'lsak, Rust kompilyatsiya vaqtida xatolikka yo'l qo'yadi. Ushbu statik tekshiruvlar bizni xatolardan himoya qiladi. s va x dan foydalanadigan main ga kod qo‘shib ko‘ring va ulardan qayerda foydalanishingiz mumkinligini va ownership qoidalari bunga xalaqit beradigan joyni ko‘ring.
Return qiymatlari va Scope
Return qilingan qiymatlar ownershipni ham o'tkazishi mumkin. 4-4 ro'yxatda 4-3 ro'yxatdagi kabi izohlar bilan ba'zi qiymatlarni qaytaradigan funksiya misoli ko'rsatilgan.
Fayl nomi: src/main.rs
fn main() { let s1 = egalik_beradi(); // egalik_beradi o'zining return qiymatini // s1 ga o'tkazadi let s2 = String::from("salom"); // s2 scopega kiradi let s3 = oladi_va_qaytaradi(s2); // s2 oladi_va_qaytaradi ichiga // ko'chiriladi, u ham o'zining return // qiymatini s3 ga o'tkazadi } // Bu erda s3 scopedan chiqib ketadi va o'chiriladi. s2 ko'chirildi, shuning uchun // hech narsa sodir bo'lmaydi. s1 scopedan chiqib ketadi va o'chiriladi. fn egalik_beradi() -> String { // egalik_beradi o'zining return // qiymatini uni chaqiradigan // funksiyaga o'tkazadi let some_string = String::from("rust"); // some_string scopea kiradi some_string // some_string return qilinadi va // chaqiruv funksiyasiga // o'tadi } // Bu funksiya Stringni oladi va bittasini qaytaradi fn oladi_va_qaytaradi(a_string: String) -> String { // a_string scopega // kiradi a_string // a_string qaytariladi va chaqiruv funksiyasiga o'tadi }
Ro'yxat 4-4: Return ownershipni o'tkazish qiymatlar
O'zgaruvchiga ownership har safar bir xil patternga amal qiladi: boshqa o'zgaruvchiga qiymat berish uni ko'chiradi. Heapdagi maʼlumotlarni oʻz ichiga olgan oʻzgaruvchi scopedan tashqariga chiqsa, agar maʼlumotlarga ownership boshqa oʻzgaruvchiga oʻtkazilmagan boʻlsa, qiymat drop orqali tozalanadi.
Bu ishlayotganda, ownership va keyin har bir funksiyaga ownershipini qaytarish biroz zerikarli. Agar funksiyaga qiymatdan foydalanishiga ruxsat bermoqchi bo'lsak, lekin ownershiplik qilmasak nima bo'ladi? Bu juda zerikarli, agar biz uni qayta ishlatmoqchi bo'lsak, biz kiritgan har qanday narsa, shuningdek, biz qaytarishni xohlashimiz mumkin bo'lgan funktsiya tanasidan kelib chiqadigan har qanday ma'lumotlarga qo'shimcha ravishda qaytarib berilishi kerak.
Rust 4-5 ro'yxatda ko'rsatilganidek, tuple yordamida bir nechta qiymatlarni return qilish imkon beradi.
Fayl nomi: src/main.rs
fn main() { let s1 = String::from("salom"); let (s2, len) = uzunlikni_hisoblash(s1); println!("'{}' uzunligi {}.", s2, len); } fn uzunlikni_hisoblash(s: String) -> (String, usize) { let length = s.len(); // len() string uzunligini qaytaradi (s, length) }
Ro'yxat 4-5: Parametrlarga ownershipni qaytarish
Ammo bu umumiy bo'lishi kerak bo'lgan kontseptsiya uchun juda ko'p funksiya va juda ko'p ish. Yaxshiyamki, Rustda qiymatni ownershipni o'tkazmasdan ishlatish xususiyati mavjud, uni reference deb atashadi.
Reference va Borrowing
Ro'yxat 4-5dagi tuple kodi bilan bog'liq muammo shundaki, biz String ni chaqiruvchi funksiyaga qaytarishimiz kerak, shunda biz uzunlikni_hisoblash ga chaqiruvdan keyin ham String dan foydalanishimiz mumkin, chunki String uzunlikni_hisoblash ga ko'chirildi. Buning o'rniga biz String qiymatiga reference(havola) berishimiz mumkin.
Reference pointerga o'xshaydi, chunki u biz ushbu manzilda saqlangan ma'lumotlarga kirish uchun amal qilishimiz mumkin bo'lgan manzildir; bu ma'lumotlar boshqa o'zgaruvchilarga tegishli. Pointerdan farqli o'laroq, reference ma'lumotnomaning amal qilish muddati davomida ma'lum turdagi yaroqli qiymatni ko'rsatishi kafolatlanadi.
Qiymatga egalik qilish o'rniga parametr sifatida obyektga referencega ega bo'lgan uzunlikni_hisoblash funksiyasini qanday aniqlash va ishlatishingiz mumkin:
Fayl nomi: src/main.rs
fn main() { let s1 = String::from("salom"); let len = uzunlikni_hisoblash(&s1); println!("'{}' uzunligi {}.", s1, len); } fn uzunlikni_hisoblash(s: &String) -> usize { s.len() }
Birinchidan, o'zgaruvchilar deklaratsiyasidagi barcha tuple kodi va funksiyani qaytarish qiymati yo'qolganiga e'tibor bering. Ikkinchidan, &s1 ni uzunlikni_hisoblash ga o'tkazamiz va uning definitionida biz String emas, &Stringni olamiz. Ushbu ampersandlar reference ni ifodalaydi va ular sizga biron bir qiymatga ownershiplik qilmasdan murojaat qilish imkonini beradi. 4-5-rasmda ushbu tushuncha tasvirlangan.
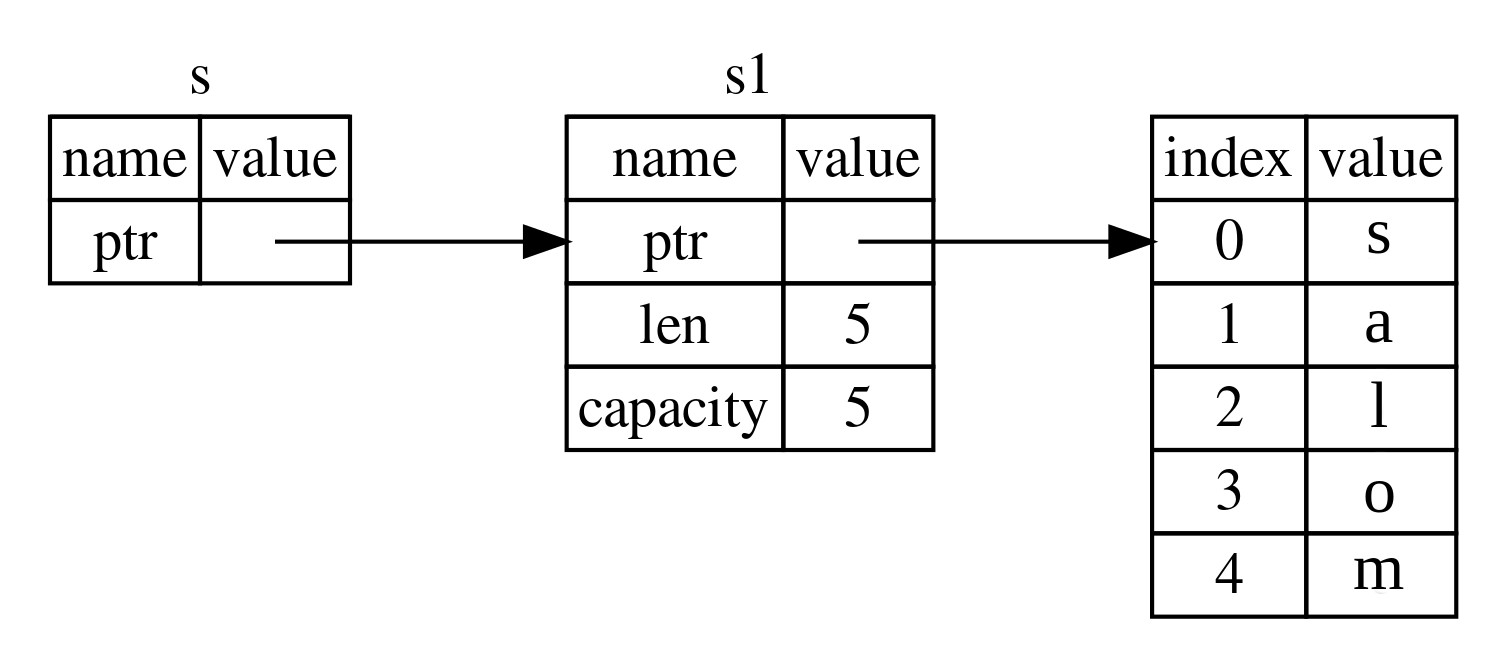
4-5-rasm: &String s chizmasi String s1ga ishora qiladi
Eslatma:
&yordamida reference qilishning teskarisi dereferencing bo'lib, u*dereference operatori yordamida amalga oshiriladi. Biz 8-bobda dereference operatoridan baʼzi foydalanishni koʻrib chiqamiz va 15-bobda dereference tafsilotlarini muhokama qilamiz.
Keling, bu yerda funksiya chaqiruvini batafsil ko'rib chiqaylik:
fn main() { let s1 = String::from("salom"); let len = uzunlikni_hisoblash(&s1); println!("'{}' uzunligi {}.", s1, len); } fn uzunlikni_hisoblash(s: &String) -> usize { s.len() }
&s1 sintaksisi bizga s1 qiymatiga refers qiluvchi, lekin unga tegishli bo`lmagan reference yaratish imkonini beradi. Unga egalik qilmaganligi sababli, reference foydalanishni to'xtatganda, u ko'rsatgan qiymat o'chirilmaydi.
Xuddi shunday, funksiya imzosi s parametrining turi reference ekanligini ko'rsatish uchun & dan foydalanadi. Keling, ba'zi tushuntirish izohlarini qo'shamiz:
fn main() { let s1 = String::from("salom"); let len = uzunlikni_hisoblash(&s1); println!("'{}' uzunligi {}.", s1, len); } fn uzunlikni_hisoblash(s: &String) -> usize { // s - Stringga reference(havola) s.len() } // Bu yerda s scopedan chiqib ketadi. Lekin u nazarda tutgan itemga ownership qilmagani // uchun u tashlanmaydi.
s o'zgaruvchisi amal qiladigan doirasi har qanday funksiya parametrining qamrovi bilan bir xil bo'ladi, lekin s foydalanishni to'xtatganda reference ko'rsatilgan qiymat o'chirilmaydi, chunki s ownershipga ega emas. Funksiya referencelarni yaroqli qiymatlar o'rniga parametr sifatida ko'rsatsa, biz ownershipni qaytarish uchun qiymatlarni qaytarishimiz shart emas, chunki bizda hech qachon ownership bo'lmagan.
Malumot yaratish harakatini borrowing(qarz olish) deb ataymiz. Haqiqiy hayotda bo'lgani kabi, agar biror kishi biror narsaga ega bo'lsa, siz undan qarz olishingiz mumkin. Ishingiz tugagach, uni qaytarib berishingiz kerak. Siz unga egalik qilmaysiz.
Xo'sh, agar biz borrowing qilgan narsani o'zgartirishga harakat qilsak nima bo'ladi? 4-6 ro'yxatdagi kodni sinab ko'ring. Spoiler ogohlantirish: bu ishlamaydi!
Fayl nomi: src/main.rs
fn main() {
let s = String::from("salom");
almashtirish(&s);
}
fn almashtirish(some_string: &String) {
some_string.push_str(", rust");
}Ro'yxat 4-6: Borrow qilingan qiymatni o'zgartirishga urinish
Mana xato:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0596]: cannot borrow `*some_string` as mutable, as it is behind a `&` reference
--> src/main.rs:8:5
|
7 | fn almashtirish(some_string: &String) {
| ------- help: consider changing this to be a mutable reference: `&mut String`
8 | some_string.push_str(", rust");
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ `some_string` is a `&` reference, so the data it refers to cannot be borrowed as mutable
For more information about this error, try `rustc --explain E0596`.
error: could not compile `ownership` due to previous error
O'zgaruvchilar standart bo'yicha o'zgarmas bo'lganidek, referencelar ham shunday. Bizga reference biror narsani o'zgartirishga ruxsat berilmagan.
O'zgaruvchan Referencelar
Biz 4-6 ro'yxatdagi kodni tuzatishimiz mumkin, buning o'rniga o'zgaruvchan referencedan foydalanadigan bir nechta kichik sozlashlar bilan borrow qilingan qiymatni o'zgartirishimiz mumkin:
Fayl nomi: src/main.rs
fn main() { let mut s = String::from("salom"); change(&mut s); } fn change(some_string: &mut String) { some_string.push_str(", dunyo"); }
Avval s ni mut qilib o'zgartiramiz. Keyin biz &mut s bilan o'zgaruvchan reference yaratamiz, bu yerda biz change funksiyasini chaqiramiz va some_string: &mut String bilan o'zgaruvchan referencei qabul qilish uchun funksiya signatureni yangilaymiz. Bu change funksiyasi olingan qiymatni o'zgartirishini aniq ko'rsatadi.
O'zgaruvchan referencelar bitta katta cheklovga ega: agar sizda qiymatga o'zgaruvchan reference bo'lsa, sizda bu qiymatga boshqa referencelar bo'lishi mumkin emas. s ga ikkita o'zgaruvchan reference yaratishga urinayotgan ushbu kod muvaffaqiyatsiz bo'ladi:
Fayl nomi: src/main.rs
fn main() {
let mut s = String::from("salom");
let r1 = &mut s;
let r2 = &mut s;
println!("{}, {}", r1, r2);
}Mana xato:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0499]: cannot borrow `s` as mutable more than once at a time
--> src/main.rs:5:14
|
4 | let r1 = &mut s;
| ------ first mutable borrow occurs here
5 | let r2 = &mut s;
| ^^^^^^ second mutable borrow occurs here
6 |
7 | println!("{}, {}", r1, r2);
| -- first borrow later used here
For more information about this error, try `rustc --explain E0499`.
error: could not compile `ownership` due to previous error
Bu xatolik bu kodning yaroqsiz ekanligini bildiradi, chunki biz bir vaqtning o'zida bir necha marta o'zgaruvchan s ni borrow qila ololmaymiz. Birinchi o'zgaruvchan borrow r1 da bo'lib, u println! da ishlatilgunga qadar davom etishi kerak, lekin bu o'zgaruvchan referenceni yaratish va undan foydalanish o'rtasida, biz r2 da r1 bilan bir xil ma'lumotlarni olgan boshqa o`zgaruvchan reference yaratishga harakat qildik.
Bir vaqtning o'zida bir xil ma'lumotlarga bir nechta o'zgaruvchan referencelarni oldini oluvchi cheklov mutatsiyaga imkon beradi, lekin juda nazorat ostida. Bu yangi Rustaceanlar bilan kurashadigan narsa, chunki aksariyat tillar xohlagan vaqtda mutatsiyaga o'tishga imkon beradi. Ushbu cheklovning afzalligi shundaki, Rust kompilyatsiya vaqtida data raceni oldini oladi. Data race poyga holatiga o'xshaydi va bu uchta xatti-harakatlar sodir bo'lganda sodir bo'ladi:
- Ikki yoki undan ortiq pointerlar bir vaqtning o'zida bir xil ma'lumotlarga kirishadi.
- Pointerlardan kamida bittasi ma'lumotlarga yozish uchun ishlatiladi.
- Ma'lumotlarga kirishni sinxronlashtirish uchun hech qanday mexanizm ishlatilmaydi.
Data race aniqlanmagan xatti-harakatlarga olib keladi va ularni runtimeda kuzatib borishga harakat qilayotganingizda tashxis qo'yish va tuzatish qiyin bo'lishi mumkin; Rust data racelari bilan kodni kompilyatsiya qilishni rad etish orqali bu muammoni oldini oladi!
Har doimgidek, biz bir vaqtning o'zida emas, balki bir nechta o'zgaruvchan referencelarga ruxsat beruvchi yangi scope yaratish uchun jingalak qavslardan foydalanishimiz mumkin:
fn main() { let mut s = String::from("salom"); { let r1 = &mut s; } // r1 bu yerda scopedan chiqib ketadi, shuning uchun biz hech //qanday muammosiz yangi reference qilishimiz mumkin. let r2 = &mut s; }
Rust o'zgaruvchan va o'zgarmas referencelarni birlashtirish uchun shunga o'xshash qoidani qo'llaydi.
fn main() {
let mut s = String::from("salom");
let r1 = &s; // muammo yo'q
let r2 = &s; // muammo yo'q
let r3 = &mut s; // KATTA MUAMMO
println!("{}, {}, va {}", r1, r2, r3);
}Mana xato:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:6:14
|
4 | let r1 = &s; // muammo yo'q
| -- immutable borrow occurs here
5 | let r2 = &s; // muammo yo'q
6 | let r3 = &mut s; // KATTA MUAMMO
| ^^^^^^ mutable borrow occurs here
7 |
8 | println!("{}, {}, va {}", r1, r2, r3);
| -- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `ownership` due to previous error
Voy! Bizda shuningdek o'zgaruvchan referencelar bo'lishi mumkin emas, bizda bir xil qiymatga o'zgarmas reference mavjud.
O'zgarmas reference foydalanuvchilari qiymat birdaniga ularning ostidan o'zgarishini kutishmaydi! Biroq, bir nechta o'zgarmas referencelarga ruxsat beriladi, chunki faqat ma'lumotlarni o'qiyotgan hech kim boshqa hech kimning ma'lumotni o'qishiga ta'sir qilish qobiliyatiga ega emas.
E'tibor bering, referencening ko'lami u kiritilgan joydan boshlanadi va oxirgi ishlatilgan vaqtgacha davom etadi. Masalan, ushbu kod kompilyatsiya qilinadi, chunki o'zgarmas referencelarning oxirgi ishlatilishi, println!, o'zgaruvchan reference kiritilishidan oldin sodir bo'ladi:
fn main() { let mut s = String::from("salom"); let r1 = &s; // muammo yo'q let r2 = &s; // muammo yo'q println!("{} va {}", r1, r2); // r1 va r2 o'zgaruvchilari bu nuqtadan keyin ishlatilmaydi let r3 = &mut s; // muammo yo'q println!("{}", r3); }
r1 va r2 o'zgarmas referencelar doirasi println dan keyin tugaydi! ular oxirgi marta ishlatiladigan joy, ya'ni o'zgaruvchan referencelar r3 yaratilishidan oldin. Ushbu doiralar bir-biriga mos kelmaydi, shuning uchun bu kodga ruxsat beriladi: kompilyator reference doirasi tugashidan bir nuqtada endi foydalanilmayotganini aytishi mumkin.
Borrowingdagi xatolar ba'zida asabiylashsa ham, Rust kompilyatori potentsial xatoni erta (runtimeda emas, balki kompilyatsiya vaqtida) ko'rsatib beradi va muammo qayerda ekanligini aniq ko'rsatadi. Keyin nima uchun ma'lumotlaringiz siz o'ylagandek emasligini kuzatishingiz shart emas.
Dangling Referencelar
Pointerlari bo'lgan tillarda, dangling pointerni - xotiradagi boshqa birovga berilgan bo'lishi mumkin bo'lgan joyga reference qiluvchi pointerni - bu xotiraga pointerni saqlab qolgan holda, xotirani biroz bo'shatish orqali yaratish oson. Rust-da, aksincha, kompilyator referencelar hech qachon dangling referencelar bo'lmasligini kafolatlaydi: agar sizda ba'zi ma'lumotlarga reference bo'lsa, kompilyator ma'lumotlarga referencedan oldin ma'lumotlar doirasi tashqariga chiqmasligini ta'minlaydi.
Keling, Rust ularni kompilyatsiya vaqtida xatosi bilan qanday oldini olishini ko'rish uchun dangling reference yaratishga harakat qilaylik:
Fayl nomi: src/main.rs
fn main() {
let dangle_reference = dangle();
}
fn dangle() -> &String {
let s = String::from("salom");
&s
}Mana xato:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0106]: missing lifetime specifier
--> src/main.rs:5:16
|
5 | fn dangle() -> &String {
| ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but there is no value for it to be borrowed from
help: consider using the `'static` lifetime
|
5 | fn dangle() -> &'static String {
| +++++++
For more information about this error, try `rustc --explain E0106`.
error: could not compile `ownership` due to previous error
Ushbu xato xabari biz hali ko'rib chiqmagan xususiyatga ishora qiladi: lifetime. Biz 10-bobda lifetime batafsil muhokama qilamiz. Ammo, agar siz lifetime haqidagi qismlarga e'tibor bermasangiz, xabarda ushbu kod nima uchun muammo ekanligining kaliti mavjud:
this function's return type contains a borrowed value, but there is no value
for it to be borrowed from
Keling, dangle kodimizning har bir bosqichida nima sodir bo'layotganini batafsil ko'rib chiqaylik:
Fayl nomi: src/main.rs
fn main() {
let dangle_reference = dangle();
}
fn dangle() -> &String { // dangle Stringga referencei qaytaradi
let s = String::from("salom"); // s - yangi String
&s // biz Stringga referenceni return qilamiz, s
} // Bu yerda s scopedan chiqib ketadi va drop qilinadi. Uning xotirasi yo'qoladi.
// Xavf!s dangle ichida yaratilganligi sababli, dangle kodi tugagach, s ajratiladi. Ammo biz unga referenceni qaytarishga harakat qildik. Bu shuni anglatadiki, bu reference yaroqsiz Stringga ishora qiladi. Bu yaxshi emas! Rust bizga buni qilishga ruxsat bermaydi.
Bu yerda yechim to'g'ridan-to'g'ri String ni return qilishdir:
fn main() { let string = dangle_yoq(); } fn dangle_yoq() -> String { let s = String::from("salom"); s }
Bu hech qanday muammosiz ishlaydi. Ownership boshqa joyga ko'chiriladi va hech narsa ajratilmaydi.
Reference Qoidalari
Keling, referencelar haqida nimalarni muhokama qilganimizni takrorlaymiz:
- Istalgan vaqtda siz yoki bitta oʻzgaruvchan referencega yoki istalgan miqdordagi oʻzgarmas referencelarga ega boʻlishingiz mumkin.
- Referencelar har doim yaroqli bo'lishi kerak.
Keyinchalik, biz boshqa turdagi referenceni ko'rib chiqamiz: slicelar.
Slice turi
Slicelar butun to'plamga emas, balki to'plamdagi elementlarning qo'shni ketma-ketligiga murojaat qilish imkonini beradi. Slice bir xil referencedir, shuning uchun u ownershipga ega emas.
Bu yerda kichik dasturlash muammosi: bo'shliqlar bilan ajratilgan so'zlar qatorini oladigan va shu qatorda topilgan birinchi so'zni qaytaradigan funksiya yozing. Agar funksiya satrda bo'sh joy topmasa, butun satr bitta so'zdan iborat bo'lishi kerak, shuning uchun butun satr qaytarilishi kerak.
Keling, slicelar hal qiladigan muammoni tushunish uchun ushbu funksiyaning imzosini slicelardan foydalanmasdan qanday yozishni ko'rib chiqaylik:
fn birinchi_soz(s: &String) -> ?birinchi_soz funksiyasi parametr sifatida &String ga ega. Biz ownershiplik qilishni xohlamaymiz, shuning uchun bu yaxshi. Ammo biz nimani return qilishimiz kerak? Bizda satrning qismi haqida gapirishning metodi yo'q. Biroq, biz bo'sh joy bilan ko'rsatilgan so'z oxiri indeksini qaytarishimiz mumkin. 4-7 ro'yxatda ko'rsatilganidek, buni sinab ko'raylik.
Fayl nomi: src/main.rs
fn birinchi_soz(s: &String) -> usize { let bayt = s.as_bytes(); for (i, &item) in bayt.iter().enumerate() { if item == b' ' { return i; } } s.len() } fn main() {}
Ro'yxat 4-7: String parametriga bayt indeks qiymatini qaytaradigan birinchi_soz funksiyasi
Biz String elementini element bo'yicha ko'rib chiqishimiz va qiymat bo'sh joy yoki yo'qligini tekshirishimiz kerakligi sababli, as_bytes metodi yordamida Stringni baytlar arrayiga aylantiramiz.
fn birinchi_soz(s: &String) -> usize {
let bayt = s.as_bytes();
for (i, &item) in bayt.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}Keyinchalik, iter metodi yordamida baytlar arrayida iterator yaratamiz:
fn birinchi_soz(s: &String) -> usize {
let bayt = s.as_bytes();
for (i, &item) in bayt.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}Biz iteratorlarni 13-bobda batafsilroq muhokama qilamiz.
Hozircha bilingki, iter to‘plamdagi har bir elementni return qiladigan va enumerate iter natijasini o‘rab, har bir elementni tuplening bir qismi sifatida return qiladigan metoddir. enumerate dan qaytarilgan tuplening birinchi elementi indeks, ikkinchi element esa elementga referencedir.
Bu indeksni o'zimiz hisoblashdan ko'ra biroz qulayroqdir.
enumerate metodi tupleni qaytarganligi sababli, biz ushbu tupleni destructure qilish uchun patternlardan foydalanishimiz mumkin. Biz 6-bobda patternlarni ko'proq muhokama qilamiz. for siklida biz tupledagi indeks uchun i va bitta bayt uchun &element ga ega bo‘lgan patternni belgilaymiz.
Biz .iter().enumerate() dan elementga referenceni olganimiz uchun biz patternda & dan foydalanamiz.
for sikli ichida biz bayt literal sintaksisidan foydalanib, bo'sh joyni ifodalovchi baytni qidiramiz. Agar bo'sh joy topsak, biz pozitsiyani return qilamiz.
Aks holda, s.len() yordamida satr uzunligini qaytaramiz.
fn birinchi_soz(s: &String) -> usize {
let bayt = s.as_bytes();
for (i, &item) in bayt.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}Endi bizda satrdagi birinchi so'zning oxirgi indeksini aniqlashning metodi bor, ammo muammo bor. Biz usize ni o'z-o'zidan qaytarmoqdamiz, lekin bu &String kontekstida faqat meaningful raqam. Boshqacha qilib aytadigan bo'lsak, bu String dan alohida qiymat bo'lganligi sababli, uning kelajakda ham amal qilishiga kafolat yo'q. Ro'yxat 4-8da 4-7 ro'yxatdagi birinchi_soz funksiyasidan foydalanadigan dasturni ko'rib chiqing.
Fayl nomi: src/main.rs
fn birinchi_soz(s: &String) -> usize { let baytlar = s.as_bytes(); for (i, &item) in baytlar.iter().enumerate() { if item == b' ' { return i; } } s.len() } fn main() { let mut s = String::from("hello world"); let soz = birinchi_soz(&s); // soz 5 qiymatini oladi s.clear(); // bu Stringni bo'shatib, uni "" ga tenglashtiradi // soz hali ham bu erda 5 qiymatiga ega, ammo biz 5 qiymatini meaningfull ishlatishimiz // mumkin bo'lgan boshqa qator yo'q. soz endi mutlaqo yaroqsiz! }
Ro'yxat 4-8: birinchi_soz funksiyasini chaqirish natijasida olingan natijani saqlash va keyin String tarkibini o'zgartirish
Bu dastur hech qanday xatosiz kompilyatsiya qiladi va agar biz s.clear() ga murojat qilgandan keyin soz ishlatgan bo'lsak ham shunday bo'lardi. Chunki soz s holatiga umuman bog‘lanmagan, soz hali ham 5 qiymatini o‘z ichiga oladi. Birinchi so‘zni chiqarish uchun biz ushbu 5 qiymatini s o‘zgaruvchisi bilan ishlatishimiz mumkin, ammo bu xato bo‘lishi mumkin, chunki sozda 5 ni saqlaganimizdan so‘ng s tarkibi o‘zgargan.
soz da indeksning s dagi ma'lumotlar bilan muvofiqligi yo‘qolishidan xavotir olish juda zerikarli va xatoga yo‘l qo‘yishga moyil! Agar biz ikkinchi_soz funksiyasini yozsak, bu indekslarni boshqarish yanada mo'rt bo'ladi. Uning signaturesi quyidagicha ko'rinishi kerak:
fn ikkinchi_soz(s: &String) -> (usize, usize) {Endi biz boshlang'ich va tugash indeksini kuzatmoqdamiz va bizda ma'lum bir holatdagi ma'lumotlardan hisoblangan, ammo bu holatga umuman bog'liq bo'lmagan ko'proq qiymatlar mavjud. Bizda bir-biriga bog'liq bo'lmagan uchta o'zgaruvchi mavjud bo'lib, ular sinxronlashtirilishi kerak.
Yaxshiyamki, Rust bu muammoni hal qildi: string slicelar.
String Slicelar
string slice String qismiga reference boʻlib, u quyidagicha koʻrinadi:
fn main() { let s = String::from("salom duno"); let salom = &s[0..5]; let dunyo = &s[6..11]; }
Butun Stringga reference oʻrniga salom qoʻshimcha [0..5] bitida koʻrsatilgan String qismiga referencedir. Biz [starting_index..ending_index] ni belgilash orqali qavslar ichidagi diapazondan foydalangan holda slicelarni yaratamiz, bu yerda starting_index bo'limdagi birinchi pozitsiyadir va ending_index slicedagi oxirgi pozitsiyadan bittaga ko'p. Ichkarida, slice ma'lumotlar tuzilmasi ending_index minus starting_index ga mos keladigan boshlang'ich pozitsiyasini va slice uzunligini saqlaydi. Demak, let dunyo = &s[6..11]; holatida dunyo so'zi s ning 6 indeksidagi baytga ko‘rsatgichni o‘z ichiga olgan bo‘lak bo‘lib, uzunligi 5 ga teng bo‘ladi.
4-6-rasmda bu diagrammada ko'rsatilgan.
4-6-rasm: Stringning bir qismiga referal qiluvchi String slice
Rustning .. diapazoni sintaksisi bilan, agar siz 0 indeksidan boshlamoqchi bo'lsangiz, qiymatni ikki davr oldidan tushirishingiz mumkin. Boshqacha qilib aytganda, ular tengdir:
#![allow(unused)] fn main() { let s = String::from("salom"); let slice = &s[0..2]; let slice = &s[..2]; }
Xuddi shu qoidaga ko'ra, agar sizning slicesingiz String ning oxirgi baytini o'z ichiga olgan bo'lsa, siz keyingi raqamni qo'yishingiz mumkin. Bu shuni anglatadiki, ular tengdir:
#![allow(unused)] fn main() { let s = String::from("salom"); let uzunlik = s.len(); let slice = &s[3..uzunlik]; let slice = &s[3..]; }
Shuningdek, butun satrning bir qismini olish uchun ikkala qiymatni ham tashlab qo'yishingiz mumkin. Shunday qilib, ular teng:
#![allow(unused)] fn main() { let s = String::from("salom"); let uzunlik = s.len(); let slice = &s[0..uzunlik]; let slice = &s[..]; }
Eslatma: String diapazoni indekslari yaroqli UTF-8 belgilar chegaralarida bo'lishi kerak. Agar siz ko'p baytli belgi o'rtasida string slice yaratishga harakat qilsangiz, dasturingiz xato bilan chiqadi. String slicelarini kiritish uchun biz faqat ushbu bo'limda ASCII ni qabul qilamiz; UTF-8 bilan ishlash bo'yicha batafsilroq muhokama 8-bobning ”UTF-8 kodlangan matnni satrlar bilan saqlash” bo'limida keltirilgan.
Ushbu ma'lumotlarning barchasini hisobga olgan holda, sliceni qaytarish uchun birinchi_soz ni qayta yozamiz. “String slice”ni bildiruvchi tur &str sifatida yoziladi:
Fayl nomi: src/main.rs
fn birinchi_soz(s: &String) -> &str { let baytlar = s.as_bytes(); for (i, &item) in baytlar.iter().enumerate() { if item == b' ' { return &s[0..i]; } } &s[..] } fn main() {}
Biz so'z oxiri indeksini 4-7 ro'yxatdagi kabi bo'shliqning birinchi marta paydo bo'lishini qidirib olamiz. Bo'shliqni topganimizda, satrning boshi va bo'sh joy indeksidan boshlang'ich va yakuniy indekslar sifatida foydalanib, satr bo'lagini qaytaramiz.
Endi biz birinchi_soz ni chaqirganimizda, biz asosiy ma'lumotlarga bog'langan bitta qiymatni olamiz. Qiymat slicening boshlang'ich nuqtasiga va bo'limdagi elementlar soniga referencedan iborat.
Sliceni return qilish ikkinchi_soz funksiyasi uchun ham ishlaydi:
fn ikkinchi_soz(s: &String) -> &str {Endi bizda oddiy API mavjud, uni buzish ancha qiyin, chunki kompilyator String ga referencelar haqiqiyligini ta'minlaydi. 4-8 ro'yxatdagi dasturdagi xatoni eslaysizmi, biz indeksni birinchi so'zning oxirigacha olib, keyin qatorni o'chirib tashlaganimizda, indeksimiz yaroqsiz edi? Bu kod mantiqan noto'g'ri edi, lekin darhol xatoliklarni ko'rsatmadi. Agar biz birinchi so'z indeksini bo'shatilgan qator bilan ishlatishga harakat qilsak, muammolar keyinroq paydo bo'ladi. Slicelar bu xatoni imkonsiz qiladi va kodimiz bilan bog'liq muammo borligini bizga tezroq bildiradi. birinchi_soz slice versiyasidan foydalanish kompilyatsiya vaqtida xatolikka olib keladi:
Fayl nomi: src/main.rs
fn birinchi_soz(s: &String) -> &str {
let baytlar = s.as_bytes();
for (i, &item) in baytlar.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let mut s = String::from("salom dunyo");
let soz = birinchi_soz(&s);
s.clear(); // error!
println!("birinchi so'z: {}", soz);
}Mana kompilyator xatosi:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:18:5
|
16 | let soz = birinchi_soz(&s);
| -- immutable borrow occurs here
17 |
18 | s.clear(); // error!
| ^^^^^^^^^ mutable borrow occurs here
19 |
20 | println!("birinchi so'z: {}", soz);
| ---- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `ownership` due to previous error
Borrowing qoidalarini eslang, agar bizda biror narsaga o'zgarmas reference bo'lsa, biz o'zgaruvchan referenceni ham qabul qila olmaymiz. Chunki clear Stringni qisqartirishi kerak, u o'zgaruvchan referenceni olishi kerak. clear chaqiruvidan keyingi println! soz dagi referencedan foydalanadi, shuning uchun o‘zgarmas reference shu nuqtada faol bo‘lishi kerak. Rust bir vaqtning o'zida clear va soz dagi o'zgarmas referenceni bir vaqtning o'zida mavjud bo'lishiga yo'l qo'ymaydi va kompilyatsiya bajarilmaydi. Rust nafaqat API-dan foydalanishni osonlashtirdi, balki kompilyatsiya vaqtidagi xatolarning butun sinfini ham yo'q qildi!
String literallar Slice sifatida
Eslatib o'tamiz, biz binary tizimda saqlanadigan string literallari haqida gapirgan edik. Endi biz slicelar haqida bilganimizdan so'ng, biz string literallarini to'g'ri tushunishimiz mumkin:
#![allow(unused)] fn main() { let s = "Hello, world!"; }
Bu erda s turi &str: bu binary faylning o'ziga xos nuqtasiga ishora qiluvchi slice. Shu sababli ham string literallari o'zgarmasdir; &str - o'zgarmas reference.
Parametrlar sifatida String Slicelar
Siz literal va String qiymatlarini olish mumkinligini bilish bizni birinchi_sozni yana bir takomillashtirishga olib keladi va bu uning signaturesi:
fn birinchi_soz(s: &String) -> &str {Tajribali Rustacean buni o'rniga 4-9 ro'yxatda ko'rsatilgan signatureni yozadi, chunki bu bizga &String qiymatlari va &str qiymatlarida bir xil funksiyadan foydalanishga imkon beradi.
fn birinchi_soz(s: &str) -> &str {
let baytlar = s.as_bytes();
for (i, &item) in baytlar.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let mening_stringim = String::from("hello world");
// `birinchi_soz` `String` ning qisman yoki to'liq slicelarida ishlaydi
let soz = birinchi_soz(&mening_stringim[0..6]);
let soz = birinchi_soz(&mening_stringim[..]);
// `birinchi_soz`, shuningdek, `String` ning butun slicelariga ekvivalent bo`lgan
// `String`-ga referencelar ustida ham ishlaydi.
let soz = birinchi_soz(&mening_stringim);
let mening_literal_stringim = "hello world";
// `birinchi_soz` qisman yoki to'liq bo'lgan string literallari slicelarida ishlaydi
let soz = birinchi_soz(&mening_literal_stringim [0..6]);
let soz = birinchi_soz(&mening_literal_stringim [..]);
// String literallari allaqachon string slicelari bo'lganligi sababli,
// bu slice sintaksisisiz ham ishlaydi!
let soz = birinchi_soz(mening_literal_stringim );
}Ro'yxat 4-9: birinchi_soz funksiyasini s parametri turi uchun string slicedan foydalanish orqali yaxshilash
Agar bizda string slice bo'lsa, biz uni to'g'ridan-to'g'ri o'tkazishimiz mumkin. Agar bizda String bo'lsa, biz String slicesini yoki String ga referenceni o'tkazishimiz mumkin. Ushbu moslashuvchanlik deref coercionlari dan foydalanadi, bu xususiyatni biz 15-bobning “Funktsiyalar va metodlar bilan Implicit Deref Coercionlari” da ko‘rib chiqamiz.
String ga reference o‘rniga string sliceni olish funksiyasini belgilash bizning API’ni hech qanday funksionallikni yo‘qotmasdan umumiyroq va foydali qiladi:
Fayl nomi: src/main.rs
fn birinchi_soz(s: &str) -> &str { let baytlar = s.as_bytes(); for (i, &item) in baytlar.iter().enumerate() { if item == b' ' { return &s[0..i]; } } &s[..] } fn main() { let mening_stringim = String::from("hello world"); // `birinchi_soz` `String` ning qisman yoki to'liq slicelarida ishlaydi let soz = birinchi_soz(&mening_stringim[0..6]); let soz = birinchi_soz(&mening_stringim[..]); // `birinchi_soz`, shuningdek, `String` ning butun slicelariga ekvivalent bo`lgan // `String`-ga referencelar ustida ham ishlaydi. let soz = birinchi_soz(&mening_stringim); let mening_literal_stringim = "hello world"; // `birinchi_soz` qisman yoki to'liq bo'lgan string literallari slicelarida ishlaydi let soz = birinchi_soz(&mening_literal_stringim [0..6]); let soz = birinchi_soz(&mening_literal_stringim [..]); // String literallari allaqachon string slicelari bo'lganligi sababli, // bu slice sintaksisisiz ham ishlaydi! let soz = birinchi_soz(mening_literal_stringim ); }
Boshqa Slicelar
String slicelari, siz tasavvur qilganingizdek, stringlarga xosdir. Ammo yana umumiy slice turi ham bor. Ushbu arrayni ko'rib chiqing:
#![allow(unused)] fn main() { let a = [1, 2, 3, 4, 5]; }
Xuddi biz satrning bir qismiga murojaat qilishni xohlaganimizdek, arrayning bir qismiga murojaat qilishni xohlashimiz mumkin. Biz shunday qilamiz:
#![allow(unused)] fn main() { let a = [1, 2, 3, 4, 5]; let slice = &a[1..3]; assert_eq!(slice, &[2, 3]); }
Ushbu slice &[i32] turiga ega. U birinchi element va uzunlikka referenceni saqlash orqali string slicelari kabi ishlaydi. Siz boshqa barcha turdagi to'plamlar uchun bunday slicedan foydalanasiz. 8-bobda vektorlar haqida gapirganda, biz ushbu to'plamlarni batafsil muhokama qilamiz.
Xulosa
Ownership, borrowing va slicelar tushunchalari kompilyatsiya vaqtida Rust dasturlarida xotira xavfsizligini ta'minlaydi. Rust tili sizga boshqa tizim dasturlash tillari kabi xotiradan foydalanishni boshqarish imkonini beradi, lekin egasi amal qilish doirasidan chiqib ketganda maʼlumotlar egasi avtomatik ravishda ushbu maʼlumotlarni tozalaydi, bu boshqaruvni olish uchun qoʻshimcha kod yozish va debug qilish shart emasligini anglatadi.
Ownership Rustning boshqa ko'plab qismlari qanday ishlashiga ta'sir qiladi, shuning uchun biz bu tushunchalar haqida kitobning qolgan qismida batafsilroq gaplashamiz. Keling, 5-bobga o'tamiz va ma'lumotlar bo'laklarini structda birga guruhlashni ko'rib chiqamiz.
Tegishli ma'lumotlarni tuzish uchun Structlardan foydalanish
struct - foydalanuvchi tomonidan belgilangan ma'lumotlar turi bo'lib, u sizga mantiqiy va mantiqiy guruhni tashkil etuvchi bir nechta tegishli qiymatlarni nomlash va to'plash imkonini beradi. Agar siz obyektga yo'naltirilgan til bilan tanish bo'lsangiz, struct obyektning ma'lumotlar atributlariga o'xshaydi. Ushbu bobda biz tuplelarni structlar bilan solishtiramiz va o'zingiz bilgan narsalarga asoslaymiz va qachon structlar ma'lumotlarni guruhlashning eng yaxshi usuli ekanligini ko'rsatamiz.
Biz structlarni qanday aniqlash va yaratishni ko'rsatamiz. Struct turi bilan bog'liq xatti-harakatni belgilash uchun bog'langan funksiyalarni, ayniqsa methodlar deb ataladigan bog'langan funksiyalarni qanday aniqlashni muhokama qilamiz. Structlar va enumlar (6-bobda muhokama qilingan) dastur domenida yangi turlarni yaratish uchun building block hisoblanadi. Ular sizga Rustning kompilyatsiya vaqti turini tekshirish imkoniyatlaridan to'liq foydalanish imkonini beradi.
Structlarni aniqlash va yaratish
Structlar “Tuple turi“ bo'limida muhokama qilingan tuplelarga o'xshaydi, chunki ikkalasi ham bir-biriga bog'liq bo'lgan bir nechta qiymatlarga ega. Tuplelar singari, structning qismlari ham har xil turdagi bo'lishi mumkin. Tuplelardan farqli o'laroq, structda siz har bir ma'lumot qismini nomlaysiz, shunda qiymatlar nimani anglatishini tushunasiz. Ushbu nomlarni qo'shish structlar tuplelardan ko'ra moslashuvchanroq ekanligini anglatadi: misol qiymatlarini belgilash yoki ularga kirish uchun ma'lumotlar tartibiga ishonishingiz shart emas.
Structni aniqlash uchun biz struct kalit so`zini kiritamiz va butun tuzilishga nom beramiz. Struct nomi birgalikda guruhlangan ma'lumotlar bo'laklarining ahamiyatini tavsiflashi kerak. Keyin, jingalak qavslar ichida biz maydonlar deb ataydigan ma'lumotlar qismlarining nomlari va turlarini aniqlaymiz. Masalan, 5-1 ro'yxati foydalanuvchi hisobi haqidagi ma'lumotlarni saqlaydigan structni ko'rsatadi.
Fayl nomi: src/main.rs
struct Foydalanuvchi { faollik: bool, foydalanuvchi: String, email: String, kirish_hisobi: u64, } fn main() {}
Ro'yxat 5-1: Foydalanuvchi structi ta'rifi
Struct aniqlangandan so'ng, tegishli ma'lumotlar turiga ega bo'lgan har bir maydonga ma'lum bir qiymat berish orqali uni yaratish mumkin. Biz structning nomini ko'rsatish orqali misol yaratamiz va keyin kalit: qiymat(key: value) juftlarini o'z ichiga olgan jingalak qavslarni qo'shamiz, bu erda kalitlar maydonlarning nomlari va qiymatlar biz o'sha maydonlarda saqlamoqchi bo'lgan ma'lumotlardir.Biz maydonlarni structda e'lon qilgan tartibda ko'rsatishimiz shart emas. Boshqacha qilib aytganda, structning ta'rifi tur uchun umumiy shablonga o'xshaydi va misollar tur qiymatlarini yaratish uchun ushbu shablonni ma'lum ma'lumotlar bilan to'ldiradi. Misol uchun, biz 5-2 ro'yxatda ko'rsatilganidek, ma'lum bir foydalanuvchini e'lon qilishimiz mumkin.
Fayl nomi: src/main.rs
struct Foydalanuvchi { faollik: bool, foydalanuvchi: String, email: String, kirish_hisobi: u64, } fn main() { let foydalanuvchi1 = Foydalanuvchi { faollik: true, foydalanuvchi: String::from("ismoilovdev"), email: String::from("ismoilovdev@example.com"), kirish_hisobi: 1, }; }
Ro'yxat 5-2: Foydalanuvchi nusxasini yaratish
structi
Structdan ma'lum bir qiymat olish uchun biz nuqta belgilaridan foydalanamiz. Masalan, ushbu foydalanuvchining elektron pochta manziliga kirish uchun biz foydalanuvchi1.email dan foydalanamiz. Agar misol o'zgaruvchan bo'lsa, biz nuqta belgisi yordamida qiymatni o'zgartirishimiz va ma'lum bir maydonga belgilashimiz mumkin. 5-3 ro'yxatda o'zgaruvchan Foydalanuvchi misolining email maydonidagi qiymatni qanday o'zgartirish mumkinligi ko'rsatilgan.
Fayl nomi: src/main.rs
struct Foydalanuvchi { faollik: bool, foydalanuvchi: String, email: String, kirish_hisobi: u64, } fn main() { let foydalanuvchi1 = Foydalanuvchi { faollik: true, foydalanuvchi: String::from("ismoilovdev"), email: String::from("ismoilovdev@example.com"), kirish_hisobi: 1, }; foydalanuvchi1.email = String::from("asilbek@example.com"); }
Ro'yxat 5-3: Foydalanuvchi misolining email maydonidagi qiymatni o'zgartirish
E'tibor bering, butun misol o'zgaruvchan bo'lishi kerak; Rust bizga faqat ma'lum maydonlarni o'zgaruvchan deb belgilashga ruxsat bermaydi. Har qanday ifodada bo'lgani kabi, biz ushbu yangi misolni bilvosita qaytarish uchun funksiya tanasidagi oxirgi ifoda sifatida structning yangi nusxasini qurishimiz mumkin.
5-4 roʻyxatda berilgan email va foydalanuvchi nomi bilan Foydalanuvchi misolini qaytaruvchi foydalanuvchi_yaratish funksiyasi koʻrsatilgan. faollik maydoni true qiymatini, kirish_hisobi esa 1 qiymatini oladi.
Fayl nomi: src/main.rs
struct Foydalanuvchi { faollik: bool, foydalanuvchi: String, email: String, kirish_hisobi: u64, } fn foydalanuvchi_yaratish(email: String, foydalanuvchi: String) -> Foydalanuvchi { Foydalanuvchi { faollik: true, foydalanuvchi: foydalanuvchi, email: email, kirish_hisobi: 1, } } fn main() { let foydalanuvchi1 = foydalanuvchi_yaratish( String::from("ismoilovdev@example.com"), String::from("ismoilovdev"), ); }
Roʻyxat 5-4: foydalanuvchi_yaratish funksiyasi email va foydalanuvchi nomini oladi va Foydalanuvchi misolini qaytaradi
Funksiya parametrlarini struct maydonlari bilan bir xil nom bilan nomlash mantiqan to‘g‘ri keladi, lekin email va foydalanuvchi maydon nomlari va o‘zgaruvchilarini takrorlash biroz zerikarli. Agar structda ko'proq maydonlar bo'lsa, har bir nomni takrorlash yanada zerikarli bo'ladi. Yaxshiyamki, qulay Shorthand bor!
Field Init Shorthandan foydalanish
Parametr nomlari va struct maydonlarining nomlari 5-4 ro'yxatda aynan bir xil bo'lgani uchun, foydalanuvchi_yaratishni qayta yozish uchun init shorthand sintaksisidan foydalanishimiz mumkin, shuning uchun u xuddi shunday ishlaydi, lekin foydalanuvchi va emailni takrorlamaydi, 5-5 ro'yxatda ko'rsatilganidek.
Fayl nomi: src/main.rs
struct Foydalanuvchi { faollik: bool, foydalanuvchi: String, email: String, kirish_hisobi: u64, } fn foydalanuvchi_yaratish(email: String, foydalanuvchi: String) -> Foydalanuvchi { Foydalanuvchi { faollik: true, foydalanuvchi, email, kirish_hisobi: 1, } } fn main() { let foydalanuvchi1 = foydalanuvchi_yaratish( String::from("ismoilovdev@example.com"), String::from("ismoilovdev"), ); }
Roʻyxat 5-5: foydalanuvchi va email parametrlari struct maydonlari bilan bir xil nomga ega boʻlgani uchun init shorthanddan foydalanadigan foydalanuvchi_yaratish funksiyasi
Bu yerda biz Foydalanuvchi structining yangi nusxasini yaratmoqdamiz, unda email deb nomlangan maydon mavjud. Biz email maydonining qiymatini foydalanuvchi_yaratish funksiyasining email parametridagi qiymatga o‘rnatmoqchimiz. email maydoni va email parametri bir xil nomga ega bo'lgani uchun biz email: email emas, balki email yozishimiz kerak.
Structni update sintaksisidan foydalanib, boshqa tuzilma nusxasidan tuzilma namunasini yaratish
Ko'pincha boshqa namunadagi qiymatlarning ko'pini o'z ichiga olgan, lekin ularning ba'zilarini o'zgartiradigan structning yangi nusxasini yaratish foydali bo'ladi. Buni struct update sintaksisi yordamida amalga oshirishingiz mumkin.
Birinchidan, 5-6 ro'yxatda biz yangilanish sintaksisisiz muntazam ravishda foydalanuvchi2 da yangi Foydalanuvchi misolini qanday yaratishni ko'rsatamiz. Biz email uchun yangi qiymat o‘rnatdik, lekin aks holda 5-2 ro‘yxatda yaratgan foydalanuvchi1 qiymatidan foydalanamiz.
Fayl nomi: src/main.rs
struct Foydalanuvchi { faollik: bool, foydalanuvchi: String, email: String, kirish_hisobi: u64, } fn main() { // --snip-- let foydalanuvchi1 = Foydalanuvchi { email: String::from("ismoilovdev@example.com"), foydalanuvchi: String::from("ismoilovdev"), faollik: true, kirish_hisobi: 1, }; let foydalanuvchi2 = Foydalanuvchi { faollik: foydalanuvchi1.faollik, foydalanuvchi: foydalanuvchi1.foydalanuvchi, email: String::from("asilbek@example.com"), kirish_hisobi: foydalanuvchi1.kirish_hisobi, }; }
Roʻyxat 5-6: foydalanuvchi1 qiymatlaridan biri yordamida yangi Foydalanuvchi namunasini yaratish
Strukturani yangilash sintaksisidan foydalanib, biz 5-7 ro'yxatda ko'rsatilganidek, kamroq kod bilan bir xil effektga erishishimiz mumkin. .. sintaksisi qolgan maydonlar aniq o'rnatilganligini va belgilangan namunadagi qiymatlarga ega bo'lishi kerakligini ko'rsatadi.
Fayl nomi: src/main.rs
struct Foydalanuvchi { faollik: bool, foydalanuvchi: String, email: String, kirish_hisobi: u64, } fn main() { // --snip-- let foydalanuvchi1 = Foydalanuvchi { email: String::from("ismoilovdev@example.com"), foydalanuvchi: String::from("ismoilovdev"), faollik: true, kirish_hisobi: 1, }; let foydalanuvchi2 = Foydalanuvchi { email: String::from("asilbek@example.com"), ..foydalanuvchi1 }; }
Ro'yxat 5-7: Foydalanuvchi misoli uchun yangi email qiymatini o'rnatish, lekin foydalanuvchi1 dagi qolgan qiymatlardan foydalanish uchun structni yangilash sintaksisidan foydalanish
5-7 roʻyxatdagi kod foydalanuvchi2 da email uchun boshqa qiymatga ega, lekin foydalanuvchi1 dan foydalanuvchi, faollik va kirish_hisobi maydonlari uchun bir xil qiymatlarga ega boʻlgan misol yaratadi. ..foydalanuvchi1 qolgan maydonlar o‘z qiymatlarini foydalanuvchi1 dagi tegishli maydonlardan olishi kerakligini ko‘rsatish uchun oxirgi o‘rinda turishi kerak, lekin biz istalgan tartibda xohlagancha ko'p maydonlar uchun qiymatlarni belgilashni tanlashimiz mumkin, strukturaning ta'rifidagi maydonlar tartibidan qat'i nazar.
E'tibor bering, strukturani yangilash sintaksisi topshiriq kabi = dan foydalanadi; Buning sababi, biz ”O'zgaruvchilar va ma'lumotlarni ko'chirish bilan o'zaro ta'sir qilish” bo'limida ko'rganimizdek, u ma'lumotlarni harakatlantiradi. Ushbu misolda biz foydalanuvchi2 ni yaratganimizdan keyin foydalanuvchi1 dan bir butun sifatida foydalana olmaymiz, chunki foydalanuvchi1ning foydalanuvchi maydonidagi String foydalanuvchi2 ga koʻchirilgan. Agar biz foydalanuvchi2 ga email va foydalanuvchi uchun yangi String qiymatlarini bergan bo‘lsak va shuning uchun foydalanuvchi1dan faqat faollik va kirish_hisobi qiymatlarini ishlatgan bo‘lsak, keyin foydalanuvchi1 foydalanuvchi2 yaratilgandan keyin ham amal qiladi. faollik va kirish_hisobi turlari nusxa ko'chirish xususiyatini amalga oshiradigan turlardir, shuning uchun biz ”Stek ma'lumotlari: Nusxalash” bo'limida muhokama qilgan xatti-harakatlar qo'llaniladi.
Har xil turlarni yaratish uchun nomli maydonlarsiz tuplelardan foydalanish
Rust shuningdek, tuple structlar deb ataladigan tuplelarga o'xshash structlarni qo'llab-quvvatlaydi. Tuple structlari struct nomi taqdim etadigan qo'shimcha ma'noga ega, ammo ularning maydonlari bilan bog'langan nomlari yo'q; aksincha, ular faqat maydonlarning turlariga ega. Tuple structlari butun tuplega nom berish va tupleni boshqa tuplelardan farqli turga aylantirish zarur bo‘lganda foydali bo‘ladi va har bir maydonni oddiy structdagi kabi nomlashda batafsil yoki ortiqcha bo‘ladi.
Tuple structini aniqlash uchun struct kalit so‘zi va struct nomidan keyin tupledagi turlardan boshlang. Masalan, bu yerda biz Rang va Nuqta nomli ikkita tuple structini aniqlaymiz va foydalanamiz:
Fayl nomi: src/main.rs
struct Rang(i32, i32, i32); struct Nuqta(i32, i32, i32); fn main() { let qora = Rang(0, 0, 0); let kelib_chiqishi = Nuqta(0, 0, 0); }
Esda tutingki, qora va kelib_chiqishi qiymatlari har xil turdagi, chunki ular turli xil tuple structlarining namunalaridir. Structdagi maydonlar bir xil turlarga ega bo'lishi mumkin bo'lsa ham, siz belgilagan har bir struct o'z turiga ega. Masalan, Rang turidagi parametrni qabul qiladigan funksiya, har ikkala tur ham uchta i32 qiymatidan iborat bo‘lsa ham, Nuqtani argument sifatida qabul qila olmaydi. Aks holda, tuple structi namunalari tupelarga o'xshaydi, chunki siz ularni alohida qismlarga ajratishingiz mumkin va individual qiymatga kirish uchun . va keyin indeksdan foydalanishingiz mumkin.
Hech qanday maydonsiz unit kabi structlar
Shuningdek, siz hech qanday maydonga ega bo'lmagan structlarni belgilashingiz mumkin! Ular unita o'xshash structlar deb ataladi, chunki ular biz ”Tuple turi” bo'limida aytib o'tgan unit turiga () o'xshash harakat qiladilar. Unitga o'xshash structlar qaysidir turdagi traitni qo'llash kerak bo'lganda foydali bo'lishi mumkin, ammo sizda turning o'zida saqlash uchun ma'lumotlaringiz yo'q. Traitlarni 10-bobda muhokama qilamiz. Mana AlwaysEqual nomli unit structini e’lon qilish va instantsiyalash misoli:
Fayl nomi: src/main.rs
struct AlwaysEqual; fn main() { let subject = AlwaysEqual; }
AlwaysEqual ni aniqlash uchun biz struct kalit so'zidan, kerakli nomdan va keyin nuqta-verguldan foydalanamiz. Jingalak qavslar yoki qavslar kerak emas! Shunda biz subject o'zgaruvchisida AlwaysEqual misolini xuddi shunday tarzda olishimiz mumkin: biz belgilagan nomdan foydalanib, hech qanday jingalak qavs yoki qavslarsiz. Tasavvur qiling-a, keyinchalik biz ushbu turdagi xatti-harakatlarni shunday amalga oshiramizki, AlwaysEqual ning har bir nusxasi har doim boshqa turdagi har bir misolga teng bo'ladi, ehtimol sinov uchun ma'lum natijaga ega bo'lishi mumkin. Ushbu xatti-harakatni amalga oshirish uchun bizga hech qanday ma'lumot kerak emas! Traitlarni qanday aniqlash va ularni har qanday turdagi, shu jumladan unitga o'xshash structlarda amalga oshirishni 10-bobda ko'rasiz.
Strukturaviy ma'lumotlarga ownershiplik qilish
5-1 roʻyxatdagi
Foydalanuvchistructi taʼrifida biz&strstring slice turidan koʻra tegishliStringturidan foydalandik. Bu ataylab qilingan tanlov, chunki biz ushbu structning har bir nusxasi uning barcha maʼlumotlariga ega boʻlishini va bu maʼlumotlar butun struct amalda boʻlgunga qadar amal qilishini istaymiz.Structlar boshqa narsaga tegishli maʼlumotlarga referencelarni saqlashi ham mumkin, ammo buning uchun biz 10-bobda muhokama qiladigan Rust xususiyatidan lifetimelar foydalanishni talab qiladi. Lifetime struct tomonidan reference qilingan ma'lumotlar struct mavjud bo'lgunga qadar amal qilishini ta'minlaydi. Aytaylik, siz ma'lumotnomani lifetimeni ko'rsatmasdan structda saqlashga harakat qildingiz, quyidagi kabi; bu ishlamaydi:
Fayl nomi: src/main.rs
struct Foydalanuvchi { faollik: bool, foydalanuvchi: &str, email: &str, kirish_hisobi: u64, } fn main() { let foydalanuvchi1 = Foydalanuvchi { faollik: true, foydalanuvchi: "ismoilovdev", email: "ismoilovdev@example.com", kirish_hisobi: 1, }; }Kompilyator referencelarning lifetimeni aniqlash zarurati haqida shikoyat qiladi:
$ cargo run Compiling structs v0.1.0 (file:///projects/structs) error[E0106]: missing lifetime specifier --> src/main.rs:3:15 | 3 | foydalanuvchi: &str, | ^ expected named lifetime parameter | help: consider introducing a named lifetime parameter | 1 ~ struct Foydalanuvchi<'a> { 2 | faollik: bool, 3 ~ foydalanuvchi: &'a str, | error[E0106]: missing lifetime specifier --> src/main.rs:4:12 | 4 | email: &str, | ^ expected named lifetime parameter | help: consider introducing a named lifetime parameter | 1 ~ struct Foydalanuvchi<'a> { 2 | faollik: bool, 3 | foydalanuvchi: &str, 4 ~ email: &'a str, | For more information about this error, try `rustc --explain E0106`. error: could not compile `structs` due to 2 previous errors10-bobda biz ushbu xatolarni qanday tuzatishni muhokama qilamiz, shunda siz referencelarni structlarda saqlashingiz mumkin, ammo hozircha biz bu kabi xatolarni
&strkabi referencelar oʻrnigaStringkabi tegishli turlardan foydalanib tuzatamiz.
Structlar yordamida namunaviy dastur
Structlarni qachon ishlatishimiz mumkinligini tushunish uchun to'rtburchakning maydonini hisoblaydigan dastur yozaylik. Biz bitta o'zgaruvchilardan foydalanishni boshlaymiz, so'ngra uning o'rniga structlardan foydalanmagunimizcha dasturni qayta yaxshilab boramiz.
Keling, cargo bilan kvadratlar deb nomlangan yangi binary loyihani yarataylik, u piksellarda ko'rsatilgan to'rtburchakning kengligi va balandligini oladi va to'rtburchakning maydonini hisoblaydi. 5-8 ro'yxatda loyihaning src/main.rs faylida nima qilishimiz kerakligini aniq bajarishga imkon beradigan bitta qisqa kod ko'rsatilgan.
Fayl nomi: src/main.rs
fn main() { let kenglik1 = 30; let balandlik1 = 50; println!( "To'rtburchakning maydoni {} kvadrat piksel.", area(kenglik1, balandlik1) ); } fn area(kenglik: u32, balandlik: u32) -> u32 { kenglik * balandlik }
Ro'yxat 5-8: Alohida kenglik va balandlik o'zgaruvchilari bilan belgilangan to'rtburchaklar maydonini hisoblash
Endi ushbu dasturni cargo run yordamida ishga tushiring:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished dev [unoptimized + debuginfo] target(s) in 0.42s
Running `target/debug/rectangles`
To'rtburchakning maydoni 1500 kvadrat piksel.
Ushbu kod har bir o'lcham bilan area funksiyasini chaqirish orqali to'rtburchakning maydonini aniqlashga muvaffaq bo'ladi, ammo biz ushbu kodni aniq va o'qilishi uchun ko'proq narsani qilishimiz mumkin.
Ushbu kod bilan bog'liq muammo area signaturesida aniq ko'rinadi:
fn main() {
let kenglik1 = 30;
let balandlik1 = 50;
println!(
"To'rtburchakning maydoni {} kvadrat piksel.",
area(kenglik1, balandlik1)
);
}
fn area(kenglik: u32, balandlik: u32) -> u32 {
kenglik * balandlik
}area funksiyasi bitta to'rtburchakning maydonini hisoblashi kerak, lekin biz yozgan funksiya ikkita parametrga ega va bizning dasturimizning hech bir joyida parametrlar o'zaro bog'liqligi aniq emas. Kenglik va balandlikni birgalikda guruhlash yanada o'qilishi va boshqarilishi oson bo'lishi mumkin edi.3-bobning ”Tuple Turi” bo'limida biz buni amalga oshirishning bir usulini, ya'ni tuplelardan foydalanishni muhokama qildik.
Tuplelar yordamida Refaktoring
5-9 ro'yxatda tuplelardan foydalanadigan dasturimizning boshqa versiyasi ko'rsatilgan.
Fayl nomi: src/main.rs
fn main() { let kvadrat1 = (30, 50); println!( "To'rtburchakning maydoni {} kvadrat pikselga teng.", area(kvadrat1) ); } fn area(olchamlari: (u32, u32)) -> u32 { olchamlari.0 * olchamlari.1 }
Ro'yxat 5-9: To'rtburchakning kengligi va balandligini tuple yordamida aniqlash
Bir tomondan, bu dastur yaxshiroq. Tuplar bizga biroz struct qo'shishga imkon beradi va biz hozir faqat bitta argumentni keltiramiz. Ammo boshqa yo'l bilan, bu versiya unchalik aniq emas: tuplelar o'z elementlarini nomlamaydi, shuning uchun biz hisob-kitobimizni kamroq aniq qilib, tuple qismlariga indeks qilishimiz kerak.
Kenglik va balandlikni aralashtirish maydonni hisoblash uchun muhim emas, lekin agar biz ekranda to'rtburchak chizmoqchi bo'lsak, bu muhim bo'ladi! Shuni yodda tutishimiz kerakki, kenglik indeks 0 da, balandlik esa 1 indeksda. Agar kimdir bizning kodimizdan foydalansa, buni tushunish va yodda tutish qiyinroq bo'ladi. Kodimizda ma'lumotlarimizning ma'nosini yetkazmaganimiz sababli, endi xatolarni kiritish osonroq.
Struktuctlar bilan Refaktoring: ko'proq ma'no qo'shish
Biz ma'lumotlarni etiketlash orqali ma'no qo'shish uchun structlardan foydalanamiz. Biz foydalanayotgan tupleni 5-10 ro'yxatda ko'rsatilganidek, butun nomi bilan bir qatorda qismlar nomlari bilan tuzilishga aylantirishimiz mumkin.
Fayl nomi: src/main.rs
struct Kvadrat { kenglik: u32, balandlik: u32, } fn main() { let kvadrat1 = Kvadrat { kenglik: 30, balandlik: 50, }; println!( "To'rtburchakning maydoni {} kvadrat pikselga teng.", area(&kvadrat1) ); } fn area(kvadrat: &Kvadrat) -> u32 { kvadrat.kenglik * kvadrat.balandlik }
Ro'yxat 5-10: Kvadrat strukturasini aniqlash
Bu yerda biz structni aniqladik va uni Kvadrat deb nomladik. Jingalak qavslar ichida biz maydonlarni kenglik va balandlik sifatida belgiladik, ularning ikkalasi ham u32 turiga ega. Keyin, main da biz Kvadrat ning ma'lum bir misolini yaratdik, uning kengligi 30 va balandligi 50.
Bizning area funksiyamiz endi biz kvadrat deb nomlagan bitta parametr bilan aniqlanadi, uning turi Kvadrat structi misolining o‘zgarmas borrowidir. 4-bobda aytib o'tilganidek, biz unga ownershiplik qilishdan ko'ra, structi borrow qilishni xohlaymiz. Shunday qilib, main o'z ownershipini saqlab qoladi va kvadrat1 dan foydalanishni davom ettirishi mumkin, shuning uchun biz funktsiya signaturesida & dan foydalanamiz va biz funksiyani chaqiramiz.
area funksiyasi Kvadrat misolining kenglik va balandlik maydonlariga kiradi (esda tutingki, borrow qilingan struct misolining maydonlariga kirish maydon qiymatlarini ko'chirmaydi, shuning uchun siz ko'pincha structlarning borrowlarini ko'rasiz). Endi area funksiyasi signaturesi biz nimani nazarda tutayotganimizni aniq aytadi: Kvadrat maydonini uning kenglik va balandlik maydonlaridan foydalanib hisoblang. Bu kenglik va balandlik bir-biri bilan bog'liqligini bildiradi va 0 va 1 qator indeks qiymatlarini ishlatishdan ko'ra, qiymatlarga tavsiflovchi nomlar beradi. Bu aniqlik uchun g'alaba.
Olingan Traitlar bilan foydali funksionallikni qo'shish
Dasturimizni debug qilish va uning barcha maydonlari uchun qiymatlarni ko'rish paytida Kvadrat misolini chop etish foydali bo'lar edi. 5-11 ro'yxatda biz avvalgi boblarda foydalanganimizdek println! makrosidan foydalanishga harakat qiladi. Biroq, bu ishlamaydi.
Fayl nomi: src/main.rs
struct Kvadrat {
kenglik: u32,
balandlik: u32,
}
fn main() {
let kvadrat1 = Kvadrat {
kenglik: 30,
balandlik: 50,
};
println!("kvadrat1 - {}", kvadrat1);
}Ro'yxat 5-11: Kvadratni chop etishga urinish
misoli
Ushbu kodni kompilyatsiya qilishda, biz ushbu asosiy xabar bilan xatoga duch kelamiz:
error[E0277]: `Kvadrat` doesn't implement `std::fmt::Display`
println! makrosi ko'plab formatlash turlarini amalga oshirishi mumkin va standart bo'yicha jingalak qavslar println!ga Display deb nomlanuvchi formatlashdan foydalanishni bildiradi: to'g'ridan-to'g'ri oxirgi foydalanuvchi iste'moli uchun mo'ljallangan chiqish. Biz hozirgacha ko'rgan primitiv turlar standart bo'yicha Display ni qo'llaydi, chunki foydalanuvchiga 1 yoki boshqa primitiv turni ko'rsatishning faqat bitta usuli bor. Lekin structlar bilan println! ning chiqishni formatlash metodi unchalik aniq emas, chunki koʻproq koʻrsatish imkoniyatlari mavjud: vergul qoʻyishni xohlaysizmi yoki yoʻqmi? Jingalak qavslarni chop qilmoqchimisiz? Barcha maydonlar ko'rsatilishi kerakmi? Ushbu noaniqlik tufayli Rust biz xohlagan narsani taxmin qilishga urinmaydi va structlarda println! va {} to'ldiruvchisi bilan foydalanish uchun Display ning taqdim etilgan ilovasi yo'q.
Agar xatolarni o'qishda davom etsak, biz ushbu foydali eslatmani topamiz:
= help: the trait `std::fmt::Display` is not implemented for `Kvadrat`
= note: in format strings you may be able to use `{:?}` (or {:#?} for pretty-print) instead
Keling, sinab ko'raylik! println! macro chaqiruvi endi println!("kvadrat1 bu {}", kvadrat1); kabi ko'rinadi. :? spetsifikatsiyasini jingalak qavslar ichiga qo'yish println! biz Debug deb nomlangan chiqish formatidan foydalanmoqchi ekanligimizni bildiradi. Debug traiti bizga sturctni ishlab chiquvchilar uchun foydali bo'lgan tarzda chop etish imkonini beradi, shuning uchun biz kodimizni tuzatish paytida uning qiymatini ko'rishimiz mumkin.
Keling, ushbu o'zgarishlar bilan kodni kompilyatsiya qilaylik. Ehh! Biz hali ham xatoni olamiz:
error[E0277]: `Rectangle` doesn't implement `Debug`
Ammo yana, kompilyator bizga foydali eslatma beradi:
= help: the trait `Debug` is not implemented for `Rectangle`
= note: add `#[derive(Debug)]` to `Rectangle` or manually `impl Debug for Rectangle`
Rust debug ma'lumotlarini chop etish funksiyasini o'z ichiga oladi, lekin biz ushbu funksiyani structimiz uchun mavjud qilish uchun ochiqdan-ochiq rozi bo'lishimiz kerak.
Buni amalga oshirish uchun 5-12 ro'yxatda ko'rsatilganidek, struct ta'rifidan oldin #[derive(Debug)] tashqi atributini qo'shamiz.
Fayl nomi: src/main.rs
#[derive(Debug)] struct Kvadrat { kenglik: u32, balandlik: u32, } fn main() { let kvadrat1 = Kvadrat { kenglik: 30, balandlik: 50, }; println!("kvadrat1 - {:?}", kvadrat1); }
Ro'yxat 5-12: Debug traitini olish uchun atribut qo‘shish va debug formatlash yordamida Kvadrat misolini chop etish
Endi dasturni ishga tushirganimizda, biz hech qanday xatolikka yo'l qo'ymaymiz va biz quyidagi natijani ko'ramiz:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished dev [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/rectangles`
kvadrat1 - Kvadrat { kenglik: 30, balandlik: 50 }
Yaxshi! Bu eng yaxshi natija emas, lekin u ushbu misol uchun barcha maydonlarning qiymatlarini ko'rsatadi, bu disk raskadrovka paytida albatta yordam beradi. Kattaroq structlarga ega bo'lsak, o'qishni biroz osonlashtiradigan chiqishga ega bo'lish foydalidir; bunday hollarda println! qatoridagi {:?} o'rniga {:#?} dan foydalanishimiz mumkin. Ushbu misolda {:#?} uslubidan foydalanish quyidagi natijalarni beradi:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished dev [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/rectangles`
kvadrat1 - Kvadrat {
kenglik: 30,
balandlik: 50
}
Debug formati yordamida qiymatni chop etishning yana bir usuli dbg! macro Ifodaga egalik qiluvchi macro (mos referencelar oladigan println! dan farqli o'laroq) o'sha dbg! qayerda fayl va satr raqamini chop etadi! macro murojati sizning kodingizda ushbu ifodaning natijaviy qiymati bilan birga sodir bo'ladi va qiymatga egalik huquqini qaytaradi.
Eslatma:
dbg!makrosini chaqirish standart chiqish konsoli stremiga (stdout) chop qiluvchiprintln!dan farqli ravishda standart xato konsoli stremiga (stderr) chop etadi. Biz 12-bobdagi ”Xato xabarlarini standart chiqish o‘rniga standart xatoga yozish” bo‘limidastderrvastdouthaqida ko‘proq gaplashamiz.
Mana bizni kenglik maydoniga tayinlanadigan qiymat, shuningdek kvadrat1dagi butun structning qiymati qiziqtiradigan misol:
#[derive(Debug)] struct Kvadrat { kenglik: u32, balandlik: u32, } fn main() { let masshtab = 2; let kvadrat1 = Kvadrat { kenglik: dbg!(30 * masshtab), balandlik: 50, }; dbg!(&kvadrat1); }
Biz 30 * masshtab iborasi atrofida dbg! qo'yishimiz mumkin va dbg! ifoda qiymatiga egalik huquqini qaytargani uchun, kenglik maydoni bizda dbg! chaqiruvi bo'lmagani kabi bir xil qiymatga ega bo'ladi. Biz dbg! kvadrat1ga egalik qilishini istamaymiz, shuning uchun keyingi chaqiruvda kvadrat1 ga referencedan foydalanamiz.
Ushbu misolning natijasi quyidagicha ko'rinadi:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished dev [unoptimized + debuginfo] target(s) in 0.61s
Running `target/debug/rectangles`
[src/main.rs:10] 30 * masshtab = 60
[src/main.rs:14] &kvadrat1 = Kvadrat {
kenglik: 30,
balandlik: 50
}
Biz birinchi debuggingda src/main.rs ning 10-qatoridan kelganini ko'rishimiz mumkin, bu erda biz 30 * masshtab ifodani debugging qilamiz va uning natijaviy qiymati 60 (butun sonlar uchun Debug formati faqat ularning qiymatini chop etish uchun ishlatiladi). src/main.rs ning 14-qatoridagi dbg! chaqiruvi &kvadrat1 qiymatini chiqaradi, bu Kvadrat structidir. Ushbu chiqishda Kvadrat turidagi chiroyli Debug formatlash qo'llaniladi. dbg! makrosi sizning kodingiz nima qilayotganini aniqlashga harakat qilayotganingizda juda foydali bo'lishi mumkin!
Rust Debug traitiga qo‘shimcha ravishda derive atributi bilan foydalanishimiz uchun bir qancha taritlarni taqdim etdi, ular bizning odatiy turlarimizga foydali xatti-harakatlar qo‘shishi mumkin.Ushbu traitlar va ularning xatti-harakatlari C ilovasida keltirilgan. Biz 10-bobda ushbu traittlarni odatiy xatti-harakatlar bilan qanday implement qilishni, shuningdek, o'z traitlaringizni qanday yaratishni ko'rib chiqamiz.Bundan tashqari, 'derive' dan boshqa ko'plab atributlar mavjud; qo'shimcha ma'lumot olish uchun Rust Referencening "Atributlar" bo'limiga qarang.
Bizning area funksiyamiz juda aniq: u faqat to'rtburchaklar maydonini hisoblaydi. Ushbu xatti-harakatni Kvadrat structimiz bilan yaqinroq bog'lash foydali bo'ladi, chunki u boshqa turlar bilan ishlamaydi. Keling, ushbu kodni qanday qilib qayta ishlashni davom ettirishimiz mumkinligini ko'rib chiqaylik, bu area funksiyasini Kvadrat turida aniqlangan area metod ga aylantiradi.
Metod Sintaksisi
Metodlar funksiyalarga oʻxshaydi: biz ularni fn kalit soʻzi va nomi bilan eʼlon qilamiz, ular parametrlari va qaytish qiymatiga ega boʻlishi mumkin va ular boshqa joydan metod chaqirilganda ishga tushadigan kodni oʻz ichiga oladi. Funktsiyalardan farqli o'laroq, metodlar struct (yoki biz mos ravishda 6-bob va 17-bobda ko'rib chiqiladigan enum yoki trait obyekti) kontekstida aniqlanadi va ularning birinchi parametri har doim self dir metod chaqirilayotgan structning namunasini ifodalaydi.
Metodlarni aniqlash
Parametr sifatida Kvadrat misoliga ega bo‘lgan area funksiyasini o‘zgartiramiz va uning o‘rniga 5-13 ro‘yxatda ko'rsatilganidek, Kvadrat structida belgilangan area metodini yaratamiz.
Fayl nomi: src/main.rs
#[derive(Debug)] struct Kvadrat { kenglik: u32, balandlik: u32, } impl Kvadrat { fn area(&self) -> u32 { self.kenglik * self.balandlik } } fn main() { let kvadrat1 = Kvadrat { kenglik: 30, balandlik: 50, }; println!( "To'rtburchakning maydoni {} kvadrat pikselga teng.", kvadrat1.area() ); }
Ro'yxat 5-13: Kvadrat structida area metodini aniqlash
Kvadrat kontekstida funksiyani aniqlash uchun Kvadrat uchun impl (implementation) blokini ishga tushiramiz. Ushbu impl blokidagi hamma narsa Kvadrat turi bilan bog'lanadi. Keyin biz area funksiyasini impl jingalak qavslar ichida harakatlantiramiz va birinchi (va bu holda, faqat) parametrni signatureda va tananing hamma joyida self o‘zgartiramiz. main da, biz area funksiyasini chaqirib, argument sifatida kvadrat1 ni topshirgan bo‘lsak, o‘rniga Kvadrat misolida area metodini chaqirish uchun metod sintaksisi dan foydalanishimiz mumkin. Metod sintaksisi misoldan keyin keladi: biz nuqta qo'shamiz, undan keyin metod nomi, qavslar va har qanday argumentlar qo'shiladi.
area uchun signatureda kvadrat: &Kvadrat o‘rniga &self dan foydalanamiz. &self aslida self: &Self ning qisqartmasi. impl blokida Self turi impl bloki uchun bo'lgan turdagi taxallusdir. Metodlar birinchi parametri uchun Self turidagi self deb nomlangan parametrga ega bo'lishi kerak, shuning uchun Rust birinchi parametr joyida faqat self nomi bilan qisqartirish imkonini beradi.
Esda tutingki, biz hali ham kvadrat: &Kvadrat da qilganimizdek, bu metod Self misolini olishini koʻrsatish uchun Self stenografiyasi oldida & dan foydalanishimiz kerak. Boshqa har qanday parametr singari, metodlar self egallashi, o'zgarmas self borrow qilishi mumkin, xuddi biz bu yerda qilganimizdek yoki o'zgaruvchan selfni borrow qilishi mumkin.
Biz bu yerda funksiya versiyasida &Kvadrat dan foydalanganimiz uchun xuddi shu sababga ko‘ra &self tanladik: biz ownershiplik qilishni istamaymiz va faqat structdagi ma’lumotlarni o‘qishni istaymiz, unga yozishni emas. Agar biz ushbu metodning bir qismi sifatida chaqirgan misolni o'zgartirmoqchi bo'lsak, birinchi parametr sifatida &mut self dan foydalanamiz. Birinchi parametr sifatida faqat selfni ishlatib, misolga ownershiplik qiladigan metod kamdan-kam uchraydi; bu metod odatda selfni boshqa narsaga aylantirganda va siz murojat qiluvchiga transformatsiyadan keyin asl nusxadan foydalanishiga yo'l qo'ymaslikni istasangiz ishlatiladi.
Funktsiyalar o'rniga metodlardan foydalanishning asosiy sababi, har bir metod signaturesida selfturini takrorlashning hojati bo'lmagan metod sintaksisidan tashqari, kodni tashkil qilishdir. Biz kelajakdagi kod foydalanuvchilarini biz taqdim etayotgan kutubxonaning turli joylarida Kvadrat imkoniyatlarini izlashga majburlashdan ko‘ra, biz tur namunasi bilan qila oladigan barcha narsalarni bitta impl blokiga joylashtirdik.
E'tibor bering, biz metodga structning maydonlaridan biri bilan bir xil nom berishni tanlashimiz mumkin. Misol uchun, biz Kvadrat da kenglik deb nomlangan metodni belgilashimiz mumkin:
Fayl nomi: src/main.rs
#[derive(Debug)] struct Kvadrat { kenglik: u32, balandlik: u32, } impl Kvadrat { fn kenglik(&self) -> bool { self.kenglik > 0 } } fn main() { let kvadrat1 = Kvadrat { kenglik: 30, balandlik: 50, }; if kvadrat1.kenglik() { println!("To'rtburchakning kengligi nolga teng bo'lmagan; bu {}", kvadrat1.kenglik); } }
Bu yerda, agar misolning kenglik maydonidagi qiymat 0 dan katta bo‘lsa, kenglik metodi true qiymatini qaytaradi, agar qiymat 0 bo'lsa, false bo‘lishini tanlaymiz: biz bir xil nomdagi metod ichidagi maydonni istalgan maqsadda ishlatishimiz mumkin. main da, biz qavslar bilan kvadrat1.kenglik ga amal qilsak, Rust kenglik metodini nazarda tutayotganimizni biladi. Qavslardan foydalanmasak, Rust kenglik maydonini nazarda tutayotganimizni biladi.
Ko'pincha, lekin har doim emas, biz metodga maydon bilan bir xil nom berganimizda, biz u faqat maydondagi qiymatni qaytarishini va boshqa hech narsa qilmasligini xohlaymiz. Shunga o'xshash metodlar getters deb ataladi va Rust ularni boshqa tillarda bo'lgani kabi tizim maydonlari uchun avtomatik ravishda amalga oshirmaydi. Getterslar foydalidir, chunki siz maydonni shaxsiy(private), lekin metodni hammaga ochiq(public) qilib qo'yishingiz mumkin va shu tariqa ushbu maydonga umumiy API ning bir qismi sifatida faqat o'qish uchun ruxsatni yoqishingiz mumkin. Biz 7-bobda public va private nima ekanligini va qanday qilib maydon yoki metodni public yoki private deb belgilashni muhokama qilamiz.
->operatori qayerda ishlatiladi?C va C++ tillarida metodlarni chaqirish uchun ikki xil operator qo'llaniladi: obyektdagi metodni to'g'ridan-to'g'ri chaqirayotgan bo'lsangiz
.va agar siz ko'rsatgichdagi metodni obyektga chaqirayotgan bo'lsangiz va avval ko'rsatgichni yo'qotishingiz kerak bo'lsa->dan foydalanasiz. Boshqacha qilib aytganda, agarobjecthavola bo'lsa, u holdaobject->something()va(*object).something()metodi chaqiruvlari bir xil bo'ladi.Rust
->operatoriga ekvivalentga ega emas; Buning o'rniga Rustda avtomatik reference va dereferencing deb nomlangan xususiyat mavjud. Metodni chaqirish Rustda bunday xatti-harakatlarga ega bo'lgan kam sonli joylardan biridir.Bu shunday ishlaydi:
object.something()bilan metodni chaqirganingizda, Rust avtomatik ravishda&,&mutyoki*ni qo'shadi, shuning uchunobjectmetod signaturega mos keladi. Boshqacha qilib aytganda, quyidagilar bir xil:#![allow(unused)] fn main() { #[derive(Debug,Copy,Clone)] struct Point { x: f64, y: f64, } impl Point { fn masofa(&self, other: &Point) -> f64 { let x_kvadrat = f64::powi(other.x - self.x, 2); let y_kvadrat = f64::powi(other.y - self.y, 2); f64::sqrt(x_kvadrat + y_kvadrat) } } let p1 = Point { x: 0.0, y: 0.0 }; let p2 = Point { x: 5.0, y: 6.5 }; p1.masofa(&p2); (&p1).masofa(&p2); }Birinchisi ancha toza ko'rinadi. Ushbu avtomatik reference qilish harakati, metodlar aniq qabul qiluvchiga ega bo'lganligi sababli ishlaydi -
selfturi. Qabul qiluvchi va metod nomini hisobga olgan holda, Rust ma'lum bir holatda kod nima qilayotganini aniq aniqlashi mumkin: o'qish(&self), o'zgartirish (&mut self) yoki iste'mol qilish (self). Rust metodi qabul qiluvchilar uchun borrow qilishni yashirin qilib qo'yganligi amalda ownershipni ergonomik qilishning katta qismidir.
Ko'proq parametrlarga ega metodlar
Kvadrat structida ikkinchi metodni implement qilish orqali metodlardan foydalanishni mashq qilaylik. Bu safar biz Kvadrat misoli Kvadrat ning boshqa nusxasini olishini va agar ikkinchi Kvadrat to'liq o'ziga (birinchi Kvadrat) sig'ishi mumkin bo'lsa, true qiymatini qaytarishini istaymiz; aks holda u falseni qaytarishi kerak.
Ya'ni, ushlab_tur metodini aniqlaganimizdan so'ng, biz 5-14 ro'yxatda ko'rsatilgan dasturni yozish imkoniyatiga ega bo'lishni xohlaymiz.
Fayl nomi: src/main.rs
fn main() {
let kvadrat1 = Kvadrat {
kenglik: 30,
balandlik: 50,
};
let kvadrat2 = Kvadrat {
kenglik: 10,
balandlik: 40,
};
let kvadrat3 = Kvadrat {
kenglik: 60,
balandlik: 45,
};
println!("kvadrat1 kvadrat2ni ushlab turadimi? {}", kvadrat1.ushlab_tur(&kvadrat2));
println!("kvadrat1 kvadrat3ni ushlab turadimi? {}", kvadrat1.ushlab_tur(&kvadrat3));
}Ro'yxat 5-14: Hali yozilmagan ushlab_tur dan foydalanish
metodi
Kutilgan natija quyidagicha ko‘rinadi, chunki kvadrat2 ning ikkala o‘lchami kvadrat1 o‘lchamidan kichikroq, lekin kvadrat3 kvadrat1 dan kengroq:
kvadrat1 kvadrat2ni ushlab turadimi? true
kvadrat1 kvadrat3ni ushlab turadimi? false
Biz metodni aniqlamoqchi ekanligimizni bilamiz, shuning uchun u impl Kvadrat blokida bo'ladi. Metod nomi ushlab_tur bo'ladi va u parametr sifatida boshqa Kvadrat ning o'zgarmas borrowini oladi. Parametrning turi qanday bo'lishini metodni chaqiruvchi kodga qarab aniqlashimiz mumkin: kvadrat1.ushlab_tur(&kvadrat2) &kvadrat2 da o'tadi, bu kvadrat2 ga o'zgarmas borrow, Kvadrat misoli. Bu mantiqqa to'g'ri keladi, chunki biz faqat kvadrat2 ni o'qishimiz kerak (yozishdan ko'ra, bu bizga o'zgaruvchan borrow kerak degan ma'noni anglatadi), va biz main kvadrat2 ownershipligini saqlab qolishini istaymiz, shuning uchun ushlab_tur metodini chaqirganimizdan keyin uni qayta ishlatishimiz mumkin. ushlab_tur ning return qiymati mantiqiy qiymat bo'ladi va implement self ning kengligi va balandligi mos ravishda boshqa Kvadrat ning kengligi va balandligidan katta ekanligini tekshiradi. Keling, 5-15 ro'yxatda ko'rsatilgan 5-13 ro'yxatdagi impl blokiga yangi ushlab_tur metodini qo'shamiz.
Fayl nomi: src/main.rs
#[derive(Debug)] struct Kvadrat { kenglik: u32, balandlik: u32, } impl Kvadrat { fn area(&self) -> u32 { self.kenglik * self.balandlik } fn ushlab_tur(&self, other: &Kvadrat) -> bool { self.kenglik > other.kenglik && self.balandlik > other.balandlik } } fn main() { let kvadrat1 = Kvadrat { kenglik: 30, balandlik: 50, }; let kvadrat2 = Kvadrat { kenglik: 10, balandlik: 40, }; let kvadrat3 = Kvadrat { kenglik: 60, balandlik: 45, }; println!("kvadrat1 kvadrat2ni ushlab turadimi? {}", kvadrat1.ushlab_tur(&kvadrat2)); println!("kvadrat1 kvadrat3ni ushlab turadimi? {}", kvadrat1.ushlab_tur(&kvadrat3)); }
Ro'yxat 5-15: Parametr sifatida boshqa Kvadrat misolini oladigan ushlab_tur metodini Kvadratda qo'llash
Ushbu kodni 5-14 ro'yxatdagi main funksiya bilan ishga tushirganimizda, biz kerakli natijani olamiz. Metodlar biz signaturega self parametridan keyin qo'shadigan bir nechta parametrlarni olishi mumkin va bu parametrlar funksiyalardagi parametrlar kabi ishlaydi.
Associate Funksiyalar
Associate Funksiyalar (Bog'langan Funktsiyalar).impl blokida aniqlangan barcha funksiyalar associated funksiyalar deb ataladi, chunki ular impl nomi bilan atalgan tur bilan bog‘langan. Biz birinchi parametr sifatida self ega bo'lmagan associated funksiyalarni belgilashimiz mumkin (va shuning uchun metodlar emas), chunki ular bilan ishlash uchun turdagi namuna kerak emas.
Biz allaqachon shunday funksiyadan foydalanganmiz: String turida aniqlangan String::from funksiyasi.
Metod bo'lmagan associated funktsiyalar ko'pincha structning yangi nusxasini qaytaradigan konstruktorlar uchun ishlatiladi. Ular ko'pincha new deb ataladi, ammo new maxsus nom emas va tilga kiritilmagan. Masalan, biz bir o‘lchamli parametrga ega bo‘lgan kvadrat nomli associated funksiyani taqdim etishimiz va undan kenglik va balandlik sifatida foydalanishimiz mumkin, bu esa bir xil qiymatni ikki marta belgilashdan ko‘ra Kvadrat kvadratini yaratishni osonlashtiradi. :
Fayl nomi: src/main.rs
#[derive(Debug)] struct Kvadrat { kenglik: u32, balandlik: u32, } impl Kvadrat { fn kvadrat(size: u32) -> Self { Self { kenglik: size, balandlik: size, } } } fn main() { let kv = Kvadrat::kvadrat(3); }
Return turidagi va funksiya tanasidagi Self kalit so'zlari impl kalit so'zidan keyin paydo bo'ladigan turning taxalluslari bo'lib, bu holda Kvadrat bo'ladi. Biz bularni 7-bobda muhokama qilamiz.
Ushbu associated funktsiyani chaqirish uchun biz struct nomi bilan :: sintaksisidan foydalanamiz; let kv = Kvadrat::kvadrat(3); misol bo'la oladi. Bu funksiya struct tomonidan nom maydoniga ega: :: sintaksisi ham associated funksiyalar, ham modullar tomonidan yaratilgan nomlar bo'shliqlari uchun ishlatiladi. Biz modullarni 7-bobda muhokama qilamiz.
Bir nechta impl bloklari
Har bir structga bir nechta impl bloklari ruxsat etiladi. Masalan, 5-15 ro'yxati 5-16 ro'yxatida ko'rsatilgan kodga ekvivalent bo'lib, har bir metod o'zining impl blokiga ega yani har bir metod o'z impl blokida.
#[derive(Debug)] struct Kvadrat { kenglik: u32, balandlik: u32, } impl Kvadrat { fn area(&self) -> u32 { self.kenglik * self.balandlik } } impl Kvadrat { fn ushlab_tur(&self, other: &Kvadrat) -> bool { self.kenglik > other.kenglik && self.balandlik > other.balandlik } } fn main() { let kvadrat1 = Kvadrat { kenglik: 30, balandlik: 50, }; let kvadrat2 = Kvadrat { kenglik: 10, balandlik: 40, }; let kvadrat3 = Kvadrat { kenglik: 60, balandlik: 45, }; println!("kvadrat1 kvadrat2ni ushlab turadimi? {}", kvadrat1.ushlab_tur(&kvadrat2)); println!("kvadrat1 kvadrat3ni ushlab turadimi? {}", kvadrat1.ushlab_tur(&kvadrat3)); }
Ro'yxat 5-16: Bir nechta impl bloklari yordamida 5-15 ro'yxatini qayta yozish
Bu metodlarni bir nechta impl bloklariga ajratish uchun hech qanday sabab yo'q, lekin bu to'g'ri sintaksis. Biz 10-bobda bir nechta impl bloklari foydali bo'lgan holatni ko'rib chiqamiz, bu yerda biz umumiy turlar va taritlarni muhokama qilamiz.
Xulosa
Structlar sizning domeningiz uchun mazmunli bo'lgan maxsus turlarni yaratishga imkon beradi. Structlardan foydalanib, siz bog'langan ma'lumotlar qismlarini bir-biriga bog'lab qo'yishingiz va kodingizni aniq qilish uchun har bir qismga nom berishingiz mumkin. impl bloklarida siz o'zingizning turingiz bilan bog'liq bo'lgan funksiyalarni belgilashingiz mumkin va metodlar - bu sizning structlaringiz misollarining xatti-harakatlarini belgilashga imkon beruvchi associated funksiyaning bir turi.
Ammo structlar maxsus turlarni yaratishning yagona usuli emas: toolboxga boshqa toolni qo'shish uchun Rust enum xususiyatiga murojaat qilaylik.
Enumlar va Pattern Match
Ushbu bobda biz enumlar deb ham ataladigan enumerationsni ko'rib chiqamiz.
Enumlar sizga turni uning mumkin bo'lgan variantlarini sanab aniqlash imkonini beradi. Avval enum ma'lumotarni qanday birlashtirishi mumkinligini ko'rsatish uchun enumni aniqlaymiz va ishlatamiz. Keyinchalik, qiymatning biror narsa yoki hech narsa bo'lishi mumkinligini ifodalovchi Option deb nomlangan juda foydali enumni o'rganamiz. Keyin biz match iborasida pattern matching enumning turli qiymatlari uchun turli kodlarni ishga tushirishni qanday osonlashtirishini ko'rib chiqamiz. Nihoyat, if let konstruksiyasi sizning kodingizdagi enumlar bilan ishlash uchun qanday qulay va ixcham idioma ekanligini ko'rib chiqamiz.
Enumni aniqlash
Structlar sizga tegishli maydonlar va ma'lumotlarni, masalan, kenglik va balandlik bilan Kvadrat ni guruhlash usulini beradigan bo'lsa, enumlar qiymatni mumkin bo'lgan qiymatlar to'plamidan biri deb aytish metodini beradi. Masalan, Kvadrat bu mumkin bo‘lgan shakllar to‘plamidan biri bo‘lib, Doira va Uchburchakni ham o‘z ichiga oladi, demoqchimiz. Buning uchun Rust bizga ushbu imkoniyatlarni enum sifatida kodlash imkonini beradi.
Keling, kodda ifodalashni xohlashimiz mumkin bo'lgan vaziyatni ko'rib chiqaylik va bu holda nima uchun enumlar foydali va structlardan ko'ra mosroq ekanligini bilib olaylik. Aytaylik, biz IP manzillar bilan ishlashimiz kerak. Hozirgi vaqtda IP manzillar uchun ikkita asosiy standart qo'llaniladi: to'rtinchi versiya va oltinchi versiya. Bular bizning dasturimiz duch keladigan IP-manzilning yagona imkoniyatlari bo'lgani uchun biz barcha mumkin bo'lgan variantlarni enumerate qilishimiz mumkin, bu yerda enumeration o'z nomini oladi.
Har qanday IP manzil to'rtinchi versiya yoki oltinchi versiya manzili bo'lishi mumkin, lekin ikkalasi bir vaqtning o'zida emas. IP-manzillarning bu xususiyati enum ma'lumotlar structini mos qiladi, chunki enum qiymati faqat uning variantlaridan biri bo'lishi mumkin. To'rtinchi versiya va oltinchi versiya manzillari hali ham IP-manzillardir, shuning uchun kod har qanday IP-manzilga tegishli vaziyatlarni ko'rib chiqayotganda ular bir xil turdagi sifatida ko'rib chiqilishi kerak.
Biz ushbu kontseptsiyani kodda IpAddrKind ro'yxatini belgilash va IP-manzil bo'lishi mumkin bo'lgan V4 va V6 turlarini enumeration qilish orqali ifodalashimiz mumkin. Bular enumning variantlari:
enum IpAddrKind { V4, V6, } fn main() { let tort = IpAddrKind::V4; let olti = IpAddrKind::V6; route(IpAddrKind::V4); route(IpAddrKind::V6); } fn route(ip_turi: IpAddrKind) {}
IpAddrKind endi biz kodimizning boshqa joylarida foydalanishimiz mumkin bo'lgan maxsus ma'lumotlar turidir.
Enum qiymatlari
Biz IpAddrKind ning ikkita variantining har birining misollarini quyidagicha yaratishimiz mumkin:
enum IpAddrKind { V4, V6, } fn main() { let tort = IpAddrKind::V4; let olti = IpAddrKind::V6; route(IpAddrKind::V4); route(IpAddrKind::V6); } fn route(ip_turi: IpAddrKind) {}
E'tibor bering, enumning variantlari uning identifikatori ostida nom maydonida joylashgan va biz ikkalasini ajratish uchun qo'sh nuqtadan foydalanamiz. Bu foydali, chunki endi ikkala IpAddrKind::V4 va IpAddrKind::V6 qiymatlari bir xil turdagi: IpAddrKind. Masalan, biz har qanday IpAddrKind ni qabul qiladigan funksiyani aniqlashimiz mumkin:
enum IpAddrKind { V4, V6, } fn main() { let tort = IpAddrKind::V4; let olti = IpAddrKind::V6; route(IpAddrKind::V4); route(IpAddrKind::V6); } fn route(ip_turi: IpAddrKind) {}
Va biz bu funktsiyani ikkala variant bilan chaqirishimiz mumkin:
enum IpAddrKind { V4, V6, } fn main() { let tort = IpAddrKind::V4; let olti = IpAddrKind::V6; route(IpAddrKind::V4); route(IpAddrKind::V6); } fn route(ip_turi: IpAddrKind) {}
Enumlardan foydalanish yanada ko'proq afzalliklarga ega. Bizning IP manzilimiz turi haqida ko'proq o'ylab ko'rsak, hozirda bizda haqiqiy IP-manzilni ma'lumotlarni saqlash imkoni yo'q; biz faqat qanday turdagi ekanligini bilamiz. 5-bobda structlar haqida hozirgina bilib olganingizni hisobga olsak, 6-1 ro'yxatda ko'rsatilganidek, bu muammoni structlar yordamida hal qilish istagi paydo bo'lishi mumkin.
fn main() { enum IpAddrKind { V4, V6, } struct IpAddr { tur: IpAddrKind, manzil: String, } let asosiy = IpAddr { tur: IpAddrKind::V4, manzil: String::from("127.0.0.1"), }; let orqaga_qaytish = IpAddr { tur: IpAddrKind::V6, manzil: String::from("::1"), }; }
Ro'yxat 6-1: struct yordamida IP manzilining ma'lumotlarini va IpAddrKind variantini saqlash
Bu yerda biz ikkita maydonga ega boʻlgan IpAddr structini aniqladik: IpAddrKind turidagi tur maydoni (biz avvalroq belgilagan raqam) va String tipidagi manzil maydoni. Bizda bu structning ikkita misoli bor. Birinchisi asosiy boʻlib, u 127.0.0.1 bogʻlangan manzil maʼlumotlari bilan tur sifatida IpAddrKind::V4 qiymatiga ega. Ikkinchi misol - orqaga_qaytish. U tur qiymati sifatida IpAddrKind ning boshqa variantiga ega, V6 va u bilan bog'langan ::1 manzili mavjud. Biz tur va manzil qiymatlarini birlashtirish uchun structdan foydalanganmiz, shuning uchun endi variant qiymat bilan bog'langan.
Shu bilan birga, bir xil kontseptsiyani faqat enum yordamida ifodalash yanada ixchamroqdir: struct ichidagi enum o'rniga, biz ma'lumotlarni to'g'ridan-to'g'ri har bir enum variantiga qo'yishimiz mumkin. IpAddr enumining ushbu yangi ta'rifida aytilishicha, V4 va V6 variantlari ham associated String qiymatlariga ega bo'ladi:
fn main() { enum IpAddr { V4(String), V6(String), } let asosiy = IpAddr::V4(String::from("127.0.0.1")); let orqaga_qaytish = IpAddr::V6(String::from("::1")); }
Biz to'g'ridan-to'g'ri enumning har bir variantiga ma'lumotlarni biriktiramiz, shuning uchun qo'shimcha structga ehtiyoj qolmaydi. Bu yerda, shuningdek, enumlar qanday ishlashining yana bir tafsilotini ko'rish osonroq bo'ladi: biz belgilagan har bir enum variantining nomi, shuningdek, enum nusxasini yaratuvchi funktsiyaga aylanadi. Ya'ni, IpAddr::V4() funksiya chaqiruvi bo'lib, u String argumentini oladi va IpAddr tipidagi misolni qaytaradi. Enumni aniqlash natijasida aniqlangan ushbu konstruktor funksiyasini avtomatik ravishda olamiz.
Structdan ko'ra enumdan foydalanishning yana bir afzalligi bor: har bir variantda bog'langan ma'lumotlarning har xil turlari va miqdori bo'lishi mumkin. To'rtinchi versiyada IP-manzillar har doim 0 dan 255 gacha bo'lgan qiymatlarga ega bo'lgan to'rtta raqamli komponentga ega bo'ladi. Agar biz V4 manzillarini to‘rtta u8 qiymati sifatida saqlamoqchi bo‘lsak-da, V6 manzillarini bitta String qiymati sifatida ifodalasak, biz struct bilan buni qila olmaymiz. Enumlar bu ishni osonlik bilan hal qiladi:
fn main() { enum IpAddr { V4(u8, u8, u8, u8), V6(String), } let asosiy = IpAddr::V4(127, 0, 0, 1); let orqaga_qaytish = IpAddr::V6(String::from("::1")); }
Biz to'rtinchi versiya va oltinchi versiya IP manzillarini saqlash uchun ma'lumotlar tuzilmalarini aniqlashning bir necha xil usullarini ko'rsatdik. Biroq, ma'lum bo'lishicha, IP-manzillarni saqlash va ularning qaysi turini kodlash istagi shunchalik keng tarqalganki, standart kutubxonada biz foydalanishimiz mumkin bo'lgan defination mavjud! . Keling, standart kutubxona IpAddr ni qanday aniqlashini ko'rib chiqaylik: u biz aniqlagan va ishlatgan aniq enum va variantlarga ega, lekin u manzil ma'lumotlarini variantlar ichida ikki xil struct shaklida joylashtiradi, har bir variant uchun turlicha belgilanadi:
#![allow(unused)] fn main() { struct Ipv4Addr { // --snip-- } struct Ipv6Addr { // --snip-- } enum IpAddr { V4(Ipv4Addr), V6(Ipv6Addr), } }
Ushbu kod har qanday turdagi ma'lumotlarni enum variantiga qo'yish mumkinligini ko'rsatadi: masalan, stringlar, raqamli turlar yoki structlar. Siz hatto boshqa raqamni ham qo'shishingiz mumkin! Bundan tashqari, standart kutubxona turlari ko'pincha siz o'ylab topganingizdan ancha murakkab emas.
E'tibor bering, standart kutubxonada IpAddr uchun definition mavjud bo'lsa ham, biz o'z definitionimizni ziddiyatli holda yaratishimiz va foydalanishimiz mumkin, chunki biz standart kutubxonaning definitionini o'z doiramizga kiritmaganmiz. Biz 7-bobda turlarni qamrab olish haqida ko'proq gaplashamiz.
Keling, 6-2 ro'yxatdagi enumning yana bir misolini ko'rib chiqaylik: bu o'z variantlarida ko'p turdagi turlarga ega.
enum Xabar { Chiqish, Kochirish { x: i32, y: i32 }, Yozish(String), RangTanlash(i32, i32, i32), } fn main() {}
Ro'yxat 6-2: Xabar enumi, uning variantlari har xil miqdor va qiymat turlarini saqlaydi
Ushbu enum har xil turdagi to'rtta variantga ega:
Chiqishda u bilan bogʻliq hech qanday maʼlumot yoʻq.Kochirishda struct kabi maydonlarni nomlagan.YozishbittaStringni o'z ichiga oladi.RangTanlauchtai32qiymatini o'z ichiga oladi.
Enumni 6-2-roʻyxatdagi kabi variantlar bilan belgilash strukturaviy definitionlarning har xil turlarini aniqlashga oʻxshaydi, faqat enum struct kalit soʻzidan foydalanmaydi va barcha variantlar Xabar turi ostida birlashtiriladi. Quyidagi structlar oldingi enum variantlari bilan bir xil ma'lumotlarni saqlashi mumkin:
struct ChiqishXabar; // unit struct struct KochirishXabar { x: i32, y: i32, } struct YozishXabar(String); // tuple struct struct RangTanshlaXabar(i32, i32, i32); // tuple struct fn main() {}
Lekin biz o'z turlariga ega bo'lgan turli structlardan foydalanganimizda, biz har qanday xabar turini qabul qiladigan funksiyalarni osonlikcha aniqlay olmadik, buni bitta tur bo'lgan 6-2 ro'yxatda e'lon qilingan Xabar turini enum bilan amalga oshirish mumkin.
Enumlar va structlar o'rtasida yana bir o'xshashlik bor: biz impl yordamida structlarda metodlarni aniqlay olganimizdek, enumlarda ham metodlarni belgilashimiz mumkin. Bu yerda biz Xabar enumimizda aniqlashimiz mumkin bo'lgan chaqiruv deb nomlangan metod:
fn main() { enum Xabar { Chiqish, Kochirish { x: i32, y: i32 }, Yozish(String), RangTanlash(i32, i32, i32), } impl Xabar { fn chaqiruv(&self) { // metod tanasi bu yerda aniqlanadi } } let m = Xabar::Yozish(String::from("salom")); m.chaqiruv(); }
Metod tanasi biz metod deb atagan qiymatni olish uchun self ishlatadi. Ushbu misolda biz Xabar::Yozish(String::from("salom")) qiymatini o'z ichiga olgan m o'zgaruvchisini yaratdik va m.chaqiruv() ishga tushganda chaqiruv metodining tanasida aynan shunday boʻladi.
Keling, standart kutubxonadagi juda keng tarqalgan va foydali bo'lgan yana bir enumni ko'rib chiqaylik: Option.
Option Enum va uning null qiymatlardan ustunligi
Ushbu bo'lim standart kutubxona tomonidan aniqlangan yana bir enum bo'lgan Option ning misolini o'rganadi.Option turi qiymat nimadir yoki hech narsa bo'lmasligi mumkin bo'lgan juda keng tarqalgan senariyni kodlaydi.
Misol uchun, agar siz bo'sh bo'lmagan ro'yxatdagi birinchi elementni so'rasangiz, qiymat olasiz. Agar siz bo'sh ro'yxatdagi birinchi elementni so'rasangiz, hech narsa olmaysiz. Ushbu kontseptsiyani turdagi tizim nuqtai nazaridan ifodalash kompilyator siz ko'rib chiqishingiz kerak bo'lgan barcha ishlarni ko'rib chiqqaningizni tekshirishi mumkinligini anglatadi; bu funksiya boshqa dasturlash tillarida juda keng tarqalgan xatolarni oldini oladi.
Dasturlash tilining dizayni ko'pincha siz qaysi xususiyatlarni o'z ichiga olganligingiz nuqtai nazaridan o'ylanadi, ammo siz chiqarib tashlagan xususiyatlar ham muhimdir. Rust ko'plab boshqa tillarda mavjud bo'lgan null xususiyatiga ega emas. Null - bu qiymat yo'qligini bildiradi. Null bo'lgan tillarda o'zgaruvchilar har doim ikkita holatdan birida bo'lishi mumkin: null yoki null emas.
2009 yilgi "Null References: The Million Dollar Mistake" taqdimotida null ixtirochisi Tony Hoare shunday deydi:
Men buni milliard dollarlik xatoyim deb atayman. O'sha paytda men object-oriented language referencelar uchun birinchi keng qamrovli turdagi tizimni loyihalashtirgan edim. Mening maqsadim referencelardan foydalanishning mutlaqo xavfsiz bo'lishini ta'minlash edi, tekshirish kompilyator tomonidan avtomatik ravishda amalga oshiriladi. Lekin men null reference qo'yish vasvasasiga qarshi tura olmadim, chunki uni amalga oshirish juda oson edi. Bu so'nggi qirq yil ichida bir milliard dollar og'riq va zarar keltirgan son-sanoqsiz xatolar, zaifliklar va tizimning ishdan chiqishiga olib keldi.
Null qiymatlari bilan bog'liq muammo shundaki, agar siz null qiymatdan a sifatida foydalanishga harakat qilsangiz no-null qiymat bo'lsa, siz qandaydir xatoga duch kelasiz. Ushbu null yoki not-null xususiyat keng tarqalganligi sababli, bunday xatoga yo'l qo'yish juda oson.
Biroq, null ifodalamoqchi bo'lgan kontseptsiya hali ham foydalidir: null hozirda yaroqsiz yoki biron sababga ko'ra mavjud bo'lmagan qiymatdir.
Muammo aslida kontseptsiyada emas, balki muayyan amalga oshirishda. Shunday qilib, Rust nulllarga ega emas, lekin u mavjud yoki yo'q qiymat tushunchasini kodlay oladigan enumga ega. Bu enum Option<T> bo'lib, u standart kutubxona tomonidan quyidagicha aniqlanadi:
#![allow(unused)] fn main() { enum Option<T> { None, Some(T), } }
Option<T> enumi shunchalik foydaliki, u hatto muqaddimaga ham kiritilgan; uni aniq doiraga kiritishingiz shart emas. Uning variantlari ham muqaddima tarkibiga kiritilgan: Some va None dan Option:: prefiksisiz bevosita foydalanishingiz mumkin. Option<T> enum hali ham oddiy enum bo'lib, Some(T) va None hali ham Option<T> turidagi variantlardir.
<T> sintaksisi Rustning oʻziga xos xususiyati boʻlib, biz hali gaplashmaganmiz. Bu umumiy turdagi parametr va biz 10-bobda genericlarni batafsil ko'rib chiqamiz.
Hozircha siz bilishingiz kerak bo'lgan narsa shuki, <T> Option enumining Some varianti har qanday turdagi ma'lumotlarning bir qismini saqlashi mumkinligini va o'rniga qo'llaniladigan har bir konkret turni bildiradi. T umumiy Option<T> turini boshqa turga aylantiradi. Raqam turlari va qator turlarini saqlash uchun Option qiymatlaridan foydalanishga misollar keltiramiz:
fn main() { let raqam = Some(5); let belgi = Some('e'); let yoq_raqam: Option<i32> = None; }
raqam turi - Option<i32>. belgi turi Option<char> bo'lib, u boshqa tur. Rust bu turlarni aniqlashi mumkin, chunki biz Some variantida qiymat belgilaganmiz. yoq_raqam uchun Rust bizdan umumiy Option turiga izoh berishimizni talab qiladi: kompilyator faqat None qiymatiga qarab mos keladigan Some varianti qanday turga ega bo'lishini aniqlay olmaydi. Bu yerda biz Rustga aytamizki, biz yoq_raqam Option<i32> turida bo'lishini nazarda tutamiz.
Agar bizda Some qiymati bo'lsa, biz qiymat mavjud ekanligini va qiymat Some ichida saqlanishini bilamiz. Agar bizda None qiymati bo'lsa, u qaysidir ma'noda null bilan bir xil narsani anglatadi: bizda haqiqiy qiymat yo'q. Xo'sh, nega Option<T> nullga ega bo'lishdan yaxshiroq?
Xulosa qilib aytganda, Option<T> va T (bu erda T har qanday tur bo'lishi mumkin) har xil turdagi, chunki kompilyator bizga Option<T> qiymatidan foydalanishga ruxsat bermaydi, go'yo bu haqiqiy qiymat. Masalan, bu kod kompilyatsiya qilinmaydi, chunki u Option<i8>ga i8 qo`shishga harakat qilmoqda:
fn main() {
let x: i8 = 5;
let y: Option<i8> = Some(5);
let natija = x + y;
}Agar biz ushbu kodni ishlatsak, biz quyidagi kabi xato xabarini olamiz:
$ cargo run
Compiling enums v0.1.0 (file:///projects/enums)
error[E0277]: cannot add `Option<i8>` to `i8`
--> src/main.rs:5:17
|
5 | let natija = x + y;
| ^ no implementation for `i8 + Option<i8>`
|
= help: the trait `Add<Option<i8>>` is not implemented for `i8`
= help: the following other types implement trait `Add<Rhs>`:
<&'a i8 as Add<i8>>
<&i8 as Add<&i8>>
<i8 as Add<&i8>>
<i8 as Add>
For more information about this error, try `rustc --explain E0277`.
error: could not compile `enums` due to previous error
Kuchli! Aslida, bu xato xabari Rust i8 va Option<i8> ni qanday qo'shishni tushunmasligini anglatadi, chunki ular turli xil. Rustda i8 kabi turdagi qiymatga ega bo'lsak, kompilyator bizda har doim haqiqiy qiymatga ega bo'lishini ta'minlaydi. Ushbu qiymatdan foydalanishdan oldin nullni tekshirmasdan ishonch bilan davom etishimiz mumkin. Faqat bizda Option<i8> (yoki qanday turdagi qiymat bilan ishlayotgan bo'lishimizdan qat'iy nazar) mavjud bo'lganda, biz qiymatga ega bo'lmasligimizdan xavotirlanishimiz kerak va kompilyator qiymatdan foydalanishdan oldin bu holatni hal qilishimizga ishonch hosil qiladi.
Boshqacha qilib aytganda, T amallarini bajarishdan oldin Option<T>ni T ga aylantirishingiz kerak. Umuman olganda, bu null bilan bog'liq eng keng tarqalgan muammolardan birini hal qilishga yordam beradi: agar biror narsa bo'lsa, u null emas deb taxmin qilish.
Null bo'lmagan qiymatni noto'g'ri qabul qilish xavfini yo'q qilish kodingizga ko'proq ishonch hosil qilishingizga yordam beradi. Null bo'lishi mumkin bo'lgan qiymatga ega bo'lish uchun, siz ushbu qiymatning turini Option<T> qilib aniq belgilashingiz kerak.
Keyin, ushbu qiymatdan foydalanganda, qiymat null bo'lsa, ishni aniq ko'rib chiqishingiz talab qilinadi. Qiymat Option<T> bo'lmagan turga ega bo'lgan har bir joyda, qiymat null emas deb ishonch bilan taxmin qilishingiz mumkin. Bu Rust uchun nullning tarqalishini cheklash va Rust kodining xavfsizligini oshirish uchun ataylab qilingan dizayn qarori edi.
Xo'sh, Option<T> turidagi qiymatga ega bo'lganingizda, Some variantidan T qiymatini qanday qilib olish mumkin, shunda siz ushbu qiymatdan foydalanishingiz mumkin? Option<T> enumi turli vaziyatlarda foydali boʻlgan koʻp sonli usullarga ega; siz ularni uning hujjatlarida tekshirishingiz mumkin. Option<T> dagi metodlar bilan tanishish Rust bilan sayohatingizda juda foydali bo`ladi.
Umuman olganda, Option<T> qiymatidan foydalanish uchun siz har bir variantni boshqaradigan kodga ega bo'lishni xohlaysiz. Siz faqat Some(T) qiymatiga ega bo'lganingizda ishlaydigan ba'zi kodni xohlaysiz va bu kod ichki T dan foydalanishga ruxsat etiladi. Agar sizda None qiymati bo'lsa va bu kodda T qiymati bo'lmasa, ishlaydigan boshqa kod ham kerak bo'ladi. match ifodasi control flow konstruksiyasi bo‘lib, u enumlar bilan foydalanilganda aynan shunday qiladi: u enumning qaysi variantiga ega bo‘lishiga qarab turli xil kodlarni ishga tushiradi va bu kod mos keladigan qiymat ichidagi ma’lumotlardan foydalanishi mumkin.
match Control Flow konstruksiyasi
Rust match deb nomlangan juda kuchli control flow konstruksiyasiga ega, bu sizga qiymatni bir qator patternlar bilan solishtirish va keyin qaysi pattern mos kelishiga qarab kodni bajarish imkonini beradi. Patternlar literal qiymatlar, o'zgaruvchilar nomlari, wildcardlar va boshqa ko'plab narsalardan iborat bo'lishi mumkin; 18-bobda har xil turdagi patternlar va ular bajaradigan ishlar yoritilgan. matchning kuchi patternlarning ifodaliligidan va kompilyator barcha mumkin bo'lgan holatlar ko'rib chiqilishini tasdiqlashidan kelib chiqadi.
match iborasini tanga saralash mashinasiga o'xshatib tasavvur qiling: tangalar bo'ylab turli o'lchamdagi teshiklari bo'lgan yo'ldan pastga siljiydi va har bir tanga o'zi mos keladigan birinchi teshikdan tushadi. Xuddi shu tarzda, qiymatlar match dagi har bir patterndan o'tadi va birinchi patternda qiymat “fits,”, qiymat bajarish paytida ishlatiladigan tegishli kod blokiga tushadi.
Tangalar haqida gap ketganda, keling, ularni match yordamida misol qilib olaylik! Biz noma'lum AQSH tangasini oladigan funksiyani yozishimiz mumkin va xuddi sanash mashinasiga o'xshab uning qaysi tanga ekanligini aniqlaydi va 6-3 ro'yxatda ko'rsatilganidek, uning qiymatini sentlarda qaytaradi.
enum Tanga { Penny, Nickel, Dime, Quarter, } fn sentdagi_qiymat(tanga: Tanga) -> u8 { match tanga { Tanga::Penny => 1, Tanga::Nickel => 5, Tanga::Dime => 10, Tanga::Quarter => 25, } } fn main() {}
Ro'yxat 6-3: Enum va match ifodasi, uning namunalari sifatida enumning variantlari mavjud
Keling, sentdagi_qiymat funksiyasidagi match ni ajratamiz. Avval biz match kalit so'zidan keyin ifodani keltiramiz, bu holda bu qiymat tanga bo'ladi. Bu if bilan ishlatiladigan shartli ifodaga juda o'xshaydi, lekin
katta farq bor: if bilan shart mantiqiy qiymatga baholanishi kerak, ammo bu yerda u har qanday turdagi bo'lishi mumkin. Ushbu misoldagi tanga turi biz birinchi qatorda belgilagan Tanga enumidir.
Keyingi match armlari. Arm ikki qismdan iborat: pattern va ba'zi kod. Bu yerdagi birinchi arm Tanga::Penny qiymati boʻlgan patternga ega, soʻngra ishlash uchun pattern va kodni ajratuvchi => operatori. Bu holatda kod faqat 1 qiymatidan iborat. Har bir arm keyingisidan vergul bilan ajratiladi.
match ifodasi bajarilganda, natijaviy qiymatni har bir armning patterniga solishtiradi. Agar pattern qiymatga mos kelsa, ushbu pattern bilan bog'langan kod bajariladi. Agar bu pattern qiymatga mos kelmasa, ijro tanga saralash mashinasida bo'lgani kabi keyingi armda davom etadi.
Bizda qancha arm kerak bo'lsa, shuncha arm bo'lishi mumkin: 6-3 ro'yxatda bizning matchimizda to'rtta arm bor.
Har bir arm bilan bog'langan kod ifodadir va mos keladigan qismdagi ifodaning natijaviy qiymati butun match ifodasi uchun qaytariladigan qiymatdir.
Agar mos keladigan arm kodi qisqa bo'lsa, biz odatda jingalak qavslardan foydalanmaymiz, chunki bu ro'yxat 6-3da bo'lgani kabi, har bir arm shunchaki qiymat qaytaradi. Agar siz mos keladigan chiziqda bir nechta kod qatorlarini ishlatmoqchi bo'lsangiz, jingalak qavslardan foydalaning va armdan keyingi vergul ixtiyoriy bo'ladi. Masalan, quyidagi kodda Omadli tanga! metod har safar Tanga::Penny bilan chaqirilganda, lekin baribir blokning oxirgi qiymatini qaytaradi, 1:
enum Tanga { Penny, Nickel, Dime, Quarter, } fn sentdagi_qiymat(tanga: Tanga) -> u8 { match tanga { Tanga::Penny => { println!("Omadli tanga!"); 1 } Tanga::Nickel => 5, Tanga::Dime => 10, Tanga::Quarter => 25, } } fn main() {}
Qiymatlarni bog'laydigan patternlar
match armlarining yana bir foydali xususiyati shundaki, ular patternga mos keladigan qiymatlarning qismlarini bog'lashlari mumkin. Enum variantlaridan qiymatlarni shunday chiqarishimiz mumkin.
Misol tariqasida, uning ichida ma'lumotlarni saqlash uchun enum variantlarimizdan birini o'zgartiraylik.
1999 yildan 2008 yilgacha Qo'shma Shtatlar bir tomondan 50 shtatning har biri uchun turli dizayndagi tangalarni bosib chiqardi. Boshqa hech qanday tangalar davlat dizayniga ega emas, shuning uchun faqat quarterlarda bunday qo'shimcha qiymat mavjud. Biz ushbu maʼlumotni Quarter variantini uning ichida saqlangan UsState qiymatini kiritish uchun oʻzgartirish orqali enumga qoʻshishimiz mumkin, biz buni 6-4 roʻyxatda qilganmiz.
#[derive(Debug)] // so we can inspect the state in a minute enum UsState { Alabama, Alaska, // --snip-- } enum Tanga { Penny, Nickel, Dime, Quarter(UsState), } fn main() {}
Roʻyxat 6-4: Quarter varianti ham UsState qiymatiga ega boʻlgan Tanga enumi
Tasavvur qiling-a, sizning do'stingiz barcha 50 shtatdan quarter yig'ishga harakat qilmoqda. Biz tangalar turi bo'yicha saralashimiz bilan birga, agar do'stimizda yo'q bo'lsa, ular uni o'z kollektsiyasiga qo'shishlari uchun har quarter bilan bog'liq shtat nomini ham chaqiramiz.
Ushbu kod uchun match ifodasida biz Tanga::Quarter varianti qiymatlariga mos keladigan patternga shtat deb nomlangan o'zgaruvchini qo‘shamiz. Tanga::Quarter mos kelganda, shtat o'zgaruvchisi o'sha quarter holati qiymatiga bog'lanadi. Keyin biz ushbu arm uchun kodda shtat dan foydalanishimiz mumkin, masalan:
#[derive(Debug)] enum UsState { Alabama, Alaska, // --snip-- } enum Tanga { Penny, Nickel, Dime, Quarter(UsState), } fn sentdagi_qiymat(tanga: Tanga) -> u8 { match tanga { Tanga::Penny => 1, Tanga::Nickel => 5, Tanga::Dime => 10, Tanga::Quarter(shtat) => { println!("{:?} dan shtat quarter!", shtat); 25 } } } fn main() { sentdagi_qiymat(Tanga::Quarter(UsState::Alaska)); }
Agar biz sentdagi_qiymat(Tanga::Quarter(UsState::Alaska)) deb ataydigan bo'lsak, tanga Tanga::Quarter(UsState::Alaska) bo'ladi. Ushbu qiymatni har bir match armi bilan solishtirganda, biz Tanga::Quarter(shtat) ga yetguncha ularning hech biri mos kelmaydi. O'sha paytda shtat uchun majburiy UsState::Alaska qiymati bo'ladi. Keyin biz bu bog'lanishni println! ifodasida qo'llashimiz mumkin, shu bilan Quarter uchun Tanga enum variantidan ichki holat qiymatini olamiz.
Option<T> uchun Match
Oldingi bo'limda biz Option<T> dan foydalanilganda Some holatidan ichki T qiymatini olishni xohladik; Biz, shuningdek, Tanga enum bilan qilganimizdek, match yordamida Option<T>ni boshqarishimiz mumkin! Tangalarni solishtirish o'rniga, biz Option<T> variantlarini solishtiramiz, lekin match ifodasining ishlash usuli bir xil bo'lib qoladi.
Aytaylik, biz Option<i32> ni oladigan funksiya yozmoqchimiz va agar ichida qiymat bo'lsa, bu qiymatga 1 qo'shiladi. Agar ichida qiymat bo'lmasa, funktsiya None qiymatini qaytarishi va hech qanday operatsiyani bajarishga urinmasligi kerak.
Ushbu funktsiyani yozish juda oson, match tufayli va 6-5-Ro'yxatga o'xshaydi.
fn main() { fn bir_qoshish(x: Option<i32>) -> Option<i32> { match x { None => None, Some(i) => Some(i + 1), } } let besh = Some(5); let olti = bir_qoshish(besh); let yoq = bir_qoshish(None); }
Roʻyxat 6-5: Optionda match ifodasidan foydalanadigan funksiya
Keling, bir_qoshish ning birinchi bajarilishini batafsilroq ko'rib chiqamiz. Biz bir_qoshish(besh) ni chaqirganimizda, bir_qoshish tanasidagi x o'zgaruvchisi Some(5) qiymatiga ega bo'ladi. Keyin biz buni har bir matchning armi bilan taqqoslaymiz:
fn main() {
fn bir_qoshish(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let besh = Some(5);
let olti = bir_qoshish(besh);
let yoq = bir_qoshish(None);
}Some(5) qiymati None patterniga mos kelmaydi, shuning uchun keyingi armga o'tamiz:
fn main() {
fn bir_qoshish(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let besh = Some(5);
let olti = bir_qoshish(besh);
let yoq = bir_qoshish(None);
}Some(5) ga Some(i) pattern mos keladimi? Ha bu shunday! Bizda ham xuddi shunday variant bor. Keyin i o'zgaruvchisi Some ichidagi qiymatga bog'lanadi, shuning uchun i 5 qiymatini oladi. Shundan so'ng match armidagi kod bajariladi, shuning uchun biz i qiymatiga 1 qo'shamiz va ichida jami 6 bo'lgan yangi Some qiymatini yaratamiz.
Keling, 6-5-Ro'yxatdagi bir_qoshish ning ikkinchi chaqiruvini ko'rib chiqaylik, bunda x None. Biz match ga kiramiz va birinchi arm bilan taqqoslaymiz:
fn main() {
fn bir_qoshish(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let besh = Some(5);
let olti = bir_qoshish(besh);
let yoq = bir_qoshish(None);
}Bu mos keladi! Qo'shiladigan qiymat yo'q, shuning uchun dastur to'xtaydi va => o'ng tomonidagi None qiymatini qaytaradi. Birinchi arm mos kelganligi sababli, boshqa armlar taqqoslanmaydi.
match va enumlarni birlashtirish ko'p holatlarda foydalidir. Rust kodida siz ushbu patterni juda ko'p ko'rasiz: enum bilan match, o'zgaruvchini ichidagi ma'lumotlarga bog'lang va keyin unga asoslangan kodni bajaring. Avvaliga bu biroz qiyin, lekin ko'nikkaningizdan so'ng uni barcha tillarda bo'lishini xohlaysiz. Bu har doim foydalanuvchilarning sevimli texnikasi.
Match barcha qiymat variantlarini qamrab oladi
Biz muhokama qilishimiz kerak bo'lgan match ning yana bir jihati bor: arm patterlari barcha imkoniyatlarni qamrab olishi kerak. Xatoga ega va kompilyatsiya qilinmaydigan bir_qoshish funksiyamizning ushbu versiyasini ko'rib chiqing:
fn main() {
fn bir_qoshish(x: Option<i32>) -> Option<i32> {
match x {
Some(i) => Some(i + 1),
}
}
let besh = Some(5);
let olti = bir_qoshish(besh);
let yoq = bir_qoshish(None);
}Biz None holatini ko‘rib chiqmadik, shuning uchun bu kod xatolikka olib keladi. Yaxshiyamki, bu xato Rust qanday tutishni biladi. Agar biz ushbu kodni kompilyatsiya qilishga harakat qilsak, biz ushbu xatoni olamiz:
$ cargo run
Compiling enums v0.1.0 (file:///projects/enums)
error[E0004]: non-exhaustive patterns: `None` not covered
--> src/main.rs:3:15
|
3 | match x {
| ^ pattern `None` not covered
|
note: `Option<i32>` defined here
--> /rustc/d5a82bbd26e1ad8b7401f6a718a9c57c96905483/library/core/src/option.rs:518:1
|
= note:
/rustc/d5a82bbd26e1ad8b7401f6a718a9c57c96905483/library/core/src/option.rs:522:5: not covered
= note: the matched value is of type `Option<i32>`
help: ensure that all possible cases are being handled by adding a match arm with a wildcard pattern or an explicit pattern as shown
|
4 ~ Some(i) => Some(i + 1),
5 ~ None => todo!(),
|
For more information about this error, try `rustc --explain E0004`.
error: could not compile `enums` due to previous error
Rust biz barcha mumkin bo'lgan holatlarni qamrab olmaganimizni biladi va hatto qaysi patterni unutganimizni biladi! Rust-da matchlar to'liq: kod to'g'ri bo'lishi uchun biz barcha mumkin bo'lgan holatlarni qamrab olishimiz kerak. Ayniqsa, Option<T> holatida, Rust bizni None holatini aniq ko'rib chiqishni unutib qo'yishimizga to'sqinlik qilsa, bizni null bo'lishi mumkin bo'lgan qiymatga ega bo`lishimizdan himoya qiladi, shunday qilib, ilgari muhokama qilingan milliard dollarlik xatoni imkonsiz qiladi.
Hammasini ushlash patternlari va _ placeholder
Enumlardan foydalanib, biz bir nechta ma'lum qiymatlar uchun maxsus harakatlarni amalga oshirishimiz mumkin, ammo boshqa barcha qiymatlar uchun bitta standart amalni bajaramiz. Tasavvur qiling-a, biz o'yinni amalga oshirmoqdamiz, unda 3 ta o'yinda o'yinchi qimirlamaydi, aksincha, chiroyli yangi shlyapa oladi. Agar siz 7 ni aylantirsangiz, o'yinchingiz chiroyli shlyapasini yo'qotadi. Boshqa barcha qiymatlar uchun o'yinchi o'yin taxtasida shuncha bo'sh joyni siljitadi. Mana, bu mantiqni amalga oshiradigan match, bu erda narda toshlarni o'rash natijasi tasodifiy qiymat emas, balki qattiq kodlangan va mantiqning qolgan qismi jismlarsiz funktsiyalar bilan ifodalanadi, chunki ularni amalga oshirish ushbu doiradan tashqarida. misol:
fn main() { let narda_toshi = 9; match narda_toshi { 3 => chiroyli_shlyapa_qoshish(), 7 => chiroyli_shlyapani_ochirish(), boshqa => player_harakati(boshqa), } fn chiroyli_shlyapa_qoshish() {} fn chiroyli_shlyapani_ochirish() {} fn player_harakati(bosh_joylar: u8) {} }
Dastlabki ikkita arm uchun patternlar 3 va 7 harfli qiymatlardir. Boshqa barcha mumkin bo'lgan qiymatlarni qamrab oladigan oxirgi arm uchun pattern biz boshqa deb nomlash uchun tanlagan o'zgaruvchidir. boshqa arm uchun ishlaydigan kod o'zgaruvchini player_harakati funksiyasiga o'tkazish orqali ishlatadi.
Ushbu kod kompilatsiya qilinadi, garchi biz u8 ga ega bo'lishi mumkin bo'lgan barcha qiymatlarni sanab o'tmagan bo'lsak ham, chunki oxirgi pattern maxsus sanab o'tilmagan barcha qiymatlarga mos keladi. Bu match toʻliq boʻlishi kerakligi haqidagi talabga javob beradi. E'tibor bering, biz armni eng oxirgi qo'yishimiz kerak, chunki patternlar tartibda baholanadi. Agar biz ushlovchi armni oldinroq qo'ysak, boshqa armlar hech qachon run bo'lmaydi, shuning uchun biz hammamizni tutgandan keyin arm qo'shsak, Rust bizni ogohlantiradi!
Rustda umumiy patterda qiymatdan foydalanishni istamaganimizda foydalanish mumkin bo'lgan pattern ham mavjud: _ - har qanday qiymatga mos keladigan va bu qiymatga bog'lanmaydigan maxsus pattern. Bu Rustga biz qiymatdan foydalanmasligimizni bildiradi, shuning uchun Rust bizni foydalanilmagan o'zgaruvchi haqida ogohlantirmaydi.
Keling, o'yin qoidalarini shunday o'zgartiraylik: agar 3 yoki 7 dan boshqa narda toshi paydo bo'lsa, siz yana boshqatdan aylantirib tashlashingiz kerak. Biz endi catch-all qiymatidan foydalanishimiz shart emas, shuning uchun biz kodimizni boshqa deb nomlangan o‘zgaruvchi o‘rniga _ ishlatish uchun o‘zgartirishimiz mumkin:
fn main() { let narda_toshi = 9; match narda_toshi { 3 => chiroyli_shlyapa_qoshish(), 7 => chiroyli_shlyapani_ochirish(), _ => qaytadan(), } fn chiroyli_shlyapa_qoshish() {} fn chiroyli_shlyapani_ochirish() {} fn qaytadan() {} }
Bu misol, shuningdek, to'liqlik talabiga javob beradi, chunki biz oxirgi qismdagi barcha boshqa qiymatlarni e'tiborsiz qoldiramiz; biz hech narsani unutmadik.
Nihoyat, biz o'yin qoidalarini yana bir bor o'zgartiramiz, shunda siz 3 yoki 7 ni o'tkazmaguningizcha sizning navbatingizda hech narsa sodir bo'lmaydi. Biz buni birlik qiymatidan (biz "Tuple turi" section da aytib o'tgan bo'sh tuple turi) _ armi bilan birga keladigan kod sifatida ifodalashimiz mumkin:
fn main() { let narda_toshi = 9; match narda_toshi { 3 => chiroyli_shlyapa_qoshish(), 7 => chiroyli_shlyapani_ochirish(), _ => (), } fn chiroyli_shlyapa_qoshish() {} fn chiroyli_shlyapani_ochirish() {} }
Bu yerda biz Rustga aniq aytamizki, biz avvalgi armdagi patternga mos kelmaydigan boshqa qiymatdan foydalanmaymiz va bu holda hech qanday kodni ishga tushirishni xohlamaymiz.
18-bobda biz ko'rib chiqadigan patternlar va match haqida ko'proq ma'lumot bor.
Hozircha biz if let sintaksisiga o‘tamiz, bu match ifodasi juda batafsil bo'lgan holatlarda foydali bo'lishi mumkin.
if let bilan Control Flow
if let sintaksisi sizga if va let ni birlashtirib, qolganlarini e'tiborsiz qoldirib, bitta patternga mos keladigan qiymatlarni boshqarishning kamroq batafsil metodiga imkon beradi. 6-6 ro'yxatdagi dasturni ko'rib chiqaylik, u max_sozlama o'zgaruvchisidagi Variant<u8> qiymatiga mos keladigan, lekin Some varianti boʻlsagina kodni bajarishni xohlaydigan dasturni koʻrib chiqamiz.
fn main() { let max_sozlama = Some(3u8); match max_sozlama { Some(max) => println!("Maksimal {} qilib sozlangan", max), _ => (), } }
Ro'yxat 6-6. Qiymat Some bo'lsagina kodni bajaradigan match ifoda
Agar qiymat Some bo'lsa, biz qiymatni patterndagi max o'zgaruvchisiga bog'lash orqali Some variantidagi qiymatni chop qilamiz. Biz None qiymati bilan hech narsa qilishni xohlamaymiz. match ifodasini qondirish uchun faqat bitta variantni qayta ishlagandan so‘ng _ => () qo‘shishimiz kerak, bu esa qo‘shish uchun zerikarli boilerplate koddir.
Buning o'rniga, biz buni qisqaroq qilib if let yordamida yozishimiz mumkin. Quyidagi kod 6-6 ro'yxatdagi match bilan bir xil ishlaydi:
fn main() { let max_sozlama = Some(3u8); if let Some(max) = max_sozlama { println!("Maksimal {} qilib sozlangan", max); } }
if let sintaksisi teng belgisi bilan ajratilgan pattern va ifodani oladi. U xuddi match bilan ishlaydi, bunda ifoda matchga beriladi va pattern uning birinchi armi hisoblanadi. Bunday holda, pattern Some(max) bo'lib, max Some ichidagi qiymatga bog'lanadi. Shundan so'ng biz if let blokining tanasida max dan xuddi mos keladigan match armida max dan foydalanganimiz kabi foydalanishimiz mumkin. Qiymat patternga mos kelmasa, if let blokidagi kod ishga tushmaydi.
if let dan foydalanish kamroq yozish, kamroq chekinish va kamroq kodli kodni bildiradi.
Biroq, siz match amal qiladigan to'liq tekshirishni yo'qotasiz. match va if let o‘rtasida tanlov qilish sizning muayyan vaziyatingizda nima qilayotganingizga va ixchamlikka ega bo‘lish to‘liq tekshirishni yo‘qotish uchun to‘g‘ri kelishilganligiga bog‘liq.
Boshqacha qilib aytganda, siz if let konstruktsiyasini match uchun sintaktik shakar sifatida o'ylab ko'rishingiz mumkin, agar kiritilgan qiymat bitta patterga mos kelsa va boshqa barcha qiymatlarga e'tibor bermasa, kodni bajaradi.
Biz elseni if let bilan kiritishimiz mumkin. else bilan birlashtirilgan kod bloki if let va elsega ekvivalent bo‘lgan match ifodasidagi _ registriga mos keladigan kod bloki bilan bir xil. 6-4 roʻyxatdagi Tanga definitionni eslang, bunda Quarter varianti ham UsState qiymatiga ega edi. Agar biz quarterlarning holatini e'lon qilishda ko'rgan barcha quarter bo'lmagan tangalarni sanashni istasak, buni quyidagi kabi match ifodasi bilan qilishimiz mumkin:
#[derive(Debug)] enum UsState { Alabama, Alaska, // --snip-- } enum Tanga { Penny, Nickel, Dime, Quarter(UsState), } fn main() { let tanga = Tanga::Penny; let mut hisobchi = 0; match tanga { Tanga::Quarter(shtat) => println!("{:?} dan shtat kvartal!", shtat), _ => hisobchi += 1, } }
Yoki if let va else ifodalaridan foydalanishimiz mumkin, masalan:
#[derive(Debug)] enum UsState { Alabama, Alaska, // --snip-- } enum Tanga { Penny, Nickel, Dime, Quarter(UsState), } fn main() { let tanga = Tanga::Penny; let mut hisobchi = 0; if let Tanga::Quarter(shtat) = tanga { println!("{:?} dan shtat kvartal!", shtat); } else { hisobchi += 1; } }
Agar dasturingizda match yordamida ifodalash uchun juda batafsil mantiq mavjud bo'lsa, Rust toolboxda if let ham mavjudligini unutmang.
Xulosa
Endi biz sanab o'tilgan qiymatlar to'plamidan biri bo'lishi mumkin bo'lgan maxsus turlarni yaratish uchun enumlardan qanday foydalanishni ko'rib chiqdik. Biz standart kutubxonaning Option<T> turi xatolarni oldini olish uchun type tizimidan qanday foydalanishni ko'rsatdik. Enum qiymatlari ichida ma'lumotlar mavjud bo'lsa, siz qancha holatlarni ko'rib chiqishingiz kerakligiga qarab, ushbu qiymatlarni ajratib olish va ishlatish uchun match yoki if let dan foydalanishingiz mumkin.
Rust dasturlaringiz endi structlar va enumlar yordamida domeningizdagi tushunchalarni ifodalashi mumkin. API-da foydalanish uchun maxsus turlarni yaratish turdagi xavfsizligini ta'minlaydi: kompilyator sizning funksiyalaringiz faqat har bir funktsiya kutgan turdagi qiymatlarni olishiga ishonch hosil qiladi.
Foydalanuvchilaringizga foydalanish uchun qulay va faqat sizning foydalanuvchilarga nima kerakligini aniq ko'rsatadigan yaxshi tashkil etilgan API taqdim etish uchun endi Rust modullariga murojaat qilaylik.
O'sib borayotgan loyihalarni paketlar, cratelar va modullar bilan boshqarish
Katta dasturlarni yozganingizda, kodingizni tartibga solish tobora muhim ahamiyat kasb etadi. Tegishli funksiyalarni guruhlash va kodni alohida xususiyatlar bilan ajratish orqali siz ma'lum bir xususiyatni amalga oshiradigan kodni qayerdan topish va funksiya qanday ishlashini o'zgartirish uchun qayerga borish kerakligini aniqlaysiz.
Biz hozirgacha yozgan dasturlar bitta faylda bitta modulda bo'lgan. Loyiha o'sib borishi bilan siz kodni bir nechta modullarga va keyin bir nechta fayllarga bo'lish orqali tartibga solishingiz kerak. Paketda bir nechta binary cratelar va ixtiyoriy ravishda bitta kutubxona cratesi bo'lishi mumkin. Paket o'sishi bilan siz qismlarni alohida cratelarga ajratib olishingiz mumkin, ular tashqi bog'liqlikka aylanadi. Ushbu bo'lim ushbu texnikaning barchasini o'z ichiga oladi. Birgalikda rivojlanadigan o'zaro bog'liq paketlar to'plamini o'z ichiga olgan juda katta loyihalar uchun Cargo workspacelarni taqdim etadi, biz ularni 14-bobdagi "Cargo Workspacelari" bo'limida ko'rib chiqamiz.
Shuningdek, biz kodni yuqoriroq darajada qayta ishlatish imkonini beruvchi implement tafsilotlarini muhokama qilamiz: operatsiyani amalga oshirganingizdan so'ng, boshqa kod dastur qanday ishlashini bilmasdan kodingizni umumiy interfeysi orqali chaqirishi mumkin. Kodni yozish usuli qaysi qismlar boshqa koddan foydalanishi uchun public ekanligini va qaysi qismlar o'zgartirish huquqiga ega bo'lgan private implement tafsilotlarini belgilaydi. Bu yodda tutish kerak bo'lgan tafsilotlar miqdorini cheklashning yana bir usuli.
Tegishli tushuncha - bu scope: kod yoziladigan ichki kontekstda "scope" deb belgilangan nomlar to'plami mavjud. Kodni o'qish, yozish va kompilyatsiya qilishda dasturchilar va kompilyatorlar ma'lum bir nuqtadagi ma'lum bir nom o'zgaruvchiga, funksiyaga, structga, enumga, modulga, constantaga yoki boshqa elementga tegishli ekanligini va bu element nimani anglatishini bilishlari kerak. Siz scopelarni yaratishingiz va qaysi nomlar doirasida yoki tashqarida ekanligini o'zgartirishingiz mumkin. Bir xil nomdagi ikkita elementni bir xil scopeda bo'lishi mumkin emas; nom ziddiyatlarini hal qilish uchun tollar mavjud.
Rust sizga kodingizning tuzilishini boshqarish imkonini beruvchi bir qator xususiyatlarga ega, jumladan, qaysi tafsilotlar oshkor bo'lishi, qaysi tafsilotlar shaxsiy va dasturlaringizdagi har bir sohada qanday nomlar mavjudligi. Ba'zan birgalikda modul tizimi deb ataladigan bu xususiyatlar quyidagilarni o'z ichiga oladi:
- Paketlar: Cratelarni qurish, sinab ko'rish va almashish imkonini beruvchi cargo xususiyati
- Cratelar: Kutubxona yoki bajariladigan faylni yaratuvchi modullar daraxti
- Modullar va use: Fayl yoʻllarning tashkil etilishi, koʻlami va maxfiyligini nazorat qilish imkonini beradi
- Pathlar: Struct, funksiya yoki modul kabi elementni nomlash usuli
Ushbu bobda biz ushbu xususiyatlarning barchasini ko'rib chiqamiz, ularning qanday o'zaro ta'sirini muhokama qilamiz va qamrovni boshqarish uchun ulardan qanday foydalanishni tushuntiramiz. Oxir-oqibat, siz modul tizimi haqida yaxshi tushunchaga ega bo'lishingiz va professional kabi sohalar bilan ishlashingiz kerak!
Paketlar va Cratelar
Biz qamrab oladigan modul tizimining birinchi qismlari paketlar va cratelardir.
Crate - bu Rust kompilyatori bir vaqtning o'zida ko'rib chiqadigan eng kichik kod miqdori. Agar siz cargo o'rniga rustc ni ishga tushirsangiz va bitta manba faylga o'tsangiz ham (biz 1-bob, "Rust dasturini yozish va ishga tushirish"da qilganimiz kabi), kompilyator bu faylni crate sifatida ko'radi. Cratelar modullarni o'z ichiga olishi mumkin va modullar crate bilan tuzilgan boshqa fayllarda aniqlanishi mumkin, buni keyingi bo'limlarda ko'rib chiqamiz.
Crate ikkita shakldan birida bo'lishi mumkin: binary crate yoki kutubxona cratesi.
Binary cratelar - bu buyruq qatori dasturi yoki server kabi ishga tushirishingiz mumkin bo'lgan bajariladigan faylga kompilyatsiya qilishingiz mumkin bo'lgan dasturlar. Har birida bajariladigan fayl ishga tushganda nima sodir bo'lishini belgilaydigan main funksiyasi bo'lishi kerak. Biz hozirgacha yaratgan barcha cratelar binary cratelar edi.
Kutubxona cratelari main funksiyaga ega emas va ular bajariladigan faylga kompilyatsiya qilinmaydi. Buning o'rniga, ular bir nechta loyihalar bilan bo'lishish uchun mo'ljallangan funksionallikni belgilaydi. Misol uchun, biz 2-bobda ishlatgan rand cratesi tasodifiy sonlarni yaratuvchi funksionallikni taʼminlaydi.
Ko'pincha Rustaceanlar “crate” deganda, ular kutubxona crateni anglatadi va ular "kutubxona" ning umumiy dasturlash tushunchasi bilan "crate" dan foydalanadilar.
Crate root bu Rust kompilyatori cratengizning ildiz modulini yaratishni boshlaydigan manba fayldir (biz modullarni “Qo'llanish doirasi va maxfiylikni nazorat qilish uchun modullarni aniqlash” bo‘limida chuqur tushuntiramiz).
Paket - bu bir yoki bir nechta cratelar to'plami bo'lib, u funksiyalar to'plamini ta'minlaydi. Paketda ushbu cratelarni qanday build qilishni tavsiflovchi Cargo.toml fayli mavjud. Cargo - bu sizning kodingizni yaratishda foydalanayotgan buyruq qatori vositasi uchun binary crateni o'z ichiga olgan paket. Cargo paketida binary crate bog'liq bo'lgan kutubxona cratesi ham mavjud. Boshqa loyihalar Cargo buyruq qatori vositasi ishlatadigan mantiqdan foydalanish uchun cargo kutubxonasi cratesiga bog'liq bo'lishi mumkin.
Paket siz xohlagancha ko'p ikkilik binary cratelarni o'z ichiga olishi mumkin, lekin bitta kutubxona cratesidan ko'p bo'lmasligi kerak. Paketda kamida bitta crate bo'lishi kerak, u kutubxona yoki binary crate bo'lishi kerak.
Keling, paketni yaratganimizda nima sodir bo'lishini ko'rib chiqaylik. Birinchidan, biz cargo new buyrug'ini kiritamiz:
$ cargo new mening-paketim
Created binary (application) `mening-paketim` package
$ ls mening-paketim
Cargo.toml
src
$ ls mening-paketim/src
main.rs
Biz cargo new ni ishga tushirgandan so'ng, biz cargo nima yaratganini ko'rish uchun ls dan foydalanamiz. mening-paketim jildida bizga paketni taqdim qiluvchi Cargo.toml fayli mavjud. Shuningdek, main.rs ni o'z ichiga olgan src jildi ham mavjud. Matn muharririda Cargo.toml ni oching va src/main.rs haqida hech qanday eslatma yo‘qligiga e'tibor bering. Cargo, src/main.rs paket bilan bir xil nomga ega binary cratening crate ildizi ekanligi haqidagi konventsiyaga amal qiladi. Xuddi shunday, Cargo ham biladiki, agar paket jildida src/lib.rs bo'lsa, paketda paket bilan bir xil nomdagi kutubxona cratesi mavjud va src/lib.rs uning crate ildizi hisoblanadi. Cargo kutubxona yoki binaryni yaratish uchun cratening ildiz fayllarini rustc ga o'tkazadi.
Bu yerda bizda faqat src/main.rs ni o'z ichiga olgan paket bor, ya'ni u faqat mening-paketim nomli binary crateni o'z ichiga oladi. Agar paketda src/main.rs va src/lib.rs bo'lsa, unda ikkita crate, binary crate va kutubxona cratesi mavjud bo'lib, ikkalasi ham paket bilan bir xil nomga ega. Paketda fayllarni src/bin jildiga joylashtirish orqali bir nechta binary cratelar bo'lishi mumkin: har bir fayl alohida binary crate bo'ladi.
Qo'llanish doirasi va maxfiylikni nazorat qilish uchun modullarni aniqlash
Ushbu bo'limda biz modullar va modul tizimining boshqa qismlari haqida gapiramiz, ya'ni elementlarni nomlash imkonini beruvchi pathlar(yo'llar); pathni qamrab oluvchi use kalit so'zi; va obyektlarni hammaga ochiq qilish(public) uchun pub kalit so'zi. Shuningdek, biz as kalit so'zini, tashqi paketlarni va glob operatorini muhokama qilamiz.
Birinchidan, kelajakda kodingizni tartibga solishda qulay foydalanish uchun qoidalar ro'yxatidan boshlaymiz. Keyin har bir qoidalarni batafsil tushuntiramiz.
Modullar qo'llanmasi
Bu yerda biz modullar, pathlar, use kalit soʻzi va pub kalit soʻzining kompilyatorda qanday ishlashi va koʻpchilik ishlab chiquvchilar oʻz kodlarini qanday tashkil qilishlari haqida qisqacha maʼlumot beramiz. Ushbu bobda biz ushbu qoidalarning har biriga misollarni ko'rib chiqamiz va modullar qanday ishlashini takrorlash uchun yaxshi vaqt.
- Cratening ildizidan boshlang: Crateni kompilyatsiya qilishda kompilyator kodni kompilyatsiya qilish uchun avval cratening ildiz fayliga (odatda kutubxona cratesi uchun src/lib.rs yoki binary crate uchun src/main.rs) qaraydi.
- Modullarni e'lon qilish: Cratening ildiz faylida siz yangi modullarni e'lon qilishingiz mumkin; aytaylik, siz
mod polizbilanpolizmodulini e'lon qilasiz; Kompilyator modul kodini quyidagi joylarda qidiradi:- Inline, jingalak qavs ichida
mod polizdan keyingi nuqta-vergul o'rnini egallaydi - src/poliz.rs faylida
- src/poliz/mod.rs faylida
- Inline, jingalak qavs ichida
- Submodullarni e'lon qilish: Crate ildizidan boshqa har qanday faylda siz submodullarni e'lon qilishingiz mumkin. Masalan, src/poliz.rs da
mod sabzavotlar;deb e`lon qilishingiz mumkin. Kompilyator quyi modul kodini quyidagi joylarda ota-modul uchun nomlangan jilddan qidiradi:- Inline, to'g'ridan-to'g'ri
mod sabzavotlardan keyin, nuqta-vergul o'rniga jingalak qavslar ichida - src/poliz/sabzavotlar.rs faylida
- src/poliz/sabzavotlar/mod.rs faylida
- Inline, to'g'ridan-to'g'ri
- Modullarda kodlash yo'llari: Modul sizning cratengizning bir qismi bo'lgandan so'ng, maxfiylik qoidalari ruxsat bergan bo'lsa, kod yo'lidan foydalanib, xuddi shu cratening istalgan joyidan ushbu moduldagi kodga murojaat qilishingiz mumkin. Misol uchun, poliz sabzavotlari modulidagi
PomidorturiCrate::poliz::sabzavotlar::Pomidorda topiladi. - Private va Public: Modul ichidagi kod standart bo'yicha uning ota-modullaridan maxfiydir. Modulni public qilish uchun uni
modo'rnigapub modbilan e’lon qiling. Public moduldagi elementlarni ham hammaga ochiq qilish uchun ularni e'lon qilishdan oldinpubdan foydalaning. usekalit so'zi: Bir doiradausekalit so'zidan foydalanish uzoq yo'llarning takrorlanishini kamaytirish uchun elementlar uchun taxalluslarni yaratadi.Crate::poliz::sabzavotlar::Pomidorga murojaat qilishi mumkin bo'lgan har qanday sohada sizuse crate::poliz::sabzavotlar::Pomidor;bilan taxallus yaratishingiz mumkin va shundan so'ng siz ushbu turdagi ushbu doirada foydalanish uchunPomidordeb yozishingiz kerak.
Bu yerda biz ushbu qoidalarni aks ettiruvchi orqa_hovli nomli binary crate yaratamiz. Crate jildi, shuningdek, orqa_hovli deb nomlangan, quyidagi fayllar va jildlarni o'z ichiga oladi:
orqa_hovli
├── Cargo.lock
├── Cargo.toml
└── src
├── poliz
│ └── sabzavotlar.rs
├── poliz.rs
└── main.rs
Bu holda cratening ildiz fayli src/main.rs bo'lib, u quyidagilarni o'z ichiga oladi:
Fayl nomi: src/main.rs
use crate::poliz::sabzavotlar::Pomidor;
pub mod poliz;
fn main() {
let ekin = Pomidor {};
println!("Men {:?} o'stiryapman!", ekin);
}pub mod poliz; qatori kompilyatorga src/poliz.rs da topilgan kodni kiritishni aytadi, ya'ni:
Fayl nomi: src/poliz.rs
pub mod sabzavotlar;Bu yerda pub mod sabzavotlar; src/poliz/sabzavotlar.rs dagi kod ham kiritilganligini bildiradi. Quyida misol uchun kod:
#[derive(Debug)]
pub struct Pomidor {}Keling, ushbu qoidalarning tafsilotlari bilan tanishamiz va ularni amalda ko'rsatamiz!
Modullarda tegishli kodlarni guruhlash
Modullar kodni o'qish va qayta foydalanishni osonlashtirish uchun crate ichida tartibga solish imkonini beradi. Modullar bizga elementlarning maxfiyligini boshqarishga ham imkon beradi, chunki modul ichidagi kod standart boʻyicha shaxsiy(private) hisoblanadi. Private elementlar tashqi foydalanish uchun mavjud bo'lmagan ichki dastur tafsilotlari. Biz modullar va ulardagi elementlarni hammaga ochiq qilishni tanlashimiz mumkin, bu esa ularni tashqi koddan foydalanish va ularga bog'liq bo'lishiga imkon beradi.
Misol tariqasida, restoranning funksionalligini ta'minlaydigan kutubxona cratesini yozamiz. Biz funksiyalarning signaturelarini aniqlaymiz, lekin restoranni implement qilishga emas, balki kodni tashkil etishga e'tibor qaratish uchun ularning tanasini bo'sh qoldiramiz.
Restoran sanoatida restoranning ba'zi qismlari uyning old tomoni va boshqalari uyning orqa tomoni deb ataladi. Uyning old tomoni mijozlar joylashgan joy; Bu mezbonlar mijozlarni joylashtiradigan, serverlar buyurtma va to'lovlarni qabul qiladigan va barmenlar ichimliklar tayyorlaydigan joyni o'z ichiga oladi. Uyning orqa tomonda oshpazlar va pishiruvchilar oshxonada ishlaydi, idish-tovoqlarni yuvuvchilar tozalaydi va menejerlar ma'muriy ishlarni bajaradi.
Cratemizni shu tarzda tuzish uchun biz uning funksiyalarini ichki modullarga ajratishimiz mumkin. cargo new restoran --lib ishga tushirish orqali restoran nomli yangi kutubxona yarating; keyin ba'zi modullar va funksiya signaturelarini aniqlash uchun 7-1 ro'yxatidagi kodni src/lib.rs ichiga kiriting. Mana, uyning old qismi:
Fayl nomi: src/lib.rs
mod uyning_oldi {
mod xizmat {
fn navbat_listiga_qoshish() {}
fn stolga_otirish() {}
}
mod serving {
fn buyurtma_olish() {}
fn buyurtma_berish() {}
fn tolovni_qabul_qilish() {}
}
}Roʻyxat 7-1: uyning_oldi moduli, keyin funksiyalarni oʻz ichiga olgan boshqa modullarni oʻz ichiga oladi.
Biz modulni mod kalit so'zidan keyin modul nomi bilan belgilaymiz (bu holda uyning_oldi). Keyin modul tanasi jingalak qavslar ichiga kiradi. Modullar ichida biz boshqa modullarni joylashtirishimiz mumkin, masalan, xizmat va xizmat_korsatish modullari. Modullar, shuningdek, structlar, enumlar, konstantalar, belgilar va 7-1 ro'yxatdagi kabi boshqa elementlar uchun ta'riflarga ega bo'lishi mumkin.
Modullardan foydalanib, biz bir-biriga bog'liq definitionlarni guruhlashimiz va ular nima uchun bog'liqligini nomlashimiz mumkin. Ushbu koddan foydalanadigan dasturchilar barcha definitionlarni o'qib chiqmasdan, guruhlarga asoslangan kodni boshqarishi mumkin, bu ularga tegishli definitionlarni topishni osonlashtiradi. Ushbu kodga yangi funksiya qo'shadigan dasturchilar dasturni tartibli saqlash uchun kodni qayerga joylashtirishni bilishadi.
Yuqorida aytib o'tganimizdek, src/main.rs va src/lib.rs fayllari crate ildiz modullari deb ataladi. Ularning nomlanishining sababi shundaki, bu ikki faylning birortasining mazmuni modul daraxti deb nomlanuvchi crate modul strukturasining ildizida joylashgan crate nomli modulni tashkil qiladi.
7-2 ro'yxatda 7-1 ro'yxatdagi strukturaning modul daraxti ko'rsatilgan.
crate
└── uyning_oldi
├── xizmat
│ ├── navbat_listiga_qoshish
│ └── stolga_otirish
└── xizmat_korsatish
├── buyurtma_olish
├── buyurtma_berish
└── tolov_qilish
7-2 ro'yxat: 7-1 ro'yxatdagi kod uchun modul daraxti
Bu daraxt ba'zi modullar bir-birining ichida qanday joylashishini ko'rsatadi; masalan, xizmat uyasi uyning_oldi ichida. Daraxt shuningdek, ba'zi modullar bir-birining aka-uka ekanligini, ya'ni ular bir modulda aniqlanganligini ko'rsatadi; xizmat va xizmat_korsatish uyning_oldi ichida belgilangan aka-ukalardir. Agar A moduli B modulida joylashgan bo'lsa, biz A moduli B modulining bolasi va B moduli A modulining otasi deb aytamiz. E'tibor bering, butun modul daraxti Crate nomli yashirin modul ostida joylashgan.
Modul daraxti sizga kompyuteringizdagi fayl tizimining jildlar daraxtini eslatishi mumkin; bu juda to'g'ri taqqoslash! Fayl tizimidagi jildlar singari, siz kodingizni tartibga solish uchun modullardan foydalanasiz. Va xuddi jilddagi fayllar singari, bizga modullarimizni topish usuli kerak.
Modul daraxtidagi elementga murojaat qilish yo'llari
Rust-ga modul daraxtidagi elementni qayerdan topish mumkinligini ko'rsatish uchun biz fayl tizimida harakat qilishda qanday yo'l(path) ishlatgan bo'lsak, xuddi shunday yo'ldan foydalanamiz. Funksiyani chaqirish uchun biz uning yo'lini bilishimiz kerak.
Yo'l ikki shaklda bo'lishi mumkin:
- Absolyut yo'l - bu crate ildizidan boshlanadigan to'liq yo'l; tashqi cretedagi kod uchun mutlaq yo'l crate nomidan boshlanadi va joriy cratedagi kod uchun esa
cratebilan boshlanadi.. - N isbiy yo‘l joriy moduldan boshlanadi va joriy modulda
self,superyoki identifikatordan foydalanadi.
Mutlaq va nisbiy yo‘llardan keyin ikki nuqta (::) bilan ajratilgan bir yoki bir nechta identifikatorlar keladi.
7-1 ro'yxatiga qaytsak, biz navbat_listiga_qoshish funksiyasini chaqirmoqchimiz deylik.
Bu so'rash bilan bir xil: navbat_listiga_qoshish funksiyasining yo'li nima?
7-3 ro'yxatda 7-1 ro'yxati mavjud bo'lib, ba'zi modullar va funksiyalar olib tashlangan.
Biz crate ildizida belgilangan yangi restoranda_ovqatlanish funksiyasidan navbat_listiga_qoshish funksiyasini chaqirishning ikkita usulini ko‘rsatamiz. Bu yoʻllar toʻgʻri, ammo bu misolni avvalgidek tuzishga toʻsqinlik qiladigan yana bir muammo bor. Sababini birozdan keyin tushuntiramiz.
restoranda_ovqatlanish funksiyasi kutubxonamizning public API-ning bir qismidir, shuning uchun biz uni pub kalit so'zi bilan belgilaymiz. “pub kalit so'zi bilan yo'llarni ochish” bo‘limida biz pub haqida batafsilroq to‘xtalib o'tamiz.
Fayl nomi: src/lib.rs
mod uyning_oldi {
mod xizmat {
fn navbat_listiga_qoshish() {}
}
}
pub fn restoranda_ovqatlanish() {
// Mutlaq yo'l (Absolute path)
crate::uyning_oldi::xizmat::navbat_listiga_qoshish();
// Nisbiy yo'l (Relative path)
uyning_oldi::xizmat::navbat_listiga_qoshish();
}Ro'yxat 7-3: navbat_listiga_qoshish funksiyasini mutlaq va nisbiy yo'llar yordamida chaqirish
Biz birinchi marta restoranda_ovqatlanish ichida navbat_listiga_qoshish funksiyasini chaqirganimizda mutlaq yo'ldan foydalanamiz. navbat_listiga_qoshish funksiyasi restoranda_ovqatlanish bilan bir xil crateda belgilangan, ya'ni mutlaq yoʻlni boshlash uchun crate kalit soʻzidan foydalanishimiz mumkin. Keyin biz navbat_listiga_qoshish ga o'tgunimizcha ketma-ket modullarning har birini o'z ichiga olamiz. Siz bir xil strukturaga ega fayl tizimini tasavvur qilishingiz mumkin: biz navbat_listiga_qoshish dasturini ishga tushirish uchun /uyning_oldi/xizmat/navbat_listiga_qoshish yo'lini belgilaymiz; crate ildizidan boshlash uchun crate nomidan foydalanish shelldagi fayl tizimi ildizidan boshlash uchun / dan foydalanishga o'xshaydi.
Biz restoranda_ovqatlanish ichida navbat_listiga_qoshish ni ikkinchi marta chaqirganimizda nisbiy yo'ldan foydalanamiz. Yo'l uyning_oldi bilan boshlanadi, modul nomi restoranda_ovqatlanish bilan bir xil modul daraxti darajasida belgilangan. Bu yerda fayl tizimi ekvivalenti uyning_oldi/xizmat/navbat_listiga_qoshish yo'lidan foydalaniladi. Modul nomi bilan boshlash yo'l nisbiy ekanligini bildiradi.
Nisbiy yoki mutlaq yo‘ldan foydalanishni tanlash loyihangiz asosida qabul qilinadigan qaror bo‘lib, element definitioni kodini elementdan foydalanadigan koddan alohida yoki birga ko‘chirish ehtimoli ko‘proq ekanligiga bog‘liq.
Masalan, uyning_oldi moduli va restoranda_ovqatlanish funksiyasini mijoz_tajribasi nomli modulga o‘tkazsak, mutlaq yo‘lni navbat_listiga_qoshishga yangilashimiz kerak bo‘ladi, lekin nisbiy yo‘l baribir amal qiladi.
Biroq, agar biz restoranda_ovqatlanish funksiyasini ovqatlanish nomli modulga alohida ko'chirsak, restoranda_ovqatlanish chaqiruvining mutlaq yo'li bir xil bo'lib qoladi, lekin nisbiy yo'l yangilanishi kerak bo'ladi. Umuman olganda, bizning afzal ko'rganimiz mutlaq yo'llarni belgilashdir, chunki biz kod definitionlari va element chaqiruvlarini bir-biridan mustaqil ravishda ko'chirishni xohlaymiz.
Keling, 7-3 ro'yxatini kompilatsiya qilishga harakat qilaylik va nima uchun u hali kompilatsiya bo'lmaganligini bilib olaylik! Biz olgan xato 7-4 ro'yxatda ko'rsatilgan.
$ cargo build
Compiling restaurant v0.1.0 (file:///projects/restaurant)
error[E0603]: module `xizmat` is private
--> src/lib.rs:9:28
|
9 | crate::uyning_oldi::xizmat::navbat_listiga_qoshish();
| ^^^^^^^ private module
|
note: the module `xizmat` is defined here
--> src/lib.rs:2:5
|
2 | mod xizmat {
| ^^^^^^^^^^^
error[E0603]: module `xizmat` is private
--> src/lib.rs:12:21
|
12 | uyning_oldi::xizmat::navbat_listiga_qoshish();
| ^^^^^^^ private module
|
note: the module `xizmat` is defined here
--> src/lib.rs:2:5
|
2 | mod xizmat {
| ^^^^^^^^^^^
For more information about this error, try `rustc --explain E0603`.
error: could not compile `restaurant` due to 2 previous errors
Ro'yxat 7-4: 7-3 ro'yxatdagi kodni kompilyatsiya qilishda kompilyator xatolari
Xato xabarlari xizmat moduli private ekanligini aytadi. Boshqacha qilib aytadigan bo'lsak, bizda xizmat moduli va navbat_listiga_qoshish funksiyasi uchun to'g'ri yo'llar mavjud, ammo Rust ulardan foydalanishimizga ruxsat bermaydi, chunki u private bo'limlarga kirish imkoniga ega emas. Rust-da barcha elementlar (funktsiyalar, metodlar, structlar, enumlar, modullar va konstantalar) standart bo'yicha ota-modullar uchun privatedir. Agar siz funksiya yoki struktura kabi elementni yaratmoqchi bo'lsangiz, uni modulga joylashtirasiz.
Ota-moduldagi elementlar ichki modullar ichidagi private elementlardan foydalana olmaydi, lekin bolalar modullaridagi elementlar o'zlarining ota-modullaridagi elementlardan foydalanishi mumkin. Buning sababi shundaki, bolalar modullari o'zlarining amalga oshirish tafsilotlarini o'rab oladi va yashiradi, lekin bolalar modullari ular aniqlangan kontekstni ko'rishlari mumkin. Bizning metaforamizni davom ettirish uchun, maxfiylik qoidalarini restoranning orqa ofisi kabi tasavvur qiling: u erda nima sodir bo'layotgani restoran mijozlari uchun private, ammo ofis menejerlari o'zlari ishlayotgan restoranda hamma narsani ko'rishlari va qilishlari mumkin.
Rust modul tizimining shu tarzda ishlashini tanladi, shuning uchun ichki dastur tafsilotlarini yashirish standart bo'yichadir. Shunday qilib, siz ichki kodning qaysi qismlarini tashqi kodni buzmasdan o'zgartirishingiz mumkinligini bilasiz. Biroq, Rust sizga obyektni hammaga ochiq qilish uchun pub kalit so'zidan foydalanib, tashqi ajdod modullariga ichki modullar kodining ichki qismlarini ochish imkoniyatini beradi.
pub kalit so'zi bilan yo'llarni ochish
Keling, 7-4 ro'yxatdagi xatoga qaytaylik, bu bizga xizmat moduli private ekanligini aytdi. Biz ota-moduldagi restoranda_ovqatlanish funksiyasi bolalar modulidagi navbat_listiga_qoshish funksiyasiga kirishini xohlaymiz, shuning uchun biz xizmat modulini pub kalit so'zi bilan belgilaymiz, ro'yxat 7-5da ko`rsatilganidek.
Fayl nomi: src/lib.rs
mod uyning_oldi {
pub mod xizmat {
fn navbat_listiga_qoshish() {}
}
}
pub fn restoranda_ovqatlanish() {
// Mutlaq yo'l (Absolute path)
crate::uyning_oldi::xizmat::navbat_listiga_qoshish();
// Nisbiy yo'l (Relative path)
uyning_oldi::xizmat::navbat_listiga_qoshish();
}Ro'yxat 7-5: xizmat modulini restoranda_ovqatlanish dan foydalanish uchun pub deb e'lon qilish
Afsuski, 7-5 ro'yxatdagi kod hali ham 7-6 ro'yxatda ko'rsatilganidek xatolikka olib keladi.
$ cargo build
Compiling restaurant v0.1.0 (file:///projects/restaurant)
error[E0603]: function `navbat_listiga_qoshish` is private
--> src/lib.rs:9:37
|
9 | crate::uyning_oldi::xizmat::navbat_listiga_qoshish();
| ^^^^^^^^^^^^^^^ private function
|
note: the function `navbat_listiga_qoshish` is defined here
--> src/lib.rs:3:9
|
3 | fn navbat_listiga_qoshish() {}
| ^^^^^^^^^^^^^^^^^^^^
error[E0603]: function `navbat_listiga_qoshish` is private
--> src/lib.rs:12:30
|
12 | uyning_oldi::xizmat::navbat_listiga_qoshish();
| ^^^^^^^^^^^^^^^ private function
|
note: the function `navbat_listiga_qoshish` is defined here
--> src/lib.rs:3:9
|
3 | fn navbat_listiga_qoshish() {}
| ^^^^^^^^^^^^^^^^^^^^
For more information about this error, try `rustc --explain E0603`.
error: could not compile `restaurant` due to 2 previous errors
Ro'yxat 7-6: 7-5 ro'yxatdagi kodni build qilishda kompilyator xatolari
Nima bo'ldi? mod xizmat oldiga pub kalit so‘zini qo‘shish modulni hammaga ochiq qiladi. Ushbu o'zgarish bilan, agar biz uyning_oldi ga kira olsak, biz xizmat ga kira olamiz. Lekin xizmat ning tarkibi hamon private; modulni public qilish uning mazmunini ochiq qilmaydi. Moduldagi pub kalit so‘zi faqat uning ota-modullaridagi kodni unga murojaat qilish imkonini beradi, uning ichki kodiga kirishga ruxsat bermaydi.
Modullar konteyner bo'lgani uchun modulni faqat public qilish orqali biz ko'p narsa qila olmaymiz; biz oldinga borishimiz va modul ichidagi bir yoki bir nechta narsalarni ham hammaga ochiq qilishni tanlashimiz kerak.
7-6 roʻyxatdagi xatolar navbat_listiga_qoshish funksiyasi private ekanligini bildiradi.
Maxfiylik qoidalari structlar, enumlar, funksiyalar va metodlar hamda modullarga nisbatan qo'llaniladi.
7-7 ro'yxatda ko'rsatilganidek, definitiondan oldin pub kalit so'zini qo'shish orqali navbat_listiga_qoshish funksiyasini ham hammaga ochiq qilaylik.
Fayl nomi: src/lib.rs
mod uyning_oldi {
pub mod xizmat {
pub fn navbat_listiga_qoshish() {}
}
}
pub fn restoranda_ovqatlanish() {
// Mutlaq yo'l (Absolute path)
crate::uyning_oldi::xizmat::navbat_listiga_qoshish();
// Nisbiy yo'l (Relative path)
uyning_oldi::xizmat::navbat_listiga_qoshish();
}Ro'yxat 7-7: mod xizmat va fn navbat_listiga_qoshish ga pub kalit so'zini qo'shish bizga restoranda_ovqatlanish funksiyasini chaqirish imkonini beradi.
Endi kod kompilyatsiya qilinadi! Nima uchunpub kalit soʻzini qoʻshish ushbu yoʻllardan navbat_listiga_qoshish da maxfiylik qoidalariga nisbatan foydalanish imkonini berishini bilish uchun mutlaq va nisbiy yoʻllarni koʻrib chiqamiz.
Mutlaq yo'lda biz crate modul daraxtining ildizi bo'lgan crate dan boshlaymiz. uyning_oldi moduli crate ildizida belgilangan. uyning_oldi ochiq boʻlmasa-da, restoranda_ovqatlanish funksiyasi uyning_oldi bilan bir xil modulda aniqlanganligi sababli (yaʼni, restoranda_ovqatlanish va uyning_oldi siblingdir ya'ni aka-uka), biz restoranda_ovqatlanish dan uyning_oldiga murojaat qilishimiz mumkin. Keyingi o'rinda pub bilan belgilangan xizmat moduli. Biz xizmat ning ota-moduliga kira olamiz, shuning uchun biz xizmat ga kira olamiz. Nihoyat, navbat_listiga_qoshish funksiyasi pub bilan belgilangan va biz uning asosiy moduliga kira olamiz, shuning uchun bu funksiya chaqiruvi ishlaydi!
Nisbiy yo'lda mantiq birinchi qadamdan tashqari mutlaq yo'l bilan bir xil bo'ladi: yo'l crate ildizidan emas, uyning_oldidan boshlanadi. uyning_oldi moduli restoranda_ovqatlanish bilan bir xil modul ichida aniqlanadi, shuning uchun restoranda_ovqatlanish belgilangan moduldan boshlanadigan nisbiy yo‘l ishlaydi. Keyin, xizmat va navbat_listiga_qoshish pub bilan belgilanganligi sababli, qolgan yo‘l ishlaydi va bu funksiya chaqiruvi amal qiladi!
Agar siz kutubxona crateyingizni boshqa loyihalar sizning kodingizdan foydalanishi uchun baham ko'rishni rejalashtirmoqchi bo'lsangiz, public API sizning crateyingiz foydalanuvchilari bilan tuzilgan shartnoma bo'lib, ular sizning kodingiz bilan qanday aloqada bo'lishini belgilaydi. Odamlar sizning crateyingizga bog'liq bo'lishini osonlashtirish uchun public API-ga o'zgartirishlarni boshqarish bo'yicha ko'plab fikrlar mavjud. Bu mulohazalar ushbu kitob doirasidan tashqarida; agar sizni ushbu mavzu qiziqtirsa, Rust API ko'rsatmalariga qarang.
Binary va kutubxonaga ega paketlar uchun eng yaxshi amaliyotlar
Paketda src/main.rs binary crate ildizi ham, src/lib.rs kutubxona cratesi ildizi ham bo‘lishi mumkinligini aytib o'tdik va ikkala crate ham standart bo‘yicha paket nomiga ega bo‘ladi. Odatda, kutubxona va binary crateni o'z ichiga olgan ushbu patternli paketlar kutubxona cratesi bilan kod chaqiradigan bajariladigan faylni ishga tushirish uchun binary crateda yetarli kodga ega bo'ladi. Bu boshqa loyihalarga paket taqdim etadigan eng ko'p funksiyalardan foydalanish imkonini beradi, chunki kutubxona cratesi kodi public bo'lishi mumkin.
Modul daraxti src/lib.rs da aniqlanishi kerak. Keyin har qanday public obyektlar binary crateda paket nomi bilan yo'llarni boshlash orqali ishlatilishi mumkin. Binary crate kutubxona cratesidan foydalanuvchiga aylanadi, xuddi butunlay tashqi crate kutubxona cratesidan foydalanadi: u faqat pulic APIdan foydalanishi mumkin. Bu sizga yaxshi API yaratishga yordam beradi; Siz nafaqat muallif, balki mijoz hamsiz!
12-bobda biz ushbu tashkiliy amaliyotni binary crate va kutubxona cratesini o'z ichiga olgan buyruq qatori dasturi bilan ko'rsatamiz.
Nisbiy yo'llarni super bilan boshlash
Yo'l boshida super dan foydalanib, joriy modul yoki crate ildizi emas, balki ota-modulda boshlanadigan nisbiy yo'llarni qurishimiz mumkin. Bu fayl tizimi yoʻlini .. sintaksisi bilan boshlashga oʻxshaydi. super dan foydalanish bizga ota-modulda ekanligini biladigan elementga murojaat qilish imkonini beradi, bu modul ota-ona bilan chambarchas bog'liq bo'lsa, modul daraxtini qayta tartibga solishni osonlashtiradi, lekin ota-ona bir kun kelib modul daraxtining boshqa joyiga ko'chirilishi mumkin.
7-8 ro'yxatdagi kodni ko'rib chiqing, unda oshpaz noto'g'ri buyurtmani tuzatgan va uni mijozga shaxsan yetkazgan vaziyatni modellashtiradi. uyning_orqasi modulida aniqlangan buyurtmani_tuzatish funksiyasi super bilan boshlanadigan yetkazib_berish yo‘lini belgilash orqali asosiy modulda belgilangan yetkazib_berish funksiyasini chaqiradi:
Fayl nomi: src/lib.rs
fn yetkazib_berish() {}
mod uyning_orqasi {
fn buyurtmani_tuzatish() {
oshpaz();
super::yetkazib_berish();
}
fn oshpaz() {}
}Ro'yxat 7-8: super bilan boshlanadigan nisbiy yo'l yordamida funksiyani chaqirish
buyurtmani_tuzatish funksiyasi uyning_orqasi modulida joylashgan, shuning uchun biz super dan uyning_orqasi ota-moduliga o'tishimiz mumkin. U yerdan yetkazib_berish ni qidiramiz va uni topamiz.
Muvaffaqiyat! Bizning fikrimizcha, uyning_orqasi moduli va yetkazib_berish funksiyasi bir-biri bilan bir xil munosabatda bo'lib qoladi va agar biz cratening modul daraxtini qayta tashkil etishga qaror qilsak, birgalikda harakatlanadi. Shu sababli, biz super dan foydalandik, shuning uchun kelajakda bu kod boshqa modulga ko‘chirilsa, kodni yangilash uchun kamroq joylarga ega bo‘lamiz.
Structlar va Enumlarni public qilish
Shuningdek, structlar va enumlarni public sifatida belgilash uchun pub dan foydalanishimiz mumkin, ammo pub dan structlar va enumlar bilan foydalanish uchun qo'shimcha tafsilotlar mavjud. Agar struct definitiondan oldin pub dan foydalansak, biz structni hammaga public qilamiz, lekin structning maydonlari hali ham private bo'lib qoladi. Biz har bir sohani alohida-alohida public qilishimiz yoki qilmasligimiz mumkin. 7-9 roʻyxatda biz public qizdirilgan_non maydoni, lekin private mavsumiy_meva maydoni bilan public uyning_orqasi:: nonushta structini belgilab oldik. Bu restoranda mijoz ovqat bilan birga keladigan non turini tanlashi mumkin bo'lgan holatni modellashtiradi, ammo oshpaz qaysi meva mavsumda va omborda borligiga qarab ovqatga hamroh bo'lishini hal qiladi. Mavjud mevalar tezda o'zgaradi, shuning uchun mijozlar mevani tanlay olmaydi yoki hatto qaysi mevani olishini ko'ra olmaydi.
Fayl nomi: src/lib.rs
mod uyning_orqasi {
pub struct Nonushta {
pub yopilgan_non: String,
mavsumiy_meva: String,
}
impl Nonushta {
pub fn yoz(yopilgan_non: &str) -> Nonushta {
Nonushta {
yopilgan_non: String::from(yopilgan_non),
mavsumiy_meva: String::from("shaftoli"),
}
}
}
}
pub fn restoranda_ovqatlanish() {
// Yozda javdar yopilgan noni bilan nonushta buyurtma qiling
let mut ovqat = uyning_orqasi::Nonushta::yoz("Javdar");
// Qaysi nonni xohlashimiz haqidagi fikrimizni o'zgartiring
ovqat.yopilgan_non = String::from("Bug'doy");
println!("Iltimos, {}li yopilgan nonni istayman", ovqat.yopilgan_non);
// Agar izohni olib tashlasak, keyingi qator kompilyatsiya qilinmaydi;
// ovqat bilan birga keladigan mavsumiy mevalarni ko'rish yoki
// o'zgartirishga ruxsat berilmagan
// ovqat.mavsumiy_meva = String::from("ko'katlar");
}Ro'yxat 7-9: Ba'zi public maydonlari va ba'zilari bo'lgan struct xususiy maydonlar
uyning_orqasi::Nonushta structdagi yopilgan_non maydoni public bo'lgani uchun restoranda_ovqatlanish da biz yopilgan_non maydoniga nuqta belgisi yordamida yozishimiz va o'qishimiz mumkin. Esda tutingki, biz mavsumiy_meva maydonidan restoranda_ovqatlanishda foydalana olmaymiz, chunki mavsumiy_meva privatedir. Qaysi xatoga yo'l qo'yganingizni bilish uchun mavsumiy_meva maydoni qiymatini o'zgartiruvchi qatorni izohdan chiqarib ko'ring!
Shuni ham yodda tutingki, uyning_orqasi::Nonushta private maydonga ega bo'lgani uchun struct Nonushta misolini yaratuvchi public bog'langan funksiyani ta'minlashi kerak (biz uni bu yerda yoz deb nomladik).Agar Nonushta bunday funksiyaga ega boʻlmagan boʻlsa, biz restoranda_ovqatlanishda Nonushta misolini yarata olmadik, chunki biz restoranda_ovqatlanishda private mavsumiy_meva maydonining qiymatini oʻrnata olmadik.
Aksincha, agar biz enumni public qilsak, uning barcha variantlari public bo'ladi. 7 10 roʻyxatda koʻrsatilganidek, bizga faqat enum kalit soʻzidan oldin pub kerak boʻladi.
Fayl nomi: src/lib.rs
mod uyning_orqasi {
pub enum Taom {
Palov,
Salat,
}
}
pub fn restoranda_ovqatlanish() {
let buyurtma1 = uyning_orqasi::Taom::Palov;
let buyurtma2 = uyning_orqasi::Taom::Salat;
}Ro'yxat 7-10: Enumni public deb belgilash uning barcha variantlarini hammaga ochiq qiladi
Biz Taom ro‘yxatini hammaga public qilganimiz uchun restoranda_ovqatlanishda Palov va Salat variantlaridan foydalanishimiz mumkin.
Enumlar, agar ularning variantlari public bo'lmasa, unchalik foydali emas; Har bir holatda pub bilan barcha enum variantlariga izoh qo'yish zerikarli bo'lar edi, shuning uchun enum variantlari uchun standart umumiy bo'lishi kerak. Structlar ko'pincha maydonlari public bo'lmasdan foydali bo'ladi, shuning uchun struct maydonlari, agar pub bilan izohlanmagan bo'lsa, standart bo'yicha hamma narsa private bo'lishining umumiy qoidasiga amal qiladi.
pub bilan bog'liq yana bir holat bor, biz uni ko'rib chiqmaganmiz va bu bizning modul tizimining oxirgi xususiyati: use kalit so'zi. Biz avval use ni o'z ichiga olamiz, so'ngra pub va use ni qanday birlashtirishni ko'rsatamiz.
use kalit so'zi bilan yo'llarni doiraga kiritish
Funksiyalarni chaqirish yo'llarini yozishga to'g'ri kelishi noqulay va takroriy tuyulishi mumkin. 7-7-Ro'yxatda navbat_listiga_qoshish funksiyasiga mutlaq yoki nisbiy yoʻlni tanladikmi, har safar navbat_listiga_qoshish funksiyasiga murojat qilmoqchi boʻlganimizda, uyning_oldi va xizmatni ham belgilashimiz kerak edi. Yaxshiyamki, bu jarayonni soddalashtirishning bir usuli bor: biz bir marta use kalit so‘zi bilan yo‘lga nom yaratishimiz mumkin, so‘ngra boshqa hamma joyda qisqaroq nomdan foydalanishimiz mumkin.
7-11 ro'yxatda biz crate::uyning_oldi::xizmat modulini restoranda_ovqatlanish funksiyasi doirasiga kiritamiz, shuning uchun restoranda_ovqatlanishdagi navbat_listiga_qoshish funksiyasini chaqirish uchun faqat xizmat::navbat_listiga_qoshish ni belgilashimiz kerak.
Fayl nomi: src/lib.rs
mod uyning_oldi {
pub mod xizmat {
pub fn navbat_listiga_qoshish() {}
}
}
use crate::uyning_oldi::xizmat;
pub fn restoranda_ovqatlanish() {
xizmat::navbat_listiga_qoshish();
}Ro'yxat 7-11: Modulni use bilan qamrab olish
use va sohaga yo'lni qo'shish fayl tizimida ramziy havola yaratishga o'xshaydi. Crate ildiziga use crate::uyning_oldi::xizmat ni qo‘shish orqali xizmat endi bu doirada haqiqiy nom bo‘lib qoladi, xuddi xizmat moduli crate ildizida aniqlangandek. use doirasiga kiritilgan yo'llar boshqa yo'llar kabi maxfiylikni ham tekshiradi.
E'tibor bering, use faqat use ishlaydigan aniq doira uchun yorliqni yaratadi. 7-12 roʻyxat restoranda_ovqatlanish funksiyasini mijoz nomli yangi bolalar moduliga oʻtkazadi, bu keyinchalik use statementidan farq qiladi, shuning uchun funksiyaning tanasi kompilyatsiya qilinmaydi:
Fayl nomi: src/lib.rs
mod uyning_oldi {
pub mod xizmat {
pub fn navbat_listiga_qoshish() {}
}
}
use crate::uyning_oldi::xizmat;
mod mijoz {
pub fn restoranda_ovqatlanish() {
xizmat::navbat_listiga_qoshish();
}
}Ro'yxat 7-12: use statementi faqat u joylashgan doirada qo'llaniladi
Kompilyator xatosi yorliq endi mijoz modulida qo'llanilmasligini ko'rsatadi:
$ cargo build
Compiling restaurant v0.1.0 (file:///projects/restaurant)
warning: unused import: `crate::uyning_oldi::xizmat`
--> src/lib.rs:7:5
|
7 | use crate::uyning_oldi::xizmat;
| ^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: `#[warn(unused_imports)]` on by default
error[E0433]: failed to resolve: use of undeclared crate or module `xizmat`
--> src/lib.rs:11:9
|
11 | xizmat::navbat_listiga_qoshish();
| ^^^^^^ use of undeclared crate or module `xizmat`
For more information about this error, try `rustc --explain E0433`.
warning: `restaurant` (lib) generated 1 warning
error: could not compile `restaurant` due to previous error; 1 warning emitted
E'tibor bering, use endi uning doirasida qo'llanilmasligi haqida ogohlantirish ham bor! Bu muammoni hal qilish uchun use ni mijoz moduliga ham o‘tkazing yoki mijoz modulidagi super::xizmat bilan ota-moduldagi yorliqlarga murojaat qiling.
use bilan idiomatik yo'llarni yaratish
7-11 ro'yxatda siz shunday deb hayron bo'lishingiz mumkin,Nima uchun biz bir xil natijaga erishish uchun navbat_listiga_qoshish funksiyasigacha toʻliq yoʻlni ishlatish oʻrniga, crate::uyning_oldi::xizmat ni ishlatishni belgilab qoʻydik va keyin restoranda_ovqatlanish ichidagi xizmat::navbat_listiga_qoshish ga murojat qildik, 7-13 ro'yxatdagi kabi.
Fayl nomi: src/lib.rs
mod uyning_oldi {
pub mod xizmat {
pub fn navbat_listiga_qoshish() {}
}
}
use crate::uyning_oldi::xizmat::navbat_listiga_qoshish;
pub fn restoranda_ovqatlanish() {
navbat_listiga_qoshish();
}Ro'yxat 7-13: navbat_listiga_qoshish funksiyasini use bilan qamrab olish, bu unidiomatikdir
Garchi 7-11 va 7-13 ro'yxatlari bir xil vazifani bajarsa-da, 7-11 ro'yxat funksiyani use bilan qamrab olishning idiomatik usulidir. Funksiyaning ota-modulini use bilan qamrab olish funksiyani chaqirishda ota-modulni belgilashimiz kerakligini anglatadi. Funksiyani chaqirishda ota-modulni ko'rsatish, to'liq yo'lning takrorlanishini minimallashtirish bilan birga, funksiya mahalliy sifatida aniqlanmaganligini aniq ko'rsatadi. 7-13 ro'yxatda navbat_listiga_qoshish qayerda aniqlangani aniq emas.
Boshqa tomondan, use bilan structlar, enumlar va boshqa elementlarni keltirishda to'liq yo'lni ko'rsatish idiomatikdir. 7-14 ro'yxat standart kutubxonaning HashMap structini binary crate doirasiga olib kirishning idiomatik usulini ko'rsatadi.
Fayl nomi: src/main.rs
use std::collections::HashMap; fn main() { let mut map = HashMap::new(); map.insert(1, 2); }
Ro'yxat 7-14: HashMap ni idiomatik tarzda qamrab olish
Bu idioma ortida hech qanday yaxshi sabab yo'q: Bu shunchaki konventsiya paydo bo'ldi va odamlar Rust kodini shu tarzda o'qish va yozishga o'rganib qolgan.
Bu idiomadan istisno shundaki, biz bir xil nomdagi ikkita elementni use statementi yordamida doiraga kiritganimizda - Rust bunga yo'l qo'ymaydi. 7-15 ro'yxatda bir xil nomga ega, ammo har xil ota-modullarga ega bo'lgan ikkita Result turini qanday ko'rinishga kiritish va ularga qanday murojaat qilish kerakligi ko'rsatilgan.
Fayl nomi: src/lib.rs
use std::fmt;
use std::io;
fn funksiya1() -> fmt::Result {
// --snip--
Ok(())
}
fn funksiya2() -> io::Result<()> {
// --snip--
Ok(())
}Ro'yxat 7-15: Bir xil nomdagi ikkita turni bir xil doiraga kiritish uchun ularning ota-modullaridan foydalanish talab etiladi.
Ko'rib turganingizdek, ota-modullardan foydalanish ikkita Result turini ajratib turadi.
Buning o'rniga use std::fmt::Result va us std::io::Result ni belgilagan bo'lsak, bizda bir xil miqyosda ikkita Result turi bo'lar edi va Rust Result dan foydalanganda qaysi birini nazarda tutganimizni bilmas edi.
as kalit so'zi bilan yangi nomlarni taqdim etish
Bir xil nomdagi ikkita turni use bilan bir xil doiraga olib kirish muammosining yana bir yechimi bor: yoʻldan soʻng biz as va yangi mahalliy nom yoki tur uchun taxallus belgilashimiz mumkin. 7-16 ro'yxatda ikkita Result turidan birini as yordamida qayta nomlash orqali 7-15 ro'yxatdagi kodni yozishning yana bir usuli ko'rsatilgan.
Fayl nomi: src/lib.rs
use std::fmt::Result;
use std::io::Result as IoResult;
fn funksiya1() -> Result {
// --snip--
Ok(())
}
fn funksiya2() -> IoResult<()> {
// --snip--
Ok(())
}Ro'yxat 7-16: as kalit so'zi bilan qamrovga kiritilgan tur nomini o'zgartirish
Ikkinchi use statementida biz std::io::Result turi uchun yangi IoResult nomini tanladik, bu endi std::fmt dan Result turiga zid kelmaydi, u ham doiraga kiradi. 7-15 va 7-16 ro'yxatlar idiomatik hisoblanadi, shuning uchun tanlov sizga bog'liq!
pub use bilan nomlarni qayta eksport(re-eksport) qilish
use kalit so'zidan foydalanib, nomni qamrovga kiritganimizda, yangi doirada mavjud bo'lgan nom private bo'ladi. Bizning kodimizni chaqiradigan kodni xuddi shu kod doirasida aniqlangandek ushbu nomga murojaat qilishini yoqish uchun biz pub va use ni birlashtira olamiz. Bu usul re-eksport deb nomlanadi, chunki biz obyektni qamrovga kiritmoqdamiz, lekin elementni boshqa qamrovlarga kiritish uchun ham mavjud qilamiz.
7-17 ro'yxatda 7-11 ro'yxatdagi kod ko'rsatilgan, ildiz modulidagi use pub use ga o'zgartirilgan.
Fayl nomi: src/lib.rs
mod uyning_oldi {
pub mod xizmat {
pub fn navbat_listiga_qoshish() {}
}
}
pub use crate::uyning_oldi::xizmat;
pub fn restoranda_ovqatlanish() {
xizmat::navbat_listiga_qoshish();
}Ro'yxat 7-17. pub use bilan yangi doiradagi istalgan kod tomonidan foydalanish uchun nom berish
Ushbu o'zgarishdan oldin tashqi kod restoran::uyning_oldi::xizmat::navbat_listiga_qoshish() yo'lidan foydalanib, navbat_listiga_qoshish funksiyasini chaqirishi kerak bo'ladi. Endi bu pub use xizmat modulini ildiz modulidan qayta eksport qilgan bo‘lsa, tashqi kod endi restoran::xizmat::navbat_listiga_qoshish() yo‘lidan foydalanishi mumkin..
Qayta eksport qilish sizning kodingizning ichki tuzilishi sizning kodingizni chaqirayotgan dasturchilarning domen haqida o'ylashlaridan farq qilganda foydali bo'ladi. Misol uchun, ushbu restoran metaforasida restoranni boshqaradigan odamlar "uyning old tomoni" va "uyning orqasi" haqida o'ylashadi. Ammo restoranga tashrif buyurgan mijozlar, ehtimol, restoranning qismlari haqida o'ylamaydilar. pub use bilan biz kodimizni bitta struct bilan yozishimiz mumkin, lekin boshqa structni ko'rsatamiz. Bu bizning kutubxonamizni kutubxonada ishlaydigan dasturchilar va kutubxonaga murojat qilayotgan dasturchilar uchun uchun yaxshi tashkil etilgan holda saqlaydi. Biz 14-bobning “pub use bilan qulay umumiy APIni eksport qilish” bo‘limida pub usening yana bir misolini va uning cratengiz hujjatlariga qanday ta’sir qilishini ko‘rib chiqamiz.
Tashqi paketlardan foydalanish
2-bobda biz tasodifiy raqamlarni olish uchun rand deb nomlangan tashqi paketdan foydalangan holda taxminiy o'yin loyihasini dasturlashtirdik. Loyihamizda rand dan foydalanish uchun biz ushbu qatorni Cargo.toml ga qo'shdik:
Fayl nomi: Cargo.toml
rand = "0.8.5"
Cargo.toml-ga randni dependency sifatida qo'shish Cargo-ga crates.io-dan rand paketini va har qanday bog'liqliklarni yuklab olishni va randni loyihamiz uchun ishlatishni aytadi.
Keyin, rand ta'riflarini paketimiz doirasiga kiritish uchun biz crate nomidan boshlanadigan use qatorini qo'shdik, rand va biz qamrab olmoqchi bo'lgan elementlarni sanab o'tdik. Eslatib o‘tamiz, 2-bobdagi “Tasodifiy raqamni yaratish” bo‘limida biz Rng traitini qamrab oldik va rand::thread_rng funksiyasini chaqirdik:
use std::io;
use rand::Rng;
fn main() {
println!("Raqamni topish o'yini!");
let yashirin_raqam = rand::rng().random_range(1..=100);
println!("Yashirin raqam: {yashirin_raqam}");
println!("Iltimos, taxminingizni kiriting.");
let mut taxmin = String::new();
io::stdin()
.read_line(&mut taxmin)
.expect("Satrni o‘qib bo‘lmadi");
println!("Sizning taxminingiz: {taxmin}");
}Rust hamjamiyatining a'zolari crates.io saytida ko'plab paketlarni taqdim etishdi va ulardan birini o'z paketingizga olish xuddi shu bosqichlarni o'z ichiga oladi: ularni paketingizning Cargo.toml faylida roʻyxatga kiriting va use dan foydalanib, ularni cratelaridagi elementlarni qamrab oling.
E'tibor bering, standart std kutubxonasi bizning paketimizdan tashqarida joylashgan cratedir. Standart kutubxona Rust tili bilan birga kelganligi sababli, biz Cargo.toml ni std qo'shish uchun o'zgartirishimiz shart emas. Ammo biz u yerdan elementlarni paketimiz doirasiga olib kirish uchun use bilan murojaat qilishimiz kerak. Masalan, HashMap bilan biz ushbu qatordan foydalanamiz:
#![allow(unused)] fn main() { use std::collections::HashMap; }
Bu standart kutubxona cratesining nomi bo'lgan std bilan boshlanadigan mutlaq yo'ldir.
Uzun use ro'yxatini qisqartirish uchun ichki yo'llardan foydalanish
Agar biz bir xil crate yoki bir xil modulda belgilangan bir nechta elementlardan foydalansak, har bir elementni o'z qatoriga qo'yish bizning fayllarimizda juda ko'p vertikal joy egallashi mumkin. Masalan, 2-4 roʻyxatdagi raqamlarni taxmin qilish dasturida mavjud boʻlgan ushbu ikkita use statementi std dagi elementlarni qamrab oladi:
Filename: src/main.rs
use rand::Rng;
// --snip--
use std::cmp::Ordering;
use std::io;
// --snip--
fn main() {
println!("Raqamni topish o'yini!");
let yashirin_raqam = rand::thread_rng().gen_range(1..=100);
println!("Yashirin raqam: {yashirin_raqam}");
println!("Iltimos, taxminingizni kiriting.");
let mut taxmin = String::new();
io::stdin()
.read_line(&mut taxmin)
.expect("Satrni o'qib bo'lmadi");
println!("Sizning taxminingiz: {taxmin}");
match taxmin.cmp(&yashirin_raqam) {
Ordering::Less => println!("Raqam Kichik!"),
Ordering::Greater => println!("Raqam katta!"),
Ordering::Equal => println!("Siz yutdingiz!"),
}
}Buning o'rniga, biz bir xil elementlarni bir qatorga kiritish uchun ichki yo'llardan foydalanishimiz mumkin. Buni 7-18 roʻyxatda koʻrsatilganidek, yoʻlning umumiy qismini, keyin ikkita nuqta qoʻyib, soʻngra yoʻllarning bir-biridan farq qiladigan qismlari roʻyxati atrofida jingalak qavslarni belgilash orqali qilamiz.
Fayl nomi: src/main.rs
use rand::Rng;
// --snip--
use std::{cmp::Ordering, io};
// --snip--
fn main() {
println!("Raqamni topish o'yini!");
let yashirin_raqam = rand::thread_rng().gen_range(1..=100);
println!("Yashirin raqam: {yashirin_raqam}");
println!("Iltimos, taxminingizni kiriting.");
let mut taxmin = String::new();
io::stdin()
.read_line(&mut taxmin)
.expect("Satrni o'qib bo'lmadi");
let taxmin: u32 = taxmin.trim().parse().expect("Iltimos, raqam yozing!");
println!("Sizning taxminingiz: {taxmin}");
match taxmin.cmp(&yashirin_raqam) {
Ordering::Less => println!("Raqam Kichik!"),
Ordering::Greater => println!("Raqam katta!"),
Ordering::Equal => println!("Siz yutdingiz!"),
}
}Ro'yxat 7-18. Qo'llash sohasiga bir xil prefiksli bir nechta elementlarni qo'shish uchun ichki yo'lni belgilash
Kattaroq dasturlarda bir xil crate yoki moduldan ko'plab elementlarni o'rnatilgan yo'llar yordamida qamrab olish juda ko'p talab qilinadigan alohida use statementlari sonini kamaytirishi mumkin!
Siz har qanday darajadagi ichki yo'ldan foydalanishingiz mumkin, bu yo'l qismini ulashuvchi ikkita use statementini birlashtirishda foydalidir. Masalan, 7-19 ro'yxat ikkita use statementini ko'rsatadi: biri std::io ni qamrab oladi va ikkinchisi std::io::Write ni qamrab oladi.
Fayl nomi: src/lib.rs
use std::io;
use std::io::Write;Ro'yxat 7-19: biri ikkinchisining bir qismi bo'lgan ikkita use statementi
Ushbu ikkita yo'lning umumiy qismi std::io va to'liq birinchi yo'ldir. Ushbu ikkita yo'lni bitta use statementiga birlashtirish uchun biz 7-20 ro'yxatda ko'rsatilganidek, ichki yo'lda self dan foydalanishimiz mumkin.
Fayl nomi: src/lib.rs
use std::io::{self, Write};Ro'yxat 7-20: Ro'yxat 7-19dagi yo'llarni bitta use statementiga birlashtirish
Bu satr std::io va std::io::Write ni qamrab oladi.
Glob operatori
Agar biz yo'lda belgilangan barcha umumiy elementlarni qamrovga kiritmoqchi bo'lsak, biz * glob operatori tomonidan keyingi yo'lni belgilashimiz mumkin:
#![allow(unused)] fn main() { use std::collections::*; }
Ushbu use statementi std::collections da aniqlangan barcha public elementlarni joriy doiraga olib keladi. Glob operatoridan foydalanganda ehtiyot bo'ling! Glob qaysi nomlar qamrovda ekanligini va dasturingizda ishlatiladigan nom qayerda aniqlanganligini aniqlashni qiyinlashtirishi mumkin.
Glob operatori ko'pincha sinovdan o'tgan hamma narsani tests moduliga kiritish uchun test paytida ishlatiladi; biz bu haqda 11-bobdagi "Testlarni qanday yozish kerak" bo'limida gaplashamiz. Glob operatori ba'zan prelude patterning bir qismi sifatida ham qo'llaniladi: ushbu pattern haqida qo'shimcha ma'lumot olish uchun standart kutubxona texnik hujjatlariga qarang.
Modullarni turli fayllarga ajratish
Hozirgacha ushbu bobdagi barcha misollar bitta faylda bir nechta modullarni aniqladi. Modullar kattalashganda, kodni boshqarishni osonlashtirish uchun ularning definitionlarini alohida faylga ko'chirishingiz mumkin.
Masalan, 7-17 ro'yxatdagi bir nechta restoran moduliga ega bo'lgan koddan boshlaylik. Biz cratening ildiz modulidagi barcha modullarni aniqlash o'rniga modullarni fayllarga ajratamiz. Bunday holda, cratening ildiz fayli src/lib.rs bo'ladi, lekin bu protsedura crate ildiz fayli src/main.rs bo'lgan binary cratelar bilan ham ishlaydi.
Birinchidan, biz uyning_oldi modulini o'z fayliga chiqaramiz. uyning_oldi moduli uchun jingalak qavslar ichidagi kodni olib tashlang va faqat mod uyning_oldi deklaratsiyasini qoldiring, shunda src/lib.rs ro'yxat 7-21da ko'rsatilgan kodni o`z ichiga oladi. E'tibor bering, biz 7-22 ro'yxatda src/uyning_oldi.rs faylini yaratmagunimizcha, bu kompilyatsiya qilinmaydi.
Fayl nomi: src/lib.rs
mod uyning_oldi;
pub use crate::uyning_oldi::xizmat;
pub fn restoranda_ovqatlanish() {
xizmat::navbat_listiga_qoshish();
}Ro'yxat 7-21. Tarkibi src/uyning_oldi.rs da joylashgan uyning_oldi modulini e'lon qilish
Keyin, jingalak qavslardagi kodni yangi faylga joylashtiring
7-22 ro'yxatda ko'rsatilganidek src/uyning_oldi.rs deb nomlangan. Kompilyator bu faylda nimani izlash kerakligini biladi, chunki u uyning_oldi deb nomlangan cratening ildiz modulida modul deklaratsiyasiga duch keldi.
Fayl nomi: src/uyning_oldi.rs
{{#rustdoc_include ../listings/ch07-managing-growing-projects/listing-07-21-and-22/src/front_of_house.rs}}Ro'yxat 7-22. src/uyning_oldi.rs faylida uyning_oldi modulining mazmunini aniqlash
Esda tutingki, modul daraxtida bir marta mod deklaratsiyasidan foydalanib faylni yuklashingiz kerak. Kompilyator fayl loyihaning bir qismi ekanligini bilgandan so'ng (va mod statementi qo'ygan joyingiz tufayli kod modul daraxtining qayerida joylashganligini biladi), loyihangizdagi boshqa fayllar yuklangan fayl kodiga u e'lon qilingan joyga yo'l orqali murojaat qilishi kerak, bu "Modul daraxtidagi elementga murojaat qilish yo'llari" bo'limida yoritilgan. Boshqacha qilib aytganda, mod boshqa dasturlash tillarida ko'rishingiz mumkin bo'lgan “include” operatsiyasi emas.
Keyinchalik, biz xizmat modulini o'z fayliga chiqaramiz. Jarayon biroz boshqacha, chunki xizmat ildiz modulining emas, balki uyning_oldi ichki modulidir.Biz xizmat faylini modul daraxtidagi ajdodlari nomi bilan ataladigan yangi jildga joylashtiramiz, bu holda src/uyning_oldi/.
xizmatni ko‘chirishni boshlash uchun biz src/uyning_oldi.rs ni faqat xizmat moduli deklaratsiyasini o‘z ichiga olgan holda o‘zgartiramiz:
Fayl nomi: src/uyning_oldi.rs
{{#rustdoc_include ../listings/ch07-managing-growing-projects/no-listing-02-extracting-hosting/src/front_of_house.rs}}Keyin biz src/uyning_oldi jildini va xizmat modulida berilgan definitionlarni o'z ichiga olgan xizmat.rs faylini yaratamiz:
Fayl nomi: src/uyning_oldi/xizmat.rs
{{#rustdoc_include ../listings/ch07-managing-growing-projects/no-listing-02-extracting-hosting/src/front_of_house/hosting.rs}}Agar biz src jildiga xizmat.rs ni qo'ysak, kompilyator xizmat.rs kodi crate ildizida e'lon qilingan va uyning_oldi modulining yordamchisi sifatida e'lon qilinmagan xizmat modulida bo'lishini kutadi. Kompilyator qoidalari qaysi modullarning kodini o'z ichiga olgan fayllarni tekshirish uchun jildlar va fayllar modul daraxtiga to'liq mos kelishini taxmin qiladi.
Muqobil fayl yo'llari
Hozirgacha biz Rust kompilyatori foydalanadigan eng idiomatik fayl yo'llarini ko'rib chiqdik, lekin Rust fayl yo'lining eski uslubini ham qo'llab-quvvatlaydi. Crate ildizida e'lon qilingan
uyning_oldinomli modul uchun kompilyator modul kodini quyidagilardan qidiradi: module’s code in:
- src/uyning_oldi.rs (biz nimani qamrab oldik)
- src/uyning_oldi/mod.rs (eski uslub, hali ham qo'llab-quvvatlanadigan yo'l)
uyning_oldisubmodul bo'lganxizmatnomli modul uchun kompilyator modul kodini qidiradi:
- src/uyning_oldi/xizmat.rs (biz nimani qamrab oldik)
- src/uyning_oldi/xizmat/mod.rs (eski uslub, hali ham qo'llab-quvvatlanadigan yo'l)
Agar bir xil modul uchun ikkala uslubdan foydalansangiz, kompilyator xatosi paydo bo'ladi. Bitta loyihada turli modullar uchun ikkala uslubning aralashmasidan foydalanishga ruxsat beriladi, lekin loyihangizni boshqarayotgan odamlar uchun chalkash bo'lishi mumkin.
mod.rs nomli fayllardan foydalanadigan uslubning asosiy kamchiligi shundaki, sizning loyihangiz mod.rs nomli ko‘plab fayllar bilan tugashi mumkin, ular bir vaqtning o‘zida muharriringizda ochilganda chalkash bo‘lishi mumkin.
Biz har bir modul kodini alohida faylga ko'chirdik va modul daraxti o'zgarishsiz qoldi. restoranda_ovqatlanish funksiyasi chaqiruvlari, definitionlar turli fayllarda bo'lsa ham, hech qanday o'zgartirishlarsiz ishlaydi. Ushbu texnika modullarni hajmi oshgani sayin yangi fayllarga ko'chirish imkonini beradi.
Esda tutingki, src/lib.rs dagi pub use crate::uyning_oldi::xizmat statementi ham o'zgarmagan va use qaysi fayllar cratening bir qismi sifatida tuzilganiga ta'sir qilmaydi. mod kalit so'zi modullarni e'lon qiladi va Rust ushbu modulga kiradigan kod moduli bilan bir xil nomdagi faylga qaraydi.
Xulosa
Rust sizga paketni bir nechta cratelarga va crateni modullarga bo'lish imkonini beradi, shunda siz bir modulda belgilangan elementlarga boshqa moduldan murojaat qilishingiz mumkin. Buni mutlaq yoki nisbiy yo'llarni belgilash orqali amalga oshirishingiz mumkin. Ushbu yo'llar use statementi bilan qamrab olinishi mumkin, shuning uchun siz ushbu doiradagi elementdan bir nechta foydalanish uchun qisqaroq yo'ldan foydalanishingiz mumkin. Modul kodi standart boʻyicha maxfiydir, lekin pub kalit soʻzini qoʻshish orqali definitionlarni hammaga public qilishingiz mumkin.
Keyingi bobda biz standart kutubxonadagi ma'lumotlar tuzilmalarining ba'zi to'plamlarini ko'rib chiqamiz, ulardan siz o'zingizning aniq tartiblangan kodingizda foydalanishingiz mumkin.
Umumiy to'plamlar
Rustning standart kutubxonasi kolleksiyalar deb nomlangan juda foydali ma'lumotlar tuzilmalarini o'z ichiga oladi. Ko'pgina boshqa ma'lumotlar turlari bitta ma'lum qiymatni ifodalaydi, lekin to'plamlar bir nechta qiymatlarni o'z ichiga olishi mumkin. O'rnatilgan array va tuple turlaridan farqli o'laroq, ushbu to'plamlar ko'rsatadigan ma'lumotlar heapda saqlanadi, ya'ni ma'lumotlar miqdori kompilyatsiya vaqtida ma'lum bo'lishi shart emas va dastur ishga tushganda o'sishi yoki qisqarishi mumkin. To'plamning har bir turi o'z imkoniyatlariga ega va ishlash jihatidan farq qiladi, shuning uchun ma'lum bir to'plamni tanlash vaziyatga bog'liq va vaqt o'tishi bilan ishlab chiquvchining mahoratidir. Ushbu bobda biz Rust dasturlarida tez-tez ishlatiladigan uchta to'plamni muhokama qilamiz:
- vector o'zgaruvchan sonli qiymatlarni bir-birining yonida saqlashga imkon beradi.
- string - bu belgilar to'plami. Biz
Stringturini avval aytib o'tgan edik, ammo bu bobda biz bu haqda chuqurroq gaplashamiz. - hash map ma'lum bir kalit bilan qiymatni bog'lash imkonini beradi.Bu map deb nomlangan umumiy ma'lumotlar strukturasining o'ziga xos tatbiqidir.
Standart kutubxona tomonidan taqdim etilgan boshqa turdagi to'plamlar haqida bilish uchun texnik hujjatlarga qarang.
Biz vectorlarni, stringlarni va hash-maplarni qanday yaratish va yangilashni, shuningdek, har birining o'ziga xosligini muhokama qilamiz.
Vectorlar bilan qiymatlar ro'yxatini saqlash
Biz ko'rib chiqadigan birinchi to'plam turi Vec<T> bo'lib, u vector sifatida ham tanilgan.
Vectorlar xotirada barcha qiymatlarni yonma-yon joylashtirgan yagona ma'lumotlar strukturasida bir nechta qiymatlarni saqlash imkonini beradi. Vectorlar faqat bir xil turdagi qiymatlarni saqlashi mumkin. Ular sizda fayldagi matn satrlari yoki xarid qilish savatidagi narsalarning narxlari kabi elementlar ro'yxatiga ega bo'lsangiz foydali bo'ladi.
Yangi vector yaratish
Yangi bo'sh vector yaratish uchun biz 8-1 ro'yxatda ko'rsatilganidek, Vec::new funksiyasini chaqiramiz.
fn main() { let v: Vec<i32> = Vec::new(); }
Roʻyxat 8-1: i32 turidagi qiymatlarni saqlash uchun yangi, boʻsh vector yaratish
E'tibor bering, biz bu erda annation tur qo'shdik. Biz ushbu vectorga hech qanday qiymat kiritmayotganimiz sababli, Rust biz qanday elementlarni saqlashni xohlayotganimizni bilmaydi. Bu muhim nuqta. Vectorlar generiklar yordamida amalga oshiriladi; Biz 10-bobda o'zingizning turlaringiz bilan generiklardan qanday foydalanishni ko'rib chiqamiz. Hozircha shuni bilingki, standart kutubxona tomonidan taqdim etilgan Vec<T> turi har qanday turni sig'dira oladi.
Muayyan turni ushlab turish uchun vector yaratganimizda, burchakli qavslar([]) ichida turni belgilashimiz mumkin. 8-1 roʻyxatida biz Rustga vdagi Vec<T> i32 turidagi elementlarni saqlashini aytdik.
Ko'pincha siz boshlang'ich qiymatlari bilan Vec<T> ni yaratasiz va Rust siz saqlamoqchi bo'lgan qiymat turini aniqlaydi, shuning uchun kamdan-kam hollarda bu turdagi annotionni bajarishingiz kerak bo'ladi. Rust qulay tarzda vec! makrosini taqdim etadi, bu esa siz bergan qiymatlarni saqlaydigan yangi vectorni yaratadi. 8-2 roʻyxati 1, 2 va 3 qiymatlariga ega boʻlgan yangi Vec<i32>ni yaratadi. Butun son turi i32 dir, chunki bu standart butun son turi, biz 3-bobning "Ma'lumotlar turlari" bo'limida muhokama qilganimizdek.
fn main() { let v = vec![1, 2, 3]; }
Ro'yxat 8-2: qiymatlarni o'z ichiga olgan yangi vector yaratish
Biz boshlang‘ich i32 qiymatlarini berganimiz sababli, Rust v turi Vec<i32> ekanligini va tur izohi shart emas degan xulosaga kelishi mumkin. Keyinchalik vectorni qanday o'zgartirishni ko'rib chiqamiz.
Vectorni yangilash
Vector yaratish va unga elementlar qo'shish uchun biz 8-3 ro'yxatda ko'rsatilganidek, push metodidan foydalanishimiz mumkin.
fn main() { let mut v = Vec::new(); v.push(5); v.push(6); v.push(7); v.push(8); }
Ro'yxat 8-3: vectorga qiymatlar qo'shish uchun push metodidan foydalanish
Har qanday o'zgaruvchida bo'lgani kabi, agar biz uning qiymatini o'zgartirish imkoniyatiga ega bo'lishni istasak, 3-bobda muhokama qilinganimizdek, mut kalit so'zidan foydalanib, uni o'zgaruvchan qilishimiz kerak. Biz joylashtirgan raqamlarning barchasi i32 turiga kiradi va Rust buni maʼlumotlardan chiqaradi, shuning uchun bizga Vec<i32> annotationi kerak emas.
Vector elementlarini o'qish
Vectorda saqlangan qiymatga murojaat qilishning ikki yo'li mavjud: indekslash yoki get metodi yordamida. Quyidagi misollarda biz qo'shimcha aniqlik uchun ushbu funksiyalardan qaytariladigan qiymatlar turlarini izohladik.
8-4 ro'yxatda indekslash sintaksisi va get metodi bilan vectordagi qiymatga kirishning ikkala usuli ko'rsatilgan.
fn main() { let v = vec![1, 2, 3, 4, 5]; let uchinchi: &i32 = &v[2]; println!("Uchinchi element {uchinchi}"); let uchinchi: Option<&i32> = v.get(2); match uchinchi { Some(uchinchi) => println!("Uchinchi element {uchinchi}"), None => println!("Uchinchi element yo'q."), } }
Ro'yxat 8-4: Vectordagi elementga kirish uchun indekslash sintaksisi yoki get metodidan foydalanish
Bu erda bir nechta detallarga e'tibor bering. Uchinchi elementni olish uchun 2 indeks qiymatidan foydalanamiz, chunki vectorlar noldan boshlab raqamlar boʻyicha indekslanadi. & va [] dan foydalanish bizga indeks qiymatidagi elementga reference beradi. Argument sifatida berilgan indeks bilan get metodidan foydalansak, biz match bilan foydalanishimiz mumkin bo'lgan Option<&T>ni olamiz.
Rust elementga reference qilishning ushbu ikki usulini taqdim etishining sababi shundaki, siz mavjud elementlar doirasidan tashqarida indeks qiymatidan foydalanmoqchi bo'lganingizda dastur qanday harakat qilishini tanlashingiz mumkin. Misol sifatida, keling, besh elementli vectorga ega bo'lganimizda nima sodir bo'lishini ko'rib chiqamiz va keyin 8-5 ro'yxatda ko'rsatilganidek, har bir texnikada 100 indeksidagi elementga kirishga harakat qilamiz.
fn main() { let v = vec![1, 2, 3, 4, 5]; let mavjud_emas = &v[100]; let mavjud_emas = v.get(100); }
Ro'yxat 8-5: besh elementni o'z ichiga olgan vectorda 100 indeksidagi elementga kirishga urinish
Ushbu kodni ishga tushirganimizda, birinchi [] metodi dasturda panic chiqaradi, chunki u mavjud bo'lmagan elementga murojaat qiladi. Ushbu usul vector oxiridan o'tgan elementga kirishga urinish bo'lsa, dasturingiz ishdan chiqishini xohlasangiz yaxshi qo'llaniladi.
get metodi vectordan tashqaridagi indeksdan o'tganda, panic qo'ymasdan Noneni qaytaradi. Vector doirasidan tashqaridagi elementga kirish vaqti-vaqti bilan oddiy sharoitlarda sodir bo'lishi mumkin bo'lsa, siz ushbu usuldan foydalanasiz. Keyin sizning kodingiz 6-bobda muhokama qilinganidek, Some(&element) yoki Nonega ega bo'lish mantiqiga ega bo'ladi.Misol uchun, indeks raqamni kiritgan odamdan kelib chiqishi mumkin. Agar ular tasodifan juda katta raqamni kiritsa va dastur None qiymatiga ega bo'lsa, siz foydalanuvchiga joriy vectorda nechta element borligini aytishingiz va ularga to'g'ri qiymat kiritish uchun yana bir imkoniyat berishingiz mumkin.Bu imlo xatosi tufayli dasturni buzishdan ko'ra foydalanuvchilar uchun qulayroq bo'lar edi!
Dasturda tegishli reference mavjud bo'lsa, borrow tekshiruvi ushbu reference va vector mazmuniga boshqa har qanday referencelar haqiqiyligini ta'minlash uchun ownership va borrowing qoidalarini (4-bobda ko'rsatilgan) amalga oshiradi. Bir xil doirada o'zgaruvchan va o'zgarmas referencelarga ega bo'lolmaysiz degan qoidani eslang. Ushbu qoida 8-6 ro'yxatda qo'llaniladi, bu yerda biz vectordagi birinchi elementga o'zgarmas referenceni ushlab turamiz va elementni oxiriga qo'shishga harakat qilamiz. Agar biz ushbu elementga keyinroq funksiyada murojaat qilsak, bu dastur ishlamaydi:
fn main() {
let mut v = vec![1, 2, 3, 4, 5];
let birinchi = &v[0];
v.push(6);
println!("Birinchi element: {birinchi}");
}Ro'yxat 8-6. Vector elementiga reference mavjud bo'lganda vectorga biron bir element qo'shishga urinish
Ushbu kodni kompilyatsiya qilish ushbu xatoga olib keladi:
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
error[E0502]: cannot borrow `v` as mutable because it is also borrowed as immutable
--> src/main.rs:6:5
|
4 | let birinchi = &v[0];
| - immutable borrow occurs here
5 |
6 | v.push(6);
| ^^^^^^^^^ mutable borrow occurs here
7 |
8 | println!("Birinchi element: {birinchi}");
| ----------- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `collections` due to previous error
8-6 ro'yxatdagi kod ishlashi kerakdek ko'rinishi mumkin: nima uchun birinchi elementga reference vector oxiridagi o'zgarishlar haqida qayg'urishi kerak? Bu xato vectorlarning ishlash usuli bilan bog'liq: vectorlar qiymatlarni xotirada bir-birining yoniga qo'yganligi sababli vector oxiriga yangi element qo'shish yangi xotira ajratishni va eski elementlarni yangi bo'sh joyga ko'chirishni talab qilishi mumkin. Hozirda vector saqlanadigan barcha elementlarni bir-birining yoniga qo'yish uchun joy etarli emas. Bunday holda, birinchi elementga reference ajratilgan xotiraga ishora qiladi. Borrowing qoidalari dasturlarning bunday vaziyatga tushishiga yo'l qo'ymaydi.
Eslatma:
Vec<T>turini implement qilish haqida ko'proq ma'lumot olish uchun "Rustonomikon" ga qarang.
Vectordagi qiymatlarni takrorlash
Vectordagi har bir elementga navbatma-navbat kirish uchun biz indekslarni birma-bir kirish uchun ishlatmasdan, barcha elementlarni takrorlaymiz. 8-7 ro'yxatda i32 qiymatlari vectoridagi har bir elementga o'zgarmas referencelarni olish va ularni chop etish uchun for siklidan qanday foydalanish ko'rsatilgan.
fn main() { let v = vec![100, 32, 57]; for i in &v { println!("{i}"); } }
Ro'yxat 8-7: for sikli yordamida elementlarni takrorlash orqali vectordagi har bir elementni chop etish
Shuningdek, biz barcha elementlarga o'zgartirish kiritish uchun o'zgaruvchan vectordagi har bir elementga o'zgaruvchan referencelarni takrorlashimiz mumkin. 8-8 ro'yxatdagi for sikli har bir elementga 50 qo'shadi.
fn main() { let mut v = vec![100, 32, 57]; for i in &mut v { *i += 50; } }
Ro'yxat 8-8: Vectordagi elementlarga o'zgaruvchan referencelarni takrorlash
O'zgaruvchan reference nazarda tutilgan qiymatni o'zgartirish uchun biz += operatoridan foydalanishimizdan oldin i qiymatiga o'tish uchun * dereference operatoridan foydalanishimiz kerak. Biz 15-bobning "Dereference operatori bilan ko'rsatgichni qiymatga kuzatib borish" bo'limida dereference operatori haqida ko'proq gaplashamiz.
O'zgarmas yoki o'zgaruvchan bo'lsin, vector bo'yicha takrorlash, borrow tekshiruvi qoidalari tufayli xavfsizdir. Agar biz 8-7 va 8-8 ro'yxatlardagi for siklining tanasiga elementlarni qo'shishga yoki olib tashlashga harakat qilsak, biz 8-6 ro'yxatdagi kodga o'xshash kompilyator xatosiga duch kelamiz. for siklidagi vectorga murojaat qilish butun vectorni bir vaqtning o'zida o'zgartirishni oldini oladi.
Bir nechta turlarni saqlash uchun enumdan foydalanish
Vectorlar faqat bir xil turdagi qiymatlarni saqlashi mumkin. Bu noqulay bo'lishi mumkin; Har xil turdagi elementlar ro'yxatini saqlash zarurati uchun, albatta, foydalanish holatlari mavjud. Yaxshiyamki, enumlashning variantlari bir xil enum turi ostida aniqlanadi, shuning uchun bizga har xil turdagi elementlarni ko'rsatish uchun bitta tur kerak bo'lganda, enumni aniqlashimiz va ishlatishimiz mumkin!
Misol uchun, biz elektron jadvalning bir qator ustunlarida integer sonlar, ba'zi float raqamlar va ba'zi stringlar mavjud bo'lgan satrdan qiymatlarni olishni xohlaymiz. Variantlari turli qiymat turlariga ega bo'lgan enumni aniqlashimiz mumkin va barcha enum variantlari bir xil turdagi hisoblanadi: enum. Keyin biz ushbu enumni ushlab turish uchun vectorni yaratishimiz mumkin va natijada har xil turlarni ushlab turadi. Biz buni 8-9 ro'yxatda ko'rsatdik.
fn main() { enum ElektronJadval { Int(i32), Float(f64), Text(String), } let qator = vec![ ElektronJadval::Int(3), ElektronJadval::Text(String::from("ko'k")), ElektronJadval::Float(10.12), ]; }
Ro'yxat 8-9: Har xil turdagi qiymatlarni bitta vectorda saqlash uchun enumni aniqlash
Rust kompilyatsiya vaqtida vectorda qanday turlar bo'lishini bilishi kerak, shuning uchun u har bir elementni saqlash uchun heapda qancha xotira kerakligini aniq biladi. Shuningdek, ushbu vectorda qanday turlarga ruxsat berilganligini aniq bilishimiz kerak. Agar Rust vectorga har qanday turni ushlab turishga ruxsat bergan bo'lsa, bir yoki bir nechta tur vector elementlari ustida bajarilgan operatsiyalarda xatoliklarni keltirib chiqarishi mumkin edi. Enum va match ifodasidan foydalanish Rust kompilyatsiya vaqtida 6-bobda muhokama qilinganidek, barcha mumkin bo'lgan holatlar ko'rib chiqilishini ta'minlaydi.
Agar siz vectorda saqlash uchun dastur runtimeda oladigan turlarning to'liq to'plamini bilmasangiz, enum texnikasi ishlamaydi. Buning o'rniga, biz 17-bobda ko'rib chiqiladigan trait obyektidan foydalanishingiz mumkin.
Endi biz vectorlardan foydalanishning eng keng tarqalgan usullarini ko'rib chiqdik, standart kutubxona tomonidan Vec<T> da belgilangan barcha foydali usullar uchun API texnik hujjatlarini ko'rib chiqishni unutmang. Masalan, push dan tashqari, pop usuli oxirgi elementni olib tashlaydi va qaytaradi.
Vectordan elementlarni olib tashlash
structlar singari, vector ham 8-10 ro'yxatda ko'rsatilganidek, amal qilish doirasidan tashqariga chiqqanda xotirasini bo'shatadi.
fn main() { { let v = vec![1, 2, 3, 4]; // v bilan ish } // <- v doiradan chiqib ketadi va bu erda bo'shatiladi }
Ro'yxat 8-10. Vector va uning elementlarini qanday o'chirishni ko'rsatadi
Vector o'chirilganda, uning barcha tarkibi ham o'chiriladi: vectorni o'chirish uning tarkibidagi qiymatlarni o'chirishni anglatadi. Borrow tekshiruvi vector mazmuniga har qanday referencelar faqat vectorning o'zi haqiqiy bo'lganda ishlatilishini ta'minlaydi.
Keling, keyingi to'plam turiga o'tamiz: String!
UTF-8 kodlangan matnni String bilan saqlash
Biz 4-bobda stringlar haqida gapirgan edik, ammo hozir ularni batafsil ko'rib chiqamiz. Yangi Rustaceanlar odatda uchta sababning kombinatsiyasiga ko'ra stringlarga yopishib qolishadi: Rustning mumkin bo'lgan xatolarni ochishga moyilligi, stringlar ko'plab dasturchilar tushunganidan ko'ra murakkabroq ma'lumotlar tuzilishi va UTF-8. Bu omillar shunday birlashadiki, agar siz boshqa dasturlash tillaridan kelgan bo'lsangiz, mavzu murakkab ko'rinishi mumkin.
To'plamlar kontekstida stringlarni muhokama qilish foydalidir, chunki stringlar baytlar to'plami sifatida amalga oshiriladi, shuningdek, bu baytlar matn sifatida talqin qilinganda foydali funksiyalarni ta'minlashning ba'zi usullari. Ushbu bo'limda biz String bo'yicha har bir to'plam turiga ega bo'lgan yaratish, yangilash va o'qish kabi operatsiyalar haqida gapiramiz. Shuningdek, biz String ning boshqa to'plamlardan qanday farq qilishini, ya'ni String ga indekslash odamlar va kompyuterlarning String ma'lumotlarini qanday talqin qilishlari o'rtasidagi farqlar tufayli qanday murakkablashishini muhokama qilamiz.
String nima?
Biz birinchi navbatda string atamasi bilan nimani nazarda tutayotganimizni aniqlaymiz. Rust asosiy tilda faqat bitta string turiga ega, bu str qator slice boʻlib, odatda uning &str shaklida koʻrinadi. 4-bobda biz boshqa joyda saqlangan ba'zi UTF-8 kodlangan string ma'lumotlariga referencelar bo'lgan string slicelar haqida gaplashdik. Masalan, satr literallari dasturning binary tizimida saqlanadi va shuning uchun satr slicedir.
Rust standart kutubxonasi tomonidan taqdim etilgan String turi asosiy tilga o'rnatilmagan va kengaytiriladigan, o'zgaruvchan, ega bo'lgan, UTF-8 kodlangan string turidir. Rustaceanlar Rust tilidagi "stringlar" ga murojaat qilganda, ular bu turlardan birini emas, balki String yoki string slice &str turlarini nazarda tutishi mumkin. Garchi bu bo'lim asosan String haqida bo'lsa-da, ikkala tur ham Rust standart kutubxonasida ko'p qo'llaniladi, String va string slicelari UTF-8 da kodlangan.
Yangi String yaratish
Vec<T> bilan mavjud bo'lgan bir xil amallarning ko'pchiligi String bilan ham mavjud, chunki String aslida qo'shimcha kafolatlar, cheklovlar va imkoniyatlarga ega baytlar vectori atrofida o'rash sifatida amalga oshiriladi. Vec<T> va String bilan bir xil ishlaydigan funksiyaga misol qilib, 8-11 ro'yxatda ko'rsatilgan yangi turdagi misolni yaratuvchi new funksiyadir.
fn main() { let mut s = String::new(); }
Ro'yxat 8-11: Yangi, bo'sh String yaratish
Ushbu satr s deb nomlangan yangi bo'sh qatorni yaratadi, biz keyin unga ma'lumotlarni yuklashimiz mumkin. Ko'pincha, biz stringni boshlamoqchi bo'lgan dastlabki ma'lumotlarga ega bo'lamiz. Buning uchun biz string literallari kabi Display traittini amalga oshiradigan har qanday turda mavjud bo'lgan to_string metotidan foydalanamiz. Ro'yxat 8-12 ikkita misolni ko'rsatadi.
fn main() { let malumot = "dastlabki tarkib"; let s = malumot.to_string(); // the method also works on a literal directly: let s = "dastlabki tarkib".to_string(); }
Ro'yxat 8-12: string literalidan String yaratish uchun to_string metodidan foydalanish
Bu kod dastlabki tarkibni o‘z ichiga olgan stringni yaratadi.
Satr literalidan String yaratish uchun String::from funksiyasidan ham foydalanishimiz mumkin. 8-13 ro'yxatdagi kod to_string funksiyasidan foydalanadigan 8-12 ro'yxatdagi kodga teng:
fn main() { let s = String::from("dastlabki tarkib"); }
Ro'yxat 8-13: string literalidan String yaratish uchun String::from funksiyasidan foydalanish
Stringlar juda ko'p narsalar uchun ishlatilganligi sababli, biz stringlar uchun juda ko'p turli xil umumiy API'lardan foydalanishimiz mumkin, bu bizga juda ko'p imkoniyatlarni taqdim etadi. Ulardan ba'zilari ortiqcha bo'lib tuyulishi mumkin, ammo ularning barchasi o'z joylariga ega! Bunday holda, String::from va to_string bir xil ishni bajaradi, shuning uchun tanlov sizga eng yoqqan uslubga bog'liq.
Yodda tutingki, stringlar UTF-8 bilan kodlangan, shuning uchun 8-14 ro'yxatda ko'rsatilganidek, biz ularga har qanday to'g'ri kodlangan ma'lumotlarni kiritishimiz mumkin.
fn main() { let hello = String::from("السلام عليكم"); let hello = String::from("Dobrý den"); let hello = String::from("Hello"); let hello = String::from("שָׁלוֹם"); let hello = String::from("नमस्ते"); let hello = String::from("こんにちは"); let hello = String::from("안녕하세요"); let hello = String::from("你好"); let hello = String::from("Olá"); let hello = String::from("Salom"); let hello = String::from("Здравствуйте"); let hello = String::from("Hola"); }
Ro'yxat 8-14: Salom so'zini turli tillarda stringlarda saqlash
Bularning barchasi yaroqli String qiymatlari.
Stringni yangilash
Agar siz unga ko'proq ma'lumot kiritsangiz, String hajmi kattalashishi mumkin va uning tarkibi Vec<T> tarkibidagi kabi o'zgarishi mumkin. Bundan tashqari, String qiymatlarini birlashtirish uchun + operatori yoki format! makrosidan qulay foydalanish mumkin.
push_str va push yordamida stringga biriktirish
Biz 8-15 roʻyxatda koʻrsatilganidek, string boʻlagini qoʻshish uchun push_str metodidan foydalanib Stringni kengaytirishimiz mumkin.
fn main() { let mut s = String::from("dastur"); s.push_str("chi"); }
Roʻyxat 8-15: push_str metodi yordamida String ga satr boʻlagini qoʻshish
Ushbu ikki qatordan keyin s tarkibida dasturchi bo'ladi. push_str metodi string bo'lagini oladi, chunki biz parametrga egalik qilishni xohlamaymiz. Masalan, 8-16 roʻyxatdagi kodda biz uning mazmunini s1 ga qoʻshgandan soʻng s2 dan foydalanish imkoniyatiga ega boʻlishni xohlaymiz.
fn main() { let mut s1 = String::from("dastur"); let s2 = "chi"; s1.push_str(s2); println!("s2 - {s2}"); }
Ro'yxat 8-16: Tarkibni String ga qo'shgandan so'ng, string bo'lagidan foydalanish
Agar push_str metodi s2 ga egalik qilgan bo‘lsa, biz uning qiymatini oxirgi satrda chop eta olmaymiz. Biroq, bu kod biz kutgandek ishlaydi!
push metodi parametr sifatida bitta belgini oladi va uni String ga qo'shadi. 8-17 ro'yxatda push metodi yordamida String ga v harfi qo'shiladi.
fn main() { let mut s = String::from("su"); s.push('v'); }
Roʻyxat 8-17: push yordamida String qiymatiga bitta belgi qoʻshish
Natijada, s tarkibida suv bo'ladi.
+ operatori yoki format! makrosidan foydalanib satrlarni birlashtirish
Ko'pincha siz ikkita mavjud satrni birlashtirishni xohlaysiz. Buning usullaridan biri 8-18 ro'yxatda ko'rsatilganidek, + operatoridan foydalanishdir.
fn main() { let s1 = String::from("Salom, "); let s2 = String::from("Rust!"); let s3 = s1 + &s2; // note s1 has been moved here and can no longer be used }
Roʻyxat 8-18: Ikkita String qiymatini yangi String qiymatiga birlashtirish uchun + operatoridan foydalanish
s3 qatorida Salom, Rust! bo'ladi. Qo‘shishdan keyin s1 ning endi haqiqiy emasligi va s2ga referenceni qo‘llaganimiz sababi + operatoridan foydalanganda chaqirilayotgan metodning imzosi bilan bog‘liq.
+ operatori add metodidan foydalanadi, uning imzosi quyidagicha ko'rinadi:
fn add(self, s: &str) -> String {Standart kutubxonada siz umumiy va tegishli turlar yordamida aniqlangan addni ko'rasiz. Bu erda biz aniq turlarni almashtirdik, bu metodni String qiymatlari bilan chaqirganimizda sodir bo'ladi. Biz 10-bobda generiklarni muhokama qilamiz.
Ushbu imzo bizga + operatorining murakkab bitlarini tushunishimiz kerak bo'lgan maslahatlarni beradi.
Birinchidan, s2 & belgisiga ega, ya'ni biz birinchi satrga ikkinchi satrning referenceni qo'shmoqdamiz. Buning sababi add funksiyasidagi s parametri: biz faqat Stringga &str qo'shishimiz mumkin; biz ikkita String qiymatini qo'sha olmaymiz. Lekin kuting – &s2 turi add uchun ikkinchi parametrda ko‘rsatilganidek, &str emas, &Stringdir. Xo'sh, nima uchun 8-18 ro'yxatdagi kod kompilyatsiya bo'ladi?
add chaqiruvida &s2 dan foydalanishimiz sababi shundaki, kompilyator &String argumentini &str ga majburlashi(coerce) mumkin. Biz add metodini chaqirganimizda Rust deref coercion dan foydalanadi, bu erda &s2 ni &s2[..] ga aylantiradi.
Biz 15-bobda coercion haqida batafsilroq gaplashamiz. add s parametriga egalik qilmaganligi sababli, s2 bu amaldan keyin ham haqiqiy String bo'lib qoladi.
Ikkinchidan, imzoda add self egalik qilishini ko'rishimiz mumkin, chunki selfda & yo'q. Bu shuni anglatadiki, 8-18-sonli ro'yxatdagi s1 add chaqiruviga o'tkaziladi va bundan keyin endi yaroqsiz bo'ladi. Shunday qilib, let s3 = s1 + &s2; har ikkala satrdan nusxa ko'chiradigan va yangisini yaratadiganga o'xshasa-da, bu statement aslida s1ga egalik qiladi va s2 mazmunining nusxasini qo'shadi, va keyin natijaga egalik huquqini qaytaradi. Boshqacha qilib aytganda, u juda ko'p nusxa ko'chirayotganga o'xshaydi, lekin unday emas; implement qilish nusxalashdan ko'ra samaraliroq.
Agar biz bir nechta satrlarni birlashtirishimiz kerak bo'lsa, + operatorining xatti-harakati noqulay bo'ladi:
fn main() { let s1 = String::from("tic"); let s2 = String::from("tac"); let s3 = String::from("toe"); let s = s1 + "-" + &s2 + "-" + &s3; }
Bu vaqtda s tic-tac-toe bo'ladi. Barcha + va " belgilar bilan nima sodir bo'layotganini ko'rish qiyin. Murakkab qatorlarni birlashtirish uchun biz format! makrosidan foydalanishimiz mumkin:
fn main() { let s1 = String::from("tic"); let s2 = String::from("tac"); let s3 = String::from("toe"); let s = format!("{s1}-{s2}-{s3}"); }
Ushbu kod s ni tic-tac-toe ga ham o'rnatadi. format! makrosi println! kabi ishlaydi, lekin natijani ekranga chop etish o'rniga mazmuni bilan Stringni qaytaradi. Kodning format! dan foydalanilgan versiyasini o‘qish ancha oson va format! makrosi tomonidan yaratilgan kod bu chaqiruv uning parametrlaridan birortasiga egalik qilmasligi uchun havolalardan foydalanadi.
Stringlarni indekslash
Ko'pgina boshqa dasturlash tillarida stringdagi alohida belgilarga indeks bo'yicha murojaat qilish orqali kirish to'g'ri va keng tarqalgan operatsiya hisoblanadi. Biroq, agar siz Rust-da indekslash sintaksisidan foydalanib, String qismlariga kirishga harakat qilsangiz, xatoga duch kelasiz. 8-19 ro'yxatdagi noto'g'ri kodni ko'rib chiqing.
fn main() {
let s1 = String::from("salom");
let h = s1[0];
}Ro'yxat 8-19: String bilan indekslash sintaksisidan foydalanishga urinish
Ushbu kod quyidagi xatoga olib keladi:
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
error[E0277]: the type `String` cannot be indexed by `{integer}`
--> src/main.rs:3:13
|
3 | let h = s1[0];
| ^^^^^ `String` cannot be indexed by `{integer}`
|
= help: the trait `Index<{integer}>` is not implemented for `String`
= help: the following other types implement trait `Index<Idx>`:
<String as Index<RangeFrom<usize>>>
<String as Index<RangeFull>>
<String as Index<RangeInclusive<usize>>>
<String as Index<RangeTo<usize>>>
<String as Index<RangeToInclusive<usize>>>
<String as Index<std::ops::Range<usize>>>
For more information about this error, try `rustc --explain E0277`.
error: could not compile `collections` due to previous error
Xato va eslatma Rust indekslashni qo'llab-quvvatlamasligini aytadi. Lekin nega yo'q? Bu savolga javob berish uchun Rust stringlarni xotirada qanday saqlashini muhokama qilishimiz kerak.
Ichki vakillik
String turi - bu Vec<u8> turidagi wrapper. Keling, 8-14 ro'yxatdagi to'g'ri kodlangan UTF-8 misol stringlarini ko'rib chiqaylik. Birinchidan, bu:
fn main() { let hello = String::from("السلام عليكم"); let hello = String::from("Dobrý den"); let hello = String::from("Hello"); let hello = String::from("שָׁלוֹם"); let hello = String::from("नमस्ते"); let hello = String::from("こんにちは"); let hello = String::from("안녕하세요"); let hello = String::from("你好"); let hello = String::from("Olá"); let hello = String::from("Salom"); let hello = String::from("Здравствуйте"); let hello = String::from("Hola"); }
Bunday holda, len 4 bo'ladi, ya'ni "Hola" qatorini saqlaydigan vektor 4 bayt uzunlikda. Bu harflarning har biri UTF-8 da kodlanganda 1 baytni oladi. Biroq, keyingi qator sizni hayratda qoldirishi mumkin. (E'tibor bering, bu qator arabcha 3 raqami emas, kirill alifbosining bosh harfi Ze bilan boshlanadi.)
fn main() { let hello = String::from("السلام عليكم"); let hello = String::from("Dobrý den"); let hello = String::from("Hello"); let hello = String::from("שָׁלוֹם"); let hello = String::from("नमस्ते"); let hello = String::from("こんにちは"); let hello = String::from("안녕하세요"); let hello = String::from("你好"); let hello = String::from("Olá"); let hello = String::from("Salom"); let hello = String::from("Здравствуйте"); let hello = String::from("Hola"); }
String uzunligi so'ralganda, siz 12 deb aytishingiz mumkin. Aslida, Rustning javobi 24: bu UTF 8 da “Здравствуйте” ni kodlash uchun zarur bo'lgan baytlar soni, chunki bu satrdagi har bir Unicode skalyar qiymati 2 bayt xotirani oladi. Shuning uchun, satr baytlaridagi indeks har doim ham haqiqiy Unicode skalyar qiymatiga mos kelmaydi. Namoyish qilish uchun ushbu yaroqsiz Rust kodini ko'rib chiqing:
let salom = "Здравствуйте";
let javob = &salom[0];Siz allaqachon bilasizki, javob birinchi harf bo'lgan З bo'lmaydi. UTF-8 da kodlanganda, З birinchi bayti 208, ikkinchisi esa 151, shuning uchun javob aslida 208 bo'lishi kerakdek tuyuladi, lekin 208 o'z-o'zidan haqiqiy belgi emas. Agar foydalanuvchi ushbu qatorning birinchi harfini so'ragan bo'lsa, 208 ni qaytarish, ehtimol bu emas; ammo, bu Rust bayt indeksi 0 bo'lgan yagona ma'lumotdir. Foydalanuvchilar odatda bayt qiymatini qaytarishni xohlamaydilar, hatto satrda faqat lotin harflari bo‘lsa ham: agar &“hello”[0] bayt qiymatini qaytaruvchi yaroqli kod bo‘lsa, u h emas, 104ni qaytaradi. .
Javob shundaki, kutilmagan qiymatni qaytarmaslik va darhol topilmasligi mumkin bo'lgan xatolarni keltirib chiqarmaslik uchun Rust ushbu kodni umuman kompilyatsiya qilmaydi va ishlab chiqish jarayonida tushunmovchiliklarning oldini oladi.
Baytlar va skalyar qiymatlar va grafema klasterlari!
UTF-8 bilan bog'liq yana bir nuqta shundaki, Rust nuqtai nazaridan satrlarga qarashning uchta mos usuli mavjud: baytlar, skalyar qiymatlar va grafema klasterlari (biz harflar deb ataydigan narsaga eng yaqin narsa).
Devanagari skriptida yozilgan hindcha “नमस्ते” so'ziga qarasak, u u8 qiymatlari vektori sifatida saqlanadi, bu quyidagicha ko'rinadi:
[224, 164, 168, 224, 164, 174, 224, 164, 184, 224, 165, 141, 224, 164, 164,
224, 165, 135]
Bu 18 bayt va kompyuterlar oxir-oqibat bu ma'lumotlarni qanday saqlaydi. Agar biz ularni Rustning char turiga ega bo'lgan Unicode skalyar qiymatlari sifatida qarasak, bu baytlar quyidagicha ko'rinadi:
['न', 'म', 'स', '्', 'त', 'े']
Bu yerda oltita char qiymati bor, lekin to'rtinchi va oltinchi harflar emas: ular o'z-o'zidan ma'noga ega bo'lmagan diakritikdir. Nihoyat, agar baytlarni grafema klasterlari sifatida ko'rib chiqsak, inson to'rt harfli hindcha so'z deb ataydigan narsani olamiz:
["न", "म", "स्", "ते"]
Rust kompyuterlar saqlaydigan ma'lumotlar qatorini talqin qilishning turli usullarini taqdim etadi, shunda ma'lumotlar qaysi inson tilida bo'lishidan qat'i nazar, har bir dastur kerakli talqinni tanlashi mumkin.
Rust bizga belgini olish uchun String ga indekslashga ruxsat bermasligining yakuniy sababi shundaki, indekslash operatsiyalari doimo konstanta(doimiy) vaqtni oladi (O(1)). Ammo String bilan ishlashni kafolatlab bo‘lmaydi, chunki Rust qancha to‘g‘ri belgilar mavjudligini aniqlash uchun tarkibni boshidan indeksgacha bosib o‘tishi kerak edi.
String bo'laklari
Satrni indekslash ko'pincha noto'g'ri fikrdir, chunki satrni indekslash operatsiyasining qaytish turi qanday bo'lishi kerakligi aniq emas: bayt qiymati, belgi, grafema klasteri yoki satr bo'lagi. Agar chindan ham string bo'laklarini yaratish uchun indekslardan foydalanish kerak bo'lsa, Rust sizdan aniqroq bo'lishingizni so'raydi.
Bitta raqam bilan [] yordamida indeksatsiya qilish o'rniga, muayyan baytlarni o'z ichiga olgan string bo'laklarini yaratish uchun diapazon bilan [] dan foydalanishingiz mumkin:
#![allow(unused)] fn main() { let salom = "Здравствуйте"; let s = &salom[0..4]; }
Bu erda s qatorning dastlabki 4 baytini o'z ichiga olgan &str bo'ladi.
Avvalroq, biz ushbu belgilarning har biri 2 baytdan iborat bo'lganligini aytib o'tgan edik, ya'ni s Зд bo'ladi.
Agar biz &salom[0..1] kabi belgi baytlarining faqat bir qismini kesishga harakat qilsak, Rust ish runtimeda xuddi vektordagi yaroqsiz indeksga kirish kabi panic qo'yadi:
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
Finished dev [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/collections`
thread 'main' panicked at 'byte index 1 is not a char boundary; it is inside 'З' (bytes 0..2) of `Здравствуйте`', src/main.rs:4:14
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Ehtiyotkorlik bilan string bo'laklarni yaratish uchun diapazonlardan foydalanishingiz kerak, chunki bu dasturni buzishi mumkin.
Stringlarni takrorlash usullari
String bo'laklari bilan ishlashning eng yaxshi usuli - belgilar yoki baytlarni xohlaysizmi, aniq bo'lishdir. Unicode skalyar qiymatlari uchun chars metodidan foydalaning. “Зд” da charsni chaqirish char turidagi ikkita qiymatni ajratib turadi va qaytaradi va har bir elementga kirish uchun natijani takrorlashingiz mumkin:
#![allow(unused)] fn main() { for c in "Зд".chars() { println!("{c}"); } }
Ushbu kod quyidagilarni chop etadi:
З
д
Shu bilan bir qatorda, bytes metodi boshqa domenga mos kelishi mumkin bo'lgan har bir baytni qaytaradi:
#![allow(unused)] fn main() { for b in "Зд".bytes() { println!("{b}"); } }
Ushbu kod ushbu satrni tashkil etuvchi to'rt baytni chop etadi:
208
151
208
180
Lekin esda tutingki, joriy Unicode skalyar qiymatlari 1 baytdan ortiq bo'lishi mumkin.
Devanagari skriptidagi kabi satrlardan grafema klasterlarini olish juda murakkab, shuning uchun bu funksiya standart kutubxona tomonidan ta'minlanmagan. Agar sizga ushbu funksiya kerak bo'lsa, crates.io saytida cratelar mavjud.
Stringlar unchalik oddiy emas
Xulosa qilib aytganda, satrlar murakkab. Turli xil dasturlash tillari ushbu murakkablikni dasturchiga qanday taqdim etish bo'yicha turli xil tanlovlar qiladi. Rust String ma'lumotlarini to'g'ri ishlashni barcha Rust dasturlari uchun standart xatti-harakatga aylantirishni tanladi, bu esa dasturchilar UTF-8 ma'lumotlari bilan ishlash haqida oldindan ko'proq o'ylashlari kerakligini anglatadi. Ushbu o'zaro kelishuv boshqa dasturlash tillarida ko'rinadiganidan ko'ra ko'proq stringlarning murakkabligini ochib beradi, lekin keyinchalik ishlab chiqish jarayonida paydo bo'lishi mumkin bo'lgan ASCII bo'lmagan belgilar xatolarini qayta ishlash zaruratini oldini oladi.
Yaxshi xabar shundaki, standart kutubxona ushbu murakkab vaziyatlarni to'g'ri hal qilishga yordam beradigan String va &str turlaridan iborat ko'plab funksiyalarni taklif etadi. Satrda qidirish uchun contains va qator qismlarini boshqa satr bilan almashtirish uchun replace kabi foydali metodlar uchun texnik hujjatlarni ko'rib chiqing.
Keling, biroz murakkabroq narsaga o'taylik: HashMap!
Hash Maplarda bog'langan qiymatlarga ega kalitlarni saqlash
Umumiy to'plamlarimizning oxirgisi hash map. HashMap<K, V> turi K turidagi kalitlarning V turidagi qiymatlarga xaritasini xeshlash funksiyasi yordamida saqlaydi, bu kalit va qiymatlarni xotiraga qanday joylashtirishini belgilaydi. Ko'pgina dasturlash tillari bunday ma'lumotlar strukturasini qo'llab-quvvatlaydi, lekin ular ko'pincha bir nechtasini nomlash uchun hash, map, object, hash table, dictionary, yoki associative array kabi boshqa nomlardan foydalanadilar.
Hash maplar ma'lumotlarni vectorlar bilan bo'lgani kabi indeks yordamida emas, balki har qanday turdagi kalit yordamida qidirmoqchi bo'lsangiz foydali bo'ladi. Misol uchun, o'yinda siz har bir jamoaning balini hesh-mapda kuzatib borishingiz mumkin, unda har bir kalit jamoaning nomi va qiymatlar har bir jamoaning ballidir. Jamoa nomi berilgan bo'lsa, siz uning ballini olishingiz mumkin.
Ushbu bo'limda biz hesh-mapllarining asosiy API-ni ko'rib chiqamiz, ammo yana ko'plab foydali funksiyalar standart kutubxona tomonidan HashMap<K, V> da belgilangan funksiyalarda yashiringan.
Har doimgidek, qo'shimcha ma'lumot olish uchun standart kutubxona texnik hujjatlarini tekshiring.
Yangi Hash Map yaratish
Bo'sh hesh mapni yaratishning bir usuli - new dan foydalanish va insert bilan elementlarni qo'shish. 8-20 ro'yxatda biz nomlari Yashil va Sariq bo'lgan ikkita jamoaning ballarini kuzatib boramiz. Yashil jamoa 10 ball bilan, Sariq jamoa esa 50 ball bilan boshlanadi.
fn main() { use std::collections::HashMap; let mut ballar = HashMap::new(); ballar.insert(String::from("Yashil"), 10); ballar.insert(String::from("Sariq"), 50); }
Ro'yxat 8-20: Yangi hesh mapni yaratish va ba'zi kalitlar va qiymatlarni kiritish
E'tibor bering, biz birinchi navbatda standart kutubxonaning to'plamlar qismidagi HashMap dan foydalanishimiz kerak. Bu quyidagicha bo'ladi use std::collections::HashMap;. Bizning uchta keng tarqalgan to'plamlarimiz orasida bu eng kam qo'llaniladi, shuning uchun u muqaddimada avtomatik ravishda kiritilgan funtsiyalarga kiritilmagan. Hash Maplar standart kutubxonadan ham kamroq qo'llab-quvvatlanadi; masalan, ularni yaratish uchun o'rnatilgan makros mavjud emas.
Vectorlar singari, hash maplar ham o'z ma'lumotlarini heapda saqlaydi. Ushbu HashMapda String turidagi kalitlar va i32 turidagi qiymatlar mavjud. Vectorlar singari, hash maplar ham bir xildir: barcha kalitlar bir-biri bilan bir xil turdagi va barcha qiymatlar bir xil turga ega bo'lishi kerak.
HashMap-dagi ma'lumotlarga kirish
Biz 8-21 ro'yxatda ko'rsatilganidek, get metodiga kalitni taqdim etish orqali hash mapdan qiymat olishimiz mumkin.
fn main() { use std::collections::HashMap; let mut ballar = HashMap::new(); ballar.insert(String::from("Yashil"), 10); ballar.insert(String::from("Sariq"), 50); let jamoa_nomi = String::from("Yashil"); let ball = ballar.get(&jamoa_nomi).copied().unwrap_or(0); }
Ro'yxat 8-21: Hesh-Mapda saqlangan Yashil jamoa hisobiga kirish
Bu yerda ball Yashil jamoa bilan bog'liq qiymatga ega bo'ladi va natija 10 bo'ladi. get metodi Option<&V>ni qaytaradi; agar hesh-mapda ushbu kalit uchun qiymat bo'lmasa, get None ni qaytaradi. Bu dastur Option<&i32> emas, Option<i32> olish uchun copied ga murojaat qilib Optionni boshqaradi, so'ngra unwrap_or ballar da ushbu kalit uchun ma'lumotlar bo'lmasa, ballni nolga o'rnatish uchun.
Biz hesh-mapdagi har bir kalit/qiymat juftligini vectorlar bilan bo'lgani kabi, for siklidan foydalangan holda takrorlashimiz mumkin:
fn main() { use std::collections::HashMap; let mut ballar = HashMap::new(); ballar.insert(String::from("Yashil"), 10); ballar.insert(String::from("Sariq"), 50); for (key, value) in &ballar { println!("{key}: {value}"); } }
Ushbu kod har bir juftlikni tasodifiy tartibda chop etadi:
Sariq: 50
Yashil: 10
Hash Maplar va Ownership(Egalik)
Copy traitini amalga oshiradigan turlar uchun, masalan, i32, qiymatlar hesh-mapiga ko'chiriladi. String kabi tegishli qiymatlar uchun qiymatlar boshqa joyga koʻchiriladi va 8-22 roʻyxatda koʻrsatilganidek, hesh-map ushbu qiymatlarning egasi boʻladi.
fn main() { use std::collections::HashMap; let maydon_nomi = String::from("Sevimli rang"); let maydon_qiymati = String::from("Yashil"); let mut map = HashMap::new(); map.insert(maydon_nomi, maydon_qiymati); // maydon_nomi va maydon_qiymati hozirda yaroqsiz, ulardan foydalanib ko'ring va qanday // kompilyator xatosiga yo'l qo'yganingizni ko'ring! }
Ro'yxat 8-22: kalitlar va qiymatlar kiritilgandan so'ng ular hesh-mapda tegishli ekanligini ko'rsatish
maydon_nomi va maydon_qiymati o'zgaruvchilari qiymatlari insert metodini chaqirish orqali HashMap-ga ko'chirilgandan keyin foydalana olmaymiz.
Agar biz HashMap-ga qiymatlarga referencelar kiritsak, ular HashMap-ga ko'chirilmaydi. Murojaatlar ko'rsatadigan qiymatlar hech bo'lmaganda hesh-mapda amal qiladigan vaqt davomida amal qilishi kerak. Biz ushbu muammolar haqida 10-bobning "Lifetime bilan referencelarni tekshirish" bo'limida ko'proq gaplashamiz.
Hash Mapni yangilash
Kalit va qiymat juftlarining soni o'sishi mumkin bo'lsa-da, har bir noyob kalit bir vaqtning o'zida u bilan bog'langan faqat bitta qiymatga ega bo'lishi mumkin (lekin aksincha emas: masalan, Yashil jamoa ham, Sariq jamoa ham ballar hash-mapida saqlangan 10 qiymatiga ega bo'lishi mumkin).
Hash-mapdagi ma'lumotlarni o'zgartirmoqchi bo'lganingizda, kalit allaqachon tayinlangan qiymatga ega bo'lgan holatda qanday ishlashni hal qilishingiz kerak. Eski qiymatni butunlay e'tiborsiz qoldirib, eski qiymatni yangi qiymat bilan almashtirishingiz mumkin. Eski qiymatni saqlab qolishingiz va yangi qiymatni e'tiborsiz qoldirishingiz mumkin, faqat kalitda qiymat bo'lmasa, yangi qiymat qo'shishingiz mumkin. Yoki eski qiymat va yangi qiymatni birlashtira olasiz. Keling, bularning har birini qanday qilishni ko'rib chiqaylik!
Qiymatni qayta yozish
Agar biz kalit va qiymatni hash-mapga kiritsak va keyin boshqa qiymat bilan bir xil kalitni kiritsak, bu kalit bilan bog'langan qiymat almashtiriladi. Ro'yxat 8-23dagi kod ikki marta insert ni chaqirsa ham, hash-mapda faqat bitta kalit/qiymat juftligi bo'ladi, chunki biz har ikki marta Yashil jamoa kaliti qiymatini kiritamiz.
fn main() { use std::collections::HashMap; let mut ballar = HashMap::new(); ballar.insert(String::from("Yashil"), 10); ballar.insert(String::from("Yashil"), 25); println!("{:?}", ballar); }
Ro'yxat 8-23: Saqlangan qiymatni ma'lum bir kalit bilan almashtirish
Bu kod {"Yashil": 25}ni chop etadi. 10ning asl qiymati ustiga yozildi.
Kalit va qiymatni faqat kalit mavjud bo'lmaganda qo'shish
Hash Mapda ma'lum bir kalit allaqachon qiymatga ega yoki yo'qligini tekshirish odatiy holdir, keyin quyidagi amallarni bajaring: agar kalit hash-mapda mavjud bo'lsa, mavjud qiymat avvalgidek qolishi kerak. Agar kalit mavjud bo'lmasa, insert va uning qiymatini kiriting.
Hash Mapda buning uchun entry deb nomlangan maxsus API mavjud bo'lib, siz tekshirmoqchi bo'lgan kalitni parametr sifatida qabul qiladi. entry metodining qaytish qiymati Entry nomli enum bo‘lib, u mavjud yoki bo‘lmasligi mumkin bo‘lgan qiymatni ifodalaydi. Aytaylik, biz Sariq jamoa uchun kalitning u bilan bog'liq qiymati bor-yo'qligini tekshirmoqchimiz. Agar shunday bo'lmasa, biz 50 qiymatini qo'shishni xohlaymiz va Yashil jamoa uchun ham xuddi shunday. Entry API-dan foydalanib, kod Ro'yxat 8-24 kabi ko'rinadi.
fn main() { use std::collections::HashMap; let mut ballar = HashMap::new(); ballar.insert(String::from("Yashil"), 10); ballar.entry(String::from("Sariq")).or_insert(50); ballar.entry(String::from("Yashil")).or_insert(50); println!("{:?}", ballar); }
Ro'yxat 8-24: entry metodidan faqat kalitda qiymat mavjud bo'lmasa, kiritish uchun foydalanish
Entry da or_insert metodi mos keladigan Entry kaliti qiymatiga o'zgaruvchan referenceni qaytarish uchun belgilangan, agar bu kalit mavjud bo'lsa, parametrni ushbu kalit uchun yangi qiymat sifatida kiritadi va yangi qiymatga o'zgaruvchan referenceni qaytaradi. Ushbu metod mantiqni o'zingiz yozishdan ko'ra ancha toza va u xavfsizroq va borrowing qoidalariga mos keladi.
8-24-raqamdagi kodni ishga tushirish {"Sariq": 50, "Yashil": 10} chop etiladi. entry ga birinchi chaqiruv 50 qiymatiga ega Sariq jamoa uchun kalitni kiritadi, chunki sariq jamoada allaqachon qiymat yo'q. entry ga ikkinchi chaqiruv hash-mapni o'zgartirmaydi, chunki Yashil jamoa allaqachon 10 qiymatiga ega.
Eski qiymat asosida yangi qiymatni yangilash
Hash-Maplar uchun yana bir keng tarqalgan foydalanish holati kalit qiymatini izlash va keyin uni eski qiymat asosida yangilashdir. Misol uchun, 8-25 ro'yxatda har bir so'z ba'zi matnda necha marta takrorlanganini hisoblaydigan kodni ko'rsatadi. Biz kalit sifatida so'zlar bilan hash-mapdan foydalanamiz va bu so'zni necha marta ko'rganimizni kuzatib borish uchun qiymatni oshiramiz. Agar so'zni birinchi marta ko'rayotgan bo'lsak, avval 0 qiymatini kiritamiz.
fn main() { use std::collections::HashMap; let matn = "salom rust qiziqarli rust"; let mut map = HashMap::new(); for soz in matn.split_whitespace() { let hisoblash = map.entry(soz).or_insert(0); *hisoblash += 1; } println!("{:?}", map); }
Ro'yxat 8-25: So'zlar va hisoblarni saqlaydigan hash-mapi yordamida so'zlarning necha marta takrorlanganini hisoblash
Bu kod {"qiziqarli": 1, "salom": 1, "rust": 2}ni chop etadi. Siz boshqa tartibda chop etilgan bir xil kalit/qiymat juftliklarini ko'rishingiz mumkin: “Hash-Mapdagi qiymatlarga kirish” bo'limidan hash-mapni takrorlash ixtiyoriy tartibda sodir bo'lishini eslang.
split_whitespace metodi matn qiymatining bo'sh joy bilan ajratilgan pastki bo'limlari ustidan iteratorni qaytaradi.or_insert metodi belgilangan kalit qiymatiga o'zgaruvchan havolani (&mut V) qaytaradi. Bu yerda biz o'zgaruvchan referenceni hisoblash o'zgaruvchisida saqlaymiz, shuning uchun bu qiymatni belgilash uchun avval yulduzcha (*) yordamida hisoblash ga murojaat qilishimiz kerak. O'zgaruvchan reference for siklining oxirida ko'lamdan chiqib ketadi, shuning uchun bu o'zgarishlarning barchasi xavfsiz va borrowing qoidalari bilan ruxsat etiladi.
Hashing funksiyalari
Odatda, HashMap SipHash nomli hashlash funksiyasidan foydalanadi, u 1 hash-jadvallari ishtirokidagi Xizmatni rad etish (DoS) hujumlariga qarshilik ko'rsatishi mumkin. Bu mavjud bo'lgan eng tezkor hashlash algoritmi emas, lekin ishlashning pasayishi bilan birga keladigan yaxshi xavfsizlik uchun kelishuv bunga arziydi. Agar siz kodingizni profilga kiritsangiz va standart hash funksiyasi sizning maqsadlaringiz uchun juda sekin ekanligini aniqlasangiz, boshqa hasherni belgilash orqali boshqa funksiyaga o'tishingiz mumkin. hasher bu BuildHasher traitini amalga oshiradigan tur. Traitlar va ularni qanday implement qilish haqida 10-bobda gaplashamiz. Siz o'zingizning hasheringizni noldan implement qilishingiz shart emas; crates.io-da boshqa Rust foydalanuvchilari tomonidan baham ko'rilgan kutubxonalar mavjud bo'lib, ular ko'plab umumiy hashlash algoritmlarini implement qiladigan hasherlarni ta'minlaydi.
Xulosa
Vectorlar, stringlar va hash-maplar ma'lumotlarni saqlash, kirish va o'zgartirish kerak bo'lganda dasturlarda zarur bo'lgan katta hajmdagi funksionallikni ta'minlaydi. Mana endi hal qilish uchun tayyorlanishingiz kerak bo'lgan ba'zi mashqlar:
-
Butun sonlar roʻyxati berilgan boʻlsa, vectordan foydalaning va roʻyxatning medianasini (tartiblanganda, oʻrtadagi qiymat) va rejimni (koʻpincha sodir boʻladigan qiymat; bu yerda hash-map foydali boʻladi) qaytaring.
-
Satrlarni pig lotin tiliga aylantiring. Har bir so'zning birinchi undoshi so'z oxiriga ko'chiriladi va "ay" qo'shiladi, shuning uchun "birinchi" "birinchi-ay" bo'ladi. Unli tovush bilan boshlangan so‘zlarning oxiriga “hay” qo‘shiladi (“olma” “olma-hay”ga aylanadi). UTF-8 kodlash haqidagi tafsilotlarni yodda tuting!
-
Hash Map va vectorlardan foydalanib, foydalanuvchiga kompaniyadagi bo'limga xodimlarning ismlarini qo'shishga ruxsat berish uchun matn interfeysini yarating. Masalan, "Asilbekni muhandislikka qo'shish" yoki "Sardorni savdoga qo'shish". Keyin foydalanuvchi bo'limdagi barcha odamlar yoki kompaniyadagi barcha odamlar ro'yxatini bo'limlar bo'yicha, alifbo tartibida tartiblangan holda olishiga ruxsat bering.
Standart kutubxona API texnik hujjatlari vectorlar, stringlar va hash-maplarda ushbu mashqlar uchun foydali bo'lgan usullarni tavsiflaydi!
Biz operatsiyalar muvaffaqiyatsiz bo'lishi mumkin bo'lgan yanada murakkab dasturlarga kirishmoqdamiz, shuning uchun xatolarni hal qilishni muhokama qilish uchun ajoyib vaqt. Qani kettik.
Xatolar bilan ishlash
Xatolar dasturiy ta'minotdagi hayot haqiqatidir, shuning uchun Rust nimadir noto'g'ri bo'lgan vaziyatlarni hal qilish uchun bir qator xususiyatlarga ega. Ko'p hollarda Rust sizdan xatolik ehtimolini tan olishingizni va kodingizni kompilyatsiya qilishdan oldin ba'zi choralarni ko'rishingizni talab qiladi. Ushbu talab sizning kodingizni ishlab chiqarishga joylashtirishdan oldin xatolarni aniqlashingiz va ularni to'g'ri hal qilishingizni ta'minlash orqali dasturingizni yanada mustahkam qiladi!
Rust xatolarni ikkita asosiy toifaga ajratadi: tiklash mumkin va tiklab bo‘lmaydigan xatolar. file not found (fayl topilmadi) xatosi kabi tiklanadigan xatolik uchun biz muammo haqida foydalanuvchiga xabar berishni va operatsiyani qaytadan urinib ko'rishni xohlaymiz. Qayta tiklanmaydigan xatolar har doim xato belgilaridir, masalan, array oxiridan tashqaridagi joyga kirishga urinish va shuning uchun biz dasturni darhol to'xtatmoqchimiz.
Aksariyat tillar bu ikki turdagi xatolarni farqlamaydi va istisnolar(exceptions) kabi mexanizmlardan foydalangan holda ikkalasini ham xuddi shunday hal qiladi. Rustda istisnolar yo'q. Buning o'rniga, u tiklanadigan xatolar uchun Result<T, E> turiga va dastur tuzatib bo'lmaydigan xatolikka duch kelganda jarayonni to'xtatuvchi panic! makrosiga ega. Bu bob avval panic! chaqirish haqida so'z boradi, soʻngra Result<T, E> qiymatlarini qaytarish haqida so'z boradi. Bundan tashqari, biz xatolikdan xalos bo'lish yoki bajarishni to'xtatish haqida qaror qabul qilishda fikrlarni o'rganamiz.
panic! bilan tuzatib bo'lmaydigan xatolar
Ba'zida sizning kodingizda yomon narsalar sodir bo'ladi va siz bu haqda hech narsa qila olmaysiz. Bunday hollarda Rustda panic! makrosi mavjud. Amalda panic chaqirishning ikki yo'li mavjud: kodimizni panic chiqaradigan harakatni amalga oshirish (masalan, arrayning oxiridan o'tib kirish) yoki aniq panic! makrosini chaqirish.
Ikkala holatda ham biz dasturimizda panicni keltirib chiqaramiz. Odatiy bo'lib, bu panic muvaffaqiyatsizlik xabarini chop etadi, dasturni bajarish paytida ajratilgan resurslarni tozalaydi, stackni tozalaydi va ishdan chiqadi. Atrof-muhit o'zgaruvchisi orqali siz panic paydo bo'lganda panic manbasini kuzatishni osonlashtirish uchun Rust chaqiruvlar srackini ko'rsatishi ham mumkin.
panicga javoban stackni bo'shatish yoki bekor qilish
Odatiy bo'lib, panic paydo bo'lganda, dastur o'chiriladi, ya'ni Rust stekni zaxiraga olib chiqadi va duch kelgan har bir funksiyadan ma'lumotlarni tozalaydi. Biroq, bu orqaga qaytish va tozalash juda ko'p ishdir. Rust, shuning uchun dasturni tozalamasdan tugatadigan darhol bekor qilishning muqobilini tanlashga imkon beradi.
Dastur ishlatgan xotira keyinchalik operatsion tizim tomonidan tozalanishi kerak bo'ladi. Agar loyihangizda natijada olingan binary faylni iloji boricha kichikroq qilishingiz kerak bo'lsa, Cargo.toml faylingizdagi tegishli
[profile]bo'limlarigapanic = 'abort'qo'shish orqali panic bo'yicha bo'shatishdan bekor qilishga o'tishingiz mumkin. Misol uchun, agar siz bo'shatish rejimida panic holatini to'xtatmoqchi bo'lsangiz, quyidagilarni qo'shing:[profile.release] panic = 'abort'
Keling, oddiy dasturda panic! deb chaqirib ko'raylik:
Fayl nomi: src/main.rs
fn main() { panic!("halokatli xato"); }
Dasturni ishga tushirganingizda, siz shunga o'xshash narsani ko'rasiz:
$ cargo run
Compiling panic v0.1.0 (file:///projects/panic)
Finished dev [unoptimized + debuginfo] target(s) in 0.25s
Running `target/debug/panic`
thread 'main' panicked at 'halokatli xato', src/main.rs:2:5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
panic! chaqiruvi oxirgi ikki qatordagi xato xabarini keltirib chiqaradi.
Birinchi qatorda panic haqidagi xabarimiz va manba kodimizdagi panic sodir bo'lgan joy ko'rsatilgan: src/main.rs:2:5 bu bizning src/main.rs faylimizning ikkinchi qatori, beshinchi belgisi ekanligini bildiradi.
Bunday holda, ko'rsatilgan qator bizning kodimizning bir qismidir va agar biz ushbu qatorga o'tsak, biz panic! makro chaqiruvini ko'ramiz. Boshqa hollarda, panic! chaqiruvi bizning kodimiz chaqiradigan kodda bo'lishi mumkin, va xato xabari tomonidan bildirilgan fayl nomi va satr raqami boshqa birovning kodi bo'ladi, bu yerda panic! makro chaqiriladi, kodimizning oxir-oqibat panic! chaqiruviga olib kelgan qatori emas. Kodimizning muammoga sabab bo'lgan qismini aniqlash uchun panic! chaqiruvidan kelgan funksiyalarning backtracedan foydalanishimiz mumkin. Keyinchalik orqaga qaytish(backtraces) haqida batafsilroq gaplashamiz.
panic! Backtracedan foydalanish
Yana bir misolni ko‘rib chiqaylik, panic! chaqiruvi to‘g‘ridan-to‘g‘ri makroni chaqiruvchi kodimizdan emas, balki kodimizdagi xato tufayli kutubxonadan kelganida qanday bo‘lishini ko‘raylik. 9-1 ro'yxatida joriy indekslar doirasidan tashqarida vectordagi indeksga kirishga harakat qiladigan ba'zi kodlar mavjud.
Fayl nomi: src/main.rs
fn main() { let v = vec![1, 2, 3]; v[99]; }
Roʻyxat 9-1: Vector oxiridan tashqaridagi elementga kirishga urinish, bu esa panic! chaqiruviga sabab boʻladi.
Bu erda biz vectorimizning 100-elementiga kirishga harakat qilyapmiz (bu indeks 99-da, chunki indekslash noldan boshlanadi), lekin vectorda faqat 3 ta element mavjud.
Bunday vaziyatda Rust panic qo'yadi. [] dan foydalanish elementni qaytarishi kerak, lekin siz noto'g'ri indeksni o'tkazyapsiz: Rust qaytara oladigan element yo'q.
C tilida ma'lumotlar strukturasining oxiridan tashqarida o'qishga urinish aniqlanmagan xatti-harakatlardir. Siz xotirada ma'lumotlar strukturasidagi ushbu elementga mos keladigan har qanday joyni olishingiz mumkin, garchi xotira ushbu tuzilishga tegishli bo'lmasa ham. Bu buffer overread deb ataladi va agar tajovuzkor indeksni ma'lumotlar tuzilmasidan keyin saqlanadigan ma'lumotlarni o'qishga ruxsat etilmasligi kerak bo'lgan tarzda o'zgartira olsa, xavfsizlik zaifliklariga olib kelishi mumkin.
Dasturingizni bunday zaiflikdan himoya qilish uchun, agar siz mavjud bo'lmagan indeksdagi elementni o'qishga harakat qilsangiz, Rust ishlashni to'xtatadi va davom etishni rad etadi. Keling, sinab ko'raylik va ko'ramiz:
$ cargo run
Compiling panic v0.1.0 (file:///projects/panic)
Finished dev [unoptimized + debuginfo] target(s) in 0.27s
Running `target/debug/panic`
thread 'main' panicked at 'index out of bounds: the len is 3 but the index is 99', src/main.rs:4:5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Bu xatolik main.rs ning 4-qatoriga ishora qiladi, bu yerda biz 99 indeksiga kirishga harakat qilamiz. Keyingi eslatma satrida biz xatoga nima sabab bo'lganligining backtraceni olish uchun RUST_BACKTRACE muhit o'zgaruvchisini o'rnatishimiz mumkinligini aytadi. backtrace - bu dastur bajarilishining ma'lum bir nuqtasiga qadar chaqirilgan barcha funktsiyalar ro'yxatini. Backtrace boshqa tillarda bo'lgani kabi Rust tilida ham xuddi shunday ishlaydi. Shuning uchun, biz boshqa joylarda bo'lgani kabi, backtrace ma'lumotlarini o'qishni tavsiya qilamiz - siz yozgan fayllar haqidagi ma'lumotlarni ko'rmaguningizcha yuqoridan pastga o'qing. Bu muammo paydo bo'lgan joy. Yuqoridagi satrlar sizning kodingiz chaqirgan koddir; Quyidagi satrlar sizning kodingiz deb ataladigan koddir. Ushbu oldingi va keyingi qatorlar asosiy Rust kodini, standart kutubxona kodi yoki siz foydalanayotgan cratelarni o'z ichiga olishi mumkin. RUST_BACKTRACE muhit oʻzgaruvchisini 0 dan tashqari istalgan qiymatga oʻrnatish orqali backtraceni olishga harakat qilaylik. 9-2 ro'yxati siz ko'rgan narsaga o'xshash natijani ko'rsatadi.
$ RUST_BACKTRACE=1 cargo run
thread 'main' panicked at 'index out of bounds: the len is 3 but the index is 99', src/main.rs:4:5
stack backtrace:
0: rust_begin_unwind
at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/std/src/panicking.rs:584:5
1: core::panicking::panic_fmt
at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/panicking.rs:142:14
2: core::panicking::panic_bounds_check
at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/panicking.rs:84:5
3: <usize as core::slice::index::SliceIndex<[T]>>::index
at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/slice/index.rs:242:10
4: core::slice::index::<impl core::ops::index::Index<I> for [T]>::index
at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/slice/index.rs:18:9
5: <alloc::vec::Vec<T,A> as core::ops::index::Index<I>>::index
at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/alloc/src/vec/mod.rs:2591:9
6: panic::main
at ./src/main.rs:4:5
7: core::ops::function::FnOnce::call_once
at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/ops/function.rs:248:5
note: Some details are omitted, run with `RUST_BACKTRACE=full` for a verbose backtrace.
Roʻyxat 9-2: RUST_BACKTRACE muhit oʻzgaruvchisi oʻrnatilganda koʻrsatiladigan panic! chaqiruvi tomonidan yaratilgan backtrace
Bu juda ko'p natija! Siz ko'rgan aniq chiqish operatsion tizimingiz va Rust versiyasiga qarab farq qilishi mumkin. Ushbu ma'lumotlar bilan backtrace uchun debug symbollari yoqilgan bo'lishi kerak. Nosozliklarni tuzatish belgilari standart boʻyicha --release opsiyasiz cargo build yoki cargo run funksiyalaridan foydalanilganda yoqilgan.
9-2 ro'yxatdagi chiqishda backtracening 6-qatori muammoni keltirib chiqarayotgan loyihamizdagi chiziqqa ishora qiladi: src/main.rs ning 4-qatori. Agar dasturimiz panic bo'lishini istamasak, biz yozgan faylni eslatib o'tgan birinchi qatorda ko'rsatilgan joydan tekshirishni boshlashimiz kerak. 9-1 ro'yxatida biz panic qo'yadigan kodni ataylab yozganmiz. panicni tuzatish usuli vector indekslari doirasidan tashqarida elementni so'ramaslikdir. Kelajakda sizning kodingiz panic qo'zg'atganda, siz panic qo'zg'ash uchun kod qanday harakatlarni amalga oshirayotganini va buning o'rniga kod nima qilishi kerakligini aniqlashingiz kerak bo'ladi.
Biz panic! makrosi va qachon panic! qo'llashimiz kerak va qachon foydalanmaslik kerakligi haqidagi muhokamaga qaytamiz! Ushbu bobning keyingi qismida “panic! qo'yish yoki panic! qo'ymaslik” haqida gapalashamiz.
Keyinchalik, Result yordamida xatoni qanday tiklashni ko'rib chiqamiz.
Result bilan tiklanadigan xatolar
Ko'pgina xatolar dasturni butunlay to'xtatishni talab qiladigan darajada jiddiy emas. Ba'zan, funksiya bajarilmasa, bu siz osongina talqin qilishingiz va javob berishingiz mumkin bo'lgan sababdir. Misol uchun, agar siz faylni ochishga urinib ko'rsangiz va fayl mavjud bo'lmagani uchun bu operatsiya bajarilmasa, jarayonni tugatish o'rniga faylni yaratishni xohlashingiz mumkin.
2-bobdagi “Potentsial muvaffaqiyatsizlikni Result bilan hal qilish” bo'limini eslang: biz u yerda muvaffaqiyatsizliklarni hal qilish uchun ikkita variantga ega bo'lgan Ok va Err varianti bo'lgan Result enumidan foydalanganmiz. Enumning o'zi quyidagicha aniqlanadi:
#![allow(unused)] fn main() { enum Result<T, E> { Ok(T), Err(E), } }
T va E umumiy turdagi parametrlardir: biz generiklarni 10-bobda batafsilroq muhokama qilamiz. Siz hozir bilishingiz kerak bo'lgan narsa shundaki, T Ok variantida muvaffaqiyatli holatda qaytariladigan qiymat turini bildiradi, va E Err(Xato) variantida xatolik holatida qaytariladigan xato turini ifodalaydi. Resultda ushbu umumiy turdagi parametrlar mavjud bo'lganligi sababli, biz qaytarmoqchi bo'lgan muvaffaqiyatli qiymat va xato qiymati har xil bo'lishi mumkin bo'lgan turli vaziyatlarda Result turidan va unda belgilangan funksiyalardan foydalanishimiz mumkin.
Keling, Result qiymatini qaytaruvchi funksiyani chaqiraylik, chunki funksiya bajarilmasligi mumkin. 9-3 ro'yxatda biz faylni ochishga harakat qilamiz.
Fayl nomi: src/main.rs
use std::fs::File; fn main() { let fayl_ochish = File::open("olma.txt"); }
Ro'yxat 9-3: Faylni ochish
File::open return(qaytish) turi Result<T, E>dir. File::openni amalga oshirishdagi umumiy T turi muvaffaqiyatli qabul qilingan qiymat turiga, std::fs::Filega, ya'ni fayl deskriptoriga mos keladi. Xato qiymatida ishlatiladigan E turi std::io::Error. Qaytish(return) turi File::open ga chaqiruv muvaffaqiyatli bo'lishi va biz o'qishimiz yoki yozishimiz mumkin bo'lgan fayl handleni qaytarishi mumkinligini anglatadi. Funksiya chaqiruvi ham muvaffaqiyatsiz bo'lishi mumkin: masalan, fayl mavjud bo'lmasligi yoki faylga kirish uchun ruxsatimiz bo'lmasligi mumkin. File::open funksiyasi muvaffaqiyatli yoki muvaffaqiyatsiz bo'lganligini va bir vaqtning o'zida bizga fayl identifikatori yoki xato haqida ma'lumot beradigan metodga ega bo'lishi kerak. Ushbu ma'lumot aynan Result enumini bildiradi.
Agar File::open muvaffaqiyatli bo'lsa, fayl_ochish qiymati fayl identifikatorini o'z ichiga olgan Ok misoli bo'ladi.
Muvaffaqiyatsiz bo'lgan taqdirda, fayl_ochish dagi qiymat Err misoli bo'lib, sodir bo'lgan xato turi haqida qo'shimcha ma'lumotni o'z ichiga oladi.
File::open qiymatiga qarab turli amallarni bajarish uchun 9-3-Ro'yxatdagi kodga o'zgartirishimiz kerak. 9-4 ro'yxatda biz 6-bobda muhokama qilgan asosiy tool - match ifodasi yordamida Result ni boshqarishning bir usuli ko'rsatilgan.
Fayl nomi: src/main.rs
use std::fs::File; fn main() { let fayl_ochish = File::open("olma.txt"); let fayl = match fayl_ochish { Ok(file) => file, Err(error) => panic!("Faylni ochishda muammo: {:?}", error), }; }
Roʻyxat 9-4: Qaytarilishi mumkin boʻlgan Result variantlarini boshqarish uchun match ifodasidan foydalanish
E'tibor bering, Option enumi kabi, Result enumi va uning variantlari avtomatik import (prelude) orqali kiritilgan, shuning uchun biz match qatoridagi Ok va Err variantlaridan oldin Result:: ni belgilashimiz shart emas.
Natija Ok bo'lsa, bu kod Ok variantidan ichki file qiymatini qaytaradi va biz ushbu faylni ishlov berish qiymatini fayl_ochish o'zgaruvchisiga tayinlaymiz. matchdan so'ng biz o'qish yoki yozish uchun fayl boshqaruvidan foydalanishimiz mumkin.
matchning boshqa qismi File::open dan Err qiymatini oladigan holatni boshqaradi. Ushbu misolda biz panic! makrosini tanladik. Agar joriy jildimizda olma.txt nomli fayl bo‘lmasa va biz ushbu kodni ishga tushirsak, biz panic! makrosidan quyidagi natijani ko‘ramiz:
$ cargo run
Compiling error-handling v0.1.0 (file:///projects/error-handling)
Finished dev [unoptimized + debuginfo] target(s) in 0.73s
Running `target/debug/error-handling`
thread 'main' panicked at 'Problem opening the file: Os { code: 2, kind: NotFound, message: "No such file or directory" }', src/main.rs:8:23
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Odatdagidek, bu chiqish bizga nima noto'g'ri ketganligini aniq aytadi.
Turli xil xatolarga moslashish
9-4 roʻyxatdagi kod nima uchun File::open muvaffaqiyatsiz boʻlishidan qatʼiy nazar panic! qoʻyadi.
Biroq, biz turli sabablarga ko'ra turli xil harakatlarni amalga oshirishni xohlaymiz: agar fayl mavjud bo'lmagani uchun File::open muvaffaqiyatsiz bo'lsa, biz faylni yaratmoqchimiz va fayl boshqaruvini yangi faylga qaytaramiz. Agar File::open boshqa sabablarga ko'ra, masalan, faylni ochishga ruxsatimiz yo'qligi sababli muvaffaqiyatsiz bo'lsa, biz hali ham kodga 9-4 ro'yxatdagi kabi panic! qo'yishini xohlaymiz. Buning uchun biz 9-5 ro'yxatda ko'rsatilgan ichki match ifodasini qo'shamiz.
Fayl nomi: src/main.rs
use std::fs::File;
use std::io::ErrorKind;
fn main() {
let fayl_ochish = File::open("olma.txt");
let fayl = match fayl_ochish {
Ok(file) => file,
Err(error) => match error.kind() {
ErrorKind::NotFound => match File::create("olma.txt") {
Ok(fc) => fc,
Err(e) => panic!("Fayl yaratishda muammo: {:?}", e),
},
boshqa_xato => {
panic!("Faylni ochishda muammo: {:?}", boshqa_xato);
}
},
};
}Ro'yxat 9-5: Har xil turdagi xatolarni turli yo'llar bilan hal qilish
File::open Err variantida qaytaradigan qiymat turi io::Error bo'lib, bu standart kutubxona tomonidan taqdim etilgan strukturadir. Ushbu strukturada io::ErrorKind qiymatini olish uchun chaqirishimiz mumkin bo'lgan kind metodi mavjud. io::ErrorKind enumi standart kutubxona tomonidan taqdim etilgan va io operatsiyasi natijasida yuzaga kelishi mumkin bo'lgan turli xil xatolarni ifodalovchi variantlarga ega. Biz foydalanmoqchi boʻlgan variant ErrorKind::NotFound boʻlib, biz ochmoqchi boʻlgan fayl hali mavjud emasligini bildiradi. Shunday qilib, biz fayl_ochish bo'yicha mos kelamiz, lekin bizda error.kind() da ichki match ham bor.
Biz ichki matchni tekshirmoqchi bo'lgan shart - error.kind() tomonidan qaytarilgan qiymat ErrorKind enumining NotFound variantidir. Agar shunday bo'lsa, biz faylni File::create yordamida yaratishga harakat qilamiz. Biroq, File::create ham muvaffaqiyatsiz bo'lishi mumkinligi sababli, bizga ichki match ifodasida ikkinchi arm kerak. Faylni yaratib bo'lmaganda, boshqa xato xabari chop etiladi. Tashqi match ning ikkinchi armi bir xil bo'lib qoladi, shuning uchun dastur yetishmayotgan fayl xatosidan tashqari har qanday xato haqida panic qo'yadi.
Result<T, E>bilanmatchdan foydalanishning muqobillariBu juda ko'p
match!matchifodasi juda foydali, lekin ayni paytda juda primitivdir. 13-bobda sizResult<T, E>da belgilangan koʻplab metodlarda qoʻllaniladigan yopilishlar(closures) haqida bilib olasiz. Ushbu metodlar kodingizdagiResult<T, E>qiymatlari bilan ishlashdamatchdan foydalanishdan ko'ra qisqaroq bo'lishi mumkin.Misol uchun, 9-5 ro'yxatda ko'rsatilgan mantiqni yozishning yana bir usuli, bu safar closures va
unwrap_or_elsemetodi yordamida:use std::fs::File; use std::io::ErrorKind; fn main() { let fayl_ochish = File::open("olma.txt").unwrap_or_else(|error| { if error.kind() == ErrorKind::NotFound { File::create("olma.txt").unwrap_or_else(|error| { panic!("Fayl yaratishda muammo: {:?}", error); }) } else { panic!("Faylni ochishda muammo: {:?}", error); } }); }Garchi bu kod 9-5 roʻyxatdagi kabi harakatga ega boʻlsa-da, unda
matchiboralari mavjud emas va oʻqish uchun qulayroq. 13-bobni o‘qib bo‘lgach, ushbu misolga qayting va standart kutubxona hujjatlaridaunwrap_or_elsemetodini qidiring. Ushbu metodlarning ko'pchiligi xatolar bilan shug'ullanayotganda katta o'rinlimatchiboralarni tozalashi mumkin.
Xatoda panic uchun yorliqlar: unwrap va expect
match dan foydalanish yetarlicha yaxshi ishlaydi, lekin u biroz batafsil bo'lishi mumkin va har doim ham maqsadni yaxshi bildirmaydi. Result<T, E> turida turli, aniqroq vazifalarni bajarish uchun belgilangan koʻplab yordamchi metodlar mavjud. unwrap metodi biz 9-4 ro'yxatda yozgan match iborasi kabi implemen qilinadigan yorliq metodidir. Agar Result qiymati Ok varianti bo'lsa, unwrap qiymati Ok ichidagi qiymatni qaytaradi. Agar Result Err varianti bo‘lsa, unwrap biz uchun panic! makrosini chaqiradi. Mana amaldagi unwrap misoli:
Fayl nomi: src/main.rs
use std::fs::File; fn main() { let fayl_ochish = File::open("olma.txt").unwrap(); }
Agar biz ushbu kodni olma.txt faylisiz ishga tushiradigan bo‘lsak, biz panic! chaqiruvidan xato xabarini ko‘ramiz.
thread 'main' panicked at 'called `Result::unwrap()` on an `Err` value: Os {
code: 2, kind: NotFound, message: "No such file or directory" }',
src/main.rs:4:49
Xuddi shunday, expect metodi bizga panic! xato xabarini tanlash imkonini beradi.
unwrap o'rniga expect dan foydalanish va yaxshi xato xabarlarini taqdim etish niyatingizni bildirishi va panic manbasini kuzatishni osonlashtirishi mumkin. expect sintaksisi quyidagicha ko'rinadi:
Fayl nomi: src/main.rs
use std::fs::File; fn main() { let fayl_ochish = File::open("olma.txt") .expect("olma.txt ushbu loyihaga kiritilishi kerak"); }
Biz expect dan xuddi unwrap kabi foydalanamiz: fayl boshqaruvini qaytarish yoki panic! makrosini chaqirish uchun.panic! chaqiruvida expect tomonidan foydalanilgan xato xabari unwrap ishlatadigan standart panic! xabari emas, balki expect parametriga o‘tadigan parametr bo‘ladi. Bu qanday ko'rinishga ega:
thread 'main' panicked at 'olma.txt should be included in this project: Os {
code: 2, kind: NotFound, message: "No such file or directory" }',
src/main.rs:5:10
Ishlab chiqarish sifati kodida ko'pchilik Rustaceanlar unwrap o'rniga expect ni tanlaydilar va nima uchun operatsiya har doim muvaffaqiyatli bo'lishi kutilayotgani haqida ko'proq kontekst beradi. Shunday qilib, agar sizning taxminlaringiz noto'g'ri ekanligi isbotlangan bo'lsa, debuggingda foydalanish uchun ko'proq ma'lumotga ega bo'lasiz.
Xatoni yo'naltirish - Propagating
Funksiyani amalga oshirish muvaffaqiyatsiz bo'lishi mumkin bo'lgan narsani chaqirganda, xatoni funksiyaning o'zida hal qilish o'rniga, nima qilish kerakligini hal qilish uchun xatoni chaqiruvchi kodga qaytarishingiz mumkin. Bu xatoni propagating deb nomlanadi va chaqiruv kodini ko'proq nazorat qiladi, bu yerda kodingiz kontekstida mavjud bo'lgan narsadan ko'ra xatoni qanday hal qilish kerakligini ko'rsatadigan ko'proq ma'lumot yoki mantiq bo'lishi mumkin.
Misol uchun, 9-6 ro'yxati fayldan foydalanuvchi nomini o'qiydigan funksiyani ko'rsatadi. Agar fayl mavjud bo'lmasa yoki o'qib bo'lmasa, bu funksiya ushbu xatolarni funksiya chaqirgan kodga qaytaradi.
Fayl nomi: src/main.rs
#![allow(unused)] fn main() { use std::fs::File; use std::io::{self, Read}; fn fayldan_foydalanuvchi_nomini_olish() -> Result<String, io::Error> { let foydalanuvchi_fayli_natijasi = File::open("olma.txt"); let mut foydalanuvchi_fayli = match foydalanuvchi_fayli_natijasi { Ok(file) => file, Err(e) => return Err(e), }; let mut foydalanuvchi = String::new(); match foydalanuvchi_fayli.read_to_string(&mut foydalanuvchi) { Ok(_) => Ok(foydalanuvchi), Err(e) => Err(e), } } }
Ro'yxat 9-6: match yordamida chaqiruv kodiga xatoliklarni qaytaruvchi funksiya
Bu funksiyani ancha qisqaroq tarzda yozish mumkin, lekin biz xatolarni qayta ishlashni o'rganish uchun uning ko'p qismini qo'lda qilishdan boshlaymiz; oxirida biz qisqaroq yo'lni ko'rsatamiz. Avval funksiyaning qaytish turini ko'rib chiqamiz: Result<String, io::Error>. Bu funksiya Result<T, E> turidagi qiymatni qaytarayotganini bildiradi, bunda parametr T aniq turdagi String bilan to'ldirilgan, va E umumiy turi aniq turdagi io::Error bilan to`ldirilgan.
Agar bu funksiya hech qanday muammosiz muvaffaqiyatli bajarilsa, ushbu funksiyani chaqiruvchi kod String ga ega boʻlgan Ok qiymatini oladi – bu funksiya fayldan o'qigan foydalanuvchi nomi. Agar bu funksiya biron bir muammoga duch kelsa, murojaat qiluvchi kod io::Error misolini o'z ichiga olgan Err qiymatini oladi, unda muammolar nima bo'lganligi haqida qo'shimcha ma'lumot mavjud. Biz ushbu funktsiyaning qaytish turi sifatida io::Error ni tanladik, chunki bu funksiyaning tanasida bajarilmay qolishi mumkin bo‘lgan ikkala operatsiyadan qaytarilgan xato qiymatining turi: File::open funksiyasi va read_to_string metodi.
Funksiyaning asosiy qismi File::open funksiyasini chaqirish orqali boshlanadi. Keyin biz Result qiymatini 9-4 ro'yxatdagi matchga o'xshash match bilan ishlaymiz.
Agar File::open muvaffaqiyatli bajarilsa, file pattern o'zgaruvchisidagi fayl ishlovi foydalanuvchi_fayli o'zgaruvchan o'zgaruvchisidagi qiymatga aylanadi va funksiya davom etadi. Err holatida, panic! deb chaqirish o‘rniga, biz return kalit so‘zidan funksiyadan to‘liq chiqib ketish uchun foydalanamiz va xato qiymatini File::open dan, endi e pattern o‘zgaruvchisiga o‘tkazamiz, bu funksiya xato qiymati sifatida chaqiruvchi kodga qaytaradi.
Shunday qilib, agar bizda foydalanuvchi_fayli da fayl boshqaruvi mavjud bo'lsa, keyin funksiya foydalanuvchi o'zgaruvchisida yangi String yaratadi va fayl mazmunini foydalanuvchi ni o'qish uchun foydalanuvchi_fayli da fayl boshqaruvidagi read_to_string metodini chaqiradi. read_to_string metodi ham Resultni qaytaradi, chunki u File::open muvaffaqiyatli bo'lishi ham mumkin, muvaffaqiyatsiz bo'lishi ham mumkin. Demak, ushbu Result bilan ishlash uchun bizga yana bir match kerak bo'ladi: agar read_to_string muvaffaqiyatli bo'lsa, demak, bizning funksiyamiz muvaffaqiyatli bo'ldi va biz foydalanuvchi nomini hozirda Ok bilan o'ralgan foydalanuvchi faylidan qaytaramiz. Agar read_to_string bajarilmasa, biz xato qiymatini xuddi File::open qiymatini qayta ishlagan match da xato qiymatini qaytarganimizdek qaytaramiz. Biroq, biz return ni aniq aytishimiz shart emas, chunki bu funksiyadagi oxirgi ifoda.
Ushbu kodni chaqiruvchi kod foydalanuvchi nomini o'z ichiga olgan Ok qiymatini yoki io::Error ni o'z ichiga olgan Err qiymatini olishni boshqaradi. Ushbu qiymatlar bilan nima qilishni hal qilish chaqiruv kodiga bog'liq. Agar chaqiruv kodi Err qiymatini olsa, u panic! deb chaqirishi va dasturni buzishi mumkin, standart foydalanuvchi nomidan foydalaning yoki foydalanuvchi nomini fayldan boshqa joydan qidiring, masalan. Bizda chaqiruv kodi aslida nima qilmoqchi ekanligi haqida yetarli ma'lumot yo'q, shuning uchun biz barcha muvaffaqiyat yoki xato ma'lumotlarini to'g'ri ishlashi uchun xatolarni propagate qilamiz.
Xatolarni propagating qilish namunasi Rustda shu qadar keng tarqalganki, Rust buni osonlashtirish uchun savol belgisi operatori ? beradi.
Propagating xatolar uchun qisqa kod: ? operatori
9-7 ro'yxatda 9-6 ro'yxatdagi kabi funksiyaga ega bo'lgan foydalanuvchi_fayli ilovasi ko'rsatilgan, ammo bu dastur ? operatoridan foydalanadi.
Fayl nomi: src/main.rs
#![allow(unused)] fn main() { use std::fs::File; use std::io::{self, Read}; fn fayldan_foydalanuvchi_nomini_olish() -> Result<String, io::Error> { let mut foydalanuvchi_fayli = File::open("olma.txt")?; let mut foydalanuvchi = String::new(); foydalanuvchi_fayli.read_to_string(&mut foydalanuvchi)?; Ok(foydalanuvchi) } }
Ro'yxat 9-7: ? operatori yordamida chaqiruvchi kodga xatoliklarni qaytaruvchi funksiya
Result qiymatidan keyin qoʻyilgan ? 9-6 roʻyxatdagi Result qiymatlarini boshqarish uchun biz belgilagan match iboralari bilan deyarli bir xil ishlaydi. Agar Result qiymati Ok bo'lsa, Ok ichidagi qiymat ushbu ifodadan qaytariladi va dastur davom etadi. Agar qiymat Err bo'lsa, Err butun funktsiyadan qaytariladi, xuddi biz return kalit so'zidan foydalanganimizdek, xato qiymati chaqiruvchi kodga propagate qiladi.
9-6 roʻyxatdagi match ifodasi va ? operatori nima qilishi oʻrtasida farq bor: ? operatori chaqirilgan xato qiymatlari from funksiyasidan oʻtadi, qiymatlarni bir turdan ikkinchi turga aylantirish uchun foydalaniladigan standart kutubxonadagi From traitida aniqlanadi.
? operatori from funksiyasini chaqirganda, qabul qilingan xato turi joriy funksiyaning qaytish turida aniqlangan xato turiga aylanadi. Bu funksiya muvaffaqiyatsiz bo'lishi mumkin bo'lgan barcha usullarni ifodalash uchun bitta xato turini qaytarganda foydalidir, agar qismlar turli sabablarga ko'ra ishlamay qolsa ham.
Misol uchun, biz 9-7 ro'yxatdagi fayldan_foydalanuvchi_nomini_olish funksiyasini o'zgartirishimiz mumkin, bu biz aniqlagan OurError nomli maxsus xato turini qaytarishimiz mumkin. Agar io::Error dan OurError misolini yaratish uchun OurError uchun impl From<io::Error> for OurError ni ham aniqlasak, keyin fayldan_foydalanuvchi_nomini_olish asosiy qismidagi ? operatori chaqiruvlari fromga murojaat qiladi va funksiyaga boshqa kod qo'shmasdan xato turlarini o'zgartiradi.
foydalanuvchi_fayli o'zgaruvchisiga qaytaradi.Agar xatolik yuzaga kelsa, ? operatori butun funksiyadan erta qaytadi va chaqiruvchi kodga istalgan Err qiymatini beradi. Xuddi shu narsa read_to_string chaqiruvi oxiridagi ? uchun ham amal qiladi.
? operatori ko'plab nosozliklarni bartaraf qiladi va bu funksiyani amalga oshirishni soddalashtiradi. 9-8 ro'yxatda ko'rsatilganidek, biz ushbu kodni ? dan keyin metod chaqiruvlar zanjiridan foydalansak, bu kodni yanada qisqartirishimiz mumkin.
Fayl nomi: src/main.rs
#![allow(unused)] fn main() { use std::fs::File; use std::io::{self, Read}; fn fayldan_foydalanuvchi_nomini_olish() -> Result<String, io::Error> { let mut foydalanuvchi = String::new(); File::open("olma.txt")?.read_to_string(&mut foydalanuvchi)?; Ok(foydalanuvchi) } }
Ro'yxat 9-8: ? operatoridan keyin zanjirlash(chaining) metodi chaqiruvlari
Biz foydalanuvchi da yangi String yaratishni funksiya boshiga o‘tkazdik; bu qism o'zgarmagan. foydalanuvchi_fayli oʻzgaruvchisini yaratish oʻrniga, File::open("olma.txt")? natijasiga toʻgʻridan-toʻgʻri read_to_string chaqiruvlarini bogʻladik. Bizda read_to_string chaqiruvi oxirida hali ham ? bor va biz xatoliklarni qaytarish oʻrniga File::open va read_to_string muvaffaqiyatli boʻlganda ham foydalanuvchini oʻz ichiga olgan OK qiymatini qaytaramiz. Funksionallik yana 9-6 va 9-7 ro'yxatdagi kabi; Bu uni yozishning boshqacha, ergonomik usuli.
9-9 ro'yxati fs::read_to_string yordamida buni yanada qisqartirish yo'lini ko'rsatadi.
Fayl nomi: src/main.rs
#![allow(unused)] fn main() { use std::fs; use std::io; fn read_username_from_file() -> Result<String, io::Error> { fs::read_to_string("hello.txt") } }
Roʻyxat 9-9: faylni ochish va keyin oʻqish oʻrniga fs::read_to_string dan foydalanish
Faylni stringda o'qish juda keng tarqalgan operatsiya, shuning uchun standart kutubxona faylni ochadigan, yangi String yaratadigan qulay fs::read_to_string funksiyasini ta'minlaydi fayl mazmunini o'qiydi, mazmunini o'sha String ga qo'yadi va uni qaytaradi. Albatta, fs::read_to_string dan foydalanish bizga xatolarni qanday hal qilishni tushuntirishga imkon bermaydi, shuning uchun biz birinchi navbatda uzoq yo'lni o'rgandik.
? Operatoridan qayerda foydalanish mumkin
? operatori faqat qaytarish turi ? ishlatiladigan qiymatga mos keladigan funksiyalarda ishlatilishi mumkin. Buning sababi, ? operatori biz 9-6 ro'yxatda belgilagan match ifodasi kabi funksiyadan tashqari qiymatni erta qaytarish uchun belgilangan. 9-6 roʻyxatda match Result qiymatidan foydalanilgan va erta qaytish armi Err(e) qiymatini qaytargan. Funksiyaning qaytish turi Result bo'lishi kerak, shunda u ushbu return bilan mos keladi.
9-10 ro'yxatda, agar biz ? dan foydalanadigan qiymat turiga mos kelmaydigan qaytish turi bilan main funksiyada ? operatoridan foydalansak, qanday xatoga duch kelamiz:
Fayl nomi: src/main.rs
use std::fs::File;
fn main() {
let fayl_ochish = File::open("olma.txt")?;
}Roʻyxat 9-10: () qaytaradigan main funksiyadagi ? dan foydalanishga urinish kompilyatsiya qilinmaydi.
Ushbu kod faylni ochadi, bu muvaffaqiyatsiz bo'lishi mumkin. ? operatori File::open tomonidan qaytarilgan Result qiymatiga amal qiladi, lekin bu main funksiya Result emas, () qaytish turiga ega. Ushbu kodni kompilyatsiya qilganimizda, biz quyidagi xato xabarini olamiz:
$ cargo run
Compiling error-handling v0.1.0 (file:///projects/error-handling)
error[E0277]: the `?` operator can only be used in a function that returns `Result` or `Option` (or another type that implements `FromResidual`)
--> src/main.rs:4:48
|
3 | fn main() {
| --------- this function should return `Result` or `Option` to accept `?`
4 | let fayl_ochish = File::open("olma.txt")?;
| ^ cannot use the `?` operator in a function that returns `()`
|
= help: the trait `FromResidual<Result<Infallible, std::io::Error>>` is not implemented for `()`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `error-handling` due to previous error
Bu xato bizga ? operatoridan faqat Result, Option yoki FromResidualni qo'llaydigan boshqa turdagi qaytaruvchi funksiyada foydalanishga ruxsat berilganligini ko`rsatadi.
Xatoni tuzatish uchun sizda ikkita variant bor. Tanlovlardan biri, funksiyangizning qaytish turini ? operatoridan foydalanayotgan qiymatga mos keladigan qilib o'zgartirish, agar bunga hech qanday cheklovlar bo'lmasa. Boshqa usul esa, Result<T, E> ni mos keladigan usulda boshqarish uchun match yoki Result<T, E> metodlaridan birini qo`llashdir.
Xato xabarida, shuningdek, ? ni Option<T> qiymatlari bilan ham foydalanish mumkinligi aytilgan. Resultda ? dan foydalanish kabi, siz ? dan faqat Option ni qaytaradigan funksiyada foydalanishingiz mumkin. ? operatorining Option<T> bo'yicha chaqirilgandagi xatti-harakati Result<T, E> da chaqirilgandagi xatti-harakatiga o'xshaydi: agar qiymat None bo'lsa None bo'ladi o'sha paytda funksiyadan erta qaytariladi. Agar qiymat Some bo'lsa, Some ichidagi qiymat ifodaning natijaviy qiymati bo`lib, funksiya davom etadi. 9-11 ro'yxatda berilgan matndagi birinchi qatorning oxirgi belgisini topadigan funksiya misoli mavjud:
fn birinchi_satrning_oxirgi_belgisi(matn: &str) -> Option<char> { matn.lines().next()?.chars().last() } fn main() { assert_eq!( birinchi_satrning_oxirgi_belgisi("Salom Do'stim\n Ahvollaring qanday?"), Some('m') ); assert_eq!(birinchi_satrning_oxirgi_belgisi(""), None); assert_eq!(birinchi_satrning_oxirgi_belgisi("\nhi"), None); }
Roʻyxat 9-11: Optionda ? operatoridan foydalanish
Bu funksiya Option<char>ni qaytaradi, chunki u yerda belgi(character) boʻlishi mumkin, lekin yoʻq boʻlishi ham mumkin. Bu kod matn string argumentini oladi va undagi lines metodini chaqiradi, bu esa satrdagi satrlar ustidan iteratorni qaytaradi. Ushbu funksiya birinchi qatorni tekshirmoqchi bo'lganligi sababli, iteratordan birinchi qiymatni olish uchun iteratorda next ni chaqiradi. Agar matn boʻsh qator boʻlsa, next ga murojat qilish Noneni qaytaradi, bu holda biz birinchi_satrning_oxirgi_belgisidan Noneni toʻxtatish va qaytarish uchun ? operatoridan foydalanamiz. Agar matn bo'sh qator bo'lmasa, next matndagi birinchi qatorning string sliceni o'z ichiga olgan Some qiymatini qaytaradi.
? operatori satr bo'lagini chiqaradi va biz uning belgilarining iteratorini olish uchun ushbu qator bo'limidagi charslarni chaqirishimiz mumkin. Bizni ushbu birinchi qatordagi oxirgi belgi qiziqtiradi, shuning uchun biz iteratordagi oxirgi elementni qaytarish uchun last deb chaqiramiz.
Bu Optiondir, chunki birinchi qator boʻsh satr boʻlishi mumkin, masalan, matn boʻsh satr bilan boshlansa, lekin "\nhi"dagi kabi boshqa qatorlarda belgilar boʻlsa. Biroq, agar birinchi qatorda oxirgi belgi bo'lsa, u Some variantida qaytariladi. O'rtadagi ? operatori bu mantiqni ifodalashning ixcham usulini beradi, bu funksiyani bir qatorda amalga oshirish imkonini beradi. Agar biz Option da? operatoridan foydalana olmasak, biz bu mantiqni ko'proq metod chaqiruvlari yoki match ifodasi yordamida amalga oshirishimiz kerak edi.
Esda tutingki, ? operatoridan Result qaytaruvchi funksiyada Resultda foydalanishingiz mumkin, va ? operatoridan Option qaytaradigan funksiyada Optionda foydalanishingiz mumkin, lekin siz aralashtirib, moslashtira olmaysiz. ? operatori Resultni avtomatik ravishda Optionga yoki aksincha o'zgartirmaydi; Bunday hollarda konvertatsiyani aniq amalga oshirish uchun Resultdagi ok metodi yoki Optiondagi ok_or kabi metodlardan foydalanishingiz mumkin.
Hozirgacha biz ishlatgan barcha main funksiyalar () ni qaytaradi. main funksiya maxsus, chunki u bajariladigan dasturlarning kirish va chiqish nuqtasi bo'lib, dasturlar kutilgandek harakat qilishi uchun uning qaytish(return) turi qanday bo'lishi mumkinligiga cheklovlar mavjud.
Yaxshiyamki, main Result<(), E>ni ham qaytarishi mumkin. 9-12 ro'yxatda 9-10 ro'yxatdagi kod mavjud, biroq biz main ning qaytish turini Result<(), Box<dyn Error>> qilib o'zgartirdik va oxiriga Ok(()) qaytish qiymatini qo'shdik. Ushbu kod endi kompilyatsiya qilinadi:
use std::error::Error;
use std::fs::File;
fn main() -> Result<(), Box<dyn Error>> {
let fayl_ochish = File::open("olma.txt")?;
Ok(())
}Roʻyxat 9-12: mainni Result<(), E> qaytarishga oʻzgartirish Result qiymatlarida ? operatoridan foydalanish imkonini beradi.
Box<dyn Error> turi bu trait ob'ekti bo'lib, biz 17-bobning "Turli turdagi qiymatlarga ruxsat beruvchi trait ob'ektlaridan foydalanish" bo'limida gaplashamiz. Hozircha siz Box<dyn Error>ni “har qanday xato” degan ma'noni anglatadi deb o'ylashingiz mumkin. Box<dyn Error> xato turi bilan main funksiyadagi Result qiymatida ? dan foydalanishga ruxsat beriladi, chunki bu har qanday Err qiymatini erta qaytarish imkonini beradi. Garchi bu main funksiyaning tanasi faqat std::io::Error turidagi xatolarni qaytarsa ham, Box<dyn Error> ni belgilab, main funksiyaga boshqa xatolarni qaytaruvchi ko'proq kod qo'shilsa ham, bu kod to'g'ri bo'lib qoladi.
main funksiya Result<(), E>ni qaytarsa, bajariladigan fayl(executable file) 0 qiymati bilan chiqadi, agar main Ok(()) qaytarsa va main Err qiymatini qaytarsa nolga teng bo'lmagan qiymat bilan chiqadi. C tilida yozilgan bajariladigan fayllar(executable file) chiqqanda butun sonlarni qaytaradi: muvaffaqiyatli chiqqan dasturlar 0 butun sonini qaytaradi, xatoga yo'l qo'ygan dasturlar esa 0 dan boshqa butun sonni qaytaradi. Rust shuningdek, ushbu konventsiyaga mos kelishi uchun bajariladigan fayllardan butun(integer) sonlarni qaytaradi.
main funksiya std::process::Termination traitini amalga oshiradigan har qanday turlarni qaytarishi mumkin, bunda ExitCode qaytaruvchi report funksiyasi mavjud. O'zingizning turlaringiz uchun Termination traitini qo'llash bo'yicha qo'shimcha ma'lumot olish uchun standart kutubxona texnik hujjatlariga murojaat qiling.
Endi biz panic! chaqirish yoki Resultni qaytarish tafsilotlarini muhokama qilganimizdan so‘ng, keling, qaysi hollarda qaysi biri to‘g‘ri kelishini hal qilish mavzusiga qaytaylik.
panic! yoki panic! qo'ymaslik
Xo'sh, qachon panic! deb murojat qilish va qachon Resultni qaytarish kerakligini qanday hal qilasiz? Kodda panic paydo bo'lganda, uni tiklashning iloji yo'q. Qayta tiklashning mumkin bo'lgan yo'li bormi yoki yo'qmi, har qanday xatolik uchun panic! deb chaiqruv qilishingiz mumkin, lekin siz chaqiruv kodi nomidan vaziyatni tuzatib bo'lmaydi degan qarorga kelasiz. Result qiymatini qaytarishni tanlaganingizda, siz chaqiruv kodini tanlash imkoniyatini berasiz. Chaqiruv kodi vaziyatga mos keladigan tarzda tiklashga urinishi mumkin yoki Errdagi xatoni qayta tiklab bo'lmaydi, deb qaror qilishi va panic! qo'yishi mumkin, bu sizning tiklanadigan xatongizni tuzatib bo'lmaydiganga aylantiradi. Shuning uchun, muvaffaqiyatsiz bo'lishi mumkin bo'lgan funksiyani belgilashda Result ni qaytarish yaxshi standart tanlovdir.
Misollar, prototip kodi va testlar kabi holatlarda Resultni qaytarish o'rniga panic qo'yadigan kodni yozish maqsadga muvofiqdir. Keling, nima uchun ekanligini ko'rib chiqaylik, keyin kompilyator muvaffaqiyatsizlik mumkin emasligini ayta olmaydigan vaziyatlarni muhokama qilaylik, lekin siz inson sifatida buni qila olasiz. Bob kutubxona kodida panic qo'yish yoki yo'qligini hal qilish bo'yicha ba'zi umumiy ko'rsatmalar bilan yakunlanadi.
Misollar, Prototip Kodi va Testlar
Ba'zi bir kontseptsiyani tasvirlash uchun misol yozayotganingizda, shuningdek, xatolarni qayta ishlash kodini o'z ichiga olgan holda, misolni kamroq tushunarli qilish mumkin. Misollarda, panic qo'zg'atishi mumkin bo'lgan unwrap kabi metodga murojaat qilish sizning ilovangiz xatoliklarni qanday hal qilishini xohlayotganingiz uchun to'ldiruvchi sifatida tushuniladi, bu sizning kodingizning qolgan qismi nima qilayotganiga qarab farq qilishi mumkin.
Xuddi shunday, prototiplashda xatolarni qanday hal qilishni hal qilishdan oldin unwrap va expect metodllari juda qulaydir.
Dasturingizni yanada mustahkamroq qilishga tayyor bo'lganingizda ular kodingizda aniq belgilar qoldiradilar.
Agar testda metod chaqiruvi muvaffaqiyatsiz bo'lsa, bu metod sinovdan o'tkazilayotgan funksiya bo'lmasa ham, butun test muvaffaqiyatsiz bo'lishini xohlaysiz. Chunki panic! – bu sinovning muvaffaqiyatsiz deb belgilanishi, unwrap yoki expect deb atalgan narsa aynan shunday bo'lishi kerak.
Siz kompilyatordan ko'ra ko'proq ma'lumotga ega bo'lgan holatlar
Agar sizda Result Ok qiymatiga ega bo'lishini ta'minlaydigan boshqa mantiqqa ega bo'lsangiz, unwrap yoki expect ni chaqirish ham o'rinli bo'lardi, ammo mantiq kompilyator tushunadigan narsa emas. Siz hali ham Result qiymatiga ega bo'lasiz, uni hal qilishingiz kerak: siz murojaat qilayotgan har qanday operatsiya sizning vaziyatingizda mantiqan imkonsiz bo'lsa ham, umuman muvaffaqiyatsiz bo'lish ehtimoli bor. Agar siz kodni qo‘lda tekshirish orqali sizda hech qachon Err varianti bo‘lmasligiga ishonch hosil qilsangiz, unwrap deb nomlash juda maqbuldir, va expect matnida hech qachon Err varianti bo'lmaydi deb o'ylagan sababni hujjatlash yaxshiroqdir. Mana bir misol:
fn main() { use std::net::IpAddr; let asosiy: IpAddr = "127.0.0.1" .parse() .expect("Qattiq kodlangan IP manzil haqiqiy bo'lishi kerak"); }
Qattiq kodlangan stringni tahlil qilish orqali IpAddr misolini yaratmoqdamiz. Biz 127.0.0.1 to‘g‘ri IP manzil ekanligini ko‘ramiz, shuning uchun bu yerda expect dan foydalanish mumkin. Biroq, qattiq kodlangan, yaroqli satrga ega bo'lish parse metodining qaytish turini o'zgartirmaydi: biz hali ham Result qiymatini olamiz va kompilyator bizni Result bilan ishlashga majbur qiladi, go‘yo Err varianti mumkin, chunki kompilyator bu satr har doim haqiqiy IP manzil ekanligini ko‘rish uchun yetarlicha aqlli emas. Agar IP-manzillar qatori dasturga qattiq kodlanganidan ko'ra foydalanuvchidan kelgan bo'lsa va shuning uchun muvaffaqiyatsizlikka uchragan bo'lsa, biz, albatta, Result ni yanada ishonchli tarzda boshqarishni xohlaymiz.
Ushbu IP-manzil qattiq kodlangan degan taxminni eslatib o'tsak, agar kelajakda IP-manzilni boshqa manbadan olishimiz kerak bo'lsa, bizni expect ni xatolarni boshqarish kodini yaxshiroq o'zgartirishga undaydi.
Xatolarni bartaraf etish bo'yicha ko'rsatmalar
Agar kodingiz yomon holatda bo'lishi mumkin bo'lsa, kodingiz panic qo'yishi tavsiya etiladi. Shu nuqtai nazardan, yomon holat deganda baʼzi taxminlar(assumption), kafolatlar(guarantee), shartnomalar(contract,) yoki oʻzgarmasliklar buzilganda, masalan, notoʻgʻri qiymatlar, qarama-qarshi qiymatlar yoki yetishmayotgan qiymatlar kodingizga oʻtkazilganda, shuningdek quyidagilardan biri yoki bir nechtasi:
- Yomon holat - foydalanuvchi noto'g'ri formatda ma'lumotlarni kiritishi kabi vaqti-vaqti bilan sodir bo'lishi mumkin bo'lgan narsadan farqli o'laroq, kutilmagan narsa.
- Ushbu nuqtadan keyin sizning kodingiz har qadamda muammoni tekshirishdan ko'ra, bu yomon holatda bo'lmaslikka tayanishi kerak.
- Siz foydalanadigan turlarda ushbu ma'lumotni kodlashning yaxshi usuli yo'q. Biz 17-bobning "Turlar sifatida kodlash holatlari va behaviorlari" bo'limida nimani nazarda tutayotganimizni misol qilib ko'rib chiqamiz.
Agar kimdir sizning kodingizga chaqiruv qilsa va mantiqiy bo'lmagan qiymatlarni o'tkazsa, kutubxona foydalanuvchisi bu holatda nima qilishni xohlashini hal qilishi uchun xatolikni qaytarish yaxshidir. Biroq, davom etish xavfli yoki zararli bo'lishi mumkin bo'lgan hollarda, eng yaxshi tanlov panic! deb chaqiruv qilish va kutubxonangizdan foydalanuvchini kodidagi xatolik haqida ogohlantirish bo'lishi mumkin, shunda ular ishlab chiqish jarayonida uni tuzatishi mumkin. Xuddi shunday, panic!ko'pincha sizning nazoratingizdan tashqarida bo'lgan tashqi kodga chaqiruv qilsangiz va uni tuzatishning imkoni bo'lmagan yaroqsiz holatni qaytarsangiz mos keladi.
Biroq, muvaffaqiyatsizlik kutilganda, panic! chaqiruv qilishdan ko'ra, Resultni qaytarish maqsadga muvofiqdir. Misollar, tahlilchiga noto'g'ri tuzilgan ma'lumotlar yoki tarif chegarasiga yetganingizni bildiruvchi holatni qaytaruvchi HTTP so'rovini o'z ichiga oladi. Bunday hollarda, Result ni qaytarish, chaqiruv kodi qanday ishlov berishni hal qilishi kerak bo'lgan muvaffaqiyatsizlik kutilgan imkoniyat ekanligini ko'rsatadi.
Agar kodingiz noto'g'ri qiymatlar yordamida chaqirilgan bo'lsa, foydalanuvchini xavf ostiga qo'yishi mumkin bo'lgan operatsiyani bajarganda, kodingiz avval qiymatlarning haqiqiyligini tekshirishi va qiymatlar noto'g'ri bo'lsa panic qo'yishi kerak.Bu asosan xavfsizlik nuqtai nazaridan: noto'g'ri ma'lumotlar bilan ishlashga urinish kodingizni zaifliklarga olib kelishi mumkin.
Agar siz chegaradan tashqari xotiraga kirishga harakat qilsangiz, standart kutubxona panic! deb chaqirishining asosiy sababi shu: joriy ma'lumotlar tuzilishiga tegishli bo'lmagan xotiraga kirishga urinish umumiy xavfsizlik muammosidir. Funksiyalarda ko'pincha shartnomalar(contracts) mavjud: agar kirish ma'lum talablarga javob bersa, ularning xatti-harakati kafolatlanadi. Shartnoma buzilganda panic qo'yish mantiqan to'g'ri keladi, chunki shartnoma buzilishi har doim chaqiruv qiluvchi tomonidagi xatolikni ko'rsatadi va bu siz chaqiruv kodini aniq ko'rib chiqishni xohlagan xatolik emas. Aslida, chaqiruv kodini tiklashning oqilona usuli yo'q; kodni chaqiruvchi dasturchilar kodni tuzatishi kerak. Funksiya uchun shartnomalar, ayniqsa buzilish panic keltirib chiqaradigan bo'lsa, funksiya uchun API texnik hujjatlarida tushuntirilishi kerak.
Biroq, barcha funksiyalaringizda ko'plab xatolarni tekshirish batafsil va zerikarli bo'ladi. Yaxshiyamki, siz Rustning turdagi tizimidan (va shunday qilib, kompilyator tomonidan amalga oshiriladigan turdagi tekshirish) siz uchun ko'plab tekshiruvlarni amalga oshiradi. Agar funksiyangiz parametr sifatida ma'lum bir turga ega bo'lsa, kompilyator sizda haqiqiy qiymatga ega ekanligiga ishonch hosil qilgan holda kodingiz mantig'ini davom ettirishingiz mumkin. Misol uchun, agar sizda Option emas, balki turingiz bo'lsa, dasturingiz nothing(hech narsa) emas, balki something(nimadir) bo'lishini kutadi. Sizning kodingiz Some va None variantlari uchun ikkita holatni ko'rib chiqishi shart emas: aniq qiymatga ega bo'lish uchun faqat bitta holat bo'ladi. Funksiyangizga hech narsa o'tkazmaslikka harakat qiladigan kodni kompilyatsiya qilinmaydi, shuning uchun funksiyangiz runtimeda bu holatni tekshirishi shart emas.
Yana bir misol, parametr hech qachon manfiy bo'lmasligini ta'minlaydigan u32 kabi belgisiz butun son turidan foydalanishdir.
Tasdiqlash uchun maxsus turlarni yaratish
Keling, bir qadam oldin haqiqiy qiymatga ega ekanligimizga ishonch hosil qilish uchun Rust turi tizimidan foydalanish g'oyasini olaylik va tekshirish uchun maxsus turni yaratishni ko'rib chiqaylik. 2-bobdagi taxmin qilish o'yinini eslang, unda bizning kodimiz foydalanuvchidan 1 dan 100 gacha bo'lgan raqamni taxmin qilishni so'radi. Biz hech qachon foydalanuvchining taxmini o'sha raqamlar o'rtasida ekanligini tasdiqlaganimiz yo'q, uni bizning maxfiy raqamimizga nisbatan tekshirishdan oldin; biz faqat taxmin ijobiy ekanligini tasdiqladik. Bunday holda, natijalar unchalik dahshatli emas edi: bizning "Raqam katta!" yoki "Raqam Kichik!" chiqishimiz hali ham to'g'ri bo'lar edi. Lekin foydalanuvchini to'g'ri taxmin qilishga va foydalanuvchi diapazondan tashqaridagi raqamni taklif qilganda va foydalanuvchi, masalan, raqamlar o'rniga harflarni kiritganda, boshqacha xatti-harakatlarga ega bo'lishga undash yaxshi bo'lardi.
Buning usullaridan biri potentsial manfiy raqamlarga ruxsat berish uchun taxminni faqat u32 o‘rniga i32 sifatida tahlil qilish va keyin diapazondagi raqamni tekshirishni qo‘shishdir, masalan:
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Raqamni topish o'yini!");
let yashirin_raqam = rand::thread_rng().gen_range(1..=100);
loop {
// --snip--
println!("Iltimos, taxminingizni kiriting.");
let mut taxmin = String::new();
io::stdin()
.read_line(&mut taxmin)
.expect("Satrni o‘qib bo‘lmadi");
let taxmin: i32 = match taxmin.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
if taxmin < 1 || taxmin > 100 {
println!("Yashirin raqam 1 dan 100 gacha bo'ladi.");
continue;
}
match taxmin.cmp(&yashirin_raqam) {
// --snip--
Ordering::Less => println!("Raqam Kichik!"),
Ordering::Greater => println!("Raqam katta!"),
Ordering::Equal => {
println!("Siz yutdingiz!");
break;
}
}
}
}If ifodasi bizning qiymatimiz diapazondan tashqarida yoki yo‘qligini tekshiradi, foydalanuvchiga muammo haqida xabar beradi va siklning keyingi iteratsiyasini boshlash uchun continue ni chaqiradi va yana bir taxminni so‘raydi. if ifodasidan keyin taxmin 1 dan 100 gacha ekanligini bilgan holda taxmin va maxfiy raqam o‘rtasidagi taqqoslashni davom ettirishimiz mumkin.
Biroq, bu ideal echim emas: agar dastur faqat 1 dan 100 gacha bo'lgan qiymatlarda ishlaganligi juda muhim bo'lsa va bu talab bilan ko'plab funksiyalarga ega bo'lsa, har bir funksiyada bunday tekshiruvga ega bo'lish zerikarli bo'ladi (va ishlashga ta'sir qilishi mumkin).
Buning o'rniga, biz yangi turni yaratishimiz va tekshirishlarni hamma joyda takrorlashdan ko'ra, turdagi namunani yaratish uchun funksiyaga qo'yishimiz mumkin. Shunday qilib, funksiyalar o'zlarining imzolarida yangi turdan foydalanishlari va ular olgan qiymatlardan ishonchli foydalanishlari xavfsiz bo'ladi. 9-13 roʻyxatda Taxmin turini aniqlashning bir usuli koʻrsatilgan, bu new funksiya 1 dan 100 gacha boʻlgan qiymatni qabul qilsagina Taxmin misolini yaratadi.
#![allow(unused)] fn main() { pub struct Taxmin { qiymat: i32, } impl Taxmin { pub fn new(qiymat: i32) -> Taxmin { if qiymat < 1 || qiymat > 100 { panic!("Taxmin qilingan qiymat 1 dan 100 gacha bo'lishi kerak, {} qabul qilnmaydi.", qiymat); } Taxmin { qiymat } } pub fn qiymat(&self) -> i32 { self.qiymat } } }
Roʻyxat 9-13: Taxmin turi, u faqat 1 dan 100 gacha qiymatlar bilan davom etadi
Birinchidan, biz i32 ga ega qiymat nomli maydonga ega Taxmin nomli structni aniqlaymiz. Bu yerda raqam saqlanadi.
Keyin biz Taxmin da new nomli bog'langan funktsiyani amalga oshiramiz, u Taxmin qiymatlari misollarini yaratadi. new funksiya i32 turidagi qiymat nomli bitta parametrga ega bo‘lishi va Taxminni qaytarishi uchun belgilangan. new funksiyaning asosiy qismidagi kod qiymatni 1 dan 100 gacha ekanligiga ishonch hosil qilish uchun tekshiradi.
Agar qiymat bu sinovdan o‘tmasa, biz panic! chaqiruvini qilamiz, bu chaqiruv kodini yozayotgan dasturchini tuzatishi kerak bo‘lgan xatolik haqida ogohlantiradi, chunki bu diapazondan tashqarida qiymat bilan Taxmin yaratish Taxmin::new tayanadigan qoidani buzadi. Taxmin::new panic qo'zg'atishi mumkin bo'lgan shartlar uning API texnik hujjatlarida muhokama qilinishi kerak; biz 14-bobda yaratgan API texnik hujjatlarida panic! ehtimolini ko‘rsatuvchi hujjatlar konventsiyalarini qamrab olamiz. Agar qiymat testdan o'tgan bo'lsa, biz uning qiymat maydoni qiymat parametriga o'rnatilgan yangi Taxmin yaratamiz va Taxminni qaytaramiz.
Keyinchalik, biz self ni oladigan, boshqa parametrlarga ega bo'lmagan va i32 ni qaytaradigan qiymat nomli metodni qo'llaymiz. Bunday usul ba'zan getter(oluvchi) deb ataladi, chunki uning maqsadi o'z maydonlaridan ba'zi ma'lumotlarni olish va uni qaytarishdir. Ushbu umumiy metod zarur, chunki Taxmin strukturasining qiymat maydoni shaxsiydir(private). qiymat maydoni shaxsiy(private) bo'lishi juda muhim, shuning uchun Taxmin strukturasi yordamida kod to'g'ridan-to'g'ri qiymat ni o'rnatishga ruxsat berilmaydi: moduldan tashqaridagi kod Taxmin::new funksiyasidan Taxmin misolini yaratish uchun foydalanishi kerak, shunday qilib, Taxmin ning Taxmin::new funksiyasidagi shartlar bo‘yicha tekshirilmagan qiymatga ega bo‘lishining imkoni yo‘qligini ta’minlaydi.
Parametrga ega bo'lgan yoki faqat 1 dan 100 gacha bo'lgan raqamlarni qaytaradigan funksiya o'z imzosida i32 emas, Taxmin ni olishi yoki qaytarishi va uning tanasida qo'shimcha tekshiruvlar o'tkazishga hojat qolmasligini e'lon qilishi mumkin.
Xulosa
Rust-ning xatolarni boshqarish xususiyatlari sizga yanada mustahkam kod yozishga yordam berish uchun mo'ljallangan.
panic! makrosi dasturingiz u bardosh bera olmaydigan holatda ekanligini bildiradi va noto‘g‘ri yoki noto‘g‘ri qiymatlar bilan davom etish o‘rniga jarayonni to‘xtatishni aytish imkonini beradi. Result enumi operatsiyalar muvaffaqiyatsiz bo'lishi va kodingiz tiklanishi mumkinligini bildirish uchun Rust turdagi tizimdan foydalanadi. Kodingizga chaqiruv qiladigan kod potentsial muvaffaqiyat yoki muvaffaqiyatsizlikni hal qilishi kerakligini aytish uchun Result dan foydalanishingiz mumkin. Tegishli vaziyatlarda panic! va Result dan foydalanish muqarrar muammolar oldida kodingizni yanada ishonchli qiladi.
Endi siz standart kutubxonada Option va Result enumlari bilan generiklardan foydalanishning foydali usullarini ko'rganingizdan so'ng, biz generiklar qanday ishlashi va ularni kodingizda qanday ishlatishingiz haqida gaplashamiz.
Generik turlar, Traitlar va Lifetimelar
Har bir dasturlash tilida kontseptsiyalarning takrorlanishini samarali boshqarish vositalari mavjud. Rustda bunday vositalardan biri generiklar: concrete turlari yoki boshqa xususiyatlar uchun mavhum stendlar. Kodni kompilyatsiya qilish va ishga tushirishda ularning o'rnida nima bo'lishini bilmasdan, biz generiklarning xatti-harakatlarini yoki ularning boshqa generiklar bilan qanday bog'liqligini ifodalashimiz mumkin.
Funktsiyalar i32 yoki String kabi aniq turdagi o'rniga ba'zi umumiy turdagi parametrlarni olishi mumkin, xuddi shu tarzda funksiya bir xil kodni bir nechta aniq qiymatlarda ishlatish uchun noma'lum qiymatlarga ega parametrlarni oladi. Aslida, biz 6-bobda Option<T>, 8-bobda Vec<T> va HashMap<K, V> va 9-bobda Result<T, E> bilan generiklardan allaqachon foydalanganmiz. Ushbu bobda siz o'zingizning turlaringizni, funksiyalaringizni va metodlaringizni generiklar bilan qanday aniqlashni o'rganasiz!
Birinchidan, kodning takrorlanishini kamaytirish uchun funksiyani qanday chiqarishni ko'rib chiqamiz. Keyin biz bir xil texnikadan faqat parametrlari turida farq qiladigan ikkita funksiyadan umumiy funksiyani yaratamiz. Shuningdek, biz struct va enum ta'riflarida generik turlardan qanday foydalanishni tushuntiramiz.
Keyin xulq-atvorni umumiy tarzda aniqlash uchun traitlar dan qanday foydalanishni o'rganasiz. Har qanday turdan farqli o'laroq, faqat ma'lum bir xatti-harakatga ega bo'lgan turlarni qabul qilish uchun umumiy turni cheklash uchun traitlarni umumiy turlar bilan birlashtira olasiz.
Va nihoyat, biz lifetimelar haqida gaplashamiz: kompilyatorga referencelar bir-biriga qanday bog'liqligi haqida ma'lumot beradigan turli xil generiklar. Lifetimelar kompilyatorga olingan qiymatlar haqida yetarli ma'lumot berishga imkon beradi, shunda u murojaatlar bizning yordamimizsiz ko'proq holatlarda haqiqiy bo'lishini ta'minlaydi.
Funksiyani ajratib olish orqali takrorlanishni olib tashlash
Generiklar bizga kodning takrorlanishini olib tashlash uchun bir nechta turlarni ifodalovchi maxsus turlarni to'ldiruvchi bilan almashtirishga imkon beradi. Generik sintaksisga kirishdan oldin, keling, birinchi navbatda, ma'lum qiymatlarni bir nechta qiymatlarni ifodalovchi to'ldiruvchi bilan almashtiradigan funksiyani chiqarib, generik turlarni o'z ichiga olmaydigan tarzda takrorlashni qanday olib tashlashni ko'rib chiqaylik. Keyin generik funksiyani chiqarish uchun xuddi shu texnikani qo'llaymiz! Funksiyaga chiqarishingiz mumkin bo'lgan takrorlangan kodni qanday tanib olishni ko'rib chiqsangiz, generiklardan foydalanishi mumkin bo'lgan takrorlangan kodni taniy boshlaysiz.
Biz ro'yxatdagi eng katta raqamni topadigan 10-1 ro'yxatidagi qisqa dasturdan boshlaymiz.
Fayl nomi: src/main.rs
fn main() { let raqamlar_listi = vec![34, 50, 25, 100, 65]; let mut eng_katta = &raqamlar_listi[0]; for raqam in &raqamlar_listi { if raqam > eng_katta { eng_katta = raqam; } } println!("Eng katta raqam {}", eng_katta); assert_eq!(*eng_katta, 100); }
Ro'yxat 10-1: Raqamlar ro'yxatidagi eng katta raqamni topish
Biz butun sonlar roʻyxatini raqamlar_listi oʻzgaruvchisida saqlaymiz va roʻyxatdagi birinchi raqamga referenceni eng_katta nomli oʻzgaruvchiga joylashtiramiz. Keyin biz roʻyxatdagi barcha raqamlarni takrorlaymiz va agar joriy raqam eng_kattada saqlangan raqamdan katta boʻlsa, ushbu oʻzgaruvchidagi referenceni almashtiramiz.
Biroq, agar joriy raqam hozirgacha ko'rilgan eng katta raqamdan kichik yoki unga teng bo'lsa, o'zgaruvchi o'zgarmaydi va kod ro'yxatdagi keyingi raqamga o'tadi. Ro'yxatdagi barcha raqamlarni ko'rib chiqqandan so'ng, eng_katta eng katta raqamga ishora qilishi kerak, bu holda bu 100 ga teng.
Bizga endi ikki xil raqamlar ro‘yxatidagi eng katta raqamni topish vazifasi qo‘yildi. Buning uchun biz 10-1 roʻyxatdagi kodni takrorlashni tanlashimiz va 10-2 roʻyxatda koʻrsatilganidek, dasturning ikki xil joyida bir xil mantiqdan foydalanishimiz mumkin.
Fayl nomi: src/main.rs
fn main() { let raqamlar_listi = vec![34, 50, 25, 100, 65]; let mut eng_katta = &raqamlar_listi[0]; for raqam in &raqamlar_listi { if raqam > eng_katta { eng_katta = raqam; } } println!("Eng katta raqam {}", eng_katta); let raqamlar_listi = vec![102, 34, 6000, 89, 54, 2, 43, 8]; let mut eng_katta = &raqamlar_listi[0]; for raqam in &raqamlar_listi { if raqam > eng_katta { eng_katta = raqam; } } println!("Eng katta raqam {}", eng_katta); }
Ro'yxat 10-2: ikkita raqamlar roʻyxatidagi eng katta raqamni topish uchun kod
Ushbu kod ishlayotgan bo'lsa-da, kodni takrorlash zerikarli va xatolarga moyil. Shuningdek, biz kodni o'zgartirmoqchi bo'lganimizda uni bir nechta joyda yangilashni unutmasligimiz kerak.
Ushbu takrorlanishni bartaraf qilish uchun biz parametrda berilgan butun sonlar ro'yxatida ishlaydigan funktsiyani aniqlash orqali abstraksiya yaratamiz. Ushbu yechim bizning kodimizni aniqroq qiladi va bizga ro'yxatdagi eng katta raqamni topish tushunchasini mavhum tarzda ifodalash imkonini beradi.
10-3 ro'yxatda biz eng katta raqamni topadigan kodni eng_katta deb nomlangan funksiyaga chiqaramiz. Keyin biz 10-2 ro'yxatdagi ikkita ro'yxatdagi eng katta raqamni topish uchun funksiyani chaqiramiz. Bundan tashqari, biz kelajakda ega bo'lishi mumkin bo'lgan i32 qiymatlarining boshqa ro'yxatida ham funksiyadan foydalanishimiz mumkin.
Fayl nomi: src/main.rs
fn eng_katta(list: &[i32]) -> &i32 { let mut eng_katta = &list[0]; for element in list { if element > eng_katta { eng_katta = element; } } eng_katta } fn main() { let raqamlar_listi = vec![34, 50, 25, 100, 65]; let natija = eng_katta(&raqamlar_listi); println!("Eng katta raqam {}", natija); assert_eq!(*natija, 100); let raqamlar_listi = vec![102, 34, 6000, 89, 54, 2, 43, 8]; let natija = eng_katta(&raqamlar_listi); println!("Eng katta raqam {}", natija); assert_eq!(*natija, 6000); }
Ro'yxat 10-3: Ikkita roʻyxatdagi eng katta raqamni topish uchun abstrakt kod
eng_katta funksiya list deb nomlangan parametrga ega bo'lib, biz funktsiyaga o'tkazishimiz mumkin bo'lgan i32 qiymatlarining har qanday aniq qismini ifodalaydi. Natijada, biz funksiyani chaqirganimizda, kod biz kiritadigan maxsus qiymatlarda ishlaydi.
Xulosa qilib aytganda, biz kodni kodni 10-2-ro'yxadan 10-3-ro'yxaga oʻzgartirish uchun qilgan qadamlarimiz:
- Ikki nusxadagi kodni aniqlang.
- Ikki nusxadagi kodni funktsiya tanasiga chiqarib oling va ushbu kodning kirish va qaytish qiymatlarini funktsiya imzosida belgilang.
- Buning o'rniga funktsiyani chaqirish uchun ikki nusxadagi kodning ikkita nusxasini yangilang.
Keyinchalik, kodning takrorlanishini kamaytirish uchun generiklar bilan bir xil qadamlardan foydalanamiz. Xuddi shu tarzda, funksiya tanasi ma'lum qiymatlar o'rniga mavhum list bo'yicha ishlay oladi, generiklar kodni mavhum turlarda ishlashga imkon beradi.
Misol uchun, bizda ikkita funksiya bor edi deylik: biri i32 qiymatlari bo‘limidagi eng katta elementni topadigan va ikkinchisi char qiymatlari bo‘limidagi eng katta elementni topadigan. Bu takroriylikni qanday yo'q qilamiz? Keling, bilib olaylik!
Generik ma'lumotlar turlari
Funksiya imzolari yoki structlar kabi elementlar uchun definitionlarni yaratish uchun biz generik(umumiy) ma'lumotlardan foydalanamiz, keyin ularni turli xil aniq ma'lumotlar turlari bilan ishlatishimiz mumkin. Keling, avval generiklar yordamida funksiyalar, structlar, enumlar va metodlarni qanday aniqlashni ko'rib chiqaylik. Keyin biz generiklar kod ishlashiga qanday ta'sir qilishini muhokama qilamiz.
Funksiya ta'riflarida
Generiklardan foydalanadigan funksiyani belgilashda biz generiklarni funksiya imzosiga joylashtiramiz, u yerda biz odatda parametrlarning ma'lumotlar turlarini va qiymatni qaytaramiz. Bu bizning kodimizni yanada moslashuvchan qiladi va kodning takrorlanishining oldini olish bilan birga funksiyamizni chaqiruvchilarga ko'proq funksionallik beradi.
eng_katta funksiyamizni davom ettirsak, 10-4 roʻyxatda ikkalasi ham boʻlakdagi eng katta qiymatni topadigan ikkita funksiya koʻrsatilgan. Keyin biz ularni generiklardan foydalanadigan yagona funksiyaga birlashtiramiz.
Fayl nomi: src/main.rs
fn eng_katta_i32(list: &[i32]) -> &i32 { let mut eng_katta = &list[0]; for element in list { if element > eng_katta { eng_katta = element; } } eng_katta } fn eng_katta_char(list: &[char]) -> &char { let mut eng_katta = &list[0]; for element in list { if element > eng_katta { eng_katta = element; } } eng_katta } fn main() { let raqamlar_listi = vec![34, 50, 25, 100, 65]; let natija = eng_katta_i32(&raqamlar_listi); println!("Eng katta raqam {}", natija); assert_eq!(*natija, 100); let char_list = vec!['y', 'm', 'a', 'q']; let natija = eng_katta_char(&char_list); println!("Eng katta belgi {}", natija); assert_eq!(*natija, 'y'); }
Roʻyxat 10-4: Ikki funksiya faqat nomlari va imzolaridagi turlari bilan farqlanadi
eng_katta_i32 funksiyasi biz 10-3 roʻyxatda ajratib olingan funksiya boʻlib, u boʻlakdagi eng katta i32ni topadi. eng_katta_char funksiyasi bo‘lakdagi eng katta charni topadi. Funksiya organlari bir xil kodga ega, shuning uchun bitta funksiyaga generik turdagi parametrni kiritish orqali takrorlanishni bartaraf qilaylik.
Yangi bitta funksiyada turlarni parametrlash uchun, biz funksiyaning qiymat parametrlari uchun qilganimiz kabi, tur parametrini nomlashimiz kerak. Tur parametri nomi sifatida istalgan identifikatordan foydalanishingiz mumkin. Lekin biz T dan foydalanamiz, chunki Rust-dagi parametr nomlari odatda qisqa, koʻpincha harfdan iborat boʻladi va Rustning tur nomlash konventsiyasi UpperCamelCase hisoblanadi. “type(tur)” so'zining qisqartmasi T, Rust dasturchilarining ko'pchiligining standart tanlovidir.
Funksiya tanasida parametrdan foydalanganda, biz imzoda parametr nomini e'lon qilishimiz kerak, shunda kompilyator bu nom nimani anglatishini biladi.
Xuddi shunday, biz funktsiya imzosida tup parametri nomini ishlatganimizda, uni ishlatishdan oldin parametr nomini e'lon qilishimiz kerak. Generik eng_katta funksiyani aniqlash uchun burchakli qavslar ichida <> nomi deklaratsiyasini funksiya nomi va parametrlar ro'yxati orasiga qo'ying, masalan:
fn eng_katta<T>(list: &[T]) -> &T {Biz bu taʼrifni shunday oʻqiymiz: eng_katta funksiyasi T turiga nisbatan umumiydir. Bu funksiya list nomli bitta parametrga ega, bu T turidagi qiymatlar bo'lagidir. eng_katta funksiya bir xil turdagi T qiymatiga referenceni qaytaradi.
10-5 ro'yxatda imzodagi umumiy ma'lumotlar turidan foydalangan holda birlashtirilgan eng_katta funksiya ta'rifi ko'rsatilgan. list shuningdek, funktsiyani i32 yoki char qiymatlari bilan qanday chaqirishimiz mumkinligini ko'rsatadi. E'tibor bering, bu kod hali kompilyatsiya qilinmaydi, ammo biz uni ushbu bobda keyinroq tuzatamiz.
Fayl nomi: src/main.rs
fn eng_katta<T>(list: &[T]) -> &T {
let mut eng_katta = &list[0];
for element in list {
if element > eng_katta {
eng_katta = element;
}
}
eng_katta
}
fn main() {
let raqamlar_listi = vec![34, 50, 25, 100, 65];
let natija = eng_katta(&raqamlar_listi);
println!("Eng katta raqam {}", natija);
let char_list = vec!['y', 'm', 'a', 'q'];
let natija = eng_katta(&char_list);
println!("Eng katta belgi {}", natija);
}Ro'yxat 10-5: Generik turdagi parametrlardan foydalangan holda eng_katta funksiya; bu hali kompilyatsiya qilinmagan
Agar dasturni hozir kompilyatsiya qilsak, biz quyidagi xatolikni olamiz:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0369]: binary operation `>` cannot be applied to type `&T`
--> src/main.rs:5:17
|
5 | if element > eng_katta {
| ------- ^ ------- &T
| |
| &T
|
help: consider restricting type parameter `T`
|
1 | fn eng_katta<T: std::cmp::PartialOrd>(list: &[T]) -> &T {
| +++++++++++++++++++++
For more information about this error, try `rustc --explain E0369`.
error: could not compile `chapter10` due to previous error
Yordam matnida std::cmp::PartialOrd qayd etilgan, bu trait va biz keyingi bo'limda traitlar haqida gaplashamiz. Hozircha shuni bilingki, bu xato eng_katta tanasi T bo'lishi mumkin bo'lgan barcha mumkin bo'lgan turlar uchun ishlamasligini bildiradi. Kod tanasidagi T turidagi qiymatlarni solishtirmoqchi bo'lganimiz uchun biz faqat qiymatlari ordere qilinadigan turlardan foydalanishimiz mumkin. Taqqoslashni yoqish uchun standart kutubxona std::cmp::PartialOrd traitiga ega bo'lib, uni turlarga tatbiq etishingiz mumkin (bu trait haqida batafsil ma'lumot uchun C ilovasiga qarang). Yordam matnining taklifiga amal qilib, biz T uchun amal qiladigan turlarni faqat PartialOrd-ni qo'llaydiganlar bilan cheklaymiz va bu misol kompilyatsiya qilinadi, chunki standart kutubxona PartialOrdni ham i32 va char da qo'llaydi.
Struktura Definitionlarida
Shuningdek, biz <> sintaksisi yordamida bir yoki bir nechta maydonlarda generik turdagi parametrlardan foydalanish uchun structlarni belgilashimiz mumkin. Ro'yxat 10-6 har qanday turdagi x va y koordinata qiymatlarini saqlash uchun Point<T> structni belgilaydi.
Fayl nomi: src/main.rs
struct Point<T> { x: T, y: T, } fn main() { let integer = Point { x: 5, y: 10 }; let float = Point { x: 1.0, y: 4.0 }; }
10-6 roʻyxat: T turidagi x va y qiymatlarini oʻz ichiga olgan Point<T> structi
Struktura ta'riflarida generiklardan foydalanish sintaksisi funksiya ta'riflarida qo'llaniladigan sintaksisiga juda oʻxshaydi. Birinchidan, burchakli qavslar ichida strukturaning nomidan keyin tur parametrining nomini e'lon qilamiz. Keyin biz aniq ma'lumotlar turlarini ko'rsatadigan struct ta'rifida generik turdan foydalanamiz.
Esda tutingki, biz Point<T>ni aniqlash uchun faqat bitta generik turdan foydalanganmiz, bu taʼrifda aytilishicha, Point<T> structi ba'zi bir T turiga nisbatan umumiy boʻlib, x va y maydonlari qaysi turdagi boʻlishidan qatʼi nazar bir xil turdagi dir. Agar biz 10-7 ro'yxatdagi kabi har xil turdagi qiymatlarga ega bo'lgan Point<T> nusxasini yaratsak, bizning kodimiz kompilyatsiya qilinmaydi.
Fayl nomi: src/main.rs
struct Point<T> {
x: T,
y: T,
}
fn main() {
let ishlamaydi = Point { x: 5, y: 4.0 };
}Roʻyxat 10-7: x va y maydonlari bir xil turdagi boʻlishi kerak, chunki ikkalasi ham bir xil umumiy maʼlumotlar turi Tga ega.
Ushbu misolda, biz x ga 5 butun qiymatini belgilaganimizda, kompilyatorga T generik turi Point<T> misoli uchun butun son bo'lishini bildiramiz. Keyin biz x bilan bir xil turga ega ekanligini aniqlagan y uchun 4.0 ni belgilaganimizda, biz quyidagi turdagi nomuvofiqlik xatosini olamiz:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0308]: mismatched types
--> src/main.rs:7:38
|
7 | let ishlamaydi = Point { x: 5, y: 4.0 };
| ^^^ expected integer, found floating-point number
For more information about this error, try `rustc --explain E0308`.
error: could not compile `chapter10` due to previous error
x va y ikkalasi ham generik bo'lgan, lekin har xil turlarga ega bo'lishi mumkin bo'lgan Point strukturasini aniqlash uchun biz bir nechta generik turdagi parametrlardan foydalanishimiz mumkin. Masalan, 10-8 roʻyxatda biz Point taʼrifini T va U turlari boʻyicha umumiy qilib oʻzgartiramiz, bunda x T turiga, y esa U turiga tegishli.
Fayl nomi: src/main.rs
struct Point<T, U> { x: T, y: U, } fn main() { let ikkita_integer = Point { x: 5, y: 10 }; let ikkita_float = Point { x: 1.0, y: 4.0 }; let integer_va_float = Point { x: 5, y: 4.0 }; }
Roʻyxat 10-8: x va y har xil turdagi qiymatlar boʻlishi uchun ikki turdagi umumiy Point<T, U>.
Endi ko'rsatilgan Point ning barcha misollariga ruxsat berilgan! Ta'rifda siz xohlagancha turdagi parametrlardan generik foydalanishingiz mumkin, lekin bir nechtadan ko'proq foydalanish kodingizni o'qishni qiyinlashtiradi. Agar siz kodingizda ko'plab generik turlar kerakligini aniqlasangiz, bu sizning kodingizni kichikroq qismlarga qayta qurish kerakligini ko'rsatishi mumkin.
Enum Definitionlarida
Structlar bilan qilganimizdek, ularning variantlarida generik ma'lumotlar turlarini saqlash uchun enumlarni belgilashimiz mumkin. Biz 6-bobda foydalanilgan standart kutubxona taqdim etadigan Option<T> enumini yana bir ko'rib chiqamiz:
#![allow(unused)] fn main() { enum Option<T> { Some(T), None, } }
Bu ta'rif endi siz uchun yanada ma'noli bo'lishi kerak. Ko'rib turganingizdek, Option<T> enum T turiga nisbatan generik va ikkita variantga ega: T turidagi bitta qiymatga ega Some va hech qanday qiymatga ega bo'lmagan None varianti.
Option<T> enum yordamida biz ixtiyoriy qiymatning mavhum kontseptsiyasini ifodalashimiz mumkin va Option<T> umumiy bo'lgani uchun biz ixtiyoriy qiymatning turi qanday bo'lishidan qat`i nazar, bu abstraktsiyadan foydalanishimiz mumkin.
Enumlar bir nechta generik turlardan ham foydalanishi mumkin. Biz 9-bobda aytib o'tgan Result enumining ta'rifi ushbu foydalanishga misoldir:
#![allow(unused)] fn main() { enum Result<T, E> { Ok(T), Err(E), } }
Result enumlari ikki xil, T va E uchun generikdir va ikkita variantga ega: T turidagi qiymatga ega OK va E turidagi qiymatga ega bo'lgan Err. Bu taʼrif Result enumidan bizda muvaffaqiyatli boʻlishi mumkin boʻlgan (T turidagi qiymatni qaytarish) yoki muvaffaqiyatsiz boʻlishi mumkin boʻlgan (E turidagi xatolikni qaytarish) istalgan joyda foydalanishni qulay qiladi. Aslida, biz 9-3 ro'yxatdagi faylni shunday ochar edik, bu yerda fayl muvaffaqiyatli ochilganda T std::fs::File turi bilan to'ldirilgan va faylni ochishda muammolar yuzaga kelganda E std::io::Error turi bilan to`ldirilgan.
Kodingizdagi vaziyatlarni faqat ular ega bo'lgan qiymatlar turlarida farq qiluvchi bir nechta struct yoki enum ta'riflari bilan tanib olganingizda, uning o'rniga generik turlardan foydalanish orqali takrorlanishdan qochishingiz mumkin.
Metod Definitionlarida
Biz structlar va enumlar bo'yicha metodlarni qo'llashimiz mumkin (5-bobda qilganimiz kabi) va ularning ta'riflarida generik turlardan ham foydalanishimiz mumkin. 10-9 ro'yxatda biz 10-6 ro'yxatda belgilagan Point<T> structi ko'rsatilgan va unda x nomli metod qo'llaniladi.
Fayl nomi: src/main.rs
struct Point<T> { x: T, y: T, } impl<T> Point<T> { fn x(&self) -> &T { &self.x } } fn main() { let p = Point { x: 5, y: 10 }; println!("p.x = {}", p.x()); }
Roʻyxat 10-9: Point<T> structida x nomli metodni qo'llash, bu T turidagi x maydoniga referenceni qaytaradi
Bu yerda biz Point<T> da x nomli metodni belgilab oldik, u x maydonidagi ma`lumotlarga referenceni qaytaradi.
Esda tutingki, biz impl dan keyin T ni e'lon qilishimiz kerak, shuning uchun biz Point<T> turidagi metodlarni amalga oshirayotganimizni aniqlash uchun T dan foydalanishimiz mumkin. T ni impl dan keyin generik tur sifatida e'lon qilish orqali Rust Point dagi burchak qavslaridagi tur aniq tur emas, balki generik tur ekanligini aniqlay oladi. Biz ushbu umumiy parametr uchun struct taʼrifida eʼlon qilingan generik parametrdan boshqa nom tanlashimiz mumkin edi, lekin bir xil nomdan foydalanish odatiy hisoblanadi. Generik turni e'lon qiladigan impl ichida yozilgan metodlar, generik turdagi o'rnini bosadigan aniq turdagi qanday bo'lishidan qat'i nazar, har qanday turdagi namunada aniqlanadi.
Tur bo'yicha metodlarni belgilashda generik turlarga cheklovlarni ham belgilashimiz mumkin. Biz, masalan, har qanday generik turdagi Point<T> misollarida emas, balki faqat Point<f32> misollarida metodlarni amalga oshirishimiz mumkin. 10-10 ro'yxatda biz f32 aniq turidan foydalanamiz, ya'ni impl dan keyin hech qanday turni e'lon qilmaymiz.
Fayl nomi: src/main.rs
struct Point<T> { x: T, y: T, } impl<T> Point<T> { fn x(&self) -> &T { &self.x } } impl Point<f32> { fn kelib_chiqishidan_masofa(&self) -> f32 { (self.x.powi(2) + self.y.powi(2)).sqrt() } } fn main() { let p = Point { x: 5, y: 10 }; println!("p.x = {}", p.x()); }
Roʻyxat 10-10: impl bloki, faqat T generik tur parametri uchun ma`lum bir aniq turdagi strukturaga tegishli.
Bu kod Point<f32> turi kelib_chiqishidan_masofa metodiga ega bo'lishini bildiradi; T f32 turiga tegishli bo'lmagan Point<T> ning boshqa misollarida bu metod aniqlanmaydi. Metod bizning pointimizning koordinatadagi nuqtadan qanchalik uzoqligini o'lchaydi (0,0, 0,0) va faqat floating point turlari uchun mavjud bo'lgan matematik operatsiyalardan foydalanadi.
Struct taʼrifidagi generik turdagi parametrlar har doim ham oʻsha structning metod imzolarida foydalanadigan parametrlar bilan bir xil boʻlavermaydi. 10-11 roʻyxatda misolni aniqroq qilish uchun Point structsi uchun X1 va Y1 va aralashtirish metodi imzosi uchun X2 Y2 generik turlari qoʻllaniladi. Metod yangi Point misolini yaratadi
self Point (X1 turidagi) x qiymati va o'tkazilgan Point (Y2 turidagi) y qiymati.
Fayl nomi: src/main.rs
struct Point<X1, Y1> { x: X1, y: Y1, } impl<X1, Y1> Point<X1, Y1> { fn aralashtirish<X2, Y2>(self, other: Point<X2, Y2>) -> Point<X1, Y2> { Point { x: self.x, y: other.y, } } } fn main() { let p1 = Point { x: 5, y: 10.4 }; let p2 = Point { x: "Salom", y: 'c' }; let p3 = p1.aralashtirish(p2); println!("p3.x = {}, p3.y = {}", p3.x, p3.y); }
Ro'yxat 10-11: O'zining strukturasi ta'rifidan farqli generik turlardan foydalanadigan metod
mainda biz x uchun i32 (5 qiymati bilan) va y uchun f64 (10,4 qiymati bilan) bo'lgan Point ni aniqladik. p2 o'zgaruvchisi bu Point structi bo'lib, x (Salom qiymati bilan) va y (c qiymati bilan) uchun char bo'lagiga ega. p1 da aralashtirishni p2 argumenti bilan chaqirish bizga p3ni beradi, bunda x uchun i32 bo‘ladi, chunki x p1 dan kelgan. p3 o‘zgaruvchisi y uchun charga ega bo‘ladi, chunki y p2 dan kelgan. println! makro chaqiruvi p3.x = 5, p3.y = c ni chop etadi.
Ushbu misolning maqsadi ba'zi generik parametrlar impl bilan e'lon qilingan va ba'zilari metod ta'rifi bilan e'lon qilingan vaziyatni ko'rsatishdir. Bu erda X1 va Y1 generik parametrlari impl dan keyin e'lon qilinadi, chunki ular struct ta'rifiga mos keladi. X2 va Y2 generik parametrlari fn aralashtirish dan keyin e'lon qilinadi, chunki ular faqat metodga tegishli.
Generiklar yordamida kodning ishlashi
Generik turdagi parametrlardan foydalanganda ish vaqti narxi bor yoki yo'qligini sizni qiziqtirgan bo'lishi mumkin. Yaxshi xabar shundaki, generik turlardan foydalanish dasturingizning aniq turlariga qaraganda sekinroq ishlashiga olib kelmaydi.
Rust buni kompilyatsiya vaqtida generiklar yordamida kodni monomorfizatsiya qilish orqali amalga oshiradi. Monomorfizatsiya - bu kompilyatsiya paytida ishlatiladigan aniq turlarni to'ldirish orqali generik kodni maxsus kodga aylantirish jarayoni. Ushbu jarayonda kompilyator biz 10-5 ro'yxatdagi generik funksiyani yaratishda qo'llagan qadamlarning teskarisini bajaradi: kompilyator generik kod chaqiriladigan barcha joylarni ko'rib chiqadi va generik kod chaqirilgan aniq turlar uchun kod ishlab chiqaradi.
Keling, bu standart kutubxonaning umumiy Option<T> enum yordamida qanday ishlashini ko'rib chiqaylik:
#![allow(unused)] fn main() { let integer = Some(5); let float = Some(5.0); }
Rust ushbu kodni kompilyatsiya qilganda, u monomorfizatsiyani amalga oshiradi. Ushbu jarayon davomida kompilyator Option<T> misollarida ishlatilgan qiymatlarni o'qiydi va ikki xil Option<T>ni aniqlaydi: biri i32, ikkinchisi esa f64. Shunday qilib, u Option<T> ning umumiy ta'rifini i32 va f64 uchun ixtisoslashgan ikkita ta'rifga kengaytiradi va shu bilan umumiy ta'rifni o'ziga xos ta'riflar bilan almashtiradi.
Kodning monomorflashtirilgan versiyasi quyidagiga o'xshaydi (kompilyator biz tasvirlash uchun ishlatayotganimizdan boshqa nomlardan foydalanadi):
Fayl nomi: src/main.rs
enum Option_i32 { Some(i32), None, } enum Option_f64 { Some(f64), None, } fn main() { let integer = Option_i32::Some(5); let float = Option_f64::Some(5.0); }
Generik Option<T> kompilyator tomonidan yaratilgan maxsus ta`riflar bilan almashtiriladi. Rust generik kodni har bir misolda turni belgilaydigan kodga kompilyatsiya qilganligi sababli, biz generiklardan foydalanish uchun hech qanday ish vaqti to'lamaymiz. Kod ishga tushganda, agar biz har bir ta'rifni qo'lda takrorlagan bo'lsak, xuddi shunday ishlaydi. Monomorfizatsiya jarayoni Rust generiklarini runtimeda juda samarali qiladi.
Traitlar: umumiy xatti-harakatni aniqlash
trait ma'lum bir turga ega bo'lgan va boshqa turlar bilan bo'lishishi mumkin bo'lgan funksionallikni belgilaydi. Biz umumiy xatti-harakatni mavhum tarzda aniqlash uchun traitlardan foydalanishimiz mumkin. Generik tur ma'lum xatti-harakatlarga ega bo'lgan har qanday tur bo'lishi mumkinligini aniqlash uchun trait (bound)chegaralari dan foydalanishimiz mumkin.
Eslatma: Traitlar ba'zi farqlarga ega bo'lsa-da, ko'pincha boshqa tillarda interfeyslar deb ataladigan xususiyatga o'xshaydi.
Traitni aniqlash
Turning xatti-harakati biz ushbu turga murojaat qilishimiz mumkin bo'lgan metodlardan iborat. Agar biz ushbu turlarning barchasida bir xil metodlarni chaqira olsak, har xil turlar bir xil xatti-harakatlarga ega. Trait ta'riflari - bu qandaydir maqsadga erishish uchun zarur bo'lgan xatti-harakatlar to'plamini aniqlash uchun metod imzolarini birgalikda guruhlash usuli.
Misol uchun, bizda turli xil va hajmdagi matnlarni o'z ichiga olgan bir nechta structlar mavjud deylik: ma'lum bir joyda joylashtirilgan yangiliklarni o'z ichiga olgan YangiMaqola structi va eng ko'pi 280 belgidan iborat bo'lishi mumkin bo'lgan Maqola yangi post, retpost yoki boshqa postga javob ekanligini ko'rsatadigan metama'lumotlar.
Biz YangiMaqola yoki Maqola misolida saqlanishi mumkin bo‘lgan ma’lumotlarning qisqacha mazmunini ko‘rsata oladigan aggregator nomli media agregator kutubxonasini yaratmoqchimiz. Buni amalga oshirish uchun bizga har bir tur bo'yicha xulosa kerak bo'ladi va biz ushbu xulosani misolda umumiy_xulosa metodini chaqirish orqali so'raymiz. 10-12 ro'yxatda ushbu xatti-harakatni ifodalovchi umumiy Xulosa traitining ta'rifi ko'rsatilgan.
Fayl nomi: src/lib.rs
pub trait Xulosa {
fn umumiy_xulosa(&self) -> String;
}Roʻyxat 10-12: umumiy_xulosa metodi bilan taʼminlangan xatti-harakatlardan iborat Xulosa traiti
Bu yerda biz trait kalit so'zidan foydalanib traitni e'lon qilamiz, so'ngra belgi nomi, bu holda Xulosa. Shuningdek, biz ushbu traitni pub deb e’lon qildik, shunda bu cratega bog‘liq bo‘lgan cratelar ham bu traitdan foydalanishi mumkin, buni bir necha misollarda ko‘ramiz. Jingalak qavslar ichida biz ushbu traitni amalga oshiradigan turlarning xatti-harakatlarini tavsiflovchi metod imzolarini e'lon qilamiz, bu holda fn umumiy_xulosa(&self) -> String.
Metod imzosidan so'ng, jingalak qavslar ichida amalga oshirish o'rniga, biz nuqta-verguldan foydalanamiz. Ushbu traitni amalga oshiradigan har bir tur metod tanasi uchun o'ziga xos xatti-harakatni ta'minlashi kerak. Kompilyator Xulosa traitiga ega boʻlgan har qanday turda aynan shu imzo bilan aniqlangan umumiy_xulosa metodi boʻlishini talab qiladi.
Traitining tanasida bir nechta metodlar bo'lishi mumkin: metod imzolari har bir satrda bittadan ko'rsatilgan va har bir satr nuqtali vergul bilan tugaydi.
Turga xos traitni amalga oshirish
Endi biz Xulosa traiti metodlarining kerakli imzolarini aniqlaganimizdan so‘ng, uni media agregatorimizdagi turlarga qo‘llashimiz mumkin. 10-13 roʻyxat sarlavhadan foydalanadigan YangiMaqola structidagi Xulosa traitining amalga oshirilishini koʻrsatadi, muallif va umumiy_xulosa qaytish qiymatini yaratish uchun joy. Maqola structi uchun biz umumiy_xulosani foydalanuvchi nomi va undan keyin maqolaning butun matni sifatida belgilaymiz, maqola mazmuni allaqachon 280 belgi bilan cheklangan deb hisoblaymiz.
Fayl nomi: src/lib.rs
pub trait Xulosa {
fn umumiy_xulosa(&self) -> String;
}
pub struct YangiMaqola {
pub sarlavha: String,
pub manzil: String,
pub muallif: String,
pub mazmuni: String,
}
impl Xulosa for YangiMaqola {
fn umumiy_xulosa(&self) -> String {
format!("{}, by {} ({})", self.sarlavha, self.muallif, self.manzil)
}
}
pub struct Maqola {
pub foydalanuvchi: String,
pub mazmuni: String,
pub javob_berish: bool,
pub repost: bool,
}
impl Xulosa for Maqola {
fn umumiy_xulosa(&self) -> String {
format!("{}: {}", self.foydalanuvchi, self.mazmuni)
}
}Roʻyxat 10-13: Xulosa traitini YangiMaqola va Maqola turlariga joriy qilish
Traitni turga tatbiq etish odatiy usullarni amalga oshirishga o'xshaydi. Farqi shundaki, impl dan so'ng biz amalga oshirmoqchi bo'lgan trait nomini qo'yamiz, so'ng for kalit so'zidan foydalanamiz va keyin traitni amalga oshirmoqchi bo'lgan tur nomini belgilaymiz. impl blokida biz trait ta'rifi belgilagan metod imzolarini qo'yamiz. Har bir imzodan keyin nuqta-vergul qo'yish o'rniga, biz jingalak qavslardan foydalanamiz va metod tanasini o'ziga xos xatti-harakat bilan to'ldiramiz, biz traitning metodlari ma'lum bir turga ega bo'lishini xohlaymiz.
Kutubxona YangiMaqola va Maqolada Xulosa traitini joriy qilganligi sababli, crate foydalanuvchilari YangiMaqola va Maqola misollaridagi xususiyat metodlarini biz odatdagi metodlar deb ataganimizdek chaqirishlari mumkin. Yagona farq shundaki, foydalanuvchi o'ziga xos traitni turlari bilan bir qatorda qamrab olishi kerak. Binary crate bizning aggregator kutubxonamiz cratesidan qanday foydalanishi mumkinligiga misol:
use aggregator::{Xulosa, Maqola};
fn main() {
let maqola = Maqola {
foydalanuvchi: String::from("ismoilovdev"),
mazmuni: String::from(
"Rust kitobi juda foydali ekan, men juda ko'p bilimlarni o'zlashtirdim",
),
javob_berish: false,
repost: false,
};
println!("1 ta yangi xabar: {}", maqola.umumiy_xulosa());
}Bu kod 1 ta yangi xabar: ismoilovdev: Rust kitobi juda foydali ekan, men juda ko'p bilimlarni o'zlashtirdim chop etadi.
aggregator cratesiga bog'liq bo'lgan boshqa cratelar ham Xulosa traitini o'z turlari bo'yicha Xulosani amalga oshirish uchun qamrab olishi mumkin. E'tiborga olish kerak bo'lgan cheklashlardan biri shundaki, biz trait yoki turning hech bo'lmaganda bittasi bizning cratemiz uchun mahalliy(local) bo'lsa, biz traitni turga qo'llashimiz mumkin. Misol uchun, biz Maqola kabi maxsus turdagi Display kabi standart kutubxona traitlarini aggregator crate funksiyamizning bir qismi sifatida amalga oshirishimiz mumkin, chunki Maqola turi aggregator cratemiz uchun mahalliydir. Shuningdek, biz Vec<T> da Xulosani aggregator cratemizda ham qo‘llashimiz mumkin, chunki Xulosa traiti aggregator cratemiz uchun mahalliydir.
Ammo biz tashqi turlarga tashqi traitlarni amalga oshira olmaymiz. Masalan, biz aggregator cratemiz ichida Vec<T> da Display traitini amalga oshira olmaymiz, chunki Display va Vec<T> ikkalasi ham standart kutubxonada belgilangan va bizning aggregator cratemiz uchun mahalliy emas. Bu cheklash kogerentlik(coherence) deb nomlangan xususiyatning bir qismi va aniqrog'i yetim qoidasi(orphan rule), chunki ota-ona turi mavjud emasligi sababli shunday nomlangan. Bu qoida boshqa odamlarning kodi sizning kodingizni buzmasligini ta'minlaydi va aksincha. Qoidalarsiz ikkita crate bir xil turdagi bir xil traitni amalga oshirishi mumkin edi va Rust qaysi dasturdan foydalanishni bilmaydi.
Standart ilovalar
Ba'zan har bir turdagi barcha metodlarni amalga oshirishni talab qilish o'rniga, traitdagi ba'zi yoki barcha metodlar uchun standart xatti-harakatlarga ega bo'lish foydali bo'ladi. Keyin, biz traitni ma'lum bir turga qo'llaganimizda, har bir metodning standart xatti-harakatlarini saqlab qolishimiz yoki bekor qilishimiz mumkin.
Roʻyxat 10-14da biz 10-12 ro'yxatda bo'lgani kabi faqat metod imzosini belgilash o'rniga Xulosa traitining umumiy_xulosa metodi uchun standart qatorni belgilaymiz.
Fayl nomi: src/lib.rs
pub trait Xulosa {
fn umumiy_xulosa(&self) -> String {
String::from("(Batafsil...)")
}
}
pub struct YangiMaqola {
pub sarlavha: String,
pub manzil: String,
pub muallif: String,
pub mazmuni: String,
}
impl Xulosa for YangiMaqola {}
pub struct Maqola {
pub foydalanuvchi: String,
pub mazmuni: String,
pub javob_berish: bool,
pub repost: bool,
}
impl Xulosa for Maqola {
fn umumiy_xulosa(&self) -> String {
format!("{}: {}", self.foydalanuvchi, self.mazmuni)
}
}Roʻyxat 10-14: Xulosa traitini umumiy_xulosa metodini standart boʻyicha amalga oshirish bilan aniqlash
YangiMaqola misollarini umumlashtirish uchun standart ilovadan foydalanish uchun biz bo'sh impl blokini impl Xulosa for YangiMaqola {} bilan belgilaymiz.
Biz YangiMaqolada to‘g‘ridan-to‘g‘ri umumiy_xulosa metodini endi aniqlamasak ham, biz standart bo‘yicha dasturni taqdim etdik va YangiMaqola Xulosa traitini amalga oshirishini belgilab oldik. Natijada, biz hali ham YangiMaqola misolida umumiy_xulosa metodini quyidagicha chaqirishimiz mumkin:
use aggregator::{self, YangiMaqola, Xulosa};
fn main() {
let maqola = YangiMaqola {
sarlavha: String::from("Tesla yangi elektromobil ustida ishlayapti"),
manzil: String::from("USA"),
muallif: String::from("Elon Musk"),
mazmuni: String::from(
"Hozirgi kunda Tesla yangi innovatsion elektromobil\
ustida ishlamoqda.",
),
};
println!("Yangi maqola mavjud! {}", maqola.umumiy_xulosa());
}Bu kod Yangi maqola mavjud! (Batafsil...)ni chop etadi.
Standart dasturni yaratish bizdan 10-13 roʻyxatdagi Maqoladagi Xulosani amalga oshirish haqida biror narsani oʻzgartirishimizni talab qilmaydi. Buning sababi, standart dasturni bekor qilish sintaksisi standart dasturga ega bo'lmagan trait metodini amalga oshirish sintaksisi bilan bir xil.
Standart ilovalar bir xil traitga ega bo'lgan boshqa metodlarni chaqirishi mumkin, hatto bu boshqa metodlarda standart dastur bo'lmasa ham. Shunday qilib, trait juda ko'p foydali funksiyalarni taqdim etishi mumkin va amalga oshiruvchilardan faqat uning kichik qismini ko'rsatishni talab qiladi. Misol uchun, biz Xulosa traitini amalga oshirish zarur bo'lgan muallif_haqida metodiga ega bo'lish uchun belgilashimiz va keyin muallif_haqida metodini chaqiradigan standart amalga oshirishga ega bo'lgan umumiy_xulosa metodini belgilashimiz mumkin:
pub trait Xulosa {
fn muallif_haqida(&self) -> String;
fn umumiy_xulosa(&self) -> String {
format!("(Batafsil: {}...)", self.muallif_haqida())
}
}
pub struct Maqola {
pub foydalanuvchi: String,
pub mazmuni: String,
pub javob_berish: bool,
pub repost: bool,
}
impl Xulosa for Maqola {
fn muallif_haqida(&self) -> String {
format!("@{}", self.foydalanuvchi)
}
}Xulosa ning ushbu versiyasidan foydalanish uchun biz faqat bir turdagi traitni amalga oshirganimizda muallif_haqida ni aniqlashimiz kerak:
pub trait Xulosa {
fn muallif_haqida(&self) -> String;
fn umumiy_xulosa(&self) -> String {
format!("(Batafsil: {}...)", self.muallif_haqida())
}
}
pub struct Maqola {
pub foydalanuvchi: String,
pub mazmuni: String,
pub javob_berish: bool,
pub repost: bool,
}
impl Xulosa for Maqola {
fn muallif_haqida(&self) -> String {
format!("@{}", self.foydalanuvchi)
}
}muallif_haqida ni aniqlaganimizdan so'ng, biz Maqola structi misollarida umumiy_xulosa deb atashimiz mumkin va umumiy_xulosa standart bajarilishi biz taqdim etgan muallif_haqida ta'rifini chaqiradi. Biz muallif_haqida ni qo'llaganimiz sababli, Xulosa traiti bizga boshqa kod yozishni talab qilmasdan umumiy_xulosa metodining harakatini berdi.
use aggregator::{self, Xulosa, Maqola};
fn main() {
let maqola = Maqola {
foydalanuvchi: String::from("ismoilovdev"),
mazmuni: String::from(
"Rust kitobi juda foydali ekan, men juda ko'p bilimlarni o'zlashtirdim",
),
javob_berish: false,
repost: false,
};
println!("1 ta yangi xabar: {}", maqola.umumiy_xulosa());
}Bu kod 1 ta yangi xabar: (Batafsil: @ismoilovdev...) ni chop etadi.
Shuni esda tutingki, xuddi shu metodni bekor qilish orqali standart dasturni chaqirish mumkin emas.
Traitlar parametr sifatida
Endi siz traitlarni qanday aniqlash va amalga oshirishni bilganingizdan so'ng, biz ko'plab turlarni qabul qiladigan funksiyalarni aniqlash uchun traitlardan qanday foydalanishni o'rganishimiz mumkin. Biz 10-13 roʻyxatdagi YangiMaqola va Maqola turlari uchun joriy qilingan Xulosa traitidan foydalanamiz, uning element parametri boʻyicha umumlashtirish metodlini chaqiradigan xabar_berish funksiyasini belgilaymiz, u Xulosa traitini amalga oshiradi. Buning uchun biz impl Trait sintaksisidan foydalanamiz, masalan:
pub trait Xulosa {
fn umumiy_xulosa(&self) -> String;
}
pub struct YangiMaqola {
pub sarlavha: String,
pub manzil: String,
pub muallif: String,
pub mazmuni: String,
}
impl Xulosa for YangiMaqola {
fn umumiy_xulosa(&self) -> String {
format!("{}, by {} ({})", self.sarlavha, self.muallif, self.manzil)
}
}
pub struct Maqola {
pub foydalanuvchi: String,
pub mazmuni: String,
pub javob_berish: bool,
pub repost: bool,
}
impl Xulosa for Maqola {
fn umumiy_xulosa(&self) -> String {
format!("{}: {}", self.foydalanuvchi, self.mazmuni)
}
}
pub fn xabar_berish(element: &impl Xulosa) {
println!("Tezkor xabarlar! {}", element.umumiy_xulosa());
}element parametri uchun aniq tur o'rniga biz impl kalit so'zini va trait nomini belgilaymiz. Ushbu parametr belgilangan traitni amalga oshiradigan har qanday turni qabul qiladi. xabar_berish qismida biz Xulosa traitidan kelib chiqadigan element bo‘yicha har qanday metodlarni chaqirishimiz mumkin, masalan, umumiy_xulosa. Biz xabar_berish ga chaiqruv qilishimiz va YangiMaqola yoki Maqola ning istalgan misolida o'tishimiz mumkin. Funksiyani String yoki i32 kabi boshqa har qanday turdagi chaqiruvchi kod kompilyatsiya qilinmaydi, chunki bu turlar Xulosa ni amalga oshirmaydi.
Traitlarni cheklash sintaksisi
impl Trait sintaksisi oddiy holatlar uchun ishlaydi, lekin aslida trait bound deb nomlanuvchi uzunroq shakl uchun sintaksis shakaridir; bu shunday ko'rinadi:
pub fn xabar_berish<T: Xulosa>(element: &T) {
println!("Tezkor xabarlar! {}", element.umumiy_xulosa());
}Ushbu uzunroq shakl oldingi bo'limdagi misolga teng, ammo batafsilroq. Trait chegaralarini ikki nuqta va ichki burchakli qavslardan keyin umumiy tur parametri e'lon qilingan holda joylashtiramiz.
impl Trait sintaksisi qulay va oddiy holatlarda ixchamroq kodni yaratadi, to'liqroq traitlar bilan bog'langan sintaksisi esa boshqa holatlarda ko'proq murakkablikni ifodalashi mumkin. Misol uchun, bizda Xulosa ni amalga oshiradigan ikkita parametr bo'lishi mumkin. Buni impl Trait sintaksisi bilan bajarish quyidagicha ko'rinadi:
pub fn xabar_berish(element1: &impl Xulosa, element2: &impl Xulosa) {Agar biz ushbu funksiya element1 va element2 turli xil turlarga ega bo'lishini istasak, impl Trait dan foydalanish maqsadga muvofiqdir (agar ikkala tur ham Xulosani qo'llasa). Agar biz ikkala parametrni bir xil turga ega bo'lishga majburlamoqchi bo'lsak, quyidagi kabi trait bounddan foydalanishimiz kerak:
pub fn xabar_berish<T: Xulosa>(element1: &T, element2: &T) {element1 va element2 parametrlarining turi sifatida belgilangan umumiy T turi funksiyani shunday cheklaydiki, element1 va element2 uchun argument sifatida berilgan qiymatning aniq turi bir xil bo`lishi kerak.
+ sintaksisi bilan bir nechta trait chegaralarini belgilash
Bundan tashqari, biz bir nechta traitlarni belgilashimiz mumkin. Aytaylik, biz xabar_berish funksiyasidan display formatlash hamda element bo‘yicha umumiy_xulosadan foydalanishni xohladik: biz xabar_berish ta'rifida element Display va Xulosa ni ham amalga oshirishi kerakligini belgilaymiz. Buni + sintaksisi yordamida amalga oshirishimiz mumkin:
pub fn xabar_berish(element: &(impl Xulosa + Display)) {+ sintaksisi generik turdagi belgilar chegaralari bilan ham amal qiladi:
pub fn xabar_berish<T: Xulosa+ Display>(element: &T) {Belgilangan ikkita trait chegarasi bilan xabar_berish asosiy qismi umumiy_xulosa deb chaqirishi va elementni formatlash uchun {} dan foydalanishi mumkin.
where bandlari bilan aniqroq trait bounds(chegaralari)
Haddan tashqari ko'p belgilar boundlaridan foydalanish o'zining salbiy tomonlariga ega. Har bir generikning o'ziga xos trait boundlari bor, shuning uchun bir nechta umumiy turdagi parametrlarga ega funksiyalar funksiya nomi va uning parametrlar ro'yxati o'rtasida ko'plab belgilar bilan bog'liq ma'lumotlarni o'z ichiga olishi mumkin, bu funksiya imzosini o'qishni qiyinlashtiradi. Shu sababli, Rust funksiya imzosidan keyin where bandida trait boundlarini belgilash uchun muqobil sintaksisga ega.
fn boshqa_funksiya<T: Display + Clone, U: Clone + Debug>(t: &T, u: &U) -> i32 {biz where bandidan foydalanishimiz mumkin, masalan:
fn boshqa_funksiya<T, U>(t: &T, u: &U) -> i32
where
T: Display + Clone,
U: Clone + Debug,
{
unimplemented!()
}Bu funksiya imzosi kamroq chalkash: funksiya nomi, parametrlar ro'yxati va qaytish turi bir-biriga yaqin bo'lib, ko'p trait boundlari bo'lmagan funksiyaga o'xshaydi.
Traitlarni amalga oshiradigan Return(qaytaruvchi) turlar
Bu yerda ko'rsatilganidek, traitni amalga oshiradigan ba'zi turdagi qiymatni qaytarish(return) uchun impl Trait sintaksisini return holatida ham ishlatishimiz mumkin:
pub trait Xulosa {
fn umumiy_xulosa(&self) -> String;
}
pub struct YangiMaqola {
pub sarlavha: String,
pub manzil: String,
pub muallif: String,
pub mazmuni: String,
}
impl Xulosa for YangiMaqola {
fn umumiy_xulosa(&self) -> String {
format!("{}, by {} ({})", self.sarlavha, self.muallif, self.manzil)
}
}
pub struct Maqola {
pub foydalanuvchi: String,
pub mazmuni: String,
pub javob_berish: bool,
pub repost: bool,
}
impl Xulosa for Maqola {
fn umumiy_xulosa(&self) -> String {
format!("{}: {}", self.foydalanuvchi, self.mazmuni)
}
}
fn return_xulosa() -> impl Xulosa {
Maqola {
foydalanuvchi: String::from("ismoilovdev"),
mazmuni: String::from(
"Rust kitobi juda foydali ekan, men juda ko'p bilimlarni o'zlashtirdim",
),
javob_berish: false,
repost: false,
}
}Qaytish(return) turi uchun impl Xulosa dan foydalanib, biz return_xulosa funksiyasi aniq turga nom bermasdan Xulosa traitini amalga oshiradigan ba'zi turlarni qaytarishini aniqlaymiz. Bunday holda, return_xulosa Maqola ni qaytaradi, lekin bu funksiyani chaqiruvchi kod buni bilishi shart emas.
Qaytish turini faqat u amalga oshiradigan traitga ko'ra belgilash qobiliyati, ayniqsa, biz 13-bobda ko'rib chiqiladigan closurelar va iteratorlar kontekstida foydalidir. Closures va iteratorlar faqat kompilyator biladigan turlarni yoki belgilash uchun juda uzoq turlarni yaratadi. impl Trait sintaksisi sizga funksiya juda uzun turni yozishga hojat qoldirmasdan Iterator traitini amalga oshiradigan ba'zi turlarni qaytarishini qisqacha belgilash imkonini beradi.
Biroq, faqat bitta turni qaytarayotgan bo'lsangiz, impl Trait dan foydalanishingiz mumkin. Masalan, YangiMaqola yoki Maqolani qaytaruvchi impl Xulosa sifatida ko‘rsatilgan qaytarish turiga ega bo‘lgan bu kod ishlamaydi:
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct Tweet {
pub username: String,
pub content: String,
pub reply: bool,
pub retweet: bool,
}
impl Summary for Tweet {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
fn returns_summarizable(switch: bool) -> impl Summary {
if switch {
NewsArticle {
headline: String::from(
"Penguins win the Stanley Cup Championship!",
),
location: String::from("Pittsburgh, PA, USA"),
author: String::from("Iceburgh"),
content: String::from(
"The Pittsburgh Penguins once again are the best \
hockey team in the NHL.",
),
}
} else {
Tweet {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
retweet: false,
}
}
}YangiMaqola yoki Maqolani qaytarishga impl Trait sintaksisi kompilyatorda qanday amalga oshirilishi bilan bog‘liq cheklovlar tufayli ruxsat berilmaydi. Ushbu xatti-harakat bilan funksiyani qanday yozishni biz 17-bobning "Turli turdagi qiymatlarga ruxsat beruvchi trait ob'ektlaridan foydalanish" bo'limida ko'rib chiqamiz.
Metodlarni shartli ravishda amalga oshirish uchun Trait Boundlardan foydalanish
Umumiy turdagi parametrlardan foydalanadigan impl bloki bilan trait bounddan foydalanib, biz belgilangan traitlarni amalga oshiradigan turlar uchun metodlarni shartli ravishda amalga oshirishimiz mumkin. Masalan, 10-15-ro'yxatdagi Pair<T> turi har doim yangi Pair<T> nusxasini qaytarish uchun new funksiyasini amalga oshiradi (5-bobning “Metodlarni aniqlash” boʻlimidan eslaylikki, Self bu impl bloki turiga tegishli turdagi taxallus(alias) boʻlib, bu holda Pair<T> boʻladi). Ammo keyingi impl blokida Pair<T> faqat cmp_display metodini qo'llaydi, uning ichki turi(inner type) T taqqoslash imkonini beruvchi PartialOrd traitini va chop etish imkonini beruvchi Display traittini amalga oshiradi.
Fayl nomi: src/lib.rs
use std::fmt::Display;
struct Pair<T> {
x: T,
y: T,
}
impl<T> Pair<T> {
fn new(x: T, y: T) -> Self {
Self { x, y }
}
}
impl<T: Display + PartialOrd> Pair<T> {
fn cmp_display(&self) {
if self.x >= self.y {
println!("Eng katta a'zo x = {}", self.x);
} else {
println!("Eng katta a'zo y = {}", self.y);
}
}
}Ro'yxat 10-15: Trait boundga qarab generik tur bo'yicha shartli ravishda qo'llash metodlari
Biz shartli ravishda boshqa traitni amalga oshiradigan har qanday tur uchun traitni amalga oshirishimiz mumkin. Trait boundlarni qondiradigan har qanday turdagi tarittni amalga oshirish blanket implementations deb nomlanadi va Rust standart kutubxonasida keng qo'llaniladi. Masalan, standart kutubxona Display traitini amalga oshiradigan har qanday turdagi ToString traitini amalga oshiradi. Standart kutubxonadagi impl bloki ushbu kodga o'xshaydi:
impl<T: Display> ToString for T {
// --snip--
}Standart kutubxonada bu keng qamrovli dastur mavjud bo'lganligi sababli, biz Display traitini amalga oshiradigan har qanday turdagi ToString traiti bilan aniqlangan to_string metodini chaqirishimiz mumkin. Masalan, biz butun sonlarni mos keladigan String qiymatlariga shunday aylantirishimiz mumkin, chunki butun sonlar Displayni amalga oshiradi:
#![allow(unused)] fn main() { let s = 3.to_string(); }
Blanket implementationlari "Implementors" bo'limidagi trait uchun texnik hujjatlarda ko'rinadi.
Traitlar va trait boundlar takrorlanishni kamaytirish uchun generik turdagi parametrlardan foydalanadigan kod yozishga imkon beradi, shuningdek, generik turning o'ziga xos xatti-harakatlariga ega bo'lishini kompilyatorga ko'rsatishga imkon beradi. Keyin kompilyator trait bilan bog'langan ma'lumotlardan bizning kodimiz bilan qo'llaniladigan barcha aniq turlar to'g'ri xatti-harakatni ta'minlaydiganligini tekshirish uchun foydalanishi mumkin. Dinamik ravishda tuzilgan tillarda, agar biz metodni aniqlamagan turdagi metodni chaqirsak, runtimeda xatoga yo'l qo'yamiz. Ammo Rust bu xatolarni vaqtni kompilyatsiya qilish uchun ko'chiradi, shuning uchun biz kodimiz ishga tushgunga qadar muammolarni hal qilishga majbur bo'lamiz. Bundan tashqari, biz runtimeda xatti-harakatni tekshiradigan kod yozishimiz shart emas, chunki biz kompilyatsiya vaqtida allaqachon tekshirganmiz. Bu generiklarning moslashuvchanligidan voz kechmasdan ishlashni yaxshilaydi.
Referencelarni lifetime bilan tekshirish
Lifetimelar - biz allaqachon uchratgan generiklarning yana bir turi. Turning biz xohlagan xatti-harakatga ega bo'lishini ta'minlash o'rniga, lifetime referencelar biz uchun kerak bo'lganda haqiqiyligini ta'minlaydi.
4-bobdagi [“Referencelar va Borrowing”](references-and-borrowing) bo‘limida biz muhokama qilmagan bir tafsilot shundan iboratki, Rust-dagi har bir referenceda o‘sha referencening amal qilish doirasi lifetime bo‘ladi. Ko'pincha, lifetimelar yashirin va inferred bo'ladi, ko'p hollarda bo'lgani kabi, turlar ham inferred qilinadi.Biz faqat bir nechta tur mumkin bo'lganda turlarga izoh berishimiz kerak. Shunga o'xshab, biz referencelarning lifetime bir necha xil yo'llar bilan bog'lanishi mumkin bo'lgan lifetimelarini izohlashimiz kerak. Rust bizdan runtimeda ishlatiladigan haqiqiy referencelar haqiqiy bo'lishini ta'minlash uchun generik lifetime parametrlaridan foydalangan holda munosabatlarga izoh berishimizni talab qiladi.
Lifetimeni izohlash boshqa dasturlash tillarining ko'pchiligida mavjud bo'lgan tushuncha ham emas, shuning uchun bu notanish tuyuladi. Garchi biz ushbu bobda lifetimeni to'liq qamrab olmasak ham, kontseptsiyadan qulay bo'lishingiz uchun lifetime sintaksisga duch kelishingiz mumkin bo'lgan umumiy usullarni muhokama qilamiz.
Lifetimeda dangling referencelarni oldini olish
Lifetimening asosiy maqsadi dasturga reference qilish uchun mo'ljallangan ma'lumotlardan boshqa ma'lumotlarga reference qilishiga olib keladigan dangling referencelar ning oldini olishdir. 10-16 ro'yxatdagi dasturni ko'rib chiqing, uning tashqi va ichki ko'lami(tashqi va ichki ishlash doirasi) bor.
fn main() {
let r;
{
let x = 5;
r = &x;
}
println!("r: {}", r);
}Ro'yxat 10-16: Qiymati ishlash doiradan chiqib ketgan referencedan foydalanishga urinish
Eslatma: 10-16, 10-17 va 10-23 ro'yxatlardagi misollar o'zgaruvchilarni ularga boshlang'ich qiymat bermasdan e'lon qiladi, shuning uchun o'zgaruvchi nomi tashqi doirada mavjud. Bir qarashda, bu Rustning null qiymatlari yo'qligiga zid bo'lib tuyulishi mumkin. Biroq, agar biz o'zgaruvchiga qiymat berishdan oldin foydalanmoqchi bo'lsak, biz kompilyatsiya vaqtida xatoga duch kelamiz, bu Rust haqiqatan ham null qiymatlarga ruxsat bermasligini ko'rsatadi.
Tashqi qamrov boshlang‘ich qiymati bo‘lmagan r nomli o‘zgaruvchini, ichki qamrov esa boshlang‘ich qiymati 5 bo‘lgan x nomli o‘zgaruvchini e’lon qiladi. Ichki doirada(qamrov) biz x ga reference sifatida r qiymatini belgilashga harakat qilamiz. Keyin ichki qamrov tugaydi va biz qiymatni r da chop etishga harakat qilamiz. Ushbu kod kompilyatsiya qilinmaydi, chunki biz undan foydalanishga urinishdan oldin r qiymati ko'rib chiqilmaydi. Mana xato xabari:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0597]: `x` does not live long enough
--> src/main.rs:6:13
|
6 | r = &x;
| ^^ borrowed value does not live long enough
7 | }
| - `x` dropped here while still borrowed
8 |
9 | println!("r: {}", r);
| - borrow later used here
For more information about this error, try `rustc --explain E0597`.
error: could not compile `chapter10` due to previous error
x o'zgaruvchisi "yetarlicha uzoq umr ko'rmaydi". Sababi, 7-qatorda ichki qamrov tugashi bilan x amaldan tashqarida bo'ladi. Lekin r tashqi doira uchun hamon amal qiladi; uning qamrovi kengroq bo'lgani uchun biz uni "uzoq yashaydi" deymiz. Agar Rust ushbu kodning ishlashiga ruxsat bergan bo'lsa, r x doiradan chiqib ketganda ajratilgan xotiraga reference bo'ladi va biz r bilan qilishga uringan har qanday narsa to'g'ri ishlamaydi. Xo'sh, Rust bu kodning yaroqsizligini qanday aniqlaydi?
Bu borrow(qarz) tekshiruvidan foydalanadi.
Borrow tekshiruvchisi
Rust kompilyatorida barcha borrowlar to'g'ri yoki yo'qligini aniqlash uchun ko'lamlarni taqqoslaydigan borrow tekshiruvi(borrow checker) mavjud. 10-17 ro'yxat 10-16 ro'yxati bilan bir xil kodni ko'rsatadi, ammo o'zgaruvchilarning lifetime(ishlash muddatini) ko'rsatadigan izohlar bilan.
fn main() {
let r; // ---------+-- 'a
// |
{ // |
let x = 5; // -+-- 'b |
r = &x; // | |
} // -+ |
// |
println!("r: {}", r); // |
} // ---------+Roʻyxat 10-17: r va x ning mos ravishda a va b nomlari bilan ishlash lifetimening izohlari
Bu yerda biz rning lifetimeni a bilan va xning lifetimeni b bilan izohladik. Ko'rib turganingizdek, ichki b bloki tashqi 'a lifetime blokdan ancha kichik. Kompilyatsiya vaqtida Rust ikki lifetimening o'lchamini solishtiradi va r ning lifetime 'a ekanligini, lekin u 'b lifetime(umr bo'yi) xotiraga ishora qilishini ko'radi. Dastur rad etildi, chunki 'b 'a dan qisqaroq: reference mavzusi reference kabi uzoq vaqt yashamaydi.
Ro'yxat 10-18 kodni tuzatadi, shuning uchun u dangling referencega ega emas va hech qanday xatosiz kompilyatsiya qilinadi.
fn main() { let x = 5; // ----------+-- 'b // | let r = &x; // --+-- 'a | // | | println!("r: {}", r); // | | // --+ | } // ----------+
Ro'yxat 10-18: To'g'ri reference, chunki referencelar mos yozuvlardan ko'ra uzoqroq lifetimega ega
Bu erda x 'b muddatiga ega, bu holda 'a dan kattaroqdir. Bu r x ga murojaat qilishi mumkin degan ma'noni anglatadi, chunki Rust r dagi reference har doim x amalda bo`lishini biladi.
Endi siz referencelarning amal qilish muddati qayerda ekanligini va referencelar har doim haqiqiy boʻlishini taʼminlash uchun Rust lifetimeni qanday tahlil qilishini bilganingizdan soʻng, keling, funksiyalar kontekstida parametrlarning generik lifetime va qiymatlarni qaytarishni koʻrib chiqaylik.
Funksiyalarning generik lifetime
Biz ikkita satr bo'lagining uzunligini qaytaradigan funksiyani yozamiz. Bu funksiya ikkita satr bo'lagini oladi va bitta satr bo'lagini qaytaradi. eng_uzun funksiyasini amalga oshirganimizdan so'ng, 10-19 ro'yxatdagi kod Eng uzun satr - abcd ni chop etishi kerak.
Fayl nomi: src/main.rs
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("Eng uzun satr {}", result);
}Ro'yxat 10-19: Ikki qator boʻlagining uzunini topish uchun eng_uzun funksiyani chaqiruvchi main funksiya
E'tibor bering, biz funksiya satrlarni emas, referencelar bo'lgan satr bo'laklarini olishni xohlaymiz, chunki biz eng_uzun funksiya uning parametrlariga egalik qilishni xohlamaymiz. 10 19 roʻyxatda biz foydalanadigan parametrlar nima uchun biz xohlagan parametrlar ekanligi haqida koʻproq muhokama qilish uchun 4-bobdagi “String slicelari parametr sifatida” boʻlimiga qarang.
Agar biz 10-20 ro'yxatda ko'rsatilganidek, eng_uzun funksiyasini amalga oshirishga harakat qilsak, u kompilyatsiya qilinmaydi.
Fayl nomi: src/main.rs
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let natija = eng_uzun(string1.as_str(), string2);
println!("Eng uzun satr {}", natija);
}
fn eng_uzun(x: &str, y: &str) -> &str {
if x.len() > y.len() {
x
} else {
y
}
}Ro'yxat 10-20: Ikki qatorli boʻlakning uzunroq qismini qaytaradigan, lekin hali kompilyatsiya qilinmagan eng_uzun funksiyaning amalga oshirilishi
Buning o'rniga biz lifetime haqida gapiradigan quyidagi xatoni olamiz:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0106]: missing lifetime specifier
--> src/main.rs:9:33
|
9 | fn eng_uzun(x: &str, y: &str) -> &str {
| ---- ---- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `x` or `y`
help: consider introducing a named lifetime parameter
|
9 | fn eng_uzun<'a>(x: &'a str, y: &'a str) -> &'a str {
| ++++ ++ ++ ++
For more information about this error, try `rustc --explain E0106`.
error: could not compile `chapter10` due to previous error
Yordam matni shuni ko'rsatadiki, return(qaytarish) turiga umumiy lifetime parametri kerak, chunki Rust qaytarilayotgan reference x yoki y ga tegishli ekanligini aniqlay olmaydi. Aslida, biz ham bilmaymiz, chunki bu funksiyaning asosiy qismidagi if bloki x ga referenceni, else bloki esa y ga referenceni qaytaradi!
Ushbu funksiyani aniqlaganimizda, biz ushbu funksiyaga o'tadigan aniq qiymatlarni bilmaymiz, shuning uchun if yoki else ishi bajarilishini bilmaymiz. Shuningdek, biz uzatiladigan referencelarning aniq amal qilish muddatini bilmaymiz, shuning uchun biz qaytaradigan(return) lifetime har doim haqiqiy bo'lishini aniqlash uchun 10-17 va 10-18 ro'yxatlarda bo'lgani kabi qamrovni ko'rib chiqa olmaymiz. Borrow tekshiruvchisi buni ham aniqlay olmaydi, chunki u x va y ning ishlash lifetime qaytarilgan qiymatning lifetime(ishlash muddati) bilan qanday bog'liqligini bilmaydi. Ushbu xatoni tuzatish uchun biz referencelar o'rtasidagi munosabatni aniqlaydigan umumiy lifetime parametrlarini qo'shamiz, shunda borrow tekshiruvi tahlilini amalga oshirishi mumkin.
Lifetime annotation sintaksisi
Lifetime annotationlar referencelarning qancha yashashini ko'rishini o'zgartirmaydi. Aksincha, ular lifetimega ta'sir qilmasdan, bir-biriga ko'plab murojaatlarning umrbod lifetimelar munosabatlarini tasvirlaydi. Signature generik turdagi parametrni ko'rsatsa, funksiyalar har qanday turni qabul qilishi mumkin bo'lgani kabi, funksiyalar ham umumiy lifetime parametrini belgilash orqali har qanday xizmat muddati bilan murojaatlarni qabul qilishi mumkin.
Lifetime annotationlar biroz noodatiy sintaksisga ega: lifetime parametrlarining nomlari apostrof (') bilan boshlanishi kerak va odatda generik turlar kabi kichik va juda qisqa bo'ladi. Ko'pchilik lifetime annotation birinchi izoh uchun 'a nomidan foydalanadi. Annotationi reference turidan ajratish uchun boʻsh joydan foydalanib, biz lifetime parametr annotationlarini referencening & belgisidan keyin joylashtiramiz.
Mana bir nechta misollar: lifetime parametri bo'lmagan i32 ga reference, 'a nomli lifetime parametriga ega i32 ga reference va lifetime 'a bo'lgan i32 ga o'zgaruvchan reference.
&i32 // reference
&'a i32 // aniq lifetimega ega bo'lgan reference
&'a mut i32 // aniq lifetimega ega o'zgaruvchan referenceBir umrlik lifetime annotatsiyaning o'zi katta ma'noga ega emas, chunki annotatsiyalar Rustga bir nechta referencelalarning lifetime generik parametrlari bir-biriga qanday bog'liqligini aytib berish uchun mo'ljallangan. Keling, eng_uzun funksiya kontekstida lifetime annotatsiyalarning bir-biriga qanday bog'liqligini ko'rib chiqaylik.
Funksiya signaturelaridagi lifetime annotatsiyalar
Funksiya signaturelarida lifetime annotatsiyalardan foydalanish uchun biz generik tur parametrlari bilan qilganimiz kabi, funksiya nomi va parametrlar ro'yxati o'rtasida burchak qavslar ichida generik lifetime parametrlarini e'lon qilishimiz kerak.
Biz signature quyidagi cheklovni ifodalashini istaymiz: qaytarilgan(return) reference ikkala parametr ham to'g'ri bo'lsa, haqiqiy bo'ladi. Bu parametrlarning lifetime(ishlash muddati) va qaytariladigan(return) qiymat o'rtasidagi bog'liqlikdir. 10-21 ro'yxatda ko'rsatilganidek, biz lifetimega 'a deb nom beramiz va keyin uni har bir referencega qo'shamiz.
Fayl nomi: src/main.rs
fn main() { let string1 = String::from("abcd"); let string2 = "xyz"; let natija = eng_uzun(string1.as_str(), string2); println!("Eng uzun satr {}", natija); } fn eng_uzun<'a>(x: &'a str, y: &'a str) -> &'a str { if x.len() > y.len() { x } else { y } }
Ro'yxat 10-21: Signaturedagi barcha referencelar bir xil lifetimega(ishlash muddati) ega bo'lishi kerakligini ko'rsatuvchi eng_uzun funksiya ta'rifi 'a
Ushbu kod 10-19-sonli ro'yxatdagi main funksiyadan foydalanganda biz xohlagan natijani kompilyatsiya qilishi va ishlab chiqarishi kerak.
Funktsiya signaturesi endi Rustga ma'lum bir lifetimeda 'a funksiyasi ikkita parametrni qabul qilishini aytadi, ularning har ikkalasi ham kamida lifetime 'a bo'lgan string bo'laklaridir. Funktsiya signaturesi, shuningdek, Rustga funksiyadan qaytarilgan string bo'lagi hech bo'lmaganda 'a lifetimegacha yashashini aytadi.
Amalda, bu eng_uzun funksiya tomonidan qaytarilgan referencening lifetime, funksiya argumentlari bilan bog'liq bo'lgan qiymatlarning eng kichik lifetimesi bilan bir xil ekanligini anglatadi. Bu munosabatlar Rust ushbu kodni tahlil qilishda foydalanishini xohlaydigan narsadir.
Esda tutingki, biz ushbu funksiya signaturesida lifetime parametrlarini belgilaganimizda, biz kiritilgan yoki qaytarilgan qiymatlarning lifetimeni o'zgartirmaymiz. Aksincha, biz borrowni tekshiruvchi(borrow checker) ushbu cheklovlarga rioya qilmaydigan har qanday qiymatlarni rad etishi kerakligini ta'kidlaymiz. Shuni esda tutingki, eng_uzun funksiya x va y qancha vaqt ishlashini aniq bilishi shart emas, faqat ushbu signatureni qondiradigan 'a ga baʼzi bir qamrovni almashtirish mumkin.
Funksiyalarda lifetimeni izohlashda annotationlar funksiya tanasida emas, balki funksiya signaturesida bo'ladi. Signaturedagi turlar singari, lifetime annotationlar funksiya shartnomasining bir qismiga aylanadi. Funktsiya signaturelari lifetime shartnomani o'z ichiga oladi, degan ma'noni anglatadi Rust kompilyatori tahlil qilish osonroq bo'lishi mumkin. Agar funksiyaga izoh berish yoki uni chaqirish bilan bog'liq muammo bo'lsa, kompilyator xatolari kodimizning bir qismiga va cheklovlarga aniqroq ishora qilishi mumkin. Buning o'rniga, Rust kompilyatori biz lifetime munosabatlari haqida ko'proq taxminlar qilgan bo'lsa, kompilyator faqat muammoning sababidan bir necha qadam uzoqda bizning kodimizdan foydalanishni ko'rsatishi mumkin.
Biz eng_uzun ga aniq referencelar berganimizda, 'a o‘rniga qo‘yilgan aniq lifetime x doirasining y doirasiga to‘g‘ri keladigan qismidir. Boshqacha qilib aytadigan bo'lsak, 'a generik lifetimesi x va y ning eng kichik lifetimaga teng bo'lgan aniq lifetimeni oladi. Biz qaytarilgan(return) referencega bir xil lifetime parametri 'a bilan izoh berganimiz sababli, qaytarilgan reference x va y lifetimening kichikroq uzunligi uchun ham amal qiladi.
Keling, turli xil aniq lifetimelarga ega bo'lgan referencelarni o'tkazish orqali eng_uzun funksiyani qanday cheklashini ko'rib chiqaylik. Ro'yxat 10-22 - bu oddiy misol.
Fayl nomi: src/main.rs
fn main() { let string1 = String::from("uzundan uzun string"); { let string2 = String::from("xyz"); let natija = eng_uzun(string1.as_str(), string2.as_str()); println!("Eng uzun satr {}", natija); } } fn eng_uzun<'a>(x: &'a str, y: &'a str) -> &'a str { if x.len() > y.len() { x } else { y } }
Ro'yxat 10-22: eng_uzun funksiyasidan foydalanish, turli xil aniq lifetimega ega String qiymatlariga referencelar
Bu misolda string1 tashqi qamrov oxirigacha amal qiladi, string2 ichki qamrov oxirigacha amal qiladi va natija ichki doiraning oxirigacha amal qiladigan narsaga ishora qiladi. Ushbu kodni ishga tushiring va siz borrowni tekshiruvchi tasdiqlaganini ko'rasiz; u kompilyatsiya qiladi va Eng uzun satr - uzundan uzun string ni yaratadi.
Keyinchalik, natijadagi referencening lifetime ikkita argumentning kichikroq lifetime bo'lishi kerakligini ko'rsatadigan misolni ko'rib chiqaylik. Biz natija o'zgaruvchisi deklaratsiyasini ichki doiradan tashqariga o'tkazamiz, lekin qiymatni belgilashni string2 bilan doiradagi natija o'zgaruvchisiga qoldiramiz. Keyin, natijani ishlatadigan println!ni ichki doira tugagandan so‘ng, ichki doiradan tashqariga o‘tkazamiz. 10-23 ro'yxatdagi kod kompilyatsiya qilinmaydi.
Fayl nomi: src/main.rs
fn main() {
let string1 = String::from("uzundan uzun string");
let natija;
{
let string2 = String::from("xyz");
natija = eng_uzun(string1.as_str(), string2.as_str());
}
println!("Eng uzun satr {}", natija);
}
fn eng_uzun<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() {
x
} else {
y
}
}Ro'yxat 10-23: string2 dan keyin natija dan foydalanishga urinish
Ushbu kodni kompilyatsiya qilmoqchi bo'lganimizda, biz quyidagi xatoni olamiz:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0597]: `string2` does not live long enough
--> src/main.rs:6:44
|
6 | natija = eng_uzun(string1.as_str(), string2.as_str());
| ^^^^^^^^^^^^^^^^ borrowed value does not live long enough
7 | }
| - `string2` dropped here while still borrowed
8 | println!("Eng uzun satr {}", natija);
| ------ borrow later used here
For more information about this error, try `rustc --explain E0597`.
error: could not compile `chapter10` due to previous error
Xato shuni ko'rsatadiki, natija println! bayonoti uchun haqiqiy bo'lishi uchun string2 tashqi doiraning oxirigacha amal qilishi kerak. Rust buni biladi, chunki biz funksiya parametrlarining lifetimeni(ishlash muddati) va qiymatlarni bir xil 'a parametridan foydalangan holda izohladik.
Inson sifatida biz ushbu kodni ko'rib chiqamiz va string1 string2 dan uzunroq ekanligini ko'rishimiz mumkin va shuning uchun natija string1 ga referenceni o'z ichiga oladi.
string1 hali amaldan tashqariga chiqmaganligi sababli, string1ga reference println! bayonoti uchun amal qiladi. Biroq, kompilyator bu holatda reference haqiqiy ekanligini ko'ra olmaydi. Biz Rustga aytdikki, eng_uzun funksiya tomonidan qaytarilgan referencening lifetime uzatilgan referencelarning lifetimesidan kichikroq vaqt bilan bir xil. Shuning uchun, borrowni tekshirish vositasi 10-23 ro'yxatdagi kodga ruxsat bermaydi, chunki noto'g'ri reference mavjud.
eng_uzun funksiyaga oʻtkazilgan referencelarning qiymatlari va amal lifetime va qaytarilgan(return) referencedan qanday foydalanishni oʻzgartiruvchi koʻproq tajribalar ishlab chiqishga harakat qiling. Kompilyatsiya qilishdan oldin tajribalaringiz borrow tekshiruvidan o'tadimi yoki yo'qmi haqida faraz qiling; keyin siz haq ekanligingizni tekshiring!
Lifetime nuqtai nazaridan fikrlash
Lifetime parametrlarini belgilashingiz kerak bo'lgan metod sizning funksiyangiz nima qilayotganiga bog'liq. Misol uchun, agar biz eng_uzun funksiyasini amalga oshirishni har doim eng uzun satr bo'lagini emas, balki birinchi parametrni qaytarish uchun o'zgartirgan bo'lsak, y parametrida lifetimeni belgilashimiz shart emas. Quyidagi kod kompilyatsiya qilinadi:
Fayl nomi: src/main.rs
fn main() { let string1 = String::from("abcd"); let string2 = "efghijklmnopqrstuvwxyz"; let natija = eng_uzun(string1.as_str(), string2); println!("Eng uzun satr {}", natija); } fn eng_uzun<'a>(x: &'a str, y: &str) -> &'a str { x }
Biz x parametri va qaytarish(return) turi uchun lifetime 'a parametrini belgiladik, lekin y parametri uchun emas, chunki y ning lifetimesi x yoki qaytarish qiymati bilan hech qanday aloqasi yo'q.
Funksiyadan mos yozuvlar qaytarilganda, qaytarish turi uchun lifetime parametri parametrlardan birining lifetime parametriga mos kelishi kerak. Agar qaytarilgan reference parametrlardan biriga tegishli bo'lmasa, u ushbu funksiya doirasida yaratilgan qiymatga murojaat qilishi kerak. Biroq, bu dangling reference bo'ladi, chunki funksiya oxirida qiymat doiradan chiqib ketadi.
Kompilyatsiya qilmaydigan eng_uzun funksiyani amalga oshirishga urinishlarni ko'rib chiqing:
Fayl nomi: src/main.rs
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let natija = eng_uzun(string1.as_str(), string2);
println!("Eng uzun satr {}", natija);
}
fn eng_uzun<'a>(x: &str, y: &str) -> &'a str {
let natija = String::from("haqiqatan ham uzun satr");
natija.as_str()
}Bu erda, biz qaytish turi uchun lifetime parametr 'a ni belgilagan bo'lsak ham, bu dastur kompilyatsiya qilinmaydi, chunki qaytish qiymatining lifetime parametrlarning lifetime bilan umuman bog'liq emas. Mana biz olgan xato xabari:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0515]: cannot return reference to local variable `result`
--> src/main.rs:11:5
|
11 | result.as_str()
| ^^^^^^^^^^^^^^^ returns a reference to data owned by the current function
For more information about this error, try `rustc --explain E0515`.
error: could not compile `chapter10` due to previous error
Muammo shundaki, natija ishchi ko'lamdan tashqariga chiqadi va eng_uzun funksiya oxirida tozalanadi. Shuningdek, biz funksiyadan natijaga referenceni qaytarishga harakat qilyapmiz. Dangling referenceni o'zgartiradigan lifetime parametrlarini belgilashning iloji yo'q va Rust bizga dangling reference yaratishga ruxsat bermaydi. Bunday holda, eng yaxshi tuzatish mos yozuvlar emas, balki tegishli referencelar turini qaytarish bo'ladi, shuning uchun chaqiruv funksiyasi qiymatni tozalash uchun javobgar bo'ladi.
Oxir oqibat, lifetime sintaksisi turli parametrlarning ishlash muddatini va funktsiyalarning qaytish qiymatlarini bog'lashdir. Ular ulangandan so'ng, Rust xotira xavfsizligini ta'minlaydigan operatsiyalarga ruxsat berish va dangling pointerlarni yaratish yoki xotira xavfsizligini boshqa tarzda buzadigan operatsiyalarga ruxsat berish uchun yetarli ma'lumotga ega.
Struktura ta'riflarida lifetime annotationlar
Hozirgacha biz belgilagan structlar barcha egalik turlariga ega. Biz referencelarni saqlash uchun structlarni belgilashimiz mumkin, ammo bu holda structning ta'rifidagi har bir referencega lifetime annotation qo'shishimiz kerak bo'ladi. 10-24 roʻyxatda ImportantExcerpt nomli struktura mavjud boʻlib, u string sliceni saqlaydi.
Fayl nomi: src/main.rs
struct ImportantExcerpt<'a> { qism: &'a str, } fn main() { let roman = String::from("Meni yaxshi dasturchi edim. Bir necha yil oldin..."); let birinchi_jumla = roman.split('.').next().expect("'.' belgisini topib bo'lmadi."); let i = ImportantExcerpt { qism: birinchi_jumla, }; }
Ro'yxat 10-24: Referencega ega bo'lgan struct, lifetime annotationni talab qiladi
Bu structda bir satr boʻlagini oʻz ichiga oluvchi qism maydoni mavjud boʻlib, bu referencelardir. Generik(umumiy) ma'lumotlar turlarida bo'lgani kabi, biz structning nomidan keyin burchakli qavslar ichida generik lifetime parametrining nomini e'lon qilamiz, shuning uchun biz structning ta'rifi tanasida lifetime parametridan foydalanishimiz mumkin. Bu izoh ImportantExcerpt namunasi oʻzining qism maydonidagi referencedan uzoqlasha olmasligini bildiradi.
Bu yerda main funksiyasi roman oʻzgaruvchisiga tegishli Stringning birinchi jumlasiga referenceni oʻz ichiga olgan ImportantExcerpt strukturasining namunasini yaratadi. romandagi ma'lumotlar ImportantExcerpt misoli yaratilishidan oldin mavjud. Bundan tashqari, roman ImportantExcerpt ishchi doirasi tashqariga chiqmagunicha, ishchi doiradan chiqib ketmaydi, shuning uchun ImportantExcerpt misolidagi reference haqiqiy hisoblanadi.
Lifetime Elision
Siz har bir referencening lifetime(ishlash muddati) borligini va referencelardan foydalanadigan funksiyalar yoki structlar uchun lifetime parametrlarini belgilashingiz kerakligini bilib oldingiz. Biroq, 4-bobda biz 4-9-ro'yxatdagda funksiyaga ega bo'ldik, u keyin yana 10-25 ro'yxatda ko'rsatiladi, unda kod lifetime annotationsiz tuzilgan.
Fayl nomi: src/lib.rs
fn first_word(s: &str) -> &str { let bytes = s.as_bytes(); for (i, &item) in bytes.iter().enumerate() { if item == b' ' { return &s[0..i]; } } &s[..] } fn main() { let my_string = String::from("hello world"); // first_word works on slices of `String`s let word = first_word(&my_string[..]); let my_string_literal = "hello world"; // first_word works on slices of string literals let word = first_word(&my_string_literal[..]); // Because string literals *are* string slices already, // this works too, without the slice syntax! let word = first_word(my_string_literal); }
Ro'yxat 10-25: Biz 4-9 ro'yxatda aniqlagan funksiya, parametr va qaytish(return) turi referencelar bo'lsa ham, lifetime annotationsiz(umrbod lifetime) tuzilgan.
Ushbu funktsiyaning lifetime annotationlarsiz kompilyatsiya qilinishining sababi tarixiydir: Rust-ning dastlabki versiyalarida (1.0-dan oldingi) bu kod kompilyatsiya bo'lmagan bo'lardi, chunki har bir reference aniq ishlash muddatini talab qiladi. O'sha paytda funktsiya signaturesi quyidagicha yozilgan bo'lar edi:
fn birinchi_belgi<'a>(s: &'a str) -> &'a str {Rust-da juda ko'p kod yozgandan so'ng, Rust jamoasi Rust dasturchilari muayyan vaziyatlarda bir xil lifetime annotatiolarni qayta-qayta kiritayotganini aniqladilar. Bu vaziyatlarni oldindan aytish mumkin edi va bir nechta deterministik patternlarga amal qildi. Ishlab chiquvchilar ushbu patternlarni kompilyator kodiga dasturlashtirdilar, shuning uchun borrow tekshiruvi ushbu vaziyatlarda lifetimeni(ishlash muddatini) aniqlay oladi va aniq izohlarga muhtoj bo'lmaydi.
Rust tarixining ushbu qismi dolzarbdir, chunki ko'proq deterministik patternlar paydo bo'lishi va kompilyatorga qo'shilishi mumkin. Kelajakda undan ham kamroqlifetime annotationlar talab qilinishi mumkin.
Rustning referencelarni tahlil qilishda dasturlashtirilgan patternlar lifetime elision qoidalari(lifetime elision rules) deb ataladi. Bu dasturchilar rioya qilishi kerak bo'lgan qoidalar emas; ular kompilyator ko'rib chiqadigan muayyan holatlar to'plamidir va agar sizning kodingiz ushbu holatlarga mos keladigan bo'lsa, lifetime vaqtlarini aniq yozishingiz shart emas.
Elision qoidalari to'liq xulosa chiqarmaydi. Agar Rust qoidalarni qat'iy qo'llasa, lekin referencelarning qancha vaqt ishlashi(lifetime) haqida hali ham noaniqlik mavjud bo'lsa, kompilyator qolgan referencelarning lifetime(ishlash muddati) qancha bo'lishi kerakligini taxmin qila olmaydi. Taxmin qilish o'rniga, kompilyator sizga lifetime annotationlarni qo'shish orqali hal qilishingiz mumkin bo'lgan xatoni beradi.
Funksiya yoki metod parametrlari bo‘yicha lifetime kirish lifetime (input lifetimes), qaytariladigan(return) qiymatlar bo‘yicha lifetime chiqish lifetimei (output lifetimes) deb ataladi.
Aniq izohlar(annotation) bo'lmasa, kompilyator referencelarning lifetimeni aniqlash uchun uchta qoidadan foydalanadi. Birinchi qoida kirish lifetimega(input lifetimes), ikkinchi va uchinchi qoidalar esa chiqish lifetimega(output lifetimes) tegishli. Agar kompilyator uchta qoidaning oxiriga yetib borsa va hali ham lifetimeni(foydalanish muddati) aniqlay olmaydigan referencelar mavjud bo'lsa, kompilyator xato bilan to'xtaydi.
Bu qoidalar fn ta'riflari hamda impl bloklari uchun amal qiladi.
Birinchi qoida shundaki, kompilyator mos yozuvlar bo'lgan har bir parametrga lifetime parametrni belgilaydi.
Ikkinchi qoida shuki, agar aynan bitta kirish lifetime(input) parametri mavjud boʻlsa, u lifetime barcha chiqish(output) lifetime parametrlariga tayinlanadi: fn foo<'a>(x: &'a i32) -> &'a i32.
Uchinchi qoida shundaki, agar kirish lifetime bir nechta parametrlar mavjud bo'lsa, lekin ulardan biri &self yoki &mut self bo'lsa, chunki bu metod bo'lsa, self lifetime barcha chiqish lifetime parametrlariga tayinlanadi. Ushbu uchinchi qoida metodlarni o'qish va yozishni ancha yaxshi qiladi, chunki kamroq belgilar kerak.
Tasavvur qilaylik, biz kompilyatormiz. 10-25 roʻyxatdagi birinchi_belgi funksiyasi signaturesidagi referencelarning lifetimeni(amal qilish muddati) aniqlash uchun biz ushbu qoidalarni qoʻllaymiz. Signature referencelalar bilan bog'liq bo'lmagan lifetimesiz(muddatsiz) boshlanadi:
fn birinchi_belgi(s: &str) -> &str {Keyin kompilyator birinchi qoidani qo'llaydi, bu har bir parametr o'z lifetimesini oladi. Biz uni odatdagidek 'a deb ataymiz, shuning uchun endi signature quyidagicha:
fn birinchi_belgi<'a>(s: &'a str) -> &str {Ikkinchi qoida amal qiladi, chunki aynan bitta kirish lifetime mavjud. Ikkinchi qoida bitta kirish(input) parametrining lifetime chiqish lifetimesiga tayinlanishini bildiradi, shuning uchun signature endi quyidagicha:
fn birinchi_belgi<'a>(s: &'a str) -> &'a str {Endi ushbu funksiya signaturesidagi barcha referencelar lifetimesiga ega va kompilyator dasturchiga ushbu funksiya signaturesidagi lifetimeni izohlashiga hojat qoldirmasdan tahlilini davom ettirishi mumkin.
Keling, yana bir misolni ko'rib chiqaylik, bu safar biz 10 20 ro'yxatda ishlashni boshlaganimizda lifetime parametrlarga ega bo'lmagan eng_uzun funksiyadan foydalangan holda:
fn eng_uzun(x: &str, y: &str) -> &str {Keling, birinchi qoidani qo'llaymiz: har bir parametr o'z lifetimeni oladi. Bu safar bizda bitta emas, ikkita parametr bor, shuning uchun bizda ikkita lifetime bor:
fn eng_uzun<'a, 'b>(x: &'a str, y: &'b str) -> &str {Siz ikkinchi qoida qo'llanilmasligini ko'rishingiz mumkin, chunki bir nechta kirish lifetime mavjud. Uchinchi qoida ham qo'llanilmaydi, chunki eng_uzun - bu metod emas, balki funksiya, shuning uchun parametrlarning hech biri self emas. Barcha uchta qoidani ko'rib chiqqandan so'ng, biz qaytish(return) turining lifetime nima ekanligini hali aniqlay olmadik. Shuning uchun biz 10-20 ro'yxatdagi kodni kompilyatsiya qilishda xatoga yo'l qo'ydik: kompilyator lifetime elision qoidalari bo'yicha ishladi, lekin signaturedagi referencelarning butun lifetimeni aniqlay olmadi.
Uchinchi qoida haqiqatan ham faqat metod signaturelarida amal qilganligi sababli, biz ushbu kontekstda lifetimeni ko'rib chiqamiz, nima uchun uchinchi qoida biz metod signaturelariga tez-tez izoh qo'yishimiz shart emasligini tushunish uchun.
Metod ta'riflarida(defination) Lifetime Annotationlar
Biz lifetime bo'lgan strukturada metodlarni qo'llaganimizda, biz 10-11 ro'yxatda ko'rsatilgan generik turdagi parametrlar bilan bir xil sintaksisdan foydalanamiz. Lifetime parametrlarini qayerda e'lon qilishimiz va ishlatishimiz ularning struktura maydonlari yoki metod parametrlari va qaytish(return) qiymatlari bilan bog'liqligiga bog'liq.
Struct maydonlarining lifetime nomlari har doim impl kalit so'zidan keyin e'lon qilinishi va keyin structning nomidan keyin ishlatilishi kerak, chunki bu lifetimelar strukturaning bir qismidir.
impl blokidagi metod signaturelarida referencelar struct maydonlaridagi referencelar lifetimega bog'langan bo'lishi mumkin yoki ular mustaqil bo'lishi mumkin. Bundan tashqari, lifetime elision qoidalari ko'pincha metod signaturelarida lifetime annotationlar kerak bo'lmasligi uchun shunday qiladi. 10-24 ro'yxatda biz aniqlagan ImportantExcerpt nomli strukturadan foydalanib, ba'zi misollarni ko'rib chiqaylik.
Birinchidan, biz daraja deb nomlangan metoddan foydalanamiz, uning yagona parametri self ga reference va qaytariladigan qiymati i32 bo‘lib, hech narsaga reference emas:
struct ImportantExcerpt<'a> { qism: &'a str, } impl<'a> ImportantExcerpt<'a> { fn daraja(&self) -> i32 { 3 } } impl<'a> ImportantExcerpt<'a> { fn qismni_elon_qilish_qaytarih(&self, elon_qilish: &str) -> &str { println!("Diqqat iltimos: {}", elon_qilish); self.qism } } fn main() { let roman = String::from("Meni yaxshi dasturchi edim. Bir necha yil oldin..."); let birinchi_jumla = roman.split('.').next().expect("'.' belgisini topib bo'lmadi."); let i = ImportantExcerpt { qism: birinchi_jumla, }; }
impl dan keyin lifetime parametr deklaratsiyasi va tur nomidan keyin foydalanish talab qilinadi, lekin biz birinchi elision qoida tufayli self ga referencening lifetimeni izohlashimiz shart emas.
Mana uchinchi umr bo'yi elision qoida qo'llaniladigan misol:
struct ImportantExcerpt<'a> { qism: &'a str, } impl<'a> ImportantExcerpt<'a> { fn daraja(&self) -> i32 { 3 } } impl<'a> ImportantExcerpt<'a> { fn qismni_elon_qilish_qaytarih(&self, elon_qilish: &str) -> &str { println!("Diqqat iltimos: {}", elon_qilish); self.qism } } fn main() { let roman = String::from("Meni yaxshi dasturchi edim. Bir necha yil oldin..."); let birinchi_jumla = roman.split('.').next().expect("'.' belgisini topib bo'lmadi."); let i = ImportantExcerpt { qism: birinchi_jumla, }; }
Ikkita kirish(input) lifetime bor, shuning uchun Rust birinchi lifetime elision qoidasini qo'llaydi va &self va elon_qilish ga ham o'z lifetimeni beradi. Keyin, parametrlardan biri &self bo'lgani uchun qaytarish(return) turi &self lifetimeni oladi va barcha lifetimelar hisobga olingan.
Statik Lifetime
Muhokama qilishimiz kerak bo'lgan maxsus lifetime bu 'static bo'lib, bu ta'sirlangan reference dasturning butun muddati davomida yashashi mumkinligini bildiradi. Barcha satr literallari 'static lifetimega ega, biz ularga quyidagicha izoh berishimiz mumkin:
#![allow(unused)] fn main() { let s: &'static str = "Mening statik lifetimem bor."; }
Ushbu satrning matni to'g'ridan-to'g'ri dasturning binary faylida saqlanadi, u har doim mavjud. Shunday qilib, barcha satr literallarining lifetime 'static dir.
Xato xabarlarida 'static lifetimedan foydalanish bo'yicha takliflarni ko'rishingiz mumkin. Biroq, 'static ni referencening lifetime sifatida belgilashdan oldin, sizda mavjud bo'lgan reference haqiqatan ham dasturingizning butun ish vaqti davomida yashaydimi yoki yo'qmi va buni xohlaysizmi, deb o'ylab ko'ring. Ko'pincha, 'static lifetimeni ko'rsatadigan xato xabari dangling reference yaratishga urinish yoki mavjud bo'lgan lifetimelarning mos kelmasligi natijasida paydo bo'ladi. Bunday hollarda, yechim 'static lifetimeni ko'rsatmasdan, bu muammolarni tuzatishdir.
Generik tur parametrlari, Trait boundlar va birgalikdagi lifetime
Keling, generik turdagi parametrlarni, trait boundlarini va lifetimeni bitta funksiyada belgilash sintaksisini qisqacha ko'rib chiqaylik!
fn main() { let string1 = String::from("abcd"); let string2 = "xyz"; let natija = elon_bilan_eng_uzun( string1.as_str(), string2, "Bugun kimningdir tug'ilgan kuni!", ); println!("Eng uzun satr {}", natija); } use std::fmt::Display; fn elon_bilan_eng_uzun<'a, T>( x: &'a str, y: &'a str, ann: T, ) -> &'a str where T: Display, { println!("E'lon! {}", ann); if x.len() > y.len() { x } else { y } }
Bu 10-21 roʻyxatdagi eng_uzun funksiya boʻlib, u ikki qatorning uzunroq qismini qaytaradi. Ammo endi u where bandida ko'rsatilgandek Display traitini amalga oshiradigan har qanday tur tomonidan to'ldirilishi mumkin bo'lgan T generik turidagi ann nomli qo'shimcha parametrga ega. Ushbu qo'shimcha parametr {} yordamida chop etiladi, shuning uchun Display trait boundi(trait chegarasi) zarur. Lifetimelar generik tur bo'lganligi sababli, lifetime parametri 'a va generik turdagi parametr T funksiya nomidan keyin burchakli qavslar ichida bir xil ro'yxatda joylashgan.
Xulosa
Biz ushbu bobda juda ko'p narsalarni ko'rib chiqdik! Endi siz generik(umumiy) turdagi parametrlar, traitlar va trait boundlari(trait chegaralari) va generik lifetime parametrlari haqida bilganingizdan so'ng, siz ko'p turli vaziyatlarda ishlaydigan kodni takrorlashsiz yozishga tayyorsiz. Generik turdagi parametrlar kodni turli turlarga qo'llash imkonini beradi. Traitlar va traitlar boundlari(chegara) turlar generik(umumiy) bo'lsa ham, ular kodga kerak bo'lgan xatti-harakatlarga ega bo'lishini ta'minlaydi. Ushbu moslashuvchan kodda hech qanday dangling referencelar bo'lmasligini ta'minlash uchun lifetime annotationlardan qanday foydalanishni o'rgandingiz. Va bu tahlillarning barchasi kompilyatsiya vaqtida sodir bo'ladi, bu runtimening ishlashiga ta'sir qilmaydi!
Ishoning yoki ishonmang, biz ushbu bobda muhokama qilgan mavzular bo'yicha ko'p narsalarni o'rganishimiz mumkin: 17-bobda traitlardan foydalanishning yana bir usuli bo'lgan trait ob'ektlari muhokama qilinadi. Bundan tashqari,lifetime annotationlarni o'z ichiga olgan murakkab stsenariylar ham mavjud, ular sizga faqat juda ilg'or stsenariylarda kerak bo'ladi; ular uchun siz Rust Reference ni o'qishingiz kerak. Ammo keyin siz Rust-da testlarni qanday yozishni o'rganasiz, shunda kodingiz kerakli tarzda ishlayotganiga ishonch hosil qilishingiz mumkin.
Avtomatlashtirilgan testlarni yozish
Edsger W. Dijkstra o'zining 1972 yildagi "Kamtar dasturchi(The Humble Programmer,)" inshosida "Dasturni sinovdan o'tkazish xatolar(buglar) mavjudligini ko'rsatishning juda samarali usuli bo'lishi mumkin, ammo bu ularning yo'qligini ko'rsatish uchun umidsiz darajada yetarli emas" dedi. Bu biz imkon qadar ko'proq sinab ko'rmasligimiz kerak degani emas!
Bizning dasturlarimizdagi to'g'rilik bizning kodimiz biz rejalashtirgan narsani qanchalik darajada bajarashi. Rust dasturlarning to'g'riligi haqida yuqori darajadagi e'tibor bilan yaratilgan, ammo to'g'riligi murakkab va isbotlash oson emas. Rust turidagi tizim bu yukning katta qismini o'z zimmasiga oladi, ammo turdagi tizim hamma narsani ushlay olmaydi. Shunday qilib, Rust avtomatlashtirilgan dasturiy ta'minot testlarini yozishni qo'llab-quvvatlaydi.
Aytaylik, ikkita_qoshish funksiyasini yozamiz, unga qaysi raqam uzatilsa, unga 2 qo'shiladi. Ushbu funksiya signaturesi integer(butun) sonni parametr sifatida qabul qiladi va natijada butun sonni qaytaradi. Biz ushbu funksiyani amalga oshirganimizda va kompilyatsiya qilganimizda, Rust, masalan, String qiymatini yoki ushbu funksiyaga noto'g'ri referenceni o'tkazmasligimizga ishonch hosil qilish uchun siz hozirgacha o'rgangan barcha turdagi tekshiruvlarni va borrowlarni tekshirishni amalga oshiradi. Ammo Rust bu funksiya biz ko'zlagan narsani aniq bajarishini tekshira olmaydi, ya'ni, masalan, parametr plus 10 yoki minus 50 emas, balki plus 2 parametrini qaytaradi! Bu yerda testlar kiradi.
Biz, masalan, ikkita_qoshish funksiyasiga 3 o'tganimizda, qaytarilgan qiymat 5 bo`lishini tasdiqlovchi testlarni yozishimiz mumkin. Mavjud har qanday to'g'ri xatti-harakat o'zgarmaganligiga ishonch hosil qilish uchun kodimizga o'zgartirish kiritganimizda biz ushbu testlarni bajarishimiz mumkin.
Sinov - bu murakkab mahorat: biz bu bobda yaxshi testlarni qanday yozish haqida har bir tafsilotni yorita olmasak-da, Rustning sinov qurilmalari mexanikasini muhokama qilamiz. Testlarni yozishda sizga mavjud bo'lgan izohlar(annotation) va makroslar, standart xatti-harakatlar va testlarni bajarish uchun taqdim etilgan variantlar, shuningdek, testlarni unit testlari va integratsiya testlariga qanday tashkil qilish haqida gaplashamiz.
Testlarni qanday yozish kerak
Testlar - bu sinovdan tashqari kod kutilgan tarzda ishlayotganligini tasdiqlovchi Rust funksiyalari. Test funksiyalari organlari odatda ushbu uchta harakatni bajaradi:
- Har qanday kerakli ma'lumotlarni yoki holatni o'rnating.
- Test qilmoqchi bo'lgan kodni ishga tushiring.
- Natijalar siz kutgan narsa ekanligini tasdiqlang.
Keling, Rust ushbu amallarni bajaradigan testlarni yozish uchun taqdim etgan xususiyatlarni ko'rib chiqaylik, ular orasida test atributi, bir nechta makroslar va should_panic atributi mavjud.
Test funksiyasining anatomiyasi
Eng sodda qilib aytganda, Rust-dagi test test atributi bilan izohlangan funksiyadir. Atributlar Rust kodining bo'laklari haqidagi metama'lumotlardir; bir misol, biz 5-bobda structlar bilan ishlatgan derive atributidir. Funksiyani test funksiyasiga oʻzgartirish uchun fn oldidan qatorga #[test] qoʻshing. cargo test buyrug'i bilan testlarni o'tkazganingizda, Rust izohli funksiyalarni ishga tushiradigan test dasturining binaryrini yaratadi va har bir test funksiyasidan o'tgan yoki muvaffaqiyatsizligi haqida hisobot beradi.
Har safar biz Cargo bilan yangi kutubxona loyihasini yaratganimizda, biz uchun test funksiyasi bo'lgan test moduli avtomatik ravishda yaratiladi. Ushbu modul sizga testlarni yozish uchun shablonni taqdim etadi, shuning uchun har safar yangi loyihani boshlaganingizda aniq struktura va sintaksisni izlashga hojat qolmaydi. Siz xohlagancha qo'shimcha test funksiyalari va test modullarini qo'shishingiz mumkin!
Har qanday kodni sinab ko'rishdan oldin shablon testi bilan tajriba o'tkazish orqali testlar qanday ishlashining ba'zi jihatlarini o'rganamiz. Keyin biz yozgan ba'zi kodlarni chaqiradigan va uning xatti-harakati to'g'riligini tasdiqlaydigan haqiqiy dunyo testlarini yozamiz.
Keling, ikkita raqamni qo'shadigan qoshuvchi nomli yangi kutubxona loyihasini yarataylik:
$ cargo new qoshuvchi --lib
Created library `qoshuvchi` project
$ cd qoshuvchi
qoshuvchi kutubxonangizdagi src/lib.rs faylining mazmuni 11-1 roʻyxatdagi kabi koʻrinishi kerak.
Fayl nomi: src/lib.rs
#[cfg(test)]
mod tests {
#[test]
fn ishlaydi() {
let natija = 2 + 2;
assert_eq!(natija, 4);
}
}Ro'yxat 11-1: Test moduli va funksiyasi avtomatik ravishda cargo new tomonidan yaratilgan
Hozircha, keling, yuqoridagi ikkita qatorga e'tibor bermaylik va funksiyaga e'tibor qarataylik. #[test] izohiga e'tibor bering: bu atribut bu test funksiyasi ekanligini bildiradi, shuning uchun test ishtirokchisi bu funksiyani test sifatida ko'rishni biladi. Umumiy stsenariylarni oʻrnatish yoki umumiy operatsiyalarni bajarishda yordam beradigan tests modulida testdan tashqari funksiyalar ham boʻlishi mumkin, shuning uchun biz har doim qaysi funksiyalar test ekanligini koʻrsatishimiz kerak.
Misol funksiya tanasi 2 va 2 qo‘shilishi natijasini o‘z ichiga olgan natija 4 ga teng ekanligini tasdiqlash uchun assert_eq! makrosidan foydalanadi. Ushbu tasdiq odatiy test formatiga misol bo'lib xizmat qiladi. Ushbu sinovdan o'tishini ko'rish uchun uni ishga tushiramiz.
cargo test buyrug'i 11-2 ro'yxatda ko'rsatilganidek, loyihamizdagi barcha testlarni amalga oshiradi.
$ cargo test
Compiling qoshuvchi v0.1.0 (file:///projects/qoshuvchi)
Finished test [unoptimized + debuginfo] target(s) in 0.57s
Running unittests src/lib.rs (target/debug/deps/qoshuvchi-92948b65e88960b4)
running 1 test
test tests::ishlaydi ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests qoshuvchi
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Ro'yxat 11-2: Avtomatik ishlab chiqarilgan testni bajarishdan olingan natija
Cargo kompilyatsiya qilindi va sinovdan o'tdi. Biz running 1 test qatorini ko'ramiz. Keyingi qatorda ishlaydi deb nomlangan yaratilgan test funksiyasining nomi va bu testni bajarish natijasi ok ekanligini ko'rsatadi. Umumiy xulosa test natijasi test result: ok. barcha testlardan muvaffaqiyatli oʻtganligini va 1 passed; deb yozilgan qismi muvaffaqiyatli oʻtganligini bildiradi; 0 failed muvaffaqiyatsiz boʻlgan testlar sonini ifodalaydi.
Muayyan misolda ishlamasligi uchun testni e'tiborsiz(ignor) deb belgilash mumkin; Biz buni ushbu bobning keyingi qismida "Agar aniq talab qilinmasa, ba'zi testlarni e'tiborsiz qoldirish" bo'limida ko'rib chiqamiz. Bu yerda biz buni qilmaganimiz sababli, xulosada 0 ignored 0-ta eʼtibor berilmagan koʻrsatiladi. Shuningdek, biz argumentni faqat nomi satrga mos keladigan testlarni o'tkazish uchun cargo test buyrug'iga o'tkazishimiz mumkin; bu filtrlash deb ataladi va biz buni "Testlar to'plamini nomi bo'yicha ishga tushirish" bo'limida ko'rib chiqamiz. Shuningdek, biz bajarilayotgan testlarni filtrlamadik, shuning uchun xulosa oxirida 0 filtered out 0-ta filtrlangan deb ko‘rsatiladi.
0 measured statistikasi samaradorlikni o'lchaydigan benchmark testlari uchundir.
Benchmark testlari, ushbu yozuvdan boshlab, faqat nightly Rust-da mavjud. Batafsil ma'lumot olish uchun benchmark testlari haqidagi hujjatlarga qarang.
Doc-tests adder(Hujjat testlari qoʻshuvchisi) dan boshlanadigan test natijasining keyingi qismi har qanday hujjat sinovlari natijalariga moʻljallangan. Bizda hali hech qanday hujjat sinovlari yo'q, lekin Rust API hujjatlarida ko'rinadigan har qanday kod misollarini to'plashi mumkin.
Bu xususiyat hujjatlaringiz va kodingizni sinxronlashtirishga yordam beradi! Hujjat testlarini qanday yozishni 14-bobning “Hujjatlarga sharhlar test sifatida” bo‘limida muhokama qilamiz. Hozircha biz Doc-tests chiqishini e'tiborsiz qoldiramiz.
Keling, testni o'z ehtiyojlarimizga moslashtirishni boshlaylik. Avval ishlaydi funksiyasining nomini tadqiqot kabi boshqa nomga o'zgartiring, masalan:
Fayl nomi: src/lib.rs
#[cfg(test)]
mod tests {
#[test]
fn tadqiqot() {
assert_eq!(2 + 2, 4);
}
}Keyin yana cargo test bajaring. Chiqish(output) endi ishlaydi o‘rniga tadqiqotni ko‘rsatadi:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.59s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::tadqiqot ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Endi biz yana bir test qo'shamiz, lekin bu safar muvaffaqiyatsiz bo'lgan testni qilamiz! Test funktsiyasidagi biror narsa panic qo'zg'atganda, testlar muvaffaqiyatsiz tugaydi. Har bir test yangi threadda o'tkaziladi va asosiy(main) thread sinov chizig'i o'lganini ko'rsa, test muvaffaqiyatsiz deb belgilanadi. 9-bobda biz panic qo'zg'ashning eng oddiy yo'li panic! makrosini chaqirish haqida gapirdik. Yangi testni boshqa funksiya sifatida kiriting, shunda src/lib.rs faylingiz 11-3 roʻyxatiga oʻxshaydi.
Fayl nomi: src/lib.rs
#[cfg(test)]
mod tests {
#[test]
fn tadqiqot() {
assert_eq!(2 + 2, 4);
}
#[test]
fn boshqa() {
panic!("Ushbu test muvaffaqiyatsizlikka uchradil");
}
}Ro'yxat 11-3: Muvaffaqiyatsiz bo'ladigan ikkinchi testni qo'shish, chunki biz panic! makrosini chaqiramiz.
cargo test yordamida testlarni qaytadan test qiling. Chiqish 11-4 ro'yxatga o'xshash bo'lishi kerak, bu bizning tadqiqot sinovimizdan o'tganligini va boshqa muvaffaqiyatsiz ekanligini ko'rsatadi.
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.72s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test tests::boshqa ... FAILED
test tests::tadqiqot ... ok
failures:
---- tests::boshqa stdout ----
thread 'tests::boshqa' panicked at 'Make this test fail', src/lib.rs:10:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::boshqa
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Ro'yxat 11-4: Bitta test sinovdan o'tgan va bitta test muvaffaqiyatsizlikka uchragan sinov natijalari
OK o'rniga test tests::boshqa qatori FAILEDni koʻrsatadi. Shaxsiy natijalar va xulosa o'rtasida ikkita yangi bo'lim paydo bo'ladi: birinchisida har bir sinov muvaffaqiyatsizligining batafsil sababi ko'rsatiladi. Bunday holda, biz src/lib.rs faylidagi 10-qatordagi panicked at 'Make this test fail' da panic qo'ygani uchun boshqa muvaffaqiyatsizlikka uchraganligi haqidagi tafsilotlarni olamiz. Keyingi bo'limda barcha muvaffaqiyatsiz testlarning nomlari keltirilgan, bu juda ko'p sinovlar va ko'plab batafsil muvaffaqiyatsiz sinov natijalari mavjud bo'lganda foydalidir. Muvaffaqiyatsiz test nomidan uni osonroq debug qilish uchun ishlatishimiz mumkin; testlarni o'tkazish usullari haqida ko'proq "Testlar qanday o'tkazilishini nazorat qilish" section bo'limida gaplashamiz.
Xulosa qatori oxirida ko'rsatiladi: umuman olganda, bizning test natijasimiz FAILED muvaffaqiyatsiz. Bizda bitta test sinovi bor edi va bitta sinov muvaffaqiyatsiz tugadi.
Sinov natijalari turli stsenariylarda qanday ko‘rinishini ko‘rganingizdan so‘ng, keling, testlarda foydali bo‘lgan panic!dan tashqari ba’zi makrolarni ko‘rib chiqaylik.
Natijalarni assert! makrosi bilan tekshirish!
Standart kutubxona tomonidan taqdim etilgan assert! makrosi testdagi baʼzi shartlar true(toʻgʻri) boʻlishini taʼminlashni istasangiz foydali boʻladi. Biz assert! makrosiga mantiqiy(boolean) qiymatga baholovchi argument beramiz. Qiymat true bo'lsa, hech narsa sodir bo'lmaydi va sinovdan o'tadi. Agar qiymat false bo‘lsa, assert! makros testning muvaffaqiyatsiz bo‘lishiga olib kelishi uchun panic! chaqiradi. assert! makrosidan foydalanish bizning kodimiz biz rejalashtirgan tarzda ishlayotganligini tekshirishga yordam beradi.
5-bob, 5-15-ro'yxarda biz 11-5-ro'yxardada takrorlangan Kvadrat strukturasi va ushlab_tur metodidan foydalandik. Keling, ushbu kodni src/lib.rs fayliga joylashtiramiz, so'ngra assert! makrosidan foydalanib, u uchun testlarni yozamiz.
Fayl nomi: src/lib.rs
#[derive(Debug)]
struct Kvadrat {
kenglik: u32,
balandlik: u32,
}
impl Kvadrat {
fn ushlab_tur(&self, boshqa: &Kvadrat) -> bool {
self.kenglik > other.kenglik && self.balandlik > boshqa.balandlik
}
}Ro'yxat 11-5: 5-bobdagi Kvadrat strukturasi va uning ushlab_tur metodidan foydalanish
ushlab_tur metodi mantiqiy(boolean) qiymatini qaytaradi, ya'ni bu assert! makrosi uchun mukammal foydalanish holati. 11-6 ro'yxatda biz kengligi 8 va balandligi 7 bo'lgan Kvadrat misolini yaratish va uning kengligi 5 va balandligi 1 bo'lgan boshqa Kvadrat misolini ushlab turishi mumkinligini tekshirish orqali ushlab_tur metodini bajaradigan testni yozamiz.
Fayl nomi: src/lib.rs
#[derive(Debug)]
struct Kvadrat {
kenglik: u32,
balandlik: u32,
}
impl Kvadrat {
fn ushlab_tur(&self, boshqa: &Kvadrat) -> bool {
self.kenglik > boshqa.kenglik && self.balandlik > boshqa.balandlik
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn katta_kichikni_ushlab_turadi() {
let kattaroq = Kvadrat {
kenglik: 8,
balandlik: 7,
};
let kichikroq = Kvadrat {
kenglik: 5,
balandlik: 1,
};
assert!(kattaroq.ushlab_tur(&kichikroq));
}
}Ro'yxat 11-6: Kattaroq kvadrat haqiqatan ham kichikroq kvadratni sig'dira oladimi yoki yo'qligini tekshiradigan ushlab_tur testi
E'tibor bering, biz tests moduliga yangi qator qo'shdik: use super::*;. tests moduli odatiy modul bo'lib, biz 7-bobda "Modul daraxtidagi elementga murojaat qilish yo'llari" bo'limida ko'rib chiqqan odatiy ko'rinish qoidalariga amal qiladi. tests moduli ichki modul bo'lgani uchun biz tashqi moduldagi sinovdan o'tayotgan kodni ichki modul doirasiga kiritishimiz kerak. Biz bu yerda globdan foydalanamiz, shuning uchun tashqi modulda biz aniqlagan har qanday narsa ushbu tests modulida mavjud bo'ladi.
Biz sinovimizga katta_kichikni_ushlab_turadi deb nom berdik va o‘zimizga kerak bo‘lgan ikkita Kvadrat misolini yaratdik.
Keyin biz assert! makrosini chaqirdik va uni kattaroq.ushlab_tur(&kichikroq) deb chaqirish natijasini berdik. Bu ifoda true ni qaytarishi kerak, shuning uchun testimiz muvaffaqiyatli o'tishi kerak. Keling, bilib olaylik!
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished test [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 1 test
test tests::larger_can_hold_smaller ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests rectangle
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Test muvaffaqiyatli o'tadi! Keling, yana bir sinovni qo'shamiz, bu safar kichikroq kvadrat kattaroq kvadratni ushlab turolmaydi:
Fayl nomi: src/lib.rs
#[derive(Debug)]
struct Kvadrat {
kenglik: u32,
balandlik: u32,
}
impl Kvadrat {
fn ushlab_tur(&self, boshqa: &Kvadrat) -> bool {
self.kenglik > boshqa.kenglik && self.balandlik > boshqa.balandlik
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn katta_kichikni_ushlab_turadi() {
// --snip--
let kattaroq = Kvadrat {
kenglik: 8,
balandlik: 7,
};
let kichikroq = Kvadrat {
kenglik: 5,
balandlik: 1,
};
assert!(kattaroq.ushlab_tur(&kichikroq));
}
#[test]
fn kichik_kattani_ushlolmaydi() {
let kattaroq = Kvadrat {
kenglik: 8,
balandlik: 7,
};
let kichikroq = Kvadrat {
kenglik: 5,
balandlik: 1,
};
assert!(!kichikroq.ushlab_tur(&kattaroq));
}
}Chunki bu holda ushlab_tur funksiyasining to'g'ri natijasi false bo'lsa, biz uni assert! makrosiga o'tkazishdan oldin bu natijani inkor etishimiz kerak. Natijada, agar ushlab_tur false qiymatini qaytarsa, testimiz o'tadi:
$ cargo test
Compiling kvadrat v0.1.0 (file:///projects/kvadrat)
Finished test [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/kvadrat-6584c4561e48942e)
running 2 tests
test tests::katta_kichikni_ushlab_turadi ... ok
test tests::kichik_kattani_ushlolmaydi ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests kvadrat
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Ikkita sinovdan o'tadi! Keling, kodimizga xatolik kiritganimizda test natijalarimiz bilan nima sodir bo'lishini ko'rib chiqaylik. Kengliklarni solishtirganda katta belgisini kichikroq belgisi bilan almashtirish orqali ushlab_tur metodini amalga oshirishni o‘zgartiramiz:
#[derive(Debug)]
struct Kvadrat {
kenglik: u32,
balandlik: u32,
}
// --snip--
impl Kvadrat {
fn ushlab_tur(&self, boshqa: &Kvadrat) -> bool {
self.kenglik < boshqa.kenglik && self.balandlik > boshqa.balandlik
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn katta_kichikni_ushlab_turadi() {
let kattaroq = Kvadrat {
kenglik: 8,
balandlik: 7,
};
let kichikroq = Kvadrat {
kenglik: 5,
balandlik: 1,
};
assert!(kattaroq.ushlab_tur(&kichikroq));
}
#[test]
fn kichik_kattani_ushlolmaydi() {
let kattaroq = Kvadrat {
kenglik: 8,
balandlik: 7,
};
let kichikroq = Kvadrat {
kenglik: 5,
balandlik: 1,
};
assert!(!kichikroq.ushlab_tur(&kattaroq));
}
}Sinovlarni o'tkazish endi quyidagilarga olib keladi:
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished test [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 2 tests
test tests::larger_can_hold_smaller ... FAILED
test tests::smaller_cannot_hold_larger ... ok
failures:
---- tests::larger_can_hold_smaller stdout ----
thread 'tests::larger_can_hold_smaller' panicked at 'assertion failed: larger.can_hold(&smaller)', src/lib.rs:28:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::larger_can_hold_smaller
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Sinovlarimiz xatoni aniqladi! kattaroq.kenglik 8 va kichikroq.kenglik 5 bo'lganligi sababli, ushlab_turda kengliklarni taqqoslash endi falseni qaytaradi: 8 5-dan kichik emas.
Tenglikni assert_eq! va assert_ne! makroslari bilan tekshirish
Funksionallikni tekshirishning keng tarqalgan usuli - bu testdan o'tayotgan kod natijasi va kod qaytarilishini kutayotgan qiymat o'rtasidagi tenglikni tekshirish. Buni assert! makrosidan foydalanib, unga == operatori yordamida ifoda o'tkazishingiz mumkin. Biroq, bu shunday keng tarqalgan testki, standart kutubxona ushbu testni yanada qulayroq bajarish uchun bir juft makros-assert_eq! va assert_ne!-ni taqdim etadi. Ushbu makrolar mos ravishda tenglik yoki tengsizlik uchun ikkita argumentni solishtiradi. Agar tasdiqlash muvaffaqiyatsiz bo'lsa, ular ikkita qiymatni chop etadilar, bu esa nima uchun sinov muvaffaqiyatsiz tugaganini ko'rishni osonlashtiradi; aksincha, assert! makros false qiymatiga olib kelgan qiymatlarni chop etmasdan, == ifodasi uchun false qiymatini olganligini bildiradi.
11-7 ro'yxatda biz o'z parametriga 2 qo'shadigan ikkita_qoshish nomli funksiyani yozamiz, so'ngra bu funksiyani assert_eq! makrosidan foydalanib tekshiramiz.
Fayl nomi: src/lib.rs
pub fn ikkita_qoshish(a: i32) -> i32 {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn ikkita_qosh() {
assert_eq!(4, ikkita_qoshish(2));
}
}Roʻyxat 11-7: assert_eq! makrosidan foydalanib ikkita_qoshish funksiyasini sinab koʻrish
Keling test o'tganligini tekshirib ko'raylik!
$ cargo test
Compiling qoshuvchi v0.1.0 (file:///projects/qoshuvchi)
Finished test [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/qoshuvchi-92948b65e88960b4)
running 1 test
test tests::ikkita_qosh ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests qoshuvchi
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Argument sifatida 4 ni assert_eq!ga o'tkazamiz, bu esa ikkita_qoshish(2) ni chaqirish natijasiga teng. Ushbu test qatori test tests::it_adds_two ... ok va ok matni testimiz muvaffaqiyatli o'tganligini bildiradi!
assert_eq! muvaffaqiyatsiz bo'lganda qanday ko'rinishini ko'rish uchun kodimizga xato kiritamiz. ikkita_qoshish funksiyasining bajarilishini o'rniga 3 qo'shish uchun o`zgartiramiz:
pub fn ikkita_qoshish(a: i32) -> i32 {
a + 3
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn ikkita_qosh() {
assert_eq!(4, ikkita_qoshish(2));
}
}Testlarni qayta ishga tushiring:
$ cargo test
Compiling qoshuvchi v0.1.0 (file:///projects/qoshuvchi)
Finished test [unoptimized + debuginfo] target(s) in 0.61s
Running unittests src/lib.rs (target/debug/deps/qoshuvchi-92948b65e88960b4)
running 1 test
test tests::ikkita_qosh ... FAILED
failures:
---- tests::ikkita_qosh stdout ----
thread 'tests::ikkita_qosh' panicked at 'assertion failed: `(left == right)`
left: `4`,
right: `5`', src/lib.rs:11:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::ikkita_qosh
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Bizning sinovimiz xatoni aniqladi! ikkita_qosh testi muvaffaqiyatsiz tugadi va xabarda muvaffaqiyatsizlikka uchragan tasdiqlash assertion failed: `(left == right)` va left va right qiymatlari nima. Bu xabar nosozliklarni(debugging) tuzatishni boshlashimizga yordam beradi: left(chap) argumenti 4 edi, lekin ikkita_qoshish(2) bo'lgan right(o'ng) argumenti 5 edi. Tasavvur qilishingiz mumkinki, bu bizda juda ko'p sinovlar o'tkazilayotganda ayniqsa foydali bo'ladi.
E'tibor bering, ba'zi dasturlash tillarda va test tizimlarida(framework) tenglikni tasdiqlash funksiyalari parametrlari expected va actual deb nomlanadi va biz argumentlarni ko'rsatish tartibi muhim ahamiyatga ega. Biroq, Rustda ular left va right deb nomlanadi va biz kutgan qiymat va kod ishlab chiqaradigan qiymatni belgilash tartibi muhim emas. Biz ushbu testdagi tasdiqni assert_eq!(ikkita_qoshish(2), 4) deb yozishimiz mumkin, natijada assertion failed: `(left == right)` ko'rsatiladigan bir xil xato xabari paydo bo'ladi.
assert_ne! makros biz bergan ikkita qiymat teng bo'lmasa o'tadi va teng bo'lsa muvaffaqiyatsiz bo'ladi. Ushbu makro biz qiymat nima bo'lishini amin bo'lmagan holatlar uchun juda foydali bo'ladi, lekin biz qiymat nima bo'lmasligi kerakligini bilamiz.
Misol uchun, agar biz biron-bir tarzda uning kiritilishini o'zgartirishi kafolatlangan funksiyani sinab ko'rayotgan bo'lsak, lekin kirishni o'zgartirish metodi testlarimizni o'tkazadigan hafta kuniga bog'liq bo'lsa, tasdiqlash uchun eng yaxshi narsa, funksiyaning chiqishi kirishga teng emasligi bo'lishi mumkin.
Sirt ostida assert_eq! va assert_ne! makroslari mos ravishda == va != operatorlaridan foydalanadi. Tasdiqlar bajarilmasa, bu makroslar debug formati yordamida o‘z argumentlarini chop etadi, ya’ni solishtirilayotgan qiymatlar PartialEq va Debug traitlarini bajarishi kerak. Barcha primitiv turlar va standart kutubxona turlarining aksariyati bu traittlarni amalga oshiradi. O'zingiz belgilagan structlar va enumlar uchun ushbu turlarning tengligini tasdiqlash uchun PartialEq ni qo'llashingiz kerak bo'ladi. Tasdiqlash muvaffaqiyatsizlikka uchraganida qiymatlarni chop etish uchun Debug ni ham qo'llashingiz kerak bo'ladi. 5-bobdagi 5-12 roʻyxatda aytib oʻtilganidek, ikkala trait ham derivable traitli boʻlganligi sababli, bu odatda struct yoki enum taʼrifiga #[derive(PartialEq, Debug)] izohini qoʻshishdek oddiy. Ushbu va boshqa "Derivable Trait"lari haqida batafsil ma'lumot olish uchun C ilovasiga qarang.
Maxsus nosozlik xabarlarini qo'shish
Shuningdek, assert!, assert_eq! va assert_ne! makroslariga ixtiyoriy argumentlar sifatida xato xabari bilan chop etiladigan maxsus xabarni qo'shishingiz mumkin. Kerakli argumentlardan so‘ng ko‘rsatilgan har qanday argumentlar format! makrosiga uzatiladi (8-bobda "+ operatori yoki format! makrosi bilan birlashtirish" bo‘limida muhokama qilingan), shuning uchun siz {} to'ldirgichlar va qiymatlarni o'z ichiga olgan format qatorini o'tkazishingiz mumkin. Maxsus xabarlar tasdiqlash nimani anglatishini hujjatlashtirish uchun foydalidir; test muvaffaqiyatsiz tugagach, kod bilan bog'liq muammo nimada ekanligini yaxshiroq tushunasiz.
Masalan, bizda odamlarni ism bilan kutib oladigan funksiya bor va biz funksiyaga kiritgan ism chiqishda(output) paydo bo‘lishini sinab ko‘rmoqchimiz:
Fayl nomi: src/lib.rs
pub fn salomlashish(name: &str) -> String {
format!("Salom {}!", name)
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn salomlash() {
let natija = salomlashish("Azizbek");
assert!(natija.contains("Azizbek"));
}
}Ushbu dasturga qoʻyiladigan talablar hali kelishib olinmagan va salomlashish boshidagi Salom matni oʻzgarishiga ishonchimiz komil. Talablar o'zgarganda testni yangilashni xohlamasligimizga qaror qildik, shuning uchun salomlashish funksiyasidan qaytarilgan qiymatga aniq tenglikni tekshirish o‘rniga, biz faqat chiqishda kirish parametrining matni borligini tasdiqlaymiz.
Endi standart sinov xatosi qanday koʻrinishini koʻrish uchun nameni chiqarib tashlash uchun salomlashish ni oʻzgartirish orqali ushbu kodga xatolik kiritamiz:
pub fn salomlashish(name: &str) -> String {
String::from("Salom!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn salomlash() {
let natija = salomlashish("Azizbek");
assert!(natija.contains("Azizbek"));
}
}Ushbu testni bajarish quyidagi natijalarni beradi:
$ cargo test
Compiling greeter v0.1.0 (file:///projects/greeter)
Finished test [unoptimized + debuginfo] target(s) in 0.91s
Running unittests src/lib.rs (target/debug/deps/greeter-170b942eb5bf5e3a)
running 1 test
test tests::salomlash ... FAILED
failures:
---- tests::salomlash stdout ----
thread 'tests::salomlash' panicked at 'assertion failed: result.contains(\"Azizbek\")', src/lib.rs:12:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::salomlash
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Bu natija faqat tasdiqlash(assertion) muvaffaqiyatsizligini va tasdiqlash qaysi qatorda ekanligini ko'rsatadi. Foydaliroq xato xabari salomlashish funksiyasidan qiymatni chop etadi. Keling, salomlashish funksiyasidan olingan haqiqiy qiymat bilan toʻldirilgan maxsus xabar to'ldiruvchisi(plaseholder) bilan format qatoridan iborat maxsus xato xabarini qoʻshamiz:
pub fn salomlashish(name: &str) -> String {
String::from("Salom!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn salomlash() {
let natija = salomlashish("Azizbek");
assert!(
natija.contains("Azizbek"),
"Salomlashishda ism yo'q, qiymat `{}` edi",
natija
);
}
}Endi sinovni o'tkazganimizda, biz ko'proq ma'lumot beruvchi xato xabarini olamiz:
$ cargo test
Compiling greeter v0.1.0 (file:///projects/greeter)
Finished test [unoptimized + debuginfo] target(s) in 0.93s
Running unittests src/lib.rs (target/debug/deps/greeter-170b942eb5bf5e3a)
running 1 test
test tests::salomlash ... FAILED
failures:
---- tests::salomlash stdout ----
thread 'tests::salomlash' panicked at 'Greeting did not contain name, value was `Salom!`', src/lib.rs:12:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::salomlash
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Sinov natijasida biz haqiqatda olgan qiymatni ko'rishimiz mumkin, bu biz kutgan narsaning o'rniga nima sodir bo'lganligini aniqlashga yordam beradi.
should_panic yordamida panic tekshirish
Qaytish(return) qiymatlarini tekshirishdan tashqari, bizning kodimiz xato holatlarini biz kutganidek hal qilishini tekshirish muhimdir. Misol uchun, biz 9-bob, 9-13 ro'yxatda yaratgan Taxmin turini ko'rib chiqaylik. Taxmin dan foydalanadigan boshqa kod Taxmin misollarida faqat 1 dan 100 gacha bo'lgan qiymatlarni o'z ichiga olishi kafolatiga bog'liq. Ushbu diapazondan(chegaradan) tashqaridagi qiymatga ega Taxmin misolini yaratishga urinish panic qo'yishini ta'minlaydigan test yozishimiz mumkin.
Buni test funksiyamizga should_panic atributini qo‘shish orqali qilamiz. Funktsiya ichidagi kod panic qo'zg'atsa, test o'tadi;funksiya ichidagi kod panic qo'ymasa, test muvaffaqiyatsiz tugaydi.
11-8 ro'yxatda Taxmin::new xatolik holatlari biz kutgan vaqtda sodir bo'lishini tekshiradigan test ko'rsatilgan.
Fayl nomi: src/lib.rs
pub struct Guess {
value: i32,
}
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 || value > 100 {
panic!("Guess value must be between 1 and 100, got {}.", value);
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic]
fn greater_than_100() {
Guess::new(200);
}
}Ro'yxat 11-8: Test panic! keltirib chiqarishini tekshirish
Biz #[should_panic] atributini #[test] atributidan keyin va u amal qiladigan test funksiyasidan oldin joylashtiramiz. Keling, ushbu testdan o'tgan natijani ko'rib chiqaylik:
$ cargo test
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished test [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::greater_than_100 - should panic ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests guessing_game
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Yaxshi ko'rinadi! Endi shartni olib tashlash orqali kodimizga xatolik kiritamiz,
agar qiymat 100 dan katta bo'lsa, new funksiya panic qo'zg'atadi:
pub struct Taxmin {
qiymat: i32,
}
// --snip--
impl Taxmin {
pub fn new(qiymat: i32) -> Taxmin {
if qiymat < 1 {
panic!("Taxmin qilingan qiymat 1 dan 100 gacha bo'lishi kerak, {} qabul qilinmaydi.", qiymat);
}
Taxmin { qiymat }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic]
fn _100_dan_ortiq() {
Taxmin::new(200);
}
}Sinovni 11-8 ro'yxatda o'tkazganimizda, u muvaffaqiyatsiz bo'ladi:
$ cargo test
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished test [unoptimized + debuginfo] target(s) in 0.62s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::_100_dan_ortiq - should panic ... FAILED
failures:
---- tests::_100_dan_ortiq stdout ----
note: test did not panic as expected
failures:
tests::_100_dan_ortiq
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Biz bu holatda unchalik foydali xabar olmaymiz, lekin test funksiyasini ko‘rib chiqsak, u #[should_panic] bilan izohlanganini ko‘ramiz. Biz erishgan muvaffaqiyatsizlik test funksiyasidagi kod panic qo'zg'atmaganligini anglatadi.
should_panic ishlatadigan testlar noaniq bo'lishi mumkin. Agar test biz kutgandan boshqa sababga ko'ra panic qo'zg'atsa ham, should_panic testi o'tadi. should_panic testlarini aniqroq qilish uchun biz should_panic atributiga ixtiyoriy expected parametrini qo'shishimiz mumkin. Test dasturi xato xabarida taqdim etilgan matn mavjudligiga ishonch hosil qiladi. Masalan, 11-9 ro'yxatdagi Taxmin uchun o'zgartirilgan kodni ko'rib chiqing, bu erda new funksiya qiymat juda kichik yoki juda kattaligiga qarab turli xabarlar bilan panicga tushadi.
Fayl nomi: src/lib.rs
pub struct Guess {
value: i32,
}
// --snip--
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 {
panic!(
"Guess value must be greater than or equal to 1, got {}.",
value
);
} else if value > 100 {
panic!(
"Guess value must be less than or equal to 100, got {}.",
value
);
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic(expected = "less than or equal to 100")]
fn greater_than_100() {
Guess::new(200);
}
}Ro'yxat 11-9: Belgilangan substringni oʻz ichiga olgan panic xabari bilan panic! sinovi
Bu testdan o‘tadi, chunki biz should_panic atributining expected parametriga qo‘ygan qiymat Taxmin::new funksiyasi panicga tushadigan xabarning substringi hisoblanadi. Biz kutgan vahima haqidagi xabarni toʻliq koʻrsatishimiz mumkin edi, bu holda Taxmin qilingan qiymat 1 dan 100 gacha bo'lishi kerak, 200 qabul qilinmaydi.. Siz belgilashni tanlagan narsa panic xabarining qanchalik noyob yoki dinamik ekanligiga va testingiz qanchalik aniq bo'lishini xohlayotganingizga bog'liq. Bunday holda, test funksiyasidagi kod else if qiymat > 100 holatini bajarishini ta`minlash uchun panic xabarining substringi kifoya qiladi.
expected xabari bilan should_panic testi muvaffaqiyatsiz tugashi bilan nima sodir bo'lishini ko'rish uchun if qiymat < 1 va else if qiymat > 100 bloklarini almashtirish orqali kodimizga yana xato kiritamiz:
pub struct Taxmin {
qiymat: i32,
}
impl Taxmin {
pub fn new(qiymat: i32) -> Taxmin {
if qiymat < 1 {
panic!(
"Taxmin qilingan qiymat 1 dan 100 gacha bo'lishi kerak, {} qabul qilinmaydi.",
qiymat
);
} else if qiymat > 100 {
panic!(
"Taxmin qilingan qiymat 1 dan katta yoki teng bo'lishi kerak, {} qabul qilinmaydi.",
qiymat
);
}
Taxmin { qiymat }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic(expected = "100 dan kichik yoki teng")]
fn _100_dan_ortiq() {
Taxmin ::new(200);
}
}Bu safar biz should_panic testini o'tkazsak, u muvaffaqiyatsiz bo'ladi:
$ cargo test
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished test [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::_100_dan_ortiq - should panic ... FAILED
failures:
---- tests::_100_dan_ortiq stdout ----
thread 'tests::_100_dan_ortiq' panicked at 'Taxmin qilingan qiymat 1 dan katta yoki teng bo'lishi kerak, 200 qabul qilinmaydi.', src/lib.rs:13:13
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
note: panic did not contain expected string
panic message: `"Taxmin qilingan qiymat 1 dan katta yoki teng bo'lishi kerak, 200 qabul qilinmaydi."`,
expected substring: `"100 dan kichik yoki teng"`
failures:
tests::_100_dan_ortiq
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Muvaffaqiyatsizlik xabari shuni ko'rsatadiki, bu test biz kutgandek panic qo'zg'atdi, lekin panic xabarida kutilgan Taxmin qilingan qiymat 100 dan kichik yoki unga teng bo'lishi kerak qatori yo'q edi. Bu holatda biz olgan vahima xabari: Taxmin qilingan qiymat 1 dan katta yoki teng bo'lishi kerak, 200 qabul qilinmaydi.. Endi biz xatomiz qayerda ekanligini aniqlashni boshlashimiz mumkin!
Testlarda Result<T, E> dan foydalanish
Bizning testlarimiz muvaffaqiyatsiz bo'lganda panic qo'zg'atadi. Biz Result<T, E> dan foydalanadigan testlarni ham yozishimiz mumkin! 11-1 roʻyxatidagi test Result<T, E> dan foydalanish va panic oʻrniga Errni qaytarish uchun qayta yozilgan:
#[cfg(test)]
mod tests {
#[test]
fn ishlaydi() -> Result<(), String> {
if 2 + 2 == 4 {
Ok(())
} else {
Err(String::from("ikki qo'shish ikki to'rtga teng emas"))
}
}
}ishlaydi funksiyasi endi Result<(), String> qaytish(return) turiga ega. Funksiya tanasida assert_eq! makrosini chaqirishdan ko'ra, testdan o'tganda Ok(()) va test muvaffaqiyatsiz bo'lganda ichida String bilan Errni qaytaramiz.
Testlarni Result<T, E> qaytaradigan qilib yozish testlar matnida savol belgisi operatoridan foydalanish imkonini beradi, bu testlarni yozishning qulay usuli bo'lishi mumkin, agar ulardagi har qanday operatsiya Err variantini qaytarsa, muvaffaqiyatsiz bo'lishi mumkin.
Result<T, E> ishlatadigan testlarda #[should_panic] izohidan(annotation) foydalana olmaysiz. Amaliyot Err variantini qaytarishini tasdiqlash uchun Result<T, E> qiymatida savol belgisi operatoridan foydalanmang. Buning oʻrniga assert!(value.is_err()) dan foydalaning.
Endi siz testlarni yozishning bir necha usullarini bilganingizdan so'ng, keling, testlarimizni o'tkazganimizda nima sodir bo'layotganini ko'rib chiqamiz va cargo test bilan foydalanishimiz mumkin bo'lgan turli xil variantlarni ko'rib chiqamiz.
Testlar qanday o'tkazilishini nazorat qilish
Xuddi cargo run kodingizni kompilyatsiya qilib, natijada olingan binaryni ishga tushirganidek, cargo test kodingizni test rejimida kompilyatsiya qiladi va natijada olingan binary testni ishga tushiradi. cargo test tomonidan ishlab chiqarilgan binary faylning standart xatti-harakati barcha testlarni parallel ravishda bajarish va sinov testlari paytida hosil bo'lgan chiqishni(output) olish, natijaning ko'rsatilishiga yo'l qo'ymaslik va sinov natijalari bilan bog'liq chiqishni o'qishni osonlashtirishdir. Biroq, siz ushbu standart xatti-harakatni o'zgartirish uchun buyruq qatori parametrlarini belgilashingiz mumkin.
Ba'zi buyruq qatori opsiyalari cargo test ga, ba'zilari esa natijada olingan binary testga o'tadi. Ushbu ikki turdagi argumentlarni ajratish uchun siz cargo test ga, so'ngra ajratuvchi -- ga o'tadigan argumentlarni, so'ngra test binarysiga o'tadigan argumentlarni sanab o'tasiz. cargo test --helpni ishga tushirish cargo test bilan foydalanishingiz mumkin bo'lgan variantlarni ko'rsatadi va cargo test -- --helpni ishga tushirish ajratuvchidan(separator) keyin foydalanishingiz mumkin bo'lgan variantlarni ko'rsatadi.
Testlarni parallel yoki ketma-ket bajarish
Bir nechta testlarni bajarganingizda, standart bo'yicha ular threadlar yordamida parallel ravishda ishlaydi, ya'ni ular tezroq ishlashni tugatadi va siz tezroq fikr-mulohaza olasiz. Testlar bir vaqtning o'zida ishlayotganligi sababli, sizning testlaringiz bir-biriga yoki umumiy holatga, jumladan, joriy ishchi jildi yoki muhit o'zgaruvchilari kabi umumiy muhitga bog'liq emasligiga ishonch hosil qilishingiz kerak.
Misol uchun, sizning har bir testingiz diskda test-output.txt nomli fayl yaratadigan va ushbu faylga ba'zi ma'lumotlarni yozadigan ba'zi kodlarni ishga tushiradi. Keyin har bir test ushbu fayldagi ma'lumotlarni o'qiydi va faylda har bir testda har xil bo'lgan ma'lum bir qiymat borligini tasdiqlaydi. Testlar bir vaqtning o'zida bajarilganligi sababli, bitta test faylni boshqa test yozish va o'qish oralig'ida faylni qayta yozishi mumkin. Ikkinchi test kod noto'g'ri bo'lgani uchun emas, balki parallel ravishda ishlayotganda testlar bir-biriga xalaqit bergani uchun muvaffaqiyatsiz bo'ladi. Bitta yechim har bir test boshqa faylga yozishiga ishonch hosil qilishdir; yana bir yechim testlarni birma-bir bajarishdir.
Agar siz testlarni parallel ravishda o'tkazishni xohlamasangiz yoki ishlatilgan threadlar sonini yanada aniqroq nazorat qilishni istasangiz, siz --test threads buyru'gini va foydalanmoqchi bo'lgan threadlar sonini test binaryga yuborishingiz mumkin. Quyidagi misolni ko'rib chiqing:
$ cargo test -- --test-threads=1
Biz dasturga parallelizmdan foydalanmaslikni aytib, test threadlari sonini 1 ga o'rnatdik. Testlarni bitta thread yordamida o'tkazish ularni parallel ravishda bajarishdan ko'ra ko'proq vaqt talab etadi, ammo agar ular umumiy holatga ega bo'lsa, testlar bir-biriga xalaqit bermaydi.
Funktsiya natijalarini ko'rsatish
Odatiy bo'lib, agar testdan o'tgan bo'lsa, Rustning test kutubxonasi standart chiqishda chop etilgan barcha narsalarni yozib oladi. Misol uchun, agar testda println! ni chaqirsak va testdan o'tgan bo'lsa, terminalda println! chiqishini ko'rmaymiz; biz faqat testdan o'tganligini ko'rsatadigan qatorni ko'ramiz. Agar test muvaffaqiyatsiz tugasa, biz xato xabarining qolgan qismi bilan standart chiqishda chop etilganini ko'ramiz.
Misol tariqasida, 11-10 ro'yxatida o'z parametrining qiymatini chop etadigan va 10 ni qaytaradigan ahmoqona funksiya, shuningdek, o'tgan test va muvaffaqiyatsizlikka uchragan test mavjud.
Fayl nomi: src/lib.rs
fn print_qiladi_va_10_qaytaradi(a: i32) -> i32 {
println!("Men {} qiymatini oldim", a);
10
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test_muvaffaqiyatli() {
let qiymat = print_qiladi_va_10_qaytaradi(4);
assert_eq!(10, qiymat);
}
#[test]
fn test_muvaffaqiyatsiz() {
let qiymat = print_qiladi_va_10_qaytaradi(8);
assert_eq!(5, qiymat);
}
}Ro'yxat 11-10: println!ni chaqiruvchi funksiya uchun testlar
Ushbu testlarni cargo test bilan bajarganimizda, biz quyidagi natijani ko'ramiz:
$ cargo test
Compiling silly-function v0.1.0 (file:///projects/silly-function)
Finished test [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/silly_function-160869f38cff9166)
running 2 tests
test tests::test_muvaffaqiyatsiz ... FAILED
test tests::test_muvaffaqiyatli ... ok
failures:
---- tests::test_muvaffaqiyatsiz stdout ----
I got the value 8
thread 'tests::test_muvaffaqiyatsiz' panicked at 'assertion failed: `(left == right)`
left: `5`,
right: `10`', src/lib.rs:19:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::test_muvaffaqiyatsiz
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
E'tibor bering, bu chiqishning hech bir joyida Men 4 qiymatini oldim ni ko'rmaymiz, ya'ni testdan o'tganda chop etiladi. Bu chiqish qo'lga olindi. Muvaffaqiyatsiz bo'lgan test natijasi, Men 8-qiymatni oldim, test xulosasi chiqishi bo'limida paydo bo'ladi, bu test muvaffaqiyatsizligi sababini ham ko'rsatadi.
Agar biz testlardan o'tish uchun yozilgan qiymatlarni ham ko'rishni istasak, Rust-ga --show-output bilan muvaffaqiyatli testlar natijasini ham ko'rsatishni aytishimiz mumkin.
$ cargo test -- --show-output
11-10 ro'yxatdagi testlarni yana --show-output buyrug'i bilan o'tkazganimizda, biz quyidagi natijani ko'ramiz:
$ cargo test -- --show-output
Compiling silly-function v0.1.0 (file:///projects/silly-function)
Finished test [unoptimized + debuginfo] target(s) in 0.60s
Running unittests src/lib.rs (target/debug/deps/silly_function-160869f38cff9166)
running 2 tests
test tests::this_test_will_fail ... FAILED
test tests::this_test_will_pass ... ok
successes:
---- tests::this_test_will_pass stdout ----
I got the value 4
successes:
tests::this_test_will_pass
failures:
---- tests::this_test_will_fail stdout ----
I got the value 8
thread 'tests::this_test_will_fail' panicked at 'assertion failed: `(left == right)`
left: `5`,
right: `10`', src/lib.rs:19:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::this_test_will_fail
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Testlar to'plamini nomi bo'yicha bajarish(ishga tushirish)
Ba'zan to'liq test to'plamini ishga tushirish uzoq vaqt talab qilishi mumkin. Agar siz ma'lum bir sohada kod ustida ishlayotgan bo'lsangiz, faqat ushbu kodga tegishli testlarni o'tkazishni xohlashingiz mumkin. Argument sifatida oʻtkazmoqchi boʻlgan test(lar)ning nomi yoki nomlarini cargo test oʻtish orqali qaysi testlarni oʻtkazishni tanlashingiz mumkin.
Testlar kichik to‘plamini qanday bajarishni ko‘rsatish uchun avval 11-11 ro‘yxatda ko‘rsatilganidek, ikkita_qoshish funksiyamiz uchun uchta test yaratamiz va qaysi birini bajarishni tanlaymiz.
Fayl nomi: src/lib.rs
pub fn ikkita_qoshish(a: i32) -> i32 {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn ikkita_qoshish_va_ikki() {
assert_eq!(4, ikkita_qoshish(2));
}
#[test]
fn uchta_qoshish_va_ikki() {
assert_eq!(5, ikkita_qoshish(3));
}
#[test]
fn yuz() {
assert_eq!(102, ikkita_qoshish(100));
}
}Ro'yxat 11-11: Uch xil nomga ega uchta test
Agar biz testlarni hech qanday argumentlarsiz o'tkazsak, avval ko'rganimizdek, barcha testlar parallel ravishda ishlaydi:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.62s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 3 tests
test tests::uchta_qoshish_va_ikki ... ok
test tests::ikkita_qoshish_va_ikki ... ok
test tests::yuz ... ok
test result: ok. 3 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Yagona testlarni o'tkazish
Biz har qanday test funksiyasining nomini faqat shu testni oʻtkazish uchun cargo testga oʻtkazishimiz mumkin:
$ cargo test yuz
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.69s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::yuz ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 2 filtered out; finished in 0.00s
Faqat yuz nomli test o'tkazildi; qolgan ikkita test bu nomga mos kelmadi. Sinov natijasi, oxirida 2 filtered out belgisini ko‘rsatish orqali bizda boshqa testlar o‘tkazilmaganligini bildiradi.
Biz bir nechta testlarning nomlarini shu tarzda aniqlay olmaymiz; faqat cargo testga berilgan birinchi qiymatdan foydalaniladi. Ammo bir nechta testlarni o'tkazishning bir usuli bor.
Bir nechta testlarni o'tkazish uchun filtrlash
Biz test nomining bir qismini belgilashimiz mumkin va nomi shu qiymatga mos keladigan har qanday test bajariladi. Masalan, ikkita testimiz nomi qoshish ni o‘z ichiga olganligi sababli, biz cargo test qoshish ni ishga tushirish orqali ikkalasini ham ishga tushirishimiz mumkin:
$ cargo test add
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.61s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test tests::uchta_qoshish_va_ikki ... ok
test tests::ikkita_qoshish_va_ikki ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 1 filtered out; finished in 0.00s
Bu buyruq nomidagi qoshish bilan barcha testlarni o'tkazdi va yuz nomli testni filtrladi. Shuni ham yodda tutingki, test paydo bo'ladigan modul test nomining bir qismiga aylanadi, shuning uchun biz modul nomini filtrlash orqali moduldagi barcha testlarni bajarishimiz mumkin.
Maxsus talab qilinmasa, ba'zi testlarni e'tiborsiz qoldirish
Ba'zida bir nechta maxsus testlarni bajarish juda ko'p vaqt talab qilishi mumkin, shuning uchun siz cargo test ning ko'p bosqichlarida ularni istisno qilishingiz mumkin. Siz oʻtkazmoqchi boʻlgan barcha testlarni argument sifatida roʻyxatga olish oʻrniga, bu yerda koʻrsatilganidek, ularni istisno qilish uchun ignore(eʼtibor bermaslik) atributidan foydalanib, vaqt talab qiluvchi testlarga izoh qoʻyishingiz mumkin:
Fayl nomi: src/lib.rs
#[test]
fn ishlamoqda() {
assert_eq!(2 + 2, 4);
}
#[test]
#[ignore]
fn qiyin_test() {
// code that takes an hour to run
}#[test]dan keyin biz chiqarib tashlamoqchi bo'lgan testga #[ignore] qatorini qo'shamiz. Endi testlarimizni o'tkazganimizda, ishlamoqda ishlaydi, lekin qiyin_test ishlamaydi:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.60s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test qiyin_test ... ignored
test ishlamoqda ... ok
test result: ok. 1 passed; 0 failed; 1 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
qiyin_test funksiyasi ignore ro'yxatiga kiritilgan. Agar biz faqat e'tiborga olinmagan(ignor qilingan) testlarni o'tkazmoqchi bo'lsak, biz cargo test -- --ignored dan foydalanishimiz mumkin:
$ cargo test -- --ignored
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.61s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test qiyin_test ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 1 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Qaysi sinovlar o'tkazilishini nazorat qilish orqali siz cargo test natijalari tez bo'lishiga ishonch hosil qilishingiz mumkin. ignored testlar natijalarini tekshirish mantiqiy bo'lgan nuqtada bo'lganingizda va natijalarni kutishga vaqtingiz bo'lsa, uning o'rniga cargo test -- --ignored ni ishga tushirishingiz mumkin. Agar siz barcha testlarni ular e'tiborsiz(ignor) qoldiriladimi yoki yo'qmi, o'tkazmoqchi bo'lsangiz, cargo test -- --include-ignored ni ishga tushirishingiz mumkin.
Test tashkil etish
Bobning boshida aytib o'tilganidek, test murakkab intizom bo'lib, turli odamlar turli terminologiya va tashkilotdan foydalanadilar. Rust hamjamiyati testlarni ikkita asosiy toifaga ko'ra o'ylaydi: birlik testlari(unit test) va integratsiya testlari(integration test). Unit testlari kichikroq va ko'proq yo'naltirilgan bo'lib, bir vaqtning o'zida bitta modulni alohida sinovdan o'tkazadi va private interfeyslarni sinab ko'rishi mumkin. Integratsiya testlari kutubxonangizdan(library) butunlay tashqarida bo'lib, kodingizdan faqat public interfeysdan foydalangan holda va har bir test uchun bir nechta modullardan foydalangan holda boshqa har qanday tashqi kod kabi foydalaning.
Kutubxonangizning qismlari siz kutgan narsani alohida va birgalikda bajarishini ta'minlash uchun ikkala turdagi testlarni yozish muhimdir.
Unit Testlar
Unit testlarining maqsadi kodning qayerda ekanligi va kutilganidek ishlamayotganligini tezda aniqlash uchun kodning har bir birligini(unit) qolgan kodlardan alohida tekshirishdan iborat. Unit testlarini har bir fayldagi src jildiga ular tekshirayotgan kod bilan joylashtirasiz. Konventsiya har bir faylda test funktsiyalarini o'z ichiga olgan tests nomli modul yaratish va modulga cfg(test) bilan izoh berishdan iborat.
Testlar moduli va #[cfg(test)]
Testlar modulidagi #[cfg(test)] izohi Rustga test kodini faqat cargo testni bajarganingizda kompilyatsiya qilishni va ishga tushirishni aytadi, cargo buildni ishga tushirganingizda emas.
Bu siz faqat kutubxona qurmoqchi bo'lganingizda kompilyatsiya vaqtini tejaydi va natijada tuzilgan artefaktda joyni tejaydi, chunki testlar kiritilmagan. Integratsiya testlari boshqa jildga o‘tgani uchun ularga #[cfg(test)] izohi kerak emasligini ko‘rasiz. Biroq, unit testlari kod bilan bir xil fayllarda joylashganligi sababli, ular kompilyatsiya qilingan natijaga kiritilmasligini belgilash uchun #[cfg(test)] dan foydalanasiz.
Eslatib o'tamiz, biz ushbu bobning birinchi qismida yangi qoshuvchi loyihasini yaratganimizda, Cargo biz uchun ushbu kodni yaratdi:
Fayl nomi: src/lib.rs
#[cfg(test)]
mod tests {
#[test]
fn ishlaydi() {
let natija = 2 + 2;
assert_eq!(natija, 4);
}
}Bu kod avtomatik ravishda yaratilgan test modulidir. cfg atributi konfiguratsiya(configuration) degan ma'noni anglatadi va Rustga quyidagi element faqat ma'lum bir konfiguratsiya opsiyasi berilganda kiritilishi kerakligini aytadi. Bunday holda, konfiguratsiya opsiyasi test bo'lib, u Rust tomonidan testlarni kompilyatsiya qilish va ishga tushirish uchun taqdim etiladi. cfg atributidan foydalanib, Cargo bizning test kodimizni faqat cargo test bilan faol ravishda o'tkazganimizdagina kompilyatsiya qiladi. Bunga #[test] bilan izohlangan funksiyalarga qoʻshimcha ravishda ushbu modulda boʻlishi mumkin boʻlgan har qanday yordamchi funksiyalar kiradi.
Private funksiyalarni testdan o'tkazish
Sinov hamjamiyatida private(xususiy) funksiyalarni to'g'ridan-to'g'ri testdan o'tkazish kerakmi yoki yo'qmi degan bahs-munozaralar mavjud va boshqa tillar private funktsiyalarni test qilib ko'rishni qiyinlashtiradi yoki imkonsiz qiladi. Qaysi sinov mafkurasiga rioya qilishingizdan qat'i nazar, Rust maxfiylik qoidalari sizga private funksiyalarni test qilish imkonini beradi.
11-12 roʻyxatdagi kodni ichki_qoshuvchi private funksiyasi bilan koʻrib chiqing.
Fayl nomi: src/lib.rs
pub fn ikkita_qoshish(a: i32) -> i32 {
ichki_qoshuvchi(a, 2)
}
fn ichki_qoshuvchi(a: i32, b: i32) -> i32 {
a + b
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn ichki() {
assert_eq!(4, ichki_qoshuvchi(2, 2));
}
}Ro'yxat 11-12: Private funksiyani test qilib ko'rish
Esda tutingki, ichki_qoshuvchi funksiyasi pub sifatida belgilanmagan. Testlar shunchaki Rust kodi va tests moduli shunchaki boshqa moduldir. "Modul daraxtidagi elementga murojaat qilish yo'llari" bo'limida muhokama qilganimizdek, bolalar modullaridagi elementlar o'zlarining asosiy modullaridagi elementlardan foydalanishlari mumkin. Ushbu testda biz test modulining ota-onasining barcha elementlarini use super::* yordamida qamrab olamiz va keyin test ichki_qoshuvchi ni chaqirishi mumkin. Agar private(shaxsiy) funksiyalarni sinab ko'rish kerak deb o'ylamasangiz, Rustda sizni bunga majbur qiladigan hech narsa yo'q.
Integratsiya testlari
Rust-da integratsiya testlari kutubxonangizdan butunlay tashqarida. Ular kutubxonangizdan boshqa kodlar kabi foydalanadilar, ya'ni ular faqat kutubxonangizning umumiy API qismi bo'lgan funksiyalarni chaqira oladi. Ularning maqsadi kutubxonangizning ko'p qismlari to'g'ri ishlashini tekshirishdir. O'z-o'zidan to'g'ri ishlaydigan kod birliklari integratsiyalashganda muammolarga duch kelishi mumkin, shuning uchun integratsiyalangan kodni sinovdan o'tkazish ham muhimdir. Integratsiya testlarini yaratish uchun sizga birinchi navbatda tests jildi kerak bo'ladi.
tests jildi
Biz loyiha jildimizning yuqori darajasida, src yonida tests jildini yaratamiz. Cargo ushbu jildda integratsiya test fayllarini qidirishni biladi. Keyin biz xohlagancha test fayllarini yaratishimiz mumkin va Cargo har bir faylni alohida crate sifatida tuzadi.
Keling, integratsiya testini yarataylik. 11-12 ro'yxatdagi kod hali ham src/lib.rs faylida bo'lsa, tests jildini yarating va tests/integratsiya_test.rs nomli yangi fayl yarating. Sizning fayl tuzilishingiz tuzilishi quyidagicha ko'rinishi kerak:
qoshuvchi
├── Cargo.lock
├── Cargo.toml
├── src
│ └── lib.rs
└── tests
└── integratsiya_test.rs
11-13 ro'yxatdagi kodni tests/integratsiya_test.rs fayliga kiriting:
Fayl nomi: tests/integration_test.rs
{{#rustdoc_include ../listings/ch11-writing-automated-tests/listing-11-13/tests/integration_test.rs}}Ro'yxat 11-13: qoshuvchi cratesidagi funksiyaning integratsiya testi
tests jildidagi har bir fayl alohida cratedir, shuning uchun biz kutubxonamizni har bir test cratesi doirasiga kiritishimiz kerak. Shuning uchun biz kodning yuqori qismiga unit testlarida kerak bo'lmagan use qoshuvchi ni qo'shamiz.
Bizga tests/integration_test.rs da #[cfg(test)] bilan hech qanday kodga izoh berish shart emas. Cargo tests jildini maxsus ko'rib chiqadi va bu jilddagi fayllarni faqat biz cargo test buyrug'ini ishga tushirganimizda kompilyatsiya qiladi. Keling cargo test qilib ishlatamiz:
$ cargo test
Compiling qoshuvchi v0.1.0 (file:///projects/qoshuvchi)
Finished test [unoptimized + debuginfo] target(s) in 1.31s
Running unittests src/lib.rs (target/debug/deps/qoshuvchi-1082c4b063a8fbe6)
running 1 test
test tests::ichki ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/integratsiya_test.rs (target/debug/deps/integratsiya_test-1082c4b063a8fbe6)
running 1 test
test ikkita_qoshish ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests qoshuvchi
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Chiqishning(output) uchta bo'limiga unit testlari, integratsiya testlari va doc testlari kiradi. E'tibor bering, agar bo'limdagi biron bir test muvaffaqiyatsiz bo'lsa, keyingi bo'limlar bajarilmaydi. Misol uchun, agar unit testi muvaffaqiyatsiz bo'lsa, integratsiya va doc testlari uchun hech qanday natija bo'lmaydi, chunki bu testlar faqat barcha unit testlari o'tgan taqdirdagina amalga oshiriladi.
Unit testlari uchun birinchi bo'lim biz ko'rganimiz bilan bir xil: har bir unit testi uchun bitta satr (biz 11 12 roʻyxatga qoʻshgan ichki deb nomlangan) va keyin unit testlari uchun xulosa qator.
Integratsiya testlari bo'limi Running tests/integration_test.rs qatoridan boshlanadi. Keyin, ushbu integratsiya testidagi har bir test funksiyasi uchun qator va Doc-tests adder boʻlimi boshlanishidan oldin integratsiya testi natijalari uchun xulosa qatori mavjud.
Har bir integratsiya test faylining o'z bo'limi bor, shuning uchun tests jildiga ko'proq fayllar qo'shsak, ko'proq integratsiya test bo'limlari bo'ladi.
cargo test ga argument sifatida test funksiyasining nomini ko‘rsatib, biz hali ham muayyan integratsiya test funksiyasini ishga tushirishimiz mumkin. Muayyan integratsiya test faylida barcha testlarni bajarish uchun cargo testning --test argumentidan keyin fayl nomidan foydalaning:
$ cargo test --test integration_test
Compiling qoshuvchi v0.1.0 (file:///projects/qoshuvchi)
Finished test [unoptimized + debuginfo] target(s) in 0.64s
Running tests/integration_test.rs (target/debug/deps/integration_test-82e7799c1bc62298)
running 1 test
test ikkita_qoshish ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Bu buyruq faqat tests/integration_test.rs faylidagi testlarni bajaradi.
Integratsiya testlarida submodullar
Ko'proq integratsiya testlarini qo'shsangiz, ularni tartibga solishga yordam berish uchun tests jildida ko'proq fayllar yaratishni xohlashingiz mumkin; masalan, siz test funktsiyalarini ular test qilib ko'rayotgan funksiyalari bo'yicha guruhlashingiz mumkin. Yuqorida aytib o'tilganidek, tests jildidagi har bir fayl o'zining alohida cratesi sifatida tuzilgan bo'lib, bu oxirgi foydalanuvchilar sizning cratengizdan qanday foydalanishini yanada yaqinroq taqlid qilish uchun alohida qamrovlarni yaratish uchun foydalidir. Biroq, bu shuni anglatadiki, tests jildidagi fayllar src dagi fayllarga o'xshamaydi, chunki kodni modul va fayllarga qanday ajratish haqida 7-bobda o'rgangansiz.
tests jildidagi fayllarning har xil xatti-harakatlari bir nechta integratsiya test fayllarida foydali bo'ladigan yordamchi funktsiyalar to'plamiga ega bo'lganingizda sezilarli bo'ladi. Aytaylik, siz ularni umumiy modulga chiqarish uchun 7-bob, "Modullarni turli fayllarga ajratish" bosqichlarini bajarishga harakat qilyapsiz. Misol uchun, agar biz tests/common.rs ni yaratsak va unga setup nomli funksiyani joylashtirsak, biz bir nechta test fayllaridagi bir nechta test funksiyalaridan chaqirmoqchi bo'lgan setup ga ba'zi kodlarni qo'shishimiz mumkin:
Fayl nomi: tests/common.rs
pub fn setup() {
// kutubxonangiz testlariga xos sozlash(setup) kodi bu yerga tushadi
}Testlarni qayta ishga tushirganimizda, biz common.rs fayli uchun test chiqishida yangi bo'limni ko'ramiz, garchi bu faylda hech qanday test funksiyalari mavjud bo'lmasa ham, biz hech qanday joydan setup funksiyasini chaqirmagan bo'lsak ham:
$ cargo test
Compiling qoshuvchi v0.1.0 (file:///projects/qoshuvchi)
Finished test [unoptimized + debuginfo] target(s) in 0.89s
Running unittests src/lib.rs (target/debug/deps/qoshuvchi-92948b65e88960b4)
running 1 test
test tests::internal ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/common.rs (target/debug/deps/common-92948b65e88960b4)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/integration_test.rs (target/debug/deps/integration_test-92948b65e88960b4)
running 1 test
test it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests qoshuvchi
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Test natijalarida setup ko'rinishida running 0 tests ko'rsatilishi biz xohlagan narsa emas. Biz shunchaki kodni boshqa integratsiya test fayllari bilan baham ko'rmoqchi edik.
Test natijasida common ko'rinishini oldini olish uchun tests/common.rs yaratish o'rniga biz tests/common/mod.rs ni yaratamiz. Loyiha jildi(fayl structurasi) endi shunday ko'rinadi:
├── Cargo.lock
├── Cargo.toml
├── src
│ └── lib.rs
└── tests
├── common
│ └── mod.rs
└── integration_test.rs
Bu eski nomlash konventsiyasi bo'lib, Rust biz 7-bobning "Muqobil fayl yo'llari(path)" bo'limida aytib o'tganimizni ham tushunadi.
Biz setup funksiya kodini tests/common/mod.rs ga ko'chirsak va tests/common.rs faylini o'chirsak, test chiqishidagi bo'lim endi ko'rinmaydi. tests jildining pastki jildlaridagi fayllar alohida cratelar sifatida kompilyatsiya qilinmaydi yoki test chiqishida(output) bo'limlarga(section) ega emas.
tests/common/mod.rs ni yaratganimizdan so'ng, biz uni modul sifatida har qanday integratsiya test faylidan foydalanishimiz mumkin. Bu yerda tests/integration_test.rs da ikkita_qoshish testidan setup funksiyasini chaqirish misoli keltirilgan:
Fayl nomi: tests/integration_test.rs
use qoshuvchi;
mod common;
#[test]
fn ikkita_qoshish() {
common::setup();
assert_eq!(4, qoshuvchi::ikkita_qosh(2));
}Esda tutingki, mod common; deklaratsiyasi biz 7-21 roʻyxatda koʻrsatgan modul deklaratsiyasi bilan bir xil. Keyin test funksiyasida biz common::setup() funksiyasini chaqirishimiz mumkin.
Binary Cratelar uchun integratsiya testlari
Agar bizning loyihamiz faqat src/main.rs faylini o'z ichiga olgan va src/lib.rs fayliga ega bo'lmagan ikkilik crate(binary crate) bo'lsa, biz tests jildida integratsiya testlarini yarata olmaymiz va src/main.rs faylida belgilangan funksiyalarni use statementi bilan qamrab ololmaymiz. Faqat kutubxona cratelari(library crate) boshqa cratelar foydalanishi mumkin bo'lgan funksiyalarni ko'rsatadi; binary cratelar o'z-o'zidan ishlashi uchun mo'ljallangan.
Bu binary faylni ta'minlovchi Rust loyihalarida src/lib.rs faylida yashovchi logicni chaqiruvchi(call logic) oddiy src/main.rs fayliga ega bo'lishining sabablaridan biri. Ushbu structedan foydalanib, integratsiya testlari kutubxona cratesini muhim funksiyalarni mavjud qilish uchun use bilan sinab ko'rishi mumkin.
Agar muhim funksiya ishlayotgan bo'lsa, src/main.rs faylidagi kichik kod miqdori ham ishlaydi va bu kichik kod miqdorini sinab ko'rish kerak emas.
Xulosa
Rust-ning test xususiyatlari(feature) kod qanday ishlashini belgilash usulini taqdim etadi va u siz kutganingizdek ishlashini ta'minlaydi, hatto siz o'zgartirishlar kiritsangiz ham. Unit testlari kutubxonaning turli qismlarini alohida bajaradi va private impelement qilish tafsilotlarini sinab ko'rishi mumkin. Integratsiya testlari kutubxonaning ko'p qismlari to'g'ri ishlashini tekshiradi va ular tashqi kod uni ishlatadigan tarzda kodni sinab ko'rish uchun kutubxonaning umumiy API'sidan foydalanadilar. Rustning type systemi va ownership qoidalari ba'zi xatolarning oldini olishga yordam bergan bo'lsa ham, testlar sizning kodingiz qanday ishlashi bilan bog'liq bo'lgan mantiqiy xatolarni kamaytirish uchun hali ham muhimdir.
Keling, ushbu bobda va oldingi boblarda olgan bilimlaringizni loyiha ustida ishlash uchun birlashtiraylik!
I/O loyihasi: Buyruqlar qatori dasturini yaratish(command line)
Ushbu bob siz hozirgacha o'rgangan ko'plab ko'nikmalarning qisqacha mazmuni va yana bir nechta standart kutubxona xususiyatlarining o'rganilishidir. Biz hozirda mavjud bo'lgan Rust tushunchalarini mashq qilish uchun fayl va buyruq qatori kiritish/chiqarish(input/output) bilan o'zaro ta'sir qiluvchi buyruq qatori vositasini(command line tool) yaratamiz.
Rust-ning tezligi, xavfsizligi, bitta ikkilik chiqishi(single binary output) va platformalararo9cross-platform qo'llab-quvvatlashi uni buyruqlar qatori vositalarini(command line tools) yaratish uchun ideal tilga aylantiradi, shuning uchun loyihamiz uchun biz klassik buyruq qatori qidiruv vositasi grep ning o'z versiyasini yaratamiz (globally search a regular expression and print) qidirish. Foydalanishning eng oddiy holatida grep belgilangan faylni belgilangan qator uchun qidiradi. Buning uchun grep o'z argumenti sifatida fayl yo'li(file path) va satrni oladi. Keyin u faylni o'qiydi, o'sha faylda string argumentini o'z ichiga olgan qatorlarni topadi va bu satrlarni chop(print qiladi) etadi.
Yo'l davomida biz buyruq qatori vositasini boshqa ko'plab buyruq qatori vositalari ishlatadigan terminal xususiyatlaridan qanday foydalanishni ko'rsatamiz. Biz foydalanuvchiga vositamizning harakatini sozlash imkonini berish uchun atrof-muhit o'zgaruvchisining qiymatini(environment variable) o'qiymiz.
Shuningdek, biz xato xabarlarini standart chiqish (stdout) o'rniga standart xato konsoli oqimiga (stderr) chop qilamiz, shuning uchun, masalan, foydalanuvchi ekranda xato xabarlarini ko'rayotganda muvaffaqiyatli chiqishni faylga yo'naltirishi mumkin.
Rust hamjamiyatining bir a'zosi Andrew Gallant allaqachon grep ning ripgrep deb nomlangan to'liq xususiyatli, juda tez versiyasini yaratgan. Taqqoslash uchun, bizning versiyamiz ancha sodda bo'ladi, ammo bu bob sizga ripgrep kabi real loyihani tushunish uchun zarur bo'lgan asosiy bilimlarni beradi.
Bizning grep loyihamiz siz hozirgacha o'rgangan bir qator tushunchalarni birlashtiradi:
- Kodni tashkil qilish (7-bobda modullar haqida bilib olganlaringizdan foydalangan holda)
- Vectorlar va stringlardan foydalanish (to'plamlar(collection), 8-bob)
- Xatolarni qayta ishlash(handling error) (9-bob)
- Kerakli hollarda traitlar va lifetimelardan foydalanish (10-bob)
- Testlar yozish (11-bob)
Shuningdek, biz 13 va 17-boblarda batafsil yoritilgan closurelar, iteratorlar va trait obyektlarini qisqacha tanishtiramiz.
Buyruqlar qatori argumentlarini qabul qilish
Keling, har doimgidek, cargo new bilan yangi loyiha yarataylik. Loyihamizni tizimingizda mavjud boʻlgan grep konsol dasturidan farqlash uchun uni minigrep deb ataymiz.
$ cargo new minigrep
Created binary (application) `minigrep` project
$ cd minigrep
Birinchi vazifa minigrep ni ikkita buyruq qatori argumentlarini qabul qilishdir: fayl yo'li va izlash uchun satr. Ya'ni, biz o'z dasturimizni cargo run bilan ishga tushirishni xohlaymiz, quyidagi argumentlar cargo uchun emas, balki dasturimizga tegishli ekanligini ko'rsatadigan ikkita tire(qo'shaloq chiziq), qidirish uchun satr va qidiruv uchun faylga yo'l. ichida, shunga o'xshash:
$ cargo run -- qidiruv-matni namuna-fayl.txt
Hozirda cargo new tomonidan yaratilgan dastur biz bergan argumentlarni qayta ishlay olmaydi. crates.io-dagi ba'zi mavjud kutubxonalar buyruq qatori argumentlarini qabul qiladigan dastur yozishda yordam berishi mumkin, ammo siz ushbu kontseptsiyani endigina o'rganayotganingiz uchun keling, bu imkoniyatni o'zimiz amalga oshiraylik.
Argument qiymatlarini o'qish
minigrep ga biz o'tadigan buyruq qatori argumentlarining qiymatlarini o'qishni yoqish uchun bizga Rust standart kutubxonasida taqdim etilgan std::env::args funksiyasi kerak bo'ladi. Bu funksiya minigrep ga uzatilgan buyruq qatori argumentlarining iteratorini qaytaradi. Biz iteratorlarni 13-bobda to'liq ko'rib chiqamiz. Hozircha siz iteratorlar haqida faqat ikkita ma'lumotni bilishingiz kerak: iteratorlar bir qator qiymatlarni ishlab chiqaradi va biz uni vector kabi to'plamga(collection) aylantirish uchun iteratorda collect metodini chaqirishimiz mumkin,iterator ishlab chiqaradigan barcha elementlarni o'z ichiga oladi.
12-1 ro'yxatidagi kod minigrep dasturingizga unga berilgan har qanday buyruq qatori argumentlarini o'qish va keyin qiymatlarni vectorga yig'ish imkonini beradi.
Fayl nomi: src/main.rs
use std::env; fn main() { let args: Vec<String> = env::args().collect(); dbg!(args); }
Ro'yxat 12-1: buyruq qatori argumentlarini vectorga yig'ish va ularni chop etish
Birinchidan, biz std::env modulini use statementi bilan qamrab olamiz, shunda uning args funksiyasidan foydalanamiz. std::env::args funksiyasi modullarning ikki darajasida joylashganligiga e'tibor bering. Biz 7-bobda muhokama qilganimizdek, istalgan funksiya bir nechta modulda joylashgan bo‘lsa, biz funksiyani emas, balki ota-modulni qamrab olishni tanladik. Shunday qilib, biz std::env dan boshqa funksiyalardan bemalol foydalanishimiz mumkin. Bu, shuningdek, use std::env::args ni qo‘shib, so‘ngra funksiyani faqat args bilan chaqirishdan ko‘ra kamroq noaniqdir, chunki args joriy modulda aniqlangan funksiya bilan osongina xato qilishi mumkin.
argsfunksiyasi va notog'ri UnicodeE'tibor bering, agar biron bir argumentda noto'g'ri Unicode bo'lsa,
std::env::argspanic qo'zg'atadi. Agar dasturingiz noto'g'ri Unicode o'z ichiga olgan argumentlarni qabul qilishi kerak bo'lsa, o'rnigastd::env::args_osdan foydalaning. Bu funksiyaStringqiymatlari o‘rnigaOsStringqiymatlarini ishlab chiqaruvchi iteratorni qaytaradi. Biz bu yerda soddalik uchunstd::env::argsdan foydalanishni tanladik, chunkiOsStringqiymatlari platformalar uchun farq qiladi va ular bilan ishlashStringqiymatlariga qaraganda murakkabroq.
main ning birinchi qatorida biz env::args deb nomlaymiz va iteratorni iterator tomonidan ishlab chiqarilgan barcha qiymatlarni o'z ichiga olgan vectorga aylantirish uchun darhol collect dan foydalanamiz. Biz ko'p turdagi to'plamlarni(collection) yaratish uchun collect funksiyasidan foydalanishimiz mumkin, shuning uchun biz stringlar vectorini xohlashimizni ko'rsatish uchun args turiga aniq izoh beramiz. Rust-da turlarga juda kamdan-kam izoh qo'yishimiz kerak bo'lsa-da, collect funksiyasi siz tez-tez izohlashingiz kerak bo'lgan funksiyadir, chunki Rust siz xohlagan to'plam turini aniqlay olmaydi.
Nihoyat, debug makrosi yordamida vectorni chop etamiz. Keling, kodni avval argumentsiz, keyin esa ikkita argument bilan ishga tushirishga harakat qilaylik:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.61s
Running `target/debug/minigrep`
[src/main.rs:5] args = [
"target/debug/minigrep",
]
$ cargo run -- anor mevalar
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 1.57s
Running `target/debug/minigrep anor mevalar`
[src/main.rs:5] args = [
"target/debug/minigrep",
"anor",
"mevalar",
]
E'tibor bering, vectordagi birinchi qiymat "target/debug/minigrep" bo'lib, bu bizning ikkilik(binary) faylimiz nomidir. Bu C dagi argumentlar ro'yxatining xatti-harakatiga mos keladi, bu dasturlarga ularni bajarishda chaqirilgan nomdan foydalanishga imkon beradi. Agar siz uni xabarlarda chop qilmoqchi bo'lsangiz yoki dasturni chaqirish uchun qanday buyruq qatori taxalluslari(alias) ishlatilganiga qarab dasturning harakatini o'zgartirmoqchi bo'lsangiz, dastur nomiga kirish ko'pincha qulaydir. Ammo ushbu bobning maqsadlari uchun biz buni e'tiborsiz qoldiramiz va faqat bizga kerak bo'lgan ikkita argumentni saqlaymiz.
Argument qiymatlarini o'zgaruvchilarda saqlash
Dastur hozirda buyruq qatori argumentlari sifatida ko'rsatilgan qiymatlarga kirish imkoniyatiga ega. Endi biz ikkita argumentning qiymatlarini o'zgaruvchilarda saqlashimiz kerak, shuning uchun biz dasturning qolgan qismida qiymatlardan foydalanishimiz mumkin. Biz buni 12-2 ro'yxatda qilamiz.
Fayl nomi: src/main.rs
use std::env;
fn main() {
let args: Vec<String> = env::args().collect();
let sorov = &args[1];
let fayl_yoli = &args[2];
println!("{} qidirilmoqda", sorov);
println!("{} faylida", fayl_yoli);
}Ro'yxat 12-2: So'rov argumenti va fayl yo'li argumentini saqlash uchun o'zgaruvchilar yaratish
Biz vectorni chop etganimizda ko'rganimizdek, dastur nomi vectordagi birinchi qiymatni args[0] oladi, shuning uchun biz 1 indeksidan argumentlarni boshlaymiz. minigrepning birinchi argumenti biz qidirayotgan satrdir, shuning uchun biz birinchi argumentga referenceni sorov o‘zgaruvchisiga qo‘yamiz. Ikkinchi argument fayl yo'li bo'ladi, shuning uchun biz fayl_yoli o'zgaruvchisiga ikkinchi argumentga reference qilamiz.
Kod biz xohlagandek ishlayotganini isbotlash uchun biz ushbu o'zgaruvchilarning qiymatlarini vaqtincha chop qilamiz. test va namuna.txt argumentlari bilan ushbu dasturni qayta ishga tushiramiz:
$ cargo run -- test namuna.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep test sample.txt`
test qidirilmoqda
namuna.txt faylida
Ajoyib, dastur ishlayapti! Bizga kerak bo'lgan argumentlarning qiymatlari to'g'ri o'zgaruvchilarga saqlanmoqda. Keyinchalik ba'zi potentsial noto'g'ri vaziyatlarni hal qilish uchun xatolarni qayta ishlash usullarini qo'shamiz, masalan, foydalanuvchi hech qanday argument keltirmasa; Hozircha biz bu holatni e'tiborsiz qoldiramiz va uning o'rniga fayllarni o'qish imkoniyatlarini qo'shish ustida ishlaymiz.
Faylni o'qish
Endi biz fayl_yoli argumentida koʻrsatilgan faylni oʻqish funksiyasini qoʻshamiz. Birinchidan, uni sinab ko'rish uchun bizga namuna fayli kerak: biz bir nechta takroriy so'zlar bilan bir nechta satrlarda kichik hajmdagi matnli fayldan foydalanamiz. 12-3 ro'yxatda Olma haqida she'r bor, u yaxshi ishlaydi! Loyihangizning root darajasida olma.txt nomli fayl yarating va “Olma” she’rini kiriting.
Fayl nomi: olma.txt
Tanishaylik, men - olma,
Nomimga quloq solma.
Olaver, ikkilanmay,
Ishtahang bo'lsin karnay
Reklamaga hojat yo'q
Ta'mim rosa yoqimli.
Ortganini quritsang,
Qishda yeysan qoqimni
Men sizlarni olmangiz,
Xomligimda olmangiz!
Asilbekga o'xshab so'ng,
Voy qornim deb qolmangiz!
Bog'larda chiroymanda,
Vitaminga boymanda!
Pishganimda yemasangiz,
Qolasizda armonda!
Ro'yxat 12-3: Olma haqidagi she'r yaxshi sinov ishini yaratadi
Matn joyida bo'lgan holda src/main.rs ni tahrirlang va 12-4 ro'yxatda ko'rsatilganidek, faylni o'qish uchun kod qo'shing.
Fayl nomi: src/main.rs
use std::env;
use std::fs;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let sorov = &args[1];
let fayl_yoli = &args[2];
println!("{} qidirilmoqda", sorov);
println!("{} faylida", fayl_yoli);
let tarkib = fs::read_to_string(fayl_yoli)
.expect("Faylni o'qiy olishi kerak edi");
println!("Fayl tarkibi:\n{tarkib}");
}Ro'yxat 12-4: Ikkinchi argument tomonidan ko'rsatilgan fayl mazmunini o'qish
Birinchidan, biz standart kutubxonaning tegishli qismini use statementi bilan keltiramiz: fayllar bilan ishlash uchun bizga std::fs kerak.
main da yangi fs::read_to_string statementi fayl_yolini oladi, bu faylni ochadi va fayl mazmunining std::io::Result<String> ni qaytaradi.
Shundan so'ng, fayl o'qilgandan keyin tarkib qiymatini chop etadigan vaqtinchalik println! statementini yana qo'shamiz, shuning uchun dasturning hozirgacha ishlayotganligini tekshirishimiz mumkin.
Keling, ushbu kodni birinchi buyruq qatori argumenti sifatida istalgan qator bilan ishga tushiramiz (chunki biz hali qidiruv qismini amalga oshirmaganmiz) va ikkinchi argument sifatida olma.txt fayli:
$ cargo run -- men olma.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep the poem.txt`
men qidirilmoqda
olma.txt faylidan
Fayl tarkibi:
Tanishaylik, men - olma,
Nomimga quloq solma.
Olaver, ikiklanmay,
Ishtahang bo'lsin karnay
Reklamaga hojat yo'q
Ta'mim rosa yoqimli.
Ortganini quritsang,
Qishda yeysan qoqimni
Men sizlarni olmangiz,
Xomligimda olmangiz!
Asilbekga o'xshab so'ng,
Voy qornim deb qolmangiz!
Bog'larda chiroymanda,
Vitaminga boymanda!
Pishganimda yemasangiz,
Qolasizda armonda!
Ajoyib! Ushbu kod fayl mazmunini o'qiydi va fayl mazmunini chop etdi. Ammo kodda bir nechta kamchiliklar mavjud. Ayni paytda main funksiya bir nechta mas'uliyatga ega: umuman olganda, har bir funksiya faqat bitta vazifa uchun javobgar bo'lsa, funksiyalar aniqroq va ularni saqlash osonroq bo'ladi. Boshqa muammo shundaki, biz xatolarni imkon qadar yaxshi hal qilmayapmiz. Dastur hali ham kichik, shuning uchun bu kamchiliklar katta muammo emas, lekin dastur o'sib ulg'aygan sayin ularni toza tuzatish qiyinroq bo'ladi. Dasturni ishlab chiqishda refaktorlashni erta boshlash yaxshi amaliyotdir, chunki kichikroq hajmdagi kodlarni qayta ishlash ancha oson. Biz buni keyin qilamiz.
Modullilikni va xatolarni boshqarishni yaxshilash uchun refaktoring
Dasturimizni yaxshilash uchun dastur tuzilishi va uning yuzaga kelishi mumkin bo'lgan xatolarni qanday hal qilishi bilan bog'liq bo'lgan to'rtta muammoni tuzatamiz. Birinchidan, bizning main funksiyamiz endi ikkita vazifani bajaradi: u argumentlarni tahlil qiladi va fayllarni o'qiydi. Dasturimiz o'sib borishi bilan main funksiya boshqaradigan alohida vazifalar soni ortadi. Funksiyaga mas'uliyat yuklagan sari, uning qismlaridan birini buzmasdan fikr yuritish, sinab ko'rish va o'zgartirish qiyinroq bo'ladi. Har bir funksiya bitta vazifa uchun javobgar bo'lishi uchun funksionallikni ajratish yaxshiroqdir.
Bu muammo ikkinchi muammo bilan ham bog'liq: sorov va fayl_yoli bizning dasturimiz uchun konfiguratsiya o'zgaruvchilari bo'lsa-da, dastur mantig'ini bajarish uchun tarkib kabi o'zgaruvchilardan foydalaniladi. main qancha uzun bo'lsa, biz ko'proq o'zgaruvchilarni qamrab olishimiz kerak bo'ladi; bizda qancha ko'p o'zgaruvchilar mavjud bo'lsa, ularning har birining maqsadini kuzatib borish shunchalik qiyin bo'ladi. Maqsadlari aniq bo'lishi uchun konfiguratsiya o'zgaruvchilarini bitta tuzilishga guruhlash yaxshidir.
Uchinchi muammo shundaki, biz faylni o‘qib chiqmaganda xato xabarini chop etish uchun expect tugmasidan foydalanganmiz, biroq xato xabari “Faylni o‘qishi kerak edi” degan yozuvni chiqaradi. Faylni o'qish bir necha usul bilan muvaffaqiyatsiz bo'lishi mumkin: masalan, fayl yetishmayotgan bo'lishi mumkin yoki bizda uni ochishga ruxsat yo'q.
Hozirda, vaziyatdan qat'i nazar, biz hamma narsa uchun bir xil xato xabarini chop qilamiz, bu esa foydalanuvchiga hech qanday ma'lumot bermaydi!
To‘rtinchidan, biz turli xil xatolarni qayta ishlash uchun expect dan qayta-qayta foydalanamiz va agar foydalanuvchi dasturimizni yetarlicha argumentlarni ko'rsatmasdan ishga tushirsa, Rustdan index out of bounds("chegaradan tashqari indeks") xatosini oladi va bu muammoni aniq tushuntirmaydi. Xatolarni qayta ishlash mantig'ini o'zgartirish kerak bo'lsa, kelajakdagi saqlovchilar(maintainerlar) kod bilan maslahatlashish uchun faqat bitta joyga ega bo'lishlari uchun barcha xatolarni qayta ishlash kodi bir joyda bo'lsa yaxshi bo'lar edi. Xatolarni qayta ishlash uchun barcha kodlar bir joyda bo'lsa, biz oxirgi foydalanuvchilarimiz uchun mazmunli bo'lgan xabarlarni chop etishimizni ta'minlaydi.
Keling, loyihamizni qayta tiklash orqali ushbu to'rtta muammoni hal qilaylik.
Binary loyihalar uchun vazifalarni ajratish
Bir nechta vazifalar uchun javobgarlikni main funksiyaga taqsimlashning tashkiliy muammosi ko'plab ikkilik(binary) loyihalar uchun umumiydir. Natijada, Rust hamjamiyati main kattalasha boshlaganda ikkilik dasturning alohida muammolarini ajratish bo'yicha ko'rsatmalar ishlab chiqdi. Bu jarayon quyidagi bosqichlardan iborat:
-
Dasturingizni main.rs va lib.rs ga bo'ling va dasturingiz mantig'ini lib.rs ga o'tkazing.
-
Agar buyruq satrini tahlil qilish mantig'i kichik bo'lsa, u main.rs da qolishi mumkin.
-
Buyruqlar qatorini tahlil qilish mantig'i murakkablasha boshlagach, uni main.rs dan chiqarib, lib.rs ga o'tkazing.
Ushbu jarayondan keyin main funksiyada qoladigan mas'uliyatlar quyidagilar bilan cheklanishi kerak:
- Argument qiymatlari bilan buyruq satrini tahlil qilish mantig'ini chaqirish
- Boshqa har qanday konfiguratsiyani sozlash
- lib.rs da
runfunksiyasini chaqirish runxatoni qaytarsa, xatoni hal qilish
Ushbu pattern vazifalarni ajratish bilan bog'liq: main.rs dasturni ishga tushirishni boshqaradi va lib.rs topshirilgan vazifaning barcha mantig'ini boshqaradi. main funksiyani toʻgʻridan-toʻgʻri test qilib koʻra olmasligingiz sababli, ushbu structura dasturingizning barcha mantig'ini lib.rs funksiyalariga koʻchirish orqali test qilib koʻrish imkonini beradi. main.rs da qolgan kod uni o'qish orqali uning to'g'riligini tekshirish uchun yetarlicha kichik bo'ladi. Keling, ushbu jarayonni kuzatib, dasturimizni qayta ishlaymiz.
Argument tahlilchisini(parser) chiqarish
Argumentlarni tahlil qilish(parsing qilish) funksiyasini main buyruq satrini tahlil qilish mantig'ini src/lib.rs ga ko'chirishga tayyorlash uchun chaqiradigan funksiyaga ajratamiz. Ro'yxat 12-5 main ning yangi boshlanishini ko'rsatadi, u parse_config yangi funksiyasini chaqiradi, biz buni hozircha src/main.rs da aniqlaymiz.
Fayl nomi: src/main.rs
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let (sorov, fayl_yoli) = parse_config(&args);
// --snip--
println!("{} qidirilmoqda", sorov);
println!("{} faylida", fayl_yoli);
let tarkib = fs::read_to_string(fayl_yoli)
.expect("Faylni o'qiy olishi kerak edi");
println!("Fayl tarkibi:\n{tarkib}");
}
fn parse_config(args: &[String]) -> (&str, &str) {
let sorov = &args[1];
let fayl_yoli = &args[2];
(sorov, fayl_yoli)
}Ro'yxat 12-5: main dan parse_config funksiyasini chiqarish
Biz hali ham buyruq qatori argumentlarini vectorga yig‘moqdamiz, lekin 1-indeksdagi argument qiymatini sorov o‘zgaruvchisiga va 2 indeksidagi argument qiymatini main funksiyasi ichidagi fayl_yoli o‘zgaruvchisiga belgilash o‘rniga, butun vectorni parse_config funksiyasiga o‘tkazamiz. Keyin parse_config funksiyasi qaysi argument qaysi o'zgaruvchiga kirishini aniqlaydigan mantiqni ushlab turadi va qiymatlarni mainga qaytaradi. Biz hali ham sorov va fayl_yoli o'zgaruvchilarini mainda yaratamiz, lekin main endi buyruq qatori argumentlari va o'zgaruvchilari qanday mos kelishini aniqlash vazifasiga ega emas.
Ushbu qayta ishlash bizning kichik dasturimiz uchun ortiqcha bo'lib tuyulishi mumkin, ammo biz kichik, bosqichma-bosqich refactoring qilmoqdamiz. Ushbu o'zgartirishni amalga oshirgandan so'ng, argumentni tahlil qilish hali ham ishlayotganligini tekshirish uchun dasturni qayta ishga tushiring. Muammolar yuzaga kelganda sabablarini aniqlashga yordam berish uchun taraqqiyotingizni tez-tez tekshirib turish yaxshidir.
Konfiguratsiya qiymatlarini guruhlash
parse_config funksiyasini yanada yaxshilash uchun yana bir kichik qadam tashlashimiz mumkin.
Ayni paytda biz tupleni qaytarmoqdamiz, lekin keyin darhol bu tupleni yana alohida qismlarga ajratamiz. Bu, ehtimol, bizda hali to'g'ri mavhumlik yo'qligining belgisidir.
Yaxshilash uchun joy borligini ko'rsatadigan yana bir ko'rsatkich parse_config ning config qismidir, bu biz qaytaradigan ikkita qiymat bir-biriga bog'liqligini va ikkalasi ham bitta konfiguratsiya qiymatining bir qismi ekanligini anglatadi. Biz hozirda bu mantiqni ma'lumotlar strukturasida yetkazmayapmiz, bundan tashqari ikkita qiymatni tuplega guruhlash; Buning o'rniga biz ikkita qiymatni bitta strukturaga joylashtiramiz va har bir struktura maydoniga mazmunli nom beramiz. Buni qilish ushbu kodning kelajakdagi saqlovchilariga(maintainerlarga) turli qadriyatlar bir-biriga qanday bog'liqligini va ularning maqsadi nima ekanligini tushunishni osonlashtiradi.
12-6 ro'yxatda parse_config funksiyasining yaxshilanishi ko'rsatilgan.
Fayl nomi: src/main.rs
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = parse_config(&args);
println!("{} qidirilmoqda", config.sorov);
println!("{} faylida", config.fayl_yoli);
let tarkib = fs::read_to_string(config.fayl_yoli)
.expect("Faylni o'qiy olishi kerak edi");
// --snip--
println!("Fayl tarkibi:\n{tarkib}");
}
struct Config {
sorov: String,
fayl_yoli: String,
}
fn parse_config(args: &[String]) -> Config {
let sorov = args[1].clone();
let fayl_yoli = args[2].clone();
Config { sorov, fayl_yoli }
}Ro'yxat 12-6: Config strukturasining namunasini qaytarish uchun parse_config ni qayta tahrirlash
Biz sorov va fayl_yoli nomli maydonlarga ega bo'lishi uchun aniqlangan Config nomli structi qo'shdik. Endi parse_config signaturesi Config qiymatini qaytarishini bildiradi. Biz argsdagi String qiymatlariga reference qilingan satr bo‘laklarini qaytargan parse_config korpusida endi Config ga tegishli String qiymatlarini o‘z ichiga olgan holda belgilaymiz. maindagi args oʻzgaruvchisi argument qiymatlarining owneri(ega) boʻlib, faqat parse_config funksiyasiga ularni borrowga(qarz olish) ruxsat beradi, yaʼni Config args qiymatlariga ownership(egalik) qilmoqchi boʻlsa, Rustning borrowing(qarz olish) qoidalarini buzgan boʻlamiz.
String ma'lumotlarini boshqarishning bir qancha usullari mavjud; Eng oson, garchi unchalik samarasiz bo'lsa ham, route qiymatlar bo'yicha clone metodini chaqirishdir.
Bu Config nusxasi uchun ma'lumotlarning to'liq nusxasini oladi, bu esa satr(string) ma'lumotlariga referenceni saqlashdan ko'ra ko'proq vaqt va xotirani oladi. Biroq, ma'lumotlarni klonlash bizning kodimizni juda sodda qiladi, chunki biz referencelarning lifetimeni(ishlash muddati) boshqarishimiz shart emas; bu holatda, soddalikka erishish uchun ozgina ishlashdan voz kechish foydali savdodir.
clonedan foydalanishning o'zaro kelishuvlariKo'pgina Rustaceanlar orasida
clonedan foydalanish vaqti xarajati tufayli ownership muammolarini hal qilish uchun foydalanmaslik tendentsiyasi mavjud. 13-bobda siz ushbu turdagi vaziyatda samaraliroq usullardan qanday foydalanishni o'rganasiz. Ammo hozircha rivojlanishni davom ettirish uchun bir nechta satrlarni nusxalash ma'qul, chunki siz bu nusxalarni faqat bir marta qilasiz va fayl yo'li va so'rovlar qatori juda kichik. Birinchi o'tishda kodni giperoptimallashtirishga urinishdan ko'ra, biroz samarasiz ishlaydigan dasturga ega bo'lish yaxshiroqdir. Rust bilan tajribangiz ortgan sayin, eng samarali yechimdan boshlash osonroq bo'ladi, ammo hozirchaclonedeb nomlash juda maqbuldir.
Biz mainni yangiladik, shuning uchun u parse_config tomonidan qaytarilgan Config namunasini config nomli o‘zgaruvchiga joylashtiradi va biz avval alohida sorov va fayl_yoli o‘zgaruvchilaridan foydalangan kodni yangiladik, shuning uchun u endi Config strukturasidagi maydonlardan foydalanadi.
Endi bizning kodimiz sorov va fayl_yoli bir-biriga bog'liqligini va ularning maqsadi dastur qanday ishlashini sozlash ekanligini aniqroq bildiradi. Ushbu qiymatlardan foydalanadigan har qanday kod ularni maqsadlari uchun nomlangan maydonlardagi config misolida topishni biladi.
Config uchun konstruktor yaratish
Hozircha biz main dan buyruq qatori argumentlarini tahlil qilish uchun javob beradigan mantiqni chiqarib oldik va uni parse_config funksiyasiga joylashtirdik. Bu bizga sorov va fayl_yoli qiymatlari o'zaro bog'liqligini va bu munosabatlar bizning kodimizda ko'rsatilishi kerakligini ko'rishga yordam berdi. Keyin biz sorov va fayl_yoli ning tegishli maqsadini nomlash va parse_config funksiyasidan qiymatlar nomlarini stuct maydoni nomi sifatida qaytarish uchun Config structini qo'shdik.
Endi parse_config funksiyasining maqsadi Config misolini yaratish bo‘lganligi sababli, biz parse_config ni oddiy funksiyadan Config structi bilan bog'langan new funksiyaga o‘zgartirishimiz mumkin. Ushbu o'zgarish kodni yanada idiomatik qiladi. Biz standart kutubxonada String kabi turlarning namunalarini String::new ni chaqirish orqali yaratishimiz mumkin. Xuddi shunday, parse_configni Config bilan bog‘langan new funksiyaga o‘zgartirib, Config::new ni chaqirish orqali Config misollarini yaratishimiz mumkin bo‘ladi. 12-7 ro'yxat biz qilishimiz kerak bo'lgan o'zgarishlarni ko'rsatadi.
Fayl nomi: src/main.rs
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("{} qidirilmoqda", config.sorov);
println!("{} faylida", config.fayl_yoli);
let tarkib = fs::read_to_string(config.fayl_yoli)
.expect("Faylni o'qiy olishi kerak edi");
println!("Fayl tarkibi:\n{tarkib}");
// --snip--
}
// --snip--
struct Config {
sorov: String,
fayl_yoli: String,
}
impl Config {
fn new(args: &[String]) -> Config {
let sorov = args[1].clone();
let fayl_yoli = args[2].clone();
Config { sorov, fayl_yoli }
}
}Ro'yxat 12-7: parse_config ni Config::new ga o'zgartirish
Biz parse_config deb chaqirgan mainni yangilab, Config::new deb chaqirdik. Biz parse_config nomini new ga o‘zgartirdik va uni new funksiyani Config bilan bog‘laydigan impl blokiga o‘tkazdik. Ishlayotganiga ishonch hosil qilish uchun ushbu kodni qayta kompilyatsiya qilib ko'ring.
Qayta ishlash xatolarini tuzatish
Endi biz xatolarimizni tuzatish ustida ishlaymiz. Eslatib o'tamiz, args vectoridagi qiymatlarga 1 yoki indeks 2 da kirishga urinish vector uchtadan kam elementni o'z ichiga olgan bo'lsa, dastur panic paydo bo'ladi. Dasturni hech qanday argumentlarsiz ishga tushirishga harakat qiling; u shunday ko'rinadi:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep`
thread 'main' panicked at 'index out of bounds: the len is 1 but the index is 1', src/main.rs:27:21
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
index out of bounds: the len is 1 but the index is 1(indeks chegaradan tashqarida: len 1, lekin indeks 1) qatori dasturchilar uchun moʻljallangan xato xabaridir. Bu bizning oxirgi foydalanuvchilarga nima qilish kerakligini tushunishga yordam bermaydi. Keling, buni hozir tuzatamiz.
Xato xabarini yaxshilash
Ro'yxat 12-8da biz new funksiyasiga chek qo'shamiz, bu 1 va 2 indekslarga kirishdan oldin bo'lakning yetarlicha uzunligini tasdiqlaydi. Agar bo'lak yetarlicha uzun bo'lmasa, dastur panic chiqaradi va yaxshiroq xato xabarini ko'rsatadi.
Fayl nomi: src/main.rs
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("{} qidirilmoqda", config.sorov);
println!("{} faylida", config.fayl_yoli);
let tarkib = fs::read_to_string(config.fayl_yoli)
.expect("Faylni o'qiy olishi kerak edi");
println!("Fayl tarkibi:\n{tarkib}");
}
struct Config {
sorov: String,
fayl_yoli: String,
}
impl Config {
// --snip--
fn new(args: &[String]) -> Config {
if args.len() < 3 {
panic!("argumentlar yetarli emas");
}
// --snip--
let sorov= args[1].clone();
let fayl_yoli = args[2].clone();
Config { sorov, fayl_yoli }
}
}Ro'yxat 12-8: Argumentlar soni uchun chek qo'shish
Bu kod biz 9-13 roʻyxatda yozgan Taxmin::new funksiyasiga oʻxshaydi, bu yerda qiymat argumenti amaldagi qiymatlar oraligʻidan tashqarida boʻlganida panic! deb chaqirdik. Bu yerda bir qator qiymatlar mavjudligini tekshirish o‘rniga, biz args uzunligi kamida 3 ekanligini va funksiyaning qolgan qismi ushbu shart bajarilgan deb taxmin qilingan holda ishlashini tekshiramiz. Agar args uchta elementdan kam boʻlsa, bu shart toʻgʻri boʻladi va dasturni darhol tugatish uchun panic! makrosini chaqiramiz.
new da qoʻshimcha bir necha qator kodlar mavjud boʻlsa, keling, xatolik qanday koʻrinishini koʻrish uchun dasturni argumentlarsiz yana ishga tushiramiz:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep`
thread 'main' panicked at 'argumentlar yetarli emas', src/main.rs:26:13
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Bu chiqish yaxshiroq: endi bizda oqilona xato xabari bor. Biroq, bizda foydalanuvchilarga berishni istamaydigan begona ma'lumotlar ham bor. Ehtimol, biz 9-13 roʻyxatda qoʻllagan texnikamizdan foydalanish bu yerda eng yaxshisi emas: panic! chaqiruvi 9-bobda muhokama qilinganidek, foydalanish muammosidan koʻra dasturlash muammosiga koʻproq mos keladi. Buning o'rniga biz 9-bobda o'rgangan boshqa texnikadan foydalanamiz - muvaffaqiyat yoki xatoni ko'rsatadigan Resultni qaytarish.
panic! o‘rniga Resultni qaytarish
Buning o'rniga, muvaffaqiyatli holatda Config misolini o'z ichiga olgan va xatolik holatida muammoni tasvirlaydigan Result qiymatini qaytarishimiz mumkin. Shuningdek, biz funksiya nomini newdan buildga o'zgartiramiz, chunki ko'plab dasturchilar new funksiyalar hech qachon ishlamay qolmasligini kutishadi. Config::build main bilan bog'langanda, muammo borligini bildirish uchun Result turidan foydalanishimiz mumkin.Keyin biz main ni Err variantini panic! chaqiruvi keltirib chiqaradigan thread 'main' va RUST_BACKTRACE haqidagi matnsiz foydalanuvchilarimiz uchun amaliyroq xatoga aylantirishimiz mumkin.
12-9 ro'yxatda biz hozir Config::build deb nomlanayotgan funksiyaning qaytish(result) qiymatiga va Resultni qaytarish uchun zarur bo'lgan funksiyaning tanasiga qilishimiz kerak bo'lgan o'zgarishlar ko'rsatilgan. E'tibor bering, biz mainni ham yangilamagunimizcha, bu kompilyatsiya qilinmaydi, biz buni keyingi ro'yxatda qilamiz.
Fayl nomi: src/main.rs
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("{} qidirilmoqda", config.sorov);
println!("{} faylida", config.fayl_yoli);
let tarkib = fs::read_to_string(config.fayl_yoli)
.expect("Faylni o'qiy olishi kerak edi");
println!("Fayl tarkibi:\n{tarkib}");
}
struct Config {
sorov: String,
fayl_yoli: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("argumentlar yetarli emas");
}
let sorov = args[1].clone();
let fayl_yoli = args[2].clone();
Ok(Config { sorov, fayl_yoli })
}
}Ro'yxat 12-9: Config::build dan Resultni qaytarish
Bizning build funksiyamiz muvaffaqiyatli holatda Config misoli va xato holatida &'static str bilan Resultni qaytaradi. Bizning xato qiymatlarimiz har doim 'static lifetimega ega bo'lgan satr harflari(string literal) bo'ladi. Biz funksiyaning asosiy qismiga ikkita o'zgartirish kiritdik: agar foydalanuvchi yetarli argumentlarni o'tkazmasa, panic! deb chaqirish o'rniga, biz endi Err qiymatini qaytaramiz va Config qaytish(return) qiymatini OK bilan o'rab oldik. Ushbu o'zgarishlar funksiyani yangi turdagi signaturega moslashtiradi.
Config::build dan Err qiymatini qaytarish main funksiyaga build funksiyasidan qaytarilgan Result qiymatini boshqarish imkonini beradi va xato holatida jarayondan tozaroq chiqish imkonini beradi.
Config::build ga murojaat qilish va xatolarni qayta ishlash
Xato holatini hal qilish va foydalanuvchi uchun qulay xabarni chop etish uchun biz 12-10 roʻyxatda koʻrsatilganidek, Config::build tomonidan qaytariladigan Resultni qayta ishlash uchun mainni yangilashimiz kerak. Shuningdek, biz panic! dan nolga teng bo‘lmagan xato kodi bilan buyruq qatori dasturidan chiqish va uning o‘rniga uni qo‘lda amalga oshirish mas’uliyatini o‘z zimmamizga olamiz. Nolga teng bo'lmagan chiqish holati - bu bizning dasturimizni chaqirgan jarayonga dastur xato holati bilan chiqqanligi haqida signal berish uchun konventsiya.
Fayl nomi: src/main.rs
use std::env;
use std::fs;
use std::process;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Argumentlarni tahlil qilish muammosi: {err}");
process::exit(1);
});
// --snip--
println!("{} qidirilmoqda", config.sorov);
println!("{} faylida", config.fayl_yoli);
let tarkib = fs::read_to_string(config.fayl_yoli)
.expect("Faylni o'qiy olishi kerak edi");
println!("Fayl tarkibi:\n{tarkib}");
}
struct Config {
sorov: String,
fayl_yoli: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("argumentlar yetarli emas");
}
let sorov = args[1].clone();
let fayl_yoli = args[2].clone();
Ok(Config { sorov, fayl_yoli })
}
}Ro'yxat 12-10: Agar Config build bo'lmasa, xato kodi bilan chiqish
Ushbu ro'yxatda biz hali batafsil ko'rib chiqmagan metoddan foydalandik: standart kutubxona tomonidan Result<T, E> da aniqlangan unwrap_or_else.
unwrap_or_else dan foydalanish bizga panic! qo'ymaydigan xatoliklarni aniqlash imkonini beradi. Agar Result Ok qiymati bo'lsa, bu metodning harakati unwrap ga o'xshaydi: u Ok o'ralayotgan(wrap) ichki qiymatni qaytaradi. Biroq, agar qiymat Err qiymati bo'lsa, bu metod kodni closure(yopish) ga chaqiradi, bu biz belgilab beradigan anonim funksiya bo'lib, unwrap_or_else ga argument sifatida o'tkazamiz. Biz 13-bobda closure(yopilish)larni batafsil ko'rib chiqamiz. Hozircha siz shuni bilishingiz kerakki, unwrap_or_else Err ning ichki qiymatidan o‘tadi, bu holda biz 12-9-listga qo‘shgan "argumentlar yetarli emas" statik qatori bo‘lib, bizning yopishimiz uchun Vertikal quvurlar(pipe) o'rtasida paydo bo'ladigan Err argumenti. Yopishdagi(closure) kod ishlayotganida err qiymatidan foydalanishi mumkin.
Biz standart kutubxonadan processni qamrab olish uchun yangi use qatorini qo‘shdik. Xato holatida ishga tushiriladigan yopishdagi kod faqat ikkita qatordan iborat: biz err qiymatini chop qilamiz va keyin process::exitni chaqiramiz. process::exit funksiyasi dasturni darhol to'xtatadi va chiqish holati kodi sifatida berilgan raqamni qaytaradi. Bu biz 12-8 roʻyxatda qoʻllagan panic! asosidagi ishlovga oʻxshaydi, ammo biz endi barcha qoʻshimcha natijalarni olmaymiz. Keling, sinab ko'raylik:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/minigrep`
Argumentlarni tahlil qilish muammosi: argumentlar yetarli emas
Ajoyib! Ushbu chiqish bizning foydalanuvchilarimiz uchun juda qulay.
main dan mantiqni ajratib olish
Endi biz konfiguratsiyani tahlil qilishni qayta tiklashni tugatdik, keling, dastur mantig'iga murojaat qilaylik. "Binary loyihalar uchun vazifalarni ajratish" da aytib o'tganimizdek, biz konfiguratsiyani o'rnatish yoki xatolarni qayta ishlash bilan bog'liq bo'lmagan main funksiyadagi barcha mantiqni ushlab turadigan run nomli funksiyani chiqaramiz. Ishimiz tugagach, main qisqa va tekshirish orqali tekshirish oson bo'ladi va biz boshqa barcha mantiqlar uchun testlarni yozishimiz mumkin bo'ladi.
12-11 ro'yxatda ajratilgan run funksiyasi ko'rsatilgan. Hozircha biz funksiyani chiqarishni kichik, bosqichma-bosqich yaxshilashni amalga oshirmoqdamiz. Biz hali ham src/main.rs da funksiyani aniqlayapmiz.
Fayl nomi: src/main.rs
use std::env;
use std::fs;
use std::process;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Argumentlarni tahlil qilish muammosi: {err}");
process::exit(1);
});
println!("{} qidirilmoqda", config.sorov);
println!("{} faylida", config.fayl_yoli);
run(config);
}
fn run(config: Config) {
let tarkib = fs::read_to_string(config.fayl_yoli)
.expect("Faylni o'qiy olishi kerak edi");
println!("Fayl tarkibi:\n{tarkib}");
}
// --snip--
struct Config {
sorov: String,
fayl_yoli: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("argumentlar yetarli emas");
}
let sorov = args[1].clone();
let fayl_yoli = args[2].clone();
Ok(Config { sorov, fayl_yoli })
}
}Ro'yxat 12-11: Dastur mantig'ining qolgan qismini o'z ichiga olgan run funksiyasini chiqarish
run funksiyasi endi faylni o‘qishdan boshlab main dan qolgan barcha mantiqni o‘z ichiga oladi. run funksiyasi argument sifatida Config misolini oladi.
run funksiyasidan xatolarni qaytarish(return)
Qolgan dastur mantigʻi run funksiyasiga ajratilgan boʻlsa, biz 12 9-ro'yxatdagi Config::build bilan qilganimiz kabi, xatolarni boshqarishni yaxshilashimiz mumkin. Dasturni expect deb chaqirish orqali panic qo‘yish o‘rniga, run funksiyasi biror narsa noto‘g‘ri ketganda Result<T, E>ni qaytaradi. Bu bizga foydalanuvchilarga qulay tarzda xatolarni mainga qayta ishlash mantig'ini yanada mustahkamlash imkonini beradi. 12-12 roʻyxatda run signaturesi va asosiy qismiga qilishimiz kerak boʻlgan oʻzgarishlar koʻrsatilgan.
Fayl nomi: src/main.rs
use std::env;
use std::fs;
use std::process;
use std::error::Error;
// --snip--
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Argumentlarni tahlil qilish muammosi: {err}");
process::exit(1);
});
println!("{} qidirilmoqda", config.sorov);
println!("{} faylida", config.fayl_yoli);
run(config);
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let tarkib = fs::read_to_string(config.fayl_yoli)?;
println!("Fayl tarkibi:\n{tarkib}");
Ok(())
}
struct Config {
sorov: String,
fayl_yoli: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("argumentlar yetarli emas");
}
let sorov = args[1].clone();
let fayl_yoli = args[2].clone();
Ok(Config { sorov, fayl_yoli })
}
}Ro'yxat 12-12: run funksiyasini Resultni qaytarish uchun o'zgartirish
Biz bu yerda uchta muhim o'zgarishlarni amalga oshirdik. Birinchidan, biz run funksiyasining qaytish turini Result<(), Box<dyn Error>>ga o'zgartirdik. Bu funksiya avval birlik(binary) turini qaytardi, () va biz buni Ok holatida qaytarilgan qiymat sifatida saqlaymiz.
Xato turi uchun biz trait obyekti Box<dyn Error>dan foydalandik (va biz std::error::Error ni yuqori qismida use statementi bilan qamrab oldik). Biz 17-bobda trait objectlarni ko'rib chiqamiz. Hozircha shuni bilingki, Box<dyn Error> funksiya Error traitini amalga oshiradigan turni qaytarishini bildiradi, lekin qaytariladigan qiymatning qaysi turini belgilashimiz shart emas. Bu bizga turli xil xato holatlarida har xil turdagi xato qiymatlarini qaytarish uchun moslashuvchanlikni beradi. dyn kalit so'zi(keywordi) "dynamic(dinamik)" so'zining qisqartmasi.
Ikkinchidan, biz 9-bobda aytib o'tganimizdek, ? operatori foydasiga expect chaqiruvini olib tashladik. Xatoda panic! o‘rniga, ? murojat qiluvchiga ishlov berish uchun joriy funksiyadan xato qiymatini qaytaradi.
Uchinchidan, run funksiyasi endi muvaffaqiyatli holatda Ok qiymatini qaytaradi.
Biz signatureda run funksiyasining muvaffaqiyat turini () deb e’lon qildik, ya’ni birlik turi qiymatini Ok qiymatiga o‘rashimiz(wrap) kerak. Bu Ok(()) sintaksisi dastlab biroz g‘alati ko‘rinishi mumkin, ammo () dan foydalanish biz runni faqat uning yon ta’siri uchun chaqirayotganimizni bildirishning idiomatik usulidir; u bizga kerakli qiymatni qaytarmaydi.
Ushbu kodni ishga tushirganingizda, u kompilyatsiya qilinadi, lekin ogohlantirishni ko'rsatadi:
$ cargo run men olma.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
warning: unused `Result` that must be used
--> src/main.rs:19:5
|
19 | run(config);
| ^^^^^^^^^^
|
= note: this `Result` may be an `Err` variant, which should be handled
= note: `#[warn(unused_must_use)]` on by default
warning: `minigrep` (bin "minigrep") generated 1 warning
Finished dev [unoptimized + debuginfo] target(s) in 0.71s
Running `target/debug/minigrep the poem.txt`
men qidirilmoqda
olma.txt faylida
Fayl tarkibi:
Tanishaylik, men - olma,
Nomimga quloq solma.
Olaver, ikiklanmay,
Ishtahang bo'lsin karnay
Reklamaga hojat yo'q
Ta'mim rosa yoqimli.
Ortganini quritsang,
Qishda yeysan qoqimni
Men sizlarni olmangiz,
Xomligimda olmangiz!
Asilbekga o'xshab so'ng,
Voy qornim deb qolmangiz!
Bog'larda chiroymanda,
Vitaminga boymanda!
Pishganimda yemasangiz,
Qolasizda armonda!
Rust bizga kodimiz Result qiymatini e'tiborsiz qoldirganligini va Result qiymati xatolik yuz berganligini ko'rsatishi mumkinligini aytadi. Ammo biz xatolik bor yoki yo'qligini tekshirmayapmiz va kompilyator bu yerda xatoliklarni hal qilish uchun kodga ega bo'lishimiz kerakligini eslatadi! Keling, bu muammoni hozir tuzatamiz.
maindagi run dan qaytarilgan xatolarni qayta ishlash
Biz xatolarni tekshirib ko'ramiz va ularni 12-10-sonli ro'yxatdagi Config::build bilan ishlatganimizga o'xshash metod yordamida hal qilamiz, lekin bir oz farq bilan:
Filename: src/main.rs
use std::env;
use std::error::Error;
use std::fs;
use std::process;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Argumentlarni tahlil qilish muammosi: {err}");
process::exit(1);
});
println!("{} qidirilmoqda", config.sorov);
println!("{} faylida", config.fayl_yoli);
if let Err(e) = run(config) {
println!("Dastur xatosi: {e}");
process::exit(1);
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let tarkib = fs::read_to_string(config.fayl_yoli)?;
println!("Fayl tarkibi:\n{tarkib}");
Ok(())
}
struct Config {
sorov: String,
fayl_yoli: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("argumentlar yetarli emas");
}
let sorov = args[1].clone();
let fayl_yoli = args[2].clone();
Ok(Config { sorov, fayl_yoli })
}
}run Err qiymatini qaytaradimi yoki yo‘qligini tekshirish uchun unwrap_or_else o‘rniga if let dan foydalanamiz va agar qaytarsa process::exit(1)ni chaqiramiz. run funksiyasi Config::build Config misolini qaytarganidek, biz unwrapni xohlagan qiymatni qaytarmaydi. Muvaffaqiyatli holatda run () ni qaytargani uchun biz faqat xatoni aniqlash haqida qayg'uramiz, shuning uchun o'ralgan(wrap) qiymatni qaytarish uchun unwrap_or_else shart emas, bu faqat () bo`ladi.
if let va unwrap_or_else funksiyalarining tanasi ikkala holatda ham bir xil: biz xatoni chop qilamiz va chiqamiz.
Kodni kutubxona(library) cratesiga bo'lish
Bizning minigrep loyihamiz hozircha yaxshi ko'rinmoqda! Endi biz src/main.rs faylini ajratamiz va src/lib.rs fayliga bir nechta kodni joylashtiramiz. Shunday qilib, biz kodni sinab ko'rishimiz va kamroq mas'uliyatli src/main.rs fayliga ega bo'lishimiz mumkin.
Keling, main funksiya bo'lmagan barcha kodlarni src/main.rs dan src/lib.rs ga o'tkazamiz:
runfunksiyasi definitioni- Tegishli
usestatementlari Configning definitioniConfig::builddefinitioni
src/lib.rs ning mazmuni 12-13 roʻyxatda koʻrsatilgan signaturelarga ega boʻlishi kerak (qisqalik uchun funksiyalarning qismlarini olib tashladik). E'tibor bering, biz 12-14 ro'yxatdagi src/main.rs ni o'zgartirmagunimizcha, bu kompilyatsiya qilinmaydi.
Fayl nomi: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub sorov: String,
pub fayl_yoli: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
// --snip--
if args.len() < 3 {
return Err("argumentlar yetarli emas");
}
let sorov = args[1].clone();
let fayl_yoli = args[2].clone();
Ok(Config { sorov, fayl_yoli })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
// --snip--
let tarkib = fs::read_to_string(config.fayl_yoli)?;
println!("Fayl tarkibi:\n{tarkib}");
Ok(())
}Ro'yxat 12-13: Config va run ni src/lib.rs ichiga ko'chirish
Biz pub kalit so‘zidan erkin foydalandik: Config da, uning maydonlari va build metodida va run funksiyasida. Endi bizda testdan o'tkazishimiz mumkin bo'lgan ommaviy(public) API mavjud kutubxona cratesi bor!
Endi biz src/lib.rs ga ko'chirilgan kodni 12-14 ro'yxatda ko'rsatilganidek src/main.rs dagi binary crate doirasiga olib kirishimiz kerak.
Fayl nomi: src/main.rs
use std::env;
use std::process;
use minigrep::Config;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Argumentlarni tahlil qilish muammosi: {err}");
process::exit(1);
});
println!("{} qidirilmoqda", config.sorov);
println!("{} faylida", config.fayl_yoli);
if let Err(e) = minigrep::run(config) {
// --snip--
println!("Dastur xatosi: {e}");
process::exit(1);
}
}Ro'yxat 12-14: src/main.rs da minigrep kutubxona cratesidan foydalanish
Kutubxona cratesidan Config turini binary crate ko'lamiga olib kirish uchun use minigrep::Config qatorini qo'shamiz va run funksiyasiga crate nomimiz bilan prefix qo'shamiz. Endi barcha funksiyalar ulanishi va ishlashi kerak. Dasturni cargo run bilan ishga tushiring va hamma narsa to'g'ri ishlashiga ishonch hosil qiling.
Vouv! Bu juda ko'p ish edi, lekin biz kelajakda muvaffaqiyatga erishdik. Endi xatolarni hal qilish ancha oson va biz kodni modulliroq qildik. Deyarli barcha ishlarimiz bundan buyon src/lib.rs da amalga oshiriladi.
Keling, eski kod bilan qiyin bo'lgan, ammo yangi kod bilan oson bo'lgan narsani qilish orqali ushbu yangi modullikdan foydalanaylik: biz bir nechta testlarni yozamiz!
Testga asoslangan ishlab chiqish bilan kutubxonaning funksionalligini rivojlantirish
Endi biz mantiqni src/lib.rs ga chiqardik va argumentlarni yig‘ish va xatolarni qayta ishlashni src/main.rs da qoldirdik, kodimizning asosiy funksionalligi uchun testlarni yozish ancha osonlashdi. Biz turli xil argumentlar bilan funksiyalarni to'g'ridan-to'g'ri chaqirishimiz va buyruq satridan binaryga murojaat qilmasdan qaytish(return) qiymatlarini tekshirishimiz mumkin.
Ushbu bo'limda biz quyidagi bosqichlar bilan test-driven development (TDD) jarayonidan foydalangan holda minigrep dasturiga qidiruv mantig'ini qo'shamiz:
- Muvaffaqiyatsiz bo'lgan testni yozing va siz kutgan sabab tufayli muvaffaqiyatsiz bo'lishiga ishonch hosil qilish uchun uni ishga tushiring.
- Yangi testdan o'tish uchun yetarli kodni yozing yoki o'zgartiring.
- Siz qo'shgan yoki o'zgartirgan kodni qayta tiklang(refaktoring) va testlar o'tishda davom etayotganiga ishonch hosil qiling.
- Repeat from step 1!
Garchi bu dasturiy ta'minotni yozishning ko'p usullaridan biri bo'lsa-da, TDD kod dizaynini boshqarishga yordam beradi. Testdan o'tishni ta'minlaydigan kodni yozishdan oldin testni yozish jarayon davomida yuqori sinov qamrovini saqlashga yordam beradi.
Biz fayl tarkibidagi so'rovlar qatorini qidirishni amalga oshiradigan va so'rovga mos keladigan qatorlar ro'yxatini tuzadigan funksiyani amalga oshirishni sinovdan o'tkazamiz. Biz bu funksiyani qidiruv funksiyasiga qo‘shamiz.
Muvaffaqiyatsiz test yozish
Bizga endi ular kerak emasligi sababli, dasturning harakatini tekshirish uchun foydalanilgan src/lib.rs va src/main.rs dan println! statementlarini olib tashlaymiz. Keyin, src/lib.rs da, 11-bobda qilganimizdek, test funksiyasiga ega tests modulini qo'shing. Test funksiyasi biz qidirish funksiyasiga ega bo'lishini xohlagan xatti-harakatni belgilaydi: u so'rov va izlash uchun matnni oladi va u so'rovni o'z ichiga olgan matndan faqat satrlarni qaytaradi. 12-15 ro'yxatda ushbu test ko'rsatilgan, u hali kompilyatsiya bo'lmaydi.
Fayl nomi: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub sorov: String,
pub fayl_yoli: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("argumentlar yetarli emas");
}
let sorov = args[1].clone();
let fayl_yoli = args[2].clone();
Ok(Config { sorov, fayl_yoli })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let tarkib = fs::read_to_string(config.fayl_yoli)?;
Ok(())
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn birinchi_natija() {
let sorov = "marali";
let tarkib = "\
Rust:
xavfsiz, tez, samarali.
Uchtasini tanlang.";
assert_eq!(vec!["xavfsiz, tez, samarali."], qidiruv(sorov, tarkib));
}
}12-15 roʻyxat: qidiruv funksiyasi uchun muvaffaqiyatsiz test yaratish
Bu test marali qatorini qidiradi.Biz izlayotgan matn uchta qatordan iborat bo‘lib, ulardan faqat bittasi maralini o‘z ichiga oladi (E’tibor bering, qo‘sh qo‘shtirnoqning ochilishidan keyingi teskari chiziq Rustga ushbu satr literalining boshiga yangi qator belgisini qo‘ymaslikni bildiradi). qidiruv funksiyasidan qaytarilgan qiymat faqat biz kutgan qatorni o'z ichiga oladi, deb ta'kidlaymiz.
Biz hali bu testni bajara olmaymiz va uning muvaffaqiyatsizligini kuzata olmaymiz, chunki test hatto kompilyatsiya ham qilmaydi: qidiruv funksiyasi hali mavjud emas! TDD tamoyillariga muvofiq, biz 12-16 roʻyxatda koʻrsatilganidek, har doim boʻsh vektorni qaytaruvchi qidiruv funksiyasining definitionni qoʻshish orqali testni kompilyatsiya qilish va ishga tushirish uchun yetarli kodni qoʻshamiz. Keyin test kompilyatsiya qilinishi va muvaffaqiyatsiz bo'lishi kerak, chunki bo'sh vektor "xavfsiz, tez, samarali." qatorini o'z ichiga olgan vektorga mos kelmaydi.
Fayl nomi: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub sorov: String,
pub fayl_yoli: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("argumentlar yetarli emas");
}
let sorov = args[1].clone();
let fayl_yoli = args[2].clone();
Ok(Config { sorov, fayl_yoli })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let tarkib = fs::read_to_string(config.fayl_yoli)?;
Ok(())
}
pub fn qidiruv<'a>(sorov: &str, tarkib: &'a str) -> Vec<&'a str> {
vec![]
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn birinchi_natija() {
let sorov = "marali";
let tarkib = "\
Rust:
xavfsiz, tez, samarali.
Uchtasini tanlang.";
assert_eq!(vec!["xavfsiz, tez, samarali."], qidiruv(sorov, tarkib));
}
}Ro'yxat 12-16: qidiruv funksiyasini yetarli darajada aniqlash, shuning uchun testimiz kompilyatsiya bo'ladi
E'tibor bering, biz qidiruv signaturesida 'a aniq lifetimeni belgilashimiz va bu lifetimeni tarkib argumenti va qaytarish(return) qiymati bilan ishlatishimiz kerak. 10-bobda esda tutingki, lifetime parametrlari qaysi argumentning lifetime(ishlash muddati) qaytariladigan qiymatning lifetime bilan bog'liqligini belgilaydi. Bunday holda, qaytarilgan vektorda tarkib argumentining bo'laklariga (sorov argumenti o'rniga) reference qiluvchi string bo'laklari bo'lishi kerakligini ko'rsatamiz.
Boshqacha qilib aytganda, biz Rustga aytamizki, qidiruv funksiyasi tomonidan qaytarilgan maʼlumotlar tarkib argumentida qidiruv funksiyasiga oʻtgan maʼlumotlar shuncha vaqtgacha yashaydi. Bu muhim! Murojaatlar haqiqiy bo'lishi uchun bo'laklar(slice) bo'yicha reference qilingan ma'lumotlar ham haqiqiy bo'lishi kerak; agar kompilyator biz tarkib emas, balki sorov ning satr bo'laklarini(string slice) yaratmoqda deb hisoblasa, u xavfsizlik tekshiruvini noto'g'ri bajaradi.
Agar biz lifetime izohlarni(annotation) unutib, ushbu funksiyani kompilyatsiya qilishga harakat qilsak, biz ushbu xatoni olamiz:
$ cargo build
Compiling minigrep v0.1.0 (file:///projects/minigrep)
error[E0106]: missing lifetime specifier
--> src/lib.rs:29:50
|
29 | pub fn qidiruv(sorov: &str, tarkib: &str) -> Vec<&str> {
| ---- ---- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `sorov` or `tarkib`
help: consider introducing a named lifetime parameter
|
29 | pub fn qidiruv<'a>(sorov: &'a str, tarkib: &'a str) -> Vec<&'a str> {
| ++++ ++ ++ ++
For more information about this error, try `rustc --explain E0106`.
error: could not compile `minigrep` (lib) due to previous error
warning: build failed, waiting for other jobs to finish...
error: could not compile `minigrep` (lib test) due to previous error
Rust bizga ikkita argumenning qaysi biri kerakligini bila olmaydi, shuning uchun biz buni aniq aytishimiz kerak. tarkib barcha matnimizni o'z ichiga olgan argument bo'lgani uchun va biz ushbu matnning mos keladigan qismlarini qaytarmoqchi bo'lganimiz sababli, biz tarkib lifetime sintaksisi yordamida qaytarish qiymatiga ulanishi kerak bo'lgan argument ekanligini bilamiz.
Boshqa dasturlash tillari signaturedagi qiymatlarni qaytarish uchun argumentlarni ulashni talab qilmaydi, ammo bu amaliyot vaqt o'tishi bilan osonlashadi. Siz ushbu misolni 10-bobdagi “Ma’lumotnomalarni lifetime bilan tekshirish” bo‘limi bilan solishtirishingiz mumkin.
Endi testni bajaramiz:
$ cargo test -- --show-output
Compiling silly-function v0.1.0 (file:///projects/silly-function)
Finished test [unoptimized + debuginfo] target(s) in 0.60s
Running unittests src/lib.rs (target/debug/deps/silly_function-160869f38cff9166)
running 1 test
test tests::birinchi_natija ... FAILED
successes:
successes:
failures:
---- tests::birinchi_natija stdout ----
thread 'tests::birinchi_natija' panicked at 'assertion failed: `(left == right)`
left: `["xavfsiz, tez, samarali."]`,
right: `[]`', src/lib.rs:46:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::birinchi_natija
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Ajoyib, test biz kutganimizdek muvaffaqiyatsiz tugadi. Keling, testdan o'tamiz!
Testdan o'tish uchun kod yozish
Hozirda testimiz muvaffaqiyatsiz tugadi, chunki biz har doim bo'sh vektorni qaytaramiz. Buni tuzatish va qidiruv ni amalga oshirish uchun dasturimiz quyidagi bosqichlarni bajarishi kerak:
tarkibning har bir satrini takrorlang.- Berilgan satrda siz izlayotgan qator mavjudligini tekshiring.
- Agar shunday bo'lsa, uni biz qaytaradigan qiymatlar ro'yxatiga qo'shing.
- Agar bunday bo'lmasa, hech narsa qilmang.
- Mos keladigan natijalar ro'yxatini qaytaring.
Keling, satrlarni takrorlashdan boshlab, har bir bosqichda ishlaylik.
lines metodi bilan qatorlar bo'ylab takrorlash
Rust 12-17 ro'yxatda ko'rsatilganidek, qulay tarzda lines deb nomlangan satrlarni qatorma-qator takrorlash uchun foydali metodga ega. E'tibor bering, bu hali kompilyatsiya qilinmaydi.
Fayl nomi: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub sorov: String,
pub fayl_yoli: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("argumentlar yetarli emas");
}
let sorov = args[1].clone();
let fayl_yoli = args[2].clone();
Ok(Config { sorov, fayl_yoli })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let tarkib = fs::read_to_string(config.fayl_yoli)?;
Ok(())
}
pub fn qidiruv<'a>(sorov: &str, tarkib: &'a str) -> Vec<&'a str> {
for line in tarkib.lines() {
// do something with line
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn birinchi_natija() {
let sorov = "marali";
let tarkib = "\
Rust:
xavfsiz, tez, samarali.
Uchtasini tanlang.";
assert_eq!(vec!["xavfsiz, tez, samarali."], qidiruv(sorov, tarkib));
}
}Ro'yxat 12-17: tarkibdagi har bir qatorni takrorlash
lines metodi iteratorni qaytaradi.Biz iteratorlar haqida 13-bobda chuqurroq gaplashamiz, lekin esda tutingki, siz iteratordan foydalanishning bunday usulini 3-5-ro'yxatda ko'rgansiz, bu yerda biz to'plamdagi har bir elementda ba'zi kodlarni ishlatish uchun iterator bilan for siklidan foydalanganmiz.
So'rov uchun har bir qatorni qidirish
Keyinchalik, joriy qatorda so'rovlar qatori mavjudligini tekshiramiz. Yaxshiyamki, satrlarda biz uchun buni amalga oshiradigan contains deb nomlangan foydali metod mavjud! 12-18 roʻyxatda koʻrsatilganidek, qidiruv funksiyasidagi contains metodiga murojatni qoʻshing. E'tibor bering, bu hali kompilyatsiya qilinmaydi.
Fayl nomi: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub sorov: String,
pub fayl_yoli: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("argumentlar yetarli emas");
}
let sorov = args[1].clone();
let fayl_yoli = args[2].clone();
Ok(Config { sorov, fayl_yoli })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let tarkib = fs::read_to_string(config.fayl_yoli)?;
Ok(())
}
pub fn qidiruv<'a>(sorov: &str, tarkib: &'a str) -> Vec<&'a str> {
for line in tarkib.lines() {
if line.contains(sorov) {
// do something with line
}
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn birinchi_natija() {
let sorov = "marali";
let tarkib = "\
Rust:
xavfsiz, tez, samarali.
Uchtasini tanlang.";
assert_eq!(vec!["xavfsiz, tez, samarali."], qidiruv(sorov, tarkib));
}
}Ro'yxat 12-18: satrda sorov dagi satr mavjudligini ko'rish uchun funksiya qo'shiladi
Ayni paytda biz funksionallikni yaratmoqdamiz. Uni kompilyatsiya qilish uchun biz funksiya signaturesida ko'rsatganimizdek, tanadan qiymatni qaytarishimiz kerak.
Mos keladigan qatorlarni saqlash
Ushbu funksiyani tugatish uchun bizga qaytarmoqchi bo'lgan mos keladigan satrlarni saqlash metodi kerak. Buning uchun biz for siklidan oldin o'zgaruvchan vector yasashimiz va vectorda lineni saqlash uchun push metodini chaqirishimiz mumkin. for siklidan so'ng, 12-19 ro'yxatda ko'rsatilganidek, vectorni qaytaramiz.
Fayl nomi: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub sorov: String,
pub fayl_yoli: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("argumentlar yetarli emas");
}
let sorov = args[1].clone();
let fayl_yoli = args[2].clone();
Ok(Config { sorov, fayl_yoli })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let tarkib = fs::read_to_string(config.fayl_yoli)?;
Ok(())
}
pub fn qidiruv<'a>(sorov: &str, tarkib: &'a str) -> Vec<&'a str> {
let mut natijalar = Vec::new();
for line in tarkib.lines() {
if line.contains(sorov) {
natijalar.push(line);
}
}
natijalar
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn birinchi_natija() {
let sorov = "marali";
let tarkib = "\
Rust:
xavfsiz, tez, samarali.
Uchtasini tanlang.";
assert_eq!(vec!["xavfsiz, tez, samarali."], qidiruv(sorov, tarkib));
}
}Ro'yxat 12-19: Biz ularni qaytarishimiz uchun mos keladigan satrlarni saqlash
Endi qidiruv funksiyasi faqat sorov ni o'z ichiga olgan qatorlarni qaytarishi kerak va bizning testimiz o'tishi kerak. Keling, testni bajaramiz:
$ cargo test
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished test [unoptimized + debuginfo] target(s) in 0.37s
Running unittests src/lib.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 1 test
test tests::birinchi_natija ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/minigrep-54f36c611e701f9d)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests minigrep
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Testimiz muvaffaqiyatli o'tdi, shuning uchun u ishlayotganini bilamiz!
Shu nuqtada, biz bir xil funksionallikni saqlab qolish uchun testlarni o'tkazgan holda qidiruv funksiyasini amalga oshirishni qayta tiklash imkoniyatlarini ko'rib chiqishimiz mumkin. Qidiruv funksiyasidagi kod juda yomon emas, lekin u iteratorlarning ba'zi foydali xususiyatlaridan foydalanmaydi. Biz 13-bobda ushbu misolga qaytamiz, u yerda iteratorlarni batafsil o'rganamiz va uni qanday yaxshilashni ko'rib chiqamiz.
run funksiyasidagi qidiruv funksiyasidan foydalanish
Endi qidiruv funksiyasi ishlayotgan va testdan o‘tgan bo‘lsa, run funksiyamizdan qidiruv ni chaqirishimiz kerak. Biz config.sorov qiymatini va fayldan o'qiydigan tarkib-ni qidiruv funksiyasiga o'tkazishimiz kerak. Keyin run qidiruvdan qaytarilgan har bir qatorni chop etadi:
Fayl nomi: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub sorov: String,
pub fayl_yoli: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("argumentlar yetarli emas");
}
let sorov = args[1].clone();
let fayl_yoli = args[2].clone();
Ok(Config { sorov, fayl_yoli })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let tarkib = fs::read_to_string(config.fayl_yoli)?;
for line in qidiruv(&config.sorov, &tarkib) {
println!("{line}");
}
Ok(())
}
pub fn qidiruv<'a>(sorov: &str, tarkib: &'a str) -> Vec<&'a str> {
let mut natijalar = Vec::new();
for line in tarkib.lines() {
if line.contains(sorov) {
natijalar.push(line);
}
}
natijalar
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn birinchi_natija() {
let sorov = "marali";
let tarkib = "\
Rust:
xavfsiz, tez, samarali.
Uchtasini tanlang.";
assert_eq!(vec!["xavfsiz, tez, samarali."], qidiruv(sorov, tarkib));
}
}Biz qidiruv dan har bir qatorni qaytarish va uni chop etish uchun for siklidan foydalanmoqdamiz.
Endi butun dastur ishlashi kerak! Keling, buni sinab ko'raylik, avval Olma she'ridagi "karnay" ning aynan bir satrini qaytarishi kerak bo'lgan so'z bilan:
$ cargo run -- karnay olma.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.01s
Running `target/debug/minigrep karnay olma.txt`
Ishtahang bo'lsin karnay
Ajoyib! Keling, bir nechta qatorga mos keladigan so'zni sinab ko'raylik, masalan, "olma":
$ cargo run -- olma olma.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.38s
Running `target/debug/minigrep olma olma.txt`
Tanishaylik, men - olma,
Nomimga quloq solma.
Men sizlarni olmangiz,
Xomligimda olmangiz!
Voy qornim deb qolmangiz!
Va nihoyat, she’rning hech bir joyida bo‘lmagan so‘zni izlaganimizda, masalan, “mashina” kabi satrlar chiqmasligiga ishonch hosil qilaylik:
$ cargo run -- mashina olma.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.01s
Running `target/debug/minigrep mashina olma.txt`
Ajoyib! Biz klassik dasturning o'z mini versiyasini yaratdik va ilovalarni qanday tuzish haqida ko'p narsalarni o'rgandik. Shuningdek, biz faylni kiritish(input) va chiqarish(output), lifetime, test va buyruq satrini tahlil qilish haqida bir oz o'rgandik.
Ushbu loyihani yakunlash uchun biz atrof-muhit(environment) o'zgaruvchilari bilan qanday ishlashni va standart xatoga qanday chop etishni qisqacha ko'rsatamiz, bu ikkalasi ham buyruq qatori dasturlarini yozishda foydalidir..
Environment(atrof-muhit) o'zgaruvchilari bilan ishlash
Biz minigrepni qo‘shimcha xususiyatni qo‘shish orqali yaxshilaymiz: foydalanuvchi environment orqali yoqishi mumkin bo‘lgan katta-kichik harflarni hisobga olmay qidirish imkoniyati.Biz bu xususiyatni buyruq qatori opsiyasiga aylantirishimiz va foydalanuvchilar uni har safar qo‘llashni xohlaganlarida kiritishlarini talab qilishimiz mumkin, lekin buning oʻrniga uni environment qilib, biz foydalanuvchilarga environmentni bir marta oʻrnatish va barcha qidiruvlarini terminal sessiyasida katta-kichik harflarga sezgir boʻlmasligiga ruxsat beramiz.
Katta-kichik harflarni sezmaydigan qidiruv funksiyasi uchun muvaffaqiyatsiz test yozish
Biz birinchi navbatda yangi harflarga_etiborsiz_qidirish funksiyasini qo'shamiz, u muhit o'zgaruvchisi qiymatga ega bo'lganda chaqiriladi. Biz TDD jarayonini kuzatishda davom etamiz, shuning uchun birinchi qadam yana muvaffaqiyatsiz testni yozishdir. Biz yangi harflarga_etiborsiz_qidirish funksiyasi uchun yangi test qo‘shamiz va 12-20 ro‘yxatda ko‘rsatilganidek, ikkita test o‘rtasidagi farqlarni aniqlashtirish uchun eski testimiz nomini birinchi_natija harflarga_etiborliga o‘zgartiramiz.
Fayl nomi: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub sorov : String,
pub fayl_yoli: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("argumentlar yetarli emas");
}
let sorov = args[1].clone();
let fayl_yoli = args[2].clone();
Ok(Config { sorov , fayl_yoli })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let tarkib = fs::read_to_string(config.fayl_yoli)?;
for line in qidiruv(&config.sorov , &tarkib) {
println!("{line}");
}
Ok(())
}
pub fn qidiruv<'a>(sorov : &str, tarkib: &'a str) -> Vec<&'a str> {
let mut natijalar = Vec::new();
for line in tarkib.lines() {
if line.contains(sorov ) {
natijalar.push(line);
}
}
natijalar
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn harflarga_etiborli() {
let sorov = "marali";
let tarkib = "\
Rust:
xavfsiz, tez, samarali.
Uchtasini tanlang.
Duct tape.";
assert_eq!(vec!["xavfsiz, tez, samarali."], qidiruv(sorov , tarkib));
}
#[test]
fn harflarga_etiborsiz() {
let sorov = "rUsT";
let tarkib = "\
Rust:
xavfsiz, tez, samarali.
Uchtasini tanlang.
Menga ishoning.";
assert_eq!(
vec!["Rust:", "Menga ishoning."],
harflarga_etiborsiz_qidirish(sorov , tarkib)
);
}
}Ro'yxat 12-20: Biz qo'shmoqchi bo'lgan katta-kichik harflarni sezgir bo'lmagan funksiya uchun yangi muvaffaqiyatsiz test qo'shish
Note that we’ve edited the old test’s contents too. We’ve added a new line
with the text "Duct tape." using a capital D that shouldn’t match the query
"duct" when we’re searching in a case-sensitive manner. Changing the old test
in this way helps ensure that we don’t accidentally break the case-sensitive
search functionality that we’ve already implemented. This test should pass now
and should continue to pass as we work on the case-insensitive search.
The new test for the case-insensitive search uses "rUsT" as its query. In
the search_case_insensitive function we’re about to add, the query "rUsT"
should match the line containing "Rust:" with a capital R and match the line
"Trust me." even though both have different casing from the query. This is
our failing test, and it will fail to compile because we haven’t yet defined
the search_case_insensitive function. Feel free to add a skeleton
implementation that always returns an empty vector, similar to the way we did
for the search function in Listing 12-16 to see the test compile and fail.
Implementing the search_case_insensitive Function
The search_case_insensitive function, shown in Listing 12-21, will be almost
the same as the search function. The only difference is that we’ll lowercase
the query and each line so whatever the case of the input arguments,
they’ll be the same case when we check whether the line contains the query.
Filename: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
for line in search(&config.query, &contents) {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}Listing 12-21: Defining the search_case_insensitive
function to lowercase the query and the line before comparing them
First, we lowercase the query string and store it in a shadowed variable with
the same name. Calling to_lowercase on the query is necessary so no
matter whether the user’s query is "rust", "RUST", "Rust", or "rUsT",
we’ll treat the query as if it were "rust" and be insensitive to the case.
While to_lowercase will handle basic Unicode, it won’t be 100% accurate. If
we were writing a real application, we’d want to do a bit more work here, but
this section is about environment variables, not Unicode, so we’ll leave it at
that here.
Note that query is now a String rather than a string slice, because calling
to_lowercase creates new data rather than referencing existing data. Say the
query is "rUsT", as an example: that string slice doesn’t contain a lowercase
u or t for us to use, so we have to allocate a new String containing
"rust". When we pass query as an argument to the contains method now, we
need to add an ampersand because the signature of contains is defined to take
a string slice.
Next, we add a call to to_lowercase on each line to lowercase all
characters. Now that we’ve converted line and query to lowercase, we’ll
find matches no matter what the case of the query is.
Let’s see if this implementation passes the tests:
$ cargo test
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished test [unoptimized + debuginfo] target(s) in 1.33s
Running unittests src/lib.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 2 tests
test tests::case_insensitive ... ok
test tests::case_sensitive ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests minigrep
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Great! They passed. Now, let’s call the new search_case_insensitive function
from the run function. First, we’ll add a configuration option to the
Config struct to switch between case-sensitive and case-insensitive search.
Adding this field will cause compiler errors because we aren’t initializing
this field anywhere yet:
Filename: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}We added the ignore_case field that holds a Boolean. Next, we need the run
function to check the ignore_case field’s value and use that to decide
whether to call the search function or the search_case_insensitive
function, as shown in Listing 12-22. This still won’t compile yet.
Filename: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}Listing 12-22: Calling either search or
search_case_insensitive based on the value in config.ignore_case
Finally, we need to check for the environment variable. The functions for
working with environment variables are in the env module in the standard
library, so we bring that module into scope at the top of src/lib.rs. Then
we’ll use the var function from the env module to check to see if any value
has been set for an environment variable named IGNORE_CASE, as shown in
Listing 12-23.
Filename: src/lib.rs
use std::env;
// --snip--
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}Listing 12-23: Checking for any value in an environment
variable named IGNORE_CASE
Here, we create a new variable ignore_case. To set its value, we call the
env::var function and pass it the name of the IGNORE_CASE environment
variable. The env::var function returns a Result that will be the
successful Ok variant that contains the value of the environment variable if
the environment variable is set to any value. It will return the Err variant
if the environment variable is not set.
We’re using the is_ok method on the Result to check whether the environment
variable is set, which means the program should do a case-insensitive search.
If the IGNORE_CASE environment variable isn’t set to anything, is_ok will
return false and the program will perform a case-sensitive search. We don’t
care about the value of the environment variable, just whether it’s set or
unset, so we’re checking is_ok rather than using unwrap, expect, or any
of the other methods we’ve seen on Result.
We pass the value in the ignore_case variable to the Config instance so the
run function can read that value and decide whether to call
search_case_insensitive or search, as we implemented in Listing 12-22.
Let’s give it a try! First, we’ll run our program without the environment
variable set and with the query to, which should match any line that contains
the word “to” in all lowercase:
$ cargo run -- to poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep to poem.txt`
Are you nobody, too?
How dreary to be somebody!
Looks like that still works! Now, let’s run the program with IGNORE_CASE
set to 1 but with the same query to.
$ IGNORE_CASE=1 cargo run -- to poem.txt
If you’re using PowerShell, you will need to set the environment variable and run the program as separate commands:
PS> $Env:IGNORE_CASE=1; cargo run -- to poem.txt
This will make IGNORE_CASE persist for the remainder of your shell
session. It can be unset with the Remove-Item cmdlet:
PS> Remove-Item Env:IGNORE_CASE
We should get lines that contain “to” that might have uppercase letters:
Are you nobody, too?
How dreary to be somebody!
To tell your name the livelong day
To an admiring bog!
Excellent, we also got lines containing “To”! Our minigrep program can now do
case-insensitive searching controlled by an environment variable. Now you know
how to manage options set using either command line arguments or environment
variables.
Some programs allow arguments and environment variables for the same configuration. In those cases, the programs decide that one or the other takes precedence. For another exercise on your own, try controlling case sensitivity through either a command line argument or an environment variable. Decide whether the command line argument or the environment variable should take precedence if the program is run with one set to case sensitive and one set to ignore case.
The std::env module contains many more useful features for dealing with
environment variables: check out its documentation to see what is available.
Xato xabarlarini standart chiqish oqimi o'rniga xato oqimiga yozish
Ayni paytda biz println! funksiyasidan foydalangan holda terminalga barcha
chiqishlarimizni yozib olamiz. Ko'pgina terminallarda ikkita chiqish turi
mavjud: umumiy ma'lumot uchun standart chiqish oqimi ( stdout )
va xato xabarlari uchun standart xato oqimi (stderr).
Ushbu farq foydalanuvchilarga dasturning muvaffaqiyatli chiqishini faylga yo'naltirishni
tanlashga imkon beradi, ammo shu bilan birga xato
xabarlarini ekranga chiqaradi.
println! funktsiyasi (makrosi) faqat standart chiqishda chop etish mumkin,
shuning uchun biz standart xatolar oqimiga chop etish uchun boshqa misollarda
ko'rib chiqaylik.
Xatolar yozilgan joyni tekshirish
Birinchidan, keling, minigrep-dan chop etilgan kontent hozirda standart chiqishga
qanday yozilishini, shu jumladan biz standart xato oqimiga yozmoqchi bo'lgan har qanday
xato xabarlarini ko'rib chiqaylik. Biz buni standart chiqish oqimini faylga yo'naltirish
va ataylab xatoga yo'l qo'yish orqali qilamiz. Biz standart xatolar oqimiga yo'naltirmaganimiz uchun,
standart xatolar oqimiga yuborilgan har qanday tarkib ekranda paydo bo'lishda davom etadi.
Buyruq qatorining (cmd) dasturlari xato xabarlarini standart xato oqimiga yuborishi kutilmoqda, shuning uchun biz standart chiqish oqimini faylga yo'naltirsak ham, ekrandagi xato xabarlarini ko'rishimiz mumkin. Bizning dasturimiz hozirda to'g'ri ishlamayapti: biz xato xabari chiqishini faylga saqlayotganini ko'ramiz.
Ushbu xatti-harakatni namoyish qilish uchun biz dasturni > va output.txt fayl nomi
bilan ishga tushiramiz. Biz standart chiqish oqimini yo'naltirishni xohlaymiz.
Biz hech qanday dalil (argument) keltirmaymiz, bu xatoga olib kelishi kerak:
$ cargo run > output.txt
> sintaksisi qobiqqa (shellga) output.txt-ga ekran o'rniga standart chiqish (standard output) tarkibini yozishni buyuradi.
Biz ekranda ko'rishni kutgan xato xabarini ko'rmadik, shuning uchun u faylda bo'lishi kerak.
Yuqorida keltirilgan output.txt-ning holati:
Problem parsing arguments: not enough arguments
Ha, bizning xato xabarimiz standart chiqishda (standard outputga) ko'rsatiladi. Bunday xato xabarlarini standart xatolar oqimiga kiritish ancha foydali, shuning uchun faqat muvaffaqiyatli ishga tushirish ma'lumotlari faylga kiradi. Biz buni keyinchalik o'zgartiramiz.
Xatolarni standard xato oqimiga chop etish (print qilish)
Xato xabarlarini chiqarish usulini o'zgartirish uchun biz 12-24-ro'yxatdagi koddan
foydalanamiz. Ushbu bobda ilgari qilgan refaktoring tufayli xato xabarlarini chop
etadigan barcha kodlar bitta main funktsiyada joylashgan. Rust standart kutubxonasi eprintln! makrosini
taqdim etadi va bu makro standart xato oqimiga kiradi, shuning uchun println! bilan chaqirilgan joyda,
keling uning o'rniga eprintln! makrosini ishlatamiz.
Fayl: src/main.rs
use std::env;
use std::process;
use minigrep::Config;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = minigrep::run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}Ro'yxat 12-24: println! yordamida Standard Output o'rniga Standard Error - da xato xabarlarini yozish!
Keling, dasturni xuddi shu tarzda, hech qanday dalilsiz (argumentsiz) qayta ishga
tushiramiz va standart chiqishni (outputni) > bilan qayta yo'naltiramiz:
$ cargo run > output.txt
Problem parsing arguments: not enough arguments
Endi biz ekranda xatoni ko'rishimiz mumkin va output.txt esa bo'sh. Bu esa aynan buyruq qatoridan (cmd-dan) biz kutgan holat.
Keling, dasturni xatoga olib kelmaydigan argumentlar bilan qayta ishga tushiramiz, ammo baribir standart chiqish faylga yo'naltiradi, misol:
$ cargo run -- to poem.txt > output.txt
Biz terminalga hech qanday chiqishni ko'rmaymiz. Va output.txt esa quydagi natijalarni o'z ichiga oladi:
Fayl: output.txt
Are you nobody, too?
How dreary to be somebody!
Yani, biz vaziyatga qarab, muvaffaqiyatli chiqish (output) uchun standart chiqish oqimidan va xatolarni chiqarish uchun standart xato oqimidan foydalanamiz.
Xulosa
Ushbu bobda siz hozirgacha o'rgangan ba'zi asosiy tushunchalar takrorlangan va
Rustda muntazam I/O operatsiyalarini qanday bajarish kerakligi aytilgan.
Buyruq qatori argumentlari (command line argumentlari), fayllar,
atrof-muhit o'zgaruvchilari va println! makrosi yordamida xatolarni
ishlatgan holda, endi siz buyruq qatori (CLI) dasturlarini yozishga tayyormiz.
Oldingi boblardagi tushunchalar bilan birgalikda sizning kodingiz yaxshi tartibga solinadi,
ma'lumotlarni tegishli tuzilmalarda samarali saqlaydi, xatolarni yaxshi qayta ishlaydi va yaxshi
sinovdan o'tkaziladi.
Keyinchalik, biz funktsional tillar ta'sirida bo'lgan Rust-ning ba'zi xususiyatlarini ko'rib chiqamiz: yopilishlar (closures) va iteratorlar.
Funksional til xususiyatlari: iteratorlar va closurelar
Rust dizayni ko'plab mavjud tillar va texnikalardan ilhomlangan va muhim ta'sirlardan biri funksional dasturlash. Funksional uslubda dasturlash ko'pincha funksiyalarni argumentlar orqali uzatish, ularni boshqa funksiyalardan qaytarish, keyinchalik bajarish uchun o'zgaruvchilarga tayinlash va hokazolar orqali qiymat sifatida foydalanishni o'z ichiga oladi.
Ushbu bobda biz funksional dasturlash nima yoki yo'qligi masalasini muhokama qilmaymiz, aksincha, Rustning ko'p tillardagi funksiyalarga o'xshash ba'zi xususiyatlarini muhokama qilamiz.
Aniqroq aytganda, biz quyidagilarni ko'rib chiqamiz:
- Closurelar, oʻzgaruvchida saqlashingiz mumkin boʻlgan funksiyaga oʻxshash konstruksiya
- Iteratorlar, bir qator elementlarni qayta ishlash usuli
- 12-bobdagi I/O loyihasini yaxshilash uchun closure va iteratorlardan qanday foydalanish kerak
- Closure va iteratorlarning ishlashi (Spoiler ogohlantirishi: ular siz o'ylagandan ham tezroq!)
Biz allaqachon Rustning boshqa ba'zi xususiyatlarini ko'rib chiqdik, masalan, pattern matching va enumlar, ular ham funksional uslubga ta'sir qiladi. Closure va iteratorlarni o'zlashtirish idiomatik, tezkor Rust kodini yozishning muhim qismi bo'lganligi sababli, biz ushbu bobni ularga bag'ishlaymiz.
Closurelar: Environmentni qamrab oladigan anonim funksiyalar
Rustning closureri - bu o'zgaruvchida saqlashingiz yoki boshqa funksiyalarga argument sifatida o'tishingiz mumkin bo'lgan anonim funktsiyalar. Closureni bir joyda yaratishingiz va keyin uni boshqa kontekstda baholash uchun boshqa joyga murojaat qilishingiz mumkin. Funksiyalardan farqli o'laroq, closurelar ular belgilangan doiradagi qiymatlarni olishlari mumkin. Ushbu closure xususiyatlari kodni qayta ishlatish va xatti-harakatlarni moslashtirishga(behavior customization) qanday imkon berishini ko'rsatamiz.
Environmentni closurelar bilan qo'lga olish
Avvalo, keyinchalik foydalanish uchun ular belgilangan muhitdan(environment) qiymatlarni olish uchun closurelardan qanday foydalanishimiz mumkinligini ko'rib chiqamiz.Bu senariy: Ko'pincha bizning futbolka kompaniyamiz reklama ro'yxatidagi kimgadir eksklyuziv, cheklangan nashrdagi futbolkani sovg'a sifatida taqdim etadi. Pochta ro'yxatidagi odamlar ixtiyoriy ravishda o'z profillariga sevimli ranglarini qo'shishlari mumkin. Agar bepul futbolka uchun tanlangan kishi o'zining sevimli ranglar to'plamiga ega bo'lsa, u rangdagi futbolkani oladi. Agar biror kishi sevimli rangni ko'rsatmagan bo'lsa, u kompaniyada eng ko'p bo'lgan rangni oladi.
Buni amalga oshirishning ko'plab usullari mavjud. Ushbu misol uchun biz Qizil va Moviy variantlariga ega FutbolkaRangi nomli enumdan foydalanamiz (oddiylik uchun mavjud ranglar sonini cheklaydi). Biz kompaniya inventarini Inventarizatsiya strukturasi bilan ifodalaymiz, unda futbolkalar deb nomlangan maydon mavjud bo‘lib, unda hozirda mavjud bo‘lgan futbolka ranglarini ifodalovchi Vec<FutbolkaRangi> mavjud.
Inventarizatsiya da belgilangan yutuq metodi bepul futbolka g‘olibining ixtiyoriy futbolka rangini afzal ko‘radi va odam oladigan futbolka rangini qaytaradi. Ushbu sozlash 13-1 ro'yxatda ko'rsatilgan:
Fayl nomi: src/main.rs
#[derive(Debug, PartialEq, Copy, Clone)]
enum FutbolkaRangi {
Qizil,
Moviy,
}
struct Inventarizatsiya {
futbolkalar: Vec<FutbolkaRangi>,
}
impl Inventarizatsiya {
fn yutuq(&self, foydalanuvchi_afzalligi: Option<FutbolkaRangi>) -> FutbolkaRangi {
foydalanuvchi_afzalligi.unwrap_or_else(|| self.most_stocked())
}
fn most_stocked(&self) -> FutbolkaRangi {
let mut qizil_raqam = 0;
let mut moviy_raqam = 0;
for rang in &self.futbolkalar {
match rang {
FutbolkaRangi::Qizil => qizil_raqam += 1,
FutbolkaRangi::Moviy => moviy_raqam += 1,
}
}
if qizil_raqam > moviy_raqam {
FutbolkaRangi::Qizil
} else {
FutbolkaRangi::Moviy
}
}
}
fn main() {
let store = Inventarizatsiya {
futbolkalar: vec![FutbolkaRangi::Moviy, FutbolkaRangi::Qizil, FutbolkaRangi::Moviy],
};
let user_pref1 = Some(FutbolkaRangi::Qizil);
let yutuq1 = store.yutuq(user_pref1);
println!(
"{:?} afzalligi bilan foydalanuvchi {:?} oladi",
user_pref1, yutuq1
);
let user_pref2 = None;
let yutuq2 = store.yutuq(user_pref2);
println!(
"{:?} afzalligi bilan foydalanuvchi {:?} oladi",
user_pref2, yutuq2
);
}Ro'yxat 13-1: Futbolka kompaniyasining sovg'a holati
main boʻlimida belgilangan dokon ikkita moviy futbolka va bitta qizil futbolka qolgan. Qizil ko'ylakni afzal ko'rgan foydalanuvchi va hech qanday imtiyozsiz foydalanuvchi uchun yutuq metodini chaqiramiz.
Shunga qaramay, ushbu kod ko'p jihatdan amalga oshirilishi mumkin va bu yerda, closurelarga e'tibor qaratish uchun biz siz allaqachon o'rgangan tushunchalarga yopishib oldik, closuredan foydalanadigan yutuq metodidan tashqari. yutuq metodida biz Option<FutbolkaRangi> turidagi parametr sifatida foydalanuvchi imtiyozini olamiz va foydalanuvchi_afzalligi da unwrap_or_else metodini chaqiramiz. Option<T> da unwrap_or_else metodi standart kutubxona tomonidan aniqlanadi. Buning uchun bitta argument kerak bo‘ladi: T qiymatini qaytaruvchi hech qanday argumentsiz closure (Option<T> enumning Some variantida, bizning holatimizda FutbolkaRangida tugaydigan qiymat turiga aylantiriladi). Agar Option<T> Some varianti bo'lsa, unwrap_or_else qiymatini Some ichidan qaytaradi. Agar Option<T> None varianti bo'lsa, unwrap_or_else closureni chaqiradi va closure orqali qaytarilgan qiymatni qaytaradi.
Biz closure ifodasini belgilaymiz || self.most_stocked()ni unwrap_or_else argumenti sifatida. Bu hech qanday parametrlarni o'zi qabul qilmaydigan closuredir (agar closure parametrlari bo'lsa, ular ikkita vertikal chiziq orasida paydo bo'ladi). Closurening asosiy qismi self.most_stocked() ni chaqiradi. Biz bu yerda closureni aniqlayapmiz va unwrap_or_else ni amalga oshirish, agar natija kerak bo‘lsa, keyinroq closureni baholaydi.
Ushbu kodni ishga tushirsak quyidagi natijani chop etadi:
$ cargo run
Compiling shirt-company v0.1.0 (file:///projects/shirt-company)
Finished dev [unoptimized + debuginfo] target(s) in 0.27s
Running `target/debug/shirt-company`
The user with preference Some(Red) gets Red
The user with preference None gets Blue
Qiziqarli tomoni shundaki, biz joriy Inventarizatsiya misolida self.most_stocked() deb nomlanuvchi closuredan o‘tdik. Standart kutubxona biz belgilagan Inventarizatsiya yoki FutbolkaRangi turlari yoki biz ushbu senariyda foydalanmoqchi bo'lgan mantiq haqida hech narsa bilishi shart emas edi. Closure self Inventarizatsiya misoliga o'zgarmas(immutable) referenceni oladi va uni biz belgilagan kod bilan unwrap_or_else metodiga uzatadi. Funksiyalar esa o'z muhitini(environmentini) shu tarzda ushlab tura olmaydi.
Closure typi Inference va Annotation
Funksiyalar va closurelar o'rtasida ko'proq farqlar mavjud. Closurelar odatda parametrlar turlarini yoki fn funksiyalari kabi qaytarish qiymatini(return value) izohlashni talab qilmaydi. Funksiyalar uchun tur annotationlari talab qilinadi, chunki turlar foydalanuvchilarga ochiq interfeysning bir qismidir. Ushbu interfeysni qat'iy belgilash, har bir kishi funksiya qanday turdagi qiymatlardan foydalanishi va qaytarishi(return) haqida kelishib olishini ta'minlash uchun muhimdir. Boshqa tomondan, closurelar bu kabi ochiq interfeysda ishlatilmaydi: ular o'zgaruvchilarda saqlanadi va ularni nomlamasdan va kutubxonamiz foydalanuvchilariga ko'rsatmasdan foydalaniladi.
Closurelar odatda qisqa va har qanday ixtiyoriy senariyda emas, faqat tor kontekstda tegishli. Ushbu cheklangan kontekstlarda kompilyator ko'pgina o'zgaruvchilarning turlarini qanday aniqlashga qodir bo'lganiga o'xshab, parametrlarning turlarini va qaytish turini taxmin qilishi mumkin (kompilyatorga closure turi annotationlari ham kerak bo'lgan kamdan-kam holatlar mavjud).
O'zgaruvchilarda bo'lgani kabi, agar biz aniqlik va ravshanlikni oshirishni xohlasak, zarur bo'lgandan ko'ra batafsilroq bo'lish uchun turdagi annotationlarni qo'shishimiz mumkin. Closure uchun turlarga izoh(annotation) qo'yish 13-2 ro'yxatda ko'rsatilgan definitionga o'xshaydi. Ushbu misolda biz closureni aniqlaymiz va uni 13-1 ro'yxatda bo'lgani kabi argument sifatida topshirgan joyda closureni belgilash o'rniga uni o'zgaruvchida saqlaymiz.
Fayl nomi: src/main.rs
use std::thread; use std::time::Duration; fn generate_workout(intensity: u32, random_number: u32) { let expensive_closure = |num: u32| -> u32 { println!("calculating slowly..."); thread::sleep(Duration::from_secs(2)); num }; if intensity < 25 { println!("Today, do {} pushups!", expensive_closure(intensity)); println!("Next, do {} situps!", expensive_closure(intensity)); } else { if random_number == 3 { println!("Take a break today! Remember to stay hydrated!"); } else { println!( "Today, run for {} minutes!", expensive_closure(intensity) ); } } } fn main() { let simulated_user_specified_value = 10; let simulated_random_number = 7; generate_workout(simulated_user_specified_value, simulated_random_number); }
Ro'yxat 13-2: Ixtiyoriy turdagi annotationlarni qo'shish closureda parametr va qaytariladigan qiymat turlari
Turga annotationlar qoʻshilishi bilan closure sintaksisi funksiyalar sintaksisiga koʻproq oʻxshaydi. Bu yerda biz taqqoslash uchun parametriga 1 qo'shadigan funksiyani va bir xil xatti-harakatlarga ega bo'lgan closureni aniqlaymiz. Tegishli qismlarni bir qatorga qo'yish uchun bir nechta bo'shliqlar qo'shdik. Bu pipelardan foydalanish va ixtiyoriy bo'lgan sintaksis miqdori bundan mustasno, closure sintaksisi funksiya sintaksisiga qanchalik o'xshashligini ko'rsatadi:
fn bitta_v1_qoshish (x: u32) -> u32 { x + 1 }
let bitta_v2_qoshish = |x: u32| -> u32 { x + 1 };
let bitta_v3_qoshish = |x| { x + 1 };
let bitta_v4_qoshish = |x| x + 1 ;Birinchi qatorda funksiya taʼrifi(definition), ikkinchi qatorda esa toʻliq izohlangan closure definitioni koʻrsatilgan. Uchinchi qatorda biz closure definitiondan turdagi annotationlarni olib tashlaymiz. To'rtinchi qatorda biz qavslarni olib tashlaymiz, ular ixtiyoriy, chunki closure tanas(body) faqat bitta ifodaga(expression) ega. Bularning barchasi to'g'ri definitionlar bo'lib, ular chaqirilganda bir xil xatti-harakatlarni keltirib chiqaradi. bitta_v3_qoshish va bitta_v4_qoshish qatorlari kompilyatsiya qilish uchun closurelarni baholashni talab qiladi, chunki turlar ulardan foydalanishdan kelib chiqadi. Bu let v = Vec::new(); ga o'xshash bo'lib, Rust turini aniqlay olishi uchun Vec ga turiga izohlar(annotation) yoki ba'zi turdagi qiymatlar kiritilishi kerak.
Closure definitionlari uchun kompilyator ularning har bir parametri va ularning qaytish(return) qiymati uchun bitta aniq turdagi xulosa chiqaradi. Masalan, 13-3 ro'yxatda parametr sifatida qabul qilingan qiymatni qaytaradigan qisqa closure definitioni ko'rsatilgan. Ushbu closure ushbu misol maqsadlaridan tashqari juda foydali emas. E'tibor bering, biz definitionga hech qanday annotation qo'shmaganmiz.
Hech qanday turdagi annotationlar mavjud emasligi sababli, biz bu yerda birinchi marta String bilan qilgan har qanday turdagi closureni chaqirishimiz mumkin. Agar biz namuna_closure ni butun(integer) son bilan chaqirishga harakat qilsak, xatoga yo'l qo'yamiz.
Fayl nomi: src/main.rs
fn main() {
let namuna_closure = |x| x;
let s = namuna_closure(String::from("salom"));
let n = namuna_closure(5);
}Ro'yxat 13-3: Ikki xil turga ega bo'lgan closureni chaqirishga urinish
Kompilyator bizga quyidagi xatoni beradi:
$ cargo run
Compiling namuna_closure v0.1.0 (file:///projects/namuna_closure)
error[E0308]: mismatched types
--> src/main.rs:5:29
|
5 | let n = namuna_closure(5);
| --------------- ^- help: try using a conversion method: `.to_string()`
| | |
| | expected struct `String`, found integer
| arguments to this function are incorrect
|
note: closure parameter defined here
--> src/main.rs:2:28
|
2 | let namuna_closure = |x| x;
| ^
For more information about this error, try `rustc --explain E0308`.
error: could not compile `namuna_closure` due to previous error
Birinchi marta namuna_closure String qiymati bilan chaqirilganda, kompilyator x turini va closurening qaytish turini String deb hisoblaydi. Keyin bu turlar(type) namuna_closure bo'limida yopiladi va biz bir xil closure(yopilish) bilan boshqa turdan foydalanishga uringanimizda xatoga duch kelamiz.
Malumot olish yoki Egalik(Ownership) huquqini ko'chirish
Closurelar o'z muhitidan qiymatlarni uchta usulda olishlari mumkin, ular to'g'ridan-to'g'ri funksiya parametr olishi mumkin bo'lgan uchta usulga mos keladi: immutably borrowing (o'zgarmas borrowing(qarz olish)), mutably borrowing (o'zgaruvchan borrowing(qarz olish)) va egalik qilish(ownership). Closure funksiya tanasi(body) olingan qiymatlar bilan nima qilishiga qarab ulardan qaysi birini ishlatishni hal qiladi.
13-4 ro'yxatda biz list deb nomlangan vectorga immutable(o'zgarmas) referencei qamrab oluvchi closureni aniqlaymiz, chunki u qiymatni chop etish uchun faqat immutable referencega muhtoj:
Fayl nomi: src/main.rs
fn main() { let list = vec![1, 2, 3]; println!("Closureni belgilashdan oldin: {:?}", list); let faqat_borrow = || println!("Closuredan: {:?}", list); println!("Closureni chaqirishdan oldin: {:?}", list); faqat_borrow(); println!("Chaqirilgandan keyin closure: {:?}", list); }
Ro'yxat 13-4: Buni closureni aniqlash va chaqirish immutable referenceni ushlaydi
Ushbu misol, shuningdek, o'zgaruvchining closure definitioniga bog'lanishi mumkinligini ko'rsatadi va biz keyinchalik o'zgaruvchi nomi va qavslar yordamida o'zgaruvchi nomi funksiya nomiga o'xshab yopishni chaqirishimiz mumkin.
Biz bir vaqtning o'zida bir nechta immutable(o'zgarmas) referencelarga ega bo'lishimiz mumkin bo'lgan list uchun, list closure definitionidan oldin, closure definitionidan keyin, lekin closure chaqirilishidan oldin va closure chaqirilgandan keyin hali ham koddan foydalanish mumkin. Ushbu kod kompilyatsiya bo'ladi, ishlaydi va chop etadi:
$ cargo run
Compiling namuna_closure v0.1.0 (file:///projects/namuna_closure)
Finished dev [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/namuna_closure`
Closureni belgilashdan oldin: [1, 2, 3]
Closureni chaqirishdan oldin: [1, 2, 3]
Closuredan: [1, 2, 3]
Chaqirilgandan keyin closure: [1, 2, 3]
Keyinchalik, 13-5 ro'yxatda biz closure bodysini list vectoriga element qo'shishi uchun o'zgartiramiz. Closure endi mutable(o'zgaruvchan) referenceni oladi:
Fayl nomi: src/main.rs
fn main() { let mut list = vec![1, 2, 3]; println!("Closureni aniqlashdan oldin: {:?}", list); let mut ozgaruvchan_borrow = || list.push(7); ozgaruvchan_borrow(); println!("Chaqirilgandan keyin closure: {:?}", list); }
Ro'yxat 13-5: Mutable(o'zgaruvchan) referenceni ushlaydigan closureni aniqlash va chaqirish
Ushbu kod kompilyatsiya bo'ladi, ishlaydi va chop etadi:
$ cargo run
Compiling namuna_closure v0.1.0 (file:///projects/namuna_closure)
Finished dev [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/namuna_closure`
Closureni aniqlashdan oldin: [1, 2, 3]
Chaqirilgandan keyin closure: [1, 2, 3, 7]
E'tibor bering, ozgaruvchan_borrow closurening ta'rifi(definition) va chaqiruvi o'rtasida endi println! belgisi yo'q: ozgaruvchan_borrow aniqlanganda, u listga o'zgaruvchan(mutable) referenceni oladi. Closure chaqirilgandan keyin biz closureni qayta ishlatmaymiz, shuning uchun mutable borrow(o'zgaruvchan qarz) tugaydi. Closure definationi va closure chaqiruvi o'rtasida chop etish uchun immutable(o'zgarmas) borrowga ruxsat berilmaydi, chunki mutable borrow mavjud bo'lganda boshqa borrowlarga ruxsat berilmaydi. Qaysi xato xabari borligini bilish uchun u yerga println! qo'shib ko'ring!
Agar closurening asosiy qismi ownershipga(egalik) muhtoj bo'lmasa ham, uni environmentda foydalanadigan qiymatlarga ownershiplik qilishga harakat qilmoqchi bo'lsangiz, parametrlar ro'yxatidan oldin move kalit so'zidan foydalanishingiz mumkin.
Ushbu uslub asosan ma'lumotlarni yangi threadga tegishli bo'lishi uchun ko'chirish uchun yangi threadga closureni o'tkazishda foydalidir. Biz 16-bobda parallellik(concurrency) haqida gapirganda, thereadlarni va nima uchun ulardan foydalanishni xohlashingizni batafsil muhokama qilamiz, ammo hozircha move kalit so'ziga muhtoj bo'lgan closure yordamida yangi threadni yaratishni qisqacha ko'rib chiqamiz. 13-6 ro'yxat vektorni asosiy thredda emas, balki yangi threadda chop etish uchun o'zgartirilgan 13-4 ro'yxatini ko'rsatadi:
Fayl nomi: src/main.rs
use std::thread; fn main() { let list = vec![1, 2, 3]; println!("Closureni aniqlashdan oldin: {:?}", list); thread::spawn(move || println!("{:?} threaddan", list)) .join() .unwrap(); }
Roʻyxat 13-6: listga ownershiplik qilish uchun threadni yopishni majburlash uchun move dan foydalanish
Biz argument sifatida ishlash uchun threadni yopish(closure) imkonini berib, yangi threadni yaratamiz. Closure tanasi(body) listni chop etadi. Roʻyxat 13-4, closure faqat oʻzgarmas(immutable) reference yordamida listni yozib oldi, chunki bu uni chop etish uchun zarur boʻlgan listga kirishning eng kam miqdori. Ushbu misolda, closure tanasi(body) hali ham faqat o'zgarmas(immutable) referencega muhtoj bo'lsa ham, biz closure definationing boshiga move kalit so'zini qo'yish orqali list closurega ko'chirilishi kerakligini ko'rsatishimiz kerak. Yangi thread asosiy threadning qolgan qismi tugashidan oldin tugashi yoki asosiy thread birinchi bo'lib tugashi mumkin. Agar asosiy thread listga ownershiplikni saqlab qolgan boʻlsa-da, lekin yangi thread paydo boʻlishidan oldin tugasa va listni tashlab qoʻysa, threaddagi immutable(oʻzgarmas) reference yaroqsiz boʻladi. Shuning uchun, kompilyator listni yangi threadga berilgan closurega ko'chirishni talab qiladi, shuning uchun reference haqiqiy bo'ladi. Kompilyatorda qanday xatolarga yo'l qo'yganingizni ko'rish uchun closure aniqlangandan so'ng, move kalit so'zini olib tashlang yoki asosiy threaddagi list dan foydalaning!
Qabul qilingan qiymatlarni closuredan va Fn traitlaridan ko'chirish
Closure ma'lumotnomani qo'lga kiritgandan so'ng(shunday qilib, agar biror narsa bo'lsa, closurega ko'chirilgan narsaga ta'sir qiladi) yoki closure aniqlangan environmentdan qiymatga ownershiplikni qo'lga kiritgandan so'ng,(agar biror narsa bo'lsa, closuredan ko'chirilgan narsaga ta'sir qiladi) closurening asosiy qismidagi kod closure keyinroq baholanganda referencelar yoki qiymatlar bilan nima sodir bo'lishini belgilaydi.
Closure tanasi(body) quyidagilardan birini amalga oshirishi mumkin: olingan qiymatni closuredan tashqariga ko'chirish(move), olingan qiymatni mutatsiyalash, qiymatni ko'chirish yoki mutatsiyalash yoki boshlash uchun environmentdan hech narsa olmaslik.
Yopishning environmentdan handlelarni ushlash(capture) va boshqarish usuli closure implementlarining qaysi traitlariga ta'sir qiladi va traitlar funksiyalar va structlar qanday closure turlaridan foydalanishi mumkinligini ko'rsatishi mumkin. Closurelar ushbu Fn belgilarining bittasi, ikkitasi yoki uchtasini avtomatik ravishda qo'shimcha usulda, closure tanasi qiymatlarni(value) qanday boshqarishiga qarab implement qilinadi:
FnOncebir marta chaqirilishi mumkin bo'lgan closurelar uchun amal qiladi. Barcha closurelar hech bo'lmaganda ushbu traitni amalga oshiradi(implement qiladi), chunki barcha closurelar chaqirilishi mumkin. Qabul qilingan qiymatlarni(value) tanasidan tashqariga ko'chiradigan closure faqatFnOnceni implement qiladi va boshqaFntraitlarining hech birini implement qilmaydi, chunki uni faqat bir marta chaqirish mumkin.FnMutqo'lga kiritilgan qiymatlarni(value) tanasidan tashqariga olib chiqmaydigan, lekin olingan qiymatlarni o'zgartirishi mumkin bo'lgan closurelarga nisbatan qo'llaniladi.Ushbu closurelarni bir necha marta chaqirish mumkin.Fnqo'lga kiritilgan qiymatlarni tanasidan tashqariga chiqarmaydigan va olingan qiymatlarni o'zgartirmaydigan closurelar, shuningdek, environmentdan hech narsani ushlab(capture) turmaydigan closurelar uchun amal qiladi. Ushbu closurelar environmentni o'zgartirmasdan bir necha marta chaqirilishi mumkin, bu bir vaqtning o'zida bir necha marta closureni chaqirish kabi holatlarda muhimdir.
Keling, 13-1 ro'yxatda biz qo'llagan Option<T> bo'yicha unwrap_or_else metodining definitionini ko'rib chiqaylik:
impl<T> Option<T> {
pub fn unwrap_or_else<F>(self, f: F) -> T
where
F: FnOnce() -> T
{
match self {
Some(x) => x,
None => f(),
}
}
}Eslatib oʻtamiz, T Optionning Some variantidagi qiymat turini ifodalovchi umumiy turdir(generic type). Bu T turi, shuningdek, unwrap_or_else funksiyasining qaytish(return) turidir: masalan, Option<String>da unwrap_or_else ni chaqiruvchi kod, String oladi.
Keyin, unwrap_or_else funksiyasi qo'shimcha F umumiy turdagi parametrga ega ekanligiga e'tibor bering. F turi f nomli parametrning turi(type) bo'lib, biz unwrap_or_else ga chaqiruv(call) qilganimizda ta`minlovchi closuredir.
Generic F turida belgilangan belgi FnOnce() -> T bo'lib, bu F bir marta chaqirilishi, hech qanday argumentga ega bo'lmasligi va T qaytarilishini bildiradi. Trait bound-da FnOnce dan foydalanish unwrap_or_else faqat bir marta f ni chaqirishi mumkin bo'lgan cheklovni ifodalaydi. unwrap_or_else matnida biz Option Some bo‘lsa, f chaqirilmasligini ko‘rishimiz mumkin. Agar Option None bo'lsa, f bir marta chaqiriladi. Barcha closurelar FnOnce ni implement qilganligi sababli, unwrap_or_else eng har xil turdagi closurelarni qabul qiladi va imkon qadar moslashuvchan.
Eslatma: Funksiyalar uchta
Fntraitlarini ham implement qilishi mumkin. Agar biz qilmoqchi bo'lgan narsa environmentdan qiymat olishni(*capture value) talab qilmasa, bizFntraitlaridan birini implement qiladigan narsa kerak bo'lganda closure o'rniga funksiya nomidan foydalanishimiz mumkin. Masalan,Option<Vec<T>>qiymatida, agar qiymatNonebo'lsa, yangi, bo'sh vektorni olish uchununwrap_or_else(Vec::new)ni chaqirishimiz mumkin.
Endi keling, slicelarda aniqlangan standart kutubxona metodini ko‘rib chiqamiz, bu unwrap_or_elsedan qanday farq qilishini va nima uchun sort_by_key trait bound uchun FnOnce o‘rniga FnMut dan foydalanishini ko‘raylik. Closure ko'rib chiqilayotgan qismdagi joriy elementga reference ko'rinishida bitta argument oladi va order qilinishi mumkin bo'lgan K turidagi qiymatni qaytaradi. Ushbu funksiya har bir elementning ma'lum bir atributi bo'yicha sliceni saralashni xohlaganingizda foydalidir. 13-7 ro'yxatda bizda Kvadrat misollar listi mavjud va biz ularni kenglik atributi bo'yicha pastdan yuqoriga tartiblash uchun sort_by_key dan foydalanamiz:
Fayl nomi: src/main.rs
#[derive(Debug)] struct Kvatrat { kengligi: u32, balandligi: u32, } fn main() { let mut list = [ Kvatrat { kengligi: 10, balandligi: 1 }, Kvatrat { kengligi: 3, balandligi: 5 }, Kvatrat { kengligi: 7, balandligi: 12 }, ]; list.sort_by_key(|r| r.kengligi); println!("{:#?}", list); }
Ro'yxat 13-7: Kvadratlarlarni kengligi bo'yicha tartiblash uchun sort_by_key dan foydalaning
Ushbu kod quyidagi natijani chop etadi:
$ cargo run
Compiling Kvadrats v0.1.0 (file:///projects/Kvadrats)
Finished dev [unoptimized + debuginfo] target(s) in 0.41s
Running `target/debug/Kvadratlar`
[
Kvadrat {
kengligi: 3,
balandligi: 5,
},
Kvadrat {
kengligi: 7,
balandligi: 12,
},
Kvadrat {
kengligi: 10,
balandligi: 1,
},
]
sort_by_key FnMut closureni olish uchun aniqlanganining sababi shundaki, u closureni bir necha marta chaqiradi: slicedagi har bir element uchun bir marta. |r| r.kengligi o'z environmentidan hech narsani ushlamaydi(capture), mutatsiyaga uchramaydi yoki boshqa joyga ko'chirmaydi, shuning uchun u trait bound bo'lgan talablarga javob beradi.
Bundan farqli o'laroq, 13-8 ro'yxat faqat FnOnce traitini amalga oshiradigan closure misolini ko'rsatadi, chunki u qiymatni environmentdan tashqariga ko'chiradi. Kompilyator bu closureni sort_by_key bilan ishlatishimizga ruxsat bermaydi:
Fayl nomi: src/main.rs
#[derive(Debug)]
struct Rectangle {
kengligi: u32,
balandligi: u32,
}
fn main() {
let mut list = [
Rectangle { kengligi: 10, balandligi: 1 },
Rectangle { kengligi: 3, balandligi: 5 },
Rectangle { kengligi: 7, balandligi: 12 },
];
let mut saralash_operatsiyalari = vec![];
let qiymat = String::from("chaqirilgan kalit orqali");
list.sort_by_key(|r| {
saralash_operatsiyalari.push(qiymat);
r.kengligi
});
println!("{:#?}", list);
}Ro'yxat 13-8: sort_by_key yordamida FnOnce closuredan foydalanishga urinish
Bu listni saralashda sort_by_key necha marta chaqirilishini hisoblashning oʻylab topilgan (bu ishlamaydi) usulidir. Ushbu kod closure environmentidan qiymat—a String ni saralash_operatsiyalari vektoriga surish(push) orqali hisoblashni amalga oshirishga harakat qiladi. Closure qiymatni ushlaydi, so‘ngra qiymat ownershipligini saralash_operatsiyalari vektoriga o‘tkazish orqali qiymatni closuredan chiqaradi. Ushbu closureni bir marta chaqirish mumkin; uni ikkinchi marta chaqirishga urinish ishlamaydi, chunki qiymat endi saralash_operatsiyalari ga push qilinadigan environmentda(muhitda) bo'lmaydi! Shuning uchun, bu closure faqat FnOnce ni amalga oshiradi(implement qiladi). Ushbu kodni kompilyatsiya qilmoqchi bo'lganimizda, biz qiymat ni closuredan chiqarib bo'lmaydigan xatoni olamiz, chunki closure FnMut ni implement qilishi kerak:
$ cargo run
Compiling kvadratlar v0.1.0 (file:///projects/kvadratlar)
error[E0507]: cannot move out of `qiymat`, a captured variable in an `FnMut` closure
--> src/main.rs:18:30
|
15 | let qiymat = String::from("chaqirilgan kalit orqali");
| ----- captured outer variable
16 |
17 | list.sort_by_key(|r| {
| --- captured by this `FnMut` closure
18 | saralash_operatsiyalari.push(qiymat);
| ^^^^^ move occurs because `qiymat` has type `String`, which does not implement the `Copy` trait
For more information about this error, try `rustc --explain E0507`.
error: could not compile `kvadratlar` due to previous error
Xato qiymatni environmentdan tashqariga olib chiqadigan closure tanasidagi(body) chiziqqa(line) ishora qiladi. Buni tuzatish uchun biz closure tanasini qiymatlarni environmentdan ko'chirmasligi uchun o'zgartirishimiz kerak. sort_by_key necha marta chaqirilishini hisoblash uchun hisoblagichni(counter) environment saqlash va uning qiymatini closure tanasida oshirish buni hisoblashning yanada sodda usuli hisoblanadi. 13-9 ro'yxatdagi closure sort_by_key bilan ishlaydi, chunki u faqat raqam_saralash_operatsiyalari counteriga mutable(o'zgaruvchan) referenceni oladi va shuning uchun uni bir necha marta chaqirish mumkin:
Fayl nomi: src/main.rs
#[derive(Debug)] struct Kvadrat { kengligi: u32, balandligi: u32, } fn main() { let mut list = [ Kvadrat { kengligi: 10, balandligi: 1 }, Kvadrat { kengligi: 3, balandligi: 5 }, Kvadrat { kengligi: 7, balandligi: 12 }, ]; let mut raqam_saralash_operatsiyalari = 0; list.sort_by_key(|r| { raqam_saralash_operatsiyalari += 1; r.kengligi }); println!("{:#?}, {raqam_saralash_operatsiyalari} operatsiyalarida tartiblangan", list); }
Roʻyxat 13-9: sort_by_key bilan FnMut closuredan foydalanishga ruxsat berilgan
Fn traitlari closurelardan foydalanadigan funksiyalar yoki turlarni belgilash yoki ishlatishda muhim ahamiyatga ega. Keyingi bo'limda biz iteratorlarni muhokama qilamiz. Ko'pgina iterator metodlari closure argumentlarini oladi, shuning uchun biz davom etayotganda ushbu closure tafsilotlarini(details) yodda tuting!
Iteratorlar yordamida elementlar ketma-ketligini qayta ishlash
Iterator pattern sizga navbat bilan elementlarning ketma-ketligi bo'yicha ba'zi vazifalarni(task) bajarishga imkon beradi. Iterator har bir elementni takrorlash va ketma-ketlik qachon tugashini aniqlash mantiqi uchun javobgardir. Iteratorlardan foydalanganda, bu mantiqni(logic) o'zingiz takrorlashingiz shart emas.
Rust-da iteratorlar dangasa, ya'ni iteratorni ishlatish uchun ishlatadigan metodlarni chaqirmaguningizcha ular hech qanday ta'sir ko'rsatmaydi. Masalan, 13-10-Ro'yxatdagi kod Vec<T> da belgilangan iter metodini chaqirish orqali v1 vektoridagi elementlar ustidan iterator yaratadi. Ushbu kod o'z-o'zidan hech qanday foydali ish qilmaydi.
fn main() { let v1 = vec![1, 2, 3]; let v1_iter = v1.iter(); }
Ro'yxat 13-10: iterator yaratish
Iterator v1_iter o'zgaruvchisida saqlanadi. Biz iteratorni yaratganimizdan so'ng, biz uni turli usullarda ishlatishimiz mumkin. 3-bobdagi 3-5 ro'yxatda biz arrayning har bir elementida ba'zi kodlarni bajarish uchun for loop siklidan foydalangan holda uni takrorladik. Korpus ostida bu bilvosita yaratgan va keyin iteratorni ishlatgan, ammo biz hozirgacha uning qanday ishlashini ko'rib chiqdik.
13-11 Ro'yxatdagi misolda biz iteratorni yaratishni for loop siklidagi iteratordan foydalanishdan ajratamiz. for loop sikli v1_iter da iterator yordamida chaqirilganda, iteratordagi har bir element loop siklning bir iteratsiyasida ishlatiladi, bu esa har bir qiymatni chop etadi.
fn main() { let v1 = vec![1, 2, 3]; let v1_iter = v1.iter(); for val in v1_iter { println!("{} : Olingan", val); } }
Ro'yxat 13-11: for loop siklida iteratordan foydalanish
Standart kutubxonalari tomonidan taqdim etilgan iteratorlarga ega bo'lmagan tillarda siz xuddi shu funksiyani o'zgaruvchini 0 indeksidan boshlab yozishingiz mumkin, qiymat olish uchun vektorga indekslash uchun ushbu o'zgaruvchidan foydalanish va vektordagi elementlarning umumiy soniga yetgunga qadar sikldagi o'zgaruvchi qiymatini oshirish.
Iteratorlar siz uchun barcha mantiqni(logic) boshqaradi, siz chalkashtirib yuborishingiz mumkin bo'lgan takroriy kodni qisqartiradi. Iteratorlar vektorlar kabi indekslash mumkin bo'lgan ma'lumotlar tuzilmalari(data structure) emas, balki turli xil ketma-ketliklar(sequence) bilan bir xil mantiqdan foydalanish uchun ko'proq moslashuvchanlikni beradi. Keling, iteratorlar buni qanday qilishini ko'rib chiqaylik.
Iterator traiti va next metodi
Barcha iteratorlar standart kutubxonada(standard library) aniqlangan Iterator nomli traitni implement qiladilar. Traitning definitioni quyidagicha ko'rinadi:
#![allow(unused)] fn main() { pub trait Iterator { type Item; fn next(&mut self) -> Option<Self::Item>; // default implement qilingan metodlar bekor qilindi } }
Eʼtibor bering, bu definitionda baʼzi yangi sintaksislar qoʻllangan: type Item va Self::Item bu trait bilan bogʻlangan turni(associated type) belgilaydi. Bog'langan turlar haqida 19-bobda batafsil gaplashamiz. Hozircha siz bilishingiz kerak bo'lgan narsa shuki, ushbu kodda aytilishicha, Iterator traitini implement qilish uchun siz Item turini ham belgilashingiz kerak bo'ladi va bu Item turi next metodining qaytarish(return) turida qo'llaniladi. Boshqacha qilib aytganda, Item turi iteratordan qaytarilgan tur bo'ladi.
Iterator traiti amalga oshiruvchilardan(implementorlar) faqat bitta metodni belgilashni talab qiladi: next metod, u bir vaqtning o'zida Some ga o'ralgan(wrapped) iteratorning bir elementini qaytaradi va takrorlash(iteratsiya) tugagach, Noneni qaytaradi.
Biz iteratorlarda next metodini to'g'ridan-to'g'ri chaqirishimiz mumkin; Ro'yxat 13-12 vektordan yaratilgan iteratorda next ga takroriy chaqiruvlardan qanday qiymatlar qaytarilishini ko'rsatadi.
Fayl nomi: src/lib.rs
#[cfg(test)]
mod tests {
#[test]
fn iterator_demonstratsiyasi() {
let v1 = vec![1, 2, 3];
let mut v1_iter = v1.iter();
assert_eq!(v1_iter.next(), Some(&1));
assert_eq!(v1_iter.next(), Some(&2));
assert_eq!(v1_iter.next(), Some(&3));
assert_eq!(v1_iter.next(), None);
}
}Ro'yxat 13-12: iteratorda next metodini chaqirish
Esda tutingki, biz v1_iter ni o'zgaruvchan(mutable) qilishimiz kerak edi: iteratorda next metodini chaqirish iterator ketma-ketlikda(sequence) qayerdaligini kuzatish uchun foydalanadigan ichki holatni(internal state) o'zgartiradi. Boshqacha qilib aytganda, bu kod iteratorni iste'mol qiladi(consumes) yoki ishlatadi. next ga har bir chaqiruv(call) iteratordan biror elementni olib tashlaydi. Biz for loop siklidan foydalanganda v1_iterni o‘zgaruvchan(mutable) qilishimiz shart emas edi, chunki sikl v1_iter ga ownership(egalik) qildi va uni sahna ortida o‘zgaruvchan qildi.
Shuni ham yodda tutingki, biz next ga chaiqruvlardan oladigan qiymatlar vektordagi qiymatlarga o'zgarmas(immutable) referencelardir. iter metodi immutable(o'zgarmas) referencelar ustida iterator hosil qiladi. Agar biz v1 ga ownershiplik(egalik) qiluvchi va tegishli qiymatlarni qaytaruvchi iterator yaratmoqchi bo'lsak, iter o‘rniga into_iter ni chaqirishimiz mumkin. Xuddi shunday, agar biz mutable(o'zgaruvchan) referencelarni takrorlashni xohlasak, iter o'rniga iter_mut ni chaqirishimiz mumkin.
Iteratorni consume qiladigan metodlar
Iterator traiti standart kutubxona(standard library) tomonidan taqdim etilgan default implementationlar bilan bir qator turli metodlarga ega; ushbu metodlar haqida Iterator traiti uchun standart kutubxona API texnik hujjatlarini ko'rib chiqish orqali bilib olishingiz mumkin. Ushbu metodlarning ba'zilari o'z definitionlarida next metodni chaqiradi, shuning uchun Iterator tratini implement qilishda next metodni qo'llash talab qilinadi.
next ni chaqiruvchi metoflar consuming adaptorlar deb ataladi, chunki ularni chaqirish iteratordan foydalanadi. Bitta misol, iteratorga ownership(egalik) qiladigan va next deb qayta-qayta chaqirish orqali elementlarni takrorlaydigan, shu bilan iteratorni consume qiladigan sum metodidir. U takrorlanayotganda, u har bir elementni ishlayotgan jamiga qo'shadi va takrorlash tugagach, jamini qaytaradi. 13-13 ro'yxatda sum metodidan foydalanishni ko'rsatadigan test mavjud:
Fayl nomi: src/lib.rs
#[cfg(test)]
mod tests {
#[test]
fn iterator_sum() {
let v1 = vec![1, 2, 3];
let v1_iter = v1.iter();
let total: i32 = v1_iter.sum();
assert_eq!(total, 6);
}
}Ro'yxat 13-13: iteratordagi barcha elementlarning umumiy miqdorini olish uchun sum metodini chaqirish
Bizga sum chaqiruvidan keyin v1_iter dan foydalanishga ruxsat berilmagan, chunki sum biz chaqiruvchi iteratorga ownershiplik(egalik) qiladi.
Boshqa iteratorlarni yaratuvchi metodlar
Iterator adaptorlari iteratorni consume(iste'mol) qilmaydigan Iterator traiti bo'yicha aniqlangan metoddir. Buning o'rniga, ular asl iteratorning ba'zi jihatlarini o'zgartirib, turli iteratorlarni ishlab chiqaradilar.
13-14 ro'yxatda iterator adapter metodini map deb chaqirish misoli ko'rsatilgan, bunda elementlar takrorlanganda(iteratsiya) har bir elementga chaqiruv(call) qilish yopiladi.
map metodi o'zgartirilgan elementlarni ishlab chiqaradigan yangi iteratorni qaytaradi. Bu yerda closure vektorning har bir elementi 1 ga oshiriladigan yangi iteratorni yaratadi:
Fayl nomi: src/main.rs
fn main() { let v1: Vec<i32> = vec![1, 2, 3]; v1.iter().map(|x| x + 1); }
Ro'yxat 13-14: Yangi iterator yaratish uchun iterator adapteriga map chaqiruv qilish qilish
Biroq, bu kod ogohlantirish(warning) ishlab chiqaradi:
$ cargo run
Compiling iterators v0.1.0 (file:///projects/iterators)
warning: unused `Map` that must be used
--> src/main.rs:4:5
|
4 | v1.iter().map(|x| x + 1);
| ^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: iterators are lazy and do nothing unless consumed
= note: `#[warn(unused_must_use)]` on by default
warning: `iterators` (bin "iterators") generated 1 warning
Finished dev [unoptimized + debuginfo] target(s) in 0.47s
Running `target/debug/iterators`
13-14 ro'yxatdagi kod hech narsa qilmaydi; biz belgilagan closure hech qachon chaqirilmaydi. Ogohlantirish(warning) bizga nima uchun eslatib turadi: iterator adapterlari dangasa va biz bu yerda iteratorni consume(ishlatish) qilishimiz kerak.
Ushbu ogohlantirishni tuzatish va iteratorni consume qilish uchun biz 12-bobda env::args bilan 12-1 ro'yxatda qo'llagan collect metodian foydalanamiz. Ushbu metod iteratorni consume qiladi va natijada olingan qiymatlarni ma'lumotlar to'plamiga(data type) to'playdi.
13-15 ro'yxatda biz vektorga map-ga chaqiruvdan qaytgan iterator bo'yicha takrorlash natijalarini yig'amiz. Ushbu vektor 1 ga oshirilgan asl vektorning har bir elementini o'z ichiga oladi.
Fayl nomi: src/main.rs
fn main() { let v1: Vec<i32> = vec![1, 2, 3]; let v2: Vec<_> = v1.iter().map(|x| x + 1).collect(); assert_eq!(v2, vec![2, 3, 4]); }
Ro'yxat 13-15: Yangi iterator yaratish uchun map metodini chaqirish va keyin yangi iteratorni consume qilish va vektor yaratish uchun collect metodini chaqirish
map yopilganligi sababli, biz har bir elementda bajarmoqchi bo'lgan har qanday operatsiyani belgilashimiz mumkin. Bu Iterator traiti taʼminlaydigan iteratsiya xatti-harakatlarini(behavior) qayta ishlatishda closurelar sizga qandaydir behaviorlarni sozlash imkonini berishining ajoyib namunasidir.
Murakkab harakatlarni(complex action) o'qilishi mumkin bo'lgan tarzda bajarish uchun iterator adapterlariga bir nechta chaiquvlarni zanjirlashingiz(chain) mumkin. Ammo barcha iteratorlar dangasa bo'lgani uchun, iterator adapterlariga chaqiruvlardan natijalarni olish uchun consuming adapter metodlaridan birini chaqirishingiz kerak.
Environmentni qamrab oladigan(capture) closurelardan foydalanish
Ko'pgina iterator adapterlari closurelarni argument sifatida qabul qiladilar va odatda biz iterator adapterlariga argument sifatida ko'rsatadigan closurelar ularning environmentini oladigan closurelar bo'ladi.
Ushbu misol uchun biz closureni oladigan filter metodidan foydalanamiz. Closure iteratordan element oladi va bool ni qaytaradi. Agar closure true qiymatini qaytarsa, qiymat filtr tomonidan ishlab chiqarilgan iteratsiyaga kiritiladi. Agar closure false bo'lsa, qiymat kiritilmaydi.
13-16 roʻyxatda biz Poyabzal structi misollari toʻplamini iteratsiya qilish uchun uning environmentidan poyabzal_olchami oʻzgaruvchisini ushlaydigan(capture) closure bilan filtrdan foydalanamiz. U faqat belgilangan o'lchamdagi poyabzallarni qaytaradi.
Fayl nomi: src/lib.rs
#[derive(PartialEq, Debug)]
struct Poyabzal {
olchami: u32,
uslub: String,
}
fn olcham_boyicha_poyabzal(poyabzal: Vec<Poyabzal>, poyabzal_olchami: u32) -> Vec<Poyabzal> {
poyabzal.into_iter().filter(|s| s.size == poyabzal_olchami).collect()
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn olcham_boyicha_filterlash() {
let poyabzal = vec![
Poyabzal {
olchami: 10,
uslub: String::from("krossovka"),
},
Poyabzal {
olchami: 13,
uslub: String::from("sandal"),
},
Poyabzal {
olchami: 10,
uslub: String::from("etik"),
},
];
let in_my_size = olcham_boyicha_poyabzal(poyabzal, 10);
assert_eq!(
in_my_size,
vec![
Poyabzal {
olchami: 10,
uslub: String::from("krossovka")
},
Poyabzal {
olchami: 10,
uslub: String::from("etik")
},
]
);
}
}Roʻyxat 13-16: poyabzal_olchamini ushlaydigan closure bilanfilter metodidan foydalanish
olcham_boyicha_poyabzal funksiyasi parametr sifatida poyabzal vektori va poyabzal o'lchamiga egalik qiladi. U faqat belgilangan o'lchamdagi poyabzallarni o'z ichiga olgan vektorni qaytaradi.
olcham_boyicha_poyabzal bodysida(tanasida) vektorga ownershiplik(egalik) qiluvchi iterator yaratish uchun into_iter ni chaqiramiz. Keyin biz ushbu iteratorni faqat closure trueni qaytaradigan elementlarni o'z ichiga olgan yangi iteratorga moslashtirish uchun filter ni chaqiramiz.
Closure muhitdan poyabzal_olchami parametrini oladi va qiymatni har bir poyabzal o'lchami bilan solishtiradi, faqat belgilangan o'lchamdagi poyabzallarni saqlaydi. Nihoyat, collect ni chaqirish moslashtirilgan iterator tomonidan qaytarilgan qiymatlarni funksiya tomonidan qaytariladigan vektorga to'playdi.
Test shuni ko'rsatadiki, biz olcham_boyicha_poyabzal deb ataganimizda, biz faqat biz ko'rsatgan qiymat bilan bir xil o'lchamdagi poyabzallarni qaytarib olamiz.
I/O loyihamizni takomillashtirish
Iteratorlar haqidagi yangi bilimlar bilan biz koddagi joylarni aniqroq va ixchamroq qilish uchun iteratorlardan foydalangan holda 12-bobdagi I/O(input/output) loyihasini yaxshilashimiz mumkin. Keling, iteratorlar Config::build va qidiruv funksiyalarini amalga implement qilishni qanday yaxshilashi mumkinligini ko'rib chiqaylik.
Iterator yordamida cloneni olib tashlash
12-6 roʻyxatda biz String qiymatlari boʻlagini olgan kodni qoʻshdik va boʻlimga indekslash va qiymatlarni klonlash orqali Config strukturasining namunasini yaratdik, Config strukturasiga ushbu qiymatlarga ownershiplik(egalik) qilish imkonini berdi. 13-17 ro'yxatda biz 12-23 ro'yxatdagi kabi Config::build funksiyasining bajarilishini takrorladik:
Fayl nomi: src/lib.rs
use std::env;
use std::error::Error;
use std::fs;
pub struct Config {
pub sorov: String,
pub fayl_yoli: String,
pub ignore_case: bool,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("argumentlar yetarli emas");
}
let sorov = args[1].clone();
let fayl_yoli = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
sorov,
fayl_yoli,
ignore_case,
})
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let tarkib = fs::read_to_string(config.fayl_yoli)?;
let natijalar = if config.ignore_case {
harflarga_etiborsiz_qidirish(&config.sorov, &tarkib)
} else {
qidiruv(&config.sorov, &tarkib)
};
for line in natijalar {
println!("{line}");
}
Ok(())
}
pub fn qidiruv<'a>(sorov: &str, tarkib: &'a str) -> Vec<&'a str> {
let mut natijalar = Vec::new();
for line in tarkib.lines() {
if line.contains(sorov) {
natijalar.push(line);
}
}
natijalar
}
pub fn harflarga_etiborsiz_qidirish<'a>(
sorov: &str,
tarkib: &'a str,
) -> Vec<&'a str> {
let sorov = sorov.to_lowercase();
let mut natijalar = Vec::new();
for line in tarkib.lines() {
if line.to_lowercase().contains(&sorov) {
natijalar.push(line);
}
}
natijalar
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn harflarga_etiborli() {
let sorov = "duct";
let tarkib = "\
Rust:
xavfsiz, tez, samarali.
Uchtasini tanlang.
Duct tape.";
assert_eq!(vec!["xavfsiz, tez, samarali."], qidiruv(sorov, tarkib));
}
#[test]
fn harflarga_etiborsiz() {
let sorov = "rUsT";
let tarkib = "\
Rust:
xavfsiz, tez, samarali.
Uchtasini tanlang.
Menga ishoning.";
assert_eq!(
vec!["Rust:", "Menga ishoning."],
harflarga_etiborsiz_qidirish(sorov, tarkib)
);
}
}Ro'yxat 13-17: Config::build funksiyasining 12-23-Ro'yxatdan takrorlanishi
O'shanda biz samarasiz clone chaqiruvlari(call) haqida qayg'urmaslikni aytdik, chunki kelajakda ularni olib tashlaymiz. Xo'sh, bu vaqt hozir!
Bizga bu yerda clone kerak edi, chunki bizda args parametrida String elementlari bo‘lgan slice bor, lekin build funksiyasi argsga ega emas. Config namunasiga ownershiplikni(egalik) qaytarish uchun Configning sorov va fayl_yoli maydonlaridagi qiymatlarni klonlashimiz kerak edi, shunda Config namunasi o‘z qiymatlariga ega bo‘lishi mumkin.
Iteratorlar haqidagi yangi bilimlarimiz bilan biz build funksiyasini oʻzgartirib, bir sliceni olish oʻrniga iteratorga argument sifatida ownershiplik qilishimiz mumkin.
Biz slice uzunligini tekshiradigan kod o'rniga iterator funksiyasidan foydalanamiz va ma'lum joylarga ko'rsatamiz. Bu Config::build funksiyasi nima qilayotganini aniqlaydi, chunki iterator qiymatlarga kira oladi.
Config::build iteratorga ownershiplik qilib, borrow qilingan indekslash operatsiyalaridan foydalanishni to'xtatgandan so'ng, biz clone deb chaqirish va yangi ajratish(allocation) o'rniga String qiymatlarini iteratordan Configga ko'chirishimiz mumkin.
Qaytarilgan(return) iteratordan to'g'ridan-to'g'ri foydalanish
I/O loyihangizning src/main.rs faylini oching, u quyidagicha ko'rinishi kerak:
Fayl nomi: src/main.rs
use std::env;
use std::process;
use minigrep::Config;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
eprintln!("Argumentlarni tahlil qilish muammosi: {err}");
process::exit(1);
});
// --snip--
if let Err(e) = minigrep::run(config) {
eprintln!("Dastur xatosi: {e}");
process::exit(1);
}
}Biz birinchi navbatda 12-24-Ro'yhatdagi main funksiyaning boshlanishini 13-18-Ro'yxatdagi kodga almashtiramiz, bu safar iteratordan foydalanadi. Biz Config::buildni ham yangilamagunimizcha, bu kompilyatsiya qilinmaydi.
Fayl nomi: src/main.rs
use std::env;
use std::process;
use minigrep::Config;
fn main() {
let config = Config::build(env::args()).unwrap_or_else(|err| {
eprintln!("Argumentlarni tahlil qilish muammosi: {err}");
process::exit(1);
});
// --snip--
if let Err(e) = minigrep::run(config) {
eprintln!("Dastur xatosi: {e}");
process::exit(1);
}
}Ro'yxat 13-18: env::args ning return(qaytish) qiymatini `Config::build`` ga o'tkazish
env::args funksiyasi iteratorni qaytaradi! Iterator qiymatlarini(value) vectorga yig'ib, keyin sliceni(bo'lak) Config::build ga o'tkazish o'rniga, endi biz env::args dan qaytarilgan(return) iteratorga ownershiplik(egalik) huquqini to'g'ridan-to'g'ri Config::build ga o'tkazmoqdamiz.
Keyinchalik, Config::build definitioni yangilashimiz kerak. I/O loyihangizning src/lib.rs faylida keling, Config::build signaturesni 13-19-raqamli roʻyxatga oʻxshatib oʻzgartiraylik. Bu hali ham kompilyatsiya qilinmaydi, chunki biz funksiya bodysini(tanasi) yangilashimiz kerak.
Fayl nomi: src/lib.rs
use std::env;
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
pub fn build(
mut args: impl Iterator<Item = String>,
) -> Result<Config, &'static str> {
// --snip--
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}Listing 13-19: Updating the signature of Config::build
to expect an iterator
The standard library documentation for the env::args function shows that the
type of the iterator it returns is std::env::Args, and that type implements
the Iterator trait and returns String values.
We’ve updated the signature of the Config::build function so the parameter
args has a generic type with the trait bounds impl Iterator<Item = String>
instead of &[String]. This usage of the impl Trait syntax we discussed in
the “Traits as Parameters” section of Chapter 10
means that args can be any type that implements the Iterator type and
returns String items.
Because we’re taking ownership of args and we’ll be mutating args by
iterating over it, we can add the mut keyword into the specification of the
args parameter to make it mutable.
Using Iterator Trait Methods Instead of Indexing
Next, we’ll fix the body of Config::build. Because args implements the
Iterator trait, we know we can call the next method on it! Listing 13-20
updates the code from Listing 12-23 to use the next method:
Fayl nomi: src/lib.rs
use std::env;
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
pub fn build(
mut args: impl Iterator<Item = String>,
) -> Result<Config, &'static str> {
args.next();
let query = match args.next() {
Some(arg) => arg,
None => return Err("Didn't get a query string"),
};
let file_path = match args.next() {
Some(arg) => arg,
None => return Err("Didn't get a file path"),
};
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}Listing 13-20: Changing the body of Config::build to use
iterator methods
Remember that the first value in the return value of env::args is the name of
the program. We want to ignore that and get to the next value, so first we call
next and do nothing with the return value. Second, we call next to get the
value we want to put in the query field of Config. If next returns a
Some, we use a match to extract the value. If it returns None, it means
not enough arguments were given and we return early with an Err value. We do
the same thing for the file_path value.
Making Code Clearer with Iterator Adaptors
We can also take advantage of iterators in the search function in our I/O
project, which is reproduced here in Listing 13-21 as it was in Listing 12-19:
Fayl nomi: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub sorov: String,
pub fayl_yoli: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("argumentlar yetarli emas");
}
let sorov = args[1].clone();
let fayl_yoli = args[2].clone();
Ok(Config { sorov, fayl_yoli })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let tarkib = fs::read_to_string(config.fayl_yoli)?;
Ok(())
}
pub fn qidiruv<'a>(sorov: &str, tarkib: &'a str) -> Vec<&'a str> {
let mut natijalar = Vec::new();
for line in tarkib.lines() {
if line.contains(sorov) {
natijalar.push(line);
}
}
natijalar
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn birinchi_natija() {
let sorov = "marali";
let tarkib = "\
Rust:
xavfsiz, tez, samarali.
Uchtasini tanlang.";
assert_eq!(vec!["xavfsiz, tez, samarali."], qidiruv(sorov, tarkib));
}
}Listing 13-21: The implementation of the search
function from Listing 12-19
We can write this code in a more concise way using iterator adaptor methods.
Doing so also lets us avoid having a mutable intermediate results vector. The
functional programming style prefers to minimize the amount of mutable state to
make code clearer. Removing the mutable state might enable a future enhancement
to make searching happen in parallel, because we wouldn’t have to manage
concurrent access to the results vector. Listing 13-22 shows this change:
Fayl nomi: src/lib.rs
use std::env;
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
pub fn build(
mut args: impl Iterator<Item = String>,
) -> Result<Config, &'static str> {
args.next();
let query = match args.next() {
Some(arg) => arg,
None => return Err("Didn't get a query string"),
};
let file_path = match args.next() {
Some(arg) => arg,
None => return Err("Didn't get a file path"),
};
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
contents
.lines()
.filter(|line| line.contains(query))
.collect()
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}Ro'yxat 13-22: qidiruv funksiyasini impelement qilishda iterator adapter metodlaridan foydalanish
Eslatib o'tamiz, qidiruv funksiyasining maqsadi tarkib dagi sorov ni o'z ichiga olgan barcha qatorlarni qaytarishdir(return). 13-16 Roʻyxatdagi filter misoliga oʻxshab, bu kod filter adapteridan faqat line.contains(sorov) uchun true qaytaradigan satrlarni saqlash uchun foydalanadi. Keyin mos keladigan qatorlarni collect bilan boshqa vectorga yig'amiz. Juda oddiyroq! harflarga_etiborsiz_qidirish funksiyasida ham iterator metodlaridan foydalanish uchun xuddi shunday o'zgartirish kiriting.
Looplar yoki iteratorlar o'rtasida tanlash
Keyingi mantiqiy savol - o'z kodingizda qaysi uslubni tanlashingiz kerakligi va nima uchun: 13-21-Ro'yxatdagi asl dastur yoki 13-22-Ro'yxatdagi iteratorlardan foydalangan holda versiya. Aksariyat Rust dasturchilari iterator uslubidan foydalanishni afzal ko'rishadi. Avvaliga o'rganish biroz qiyinroq, lekin siz turli xil iterator adapterlari va ular nima qilishini his qilganingizdan so'ng, iteratorlarni tushunish osonroq bo'ladi. Kod aylanishning turli bitlari va yangi vectorlarni yaratish o'rniga, loop siklning yuqori darajadagi(high-level) maqsadiga e'tibor qaratadi. Bu ba'zi oddiy kodlarni abstrakt qiladi, shuning uchun ushbu kodga xos bo'lgan tushunchalarni, masalan, iteratordagi har bir element o'tishi kerak bo'lgan filtrlash shartini ko'rish osonroq bo'ladi.
Ammo ikkita dastur haqiqattan ham ekvivalentmi? Intuitiv taxmin shundan iboratki, low-leveldagi loop tezroq bo'ladi. Keling, performance haqida gapiraylik.
Ishlash samaradorligini(Performance) solishtirish: Looplar va iteratorlar
Looplar yoki iteratorlardan foydalanishni aniqlash uchun siz qaysi implement qilish tezroq ekanligini bilishingiz kerak: qidiruv funksiyasining aniq for lop sikliga ega versiyasi yoki iteratorli versiya.
Ser Arthur Conan Doylening Sherlok Xolmsning sarguzashtlari(The Adventures of Sherlock Holmes) asarining to‘liq mazmunini Stringga yuklash va mazmundan the so‘zini izlash orqali sinovdan o‘tkizdik. Mana, for loop siklidan foydalangan holda qidiruv versiyasi va iteratorlardan foydalangan holda sinov natijalari:
test bench_search_for ... bench: 19,620,300 ns/iter (+/- 915,700)
test bench_search_iter ... bench: 19,234,900 ns/iter (+/- 657,200)
Iterator versiyasi biroz tezroq edi! Biz bu yerda benchmark kodini tushuntirmaymiz, chunki bu ikkita versiyaning ekvivalentligini isbotlash emas, balki ushbu ikki dasturning ishlash jihatidan qanday taqqoslanishi haqida umumiy tushunchaga ega bo'lishdir.
Batafsilroq tahlil qilish uchun siz tarkib sifatida har xil oʻlchamdagi turli matnlarni, sorov sifatida turli uzunlikdagi turli soʻz va soʻzlarni va boshqa har xil oʻzgarishlardan foydalanishni tekshirishingiz kerak. Gap shundaki: iteratorlar, garchi yuqori darajadagi(high-level) abstraksiya bo'lsa ham, xuddi quyi darajadagi(lower-level) kodni o'zingiz yozganingizdek, taxminan bir xil kodga kompilyatsiya qilinadi. Iteratorlar Rustning zero-cost(nol xarajatli) abstraksiyalaridan biri bo‘lib, bu orqali biz abstraktsiyadan foydalanish qo‘shimcha runtime yukini talab qilmaydi. Bu C++ tilining asl dizayneri va amalga oshiruvchisi(implementori) Bjarne Stroustrupning “C++ asoslari (Foundations of C++)” (2012) asarida zero-overhead belgilashiga o‘xshaydi:
Umuman olganda, C++ ilovalari zero overhead(nol qo'shimcha xarajatlar) printsipiga bo'ysunadi: Siz foydalanmayotgan narsangiz uchun pul to'lamaysiz. Va yana: Siz foydalanadigan narsadan yaxshiroq kodlash mumkin emas.
Yana bir misol sifatida, quyidagi kod audio dekoderdan olingan. Dekodlash algoritmi oldingi namunalarning chiziqli(linear) funksiyasi asosida kelajakdagi qiymatlarni baholash uchun linear prediction(taxmin qilish) qilish matematik operatsiyasidan foydalanadi. Ushbu kod uchta o'zgaruvchi bo'yicha matematikani amalga oshirish uchun iterator zanjiridan foydalanadi: ma'lumotlarning bufer qismi, 12 koeffitsient massivi va qlp_shift da ma'lumotlarni o'zgartirish uchun miqdor. Biz ushbu misolda o'zgaruvchilarni e'lon qildik, lekin ularga hech qanday qiymat bermadik; Garchi bu kod o'z kontekstidan tashqarida unchalik katta ma'noga ega bo'lmasa-da, bu Rust yuqori darajadagi g'oyalarni low-leveldagi kodga qanday tarjima qilishining qisqacha, haqiqiy misolidir.
let buffer: &mut [i32];
let koeffitsient: [i64; 12];
let qlp_shift: i16;
for i in 12..buffer.len() {
let taxmin_qilish = koeffitsient.iter()
.zip(&buffer[i - 12..i])
.map(|(&c, &s)| c * s as i64)
.sum::<i64>() >> qlp_shift;
let delta = buffer[i];
buffer[i] = taxmin_qilish as i32 + delta;
}taxmin_qilish qiymatini hisoblash uchun ushbu kod koeffitsient dagi 12 ta qiymatning har birini iteratsiya(takrorlaydi) qiladi va koeffitsient qiymatlarini buferdagi oldingi 12 ta qiymat bilan bog‘lash uchun zip metodidan foydalanadi. Keyin, har bir juftlik uchun biz qiymatlarni ko'paytiramiz, barcha natijalarni yig'amiz va qlp_shift bitlari yig'indisidagi bitlarni o'ngga siljitamiz.
Audio dekoderlar kabi ilovalardagi hisob-kitoblar ko'pincha performenceni(ish samaradorligi) birinchi o'ringa qo'yadi. Bu yerda biz iterator yaratamiz, ikkita adapterdan foydalanamiz va keyin qiymatni consume(iste'mol) qilamiz. Ushbu Rust kodi qaysi assembly kodini kompilyatsiya qiladi? Xo'sh, ushbu yozuvdan boshlab, u siz qo'lda yozadigan assemblyga kopilatsiya qiladi. koeffitsient dagi qiymatlar ustidagi iteratsiyaga mos keladigan loop sikl umuman yo‘q: Rust 12 ta iteratsiya(takrorlash) borligini biladi, shuning uchun u loop siklni unrolls qiladi. Unrolling - bu optimallashtirish bo'lib, u loop siklni boshqarish kodining qo'shimcha yukini olib tashlaydi va buning o'rniga loop siklning har bir iteratsiyasi uchun takroriy kod hosil qiladi.
Barcha koeffitsientlar registrlarda saqlanadi, ya'ni qiymatlarga kirish juda tez. Runtimeda massivga kirishda chegaralar yo'q. Rust qo'llashi mumkin bo'lgan barcha optimallashtirishlar natijada olingan kodni juda samarali qiladi. Endi siz buni bilganingizdan so'ng, siz iteratorlar va closurelardan qo'rqmasdan foydalanishingiz mumkin! Ular kodni yuqori darajadagi(high-level) ko'rinishga olib keladi, lekin buning uchun runtime ishlashi uchun jazo qo'llamaydi.
Xulosa
Closure va iteratorlar - bu funksional dasturlash tili g'oyalaridan ilhomlangan Rust xususiyatlari(feature). Ular Rustning low-leveldagi ishlashda high-leveldagi g'oyalarni aniq ifodalash qobiliyatiga hissa qo'shadilar. Closure va iteratorlarni implement qilish runtimening ishlashiga ta'sir qilmaydi. Bu Rustning zero-cost(nol xarajatli) abstraksiyalarni taqdim etishga intilish maqsadining bir qismidir.
Endi biz I/O loyihamizning ifodaliligini yaxshilaganimizdan so‘ng, keling, loyihani dunyo bilan baham ko‘rishimizga yordam beradigan cargoning yana bir qancha xususiyatlarini ko‘rib chiqaylik.
Cargo va Crates.io haqida ko'proq
Hozirgacha biz kodimizni yaratish(build), ishga tushirish(run) va sinab ko'rish(test) uchun faqat Cargo-ning eng asosiy xususiyatlaridan foydalanganmiz, ammo u ko'proq narsani qila oladi. Ushbu bobda biz sizga quyidagi amallarni bajarishni ko'rsatish uchun uning boshqa, yanada ilg'or xususiyatlarini muhokama qilamiz:
- Reliz profillari bilan buildarni customizatsiya qilish
- Kutubxonalarni(library) crates.io saytida nashr eting
- Workspacelar bilan yirik loyihalarni tashkil qiling
- crates.io dan binary(ikkilik) fayllarni o'rnating
- Maxsus buyruqlar yordamida cargoni kengaytiring
Cargo biz ushbu bobda ko'rib chiqiladigan funksiyalardan ham ko'proq narsani qila oladi, shuning uchun uning barcha xususiyatlarini to'liq tushuntirish uchun uning texnik hujjatlariga qarang.
Reliz profillari bilan buildarni customizatsiya qilish
Rust-da release profillari turli xil konfiguratsiyalarga ega bo'lgan oldindan belgilangan va sozlanishi mumkin bo'lgan profillar bo'lib, ular dasturchiga kodni kompilyatsiya qilish uchun turli xil variantlarni ko'proq nazorat qilish imkonini beradi. Har bir profil boshqalardan mustaqil ravishda configuratsiya qilingan.
Cargo ikkita asosiy profilga ega: cargo buildni ishga tushirganingizda dev cargo profili va cargo build --releaseni ishga tushirganingizda release cargo profilidan foydalanadi. dev profili ishlab chiqish(development) uchun yaxshi standart sozlamalar bilan belgilangan va release profili relizlar uchun yaxshi standart parametrlarga ega.
Ushbu profil nomlari sizning buildlaringiz natijalaridan tanish bo'lishi mumkin:
$ cargo build
Finished dev [unoptimized + debuginfo] target(s) in 0.0s
$ cargo build --release
Finished release [optimized] target(s) in 0.0s
dev va release - bu kompilyator tomonidan ishlatiladigan turli xil profillar.
Loyihaning Cargo.toml fayliga [profile.*] boʻlimlarini aniq qoʻshmagan boʻlsangiz, Cargo har bir profil uchun standart(default) sozlamalarga ega.
Moslashtirmoqchi(customizatsiya) boʻlgan har qanday profil uchun [profile.*] boʻlimlarini qoʻshish orqali siz default sozlamalarning har qanday quyi toʻplamini bekor qilasiz. Masalan, dev va release profillari uchun opt-level sozlamalari uchun default qiymatlar:
Fayl nomi: Cargo.toml
[profile.dev]
opt-level = 0
[profile.release]
opt-level = 3
opt-level sozlama Rust kodingizga qo'llaniladigan optimallashtirishlar sonini nazorat qiladi, 0 dan 3 gacha. Ko'proq optimallashtirishni qo'llash kompilyatsiya vaqtini uzaytiradi, shuning uchun agar siz tez-tez ishlab chiqayotgan bo'lsangiz va kodingizni kompilyatsiya qilsangiz, natijada olingan kod sekinroq ishlayotgan bo'lsa ham, tezroq kompilyatsiya qilishni kamroq optimallashtirishni xohlaysiz. Shunday qilib, dev uchun default opt-level 0 dir. Kodni releasega chiqarishga tayyor bo'lganingizda, kompilyatsiya qilish uchun ko'proq vaqt sarflaganingiz ma'qul. Siz release rejimida faqat bir marta kompilyatsiya qilasiz, lekin kompilyatsiya qilingan dasturni ko'p marta ishga tushirasiz, shuning uchun release rejimi tradelari tezroq ishlaydigan kod uchun kompilyatsiya vaqtini uzaytiradi. Shuning uchun release profili uchun default opt-level 3 dir.
Siz Cargo.toml da boshqa qiymat qoʻshish orqali default sozlamani bekor qilishingiz mumkin. Misol uchun, agar biz development profilida optimallashtirish darajasi 1 dan foydalanmoqchi bo'lsak, loyihamizning Cargo.toml fayliga ushbu ikki qatorni qo'shishimiz mumkin:
Fayl nomi: Cargo.toml
[profile.dev]
opt-level = 1
Bu kod default 0 sozlamasini bekor qiladi. Now when we run cargo build,
Cargo dev profili uchun default sozlamalardan hamda opt-levelga moslashtirishimizdan foydalanadi. Biz opt-levelni 1 ga o‘rnatganimiz sababli, Cargo defaultdan ko‘ra ko‘proq optimallashtirishni qo‘llaydi, lekin release builddagi kabi emas.
Har bir profil uchun konfiguratsiya opsiyalari va standart sozlamalarning to'liq ro'yxati uchun Cargo texnik hujjatlariga qarang.
Crateni Crates.io-ga nashr qilish
Biz crates.io paketlaridan loyihamizga dependency sifatida foydalandik, lekin siz oʻz paketlaringizni nashr(publish) qilish orqali kodingizni boshqa odamlar bilan ham baham koʻrishingiz mumkin. crates.io saytidagi crate registri paketlaringizning manba kodini tarqatadi, shuning uchun u birinchi navbatda open source kodni saqlaydi.
Rust va Cargoda publish etilgan paketingizni odamlar topishi va undan foydalanishini osonlashtiradigan funksiyalar mavjud. Biz ushbu xususiyatlarning ba'zilari haqida keyin gaplashamiz va keyin paketni qanday nashr(publish) qilishni tushuntiramiz.
Foydali hujjatlarga(documentation) sharhlar(comment) qo'yish
Paketlaringizni to'g'ri hujjatlashtirish boshqa foydalanuvchilarga ulardan qanday va qachon foydalanishni bilishga yordam beradi, shuning uchun texnik hujjatlarni yozish uchun vaqt sarflashga arziydi. 3-bobda biz Rust kodini ikkita slash // yordamida qanday izohlashni(comment) muhokama qildik. Rust shuningdek, HTML hujjatlarini yaratadigan documentation comment deb nomlanuvchi hujjatlar uchun o'ziga xos izohga ega. HTML sizning cratengiz qanday impelemnent qilinganidan farqli o'laroq, sizning cratengizdan qanday foydalanishni bilishga qiziqqan dasturchilar uchun mo'ljallangan umumiy API elementlari uchun hujjat sharhlari mazmunini ko'rsatadi.
Hujjatlarga sharhlar ikkita o'rniga uchta slashdan foydalaniladi, /// va matnni formatlash uchun Markdown notationni qo'llab-quvvatlaydi. Hujjatlarga sharhlarni ular hujjatlashtirilayotgan element oldiga qo'ying. 14-1 Ro'yxatda my_crate nomli cratedagi bir_qoshish funksiyasi uchun hujjat sharhlari ko'rsatilgan.
Fayl nomi: src/lib.rs
/// Berilgan raqamga bitta qo'shadi.
///
/// # Misollar
///
/// ```
/// let argument = 5;
/// let javob = my_crate::bir_qoshish(argument);
///
/// assert_eq!(6, javob);
/// ```
pub fn bir_qoshish(x: i32) -> i32 {
x + 1
}Ro'yxat 14-1: Funksiya uchun hujjat sharhi(documentation comment
Bu yerda biz bir_qoshish funksiyasi nima qilishini tavsiflab beramiz, Misollar sarlavhasi bilan bo‘limni boshlaymiz, so‘ngra bir_qoshish funksiyasidan qanday foydalanishni ko‘rsatadigan kodni taqdim etamiz. Biz ushbu hujjat sharhidan HTML hujjatlarini cargo docni ishga tushirish orqali yaratishimiz mumkin. Bu buyruq Rust bilan tarqatilgan rustdoc toolini ishga tushiradi va yaratilgan HTML hujjatlarini target/doc jildiga joylashtiradi.
Qulaylik uchun cargo doc --open ni ishga tushirish joriy crate hujjatlari uchun HTML-ni yaratadi (shuningdek, cratengizning barcha dependencilari uchun hujjatlar) va natijani veb-brauzerda ochadi. bir_qoshish funksiyasiga o‘ting va 14-1-rasmda ko‘rsatilganidek, hujjat sharhlaridagi matn qanday ko‘rsatilishini ko‘rasiz:
14-1-Rasm: bir_qoshish funksiyasi uchun HTML hujjatlari
Tez-tez ishlatiladigan bo'limlar
Biz HTML-da Misollar sarlavhali bo'lim yaratish uchun 14-1 ro'yxatdagi # Misollar Markdown sarlavhasidan foydalandik. Mualliflar o'z hujjatlarida tez-tez foydalanadigan boshqa bo'limlar:
- Panics: Hujjat yozilayotan funksiya senariylari panic qo'zg'atishi mumkin. O'z dasturlari panic qo'zg'ashini istamaydigan funksiyaning murojaat qiluvchilari bunday holatlarda funksiyani chaqirmasliklariga ishonch hosil qilishlari kerak.
- Errors: Agar funksiya
Resultni qaytarsa, yuzaga kelishi mumkin bo'lgan xatolar turlarini tavsiflash va bu xatolar qaytarilishiga qanday sharoitlar sabab bo'lishi mumkinligi murojaat qiluvchilar uchun foydali bo'lishi mumkin, shuning uchun ular turli xil xatolarni turli yo'llar bilan hal qilish uchun kod yozishlari mumkin. - Safety: Agar funksiya murojaat qilish uchun
unsafebo'lsa (biz 19-bobda xavfsizlikni muhokama qilamiz), funksiya nima uchun xavfli ekanligini tushuntiruvchi bo'lim bo'lishi kerak va funksiya murojaat qiluvchilar qo'llab-quvvatlashini kutayotgan o'zgarmaslarni qamrab oladi.
Ko'pgina hujjatlar sharhlari ushbu bo'limlarning barchasiga muhtoj emas, ammo bu sizning kodingiz foydalanuvchilari bilishni qiziqtiradigan jihatlarni eslatish uchun yaxshi nazorat ro'yxati.
Texnik hujjatlarga sharhlar test sifatida
Hujjatlarga sharhlaringizga(documentation comment) misol kod bloklarini qo'shish kutubxonangizdan(library) qanday foydalanishni ko'rsatishga yordam beradi va bu qo'shimcha bonusga ega bo'ladi: cargo test ishga tushirish hujjatlaringizdagi kod misollarini test sifatida ishga tushiradi! Hech narsa misollar bilan hujjatlashtirishdan yaxshiroq emas. Lekin hech narsa ishlamaydigan misollardan ko'ra yomonroq emas, chunki hujjatlar yozilgandan beri kod o'zgargan. Agar biz 14-1 roʻyxatdagi bir_qoshish funksiyasi uchun hujjatlar bilan cargo test oʻtkazsak, test natijalarida quyidagi boʻlimni koʻramiz:
Doc-tests my_crate
running 1 test
test src/lib.rs - bir_qoshish (line 5) ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.27s
Endi funksiyani yoki misolni, misoldagi assert_eq! panic qo'zg'atadigan tarzda o'zgartirsak va yana cargo test ishga tushirsak, hujjat testlari misol va kod bir-biri bilan sinxronlanmaganligini aniqlaymiz.!
O'z ichiga olgan elementlarni sharhlash
Hujjat sharhining uslubi //! hujjatni sharhlardan keyingi elementlarga emas, balki sharhlarni o'z ichiga olgan elementga qo'shadi. Biz odatda bu doc izohlaridan cratening ildiz(root) faylida (odatda src/lib.rs) yoki modul ichida crateni yoki butun modulni hujjatlash uchun foydalanamiz.
Masalan, bir_qoshish funksiyasini o'z ichiga olgan my_crate cratesi maqsadini tavsiflovchi hujjatlarni qo'shish uchun biz src/lib.rs faylining boshiga //! bilan boshlanadigan hujjat sharhlarini qo`shamiz, 14-2 ro'yxatda ko'rsatilganidek:
Fayl nomi: src/lib.rs
//! # Mening Crateyim
//!
//! `my_crate` - muayyan hisob-kitoblarni bajarishni qulayroq qilish uchun
//! yordamchi dasturlar to'plami.
/// Berilgan raqamga bitta qo'shadi.
// --snip--
///
/// # Misollar
///
/// ```
/// let argument = 5;
/// let javob = my_crate::bir_qoshish(argument);
///
/// assert_eq!(6, javob);
/// ```
pub fn bir_qoshish(x: i32) -> i32 {
x + 1
}Ro'yxat 14-2: Umuman olganda, my_crate cratesi uchun hujjatlar
E'tibor bering, //! bilan boshlanadigan oxirgi qatordan keyin hech qanday kod yo'q. Fikrlarni /// o'rniga //! bilan boshlaganimiz sababli, biz ushbu sharhdan keyingi elementni emas, balki ushbu sharhni o'z ichiga olgan elementni hujjatlashtirmoqdamiz. Bunday holda, bu element crate ildizi(root) bo'lgan src/lib.rs faylidir. Ushbu sharhlar butun crateni tasvirlaydi.
cargo doc --openni ishga tushirganimizda, bu izohlar 14-2-rasmda ko‘rsatilganidek, my_crate hujjatlarining birinchi sahifasida cratedagi public itemlar ro‘yxati ustida ko'rsatiladi:
14-2-rasm: my_crate uchun taqdim etilgan hujjatlar, jumladan, crateni bir butun sifatida tavsiflovchi sharh
Elementlar ichidagi hujjat sharhlari, ayniqsa, cratelar va modullarni tavsiflash uchun foydalidir. Foydalanuvchilarga cratening tashkil etilishini tushunishlariga yordam berish uchun konteynerning umumiy maqsadini tushuntirish uchun ulardan foydalaning.
pub use bilan qulay Public APIni eksport qilish
Public API structi crateni nashr qilishda muhim ahamiyatga ega. Sizning cratengizdan foydalanadigan odamlar structureni sizdan ko'ra kamroq bilishadi va agar sizning cratengiz katta modul ierarxiyasiga ega bo'lsa, ular foydalanmoqchi bo'lgan qismlarni topishda qiyinchiliklarga duch kelishlari mumkin.
7-bobda biz pub kalit so‘zi yordamida itemlarni qanday qilib hammaga ochiq(public) qilish va use kalit so‘zi bilan obyektlarni qamrovga(scope) kiritishni ko‘rib chiqdik.Biroq, crateni ishlab chiqishda sizga mantiqiy bo'lgan structure foydalanuvchilaringiz uchun unchalik qulay bo'lmasligi mumkin. Siz structlaringizni bir nechta darajalarni o'z ichiga olgan ierarxiyada tartibga solishni xohlashingiz mumkin, ammo keyin siz ierarxiyada chuqur aniqlagan turdan foydalanmoqchi bo'lgan odamlar ushbu tur mavjudligini aniqlashda muammolarga duch kelishlari mumkin.
Ular, shuningdek, use my_crate::FoydaliTur; o'rniga use my_crate::biror_modul::boshqa_modul::FoydaliTur; ni kiritishlari kerakligidan bezovtalanishi mumkin.
Yaxshi xabar shundaki, agar sturcture boshqa kutubxonadan(library) foydalanishi uchun qulay bo'lmasa, ichki organizationgizni o'zgartirishingiz shart emas: Buning o'rniga, pub use dan foydalanib, private structuredan farq qiladigan public structure yaratish uchun itemlarni qayta eksport qilishingiz mumkin. Qayta eksport qilish public ob'ektni bir joyda oladi va uni boshqa joyda hammaga ochiq(public) qiladi, go'yo u boshqa joyda aniqlangandek.
Masalan, badiiy tushunchalarni modellashtirish uchun rassom nomli kutubxona(library) yaratdik, deylik.
Ushbu kutubxona ichida ikkita modul mavjud: 14-3 roʻyxatda koʻrsatilganidek, AsosiyRang va IkkilamchiRang nomli ikkita raqamni oʻz ichiga olgan turlar moduli va aralashtirish nomli funksiyani oʻz ichiga olgan yordamchi moduli:
Fayl nomi: src/lib.rs
//! # Rassom
//!
//! Badiiy tushunchalarni modellashtirish uchun kutubxona.
pub mod turlar {
/// RYB rang modeliga muvofiq asosiy ranglar.
pub enum AsosiyRang {
Qizil,
Sariq,
Kok,
}
/// RYB rang modeliga muvofiq ikkinchi darajali ranglar.
pub enum IkkilamchiRang {
Qovoqrang,
Yashil,
Siyohrang,
}
}
pub mod yordamchi {
use crate::turlar::*;
/// Ikkilamchi rang yaratish uchun ikkita asosiy rangni teng
/// miqdorda birlashtiradi.
pub fn aralashtirish(c1: AsosiyRang, c2: AsosiyRang) -> IkkilamchiRang {
// --snip--
unimplemented!();
}
}Roʻyxat 14-3: turlar va yordamchi modullariga ajratilgan rassom kutubxonasi
14-3-rasmda cargo doc tomonidan yaratilgan ushbu crate uchun hujjatlarning bosh sahifasi qanday ko'rinishi ko'rsatilgan:
14-3-rasm: turlar va yordamchi modullari ro‘yxati keltirilgan rassom hujjatlarining bosh sahifasi
E'tibor bering, AsosiyRang va IkkilamchiRang turlari birinchi sahifada ko'rsatilmagan va aralashtirish funksiyasi ham mavjud emas. Ularni ko'rish uchun turlar va yordamchi ni bosishimiz kerak.
Ushbu kutubxonaga bog'liq bo'lgan boshqa cratega rassom dan elementlarni qamrab oladigan, hozirda aniqlangan modul stryucturedan ko'rsatadigan use statementlari kerak bo'ladi. 14-4 roʻyxatda rassom cratesidagi AsosiyRang va aralashtirish elementlaridan foydalanadigan crate misoli koʻrsatilgan:
Fayl nomi: src/main.rs
use art::turlar::AsosiyRang;
use rassom::yordamchi::aralashtirish;
fn main() {
let qizil = AsosiyRang::Qizil;
let yellow = AsosiyRang::Sariq;
aralashtirish(qizil, sariq);
}Roʻyxat 14-4: rassom crate itemlaridan foydalanilgan, ichki stuctureni eksport qilingan crate
rassom cratesidan foydalanadigan 14-4-Ro'yxatdagi kod muallifi AsosiyRang turlar modulida, aralashtirish esa yordamchi modulida ekanligini aniqlashi kerak edi. rassom cratening modul stucturesi undan foydalanadiganlarga qaraganda rassom crate ustida ishlayotgan developerlarga ko'proq mos keladi. The internal
structure doesn’t contain any useful information for someone trying to
understand how to use the art crate, but rather causes confusion because
developers who use it have to figure out where to look, and must specify the
module names in the use statements.
Ichki stuctureda rassom cratesidan qanday foydalanishni tushunishga urinayotganlar uchun foydali ma'lumotlar mavjud emas, aksincha, chalkashliklarga sabab bo'ladi, chunki undan foydalanadigan developerlar qayerga qarash kerakligini aniqlashlari kerak va use statementlarida modul nomlarini ko'rsatishi kerak.
Ichki organizationni public API’dan olib tashlash uchun biz 14-5 ro‘yxatda ko‘rsatilganidek, top leveldagi elementlarni qayta eksport qilish uchun pub use statementlarini qo‘shish uchun 14-3 ro‘yxatdagi rassom crate kodini o‘zgartirishimiz mumkin:
Fayl nomi: src/lib.rs
//! # Rassom
//!
//! Badiiy tushunchalarni modellashtirish uchun kutubxona.
pub use self::turlar::AsosiyRang;
pub use self::turlar::IkkilamchiRang;
pub use self::yordamchi::aralashtirish;
pub mod turlar {
// --snip--
/// RYB rang modeliga muvofiq asosiy ranglar.
pub enum AsosiyRang {
Qizil,
Sariq,
Kok,
}
/// RYB rang modeliga muvofiq ikkinchi darajali ranglar.
pub enum IkkilamchiRang {
Qovoqrang,
Yashil,
Siyohrang,
}
}
pub mod yordamchi {
// --snip--
use crate::turlar::*;
/// Ikkilamchi rang yaratish uchun ikkita asosiy rangni teng
/// miqdorda birlashtiradi.
pub fn aralashtirish(c1: AsosiyRang, c2: AsosiyRang) -> IkkilamchiRang {
IkkilamchiRang::Qovoqrang
}
}Ro'yxat 14-5: Elementlarni qayta eksport qilish uchun pub use statementlarini qo'shish
Ushbu crate uchun cargo doc yaratadigan API hujjatlari Endi 14-4-rasmda ko'rsatilganidek, re-exportlarni birinchi sahifada listga oling va bog'lang, bu AsosiyRang va IkkilamchiRang turlarini va aralashtirish funksiyasini topishni osonlashtiradi.

14-4-rasm: re-exportlar ro'yxati keltirilgan rassom hujjatlarining birinchi sahifasi
rassom crate foydalanuvchilari hali ham 14-4 roʻyxatda koʻrsatilganidek, 14-3 roʻyxatdagi ichki(internal) structureni koʻrishlari va foydalanishlari mumkin yoki ular 14-6 roʻyxatda koʻrsatilganidek, 14-5 roʻyxatdagi qulayroq structuredan foydalanishlari mumkin:
Fayl nomi: src/main.rs
use rassom::aralashtirish;
use rassom::AsosiyRang;
fn main() {
// --snip--
let qizil = AsosiyRang::qizil;
let sariq = AsosiyRang::Sariq;
mix(qizil, sariq);
}Ro'yxat 14-6: rassom cratesidan re-export(qayta eksport) qilingan itemlarni ishlatadigan dastur
Ko'plab ichki modullar mavjud bo'lsa, pub use bilan top leveldagi turlarni qayta eksport(re-export) qilish cratedan foydalanadigan foydalanuvchilar tajribasida sezilarli o'zgarishlarga olib kelishi mumkin. pub use ning yana bir keng tarqalgan qoʻllanilishi bu crate deifinationlarini cratengizning public API qismiga aylantirish uchun joriy cratedagi dependency definitionlarini qayta eksport qilishdir.
Foydali public API stucturesini yaratish fandan ko'ra ko'proq san'atdir va siz foydalanuvchilaringiz uchun eng mos keladigan APIni topish uchun takrorlashingiz mumkin. pub use ni tanlash sizga cratengizni ichki stuctureda moslashuvchanlikni beradi va bu ichki stuctureni foydalanuvchilarga taqdim etgan narsadan ajratadi. O'rnatgan ba'zi cratelar kodlarini ko'rib chiqing, ularning ichki tuzilishi(internal structure) public APIdan farq qiladimi yoki yo'qmi.
Crates.io da account sozlash
Har qanday cratelarni nashr qilishdan oldin crates.io saytida hisob(account) yaratishingiz va API tokenini olishingiz kerak.
Buning uchun crates.io saytidagi bosh sahifaga tashrif buyuring va GitHub hisob qaydnomasi(account) orqali tizimga kiring. (GitHub hisobi hozirda talab hisoblanadi, ammo sayt kelajakda hisob yaratishning boshqa usullarini qo'llab-quvvatlashi mumkin.), Tizimga kirganingizdan so'ng,https://crates.io/me/ sahifasidagi hisob sozlamalariga tashrif buyuring va API kalitingizni(key) oling. Keyin API kalitingiz bilan cargo login buyrug'ini bajaring, masalan:
$ cargo login abcdefghijklmnopqrstuvwxyz012345
Bu buyruq Cargoga API tokeningiz haqida xabar beradi va uni ~/.cargo/credentials da saqlaydi. E'tibor bering, bu token secret: uni boshqa hech kim bilan baham ko'rmang. Agar biron-bir sababga ko'ra uni kimdir bilan baham ko'rsangiz, uni bekor qilishingiz va crates.io saytida yangi token yaratishingiz kerak.
Yangi cratega metadata qo'shish
Aytaylik, sizda nashr qilmoqchi bo'lgan cratengiz bor. Nashr qilishdan oldin cratening Cargo.toml faylining [package] boʻlimiga metamaʼlumotlar qoʻshishingiz kerak boʻladi.
Sizning cratengizga noyob nom kerak bo'ladi. Mahalliy(local) miqyosda crate ustida ishlayotganingizda, cratega xohlaganingizcha nom berishingiz mumkin. Biroq, crates.io saytidagi crate nomlari birinchi kelganda, birinchi navbatda beriladi. Crate nomi olingandan so'ng, boshqa hech kim bu nom bilan crateni nashr eta olmaydi. Crateni nashr etishga urinishdan oldin foydalanmoqchi bo'lgan nomni qidiring. Agar nom ishlatilgan bo'lsa, nashr qilish uchun yangi nomdan foydalanish uchun boshqa nom topib, Cargo.toml faylida [package] bo'limi ostidagi name maydonini tahrirlashingiz kerak bo'ladi:
Fayl nomi: Cargo.toml
[package]
name = "kalkulyator"
Noyob nom tanlagan bo'lsangiz ham, ushbu nuqtada crateni nashr qilish uchun cargo publish ni ishga tushirganingizda, siz ogohlantirish va keyin xatolikni olasiz:
$ cargo publish
Updating crates.io index
warning: manifest has no description, license, license-file, documentation, homepage or repository.
See https://doc.rust-lang.org/cargo/reference/manifest.html#package-metadata for more info.
--snip--
error: failed to publish to registry at https://crates.io
Caused by:
the remote server responded with an error: missing or empty metadata fields: description, license. Please see https://doc.rust-lang.org/cargo/reference/manifest.html for how to upload metadata
Bu xato, chunki sizda ba'zi muhim ma'lumotlar yetishmayapti: tavsif(description) va litsenziya talab qilinadi, shunda foydalanuvchilar sizning cratengiz nima qilishini va undan qanday shartlar ostida foydalanishlari mumkinligini bilishlari mumkin. Cargo.toml ga bir yoki ikki jumladan iborat tavsif(description) qo'shing, chunki u qidiruv natijalarida cratengiz bilan birga ko'rinadi. license maydoni uchun siz litsenziya identifikatorining qiymatini berishingiz kerak. Linux
Foundation’s Software Package Data Exchange (SPDX) ushbu qiymat uchun foydalanishingiz mumkin bo'lgan identifikatorlarni sanab o'tadi. Masalan, MIT litsenziyasidan foydalangan holda cratengizni litsenziyalaganingizni ko'rsatish uchun MIT identifikatorini qo'shing:
Fayl nomi: Cargo.toml
[package]
name = "kalkulyator"
license = "MIT"
Agar siz SPDX da ko'rinmaydigan litsenziyadan foydalanmoqchi bo'lsangiz, ushbu litsenziya matnini faylga joylashtirishingiz, faylni loyihangizga kiritishingiz kerak, va keyin license kalitidan foydalanish oʻrniga oʻsha fayl nomini koʻrsatish uchun license-file dan foydalaning.
Loyihangiz uchun qaysi litsenziya to'g'ri kelishi haqidagi ko'rsatmalar ushbu kitob doirasidan tashqarida. Rust hamjamiyatidagi(community) ko'p odamlar o'z loyihalarini Rust bilan bir xil tarzda MIT OR Apache-2.0 qo'sh litsenziyasidan foydalangan holda litsenziyalashadi. Ushbu amaliyot shuni ko'rsatadiki, loyihangiz uchun bir nechta litsenziyaga ega bo'lish uchun OR bilan ajratilgan bir nechta litsenziya identifikatorlarini ham belgilashingiz mumkin.
Noyob nom, versiya, tavsif(description) va litsenziya qoʻshilgan holda nashr etishga tayyor boʻlgan loyiha uchun Cargo.toml fayli quyidagicha koʻrinishi mumkin:
Fayl nomi: Cargo.toml
[package]
name = "kalkulyator"
version = "0.1.0"
edition = "2021"
description = "Sanoq tizimlari bilan ishlaydigan kalkulyator"
license = "MIT OR Apache-2.0"
[dependencies]
Cargo hujjatlarida boshqalar sizning cratengizni osongina topishi va undan foydalanishi uchun siz belgilashingiz mumkin bo'lgan boshqa metama'lumotlar tasvirlangan.
Crates.io-da nashr qilish
Endi siz hisob(account) yaratdingiz, API tokeningizni saqladingiz, cratengiz uchun nom tanladingiz va kerakli metamaʼlumotlarni koʻrsatdingiz, siz nashr(publish) qilishga tayyorsiz! Crateni nashr qilish boshqalar foydalanishi uchun crates.io saytiga ma'lum bir versiyani yuklaydi.
Ehtiyot bo'ling, chunki nashr doimiydir(permanent). Versiyani hech qachon qayta yozib bo'lmaydi va kodni o'chirib bo'lmaydi.crates.io -ning asosiy maqsadlaridan biri doimiy kod arxivi bo'lib xizmat qilishdir, shunda crates.io-dan cratelarga bog'liq bo'lgan barcha loyihalar o'z ishini davom ettiradi. Versiyani o'chirishga ruxsat berish bu maqsadni amalga oshirishni imkonsiz qiladi. Biroq, siz nashr(publish) etishingiz mumkin bo'lgan crate versiyalari soniga cheklov yo'q.
cargo publish buyrug'ini qayta ishga tushiring. Endi u muvaffaqiyatli bo'lishi kerak:
$ cargo publish
Updating crates.io index
Packaging kalkulyator v0.1.0 (file:///projects/kalkulyator)
Verifying kalkulyator v0.1.0 (file:///projects/kalkulyator)
Compiling kalkulyator v0.1.0
(file:///projects/kalkulyator/target/package/kalkulyator-0.1.0)
Finished dev [unoptimized + debuginfo] target(s) in 0.19s
Uploading kalkulyator v0.1.0 (file:///projects/kalkulyator)
Tabriklaymiz! Siz endi kodingizni Rust hamjamiyatiga(community) ulashdingiz va har kim o'z loyihasiga dependency sifatida cratengizni osongina qo'shishi mumkin.
Mavjud cratening yangi versiyasini nashr qilish
Cratengizga oʻzgartirishlar kiritib, yangi versiyani chiqarishga tayyor boʻlgach, Cargo.toml faylida koʻrsatilgan version qiymatini oʻzgartirasiz va qayta nashr qilasiz. Siz kiritgan o'zgartirishlar turiga qarab keyingi versiya raqami qanday bo'lishini aniqlash uchun semantik versiya qoidalaridan foydalaning.
Keyin yangi versiyani yuklash uchun cargo publishni ishga tushiring.
Crates.io-dan cargo yank bilan eskirgan versiyalar
Cratening oldingi versiyalarini olib tashlamasangiz ham, kelajakdagi loyihalarni ularni yangi dependency sifatida qo'shishning oldini olishingiz mumkin. Bu crate versiyasi bir yoki boshqa sabablarga ko'ra buzilganda foydalidir. Bunday vaziyatlarda Cargo crate versiyasini yanking(tortib) olishni qo'llab-quvvatlaydi.
Versiyani yanking o'zgartirish yangi loyihalarning ushbu versiyaga bog'lanishiga to'sqinlik qiladi, lekin shunga qaramay, unga bog'liq bo'lgan barcha mavjud loyihalarni ishlashni davom ettirishga imkon beradi. Aslini olganda, yank degani Cargo.lock bilan barcha loyihalar buzilmasligini va kelajakda yaratilgan Cargo.lock fayllari yanked versiyasidan foydalanmasligini anglatadi.
Cratening versiyasini tortib olish uchun siz avval nashr qilgan crate jildida cargo yank ni ishga tushiring va qaysi versiyani yank qilishni belgilang. Misol uchun, agar biz kalkulyator nomli 1.0.1 versiyasini chop etgan bo'lsak va biz uni yank qilib olmoqchi bo'lsak, kalkulyator loyihasi jildida biz quyidagi amllarni bajaramiz:
$ cargo yank --vers 1.0.1
Updating crates.io index
Yank kalkulyator@1.0.1
Buyruqga --undo ni qo'shish orqali siz yank ni bekor qilishingiz va loyihalarni versiyaga qarab qaytadan boshlashga ruxsat berishingiz mumkin:
$ cargo yank --vers 1.0.1 --undo
Updating crates.io index
Unyank kalkulyator@1.0.1
Yank hech qanday kodni o'chirmaydi. U, masalan, tasodifan yuklangan secretlarni o'chira olmaydi. Agar bu sodir bo'lsa, siz ushbu secretlarni darhol tiklashingiz kerak.
Cargo Workspacelar
12-bobda biz bianry crate va kutubxona cratesini o'z ichiga olgan paketni yaratdik. Loyihangiz rivojlanib borgan sari, kutubxona(library) cratesi kattalashib borishini va paketingizni bir nechta kutubxona cratelariga bo'lishni xohlayotganingizni ko'rishingiz mumkin. Cargo tandemda ishlab chiqilgan bir nechta tegishli paketlarni boshqarishga yordam beradigan workspaces deb nomlangan xususiyatni taklif etadi.
Workspace yaratish
workspace - bu bir xil Cargo.lock va output(chiqish) jildiga ega bo'lgan paketlar to'plami. Keling, workspcedan foydalangan holda loyiha yarataylik - biz workspacening tuzilishiga e'tibor qaratishimiz uchun arzimas koddan foydalanamiz. Workspaceni tuzishning bir necha yo'li mavjud, shuning uchun biz faqat bitta umumiy usulni ko'rsatamiz. Binary(ikkilik) va ikkita kutubxonani o'z ichiga olgan workspacega ega bo'lamiz. Asosiy funksionallikni ta'minlaydigan binary ikkita kutubxonaga bog'liq bo'ladi. Bitta kutubxona bitta_qoshish funksiyasini, ikkinchi kutubxona esa ikkita_qoshish funksiyasini taqdim etadi.
Ushbu uchta crate bir xil workspacening bir qismi bo'ladi. Biz workspaceni uchun yangi jild yaratishdan boshlaymiz:
$ mkdir qoshish
$ cd qoshish
Keyinchalik, qoshuvchi jildida biz butun workspaceni sozlaydigan Cargo.toml faylini yaratamiz. Bu faylda [package] boʻlimi boʻlmaydi.
Buning o'rniga, u binary(ikkilik) crate yordamida paketga yo'lni ko'rsatib, workspacega a'zolar qo'shish imkonini beruvchi [workspace] bo'limidan boshlanadi; bu holda, bu yo'l qoshuvchi:
Fayl nomi: Cargo.toml
[workspace]
members = [
"qoshuvchi",
]
Keyin, qoshuvchi jilida cargo new ni ishga tushirish orqali qoshuvchi binary cratesini yaratamiz:
$ cargo new qoshuvchi
Created binary (application) `qoshuvchi` package
Ushbu nuqtada biz cargo build ni ishga tushirish orqali worksoaceni qurishimiz mumkin. Sizning qoshuvchi jildingiz quyidagicha ko'rinishi kerak:
├── Cargo.lock
├── Cargo.toml
├── qoshuvchi
│ ├── Cargo.toml
│ └── src
│ └── main.rs
└── target
Workspaceda kompilyatsiya qilingan artefaktlar joylashtiriladigan top leveldagi bitta target jildi mavjud; qoshuvchi paketi o'zining target jildiga ega emas. Agar biz qoshuvchi jildi ichidan cargo buildni ishga tushirsak ham, kompilyatsiya qilingan artefaktlar hali ham qoshish/qoshuvchi/target emas, balki qoshish/target da tugaydi. Cargo workspacedagi target jildini shunday tuzadi, chunki workspacedagi cratelar bir-biriga bog'liq bo'lishi kerak. Agar har bir crate o'zining target jildiga ega bo'lsa, har bir crate artefaktlarni o'zining target jildiga joylashtirish uchun workspacedagi boshqa cratelarning har birini qayta kompilyatsiya qilishi kerak edi. Bitta target jildini baham ko'rish(share) orqali cratelar keraksiz rebuildingdan qochishi mumkin.
Workspaceda ikkinchi paketni yaratish
Keyinchalik, workspaceda boshqa a'zolar(member) paketini yaratamiz va uni bitta_qoshish deb nomlaymiz. members ro'yxatida bitta_qoshish yo'lini belgilash uchun top leveldagi Cargo.toml ni o'zgartiring:
Fayl nomi: Cargo.toml
[workspace]
members = [
"qoshuvchi",
"bitta_qoshish",
]
Keyin bitta_qoshish nomli yangi kutubxonalibrary cratesini yarating:
$ cargo new bitta_qoshish --lib
Created library `bitta_qoshish` package
Sizning qoshish jildingizda endi quyidagi jild va fayllar bo‘lishi kerak:
├── Cargo.lock
├── Cargo.toml
├── bitta_qoshish
│ ├── Cargo.toml
│ └── src
│ └── lib.rs
├── qoshuvchi
│ ├── Cargo.toml
│ └── src
│ └── main.rs
└── target
bitta_qoshish/src/lib.rs fayliga bitta_qoshish funksiyasini qo'shamiz:
Fayl nomi: bitta_qoshish/src/lib.rs
pub fn bitta_qoshish(x: i32) -> i32 {
x + 1
}Endi biz kutubxonamizga ega bo'lgan bitta_qoshish paketiga bog'liq bo'lgan qoshuvchi paketiga ega bo'lishimiz mumkin. Birinchidan, biz qoshuvchi/Cargo.toml ga bitta_qoshish yo'liga bog'liqlikni qo'shishimiz kerak.
Fayl nomi: qoshuvchi/Cargo.toml
[dependencies]
bitta_qoshish = { path = "../bitta_qoshish" }
Cargo workspacedagi cratelar bir-biriga bog'liq bo'ladi deb o'ylamaydi, shuning uchun biz qaramlik munosabatlari(relationship) haqida aniq bo'lishimiz kerak.
Keyin, keling, qoshuvchi cratedagi bitta_qoshish funksiyasidan (bitta_qoshish cratesidan) foydalanamiz. qoshuvchi/src/main.rs faylini oching va yangi bitta_qoshish kutubxona cratesini qamrab olish uchun tepaga use qatorini qo'shing. Keyin 14-7 roʻyxatdagi kabi bitta_qoshish funksiyasini chaqirish uchun main funksiyani oʻzgartiring.
Fayl nomi: qoshuvchi/src/main.rs
use bitta_qoshish;
fn main() {
let raqam = 10;
println!("Salom, Rust! {raqam} plyus bir {} ga teng!", bitta_qoshish::bitta_qoshish(raqam));
}Roʻyxat 14-7: bitta_qoshish kutubxonasi cratesidan qoshish cratesidan foydalanish
Keling, yuqori darajadagi qoshish jildida cargo buildni ishga tushirish orqali workspaceni build qilaylik!
$ cargo build
Compiling bitta_qoshish v0.1.0 (file:///projects/qoshish/bitta_qoshish)
Compiling qoshuvchi v0.1.0 (file:///projects/qoshish/qoshuvchi)
Finished dev [unoptimized + debuginfo] target(s) in 0.68s
Binary crateni qoshish jildidan ishga tushirish uchun biz -p argumenti va cargo run bilan paket nomidan foydalanib workspaceda qaysi paketni ishga tushirishni belgilashimiz mumkin:
$ cargo run -p qoshuvchi
Finished dev [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/qoshuvchi`
Salom, Rust! 10 plyus bir 11 ga teng!
Bu kodni qoshuvchi/src/main.rs da ishga tushiradi, bu bitta_qoshish cratesiga bog'liq.
Workspacedagi tashqi(external) paketga bog'liqlik
E'tibor bering, workspaceda har bir crate jildida Cargo.lock emas, balki top leveldagi faqat bitta Cargo.lock fayli mavjud. Bu barcha cratelar barcha depencilarning(bog'liqlik) bir xil versiyasidan foydalanishini ta'minlaydi. Agar biz qoshuvchi/Cargo.toml va bitta_qoshish/Cargo.toml fayllariga rand paketini qo'shsak, Cargo ikkalasini ham rand ning bitta versiyasida hal qiladi va buni bitta Cargo.lockda qayd etadi. Workspacedagi barcha cratelarni bir xil depensilardan foydalanishga aylantirish, cratelarning har doim bir-biriga mos kelishini anglatadi. Keling, bitta_qoshish/Cargo.toml faylidagi [dependencies] bo'limiga rand cratesini qo'shamiz, shunda biz bitta_qoshish cratesida rand cratesidan foydalanishimiz mumkin:
Fayl nomi: bitta_qoshish/Cargo.toml
[dependencies]
rand = "0.8.5"
Endi biz bitta_qoshish/src/lib.rs fayliga use rand; ni qo'shishimiz mumkin va qoshish jildida cargo build-ni ishga tushirish orqali butun workspaceni build qilish rand cratesini olib keladi va kompilyatsiya qiladi. Biz bitta ogohlantirish olamiz, chunki biz qamrab olgan rand ni nazarda tutmayapmiz:
$ cargo build
Updating crates.io index
Downloaded rand v0.8.5
--snip--
Compiling rand v0.8.5
Compiling bitta_qoshish v0.1.0 (file:///projects/qoshish/bitta_qoshish)
warning: unused import: `rand`
--> bitta_qoshish/src/lib.rs:1:5
|
1 | use rand;
| ^^^^
|
= note: `#[warn(unused_imports)]` on by default
warning: `bitta_qoshish` (lib) generated 1 warning
Compiling qoshuvchi v0.1.0 (file:///projects/qoshish/qoshuvchi)
Finished dev [unoptimized + debuginfo] target(s) in 10.18s
Top leveldagi Cargo.lock endi bitta_qoshish rand ga bog'liqligi(dependency) haqida ma'lumotni o'z ichiga oladi. Biroq, workspacening biror joyida rand ishlatilsa ham, ularning Cargo.toml fayllariga rand qo'shmagunimizcha, biz uni workspacedagi boshqa cratelarda ishlata olmaymiz. Masalan, agar biz qoshuvchi paketi uchun qoshuvchi/src/main.rs fayliga use rand; qo'shsak, xatoga duch kelamiz:
$ cargo build
--snip--
Compiling qoshuvchi v0.1.0 (file:///projects/qoshish/qoshuvchi)
error[E0432]: unresolved import `rand`
--> qoshuvchi/src/main.rs:2:5
|
2 | use rand;
| ^^^^ no external crate `rand`
Buni tuzatish uchun qoshuvchi paketi uchun Cargo.toml faylini tahrirlang va rand ham unga dependency(bog'liqligini) ekanligini ko'rsating. qoshuvchi paketini yaratish Cargo.lock dagi qoshuvchi uchun depensiar ro'yxatiga rand qo'shadi, lekin rand ning qo'shimcha nusxalari yuklab olinmaydi. Cargo rand paketidan foydalangan holda workspacedagi har bir cratedagi har bir crate bir xil versiyadan foydalanishini taʼminladi, bu bizga joyni tejaydi va workspacedagi cratelar bir-biriga mos kelishini taʼminlaydi.
Workspacega test qo'shish
Yana bir yaxshilanish uchun, keling, bitta_qoshish cratesidagi bitta_qoshish::bitta_qoshish funksiyasi testini qo'shamiz:
Fayl nomi: bitta_qoshish/src/lib.rs
pub fn bitta_qoshish(x: i32) -> i32 {
x + 1
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn ishlamoqda() {
assert_eq!(3, bitta_qoshish(2));
}
}Top-leveldagi qoshish jildida cargo test-ni ishga tushiring. Shunga o'xshash tuzilgan workspaceda cargo test ni o'tkazish workspacedagi barcha cratelar uchun testlarni o'tkazadi:
$ cargo test
Compiling bitta_qoshish v0.1.0 (file:///projects/qoshish/bitta_qoshish)
Compiling adder v0.1.0 (file:///projects/qoshish/qoshuvchi)
Finished test [unoptimized + debuginfo] target(s) in 0.27s
Running unittests src/lib.rs (target/debug/deps/bitta_qoshish-f0253159197f7841)
running 1 test
test tests::ishlamoqda ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/qoshuvchi-49979ff40686fa8e)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests bitta_qoshish
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Chiqishning(output) birinchi qismida bitta_qoshish cratesidagi ishlamoqda testi muvaffaqiyatli o'tganligi ko'rsatilgan. Keyingi bo'limda qoshuvchi cratesida nol testlar topilganligi ko'rsatilgan, so'ngra oxirgi bo'lim bitta_qoshish cratesida nol hujjat testlari topilganligini ko'rsatadi.
Bundan tashqari, biz top leveldagi jilddan -p flagidan foydalanib va biz test qilib ko'rmoqchi bo'lgan crate nomini ko'rsatib, workspacedagi ma'lum bir crate uchun testlarni o'tkazishimiz mumkin:
$ cargo test -p bitta_qoshish
Finished test [unoptimized + debuginfo] target(s) in 0.00s
Running unittests src/lib.rs (target/debug/deps/bitta_qoshish-b3235fea9a156f74)
running 1 test
test tests::ishlamoqda ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests bitta_qoshish
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Bu chiqishda cargo test koʻrsatilgan, faqat bitta_qoshish cratesi uchun stestlar oʻtkazilgan va qoshuvchi cratesi testlari oʻtkazilmagan.
Agar siz workspacedagi cratelarni crates.io-ga nashr(publish) qilsangiz, workspacedagi har bir crate alohida nashr etilishi kerak bo'ladi.
cargo test singari, biz p flagidan foydalanib va nashr qilmoqchi bo'lgan crate nomini ko'rsatib, workspacemizda ma'lum bir crateni nashr qilishimiz mumkin.
Qo'shimcha mashq qilish uchun ushbu workspacega bitta_qoshish cratesga o'xshash ikkita_qoshish cratesini qo'shing!
Loyihangiz o'sib ulg'aygan sayin, workspacedan foydalanishni o'ylab ko'ring: bitta katta kod blokidan ko'ra kichikroq, individual komponentlarni tushunish osonroq. Bundan tashqari, cratelarni workspaceda saqlash, agar ular bir vaqtning o'zida tez-tez almashtirilsa, cratelar orasidagi muvofiqlashtirishni osonlashtirishi mumkin.
Binary(ikkilik) fayllarni cargo install bilan o'rnatish
cargo install buyrug'i binary cratelarni mahalliy(local) sifatida o'rnatish va ishlatish imkonini beradi. Bu tizim paketlarini almashtirish uchun mo'ljallanmagan; Bu Rust dasturchilari uchun crates.io saytida boshqalar baham ko'rgan toollarni o'rnatishning qulay usuli bo'lishi kerak. E'tibor bering, siz faqat binary targetlarga ega bo'lgan paketlarni o'rnatishingiz mumkin. binary target bu o'z-o'zidan ishga tushirilmaydigan, lekin mos bo'lgan kutubxona(library) targetdidan farqli o'laroq, src/main.rs fayli yoki cratening bir qismi sifatida bajariladigan boshqa faylni o'z ichiga olgan bajariladigan dastur. Boshqa dasturlarga kiritish uchun. Odatda, cratelar README faylida crate va kutubxona ekanligi, binary targetli yoki har ikkalasi haqida ma'lumotga ega.
cargo install bilan o'rnatilgan barcha binary fayllar o'rnatish ildizining(root) bin jildida saqlanadi. Rust-ni rustup.rs yordamida o'rnatgan bo'lsangiz va hech qanday maxsus konfiguratsiyaga ega bo'lmasangiz, bu jild $HOME/.cargo/bin bo'ladi. cargo install bilan oʻrnatgan dasturlarni ishga tushirish uchun jildingiz $PATHda ekanligiga ishonch hosil qiling.
Masalan, 12-bobda biz fayllarni qidirish uchun ripgrep deb nomlangan grep toolining Rust ilovasi mavjudligini eslatib o'tdik. Keling ripgrep ni o'rnatish uchun biz quyidagilarni ishga tushirishimiz mumkin:
$ cargo install ripgrep
Updating crates.io index
Downloaded ripgrep v13.0.0
Downloaded 1 crate (243.3 KB) in 0.88s
Installing ripgrep v13.0.0
--snip--
Compiling ripgrep v13.0.0
Finished release [optimized + debuginfo] target(s) in 3m 10s
Installing ~/.cargo/bin/rg
Installed package `ripgrep v13.0.0` (executable `rg`)
Chiqishning ikkinchidan oxirgi qatori o'rnatilgan binary faylning joylashuvi va nomini ko'rsatadi, bu ripgrep holatida rgdir. O'rnatish jildi $PATH da bo'lsa, avval aytib o'tilganidek, siz rg --help ni ishga tushirishingiz va fayllarni qidirish uchun tezroq, rustda kuchidan foydalanib yozilgan tooldan foydalanishni boshlashingiz mumkin!
Maxsus buyruqlar bilan cargoni kengaytirish
Cargo cargoni o'zini o'zgartirmasdan, uni yangi kichik buyruqlar bilan kengaytirishingiz uchun mo'ljallangan. Agar $PATH-dagi binary fayl cargo-birnarsa deb nomlangan bo'lsa, uni cargo birnarsasini ishga tushirish orqali uni Cargo kichik buyrug'i kabi ishga tushirishingiz mumkin. Bu kabi maxsus buyruqlar cargo --list ishga tushirilganda ham ro'yxatga olinadi. Kengaytmalarni(extension) o'rnatish va keyin ularni xuddi o'rnatilgan Cargo toollari kabi ishga tushirish uchun cargo install dan foydalanish imkoniyati Cargo dizaynining o'ta qulay afzalligidir!
Xulosa
Cargo va crates.io bilan kod almashish Rust ekotizimini turli xil vazifalar uchun foydali qiladigan dizaynning bir qismidir. Rustning standart kutubxonasi(standard library) kichik va barqaror(stable), lekin cratelarni almashish(share), ishlatish va tildagidan farqli vaqt jadvalida yaxshilash oson. crates.io saytida sizga foydali bo'lgan kodni baham(share) ko'rishdan uyalmang, ehtimol u boshqa birovga ham foydali bo'lishi mumkin!
Smart Pointerlar
Pointer bu xotirada biror manzilni o'z ichiga olgan o'zgaruvchi uchun umumiy
tushuncha. Ushbu manzil biror boshqa ma'lumotga ishora qiladi. Rustda eng keng
tarqalgan pointer turi bu siz 4-bobda o'rgangan reference hisoblanadi.
Referencelar & belgisi bilan ko'rsatiladi va qaratilgan qiymatni qarzga oladi.
Ularning ma'lumotga murojaat qilishdan boshqa hech qanday maxsus qobiliyati
bo'lmaydi.
Smart pointerlar esa pointer kabi ishlaydigan, lekin qo'shimcha metama'lumotlar va imkoniyatlarga ega ma'lumot tuzilmalaridir. Smart pointerlar tushunchasi faqatgina Rustda yagona emas: smart pointerlar C++da paydo bo'lgan va boshqa tillarda ham mavjud. Rust standart kutubxonasi taqdim etadigan turli xil smart pointerlarga ega bo'lib, ular referencelardan tashqari funksionallikni ta'minlaydi. Umumiy tushunchani o'rganish uchun biz smart pointerlarning bir nechta turli misollarini ko'rib chiqamiz, jumladan reference hisoblash smart pointer turi. Ushbu pointer sizga egalar sonini kuzatish orqali ma'lumotning bir nechta egalari bo'lish imkonini beradi va egalari qolmaganda ma'lumotni tozalaydi.
Rust o'zining egalik va qarz olish tushunchasi bilan referencelar va smart pointerlar o'rtasida qo'shimcha farqga ega: referencelar faqat ma'lumotlarni qarzga olsa, ko'p hollarda smart pointerlar ma'lumotga egalik qiladilar.
Garchi biz ularni o‘sha paytda shunday deb atamagan bo‘lsak-da, biz ushbu
kitobda bir nechta smart pointerlarga duch keldik, jumladan, 8-bobdagi String
va Vec<T>. Bu ikkala tur ham smart pointer hisoblanadi, chunki u biror
xotiraga egalik qiladi va sizga uni manipulyatsiya qilish imkonini beradi.
Shuningdek, ularda metama'lumot va qo'shimcha imkoniyatlar yoki kafolatlar
bo'ladi. Masalan, String o'z sig'imini metama'lumot sifatida saqlaydi va uning
ma'lumoti har doim UTF-8 bo'lishini ta'minlash uchun qo'shimcha xususiyatga ega.
Smart pointerlar odatda structlar yordamida amalga oshiriladi. Oddiy structdan
farqli o'laroq, smart pointerlar Deref va Drop traitlarini amalga oshiradi.
Deref traiti smart pointer struct-ning instancesiga reference kabi o'zini
tutish imkonini beradi, shunday qilib siz ikkala referencelar yoki smart
pointerlar bilan ishlash uchun kod yozishingiz mumkin. Drop traiti smart
pointerning instancesi scopedan chiqib ketganda ishga tushadigan kodni
moslashtirish imkonini beradi. Ushbu bobda biz ikkala traitni muhokama qilamiz
va nima uchun ular smart pointerlar uchun muhimligini ko'rsatamiz.
Smart pointer patterni Rustda tez-tez ishlatiladigan umumiy dizayn patterni ekanligini hisobga olsak, bu bobda mavjud bo'lgan barcha smart pointerlar qamrab olinmaydi. Ko'pgina kutubxonalarda o'zlarining smart pointerlari mavjud va siz hatto o'zingiznikini yozishingiz mumkin. Biz standart kutubxonadagi eng keng tarqalgan smart pointerlarni ko'rib chiqamiz:
Box<T>heapga qiymatlarni joylashtirish uchunRc<T>, bir nechta egalik qilish imkonini beruvchi referencelar hisoblash turiRef<T>vaRefMut<T>,RefCell<T>orqali kiriladi, bu qarz olish qoidalariga kompilyatsiya vaqti o'rniga runtimeda rioya qilishga majburlovchi tur
Bundan tashqari, biz ichki o'zgaruvchanlik patternini ko'rib chiqamiz, bunda o'zgarmas tur ichki qiymatni o'zgartirish uchun APIni ochib beradi. Shuningdek, biz reference davrlarini muhokama qilamiz: ular xotirani oqishiga olib kelishi va ularni qanday oldini olish mumkin.
Keling sho'ng'iymiz!
Heapdagi ma'lumotlarni ko'rsatish uchun Box<T> dan foydalanish
Eng sodda smart pointer bu box bo'lib, uning turi Box<T> deb yoziladi.
Boxlar sizga ma'lumotlarni stackda emas, balki heapda saqlashga imkon beradi.
Stackda esa heapdagi ma'lumotlariga pointer qoladi. Stack va heap o'rtasidagi
farqni ko'rib chiqish uchun 4-bobga qarang.
Boxlar o'z ma'lumotlarini stackda emas, balki heapda saqlashdan tashqari, ishlash bo'yicha qo'shimcha xarajatlarga ega emas. Lekin ularda ko'p qo'shimcha imkoniyatlar ham yo'q. Siz ulardan ko'pincha quyidagi holatlarda foydalanasiz:
- Agar sizda kompilyatsiya vaqtida o'lchami noma'lum bo'lgan tur mavjud bo'lsa va siz aniq o'lchamni talab qiladigan kontekstda ushbu turdagi qiymatdan foydalanmoqchi bo'lsangiz
- Agar sizda katta hajmdagi maʼlumotlar mavjud boʻlsa va siz egalik huquqini oʻtkazganingizda maʼlumotlardan nusxa olinmasligiga ishonch hosil qilmoqchi bo'lsangiz
- Agar siz biror qiymatga egalik qilmoqchi bo'lsangiz va siz uni ma'lum bir turda bo'lishiga emas, balki ma'lum bir traitni implement qiluvchi tur bo'lishi haqida qayg'ursangiz
Birinchi holatni “Rekursiv turlarni Boxlar bilan qo'llash” bo‘limida ko‘rsatamiz. Ikkinchi holatda, katta hajmdagi ma'lumotlarga egalik huquqini o'tkazish uzoq vaqt talab qilishi mumkin, chunki ma'lumotlar stackdan ko'chiriladi. Bunday vaziyatda ishlashni yaxshilash uchun biz katta hajmdagi ma'lumotlarni heapda box ichida saqlashimiz mumkin. Shundan so'ng, pointer ma'lumotlarining faqat kichik miqdori stackdan ko'chiriladi, heapdagi u reference qilingan ma'lumotlar esa bir joyda qoladi. Uchinchi holat trait object sifatida tanilgan va butun 17-bob shu mavzuga bag'ishlangan, “Turli turdagi qiymatlarga ruxsat beruvchi Trait Objectlaridan foydalanish” o'sha mavzu. Shunday qilib, bu erda o'rgangan narsalaringizni 17-bobda yana qo'llaysiz!
Heapda ma'lumotlarni saqlash uchun Box<T> dan foydalanish
Box<T> uchun heap xotiradan foydalanish holatini muhokama qilishdan oldin, biz
sintaksisni va Box<T> ichida saqlangan qiymatlar bilan qanday o'zaro aloqa
qilishni ko'rib chiqamiz.
15-1 ro'yxatda i32 qiymatini heapda saqlash uchun boxdan qanday foydalanish
ko'rsatilgan:
Fayl nomi: src/main.rs
fn main() { let b = Box::new(5); println!("b = {}", b); }
Ro'yxat 15-1: i32 qiymatini box yordamida heapda
saqlash
Biz b o'zgaruvchini heapda joylashgan 5ga point qiluvchi Box qiymatiga ega
bo'lishi uchun e'lon qilamiz. Ushbu dastur b = 5 ni chop etadi; bu holda biz
boxdagi ma'lumotlarga, stackda bo'lgani kabi kirishimiz mumkin. mainning
oxiridagi b kabi boxlar scopedan chiqib ketganda, xuddi egalik qilingan
qiymatlarga o'xshab, u ham xotiradan o'chiriladi. O'chirilish ham box (stackda
saqlanuvchi) uchun va u point qiluvchi ma'lumotlar (heapda saqlanuvchi) uchun
ham sodir bo'ladi.
Heapda bitta qiymat saqlash unchalik foydali emas, shuning uchun boxlarni o'zini
bu tarzda ko'pincha ishlatmaysiz. Ko'pincha holatlarda bitta i32 kabi
qiymatlarni stackda saqlash maqsadga muvofiq bo'ladi. Keling, boxlar, agar bizda
boxlar bo'lmasa, ruxsat berilmaydigan turlarni e'lon qilishga imkon beradigan
holatni ko'rib chiqaylik.
Rekursiv turlarni Boxlar bilan qo'llash
Rekursiv turning qiymati o'zining bir qismi sifatida bir xil turdagi boshqa qiymatga ega bo'lishi mumkin. Rekursiv turlar muammo tug'diradi, chunki kompilyatsiya vaqtida Rust tur qancha joy egallashini bilishi kerak. Biroq, rekursiv turdagi qiymatlarni joylashtirish nazariy jihatdan cheksiz davom etishi mumkin, shuning uchun Rust qiymat uchun qancha joy kerakligini bilmaydi. Boxlar ma'lum o'lchamga ega bo'lganligi sababli, biz rekursiv tur ta'rifiga box kiritish orqali rekursiv turlarni qo'llashimiz mumkin.
Rekursiv turga misol sifatida keling, cons listni o'rganamiz. Bu funktsional dasturlash tillarida keng tarqalgan ma'lumotlar turi hisoblanadi. Biz e'lon qiladigan cons list turi rekursiyadan tashqari sodda; shuning uchun biz ishlaydigan misoldagi tushunchalar rekursiv turlarni o'z ichiga olgan murakkab vaziyatlarga tushganingizda foydali bo'ladi.
Cons List haqida batafsil ma'lumot
Cons list Lisp dasturlash tili va uning dialektlaridan kelib chiqqan va
ichma-ich juftliklardan tashkil topgan maʼlumotlar strukturasi boʻlib, linked
listning Lispdagi versiyasi hisoblanadi. Uning nomi Lispdagi cons
funktsiyasidan (“construct function” uchun qisqartma) kelib chiqqan bo'lib,
uning ikkita argumentidan yangi juftlik yaratadi. Qiymat va boshqa juftlikdan
iborat bo'lgan juftlikda cons ni chaqirish orqali biz rekursiv juftliklardan
iborat bo'lgan cons list tuzishimiz mumkin.
Misol uchun, bu yerda 1, 2, 3 ro'yxatini o'z ichiga olgan cons listining psevdokod ko'rinishi, har bir juft qavs ichida:
(1, (2, (3, Nil)))
Cons listdagi har bir element ikkita elementni o'z ichiga oladi: shu elementning
qiymati va keyingi element. Ro'yxatning oxirgi elementida keyingi elementsiz
faqat Nil deb nomlangan qiymatdan iborat bo'ladi. Cons list cons
funksiyasini rekursiv chaqirish orqali hosil qilinadi. Rekursiyaning tubidagi
holatini bildiruvchi qoidaga aylangan nom Nil hisoblanadi. E'tibor bering, bu
6-bobdagi “null” yoki “nil” tushunchasi bilan bir xil emas, ya'ni noto'g'ri yoki
yo'q qiymat.
Cons list ma'lumotlar tuzilmasi Rust-da tez-tez ishlatilmaydi. Ko'pincha Rust-da
sizga elementlar ro'yxati kerak bo'lsa, Vec<T> foydalanish uchun yaxshiroq
tanlovdir. Boshqa, murakkabroq rekursiv ma'lumot turlaridan foyladanish bir
qancha vaziyatlarda foydalidir, ammo ushbu bobdagi cons listdan boshlab, boxlar
qanday qilib, rekursiv ma'lumot turini e'lon qilishga imkon berishini
o'rganishimiz mumkin.
Ro'yxat 15-2 cons list uchun enum ko'rinishini o'z ichiga oladi. E'tibor bering,
ushbu kod hali kompilyatsiya qilinmaydi, chunki List turi ma'lum hajmga ega
emas, biz buni tushuntiramiz.
Fayl nomi: src/main.rs
enum List {
Cons(i32, List),
Nil,
}
fn main() {}Ro'yxat 15-2: i32 qiymatlarining cons list ma'lumotlar
tuzilmasida ifodalash uchun enumni e'lon qilishga birinchi urish
Eslatma: Biz ushbu misol maqsadlari uchun faqat
i32qiymatlarini o'z ichiga olgan cons listni amalga oshirmoqdamiz. Biz 10-bobda muhokama qilganimizdek, har qanday turdagi qiymatlarni saqlashi mumkin bo'lgan cons list turini generiklar yordamida e'lon qilishimiz mumkin edi.
List turidan foydalanib 1, 2, 3 roʻyxatini saqlash 15-3 ro'yxat kabi
bo'ladi:
Fayl nomi: src/main.rs
enum List {
Cons(i32, List),
Nil,
}
use crate::List::{Cons, Nil};
fn main() {
let list = Cons(1, Cons(2, Cons(3, Nil)));
}15-3 roʻyxat: 1, 2, 3 roʻyxatini saqlash uchun List
enumidan foydalanish
Birinchi Cons qiymati 1 va boshqa List qiymatiga ega. Bu List qiymati
2 va boshqa List qiymatiga ega bo'lgan boshqa Cons qiymatidir. Ushbu
List qiymati 3 ni o'z ichiga olgan yana bitta Cons qiymati va List
qiymati, nihoyat Nil, ro'yxat oxirini bildiruvchi rekursiv bo'lmagan variant.
Agar biz 15-3 ro'yxatdagi kodni kompilyatsiya qilishga harakat qilsak, biz 15-4 ro'yxatda ko'rsatilgan xatoni olamiz:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
error[E0072]: recursive type `List` has infinite size
--> src/main.rs:1:1
|
1 | enum List {
| ^^^^^^^^^
2 | Cons(i32, List),
| ---- recursive without indirection
|
help: insert some indirection (e.g., a `Box`, `Rc`, or `&`) to break the cycle
|
2 | Cons(i32, Box<List>),
| ++++ +
For more information about this error, try `rustc --explain E0072`.
error: could not compile `cons-list` due to previous error
Ro'yxat 15-4: Rekursiv enumni e'lon qilishga urinishda yuzaga keladigan xato
Xato ushbu tur “cheksiz o'lchamga ega” ekanligini ko'rsatadi. Buning sababi
shundaki, biz Listni rekursiv variant bilan e'lon qildik: u bevosita o'zining
boshqa qiymatini saqlaydi. Natijada, Rust List qiymatini saqlash uchun qancha
joy kerakligini aniqlay olmaydi. Keling, nima uchun bu xatoga duch kelganimizni
qismlarga ajratamiz. Birinchidan, Rust rekursiv bo'lmagan turdagi qiymatni
saqlash uchun qancha joy kerakligini qanday hal qilishini ko'rib chiqamiz.
Rekursiv bo'lmagan turning o'lchamini hisoblash
6-bobda enum ta'riflarini muhokama qilganimizdagi 6-2 ro'yxatda e'lon qilingan
Xabar enumini eslang:
enum Xabar { Chiqish, Kochirish { x: i32, y: i32 }, Yozish(String), RangTanlash(i32, i32, i32), } fn main() {}
Xabar qiymati uchun qancha joy ajratish kerakligini aniqlash uchun Rust har
bir variantni ko'rib chiqadi va qaysi variantga ko'proq joy kerakligini
aniqlaydi. Rust Xabar::Chiqish uchun hech qanday joy kerak emasligini,
Xabar::Kochirish ikkita i32 qiymatini saqlash uchun yetarli joy kerakligini
aniqlaydi va hokazo. Faqat bitta variant qo'llanilishi sababli, Xabar
qiymatiga kerak bo'ladigan eng ko'p joy-bu uning eng katta variantini saqlash
uchun zarur bo'lgan joy hisoblanadi.
Rust 15-2 roʻyxatdagi List enum kabi rekursiv turga qancha boʻsh joy
kerakligini aniqlashga harakat qilganda nima sodir boʻlishini bu bilan
taqqoslang. Kompilyator i32 turidagi qiymat va List turidagi qiymatga ega
bo'lgan Cons variantini ko'rib chiqishdan boshlaydi. Shuning uchun, Cons
uchun i32 va List o'lchamiga teng bo'sh joy kerak bo'ladi. List turiga
qancha xotira kerakligini aniqlash uchun kompilyator Cons variantidan boshlab
variantlarni ko'rib chiqadi. Cons variantida i32 turidagi qiymat va List
turidagi qiymat mavjud va bu jarayon 15-1-rasmda ko'rsatilganidek, cheksiz davom
etadi.

15-1-rasm: Cheksiz Cons variantlaridan iborat cheksiz
List
O'lchami ma'lum bo'lgan rekursiv turni e'lon qilish uchun Box<T> dan foydalanish
Rust rekursiv e'lon qilingan turlar uchun qancha joy ajratish kerakligini aniqlay olmaganligi sababli, kompilyator ushbu foydali taklif bilan xatolik beradi:
help: insert some indirection (e.g., a `Box`, `Rc`, or `&`) to make `List` representable
|
2 | Cons(i32, Box<List>),
| ++++ +
Ushbu taklifda "indirection" qiymatni to'g'ridan-to'g'ri saqlash o'rniga, biz pointerni qiymatga saqlash orqali qiymatni bilvosita saqlash uchun ma'lumotlar strukturasini o'zgartirishimiz kerakligini anglatadi.
Box<T> pointer bo'lgani uchun Rust har doim Box<T> uchun qancha joy
kerakligini biladi: pointerning o'lchami u ko'rsatayotgan ma'lumotlar miqdoriga
qarab o'zgarmaydi. Bu shuni anglatadiki, biz to'g'ridan-to'g'ri boshqa List
qiymati o'rniga Cons variantiga Box<T> qo'yishimiz mumkin. Box<T> keyingi
List qiymatiga ishora qiladi, bu qiymat Cons varianti ichida emas, balki
heapda bo'ladi. G'oyaga ko'ra, bizda hali ham boshqa ro'yxatlarni o'z ichiga
olgan ro'yxatlar bilan yaratilgan ro'yxat mavjud, ammo bu amalga oshirish endi
elementlarni bir-birining ichiga emas, balki bir-birining yoniga joylashtirishga
o'xshaydi.
Biz 15-2 ro'yxatidagi List enumni va 15-3 ro'yxatidagi Listning
qo'llanishini 15-5 ro'yxatidagi kodga o'zgartirishimiz mumkin, bu kompilyatsiya
bo'ladi:
Fayl nomi: src/main.rs
enum List { Cons(i32, Box<List>), Nil, } use crate::List::{Cons, Nil}; fn main() { let list = Cons(1, Box::new(Cons(2, Box::new(Cons(3, Box::new(Nil)))))); }
Ro'yxat 15-5: Maʼlum oʻlchamga ega boʻlish uchun Box<T>
dan foydalanadigan Listni e'lon qilinishi
Cons variantiga i32 o'lchamiga va boxdagi pointer ma'lumotlarini saqlash
uchun bo'sh joy kerak. Nil varianti hech qanday qiymatlarni saqlamaydi,
shuning uchun u Cons variantiga qaraganda kamroq joy talab qiladi. Endi
bilamizki, har qanday List qiymati i32 o‘lchamini va boxdagi pointer
ma’lumotlari hajmini egallaydi. Boxdan foydalanib, biz cheksiz, rekursiv
zanjirni buzdik, shuning uchun kompilyator List qiymatini saqlash uchun
kerakli hajmni aniqlay oladi. 15-2-rasmda Cons varianti hozir qanday
ko'rinishi ko'rsatilgan.

15-2-rasm: Cheksiz o'lchamli bo'lmagan List, chunki
Cons endi Box saqlaydi
Boxlar faqat bilvosita va heapda joylashuvni ta'minlaydi; ularda biz boshqa smart pointerlarda ko'radigan boshqa maxsus imkoniyatlar yo'q. Ular, shuningdek, ushbu maxsus imkoniyatlarga ega bo'lgan ishlash xarajatlariga ega emaslar, shuning uchun ular bizga kerak bo'lgan yagona xususiyat bo'lgan cons list kabi holatlarda foydali bo'lishi mumkin. Biz 17-bobda boxlar uchun ko'proq foydalanish holatlarini ko'rib chiqamiz.
Box<T> turi smart pointerdir, chunki u Deref xususiyatini amalga oshiradi,
bu esa Box<T> qiymatlariga reference kabi qarashga imkonini beradi. Box<T>
qiymati scopedan chiqib ketganda, box ko'rsatayotgan heapdagi ma'lumotlar ham
Drop xususiyatini amalga oshirish tufayli tozalanadi. Ushbu ikki xususiyat biz
ushbu bobning qolgan qismida muhokama qiladigan boshqa smart pointer turlari
tomonidan taqdim etilgan funksionallik uchun yanada muhimroq bo'ladi. Keling,
ushbu ikki xususiyatni batafsil ko'rib chiqaylik.
Smart Pointerlarni Deref Xususiyati Bilan Oddiy Havolalar Kabi Ishlatish
Deref xususiyatini qo'llash, dereference operatorining * (ko'paytirish
yoki glob operatori bilan adashtirmaslik kerak) xulq-atvorini sozlashga imkon
beradi. Smart pointerlarni Deref xususiyati bilan oddiy havolalar kabi
qo'llasangiz, siz havolalar ustida ishlaydigan kod yozishingiz, shuningdek,
ushbu kodni smart pointerlar bilan ishlatishingiz mumkin bo'ladi.
Keling, avvalo, dereference operatori oddiy havolalar bilan qanday ishlashini
ko'rib chiqaylik. Keyin biz Box<T> kabi maxsus turni e'lon qilishga harakat
qilamiz va dereference operatori nega bizning yangi e'lon qilgan turimizdagi
havola kabi ishlamayotganini ko'ramiz. Biz Deref xususiyatini amalga oshirish
smart pointerlarning havolalarga o'xshash tarzda ishlashiga qanday imkon
berishini ko'rib chiqamiz. Keyin biz Rustning deref coercion xususiyatini va
u bizga havolalar yoki smart pointerlar bilan ishlashga qanday imkon berishini
ko'rib chiqamiz.
Eslatma: biz qurmoqchi bo'lgan
MyBox<T>turi va haqiqiyBox<T>o‘rtasida bitta katta farq bor: bizning versiyamiz o‘z ma’lumotlarini heapda saqlamaydi. Biz ushbu misolda e'tiborimizniDerefga qaratmoqdamiz, shuning uchun ma'lumotlarning qayerda saqlanishi pointerga o'xshash xatti-harakatlardan kamroq ahamiyatga ega.
Pointerni Qiymatga bog'lash
Muntazam havola pointerning bir turi bo'lib, pointerni boshqa joyda saqlangan
qiymatga o'q kabi tasavvur qilishning bir usuli. 15-6 ro'yxatda biz i32
qiymatiga havola yaratamiz va keyin qiymatga havolani bog'lash uchun dereference
operatoridan foydalanamiz:
Fayl nomi: src/main.rs
fn main() { let x = 5; let y = &x; assert_eq!(5, x); assert_eq!(5, *y); }
Ro'yxat 15-6: i32 qiymatiga havola orqali murojat qilish
uchun dereference operatoridan foydalanish
x o'zgaruvchisi i32 turidagi 5 qiymatiga ega. Biz y ni x ning
havolasiga tenglashtiramiz. Biz x 5 ga teng ekanligini solishtirishimiz
mumkin. Ammo, agar biz y dagi qiymatni solishtirmoqchi bo'lsak, kompilyator
haqiqiy qiymatni solishtirishi uchun *y dan foydalanib, u havola qilgan
qiymatga (ya'ni, dereference) murojaat qilishimiz kerak. y da dereference
qo'llaganimizdan so'ng, y ishora qilib turgan butun son qiymatiga kirish
imkoniga ega bo'lamiz, bu 5 bilan solishtirishimizga imkon beradi.
Agar assert_eq!(5, y); yozishga harakat qilganimizda, ushbu kompilyatsiya
xatoligini olgan bo'lar edik:
$ cargo run
Compiling deref-example v0.1.0 (file:///projects/deref-example)
error[E0277]: can't compare `{integer}` with `&{integer}`
--> src/main.rs:6:5
|
6 | assert_eq!(5, y);
| ^^^^^^^^^^^^^^^^ no implementation for `{integer} == &{integer}`
|
= help: the trait `PartialEq<&{integer}>` is not implemented for `{integer}`
= help: the following other types implement trait `PartialEq<Rhs>`:
f32
f64
i128
i16
i32
i64
i8
isize
and 6 others
= note: this error originates in the macro `assert_eq` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0277`.
error: could not compile `deref-example` due to previous error
Raqam va raqamga havola bilan solishtirishga yo'l qo'yilmaydi, chunki ular har xil turlar. Biz havola qilingan qiymatga murojaat qilish uchun dereference operatoridan foydalanishimiz kerak.
Box<T> ni Havola Kabi Ishlatish
15-6 ro'yxatdagi kodni havola o'rniga Box<T> ishlatgan holda qayta yozishimiz
mumkin; 15-7 ro'yxatdagi funksiyalarida Box<T> da ishlatiladigan dereference
operatori 15-6 ro'yxatidagi havolada ishlatilgan dereference operatori
bilan bir xil tarzda ishlatiladi:
Fayl nomi: src/main.rs
fn main() { let x = 5; let y = Box::new(x); assert_eq!(5, x); assert_eq!(5, *y); }
Ro'yxat 15-7: Box<i32> da dereference operatorini
ishlatish
15-7 va 15-6 ro'yxat o'rtasidagi asosiy farq shundaki, biz bu yerda y ni x
qiymatiga havola emas, balki x ning ko'chirilgan qiymatiga ishora qiluvchi
Box<T> ning misoli qilib belgiladik. Oxirgi solishtiruvda biz dereference
operatoridan Box<T> ko'rsatgichiga murojat qilish uchun xuddi y havola
bo'lganida qilganimizdek bajarishimiz mumkin. Keyin biz Box<T> ning o'ziga xos
xususiyatlarini o'rganamiz, bu bizga o'z turimizni e'lon qilish orqali
dereference operatoridan foydalanishga imkon beradi.
O'zimizning Aqlli Ko'rsatgichimizni E'lon Qilish
Keling, aqlli ko'rsatgichlar havolalardan qanday farq qilishini bilish uchun
standart kutubxona tomonidan taqdim etilgan Box<T> turiga o'xshash aqlli
ko'rsatgichni yarataylik. Keyin biz dereference operatoridan foydalanish
qobiliyatini qanday qo'shishni ko'rib chiqamiz.
Box<T> turi oxir-oqibat bitta elementga ega bo'lgan tuple struct sifatida
aniqlanadi, 15-8 ro'yxatda xuddi shu tarzda MyBox<T> turini belgilaydi.
Shuningdek, Box<T> da belgilangan new funksiyaga mos keladigan new
funksiyani aniqlaymiz.
Fayl nomi: src/main.rs
struct MyBox<T>(T); impl<T> MyBox<T> { fn new(x: T) -> MyBox<T> { MyBox(x) } } fn main() {}
Ro'yxat 15-8: MyBox<T> turini aniqlash
Biz MyBox nomli structni aniqlaymiz va T generic parametrini e'lon qilamiz,
chunki biz turimiz istalgan turdagi qiymatlarni ushlab turishini xohlaymiz.
MyBox turi T turidagi bitta elementga ega bo'lgan tuple structdir.
MyBox::new funksiyasi T turidagi bitta parametrni oladi va berilgan qiymatni
ushlab turuvchi MyBox misolini qaytaradi.
15-7 ro'yxatdagi main funksiyasini 15-8 ro'yxatiga qo'shib, Box<T> o'rniga
biz belgilagan MyBox<T>turidan foydalanish uchun o'zgartirishga harakat
qilaylik. 15-9 ro'yxatdagi kod kompilyatsiya qilinmaydi, chunki Rust MyBox ni
qanday qilib dereference qilishni bilmaydi.
Fayl nomi: src/main.rs
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
fn main() {
let x = 5;
let y = MyBox::new(x);
assert_eq!(5, x);
assert_eq!(5, *y);
}Ro'yxat 15-9: MyBox<T> dan xuddi havolalar va Box<T>
dan foydalanganimiz kabi foydalanishga urinish
Natijada kompilyatsiya xatosi:
$ cargo run
Compiling deref-example v0.1.0 (file:///projects/deref-example)
error[E0614]: type `MyBox<{integer}>` cannot be dereferenced
--> src/main.rs:14:19
|
14 | assert_eq!(5, *y);
| ^^
For more information about this error, try `rustc --explain E0614`.
error: could not compile `deref-example` due to previous error
Bizning MyBox<T> turini dereference qilib bo'lmaydi, chunki biz bu qobiliyatni
o'z turimizda qo'llamaganmiz. * operatori yordamida dereference qilishni
yoqish uchun biz Deref traitini qo`llaymiz.
Deref Traitni Amalga Oshirish Orqali Turga Havola Kabi Munosabatda Bo'lish
10-bobning “Turga xos Traitni amalga
oshirish” boʻlimida muhokama
qilinganidek, traitni amalga oshirish uchun biz traitning talab qilinadigan
usullarini amalga oshirishimiz kerak. Standart kutubxona tomonidan taqdim
etilgan Deref xususiyati bizdan self qarz oladigan va ichki ma'lumotlarga
havolani qaytaradigan deref nomli metodni qo'llashimizni talab qiladi. 15-10
ro'yxat MyBox ta'rifiga qo'shish uchun Deref amalga oshirilishini o'z ichiga
oladi:
Fayl nomi: src/main.rs
use std::ops::Deref; impl<T> Deref for MyBox<T> { type Target = T; fn deref(&self) -> &Self::Target { &self.0 } } struct MyBox<T>(T); impl<T> MyBox<T> { fn new(x: T) -> MyBox<T> { MyBox(x) } } fn main() { let x = 5; let y = MyBox::new(x); assert_eq!(5, x); assert_eq!(5, *y); }
Ro'yxat 15-10: MyBox<T> uchun Deref ni amalga
oshirish
Type Target = T; sintaksisi foydalanish uchun Deref xususiyati uchun
bog`langan turni belgilaydi. Bog'langan turlar generic parametrni e'lon
qilishning biroz boshqacha usulidir, ammo hozircha ular haqida
tashvishlanishingiz shart emas; biz ularni 19-bobda batafsil yoritamiz.
Biz deref metodining tanasini &self.0 bilan to'ldiramiz, shuning uchun
deref biz * operatori bilan kirmoqchi bo'lgan qiymatga havolani qaytaradi;
5-bobning “Har xil turlarni yaratish uchun nomli maydonlarsiz tuplelardan
foydalanish” boʻlimidan .0 tuple structidagi
birinchi qiymatga kirishini esga oling. MyBox<T> qiymatida * ni chaqiruvchi
15-9 ro'yxatdagi main funksiya endi kompilyatsiya qilinadi va solishtiruvlar
o`tadi!
Deref traitisiz kompilyator faqat & havolalarini dereference qilishi mumkin.
deref metodi kompilyatorga Deref ni qo'llaydigan har qanday turdagi qiymatni
olish va deref usulini chaqirish va & havolasini olish imkoniyatini beradi.
15-9 ro'yxatda *y ga kirganimizda, Rust sahna ortida ushbu kodni ishga
tushirdi:
*(y.deref())Rust * operatorini deref metodini chaqirish va keyin oddiy dereference bilan
almashtiradi, shuning uchun deref metodini chaqirish kerakligi haqida
o'ylamasligimiz kerak. Ushbu Rust xususiyati bizga oddiy havola yoki Deref ni
qo'llaydigan turga ega bo'ladimi, bir xil ishlaydigan kod yozish imkonini
beradi.
deref metodi qiymatga havolani qaytarishining sababi va *(y.deref()) qavslar
tashqarisidagi oddiy dereference hali ham zarur bo'lishi ownership tizimi bilan
bog'liq. Agar deref usuli qiymatga havola o'rniga to'g'ridan-to'g'ri qiymatni
qaytargan bo'lsa, qiymat o'zidan o'chiriladi. Biz MyBox<T> ichidagi ichki
qiymatga egalik qilishni istamaymiz, bu holatda yoki ko'p hollarda biz
dereference operatoridan foydalanamiz.
Esda tutingki, * operatori deref metodini chaqirish va keyin * operatorini
faqat bir marta chaqirish bilan almashtiriladi, har safar kodimizda * dan
foydalanamiz. * operatorini almashtirish cheksiz takrorlanmasligi sababli, biz
15-9 ro'yxatdagi assert_eq! dagi 5 ga mos keladigan i32 turidagi
ma'lumotlarga ega bo`lamiz.
Funksiya va Metodlar bilan Yashirin Deref Coercion'lar
Deref coercion havolani Deref xususiyatini boshqa turga havolada amalga
oshiradigan turga aylantiradi. Masalan, deref coercion &String ni &str ga
aylantirishi mumkin, chunki String Deref traitini amalga oshiradi va u
&str ni qaytaradi. Deref coercion - bu Rust funksiyalar va metodlarga
argumentlar bo'yicha bajaradigan qulaylik va faqat Deref traitini amalga
oshiradigan turlarda ishlaydi. Bu funksiya yoki metod ta'rifidagi parametr turiga
mos kelmaydigan funksiya yoki metodga argument sifatida ma'lum bir turdagi
qiymatga havolani uzatganimizda avtomatik ravishda sodir boʻladi. Deref
metodiga chaqiruvlar ketma-ketligi biz taqdim etgan turni parametr kerak
bo'lgan turga aylantiradi.
Rustga deref coercion qo'shildi, shuning uchun dasturchilar funktsiya va metod
chaqiruvlarini yozish uchun & va * bilan ko'p aniq havolalar va
dereferencelarni qo'shishlari shart emas. Deref coercion xususiyati bizga
havolalar yoki aqlli ko'rsatkichlar uchun ishlashi mumkin bo'lgan ko'proq kod
yozish imkonini beradi.
Deref coercionni amalda ko'rish uchun biz 15-8 ro'yxatda belgilagan MyBox<T>
turini hamda 15-10 ro'yxatiga qo'shgan Deref ni amalga oshirishdan
foydalanamiz. Ro'yxat 15-11 string slice parametriga ega bo'lgan funksiyaning
ta'rifini ko'rsatadi:
Fayl nomi: src/main.rs
fn salom(nom: &str) { println!("Salom, {nom}!"); } fn main() {}
Ro'yxat 15-11: &str tipidagi nom parametriga ega
salom funksiyasi
Biz salom funksiyasini argument sifatida string slice bilan chaqirishimiz
mumkin, masalan, salom("Rust");. Deref coercion 15-12 ro'yxatda
ko'rsatilganidek, MyBox<String> turidagi qiymatga havola bilan salom ni
chaqirish imkonini beradi:
Fayl nomi: src/main.rs
use std::ops::Deref; impl<T> Deref for MyBox<T> { type Target = T; fn deref(&self) -> &T { &self.0 } } struct MyBox<T>(T); impl<T> MyBox<T> { fn new(x: T) -> MyBox<T> { MyBox(x) } } fn salom(nom: &str) { println!("Salom, {nom}!"); } fn main() { let m = MyBox::new(String::from("Rust")); salom(&m); }
Ro'yxat 15-12: MyBox<String> qiymatiga havola bilan
salom deb chaqirish, bu deref coercion tufayli ishlaydi
Bu yerda biz &m argumenti bilan salom funksiyasini chaqiramiz, bu
MyBox<String> qiymatiga havola. Biz Deref traitini MyBox<T> uchun
15-10 ro'yxatda amalga oshirganimiz uchun Rust deref ni chaqirish orqali
&MyBox<String> ni &String ga aylantirishi mumkin. Standart kutubxona String
da Deref ning amalga oshirilishini ta'minlaydi, bu string slice qaytaradi va
bu Deref uchun API hujjatlarida. Rust &String ni &str ga aylantirish uchun
yana deref ni chaqiradi, bu salom funksiyasi ta`rifiga mos keladi.
Agar Rust deref coercionni amalga oshirmagan bo'lganida, biz &MyBox<String>
tipidagi qiymat bilan salom ni chaqirish uchun 15-12 ro'yxatdagi kod
o'rniga 15-13 ro'yxatdagi kodini yozishimiz kerak edi.
Fayl nomi: src/main.rs
use std::ops::Deref; impl<T> Deref for MyBox<T> { type Target = T; fn deref(&self) -> &T { &self.0 } } struct MyBox<T>(T); impl<T> MyBox<T> { fn new(x: T) -> MyBox<T> { MyBox(x) } } fn salom(nom: &str) { println!("Salom, {nom}!"); } fn main() { let m = MyBox::new(String::from("Rust")); salom(&(*m)[..]); }
Ro'yxat 15-13: Agar Rustda deref coercion bo'lmaganida, biz yozishimiz kerak bo'lgan kod
(*m) MyBox<String> ni String ga yo'naltiradi. Keyin & va [..] salom
belgisiga mos kelishi uchun butun stringga teng bo'lgan String string sliceni
oladi. Deref coercionsiz ushbu kodni o'qish, yozish va tushunish ushbu belgilar
bilan qiyinroq. Deref coercion Rustga ushbu konversiyalarni biz uchun avtomatik
tarzda boshqarishga imkon beradi.
"Deref" traiti jalb qilingan turlar uchun aniqlanganda, Rust turlarni tahlil
qiladi va parametr turiga mos keladigan havolani olish uchun kerak bo'lganda
Deref::deref dan foydalanadi. Deref::deref qo'shilishi kerak bo'lgan vaqtlar
soni kompilyatsiya vaqtida hal qilinadi, shuning uchun deref coerciondan
foydalanganlik uchun ishga tushirish vaqtida jarima yo'q!
Deref Coercion O'zgaruvchanlik bilan Qanday O'zaro Ta'sir Qilishi
O'zgarmas havolalarda * operatorini rad qilish uchun Deref traitidan
foydalanishga o'xshab, o'zgaruvchan havolalarda * operatorini rad
qilish uchun DerefMut traitidan foydalanishingiz mumkin.
Rust ushbu uchta holatda tur va traitni amalga oshirishlarni topsa, deref coercionni amalga oshiradi
&Tdan&Ugacha,T: Deref<Target=U>&mut Tdan&mut UgachaT: DerefMut<Target=U>&mut Tdan&UgachaT: Deref<Target=U>
Birinchi ikkita holat bir-biri bilan bir xil, faqat ikkinchisi o'zgaruvchanlikni
amalga oshiradi. Birinchi holatda aytilishicha, agar sizda &T bo'lsa va T
Deref ni U turiga qo'llasa, shaffof tarzda &U ni olishingiz mumkin.
Ikkinchi holatda aytilishicha, xuddi shunday deref coercion o'zgaruvchan
havolalar uchun sodir bo'ladi.
Uchinchi holat qiyinroq: Rust o'zgarmasga o'zgaruvchan havolani ham majbur qiladi. Ammo buning teskarisi mumkin emas: o'zgarmas havolalar hech qachon o'zgaruvchan havolalarga majburlamaydi. Qarz olish qoidalari tufayli, agar sizda o'zgaruvchan havola bo'lsa, bu o'zgaruvchan havola ma'lumot uchun yagona havola bo'lishi kerak (aks holda dastur kompilyatsiya qilinmaydi). Bitta o'zgaruvchan havolani bitta o'zgarmas havolaga aylantirish hech qachon qarz olish qoidalarini buzmaydi. O'zgarmas havolani o'zgaruvchan havolaga aylantirish uchun dastlabki o'zgarmas havola ushbu ma'lumotga yagona o'zgarmas havola bo'lishini talab qiladi, ammo qarz olish qoidalari bunga kafolat bermaydi. Shu sababli, Rust o'zgarmas havolani o'zgaruvchan havolaga aylantirish mumkin deb taxmin qila olmaydi.
Drop Trait bilan tozalash uchun kodni yuritish
Agar qiymat o‘z doirasidan chiqqanda uni o‘zgartirish imkonini beradigan ikkinchi muhim sanalgan smart pointer namunasidan biri bu Dropdir. Siz Drop traitini implementatsiya qilish uchun xohlagan turdan foydalanishingiz mumkin, va kodni fayl yoki tarmoqlarni ulash resurslarini yaratish uchun ham ishlatilishi mumkin
Dropni smart pointerlar kontekstida ishlatishimizning sababi Drop traiti smart pointerni implementatsiyasida deyarli har doim ishlatiladi. Masalan, qachonki Box<T> tashlab yuborilganda u quti ko‘rsatayotgan heapdan joy ajratadi.
Ayrim dasturlash tillarida ayrim turlar uchun dasturchi xotirani bo‘shatish uchun yoki har safar resurslar o‘sha tur instancedan ishlatib bo‘lmagungacha kodni chaqirishi kerak. Fayl handlelari, soketlar va locklar bunga misol bo‘la oladi. Agar ular kodni chaqirishni unitsalar, tizimda haddan tashqari yuklanish yuzaga keladi va tizim ishdan chiqadi. Rustda agar qiymat o‘z doirasidan chiqqanda siz kodning ma’lum bir qismi ishga tushirishni belgilashingiz mumkin, kompilyator avtomatik ravishda kodni kiritadi. Natijada, ma’lum bir turdagi instance tugagan dasturning hamma joyiga tozalovchi kodni joylashtirishdan xavotir olmasangiz ham bo‘ladi va siz resurslarni sizib ketishini oldini olgan bo‘lasiz!
Siz Drop traiti implementatsiyasi yordamida agar qiymat doirasidan chiqqan holda kodni run qilish uchun belgilashingiz mumkin. Drop traiti sizdan selfdan referens oluvchi drop nomli metodni implementatsiya qilishni talab qiladi. Rustda drop qachon chaqirilishini ko‘rish uchun, dropni println! yordamida implementatsiya qilib ko‘raylik.
15-14 ni ko‘rib chiqadigan bo‘lsak, Rustda qachon drop funksiyasi ishlashini ko‘rish uchun faqat o‘ziga tegishli bo‘lganCustomSmartPointer structi faqat agar instance o‘z doirasidan chiqqanda Dropping CustomSmartPointer! ni print qiladi.
Fayl nomi: src/main.rs
struct CustomSmartPointer { data: String, } impl Drop for CustomSmartPointer { fn drop(&mut self) { println!("CustomSmartPointerni `{}` ma'lumot bilan tashlab yuborish!", self.data); } } fn main() { let c = CustomSmartPointer { data: String::from("menga tegishli"), }; let d = CustomSmartPointer { data: String::from("boshqaga tegishli"), }; println!("CustomSmartPointerlar yaratildi."); }
15-14ni ko'rib chiqish: CustomSmartPointer structi biz tozalash uchun qo’ygan kodda Drop traitining implementatsiyasi
Drop traiti o‘z ichiga preludeni oladi, shuning uchun biz uni scopeni ichiga olishimiz shart emas. Biz CustomSmartPointerda Dropni implementatsiya qilamiz va drop metodi implementatisyasi uchun println!ni chaqiramiz. drop funksiyasining tana (body) qismi bu sizning turdagi instance o‘z doirasidan (scope) chiqib ketgandagi ayrim bir logikaga ega koddir. Rustda qachon drop chaqirilishini ko‘rish uchun biz ozgina tekstni print qilamiz.
mainda biz 2ta CustomSmartPointer instancelarini yaratamiz va keyin CustomSmartPointers yaratildini print qilamiz. mainning oxirida CustomSmartPointer doiradan (scope) chiqib ketadi va Rust yakuniy xabarni print qilib, biz kodga qo‘ygan drop metodini chaqiradi. E’tibor bering biz drop metodini to‘g‘ridan-to‘g‘ri chaqririshimiz shart emas.
Agar biz dasturni run qilsak, quyidagi outputni ko‘ramiz:
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
Finished dev [unoptimized + debuginfo] target(s) in 0.60s
Running `target/debug/drop-example`
CustomSmartPointerlar yaratildi.
CustomSmartPointerni `menga tegishli` ma'lumot bilan tashlab yuborish!
CustomSmartPointerni `boshqaga tegishli` ma'lumot bilan tashlab yuborish!
Rust avtomatik ravishda bizning o‘rnimizga biz ko‘rsatgan kodni instance doiradan (scope) chiqqanda dropni chaqirdi. O‘zgaruvchilar yaratilish paytida teskari tartibda tushib qoldiriladi (drop qilinadi), shuning uchun d cdan oldin tushib qoldirildi (drop qilindi). Ushbu misolning maqsadi sizga drop metodining qanday ishlashining vizual ko‘rinishini berishdir; odatda xabarni print qilishning o‘rniga siz sizning turingizni ishga tushirish (run qilish) uchun tozalash kodini ko‘rsatasiz.
std::mem::drop yordamida Qiymatni Erta Drop qilish
Afsuski, avtomatik drop funksiyasini o‘chirish oson emas. Odatda dropni o‘chirish zarur emas; Dropning asosiy mohiyati uning avtomatik ravishda hal qilishidir. Ba’zi paytlarda siz qiymatni erta tozalashga duch kelishingiz mumkin. Lockalarni boshqaruvchi smart pointerlarni ishlatishga bir misol bo‘la oladi: bir doirada (scope)da boshqa kodni olish uchun siz lockni chaqiradigan drop metodini majburiy ravishda ishlatishingiz mumkin. Rust sizga Drop traitidagi drop metodini qo‘lda tushurishga qo‘ymaydi; agar siz qiymatni o‘z doirani (scope) tugashidan oldin majburiy drop bo‘lishini xohlasangiz. uning uchun siz standart kutubxona tomonidan taqdim etilgan std::mem::dropni ishlatishingiz mumkin.
Agar biz 15-14dagi ilovaga qo‘lda Drop traitining drop metodi yordamida mainga o‘zgaritirish kiratigan bo‘lsak, 15-15 ilovada ko‘rsatilgan kompilyator xatosini ko‘ramiz:
Fayl nomi: src/main.rs
struct CustomSmartPointer {
data: String,
}
impl Drop for CustomSmartPointer {
fn drop(&mut self) {
println!("CustomSmartPointerni `{}` ma'lumot bilan Drop qilish!", self.data);
}
}
fn main() {
let c = CustomSmartPointer {
data: String::from("ma'lumot"),
};
println!("CustomSmartPointer yaratildi.");
c.drop();
println!("main tugashidan oldin CustomSmartPointer drop qilindi.");
} 15-15 ro'yxat: Drop traitidagi drop metodi orqali qo'lda erta tozalashga harakat qilish
Ushbu kodni komplilyatsiya qilganimizda quyidagi xatolikni ko‘ramiz:
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
error[E0040]: explicit use of destructor method
--> src/main.rs:16:7
|
16 | c.drop();
| --^^^^--
| | |
| | explicit destructor calls not allowed
| help: consider using `drop` function: `drop(c)`
For more information about this error, try `rustc --explain E0040`.
error: could not compile `drop-example` due to previous error
Ushbu xatolikdagi xabarda dropni to‘g‘ridan-to‘g‘ri chaqira olmasligizni ko‘rsatadi. Xatolikdagi xabar instanceni tozalovchi umumiy dasturlash atamasi bo‘lgan funksiya, ya’ni destructorni ishlatadi. destructor constructorga o‘xshash bo‘lib, instancelarni yaratadi. Rustda drop funksiyasi alohida bir destructordir.
Rust bizga dropni to‘g‘ridan-to‘g‘ri chaqrishga qo‘ymaydi chunki Rust qiymatni avtomatik ravishda baribir mainni oxirida dropni chaqiradi. Ushbu holat double free xatoligini keltirib chiqarishi mumkin chunki Rust bitta qiymatni ikki marta tozalashga xarakat qiladi.
Agar qiymat o‘z doirasidan (scope) chiqqanda biz dropni avtomatik kiritishini o‘chirib qo‘ya olmaymiz va drop metodini to‘g‘ridan-to‘g‘ri chaqira olmaymiz. Shuning uchun agar bizga majburiy ravishda qiymat tozalanishini xoxlasak, biz std::mem::dropfunksiyasini ishlatamiz
std::mem::drop funksiyasi Drop traitidagi drop metodidan farq qiladi. Biz buni majburan tozalash (drop) qilishni xohlagan qiymatni argument sifatida berish deb ataymiz. Funksiya preludeda, va 15-16 ro'yxatda ko‘rsatilgandek biz 15-15 ro'yxatdagi mainda drop funkisyasini chaqirish uchun o‘zgartirish kiritishimiz mumkin:
Fayl nomi: src/main.rs
struct CustomSmartPointer { data: String, } impl Drop for CustomSmartPointer { fn drop(&mut self) { println!("CustomSmartPointerni `{}` ma'lumot bilan Drop qilish!", self.data); } } fn main() { let c = CustomSmartPointer { data: String::from("ma'lumot"), }; println!("CustomSmartPointer yaratildi."); drop(c); println!("main tugashidan oldin CustomSmartPointer drop qilindi."); }
15-16 ro'yxat: qiymat o'z doirasidan (scope) chiqqanda to'g'ridan-to'g'ri std::mem::dropni chaqirish
Run qilingan kod quyidagini print qiladi:
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
Finished dev [unoptimized + debuginfo] target(s) in 0.73s
Running `target/debug/drop-example`
CustomSmartPointer created.
Dropping CustomSmartPointer with data `some data`!
CustomSmartPointer dropped before the end of main.
c nuqtasida tozalash (drop qilish) uchun drop metodi kodini chaqirishini ko‘rsatish uchunCustomSmartPointerdagi ma’lumot bilan tozalash (drop qilish) CustomSmartPointer yaratildi va CustomSmartPointer main tugashidan oldin tozalandi (drop qilindi) matnlari orasida print qilindi.
Siz Drop traiti implementatsiyasida ko‘rsatilgan koddan har xil turda tozalashni qulay va xavfsiz qilishingiz mumkin: masalan, siz uni o‘zingizning xotira taqsimlagichni yaratish uchun ishlatsangiz bo‘ladi. Drop traiti va Rustning ownership tizimi bilan tozalash uchun bosh qotirmasangiz ham bo‘ladi chunki Rust buni avtomatik ravishda qiladi.
Siz ishlatilib turgan qiymatlarni bexosdan tozalanib ketish muammolaridan xavotir olmasangiz bo‘ladi: ownership tizimi referencelarni doim to‘g‘riligiga hamda drop qiymat bir marta chaqrilib boshqa ishlatilmasligini ta’minlaydi.
Hozirda biz Box<T>ni va smart pointerlarni ba’zi bir xususiyatlarini tekshirib oldik, keling standart kutubxonada keltirilgan boshqa smart pointerlarni ham ko‘rib chiqaylik.
Rc<T>, reference hisoblangan Smart Pointer
Ko‘p hollarda, ownership ochiq, ya’ni tushunarli holda bo’ladi: sizga qaysi o‘zgaruvchi qaysi berilgan qiymatga egalik qilishini aniq bilasiz. Ammo, ayrim hollarda bitta qiymat ko‘p egalarga ega bo‘lishi mumkin. Masalan, grafik ma’lumotlar tuzilmasida (data structures), bir nechta edgelar bitta nodeni point qilishi mumkin, vas shu node unga point qilingan barcha edgelar tomonidan egalik qilinadi. Nodega edgelar point qilinmagungacha, shuningdek egalari bo‘lmagungacha tozalanishi mumkin emas.
Rustning refenceni hisoblovchi Rc
Rc<T> ni zaldagi televizor sifatida tasavvur qiling. Agar bir kishi televizor ko‘rish uchun xonaga kirsa, u televizorni yoqadi. Boshqalar esa shunchaki xonaga kirib tomosha qilsalar bo‘ladi. Xonadan oxirgi odam chiqib ketayotganda, ular televizorni o‘chirib ketishadi chunki televizor boshqa ishlatilmaydi. Agar bir kishi boshqalar televizorni tomosha qilib o‘tirganida o‘chirsa boshqalar uchun g‘alati bo‘lishi mumkin.
Biz Rc<T>ni ma’lumotni heapda dasturning ko‘p qismlarini o‘qishi uchun ajratishni hohlasaganimizda foydalanamiz va biz kompilyatsiya vaqti qaysi qism ma’lumotini oxirgi foydalanishni yakunlaganini bila olmaymiz. Agar biz ma’lumotni qaysi qismi oxirida to‘xtashini bilganimizda, biz shu qismni ma’lumotni egasi sifatida tayinlar edik va kompilyatsiya vaqtida qo‘llaniladigan oddiy egalik (ownership) qoidalari kuchga kirar edi.
Shuni yodda tutish kerakki Rc<T> yakka-thread holatlardagina ishlatiladi. Biz 16-bo‘limda parralellik haqida suhlashganimizda, biz ko‘p threadli dasturlarda referenceni hisoblashni qanday qilishni o‘rganamiz.
Rc<T>ni Ma'lumotni Ulashish uchun ishlatish
Keling kamchiligi bor bo‘lgan 15-5 ro‘yxat misolimizga qaytaylik. Esingizda bo‘lsa biz Box<T>ni ishlatishni ko‘rsatib o‘tgan edik. Bu safar, biz 2ta ro‘yxat ham egalikni (ownership) 3-ro‘yxat bilan ulashadigan ro‘yxat yaratamiz. Aniq qilib aytadigan bo‘lsak, 15-3 shaklga o‘xshashdir:

15-3-shakl: Ikkita ro'yxatlar, ya'ni b va c egalikni uchinchi ro'yxat, ya'ni aga ulashishi
Biz 5 va 10 dan iborat bo‘lgan a ro‘yxatni yaratamiz. Keyin yana ikkita ro‘yxatni ham yaratamiz, ya’ni 3dan boshlanadigan b va 4dan boshlanadigan c. b va c ro‘yxatlari 5 va 10dan iborat bo‘lgan a ro‘yxatda davom etadi. Boshqacha qilib aytganda, ro‘yxatlar birinchi 5 va 10dan iborat bo‘lgan birinchi ro‘yxat bilan ulashishadi.
15-17-ro‘yxatda ko‘rsatilgandek, bizning ssenariy bo‘yicha Box<T> bilan Listdagi ta’rifimiz yordamida implement qilishga urunsak ishga tushmaydi:
Fayl-nomi: src/main.rs
enum List {
Cons(i32, Box<List>),
Nil,
}
use crate::List::{Cons, Nil};
fn main() {
let a = Cons(5, Box::new(Cons(10, Box::new(Nil))));
let b = Cons(3, Box::new(a));
let c = Cons(4, Box::new(a));
}15-17-ro'yxat: Ko'rib turganimizdek, Box<T> yordamida uchunchi ro'yxatga ikkita ro'yxatni egaligini (ownership) ulashib bo'lmaydi
Ushbu kodni kompilyatsiya qilsak, biz yuqoridagi xatolikni ko'ramiz:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
error[E0382]: use of moved value: `a`
--> src/main.rs:11:30
|
9 | let a = Cons(5, Box::new(Cons(10, Box::new(Nil))));
| - move occurs because `a` has type `List`, which does not implement the `Copy` trait
10 | let b = Cons(3, Box::new(a));
| - value moved here
11 | let c = Cons(4, Box::new(a));
| ^ value used here after move
For more information about this error, try `rustc --explain E0382`.
error: could not compile `cons-list` due to previous error
Cons variantlari o'zlariga tegishli bo'lgan ma'lumotlargagina egalik (own) qila oladi, shuninguchun biz b ro'yxatini yaratganimizda, a bga o'tadi va b aga egalik qiladi.Undan keyin, c ni yaratish uchun adan foydalanmoqchi bo'lganizmizda bizga ruxsat bermaydi chunki a ko'chib ketganligi uchun.
Buning o'rniga havolalarni ushlab turish uchun Cons ta'rifini o'zgartirishimiz mumkin, lekin keyin biz layvtaym parametrlarini ko'rsatishimiz kerak bo'ladi. Layvtaym parametrlarini belgilash orqali, biz ro'yxatdagi har bir elementning yashashini ko'rsatamiz. 15-17 ro'yxatda ko'rsatilganidek bu elementlar va ro'yxatlarga tegishli, lekin har doim gam emas.
15-18-ro'yxatda ko'rsatilganidek, Box<T>ning o'rnigaRc<T>ni ishlatish uchun biz bizning Ro'yxatimizning mazmunini o'zgartiramiz. Har bir Cons varianti qiymatni o'zida ushlab turadi va Rc<T> Ro'yxatni ko'rsatadi. aning egaligini olishning o'rniga bni yaratganimizda, a ni ushlab turgan Rc<List>ni klonlaymiz, shu bilan birga referenslar sonini birdan ikkiga ko'paytiramiz va Rc<List>dagi ma'lumotlarning egaligini ulashish uchun a va bga ruxsat beramiz. referenslar sonini ikkidan uchga ko'paytirgan holda, cni yaratayotganimizda ani ham klonlaymiz. Rc::cloneni har safar chaqirganimizda, Rc<List> tarkibidagi ma'lumotlarining referenslari soni oshiriladi, zero referenslar paydo bo'lmagungacha ma'lumotlar tozalanmaydi.
Filename: src/main.rs
enum List { Cons(i32, Rc<List>), Nil, } use crate::List::{Cons, Nil}; use std::rc::Rc; fn main() { let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil))))); let b = Cons(3, Rc::clone(&a)); let c = Cons(4, Rc::clone(&a)); }
Listing 15-18: A definition of List that uses
Rc<T>
Biz scopeni ichiga Rc<T>ni kiritsh uchun use statementini qo'shishimiz kerak
chunki u muqaddimani ichida bo'lmagani uchun. mainni ichida 5 va 10ni saqlovch ro'yxatni
yaratamiz va uni aga tegishli yangi Rc<List>ga joylashtiramiz. Keyin esa b va c yaratganimizda, Rc::clone funksiyasini chaqiramiz va argument sifatida aga tegishli bo'lgan Rc<List>ga o'tkazib yuboramiz.
Rc::clone(&a)ning o'rniga biz a.clone() chaqirishimiz mumkin edi, lekin Rust
qoidalariga muofiq ushbu holatda Rc::clone ishlatgan ma'qul. Rc::clonening implementatsiyasi clonening ko'p implementatsiya turiga o'xshab ma'lumotlarni to'liq
nusxa olmaydi. Rc::clonening chaqirilishi referenslarning sonini ko'paytiradi, va shuning uchun ham ko'p vaqt olmaydi. Ma'lumotlarni to'liq nusxalash esa ko'p vaqt talab etadi. Referenslarni hisoblash uchun Rc::cloneni ishlatsak, biz to'liq nusxalangan bilan referenslar soni ortgan nusxalar orasidagi farqni tasavvur qilishimiz mumkin. Kodning unumdorlik muammolarini qidirayotganimizda, bizga faqat to'liq nusxalangan nusxalarga e'tibor qaratib, Rc::clonening chaqirilishini e'tiborga olmasak ham bo'ladi.
Rc<T>ni nusxalash Referenslar hisobini orttiradi
ada referenslarni yaratib va uni Rc<List>ga drop qilib referenslar sonini ortayotganligini keling bizning ishlab turgan 15-18-ro'yxatimizdagi misolga o'zgartirish kiritib ko'raylik,
15-19-ro'yxatda, mainni o'zgartirib ko'raylik chunki uning ichki scope(doirasi) cro'yxatining atrofida shundan so'ng biz c scope(doirasida) chiqqanda qanday qilib referenslar soni ortayotganini ko'ramiz.
Fayl-nomi: src/main.rs
enum List { Cons(i32, Rc<List>), Nil, } use crate::List::{Cons, Nil}; use std::rc::Rc; fn main() { let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil))))); println!("count after creating a = {}", Rc::strong_count(&a)); let b = Cons(3, Rc::clone(&a)); println!("count after creating b = {}", Rc::strong_count(&a)); { let c = Cons(4, Rc::clone(&a)); println!("count after creating c = {}", Rc::strong_count(&a)); } println!("count after c goes out of scope = {}", Rc::strong_count(&a)); }
15-19-ro'yxat: Referens soni ortayotganligini print qilish
Dasturda referens soni o'zgargan har bir nuqtada, Rc::strong_count funksiyasini chaqirish yordamida biz referens sonini print qilamiz. Ushbu funksiyani nomicountdeb emas strong_count deb nomlanadi, chunki Rc<T> turida weak_count ham bor; biz weak_countni "Referenslar siklini oldini olish: Rc<T>ni Weak<T>ga aylantirish" bo'limida ko'ramiz.
Ushbu kod quyidagini print qiladi:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished dev [unoptimized + debuginfo] target(s) in 0.45s
Running `target/debug/cons-list`
count after creating a = 1
count after creating b = 2
count after creating c = 3
count after c goes out of scope = 2
ada Rc<List>ning referens soni 1 ekanligini ko'rishimiz mumkin; keyinchalik har safar biz clone ni chaqirganimizda, son 1ga ortib boraveradi. c o'z scope(doirasi)dan chiqib ketganida,referens soni 1ga kamayadi. Rc::clone funksiyasi yordamida referens sonini ortirish uchun chaqirganimizdek referens soni kamaytirish uchun hech qanday funksiyasini chaqirishimiz kerak bo'lmaydi, chunki Drop traitining implementatsiyasi Rc<T> qiymati o'z scope(doirasi)dan chiqqanda avtomatik ravishda referens sonini kamaytiradi.
main oxirida b va keyin alarning scope(doirasidan) chiqib, son/hisob 0ga tenglashib, Rc<List> to'liq tozalanganligini biz ushbu misolda ko'ra olmaymiz. Rc<T>ni ishlatish yordamida bitta qiymat ko'p egalarga ega bo'lishi mumkin, hamda son/hisob qiymat egalaridan biri bor bo'lgunga qadar yaroqliligini tekshirib turadi.
O'zgarmas o'zgaruvchilar yordamida, Rc<T> o'qish uchun ma'lumotlarni dasturning ko'p joylari orasida ulashish imkonini beradi. Agar Rc<T> ko'p o'zgaruvchan referenslarga ega bo'lish imkonini bergan bo'lsa, siz 4-Bo'limda ko'rsatilganidek borrowing qoidalarini birini buzishingiz mumkin: ko'p o'zgaruchilar bir xil joyga borrow qilib data race va nomuvofiqliklarga sabab bo'lishi mumkin. Lekin ma'lumotni o'zrgatira olish foydalidir! keyingi bo'limda, biz ichki o'zgaruvchanlik shakli(pattern) va RefCell<T> turi bilan Rc<T> yordamida o'zgarmaslik cheklovi bilan ishlash ko'rib chiqamiz.
RefCell<T> va Ichki O'zgaruvchanlik Shakli(pattern)
Ichki o'zgaruvchanlik bu Rustda ma'lumotlarga o'zgarmas referenslar mavjud bo'lganda ham ma'lumotni o'zgartirish imkonini beruvchi (dizayn) shakli/patternidir: odatda bu borrowing qoidalari bo'yicha esa taqiqlangan. Ma'lumotni o'zgaruvchan qilish uchun shakl/pattern Rustning o'zgaruvchanlik va borrowingni boshqaruchi oddiy qoidalarini chetlab o'tish uchun ma'lumotlar strukturasi ichiga unsafe kod ishlatiladi. Xavfsiz bo'lmagan kod bizning o'rnimizga kompilyatorga qoidalarni kompliyator yordamisiz tekshirayotganimizni ko'rsatadi; xavfsiz bo'lmagan kod haqida 19-bo'limda o'rganib chiqamiz.
Biz ichki o'zgaruvchanlik shakli/patterni ishlatadigan turlardan faqatgina borrowing qoidalari runtimeda amal qilingaligi paytida ishlatishimiz mumkin, kompilyator bunga kafolat bera olmaydi. Keyin unsafe kod xavfsiz APIga ulanadi va tashqi tur o'zgarmasligicha qoladi.
Keling ushbu tushunchani ichki o'zgaruvchanlik shakliga amal qiluvchi quyidagi RefCell<T> turiga qarab ko'rib chiqaylik.
Enforcing Borrowing Rules at Runtime with RefCell<T> yordamida Borrowing qoidalarini Runtime vaqtida kuch bilan ishlatish
Rc<T>lidan faqrli o'laroq, RefCell<T> turi o'zi egalik qilib turgan ma'lumotda yagona egalikni namoyish etadi. Xo'sh, RefCell<T> turi Box<T> turidan nimasi bilan farq qiladi? 4-bo'limda o'tilgan borrowing qoidalarini esga olaylik:
- Xohlagan belgilangan vaqtda, siz yoki (ikkalasini bir vaqtda ega bo'lish mumkin emas)bitta o'zgaruvchan referens yoki xohlagan sondagi o'zgarmas referenslarga ega bo'lishingiz mumkin.
- Referenslar har doim yaroqli bo'lishi shart
Referenslar va Box<T> bilan, borrowing qoidalarining kompilyatsiya vaqtida o'zgarmaslar kuchga kiradi. RefCell<T> bilan esa ushbu o'zgarmaslar runtime paytida kuchga kiradi. Referenslar bilan, agar siz ushbu qoidalarni buzsangiz, sizda kompilyator xatoligi yuzaga keladi. RefCell<T> bilan suhbu qoidalarni buzganingizda, sizning dasturingizda panic vujudga kelib, dastur chiqib ketadi.
The advantages of checking the borrowing rules at compile time are that errors will be caught sooner in the development process, and there is no impact on runtime performance because all the analysis is completed beforehand. For those reasons, checking the borrowing rules at compile time is the best choice in the majority of cases, which is why this is Rust’s default.
Borrowing qoidalarini kompilyatsiay vaqtida tekshirishning yaxshi tarafi xatolarni development vaqtida tezroq topishdir, va runtime unumdorligiga ta'sir ko'rsatmaydi chunki hamma analizlar oldindan qilingan bo'ladi. Ko'p hollarda borrowing qoidalarini kompilyatsiya vaqtida tekshirish eng yaxshi tanlovdir, sababi ushbu xususiyat Rustda odatiy xususiyatidir.
Borrowing qoidalarini runtime vaqtida tekshrishning afzalligi shundaki, kompilyatsiya vaqtidagi tekshiruvlar tomonidan ruxsat etilmaganda ba'zi xotira uchun xavfsizlik ssenariylarga ruxsat beriladi. Rust kompilyatoriga o'xshagan statik analizlar o'z-o'zidan konservativdir. Kodni tahlil qilayotganda kodning ba'zi bir xususiyatlarini aniqlash qiyindir: bunga Halting Problem mashxur misol bo'la oladi, bu kitob doirasidan tashqarida bo'lsada lekin izlanib o'rganish uchun qiziq mavzu
Agar Rust kompilyatori egalik (ownership) qoidalari asosida kompilyatsiya qilayotganini aqiqlay olmasa, bu to'g'ri, ya'ni ishlab turgan dasturni rad etishi mumkin, shuning uchun ham konservativ hisoblanadi va bu ba'zi tahlillar uchun qiyindir. Agar Rust xatolikka ega bo'lgan dasturni qabul qilsa, foydalanuvchilar Rust beradigan kafolatlarga ishona olmaydilar. Agarda, Rust ishlab turgan dasturni rad etsa, dasturchi uchun noqulaylik tug'diradi, lekin hech qanday qo'rqinchli narsa bo'lmaydi. RefCell<T> turi sizning kodingiz borrowing qoidlariga amal qilayotganiga ishonchingiz komil bo'lganda lekin kompilyator buni tushuna olmayotganda va kafolat bera olmaganda foydalidir.
RefCell<T> Rc<T>ga o'xshab bitta potokli (oqimli) ssenariylarda ishlatilinadi va agar siz ko'p potokli (oqimli) holatda ishlatsangiz kompilyatsiya vaqtidagi xatolikni yuzaga keltiradi. Biz RefCell<T>ni ko'p potokli (oqimli) dasturda qanday qilib funksionalligini olishni 16-bo'limda ko'rib chiqamiz.
Quyida takrorlash uchun Box<T>, Rc<T>, yoki RefCell<T>ni tanlash sabablari:
Rc<T>bitta ma'lumotga ko'p egalarga ega bo'lish imkonini beradi;Box<T>vaRefCell<T>esa yagona egaga egadirlar;Box<T>kompilyatsiya vaqtida o'zgaruvchan va o'zgarmas borrowlarni tekshrilishini ta'minlaydi;Rc<T>kompilyatsiya vaqtida faqat o'zgarmas borrowlarni tekshrilishini ta'minlaydi;RefCell<T>runtimeda o'zgaruvchan va o'zgarmas borrowlarni tekshrilishini ta'minlaydi.- Because
RefCell<T>runtimeda o'zgaruvchan borrowlar tekshirilishi ta'minlaydi, agarRefCell<T>o'zgarmas bo'lsadaRefCell<T>ichida qiymatni o'zgaruvchan qilishingiz mumkin.
Qiymatni o'zgarmas qiymat ichida o'zgaruvchan qilish ichki o'zgaruvchanlik shaklidir (pattern). Keling ichki o'zgaruvchanlikni foydali ekanligini va bu qanday sodir bo'lishini misollarda ko'rib chiqaylik.
Ichki o'zgaruvchanlik: O'zgaruvchan Borrowdan O'zgarmas Qiymatga
Borrowing qoilari natijasida, o'zgarmas qiyamtga ega bo'lganingizda, siz o'zgaruvchan borrow qila olmaysiz. Masalan, ushbu kod kompilyatsiya qilinmaydi:
fn main() {
let x = 5;
let y = &mut x;
}Agar siz ushbu kodni kompilyatsiya qilishga harakat qilsangiz, quyidagi xatolik kelib chiqadi:
$ cargo run
Compiling borrowing v0.1.0 (file:///projects/borrowing)
error[E0596]: cannot borrow `x` as mutable, as it is not declared as mutable
--> src/main.rs:3:13
|
2 | let x = 5;
| - help: consider changing this to be mutable: `mut x`
3 | let y = &mut x;
| ^^^^^^ cannot borrow as mutable
For more information about this error, try `rustc --explain E0596`.
error: could not compile `borrowing` due to previous error
Shunday vaziyatlar borki qiymat o'zini-o'zi o'zining metodlarida o'zgarivchan qilishi
foydali hisoblanadi, lekin boshqa kodda o'zgarmas shaklda bo'ladi. Kodning doirasidan
tashqaridagi qiymat metodi qiymatni o'zgaruvchan qila olmaydi. RefCell<T>ni ishlatish ichki
o'zgaruvchanlikga ega bo'lishning bir yo'li hisoblanadi, lekin RefCell<T> borrowing
qoidalarini to'liq aylanib o'tmaydi: kompilyatorda borrow tekshiruvchisi shu ichki o'zgaruvchanlikka
ruxsat beradi, va borrowing qoidalari runtimes tekshiriladi. Agar qoidalarni rad etsangiz,
kompilyator xatoligini o'rniga panic! ko'rasiz.
RefCell<T>ni o'zgarmas qiymatni o'zgaruvchanga aylantirishni, hamda nimaga RefCell<T>ni
ishlatish foydali ekanligini amaliy misollarda ko'rib chiqaylik.
Ichki o'zgaruvchanlik uchun foydalanish holati/misoli: Soxta Obyektlar
Ayrim hollarda test vaqti dasturchi boshqa turni o'rniga kerakli hatti-harakatni kuzatish uchun va to'g'ri kompilyatsiya amalga oshirilganligini tasdiqlash uchun boshqa bir turni ishlatib ko'radi. Ushbu to'ldiruvchi tur test double deb ataladi. Qiyin bo'lgan sahna ko'rinishida aktyorning o'rniga chiqib, sahna ko'rinishi amalga oshirib beruvchi, ya'nikino yaratishda "kaskadyor" misolida ko'rib chiqaylik. Test doublelari boshqa turlarda test o'tkazayotganimizda xizmat qiladi. Soxta obyektlar test paytida nimalar sodir bo'lishini qayd etuvchi test doublelar o'ziga xos turlardan biri bo'lib, siz to'g'ri amallar amalga oshirilayotganini ko'zdan kechirishingiz mumkin.
Rustda boshqa dasturlash tillari kabi bir xil ma'noli obyektlarga ega emas, va soxta obyekt funksionalligini olgan standart kutubxonasi yo'q. Aksincha, soxta obyektlar kabi ish bajaruvchi struct yaratishingiz mumkin.
Ushbu ssenariyni ko'rib chiqaylik: qiymatni maksimal qiymatga nisbatan kuzatuvchi kutubxona yaratamiz va joriy qiymat maksimal qiymatga qanchalik yaqinligiga qarab bizga xabar jo'natib turadi. Ushbu kutubxona foydalanuvchi uchun ruxsat etilgan API 'call'lar sonini kuzatib borish uchun ishlatilishi mumkin, bu ishlatish mumkin bo'lgan bir misol.
Bizning kutubxonamiz faqatgina qiymatni maksimal qiymatga qanchalik yaqin ekanligi
va qaysi vaqtda qaysi xabar jo'natilishini kuzatib turish imkonini beredi. Bizning
kutubxonamizdan foydalanadigan ilovalar xabar jo'natish mexanizmini ta'minlashini
talab qiladi, ya'ni ilova xabarni ilova ichida, email orqali, matnli xabar ko'rinishida
yoki boshqa ko'rinishda yuborishi mumkin. Kutubxona ushbu tafsilotlarni bilishi talab etilmaydi.
Kutubxona uchun biz tomonimizdan qo'llaniladigan Messenger traitini implementatsiya qiladigan
narsa kerak xolos.
Faylnomi: src/lib.rs
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}15-20-ro'yxat: Qiymatni qanchalik maksimal qiymatga yaqinligini kuzatish va kerakli darajaga yetganda ogohlantiruvchi kutubxona
Ushbu kodning e'tiborli tomoni shundaki Messenger traitining send nomli metodi
xabarning matni hamdaselfga o'zgarmas referensni oladi. Ushbu trait bizning soxta
obyektimizning implementatisiyasi uchun kerak bo'lgan interfeys hisoblanadi, shu
holatda soxta obyekt haqiqiy obyektga o'xshab ishlatilishi mumkin. Yana bir muhim
tomoni shundaki, biz set_valueni ko'rinishini LimitTracker orqali ko'rishimiz mumkin.
Biz xohlaganimizcha o'tkazayotganimizni value parametri uchun o'zgartirishimiz mumkin,
lekin set_value biz da'vo qilishimiz mumkin bo'lgan narsani return qilmaydi. Agar biz
Messenger traitini implementatisiya qiladigan va ma'lum bir qiymatga ega bo'lgan LimitTracker
yaratsak, value uchun turli raqamlar berganimizda, xabar kerakli xabar ko'rinishida jo'natildi
deya olishni xohlaymiz.
Pochta orqali yoki matn xabar orqali xabar jo'natish o'rniga biz send ni ishga tushurib yuborilishi kerak bo'lgan xabarni
kuzatish uchun soxta obyekt kerak bo'ladi. Obyektning yangi namunasini yaratishimiz mumkin, soxta obyektdan foydalanadigan
LimitTracker yaratib, LimitTrackerda set_value metodini qo'llashimiz va soxta obyekt biz kutgan xabar bor yoki yo'qligin
tekshirib ko'ramiz. 15-21-ro'yxat soxta obyekt implementatsiya qilishga urinishi, lekin borrow tekshiruvchi ruxsat bermasligi ko'rsatilgan:
Faylnomi: src/lib.rs
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
struct MockMessenger {
sent_messages: Vec<String>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: vec![],
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
self.sent_messages.push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
let mock_messenger = MockMessenger::new();
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
limit_tracker.set_value(80);
assert_eq!(mock_messenger.sent_messages.len(), 1);
}
}15-21-ro'yxat: MockMessengerning implementatsiya qilishga urinishi, ammo borrow checker bunga ruxsat bermayotgaligi ko'rsatilgan
Ushbu test kodimiz Sent_messages maydoniga ega boʻlgan MockMessenger strukturasini belgilaydi va u Vecga ega bo'lgan String qiymatlari bilan joʻnatilishi kerak boʻlgan xabarlarni kuzatib boradi. Shuningdek, biz bo'sh xabarlar ro'yxati bilan boshlanadigan yangi MockMessenger qiymatlarini yaratishni qulay qilish uchun yangi funksiyasini aniqlaymiz. Biz bo'sh xabarlar ro'yxati bilan boshlanadigan yangi MockMessenger qiymatlarini yaratamiz. Keyin biz LimitTracker ga MockMessengerni berishimiz uchun MockMessenger uchun “Messenger” xususiyatini amalga oshiramiz. send usulining taʼrifida biz uzatilgan xabarni parametr sifatida qabul qilamiz va uni sent_messagesning MockMessenger roʻyxatida saqlaymiz.
Sinovda biz LimitTrackerga valueni max qiymatining 75 foizidan ko‘prog‘iga o‘rnatish buyurilganda nima sodir bo‘lishini sinab ko‘ramiz. Birinchidan, biz yangi MockMessenger ni yaratamiz, u xabarlarning bo'sh ro'yxati bilan boshlanadi. Keyin biz yangi LimitTracker yaratamiz va unga yangi MockMessenger va max qiymati 100 ga teng reference beramiz. 100dan 75dan katta bo'lgan, 80ga teng bo'lgan qiymatli LimitTrackerdagi set_value metodini ishga tushiramiz. Keyin biz MockMessenger kuzatayotgan xabarlar roʻyxatida bitta xabar boʻlishi kerakligini taʼkidlaymiz.
Biroq, bu testda ko'rsatilganidek, bitta muammo bor:
$ cargo test
Compiling limit-tracker v0.1.0 (file:///projects/limit-tracker)
error[E0596]: cannot borrow `self.sent_messages` as mutable, as it is behind a `&` reference
--> src/lib.rs:58:13
|
2 | fn send(&self, msg: &str);
| ----- help: consider changing that to be a mutable reference: `&mut self`
...
58 | self.sent_messages.push(String::from(message));
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ `self` is a `&` reference, so the data it refers to cannot be borrowed as mutable
For more information about this error, try `rustc --explain E0596`.
error: could not compile `limit-tracker` due to previous error
warning: build failed, waiting for other jobs to finish...
Biz MockMessengerni xabarlarni kuzatib borish uchun o‘zgartira olmaymiz, chunki send metodi selfga o'zgarmas refernce oladi. Shuningdek, xato matnidagi &mut self dan foydalanish taklifini ham qabul qila olmaymiz, chunki send signaturasi Messenger traiti taʼrifidagi imzoga toʻgʻri kelmas edi (urunib ko'rganingizda qanaqa xatolik (error message) bo'lishini ko'rishingiz mumkin).
Ushbu holatda bizga ichgi o'zgaruvchanlik yordam berishi mumkin! Biz RefCell<T> orqali sent_messagesni joylyamiz, va keyin biz ko'rgan xabarlarni joylashtirish uchun send metodi sent_messagesni o'zgartira oladi. 15-22-ro'yxat bu qanday ko'rinishda bo'lishini ko'rsatadi:
Faylnomi: src/lib.rs
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
use std::cell::RefCell;
struct MockMessenger {
sent_messages: RefCell<Vec<String>>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: RefCell::new(vec![]),
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
self.sent_messages.borrow_mut().push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
// --snip--
let mock_messenger = MockMessenger::new();
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
limit_tracker.set_value(80);
assert_eq!(mock_messenger.sent_messages.borrow().len(), 1);
}
}15-22-ro'yxat: tashqi qiymat o'zgarmas bo'lganida RefCell<T> yordamida ichki qiymatni o'zgaruvchan qilish
sent_messages maydoni endi Vec<String> oʻrniga RefCell<Vec<String>> turiga ega.
new funksiyada biz yangisini yaratamiz RefCell<Vec<String>> bo'sh vektor atrofidagi misol.
new funksiyasida biz yangi RefCell<Vec<String>> instancesini bo'sh vektor atrofida yaratib olamiz.
send metodini ishga tushirishda, traitning ma'no/tarifiga o'xshash bo'lgan birinchi parametr selfning o'zgarmas borrowi bo'lib qolaveradi. Vvektor hisoblangan RefCell<Vec<String>>ninig ichidagi qiymatga o'zgaruvchan reference olish uchun self.sent_messagesning RefCell<Vec<String>>dagi borrow_mutni ishga tushuramiz. Keyin test paytida yuborilgan xabarlarni kuzatib borish uchun vektorga o'zgaruvchan referenceda push ni ishga tushirishimiz mumkin.
Tasdiqlash uchun biz qilishimiz kerak bo'lgan oxirgi o'zgarish bu: ichki vektor ichida qancha itemlar borligini ko'rish uchun, vektorga o'zgarmas refrence olish uchunRefCell<Vec<String>>dagi borrowni ishga tushiramiz.
RefCell<T>dan qanday ishlatish mumkiniligi bilan tanishdik, keling qanday ishlashi haqida o'raganib chiqaylik.
Runtime vaqtidan RefCell<T> yordamida Borrowlarni kuzatish
O'zgarmas va o'zgaruvchan referencelarni yaratishda biz mos ravishda & va &mut sintaksisidan foydalanamiz. RefCell<T> bilan biz RefCell<T>ga tegishli xavfsiz API tarkibiga kiruvchi borrow va borrow_mut usullaridan foydalanamiz. borrow metodi Ref<T> smart pointer turini, borrow_mut esa RefMut<T> smart pointer turini qaytaradi. Ikkala tur ham Deref ni implementatsiya qiladi, shuning uchun biz ularni/doimiy oddiy reference kabi ko'rib chiqishimiz mumkin.
RefCell<T> hozirda qancha Ref<T> va RefMut<T> smart pointerlari faol ekanligini kuzatib boradi. Har safar biz borrow ishga tushirganimizda, RefCell<T> qancha o'zgarmas borrowlar faolligini oshiradi. Agar Ref<T> qiymati chegarasidan chiqib ketsa, o'zgarmas borrowlar soni bittaga kamayadi. Kompilyatsiya vaqtidagi borrowing qoidalari kabi, RefCell<T> bizga istalgan vaqtda koʻp oʻzgarmas yoki bitta oʻzgaruvchan borrowga ega boʻlish imkonini beradi.
Agar biz referencelarda bo'lgani kabi kompilyator xatosini olishdan ko'ra, ushbu qoidalarni buzishga harakat qilsak, RefCell<T> amalga oshirilishi runtime vaqtida panic qo'yadi. 15-23 ro'yxatda 15-22 ro'yxatda send ning implementatsiyasining modifikatsiyasi ko'rsatilgan. RefCell<T> runtimeda buni amalga oshirishga to'sqinlik qilishini ko‘rsatish uchun biz ataylab bir xil qamrov uchun faol ikkita o‘zgaruvchan borrowni yaratishga harakat qilapmiz.
Faylnomi: src/lib.rs
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
use std::cell::RefCell;
struct MockMessenger {
sent_messages: RefCell<Vec<String>>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: RefCell::new(vec![]),
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
let mut one_borrow = self.sent_messages.borrow_mut();
let mut two_borrow = self.sent_messages.borrow_mut();
one_borrow.push(String::from(message));
two_borrow.push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
let mock_messenger = MockMessenger::new();
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
limit_tracker.set_value(80);
assert_eq!(mock_messenger.sent_messages.borrow().len(), 1);
}
}Listing 15-23: Creating two mutable references in the
same scope to see that RefCell<T> will panic
borrow_mutdan qaytarilgan RefMut<T> smart pointer uchun one_borrow o'zgaruvchisini yaratamiz. Keyin two_borrow o'zgaruvchisida xuddi shu tarzda boshqa o'zgaruvchan borrow hosil qilamiz. Bu bir scopeda ikkita o'zgaruvchan reference qiladi, bu aslida mumkin emas. Kutubxonamiz uchun testlarni o'tkazganimizda, 15-23 ro'yxatdagi kod hech qanday xatosiz kompilyatsiya qilinadi, ammo test muvaffaqiyatsiz bo'ladi:
$ cargo test
Compiling limit-tracker v0.1.0 (file:///projects/limit-tracker)
Finished test [unoptimized + debuginfo] target(s) in 0.91s
Running unittests src/lib.rs (target/debug/deps/limit_tracker-e599811fa246dbde)
running 1 test
test tests::it_sends_an_over_75_percent_warning_message ... FAILED
failures:
---- tests::it_sends_an_over_75_percent_warning_message stdout ----
thread 'tests::it_sends_an_over_75_percent_warning_message' panicked at 'already borrowed: BorrowMutError', src/lib.rs:60:53
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::it_sends_an_over_75_percent_warning_message
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
E'tibor bering ushbu kod quyidagi panicni keltirib chiqardi already borrowed: BorrowMutError. Bu RefCell<T>runtime vaqtida borrowing qoidalari buzilishini boshqariishini ko'rsak bo'ladi
Ko'p marta qilganimizdek, ya'ni kompilyatsiya vaqtida emas, balki ish vaqtida borriwing
xatolarini ko'rish, ishlab chiqish jarayonida keyinchalik kodingizda
xatolar topishingiz mumkinligini anglatadi, ya'ni sizning kodingiz productionga
deploy qilinmagungacha. Bundan tashqari, sizning kodingiz kompilyatsiya vaqtida emas, aksincha runtime
vaqtida borrowlarni kuzatib borishi natijasida kichik runtime xatolik bo'lishi mumkin.
Lekin, RefCell<T>dan foydalanish faqat o'zgaruvchan qiymatlar mumkin bo'lgan kontekstdan foydalanayotgan
vaqtingizdagi xabarlarni kuzatish uchun o'zini o'zgaritira oladigan soxta obyektni yaratish imkonini beradi. Doimiy referencelardan ko'ra ko'proq funksionallikni olishni xohlasangiz RefCell<T>dan foydalanishingiz mumkin, uning farqli tomomnlariga qaramasdan ham.
Rc<T> va RefCell<T>ni birlashtirish orqali ozgaruvchan malumotlarning bir nechta egalariga ega bo`lish
RefCell<T> dan foydalanishning keng tarqalgan usuli Rc<T> bilan kombinatsiyadir. Eslatib o'tamiz, Rc<T> sizga ba'zi ma'lumotlarning bir nechta egalariga ega bo'lish imkonini beradi, lekin u faqat ushbu ma'lumotlarga o'zgarmas ruxsat beradi. Agar sizda RefCell<T> ga ega Rc<T> boʻlsa, siz bir nechta egalari boʻlishi mumkin boʻlgan va siz o'zgartira oladigan qiymatni olishingiz mumkin!
Misol uchun, 15-18-sonli ro'yxatdagi kamchiliklar ro'yxati misolini eslang, bu ro'yxatda bir nechta ro'yxatlarga boshqa ro'yxat egaligini ulashishga ruxsat berish uchun Rc<T> dan foydalanganmiz. Rc<T> faqat oʻzgarmas qiymatlarga ega boʻlgani uchun biz ularni yaratganimizdan soʻng biz roʻyxatdagi qiymatlarni oʻzgartira olmaymiz. Ro'yxatlardagi qiymatlarni o'zgartirish imkoniyatiga ega bo'lish uchun RefCell<T> ni qo'shaylik. 15-24-ro'yxat shuni ko'rsatadiki, Cons ta'rifida RefCell<T> dan foydalanib, biz barcha ro'yxatlarda saqlangan qiymatni o'zgartirishimiz mumkin:
src/main.rs nomli fayl:
#[derive(Debug)] enum List { Cons(Rc<RefCell<i32>>, Rc<List>), Nil, } use crate::List::{Cons, Nil}; use std::cell::RefCell; use std::rc::Rc; fn main() { let value = Rc::new(RefCell::new(5)); let a = Rc::new(Cons(Rc::clone(&value), Rc::new(Nil))); let b = Cons(Rc::new(RefCell::new(3)), Rc::clone(&a)); let c = Cons(Rc::new(RefCell::new(4)), Rc::clone(&a)); *value.borrow_mut() += 10; println!("a after = {:?}", a); println!("b after = {:?}", b); println!("c after = {:?}", c); }
15-24-ro'yxat: Rc<RefCell<i32>> yordamida o'zgaruvchan List yaratish
Keyinchalik to'g'ridan-to'g'ri foydalana olishimiz mumkin bo'lgan Rc<RefCell<i32>> namunasi (instance) bo'lgan qiymatni yaratamiz value nomli o'zgaruvchiga joylashtiramiz. Keyin a bilan birga valueni o'z ichiga olgan Cons variantida List yaratamiz. valueni klonlashimiz kerak bo'ladi, shunda valuedan aga ownershipni (egalik) berishdan yoki valuedan a borrowga ega bo;lishdan ko'ra a va valuening ikkalasi ham ichki 5ga ownershipga (egalikka) ega bo'ladilar.
15-18-ro'yxatda qilganimizdek, a ro'yxatini Rc<T> ichiga o'rab olamiz, shunda b va c ro'yxatlarini yaratganimizda, ular ikkalasi ham a ga murojaat (refer) qilishlari mumkin bo'ladi
a, b va c ro'yxatlarini yaratganimizdan so'ng, biz qiymat qiymatiga 10 qo'shmoqchimiz. Biz buni 5-bobda muhokama qilgan avtomatik yoʻqotish xususiyatidan foydalanadigan valueda borrow_mut ni ishga tushurishh orqali, ya'ni Rc<T>ni ichki RefCell<T> qiymatiga yo'naltirish orqali amalga oshiramiz ([-> Operatori Qayerda?”]ida ko'ring wheres-the---operator). borrow_mut usuli RefMut<T> smart pointerini qaytaradi va biz unda dereference operatoridan foydalanamiz va uning ichki qiymatni o`zgartiramiz.
a, b, va c print qilganimizda, 5dan ko'ra 15lik qiymatni hammasi o'zgaritirish kiritganligini ko'rishimiz mumkin.
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished dev [unoptimized + debuginfo] target(s) in 0.63s
Running `target/debug/cons-list`
a after = Cons(RefCell { value: 15 }, Nil)
b after = Cons(RefCell { value: 3 }, Cons(RefCell { value: 15 }, Nil))
c after = Cons(RefCell { value: 4 }, Cons(RefCell { value: 15 }, Nil))
Ushbu uslub juda jozibali! RefCell<T> dan foydalanib, biz tashqi o'zgarmas List qiymatiga ega bo'lamiz. Lekin biz RefCell<T> da uning ichki o'zgaruvchanligiga kirish/boshqarishni ta'minlaydigan metoddan foydalanishimiz mumkin, shunda kerak bo'lganda ma'lumotlarimizni o'zgartirishimiz mumkin. Runtime qarz olish (borrowing) qoidalari bizni ma'lumotlar o'zgaruvchanligidan (data races) himoya qilishini tekshiradi, va ba'zida ma'lumotlar tuzilmalarimizdagi bu moslashuvchanlik uchun biroz tezlikni oshirishga/o'zgaritishga (trading) arziydi. RefCell<T> ko'p oqimli (multithreaded) kod uchun ishlamaydi, shuni inobatga oling! Mutex<T> bu RefCell<T> ning xafsizroq versiyasidir va biz Mutex<T> ni 16-bobda muhokama qilamiz.
Yo'naltiruvchi tsikllar xotirani oqishi mumkin
Rustning xotira xavfsizligi kafolatlari buni qiyinlashtiradi, lekin imkonsiz emas
tasodifan hech qachon tozalanmaydigan xotira yaratish (xotira oqish deb nomlanadi).
Xotiraning oqishi to'liq oldini olish Rustning kafolatlaridan biri emas, ya'ni
xotira sızıntıları Rust-da xotira xavfsizdir. Rust xotira oqishiga ruxsat berishini ko'rishimiz mumkin
Rc<T> va RefCell<T> dan foydalanib: bu yerda havolalar yaratish mumkin.
elementlar siklda bir-biriga ishora qiladi. Bu xotira oqishini yaratadi, chunki
tsikldagi har bir elementning mos yozuvlar soni hech qachon 0 ga etib bormaydi va qiymatlar
hech qachon tashlab ketilmaydi.
Malumot siklini yaratish
Keling, mos yozuvlar sikli qanday sodir bo'lishi mumkinligini va uni qanday oldini olishni ko'rib chiqaylik,
Listingdagi List enum va tail usulining ta`rifidan boshlab
15-25:
Filename: src/main.rs
use crate::List::{Cons, Nil}; use std::cell::RefCell; use std::rc::Rc; #[derive(Debug)] enum List { Cons(i32, RefCell<Rc<List>>), Nil, } impl List { fn tail(&self) -> Option<&RefCell<Rc<List>>> { match self { Cons(_, item) => Some(item), Nil => None, } } } fn main() {}
Listing 15-25: A cons list definition that holds a
RefCell<T> so we can modify what a Cons variant is referring to
Biz 15-5 roʻyxatdagi “Roʻyxat” taʼrifining boshqa variantidan foydalanmoqdamiz. The
Cons variantidagi ikkinchi element endi RefCell<Rc<List>>, ya`ni
Biz Listingda bo'lgani kabi "i32" qiymatini o'zgartirish imkoniyatiga ega bo'lish o'rniga
15-24, biz 'Kasalliklar' varianti ko'rsatayotgan 'Ro'yxat' qiymatini o'zgartirmoqchimiz.
Bizga kirishni qulay qilish uchun biz "quyruq" usulini ham qo'shmoqdamiz
ikkinchi element, agar bizda "Kasalliklar" varianti bo'lsa.
15-26 roʻyxatda biz “asosiy” funksiyani qoʻshmoqdamiz.
Ro'yxat 15-25. Bu kod a royxatini va b ga ishora qiluvchi royxatni yaratadi
a ichidagi ro'yxat. Keyin u a royxatini b ga ishora qilib ozgartiradi va a ni yaratadi
mos yozuvlar aylanishi. Yo'lda nima ekanligini ko'rsatish uchun `println!' iboralari mavjud
mos yozuvlar soni bu jarayonning turli nuqtalarida.
Filename: src/main.rs
use crate::List::{Cons, Nil}; use std::cell::RefCell; use std::rc::Rc; #[derive(Debug)] enum List { Cons(i32, RefCell<Rc<List>>), Nil, } impl List { fn tail(&self) -> Option<&RefCell<Rc<List>>> { match self { Cons(_, item) => Some(item), Nil => None, } } } fn main() { let a = Rc::new(Cons(5, RefCell::new(Rc::new(Nil)))); println!("a initial rc count = {}", Rc::strong_count(&a)); println!("a next item = {:?}", a.tail()); let b = Rc::new(Cons(10, RefCell::new(Rc::clone(&a)))); println!("a rc count after b creation = {}", Rc::strong_count(&a)); println!("b initial rc count = {}", Rc::strong_count(&b)); println!("b next item = {:?}", b.tail()); if let Some(link) = a.tail() { *link.borrow_mut() = Rc::clone(&b); } println!("b rc count after changing a = {}", Rc::strong_count(&b)); println!("a rc count after changing a = {}", Rc::strong_count(&a)); // Uncomment the next line to see that we have a cycle; // it will overflow the stack // println!("a next item = {:?}", a.tail()); }
Listing 15-26: Creating a reference cycle of two List
values pointing to each other
Biz “a” o‘zgaruvchisida “Ro‘yxat” qiymatiga ega “Rc” misolini yaratamiz.
boshlang'ich ro'yxati "5, Nil" bilan. Keyin biz
Rc<List> misol xoldingini yaratamiz
10 qiymati va nuqtalarni o'z ichiga olgan "b" o'zgaruvchisidagi boshqa "Ro'yxat" qiymati
a ro'yxatiga.
Biz "a" ni o'zgartiramiz, shuning uchun u "Nil" o'rniga "b" ga ishora qiladi va sikl hosil qiladi. Biz qilamiz
RefCell<Rc<List>> ga havola olish uchun tail usuli yordamida
"a" da, biz "link" o'zgaruvchisini qo'yamiz. Keyin biz "borrow_mut" dan foydalanamiz
RefCell<Rc<List>> ichidagi qiymatni Rc<List>dan oʻzgartirish uchun usul
Bu b dagi Rc<List> uchun Nil qiymatiga ega.
Ushbu kodni ishga tushirganimizda, oxirgi println! uchun izoh berilgan
lahzada biz ushbu natijani olamiz:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished dev [unoptimized + debuginfo] target(s) in 0.53s
Running `target/debug/cons-list`
a initial rc count = 1
a next item = Some(RefCell { value: Nil })
a rc count after b creation = 2
b initial rc count = 1
b next item = Some(RefCell { value: Cons(5, RefCell { value: Nil }) })
b rc count after changing a = 2
a rc count after changing a = 2
a va bdagi Rc<List> misollarining mos yozuvlar soni 2 dan keyin
biz a royxatini b ga ishora qilish uchun ozgartiramiz. "Asosiy" oxirida Rust ni tushiradi
b o'zgaruvchisi, bu b Rc<List> misolining mos yozuvlar sonini kamaytiradi
2 dan 1 gacha. Rc<List> to'plamida bo'lgan xotira o'chirilmaydi.
bu nuqta, chunki uning mos yozuvlar soni 0 emas, 1. Keyin Rust a tushiradi, qaysi
a Rc<List> misolining mos yozuvlar sonini 2 dan 1 gacha kamaytiradi
yaxshi. Bu misolning xotirasini ham tashlab bo'lmaydi, chunki boshqasi
Rc<List> misoli hali ham unga ishora qiladi. Ro'yxatga ajratilgan xotira bo'ladi
abadiy yig'ilmagan qoladi. Ushbu mos yozuvlar siklini tasavvur qilish uchun biz yaratdik
15-4-rasmdagi diagramma.

Figure 15-4: A reference cycle of lists a and b
pointing to each other
Agar siz oxirgi println!-ni izohdan olib tashlasangiz va dasturni ishga tushirsangiz, Rust bunga harakat qiladi
bu siklni a bilan b a ga ishora qilib va shunga o`xshash davom etguncha chop eting
stekni to'ldirib yuboradi.
Haqiqiy dunyo dasturi bilan taqqoslaganda, oqibatlar mos yozuvlar aylanishini yaratadi bu misolda unchalik dahshatli emas: biz mos yozuvlar siklini yaratganimizdan so'ng, dastur tugaydi. Ammo, agar murakkabroq dasturda ko'p xotira ajratilgan bo'lsa siklda va uni uzoq vaqt ushlab tursa, dastur ko'proq xotiradan foydalanadi kerak bo'lganidan ko'ra va tizimni to'sib qo'yishi mumkin, bu esa uning tugashiga olib keladi mavjud xotira.
Malumot davrlarini yaratish oson emas, lekin bu ham imkonsiz emas.
Agar sizda Rc<T> qiymatlari yoki shunga o'xshash ichki o'rnatilgan RefCell<T> qiymatlari mavjud bo'lsa
ichki o'zgaruvchanlik va mos yozuvlar hisoblash bilan turlarning kombinatsiyasi, siz kerak
tsikllarni yaratmasligingizga ishonch hosil qiling; ularni qo'lga olish uchun siz Rustga tayanolmaysiz.
Malumot siklini yaratish dasturingizdagi mantiqiy xato bo'lishi mumkin
avtomatlashtirilgan testlar, kodlarni ko'rib chiqish va boshqa dasturiy ta'minotni ishlab chiqish amaliyotlaridan foydalaning
minimallashtirish.
Malumot davrlarini oldini olishning yana bir yechimi maʼlumotlaringizni qayta tashkil etishdir tuzilmalar shunday qilib, ba'zi havolalar egalik huquqini bildiradi, ba'zi havolalar esa bildirmaydi. Natijada, siz ba'zi egalik munosabatlaridan tashkil topgan davrlarga ega bo'lishingiz mumkin va ba'zi mulkiy bo'lmagan munosabatlar va faqat mulkchilik munosabatlari ta'sir qiladi qiymat tushirilishi mumkinmi yoki yo'qmi. 15-25 ro'yxatda biz har doim "Kasalliklar" ni xohlaymiz o'z ro'yxatiga egalik qilish variantlari mavjud, shuning uchun ma'lumotlar strukturasini qayta tashkil qilish mumkin emas. Keling, ota-ona va tugunlardan tashkil topgan grafiklardan foydalangan holda misolni ko'rib chiqaylik egalik bo'lmagan munosabatlar qachon oldini olish uchun to'g'ri yo'l ekanligini ko'rish mos yozuvlar davrlari.
Preventing Reference Cycles: Turning an Rc<T> into a Weak<T>
Hozirgacha biz "Rc::clone" ni chaqirish ko'rsatkichni oshirishini ko'rsatdik
Rc<T> misolining kuchli_hisobchasi va Rc<T> misoli faqat tozalanadi
yuqoriga, agar uning "kuchli_hisoblash" qiymati 0 bo'lsa. Shuningdek, "kuchli_hisob" ga * zaif havola* yaratishingiz mumkin
Rc<T> misolidagi qiymatni Rc::downgrade deb chaqirish va
Rc<T> ga havola. Kuchli havolalar egalik huquqini baham ko'rishingiz mumkin
Rc<T> misoli. Zaif havolalar egalik munosabatlarini bildirmaydi,
va Rc<T> namunasi tozalanganda ularning soni ta'sir qilmaydi. Ular
mos yozuvlar aylanishiga olib kelmaydi, chunki ba'zi zaif havolalarni o'z ichiga olgan har qanday tsikl
jalb qilingan qiymatlarning kuchli mos yozuvlar soni 0 bo'lsa, buziladi.
Rc::downgrade ga qongiroq qilganingizda, siz Zaif<T> tipidagi aqlli korsatgichga ega bolasiz.
Rc<T> misolidagi strong_count ni 1 ga oshirish orniga, Rc::downgrade zaif_hisobni1 ga oshiradi.Rcturi foydalanadi QanchaZaifhavolalari mavjudligini kuzatish uchunzaif_hisob kuchli_hisob. Farqi shundaki, "zaif_hisob" uchun 0 bo'lishi shart emas Rc
Chunki Zaif<T> havola qiladigan qiymat oʻchirilgan boʻlishi mumkin
Zaif<T> ko'rsatayotgan qiymatga ega bo'lgan har qanday narsaga ishonch hosil qilishingiz kerak
qiymati hali ham mavjud. Buni “ZaifOption<Rc<T>>ni qaytaradi. Siz "Ba'zi" natijasini olasiz
agar "RcRc<T> qiymati olib tashlandi. Chunki yangilash Option<Rc<T>>ni qaytaradi,
Rust Some ishi va None ishi ko'rib chiqilishini ta'minlaydi va
yaroqsiz ko'rsatgich bo'lmaydi.
Misol sifatida, elementlari faqat keyingi haqida biladigan ro'yxatni ishlatish o'rniga elementi boʻlsa, biz daraxt yaratamiz, uning obʼyektlari oʻz bolalari buyumlari haqida va ularning ota-onalari.
Creating a Tree Data Structure: a Node with Child Nodes
Boshlash uchun biz ularning tugunlari haqida biladigan tugunlari bo'lgan daraxt quramiz. Biz o'zining "i32" qiymatiga ega bo'lgan "tugun" nomli tuzilmani yaratamiz. uning bolalar 'Tugun' qiymatlariga havolalar:
Filename: src/main.rs
use std::cell::RefCell; use std::rc::Rc; #[derive(Debug)] struct Node { value: i32, children: RefCell<Vec<Rc<Node>>>, } fn main() { let leaf = Rc::new(Node { value: 3, children: RefCell::new(vec![]), }); let branch = Rc::new(Node { value: 5, children: RefCell::new(vec![Rc::clone(&leaf)]), }); }
Biz "Tugun" o'z farzandlariga ega bo'lishini istaymiz va biz bu egalikni baham ko'rmoqchimiz
o'zgaruvchilar, shuning uchun biz daraxtdagi har bir "Tugun" ga to'g'ridan-to'g'ri kirishimiz mumkin. Buning uchun biz
Vec<T> elementlarini Rc<Node> tipidagi qiymatlar sifatida belgilang. Biz ham xohlaymiz
qaysi tugunlar boshqa tugunning bolalari ekanligini o'zgartiring, shuning uchun bizda RefCell<T> mavjud
Vec<Rc<tugun>> atrofidagi bolalar.
Keyinchalik, biz strukturaning ta'rifidan foydalanamiz va bitta "Tugun" nomini yaratamiz
barg qiymati 3 va bolalari yo'q va boshqa misol filial
15-27 roʻyxatda koʻrsatilganidek, qiymati 5 va “barg” uning farzandlaridan biri sifatida:
Filename: src/main.rs
use std::cell::RefCell; use std::rc::Rc; #[derive(Debug)] struct Node { value: i32, children: RefCell<Vec<Rc<Node>>>, } fn main() { let leaf = Rc::new(Node { value: 3, children: RefCell::new(vec![]), }); let branch = Rc::new(Node { value: 5, children: RefCell::new(vec![Rc::clone(&leaf)]), }); }
Listing 15-27: Creating a leaf node with no children
and a branch node with leaf as one of its children
Biz Rc<tugun>ni bargda klonlaymiz va uni filialda saqlaymiz, yani Endi “barg”dagi “tugun” ikkita egasiga ega: “barg” va “novda”. dan olishimiz mumkin 'branch.children' orqali 'shox'dan 'barg'ga, lekin undan olishning iloji yo'q 'barg'dan 'filialga'. Sababi, barg sozi filial va
aloqadorligini bilmaydi. Biz “barg” “filial” uning ekanligini bilishini istaymiz
ota-ona. Biz buni keyin qilamiz.
Bolaning ota-onasiga havolani qo'shish
Bola tugunni ota-onasidan xabardor qilish uchun biz "ota-ona" maydonini qo'shishimiz kerak
bizning "tugun" tuzilmasining ta'rifi. Muammo nima turini tanlashda
"ota-ona" bo'lishi kerak. Biz bilamizki, unda Rc<T> bo'lishi mumkin emas, chunki bu bo'lar edi
leaf.parent filialga ishora qiluvchi mos yozuvlar siklini yarating va
bargga ishora qiluvchi filial.bolalar, bu ularning kuchli_hisobiga olib keladi
qiymatlar hech qachon 0 bo'lmasligi kerak.
O'zaro munosabatlar haqida boshqa yo'l bilan o'ylab, ota-ona tuguniga ega bo'lishi kerak bolalar: agar ota-ona tugunlari tushirilsa, uning tugunlari sifatida tushirilishi kerak yaxshi. Biroq, bola o'z ota-onasiga egalik qilmasligi kerak: agar biz bola tugunini tashlasak, ota-ona hali ham mavjud bo'lishi kerak. Bu zaif havolalar uchun holat!
Shunday qilib, "RcRefCell<Zaif<tugun>>. Endi bizning "tugun" tuzilmasining ta'rifi ko'rinadi
shunga o'xshash:
Filename: src/main.rs
use std::cell::RefCell; use std::rc::{Rc, Weak}; #[derive(Debug)] struct Node { value: i32, parent: RefCell<Weak<Node>>, children: RefCell<Vec<Rc<Node>>>, } fn main() { let leaf = Rc::new(Node { value: 3, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![]), }); println!("leaf parent = {:?}", leaf.parent.borrow().upgrade()); let branch = Rc::new(Node { value: 5, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![Rc::clone(&leaf)]), }); *leaf.parent.borrow_mut() = Rc::downgrade(&branch); println!("leaf parent = {:?}", leaf.parent.borrow().upgrade()); }
Tugun o'zining asosiy tuguniga murojaat qilishi mumkin, lekin uning ota-onasiga ega emas. 15-28 ro'yxatda biz ushbu yangi ta'rifdan foydalanish uchun "asosiy" ni yangilaymiz, shuning uchun "barg" tugun o'zining ota-onasi "filial" ga murojaat qilish usuliga ega bo'ladi:
Filename: src/main.rs
use std::cell::RefCell; use std::rc::{Rc, Weak}; #[derive(Debug)] struct Node { value: i32, parent: RefCell<Weak<Node>>, children: RefCell<Vec<Rc<Node>>>, } fn main() { let leaf = Rc::new(Node { value: 3, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![]), }); println!("leaf parent = {:?}", leaf.parent.borrow().upgrade()); let branch = Rc::new(Node { value: 5, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![Rc::clone(&leaf)]), }); *leaf.parent.borrow_mut() = Rc::downgrade(&branch); println!("leaf parent = {:?}", leaf.parent.borrow().upgrade()); }
Listing 15-28: A leaf node with a weak reference to its
parent node branch
“Yaproq” tugunini yaratish 15-27 roʻyxatga oʻxshaydi, bundan tashqari
"ota-ona" maydoni: "barg" ota-onasiz boshlanadi, shuning uchun biz yangisini yaratamiz,
bo'sh Zaif<tugun> mos yozuvlar misoli.
Shu nuqtada, biz yordamida barg ota-onasiga havola olishga harakat qilganimizda
"yangilash" usulida biz "Yo'q" qiymatini olamiz. Buni biz dan chiqishda ko'ramiz
birinchi println! bayonoti:
barg ota-onasi = Yo'q
Biz filial tugunini yaratganimizda, u ham yangi Zaif<tugun>ga ega bo'ladi.
"ota" maydonida havola, chunki "filial" da asosiy tugun yo'q.
Bizda hamon “barg” “filial” farzandlaridan biri. Bir marta bizda
“Filial”dagi “tugun” misolida biz “barg”ni “zaifbargning ota maydonida RefCell<Zaif<tugun>> va keyin biz
Rc::downgrade funksiyasidan filialga Zaif<tugun> havolasini yaratish
filialdagi Rc
Biz “barg” ning ota-onasini yana chop qilsak, bu safar “Ba’zi” variantini olamiz
"filial" ni ushlab turish: endi "barg" ota-onasiga kira oladi! Biz "barg" ni chop etganda, biz
Shuningdek, oxir-oqibat bizda bo'lgani kabi stekning to'lib ketishi bilan yakunlangan tsikldan qoching
Ro'yxat 15-26; Zaif<tugun> havolalari (Zaif) sifatida chop etiladi:
barg ota = Ba'zi(tugun {qiymat: 5, ota: RefCell {qiymat: (zaif)},
bolalar: RefCell { qiymat: [tugun {qiymat: 3, ota: RefCell {qiymat: (zaif)},
bolalar: RefCell { qiymat: [] } }] } })
Cheksiz chiqishning yo'qligi ushbu kod mos yozuvlar yaratmaganligini ko'rsatadi
tsikl. Buni biz qo'ng'iroq qilishdan olgan qadriyatlarimizga qarab ham aytishimiz mumkin
Rc::strong_count va Rc::weak_count.
"Kuchli_hisob" va "zaif_hisob" dagi o'zgarishlarni vizualizatsiya qilish
Keling, Rc<tugun> kuchli_hisoblash va zaif_hisoblash qiymatlari qanday ekanligini ko'rib chiqamiz.
misollar yangi ichki doirani yaratish va yaratishni ko'chirish orqali o'zgaradi
filial shu doiraga kiradi. Shunday qilib, biz "filial" bo'lganda nima sodir bo'lishini ko'rishimiz mumkin
yaratilgan va keyin u ko'lamdan chiqib ketganda tushib ketgan. O'zgartirishlar ko'rsatilgan
15-29 ro'yxatda:
Filename: src/main.rs
use std::cell::RefCell; use std::rc::{Rc, Weak}; #[derive(Debug)] struct Node { value: i32, parent: RefCell<Weak<Node>>, children: RefCell<Vec<Rc<Node>>>, } fn main() { let leaf = Rc::new(Node { value: 3, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![]), }); println!( "leaf strong = {}, weak = {}", Rc::strong_count(&leaf), Rc::weak_count(&leaf), ); { let branch = Rc::new(Node { value: 5, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![Rc::clone(&leaf)]), }); *leaf.parent.borrow_mut() = Rc::downgrade(&branch); println!( "branch strong = {}, weak = {}", Rc::strong_count(&branch), Rc::weak_count(&branch), ); println!( "leaf strong = {}, weak = {}", Rc::strong_count(&leaf), Rc::weak_count(&leaf), ); } println!("leaf parent = {:?}", leaf.parent.borrow().upgrade()); println!( "leaf strong = {}, weak = {}", Rc::strong_count(&leaf), Rc::weak_count(&leaf), ); }
Listing 15-29: Creating branch in an inner scope and
examining strong and weak reference counts
'barg' yaratilgandan so'ng, uning 'Rcbarg, biz hisoblarni chop etganda, filialdagi Rckuchli soni 1 va zaif soni 1 bo‘ladi (“leaf.parent” ko‘rsatish uchunzaifbilanfilialga). Hisoblarni “barg”da chop etganimizda, biz ko'ramiz uning kuchli soni 2 ga teng bo'ladi, chunki filialendi kloniga egabargning Rc branch.children` da saqlanadi, lekin baribir zaif bo'ladi.
soni 0.
Ichki qamrov tugagach, "filial" doiradan chiqib ketadi va kuchli soni
Rc<Node> 0 ga kamayadi, shuning uchun uning Tugun tushiriladi. Zaif hisob 1
'leaf.parent' dan "tugun" tushirilgan yoki yo'qligiga ta'sir qilmaydi, shuning uchun biz
hech qanday xotira oqishiga yo'l qo'ymang!
Qo'llanish doirasi tugagandan so'ng "barg" ning ota-onasiga kirishga harakat qilsak, biz olamiz
Yana 'Yo'q'. Dastur oxirida bargdagi Rc<tugun> kuchli
soni 1 va kuchsiz soni 0, chunki "barg" o'zgaruvchisi endi yagona
yana Rc<tugun> ga murojaat qiling.
Hisoblash va qiymatni pasaytirishni boshqaradigan barcha mantiq o'rnatilgan
Rc<T> va Zaif<T> va ularning Drop xususiyatini amalga oshirish. tomonidan
bolaning ota-onasiga bo'lgan munosabati a bo'lishi kerakligini ko'rsatib
Tugun tarifida zaif havolasi, siz ota-onaga ega bolishingiz mumkin
tugunlar mos yozuvlar siklini yaratmasdan, bola tugunlariga ishora qiladi va aksincha
va xotira oqadi.
Xulosa
Ushbu bobda turli xil kafolatlar berish uchun aqlli ko'rsatkichlardan qanday foydalanish kerakligi ko'rib chiqildi
Rust odatiy havolalar bilan sukut bo'yicha qiladi. The
Box<T> turi ma'lum o'lchamga ega va u yerda ajratilgan ma'lumotlarga ishora qiladi. The
Rc<T> turi to'pdagi ma'lumotlarga havolalar sonini kuzatib boradi
bu ma'lumotlar bir nechta egalariga ega bo'lishi mumkin. RefCell<T> turi ichki ko'rinishi bilan
o'zgaruvchanlik bizga o'zgarmas tur kerak bo'lganda foydalanishimiz mumkin bo'lgan turni beradi, lekin
ushbu turdagi ichki qiymatni o'zgartirish kerak; u qarz olishni ham majbur qiladi
kompilyatsiya vaqtida emas, balki ish vaqtidagi qoidalar.
Shuningdek, ko'plab imkoniyatlarni beradigan "Deref" va "Drop" xususiyatlari ham muhokama qilindi
aqlli ko'rsatkichlarning funksionalligi. Biz sabab bo'lishi mumkin bo'lgan mos yozuvlar davrlarini o'rganib chiqdik
xotira oqishi va ularni Zaif<T> yordamida qanday qilib oldini olish mumkin.
Agar ushbu bob sizni qiziqtirgan bo'lsa va siz o'zingiznikini amalga oshirmoqchi bo'lsangiz aqlli ko'rsatkichlar, foydaliroq bo'lishi uchun “The Rustonomicon” ni tekshiring ma'lumot.
Keyinchalik, biz Rustdagi parallellik haqida gaplashamiz. Siz hatto bir nechta yangi narsalarni bilib olasiz aqlli ko'rsatkichlar.
Fearless Concurrency
Bir vaqtning o'zida dasturlashni(concurrent programming) xavfsiz va samarali boshqarish Rustning asosiy maqsadlaridan biridir. Dasturning turli qismlari mustaqil ravishda bajariladigan(execute) concurrent programming va dasturning turli qismlari bir vaqtning o'zida bajariladigan parallel dasturlash ko'proq kompyuterlar o'zlarining bir nechta protsessorlaridan foydalanishlari sababli tobora muhim ahamiyat kasb etmoqda. Tarixiy jihatdan, ushbu kontekstlarda dasturlash qiyin va xatolarga moyil bo'lgan: Rust buni o'zgartirishga umid qilmoqda.
Dastlab, Rust jamoasi xotira xavfsizligini ta'minlash va parallel muammolarning oldini olish turli usullar bilan hal qilinishi kerak bo'lgan ikkita alohida muammo deb o'ylagan. Vaqt o'tishi bilan jamoa egalik(ownership) va turdagi tizimlar(type system) xotira xavfsizligi va parallellik muammolarini boshqarishga yordam beradigan kuchli vositalar to'plami ekanligini aniqladi! Ownership(egalik) va turlarni tekshirishdan(type checking) foydalangan holda, ko'plab parallellik xatolar runtimedagi xatolardan ko'ra Rustda kompilyatsiya vaqtidagi xatolardir. Shuning uchun, runtime bilan bir vaqtda xatolik yuzaga kelgan aniq holatlarni takrorlash uchun ko'p vaqt sarflashdan ko'ra, noto'g'ri kod kompilyatsiya qilishni rad etadi va muammoni tushuntiruvchi xatoni taqdim etadi. Natijada, siz kodingizni ishlab chiqarishga(production) yuborilgandan keyin emas, balki uning ustida ishlayotganingizda tuzatishingiz mumkin. Biz Rustning bu jihatini fearless concurrency deb nomladik. Fearless concurrency sizga nozik xatolarsiz kod yozish imkonini beradi va yangi xatolarni kiritmasdan qayta tiklash oson.
Eslatma: Oddiylik uchun biz ko'p muammolarni concurrent va yoki parallel deb aniqroq bo'lishdan ko'ra concurrent deb ataymiz. Agar bu kitob concurrency va yoki parallellik haqida bo'lsa, biz aniqroq bo'lardik. Ushbu bo'lim uchun, iltimos, biz concurrent ishlatganimizda, parallel va/yoki concurrentni aqliy ravishda almashtiring.
Ko'pgina tillar bir vaqtda muammolarni hal qilish(concurrent problem) uchun taklif qiladigan yechimlar haqida dogmatikdir. Misol uchun, Erlang xabarlarni bir vaqtda uzatish uchun oqlangan funksiyaga ega, ammo threadlar orasidagi holatni(state) almashishning noaniq usullariga ega. Mumkin bo'lgan yechimlarning faqat bir qismini qo'llab-quvvatlash high-leveldagi tillar uchun oqilona strategiyadir, chunki high-leveldagi til mavhumlikni qo'lga kiritish uchun ba'zi nazoratdan voz kechishdan foyda va'da qiladi. Biroq, low-leveldagi tillar har qanday vaziyatda eng yaxshi samaradorlik bilan yechimni ta'minlashi va hardwarega(qurilma) nisbatan kamroq abstraktsiyalarga ega bo'lishi kutilmoqda. Shu sababli, Rust sizning vaziyatingiz va talablaringizga mos keladigan tarzda muammolarni modellashtirish uchun turli xil vositalarni taklif qiladi.
Mana biz ushbu bobda muhokama qiladigan mavzular:
- Bir vaqtning o'zida bir nechta kod qismlarini ishlatish uchun threadlarni qanday yaratish kerak
- Message-passing Xabarlarni uzatish concurrency, bu yerda kanallar threadlar o'rtasida xabarlar yuboradi
- Shared-state bir vaqtning o'zida bir nechta thereadlar(multiple thread) ma'lumotlarning bir qismiga kirish huquqiga ega
SyncvaSendtraitlari, Rustning parallellik kafolatlarini foydalanuvchi tomonidan belgilangan turlarga hamda standart kutubxona tomonidan taqdim etilgan turlarga kengaytiradi.
Kodni bir vaqtning o'zida ishga tushirish uchun threadlardan foydalanish
Kodni bir vaqtning o'zida ishga tushirish(simultaneously) uchun threadlardan foydalanish hozirgi operatsion tizimlarning ko'pchiligida bajarilgan(execute) dastur kodi process ishga tushiriladi va operatsion tizim bir vaqtning o'zida bir nechta processlarni boshqaradi.Dastur doirasida siz bir vaqtning o'zida ishlaydigan(simultaneously) mustaqil qismlarga(independent part) ham ega bo'lishingiz mumkin. Ushbu mustaqil qismlarni boshqaradigan xususiyatlar threadlar deb ataladi. Masalan, veb-server bir vaqtning o'zida bir nechta so'rovlarga(requestlar) javob berishi uchun bir nechta(multiple) threadlarga ega bo'lishi mumkin.
Bir vaqtning o'zida bir nechta vazifalarni(multiple task) bajarish uchun dasturingizdagi hisoblashni bir nechta(multiple) threadlarga bo'lish unumdorlikni oshirishi mumkin, ammo bu murakkablikni ham oshiradi. Theredlar bir vaqtning o'zida(simultaneously) ishlashi mumkinligi sababli, kodingizning turli xil ish threadlaridagi qismlari qaysi tartibda ishlashi haqida hech qanday kafolat yo'q. Bu muammolarga olib kelishi mumkin, masalan:
- Race conditionlari, bu yerda threadlar ma'lumotlar yoki resurslarga mos kelmaydigan tartibda kirishadi
- Deadlock, bu yerda ikkita thread bir-birini kutib, ikkala threadning davom etishiga to'sqinlik qiladi
- Faqat ma'lum holatlarda yuzaga keladigan va qayta ishlab chiqarish va ishonchli tarzda tuzatish qiyin bo'lgan xatolar
Rust threadlardan foydalanishning salbiy ta'sirini yumshatishga harakat qiladi, lekin multithreadli kontekstda dasturlash hali ham ehtiyotkorlik bilan o'ylashni talab qiladi va bitta threadda ishlaydigan dasturlardan farq qiladigan kod tuzilishini talab qiladi.
Dasturlash tillari threadlarni turli yo'llar bilan amalga oshiradi(impelement qiladi) va ko'pgina operatsion tizimlar yangi threadlarni yaratish uchun til chaqirishi mumkin bo'lgan API-ni taqdim etadi. Rust standart kutubxonasi(standard library) 1:1 threadni amalga oshirish modelidan foydalanadi, bunda dastur har bir til uchun bitta operatsion tizim threadidan foydalanadi. 1:1 modeliga turli xil o'zgarishlarni keltirib chiqaradigan boshqa theredlar modellarini amalga oshiradigan(implement qiladigan) cratelar mavjud.
spawn yordamida yangi thread yaratish
Yangi thread yaratish uchun biz thread::spawn funksiyasini chaqiramiz va unga yangi threadda ishga tushirmoqchi bo'lgan kodni o'z ichiga olgan closureni (biz 13-bobda closurelar haqida gapirgan edik) o'tkazamiz. 16-1 ro'yxatdagi misol asosiy(main) threaddagi ba'zi matnni va yangi threaddagi boshqa matnni chop etadi:
Fayl nomi: src/main.rs
use std::thread; use std::time::Duration; fn main() { thread::spawn(|| { for i in 1..10 { println!("salom ochilgan threaddan {}-raqam!", i); thread::sleep(Duration::from_millis(1)); } }); for i in 1..5 { println!("salom, main threaddan {}-raqam!", i); thread::sleep(Duration::from_millis(1)); } }
Ro'yxat 16-1: Bir narsani chop etish uchun yangi thread yaratish, main thread esa boshqa narsalarni chop etish
Esda tutingki, Rust dasturining asosiy ishi tugagach, barcha ochilgan threadlar ishlashni tugatgan yoki tugatmaganidan qat'i nazar, o'chiriladi. Ushbu dasturning chiqishi har safar bir oz boshqacha bo'lishi mumkin, ammo u quyidagilarga o'xshaydi:
salom, main threaddan 1-raqam!
salom, ochilgan threaddan 1-raqam!
salom, main threaddan 2-raqam!
salom, ochilgan threaddan 2-raqam!
salom, main threaddan 3-raqam!
salom, ochilgan threaddan 3-raqam!
salom, main threaddan 4-raqam!
salom, ochilgan threaddan 4-raqam!
salom, ochilgan threaddan 5-raqam!
thread::sleepga chaqiruvlar threadni qisqa muddatga uning bajarilishini to'xtatishga majbur qiladi, bu esa boshqa threadning ishlashiga imkon beradi. Ehtimol, threadlar navbatma-navbat bo'ladi, lekin bu kafolatlanmaydi: bu sizning operatsion tizimingiz threadlarni qanday rejalashtirishiga(schedule) bog'liq. Bu ishga tushirishda birinchi bo'lib main thread chop etiladi, garchi ishlab chiqarilgan threadning chop etish bayonoti kodda birinchi bo'lib paydo bo'lsa ham. Va biz paydo bo'lgan thredga i 9 bo'lguncha chop etishni aytgan bo'lsak ham, asosiy thread yopilishidan oldin u 5 ga yetdi.
Agar siz ushbu kodni ishga tushirsangiz va faqat main threaddan olingan ma'lumotlarni ko'rsangiz yoki hech qanday o'xshashlikni ko'rmasangiz, operatsion tizimning threadlar o'rtasida almashishi uchun ko'proq imkoniyatlar yaratish uchun diapazonlardagi raqamlarni oshirib ko'ring.
join handlerlari yordamida barcha threadlar tugashini kutilmoqda
16-1 ro'yxatidagi kod ko'pincha main thread tugashi tufayli paydo bo'lgan threadni muddatidan oldin to'xtatibgina qolmay, balki threadlarning ishlash tartibiga kafolat yo'qligi sababli, biz ham yangi ochilgangan threadning umuman ishga tushishiga kafolat bera olmaymiz!
O'zgaruvchida thread::spawn ning qaytish(return) qiymatini saqlash orqali ochilgangan threadning ishlamasligi yoki muddatidan oldin tugashi muammosini hal qilishimiz mumkin. thread::spawn ning qaytish turi(return type) JoinHandle dir. JoinHandle - bu tegishli qiymat bo'lib, biz join metodini chaqirganimizda, uning threadi tugashini kutamiz. 16-2 ro'yxatda biz 16-1 ro'yxatda yaratgan JoinHandle dan qanday foydalanish va joinni chaqirish orqali yaratilgan thread main chiqishdan oldin tugashini ko'rsatadi:
Fayl nomi: src/main.rs
use std::thread; use std::time::Duration; fn main() { let handle = thread::spawn(|| { for i in 1..10 { println!("salom ochilgan threaddan {}-raqam!", i); thread::sleep(Duration::from_millis(1)); } }); for i in 1..5 { println!("salom, main threaddan {}-raqam!", i); thread::sleep(Duration::from_millis(1)); } handle.join().unwrap(); }
Roʻyxat 16-2: JoinHandle ni thread::spawn dan saqlash, threadning oxirigacha ishga tushishini kafolatlash
Handleda joinni chaqirish, handle bilan ifodalangan thread tugaguncha ishlayotgan threadni bloklaydi. Threadni bloklash uning ish bajarishi yoki chiqishining oldini olish degani. Biz chaqiruvni(call) main threadning foor loop siklidan keyin qo'yganimiz sababli, 16-2 ro'yxatini ishga tushirish shunga o'xshash natijani berishi kerak:
salom, main threaddan 1-raqam!
salom, main threaddan 2-raqam!
salom, ochilgan threaddan 1-raqam!
salom, main threaddan 3-raqam!
salom, ochilgan threaddan 2-raqam!
salom, main threaddan 4-raqam!
salom, ochilgan threaddan 3-raqam!
salom, ochilgan threaddan 4-raqam!
salom, ochilgan threaddan 5-raqam!
salom, ochilgan threaddan 6-raqam!
salom, ochilgan threaddan 7-raqam!
salom, ochilgan threaddan 8-raqam!
salom, ochilgan threaddan 9-raqam!
Ikki thread almashishda davom etadi, lekin main thread handle.join() chaqiruvi tufayli kutadi va hosil qilingan thread tugamaguncha tugamaydi.
Ammo keling, main da for loop siklidan oldin handle.join() ni ko‘chirsak nima bo‘lishini ko‘rib chiqamiz, masalan:
Fayl nomi: src/main.rs
use std::thread; use std::time::Duration; fn main() { let handle = thread::spawn(|| { for i in 1..10 { println!("salom ochilgan threaddan {}-raqam!", i); thread::sleep(Duration::from_millis(1)); } }); handle.join().unwrap(); for i in 1..5 { println!("salom, main threaddan {}-raqam!", i); thread::sleep(Duration::from_millis(1)); } }
Main thread ochilgan thread tugashini kutadi va keyin for loop siklini ishga tushiradi, shuning uchun bu yerda ko'rsatilganidek, chiqish boshqa qo'shilmaydi:
salom, ochilgan threaddan 1-raqam!
salom, ochilgan threaddan 2-raqam!
salom, ochilgan threaddan 3-raqam!
salom, ochilgan threaddan 4-raqam!
salom, ochilgan threaddan 5-raqam!
salom, ochilgan threaddan 6-raqam!
salom, ochilgan threaddan 7-raqam!
salom, ochilgan threaddan 8-raqam!
salom, ochilgan threaddan 9-raqam!
salom, main threaddan 1-raqam!
salom, main threaddan 2-raqam!
salom, main threaddan 3-raqam!
salom, main threaddan 4-raqam!
Kichik tafsilotlar(detail), masalan, join deb ataladigan joy, sizning threadlaringiz bir vaqtning o'zida ishlashi yoki ishlamasligiga ta'sir qilishi mumkin.
Threadlar bilan move closuredan foydalanish
Biz tez-tez closurelar thread::spawn ga o'tiladigan move kalit so'zidan foydalanamiz, chunki closure keyinchalik environmentdan foydalanadigan qiymatlarga ownershiplik(egalik) qiladi va shu tariqa bu qiymatlarga ownershiplik huquqini bir threaddan ikkinchisiga o'tkazadi. 13-bobning “Ma’lumotnomalarni qo‘lga kiritish yoki ownershiplik huquqini ko‘chirish” bo‘limida biz closure kontekstida moveni muhokama qildik. Endi biz move va thread::spawn o'rtasidagi o'zaro ta'sirga ko'proq e'tibor qaratamiz.
Ro'yxat 16-1da e'tibor bering, biz thread::spawn ga o'tadigan closure hech qanday argument talab qilmaydi: biz ochilgan thread kodidagi main threaddan hech qanday ma'lumotdan foydalanmayapmiz. Tugallangan threaddagi main threaddan ma'lumotlarni ishlatish uchun ochilgan threadning yopilishi kerakli qiymatlarni olishi kerak. 16-3 ro'yxatda main threadda vector yaratish va uni ishlab ochilgan threadda ishlatishga urinish ko'rsatilgan. Biroq, bu hali ishlamaydi, buni birozdan keyin ko'rasiz.
Fayl nomi: src/main.rs
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(|| {
println!("Mana vektor: {:?}", v);
});
handle.join().unwrap();
}Ro'yxat 16-3: main thread tomonidan yaratilgan vectorni boshqa threadda ishlatishga urinish
Closure v dan foydalanadi, shuning uchun u v ni oladi va uni closure environmentining bir qismiga aylantiradi. Chunki thread::spawn bu closureni yangi threadda ishga tushiradi, biz ushbu yangi thread ichidagi v ga kirishimiz kerak. Ammo biz ushbu misolni kompilatsiya qilganimizda, biz quyidagi xatoni olamiz:
$ cargo run
Compiling threads v0.1.0 (file:///projects/threads)
error[E0373]: closure may outlive the current function, but it borrows `v`, which is owned by the current function
--> src/main.rs:6:32
|
6 | let handle = thread::spawn(|| {
| ^^ may outlive borrowed value `v`
7 | println!("Here's a vector: {:?}", v);
| - `v` is borrowed here
|
note: function requires argument type to outlive `'static`
--> src/main.rs:6:18
|
6 | let handle = thread::spawn(|| {
| __________________^
7 | | println!("Here's a vector: {:?}", v);
8 | | });
| |______^
help: to force the closure to take ownership of `v` (and any other referenced variables), use the `move` keyword
|
6 | let handle = thread::spawn(move || {
| ++++
For more information about this error, try `rustc --explain E0373`.
error: could not compile `threads` due to previous error
Rust v ni qanday capture qilishni infers(xulosa) qiladi va println! faqat v ga reference kerakligi sababli, closure v ni olishga harakat qiladi. Biroq, muammo bor: Rust ochilgan threrad qancha vaqt ishlashini ayta olmaydi, shuning uchun v ga reference har doim haqiqiy(valiq yaroqli) bo'lishini bilmaydi.
16-4 ro'yxatda v ga reference bo'lishi mumkin bo'lgan senariy ko'rsatilgan va u yaroqli(valiq) bo'lmaydi:
Fayl nomi: src/main.rs
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(|| {
println!("Mana vektor: {:?}", v);
});
drop(v); // oh no!
handle.join().unwrap();
}Roʻyxat 16-4: v tushiradigan main threaddan v ga referenceni olishga harakat qiluvchi yopilgan thread.
Agar Rust bizga ushbu kodni ishga tushirishga ruxsat bergan bo'lsa, ochilgan thread umuman ishlamasdan darhol fonga qo'yilishi mumkin. Ochilgan thread ichida v ga reference bor, lekin main thread darhol v ni tushiradi, biz 15-bobda muhokama qilgan drop funksiyasidan foydalangan holda. Keyin, ochilgan thread bajarila boshlaganda, v endi haqiqiy(valiq) emas, shuning uchun unga referense ham yaroqsiz. Oh yo'q!
16-3 ro'yxatdagi kompilyator xatosini tuzatish uchun xato xabari maslahatidan foydalanishimiz mumkin:
help: to force the closure to take ownership of `v` (and any other referenced variables), use the `move` keyword
|
6 | let handle = thread::spawn(move || {
| ++++
Closuredan oldin move kalit so‘zini qo‘shish orqali biz closureni Rustga qiymatlarni olishi kerak degan xulosaga(infer) kelishga ruxsat berishdan ko‘ra, u foydalanadigan qiymatlarga ownershiklik qilishga majburlaymiz. 16-5 ro'yxatda ko'rsatilgan 16-3 ro'yxatga kiritilgan o'zgartirish biz xohlagan tarzda kompilatsiya bo'ladi va ishlaydi:
Fayl nomi: src/main.rs
use std::thread; fn main() { let v = vec![1, 2, 3]; let handle = thread::spawn(move || { println!("Mana vektor: {:?}", v); }); handle.join().unwrap(); }
Roʻyxat 16-5: move kalit soʻzidan foydalanib, closureni oʻzi foydalanadigan qiymatlarga ownershiplik qilishga majburlash
Kodni 16 4 ro'yxatida tuzatish uchun xuddi shu narsani sinab ko'rishimiz mumkin, bu yerda main thread move closuresi orqali drop deb ataladi. Biroq, bu tuzatish ishlamaydi, chunki 16-4-raqamli roʻyxat boshqa sabablarga koʻra amalga oshirilmaydi. Agar biz closurega move ni qo‘shsak, biz v ni closure environmentiga o'tkazamiz va biz main threadda endi drop ni chaqira olmaymiz. Buning o'rniga biz ushbu kompilyator xatosini olamiz:
$ cargo run
Compiling threads v0.1.0 (file:///projects/threads)
error[E0382]: use of moved value: `v`
--> src/main.rs:10:10
|
4 | let v = vec![1, 2, 3];
| - move occurs because `v` has type `Vec<i32>`, which does not implement the `Copy` trait
5 |
6 | let handle = thread::spawn(move || {
| ------- value moved into closure here
7 | println!("Here's a vector: {:?}", v);
| - variable moved due to use in closure
...
10 | drop(v); // oh no!
| ^ value used here after move
For more information about this error, try `rustc --explain E0382`.
error: could not compile `threads` due to previous error
Rustning ownershiplik(egalik) qoidalari bizni yana qutqardi! 16-3 roʻyxatdagi koddan xatoga yoʻl qoʻydik, chunki Rust konservativ boʻlib, thread uchun faqat v harfini oldi, bu esa main thread nazariy jihatdan ochilgangan threadning referenceni bekor qilishi mumkinligini anglatadi. Rustga v ownershiplik huquqini ochilgan threadga o'tkazishni aytish orqali biz Rustga main thread endi v dan foydalanmasligiga kafolat beramiz. Agar biz 16-4 ro'yxatni xuddi shunday o'zgartirsak, main threadda v dan foydalanmoqchi bo'lganimizda ownershiplik qoidalarini buzgan bo'lamiz. move kalit so'zi Rustning borrowing olishning konservativ defaultini bekor qiladi; ownershiplik qoidalarini buzishimizga yo'l qo'ymaydi.
Threadar va thread API haqida asosiy tushunchaga ega bo'lgan holda, keling, threadlar bilan nima qilishimiz mumkinligini ko'rib chiqaylik.
Threadlar orasidagi ma'lumotlarni uzatish uchun Message Passing(xabar uzatish)dan foydalanish
Xavfsiz concurrencyni ta'minlashning tobora ommalashib borayotgan yondashuvlaridan biri bu message passing bo'lib, bu yerda threadlar yoki actorlar bir-biriga ma'lumotlarni o'z ichiga olgan xabarlarni yuborish orqali muloqot qilishadi. Go tili texnik hujjatlaridagi shiordagi g‘oya: “Xotirani almashish(share) orqali muloqot qilmang; Buning o'rniga, muloqot(communication) orqali xotirani share qiling."
Message-sending(xabar yuborish) concurrencyni amalga oshirish uchun Rustning standart kutubxonasi channels amalga oshirishni ta'minlaydi. Channel(kanal) - bu umumiy dasturlash tushunchasi bo'lib, uning yordamida ma'lumotlar bir threaddan ikkinchisiga yuboriladi.
Dasturlashdagi kanalni(channel) oqim yoki daryo kabi suvning yo'naltirilgan kanali kabi tasavvur qilishingiz mumkin. Agar siz daryoga rezina o'rdak kabi narsalarni qo'ysangiz, u suv yo'lining oxirigacha pastga tushadi.
Kanalning ikkita yarmi bor: uzatuvchi(transmitte) va qabul qiluvchi(receiver). Transmitterning yarmi daryoga rezina o'rdak qo'yadigan yuqori oqim joyidir va qabul qiluvchining yarmi rezina o'rdak quyi oqimga tushadi. Kodingizning bir qismi siz yubormoqchi bo'lgan ma'lumotlarga ega bo'lgan transmitterdagi metodlarni chaqiradi, boshqa qismi esa kelgan xabarlarni qabul qiluvchi tomonni tekshiradi. Agar transmitter yoki receiverning yarmi tushib qolsa, kanal closed(yopiq) deyiladi.
Bu yerda biz qiymatlarni yaratish va ularni kanalga yuborish uchun bitta threadga ega bo'lgan dasturni va qiymatlarni qabul qiladigan va ularni chop etadigan boshqa threadni ishlab chiqamiz. Featureni tasvirlash uchun kanal yordamida threadlar orasidagi oddiy qiymatlarni yuboramiz. Texnika bilan tanishganingizdan so'ng, siz bir-biringiz bilan aloqa o'rnatishingiz kerak bo'lgan har qanday threadlar uchun kanallardan foydalanishingiz mumkin, masalan, chat tizimi yoki ko'p threadlar hisoblash qismlarini bajaradigan va qismlarni natijalarni jamlaydigan bitta threadga yuboradigan tizim.
Birinchidan, 16-6 ro'yxatda biz channel(kanal) yaratamiz, lekin u bilan hech narsa qilmaymiz. E'tibor bering, bu hali kompilyatsiya qilinmaydi, chunki Rust kanal orqali qanday turdagi qiymatlarni yuborishimizni ayta olmaydi.
Fayl nomi: src/main.rs
use std::sync::mpsc;
fn main() {
let (tx, rx) = mpsc::channel();
}Ro'yxat 16-6: Kanal yaratish va ikkita yarmini tx va rx ga belgilash
Biz mpsc::channel funksiyasidan foydalanib yangi kanal yaratamiz; mpsc multiple producer, single consumer degan maʼnoni anglatadi. Qisqa qilib aytganda, Rustning standart kutubxonasi kanallarni implement qilish usuli kanalda qiymatlarni ishlab chiqaradigan bir nechta sending(jo'natish) uchlari bo'lishi mumkin, ammo bu qiymatlarni qabul qiladigan consumer faqat bitta receiving(qabul qiluvchi) end bo'lishi mumkinligini anglatadi. Tasavvur qiling-a, bir nechta daryolar birlashib, bitta katta daryoga quyiladi: har qanday oqim oxirida bitta daryoga tushadi. Hozircha biz bitta ishlab chiqaruvchidan(single producer) boshlaymiz, lekin biz ushbu misol ishlaganda bir nechta producerlarni(multiple producer) qo'shamiz.
mpsc::channel funksiyasi tupleni qaytaradi, uning birinchi elementi jo'natuvchi end - transmitter va ikkinchi element - receiver end - qabul qiluvchidir. tx va rx qisqartmalari an'anaviy ravishda ko'plab sohalarda mos ravishda transmitter va receiver uchun ishlatiladi, shuning uchun biz har bir endni ko'rsatish uchun o'zgaruvchilarimizni shunday nomlaymiz. Biz tuplelarni destruksiya pattern let statementdan foydalanmoqdamiz; Biz 18-bobda let statementlarida patternlardan foydalanish va destruksiyani muhokama qilamiz. Hozircha shuni bilingki, let statementdan shu tarzda foydalanish mpsc::channel tomonidan qaytarilgan tuple qismlarini ajratib olishning qulay usuli hisoblanadi.
16-7 ro'yxatda ko'rsatilganidek, transmitter uchini ochilgan threadga o'tkazamiz va u bitta threadni yuborsin, shunda hosil qilingan thread main thread bilan bog'lanadi. Bu daryoning yuqori oqimiga rezina o'rdak qo'yish yoki bir threaddan ikkinchisiga chat xabarini yuborishga o'xshaydi.
Fayl nomi: src/main.rs
use std::sync::mpsc; use std::thread; fn main() { let (tx, rx) = mpsc::channel(); thread::spawn(move || { let val = String::from("salom"); tx.send(val).unwrap(); }); }
Roʻyxat 16-7: tx ni ochilgan threadga koʻchirish va salom yuborish
Shunga qaramay, biz yangi thread yaratish uchun thread::spawn dan foydalanamiz va keyin move yordamida tx ni yopishga(close) o'tkazamiz, shunda hosil qilingan thread txga ega bo'ladi. Kanal orqali xabarlarni jo'natish uchun ochilgan thread transmitterga ega bo'lishi kerak. Transmitterda biz jo'natmoqchi bo'lgan qiymatni qabul qiluvchi send metodi mavjud. send metodi Result<T, E> typeni qaytaradi, shuning uchun agar qabul qiluvchi(receiver) allaqachon drop qilingan bo'lsa va qiymatni yuborish uchun joy bo'lmasa, yuborish operatsiyasi xatolikni qaytaradi. Ushbu misolda biz xatolik yuz berganda panic qo'yish uchun unwrap ni chaqiramiz. Ammo haqiqiy dasturda biz uni to'g'ri hal qilamiz: xatolarni to'g'ri hal qilish strategiyalarini ko'rib chiqish uchun 9-bobga qayting.
16-8 ro'yxatda biz main threaddagi qabul qiluvchidan(receive) qiymatni olamiz. Bu daryoning oxiridagi suvdan rezina o'rdakni olish yoki suhbat xabarini olish kabi.
Fayl nomi: src/main.rs
use std::sync::mpsc; use std::thread; fn main() { let (tx, rx) = mpsc::channel(); thread::spawn(move || { let val = String::from("salom"); tx.send(val).unwrap(); }); let received = rx.recv().unwrap(); println!("Tushundim: {}", received); }
Ro'yxat 16-8: main threadda salom qiymatini olish va uni chop etish
Receiverda ikkita foydali metod mavjud: recv va try_recv. Biz recv dan foydalanmoqdamiz, bu receive(qabul qilish) ning qisqartmasi bo'lib, u main threadning bajarilishini bloklaydi va kanalga qiymat yuborilguncha kutadi. Qiymat yuborilgach, recv uni Result<T, E> shaklida qaytaradi. Transmitter yopilganda, recv boshqa qiymatlar kelmasligini bildirish uchun xatolikni qaytaradi.
try_recv metodi bloklanmaydi, aksincha darhol Result<T, E>ni qaytaradi: Ok qiymati, agar mavjud bo‘lsa, xabarni ushlab turadi va bu safar hech qanday xabar bo‘lmasa, Err qiymati. try_recv dan foydalanish, agar ushbu thread xabarlarni kutayotganda boshqa ishi boʻlsa foydali boʻladi: biz tez-tez try_recv ni chaqiradigan, agar mavjud bo'lsa, xabarni ko'rib chiqadigan va boshqasi qayta tekshirilgunga qadar biroz vaqt ishlaydigan sikl yozishimiz mumkin.
Biz ushbu misolda soddalik uchun recv dan foydalandik; bizda main thread uchun xabarlarni kutishdan boshqa ishimiz yo'q, shuning uchun main threadi bloklash maqsadga muvofiqdir.
Kodni 16-8 ro'yxatda ishga tushirganimizda, biz main threaddan chop etilgan qiymatni ko'ramiz:
Tushundim: salom
Mukammal! Perfect!
Kanallar va ownershiplik(egalkik) huquqini o'tkazish
Ownershiplik qoidalari xabarlarni jo'natishda muhim rol o'ynaydi, chunki ular xavfsiz, bir vaqtda kod yozishga yordam beradi. Bir vaqtning o'zida dasturlashda(concurrent programming) xatolarning oldini olish Rust dasturlarida ownershiplik haqida o'ylashning afzalligi hisoblanadi. Muammolarning oldini olish uchun kanallar va ownershiplik qanday ishlashini ko‘rsatish uchun tajriba o‘tkazamiz: biz kanalga yuborganimizdan so‘ng val qiymatidan foydalanishga harakat qilamiz. Nima uchun bu kodga ruxsat berilmaganligini bilish uchun 16-9-raqamdagi kodni kompilyatsiya qilib ko'ring:
Fayl nomi: src/main.rs
use std::sync::mpsc;
use std::thread;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let val = String::from("salom");
tx.send(val).unwrap();
println!("qandaysan {}", val);
});
let received = rx.recv().unwrap();
println!("Tushundim: {}", received);
}Roʻyxat 16-9: valni kanalga yuborganimizdan keyin foydalanishga urinish
Bu yerda biz tx.send orqali kanalga yuborganimizdan so‘ng valni chop etishga harakat qilamiz.
Bunga ruxsat berish noto'g'ri fikr bo'ladi: qiymat boshqa threadga yuborilgandan so'ng, biz qiymatni qayta ishlatishdan oldin uni o'zgartirishi yoki tashlab yuborishi(drop) mumkin. Potensial ravishda, boshqa threadning o'zgartirishlari nomuvofiq yoki mavjud bo'lmagan ma'lumotlar tufayli xatolar yoki kutilmagan natijalarga olib kelishi mumkin. Biroq, agar biz 16-9 ro'yxatdagi kodni kompilyatsiya qilmoqchi bo'lsak, Rust bizga xato qiladi:
$ cargo run
Compiling message-passing v0.1.0 (file:///projects/message-passing)
error[E0382]: borrow of moved value: `val`
--> src/main.rs:10:31
|
8 | let val = String::from("hi");
| --- move occurs because `val` has type `String`, which does not implement the `Copy` trait
9 | tx.send(val).unwrap();
| --- value moved here
10 | println!("val is {}", val);
| ^^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0382`.
error: could not compile `message-passing` due to previous error
Bizning concurrency xatomiz kompilyatsiya vaqtida xatolikka olib keldi. send funksiyasi oʻz parametriga ownershiplik qiladi va qiymat koʻchirilganda qabul qiluvchi(receiver) unga ownershiplik qiladi. Bu bizni qiymatni yuborgandan keyin tasodifan qayta ishlatishdan to'xtatadi; ownershiplik tizimi hamma narsa yaxshi ekanligini tekshiradi.
Bir nechta qiymatlarni yuborish va qabul qiluvchining(receiver) kutayotganini ko'rish
16-8 ro'yxatdagi kod kompilatsiya bo'ldi va ishga tushirildi, lekin u bizga ikkita alohida thread kanal orqali bir-biri bilan gaplashayotganini aniq ko'rsatmadi. 16-10-ro'yxatda biz 16-8-ro'yxatdagi kod bir vaqtda ishlayotganini tasdiqlovchi ba'zi o'zgartirishlar kiritdik: ochilgan thread endi bir nechta xabarlarni yuboradi va har bir xabar o'rtasida bir soniya pauza qiladi.
Fayl nomi: src/main.rs
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let vals = vec![
String::from("qandaysan"),
String::from("otabek"),
String::from("vodiyga"),
String::from("ketti"),
];
for val in vals {
tx.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
for received in rx {
println!("Tushundim: {}", received);
}
}Ro'yxat 16-10: Bir nechta xabarlarni yuborish va har biri o'rtasida pauza qilish
Bu safar, ochilgan threadda biz main threadga yubormoqchi bo'lgan satrlar vektori mavjud. Biz ularni takrorlaymiz, har birini alohida yuboramiz va 1 soniyalik Duration qiymati bilan thread::sleep funksiyasini chaqirish orqali har biri o‘rtasida pauza qilamiz.
Main threadda biz endi recv funksiyasini aniq chaqirmayapmiz: buning o'rniga biz rx ni iterator sifatida ko'rib chiqamiz. Qabul qilingan har bir qiymat uchun biz uni chop etamiz. Kanal yopilganda(close), iteratsiya tugaydi.
16-10 ro'yxatdagi kodni ishga tushirganda, har bir satr orasida 1 soniyalik pauza bilan quyidagi chiqishni ko'rishingiz kerak:
Tushundim: qandaysan
Tushundim: otabek
Tushundim: vodiyga
Tushundim: ketti
Bizda main threaddagi for siklida pauza yoki kechikishlar keltirib chiqaradigan kod yo‘qligi sababli, biz main thread hosil qilingan threaddan qiymatlarni olishni kutayotganini aytishimiz mumkin.
Transmitterni klonlash orqali bir nechta producerlarni yaratish
Avvalroq mpsc multiple producer, single consumer degan qisqartma ekanligini eslatib o'tgan edik. Keling, 16-10 ro'yxatdagi kodni ishlatish va kengaytirish uchun mpsc ni qo'yaylik va barchasi bir xil qabul qiluvchiga(receiver) qiymatlarni yuboradigan bir nechta threadlarni yaratamiz. Biz buni 16-11 ro'yxatda ko'rsatilganidek, transmitterni klonlash orqali amalga oshirishimiz mumkin:
Fayl nomi: src/main.rs
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn main() {
// --snip--
let (tx, rx) = mpsc::channel();
let tx1 = tx.clone();
thread::spawn(move || {
let vals = vec![
String::from("salom"),
String::from("threaddan"),
String::from("siz"),
String::from("uchun"),
];
for val in vals {
tx1.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
thread::spawn(move || {
let vals = vec![
String::from("ko'plab"),
String::from("habarlar"),
String::from("hammasi"),
String::from("ishlayapti"),
];
for val in vals {
tx.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
for received in rx {
println!("Tushundim: {}", received);
}
// --snip--
}Ro'yxat 16-11: Bir nechta producerlardan(multiple producer) bir nechta xabarlarni(multiple message) yuborish
Bu safar, birinchi ochilgan threadni yaratishdan oldin, biz transmitterda clone deb nomlaymiz. Bu bizga yangi transmitterni beradi, biz birinchi ochilgan threadga o'tishimiz mumkin. Biz asl transmitterni ikkinchi ochilgan threadga o'tkazamiz.
Bu bizga ikkita thread beradi, ularning har biri bitta qabul qiluvchiga(receiver) turli xabarlar yuboradi.
Kodni ishga tushirganingizda, chiqishingiz quyidagicha ko'rinishi kerak:
Tushundim: salom
Tushundim: threaddan
Tushundim: siz
Tushundim: uchun
Tushundim: ko'plab
Tushundim: habarlar
Tushundim: hammasi
Tushundim: ishlayapti
Tizimingizga qarab qiymatlarni boshqa tartibda ko'rishingiz mumkin. Bu concurrencyni qiziqarli va qiyin qiladi. Agar siz thread::sleep bilan tajriba o'tkazsangiz, unga turli threadlarda turli qiymatlar bersangiz, har bir ishga tushirish aniqroq bo'lmaydi va har safar har xil chiqish hosil qiladi.
Endi biz kanallar qanday ishlashini ko'rib chiqdik, keling, boshqa concurrency usulini ko'rib chiqaylik.
Concurrencyda Shared-State
Message passing(Xabarni uzatish) - bu concurrencyni boshqarishning yaxshi usuli, ammo bu yagona emas. Yana bir usul bir nechta(multiple) threadlar bir xil umumiy ma'lumotlarga(shared data) kirishlari mumkin. Go tilidagi texnik hujjatlardagi shiorning ushbu qismini yana bir bor ko'rib chiqing: "xotirani almashish(sharing memory) orqali muloqot(comminicate) qilmang."
Xotirani almashish(sharing memory) orqali muloqot(comminication) qanday ko'rinishga ega bo'lar edi? Bundan tashqari, nima uchun message-passing enthusiastlar memory sharingdan foydalanmaslik haqida ogohlantiradilar?
Qaysidir ma'noda, har qanday dasturlash tilidagi kanallar bitta ownershiplik huquqiga o'xshaydi, chunki qiymatni kanalga o'tkazganingizdan so'ng, siz boshqa qiymatdan foydalanmasligingiz kerak. Shared memory concurrencyda bir nechta ownershiplik huquqiga o'xshaydi: concurrencyda bir nechta threadlar bir xil xotira joyiga(memory location) kirishi mumkin. 15-bobda ko'rganingizdek, smart pointerlar bir nechta ownershiplik qilish imkoniyatini yaratdi, bir nechta(multiple) ownershiplik murakkablikni oshirishi mumkin, chunki bu turli ownerlarni boshqarish kerak. Rust type tizimi va ownershiplik qoidalari ushbu boshqaruvni to'g'ri bajarishga katta yordam beradi. Misol uchun, shared memory uchun eng keng tarqalgan concurrency primitivlaridan biri bo'lgan mutexlarni ko'rib chiqaylik.
Bir vaqtning o'zida bitta threaddan ma'lumotlarga kirishga ruxsat berish uchun mutexlardan foydalanish
Mutex bu mutual exclusion ning qisqartmasi boʻlib, mutex istalgan vaqtda baʼzi maʼlumotlarga faqat bitta threadga kirish imkonini beradi. Mutexdagi ma'lumotlarga kirish uchun thread birinchi navbatda mutexning *lock(qulf)*ni olishni so'rab kirishni xohlashini bildirishi kerak. Lock(qulf) - bu mutexning bir qismi bo'lgan ma'lumotlar tuzilmasi bo'lib, u hozirda ma'lumotlarga kimning eksklyuziv kirish huquqiga ega ekanligini kuzatib boradi. Shuning uchun, mutex qulflash tizimi(locking system) orqali o'zida mavjud bo'lgan ma'lumotlarni himoya qilish(guarding) sifatida tavsiflanadi.
Mutexlardan foydalanish qiyinligi bilan mashhur, chunki siz ikkita qoidani eslab qolishingiz kerak:
- Ma'lumotlardan foydalanishdan oldin siz qulfni olishga harakat qilishingiz kerak.
- Mutex himoya qiladigan ma'lumotlar bilan ishlashni tugatgandan so'ng, boshqa threadlar qulfni(lock) olishi uchun ma'lumotlarni qulfdan chiqarishingiz(unlock) kerak.
Mutexni tushunish uchun bitta mikrofon bilan konferensiyada guruh muhokamasining haqiqiy hayotiy misolini tasavvur qiling. Panel ishtirokchisi gapirishdan oldin mikrofondan foydalanishni xohlashini so'rashi yoki signal berishi kerak. Mikrofonni olishganda, ular xohlagancha gaplashishi mumkin va keyin mikrofonni gapirishni so'ragan keyingi ishtirokchiga beradi. Agar panel ishtirokchisi mikrofon bilan ishlashni tugatgandan so'ng uni o'chirishni unutib qo'ysa, boshqa hech kim gapira olmaydi. Agar umumiy mikrofonni boshqarish noto'g'ri bo'lsa, panel rejalashtirilganidek ishlamaydi!
Mutexlarni boshqarish juda qiyin bo'lishi mumkin, shuning uchun ko'p odamlar kanallarga(channel) ishtiyoq bilan qarashadi. Biroq, Rust type tizimi va ownershiplik qoidalari tufayli siz qulflash(locking) va qulfni noto'g'ri ochishingiz(unlocking) mumkin emas.
Mutex<T> API
Mutexdan qanday foydalanishga misol sifatida, keling, 16-12 ro'yxatda ko'rsatilganidek, bitta threadli kontekstda mutexdan foydalanishdan boshlaylik:
Fayl nomi: src/main.rs
use std::sync::Mutex; fn main() { let m = Mutex::new(5); { let mut raqam = m.lock().unwrap(); *raqam = 6; } println!("m = {:?}", m); }
Ro'yxat 16-12: Mutex<T> API-ni soddaligi uchun single-threadli kontekstda oʻrganish
Ko'pgina turlarda(type) bo'lgani kabi, biz bog'langan new funksiyasidan foydalangan holda Mutex<T> ni yaratamiz.
Mutex ichidagi ma'lumotlarga kirish uchun biz qulfni olish uchun lock metodidan foydalanamiz. Bu chaqiruv joriy threadni bloklaydi, shuning uchun u bizni qulflash navbati kelmaguncha hech qanday ishni bajara olmaydi.
Qulfni ushlab turgan boshqa thread panic qo'zg'atsa, lock chaqiruvi muvaffaqiyatsiz bo'ladi. Bunday holda, hech kim qulfni qo'lga kirita olmaydi, shuning uchun biz unwrapni tanladik va agar shunday vaziyatda bo'lsak, bu threadni panic qo'yishni tanladik.
Qulfni qo'lga kiritganimizdan so'ng, biz bu holatda num deb nomlangan return qiymatini ichidagi ma'lumotlarga o'zgaruvchan reference sifatida ko'rib chiqishimiz mumkin. Tur(type) tizimi m dagi qiymatni ishlatishdan oldin qulfni olishimizni ta'minlaydi. m turi i32 emas, Mutex<i32>, shuning uchun biz i32 qiymatidan foydalanish uchun lockni chaqirishimiz kerak. Biz unuta olmaymiz; aks holda turdagi tizim bizga ichki i32 ga kirishga ruxsat bermaydi.
Taxmin qilgan bolishingiz mumkinki Mutexlock qo'ng'irog'i MutexGuard deb nomlangan ochish
qo'ng'irog'i bilan oralgan LockResult-ga o'ralgan aqlli ko'rsatgichni qaytaradi . MutexGuard ko'rsatkichi esa bizning ichki ma'lumotlarimizga ishora
qilish uchun Derefni amalga oshiradi( Derefdan foydalanadi). Aqlli ko'rsatgichda Drop ilovasi ham mavjud bo'lib, MutexGuard qo'llanilish doirasidan
tashqariga chiqqanda avtomatik ravishda qulfni chiqaradi va bu esa ichki doiraning oxirida sodir bo'ladi. Natijada, biz qulfni(lock) bo'shatishni unutib
qo'ymaymiz va asosiysi mutexni boshqa threadlar tomonidan ishlatilishini bloklaymiz, chunki qulfni(lock) chiqarish avtomatik ravishda sodir bo'ladi.
Qulfni tashlaganimizdan so'ng, biz mutex qiymatini print qilishimiz(chop etishimiz ) va ichki i32 ni 6 ga o'zgartira olganimizni ko'rishimiz mumkin.
Bitta Muteks<T>ni Bir nechta mavzular o'rtasida ulashish(almashtirish):
Keling, Mutex<T>-dan foydalanib, bir nechta oqimlar o'rtasida qiymatni share qilishga(qiymatni almashtirishga) harakat qilaylik. Biz 10 ta threadni
aylantiramiz va ularning har biri hisoblagich qiymatini 1 ga oshiradi, shuning uchun hisoblagich 0 dan 10 gacha boradi. 16-13 ro'yxatdagi keyingi misolda
kompilyator xatosi (compiler error)bo'ladi va biz bu xatoni o'rganish uchun ishlatamiz. Mutex<T>-dan foydalanish va Rust uni to'g'ri ishlatishimizga
qanday yordam berishi haqida ko'proq o'rganamiz.
Fayl nomi: src/main.rs
use std::sync::Mutex;
use std::thread;
fn main() {
let counter = Mutex::new(0);
let mut handles = vec![];
for _ in 0..10 {
let handle = thread::spawn(move || {
let mut num = counter.lock().unwrap();
*num += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Result: {}", *counter.lock().unwrap());
}Ro'yxat 16-13: Mutex<T> tomonidan qo'riqlanadigan hisoblagichni har biri o'nta threaddan amalga oshirishi.
Mutex<T>ni ichida i32 ni ushlab turish uchun hisoblagich o'zgaruvchisini yaratamiz, xuddi 16-12 ro'yxatdagi kabi(listing 16-12). Keyingi amal esa,
biz raqamlar oralig'ida takrorlash orqali 10 ta thread yaratamiz. Biz thread::spawn dan foydalanamiz va barcha threadlarga bir xil yopilishni beramiz:
hisoblagichni threadga o'tkazish uchun ishlatiladigan qulflash usulini amalga oshirish orqali(chaqirish orqali) orqali Mutex<T> da blokirovkaga ega
bo'ladi va keyin mutexdagi qiymatga 1 qo'shiladi. Thread o'zining yopilishini tugatgandan so'ng, num doirasi tashqariga chiqadi va boshqa thread uni
olishi uchun qulfni bo'shatadi.
Asosiy threadda biz barcha birlashma tutqichlarini yig'amiz. Keyin, 16-2 ro'yxatdagidek,barcha threadlar tugashiga ishonch hosil qilish uchun har bir
tutqichga join chaqiramiz. O'sha paytda asosiy thread qulfni oladi va ushbu dasturning natijasini print(chop etadi).
Bu misol tuzilmasligiga ishora qilingan. Endi nima uchunligini o'ylab ko'raylik!
$ cargo run
Compiling shared-state v0.1.0 (file:///projects/shared-state)
error[E0382]: use of moved value: `counter`
--> src/main.rs:9:36
|
5 | let counter = Mutex::new(0);
| ------- move occurs because `counter` has type `Mutex<i32>`, which does not implement the `Copy` trait
...
9 | let handle = thread::spawn(move || {
| ^^^^^^^ value moved into closure here, in previous iteration of loop
10 | let mut num = counter.lock().unwrap();
| ------- use occurs due to use in closure
For more information about this error, try `rustc --explain E0382`.
error: could not compile `shared-state` due to previous error
Xato xabari counter(hisoblagich) qiymati tsiklning oldingi iteratsiyasida ko'chirilganligini bildiradi. Rust bizga qulflash counter(hisoblagichining)
egaligini bir nechta mavzularga o'tkaza olmasligimizni aytadi. Keling, 15-bobda muhokama qilgan bir nechta egalik usuli bilan kompilyator xatosini
tuzataylik.
Bir nechta mavzular bilan bir nechta egalik
15-bobda mos yozuvlar hisoblangan qiymatni yaratish uchun aqlli ko'rsatkich RcMutex<T>-ni Rc <T>-ga 16-14-listingda o'rab olamiz va egalikni threadga ko'chirishdan oldin Rc<T>-ni
klonlaymiz(nusxasini yaratmoq, cloning).
Fayl nomi: src/main.rs
use std::rc::Rc;
use std::sync::Mutex;
use std::thread;
fn main() {
let counter = Rc::new(Mutex::new(0));
let mut handles = vec![];
for _ in 0..10 {
let counter = Rc::clone(&counter);
let handle = thread::spawn(move || {
let mut num = counter.lock().unwrap();
*num += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Result: {}", *counter.lock().unwrap());
}Listing 16-14: Rc<T> ni ishlatib, bir nechta iplar (threads) Mutex<T> ga egalik qilishiga imkon berishga urinish.
Yana bir bor, biz kompilyatsiya qilamiz va... turli xatolarni olamiz! Kompilyator bizga ko'p narsani o'rgatmoqda.
$ cargo run
Compiling shared-state v0.1.0 (file:///projects/shared-state)
error[E0277]: `Rc<Mutex<i32>>` cannot be sent between threads safely
--> src/main.rs:11:36
|
11 | let handle = thread::spawn(move || {
| ------------- ^------
| | |
| ______________________|_____________within this `[closure@src/main.rs:11:36: 11:43]`
| | |
| | required by a bound introduced by this call
12 | | let mut num = counter.lock().unwrap();
13 | |
14 | | *num += 1;
15 | | });
| |_________^ `Rc<Mutex<i32>>` cannot be sent between threads safely
|
= help: within `[closure@src/main.rs:11:36: 11:43]`, the trait `Send` is not implemented for `Rc<Mutex<i32>>`
note: required because it's used within this closure
--> src/main.rs:11:36
|
11 | let handle = thread::spawn(move || {
| ^^^^^^^
note: required by a bound in `spawn`
--> /rustc/d5a82bbd26e1ad8b7401f6a718a9c57c96905483/library/std/src/thread/mod.rs:704:8
|
= note: required by this bound in `spawn`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `shared-state` due to previous error
Afsus, bu xato xabari juda uzun va yoqimsizroq(rasmiyligi uchun) ekan! Bu yerda diqqat qilish kerak bo'lgan muhim qism:
Rc<Mutex<i32>> ` threadlar o'rtasida xavfsiz yuborilishi mumkin emas. Kompilyator bizga buning sababini ham aytib beradi: Send xususiyati
Rc<Mutex<i32>> uchun amalga oshirilmagan. Keyingi bo'limda Send(Yuborish) haqida gaplashamiz: bu biz threadlar bilan ishlatadigan turlarni bir
vaqtda vaziyatlarda foydalanishga mo'ljallanganligini ta'minlaydigan xususiyatlardan biridir.
Afsuski, Rc<T> ni threadlar bo'ylab almashish xavfsiz emas(yuqorida ham aytilishicha mumkin ham emas). Rc<T> mos yozuvlar sonini boshqarganda, u clone
(klonlash) uchun har bir qo'ng'iroq uchun hisobni qo'shadi va har bir clone(klon) tushirilganda hisobdan ayiradi. Ammo hisobdagi o'zgarishlarni boshqa
oqim bilan to'xtatib qo'ymasligiga ishonch hosil qilish uchun u parallellik ibtidoiylaridan(parallallik ibtidoiysi bu concurrency yani raqobatga tegishli
mavzu) foydalanmaydi. Bu noto'g'ri hisob-kitoblarga olib kelishi mumkin - nozik xatolar, o'z navbatida, xotiraning oqishi yoki biz bilan ishlash
tugashidan oldin qiymatning tushib ketishiga olib kelishi mumkin. Bizga aynan Rc<T>ga o'xshash tur kerak bo'ladi, ammo u mos yozuvlar soniga
o'zgartirish kiritadi.
Arc<T> bilan atomik havolalarni hisoblash
Yaxshiyamki, Arc<T> Rc<T> kabi bir xil vaziyatlarda foydalanish uchun xavfsiz tur. A atomik degan ma'noni anglatadi, ya'ni bu atomik havola orqali
hisoblangan tur. Atomlar parallellik ibtidoiyning(concurrency:konkurentlik) qo'shimcha turi bo'lib,bu yerda batafsik ko'rib chiqolmaymiz: batafsil
ma'lumot uchun std::sync::atomic uchun standart kutubxona hujjatlariga(dokumentatsiyasiga) qarang. Shu nuqtada, atomlar ibtidoiy turlar kabi ishlashini
bilishingiz kerak, lekin ularni threadlar bo'ylab almashish xavfsizdir.
Keyin nima uchun barcha ibtidoiy turlar atom emasligi va nega standart kutubxona turlari sukut bo'yicha Arc<T> dan foydalanish uchun amalga
oshirilmaganligi haqida hayron bo'lishingiz mumkin. Buning sababi shundaki, thread xavfsizligi faqat sizga kerak bo'lganda to'lamoqchi bo'lgan ishlash
jazosi bilan birga keladi(PERFORMANCE PENALTY-IJRO,BAJARISH UCHUN JAZO) .Agar siz faqat bitta oqim ichidagi qiymatlar ustida amllarni bajarayotgan
bo'lsangiz yani atomik kafolatlarni bajarish shart bo'lmasa, kodingiz tezroq ishlashi mumkin.
Keling, misolimizga qaytaylik: Arc<T> va Rc<T> bir xil APIga ega, shuning uchun biz dasturimizni use(foydalanish) qatorini, new(yangi) chaqiruvni
va clone(klonlash) uchun qo'ng'iroqni o'zgartirish orqali tuzatamiz. 16-15 ro'yxatdagi kod nihoyat togri boladi:
Fayl nomi: src/main.rs
use std::sync::{Arc, Mutex}; use std::thread; fn main() { let counter = Arc::new(Mutex::new(0)); let mut handles = vec![]; for _ in 0..10 { let counter = Arc::clone(&counter); let handle = thread::spawn(move || { let mut num = counter.lock().unwrap(); *num += 1; }); handles.push(handle); } for handle in handles { handle.join().unwrap(); } println!("Result: {}", *counter.lock().unwrap()); }
Ro'yxat 16-15: Mutex<T>-ni o'rash uchun Arc<T> dan foydalanish, bir nechta mavzular bo'ylab egalik huquqini baham ko'rish
uchun
Ushbu kod quyidagilarni print qiladi:
Result: 10
Biz uddaladik! Biz 0 dan 10 gacha hisobladik, bu katta ishdek korinmasligi mumkin, ammo bu bizga Mutex<T> va thread xavfsizligi haqida ko‘p narsalarni
o‘rgatadi. Hisoblagich faqat ko'paytirishdan koproq ish qila olishini orgatdi. Ushbu strategiyadan foydalanib, siz hisobni mustaqil qismlarga
bo'lishingiz, bu qismlarni threadlar bo'ylab ajratishingiz va keyin Mutex<T> dan foydalanib, har bir thread yakuniy natijani o'z qismi bilan yangilashi
mumkin.
E'tibor bering, agar siz oddiy raqamli amallarni bajarayotgan bo'lsangiz, standart kutubxonaning std::sync::atomic modulida taqdim etilgan Mutex<T>
turlaridan oddiyroq turlar mavjud. Ushbu turlar ibtidoiy turlarga xavfsiz, parallel, atomik kirishni ta'minlaydi va ushbu misol uchun Mutex<T>ning
ibtidoiy turi bilan foydalanishni tanladik, shuning uchun Mutex<T> qanday ishlashiga e'tibor qaratishimiz mumkin.
RefCell<T>/Rc<T> va Mutex<T>/Arc<T> o'rtasidagi o'xshashliklar
Hisoblagich(counter) o'zgarmasligini payqagan bo'lishingiz mumkin, lekin biz uning ichidagi qiymatga o'zgaruvchan havolani olishimiz mumkin; bu Mutex<T> Cell oilasi kabi ichki o'zgaruvchanlikni qollab quvvatlaydi. Xuddi shu tarzda biz Rc<T> ichidagi tarkibni o'zgartirishga ruxsat berish uchun 15-bobda
RefCell<T> dan foydalanganmiz, Arc<T> ichidagi tarkibni mutatsiya qilish uchun Mutex<T> dan foydalanamiz.
Yana bir muhim ma' lumot, Mutex<T> dan foydalanganda Rust sizni barcha turdagi mantiqiy xatolardan himoya qila olmaydi. 15-bobda Rc<T> dan
foydalanish oziga xos yozuvlar sikllarini yaratish xavfi bilan kelganligini eslang, bu erda ikkita Rc<T> qiymati bir-biriga tegishli bo'lib, xotira
susayishi, tanqisligiga olib keladi. Xuddi shunday, Mutex<T> ham boshi berk deadlocks(ko'chalarni) yaratish xavfi bilan birga keladi. Bular amal ikkita
resursni bloklashi kerak bo'lganda sodir bo'ladi va ikkita thread har biri locks(qulflardan) birini qo'lga kiritib. Agar siz ziddiyatlarga qiziqsangiz,
tanqislik deadlocks(ko'chasiga) ega Rust dasturini yaratishga harakat qiling; keyin har qanday tilda mutekslar uchun ziddiyatni yengilashtirish, yechim
topish strategiyalarini o'rganing va Rustda ularni amalga oshirishga kirishing. Mutex<T> va MutexGuard uchun standart kutubxona API hujjatlari
foydali ma'lumotlarni taqdim etadi.
Biz ushbu bobni Send(Yuborish) va Sync(Sinxronlashtirish) xususiyatlari va ularni maxsus turlar bilan qanday ishlatishimiz haqida gapirib,
yakunlaymiz.
Extensible Concurrency with the Sync and Send Traits
Interestingly, the Rust language has very few concurrency features. Almost every concurrency feature we’ve talked about so far in this chapter has been part of the standard library, not the language. Your options for handling concurrency are not limited to the language or the standard library; you can write your own concurrency features or use those written by others.
However, two concurrency concepts are embedded in the language: the
std::marker traits Sync and Send.
Allowing Transference of Ownership Between Threads with Send
The Send marker trait indicates that ownership of values of the type
implementing Send can be transferred between threads. Almost every Rust type
is Send, but there are some exceptions, including Rc<T>: this cannot be
Send because if you cloned an Rc<T> value and tried to transfer ownership
of the clone to another thread, both threads might update the reference count
at the same time. For this reason, Rc<T> is implemented for use in
single-threaded situations where you don’t want to pay the thread-safe
performance penalty.
Therefore, Rust’s type system and trait bounds ensure that you can never
accidentally send an Rc<T> value across threads unsafely. When we tried to do
this in Listing 16-14, we got the error the trait Send is not implemented for Rc<Mutex<i32>>. When we switched to Arc<T>, which is Send, the code
compiled.
Any type composed entirely of Send types is automatically marked as Send as
well. Almost all primitive types are Send, aside from raw pointers, which
we’ll discuss in Chapter 19.
Allowing Access from Multiple Threads with Sync
The Sync marker trait indicates that it is safe for the type implementing
Sync to be referenced from multiple threads. In other words, any type T is
Sync if &T (an immutable reference to T) is Send, meaning the reference
can be sent safely to another thread. Similar to Send, primitive types are
Sync, and types composed entirely of types that are Sync are also Sync.
The smart pointer Rc<T> is also not Sync for the same reasons that it’s not
Send. The RefCell<T> type (which we talked about in Chapter 15) and the
family of related Cell<T> types are not Sync. The implementation of borrow
checking that RefCell<T> does at runtime is not thread-safe. The smart
pointer Mutex<T> is Sync and can be used to share access with multiple
threads as you saw in the “Sharing a Mutex<T> Between Multiple
Threads” section.
Implementing Send and Sync Manually Is Unsafe
Because types that are made up of Send and Sync traits are automatically
also Send and Sync, we don’t have to implement those traits manually. As
marker traits, they don’t even have any methods to implement. They’re just
useful for enforcing invariants related to concurrency.
Manually implementing these traits involves implementing unsafe Rust code.
We’ll talk about using unsafe Rust code in Chapter 19; for now, the important
information is that building new concurrent types not made up of Send and
Sync parts requires careful thought to uphold the safety guarantees. “The
Rustonomicon” has more information about these guarantees and how to
uphold them.
Summary
This isn’t the last you’ll see of concurrency in this book: the project in Chapter 20 will use the concepts in this chapter in a more realistic situation than the smaller examples discussed here.
As mentioned earlier, because very little of how Rust handles concurrency is part of the language, many concurrency solutions are implemented as crates. These evolve more quickly than the standard library, so be sure to search online for the current, state-of-the-art crates to use in multithreaded situations.
The Rust standard library provides channels for message passing and smart
pointer types, such as Mutex<T> and Arc<T>, that are safe to use in
concurrent contexts. The type system and the borrow checker ensure that the
code using these solutions won’t end up with data races or invalid references.
Once you get your code to compile, you can rest assured that it will happily
run on multiple threads without the kinds of hard-to-track-down bugs common in
other languages. Concurrent programming is no longer a concept to be afraid of:
go forth and make your programs concurrent, fearlessly!
Next, we’ll talk about idiomatic ways to model problems and structure solutions as your Rust programs get bigger. In addition, we’ll discuss how Rust’s idioms relate to those you might be familiar with from object-oriented programming.
Object-Oriented Programming Features of Rust
Object-oriented programming (OOP) is a way of modeling programs. Objects as a programmatic concept were introduced in the programming language Simula in the 1960s. Those objects influenced Alan Kay’s programming architecture in which objects pass messages to each other. To describe this architecture, he coined the term object-oriented programming in 1967. Many competing definitions describe what OOP is, and by some of these definitions Rust is object-oriented, but by others it is not. In this chapter, we’ll explore certain characteristics that are commonly considered object-oriented and how those characteristics translate to idiomatic Rust. We’ll then show you how to implement an object-oriented design pattern in Rust and discuss the trade-offs of doing so versus implementing a solution using some of Rust’s strengths instead.
Obyektga Yo'naltirilgan Dasturlash Xususiyatlari
Dasturlash jamiyatida bir tilni obyektga yo'naltirilgan deb hisoblash uchun qanday xususiyatlarga ega bo'lishi kerakligi haqida kelishuv yo'q. Rust ko'p dasturlash paradigmalaridan, jumladan OOPdan ilhomlangan; masalan, 13-bobda funksional dasturlashdan kelgan xususiyatlarni o'rgandik. Ehtimol, OOP tillari ma'lum umumiy xususiyatlarga ega, ya'ni obyektlar, inkapsulyatsiya va meros. Keling, har bir xususiyatning nimani anglatishini va Rust uni qo'llab-quvvatlaydimi yoki yo'qligini ko'rib chiqaylik.
Obyektlar Ma'lumotlar va Xatti-harakatlarni O'z ichiga oladi
Erich Gamma, Richard Helm, Ralph Johnson va John Vlissides tomonidan yozilgan *Design Patterns: Elements of Reusable Object-Oriented Software (Addison-Wesley Professional, 1994), oddiygina The Gang of Four deb ataladigan kitob, obyektga yo'naltirilgan dizayn shablonlarining katalogidir. U OOPni quyidagicha ta'riflaydi:
Obyektga yo'naltirilgan dasturlar obyektlardan tashkil topgan. Bir obyekt ma'lumotlar va ushbu ma'lumotlar bilan ishlaydigan protseduralarni paketlaydi. Protseduralar odatda metodlar
yoki operatsiyalar deb ataladi.
Ushbu ta'rifga ko'ra, Rust obyektga yo'naltirilgan: structlar va enumlar ma'lumotlarga ega va impl bloklari structlar va enumlarda metodlar taqdim
etadi. Garchi structlar va enumlar metodlar bilan obyekt deb atalmagan bo'lsa-da, ular The Gang of Four ta'rifiga ko'ra obyektlarning bir xil
funksionalligini ta'minlaydi.
Amalga oshirish Tafsilotlarini Yashiruvchi Inkapsulyatsiya
OOP bilan odatda bog'liq bo'lgan yana bir jihat inkapsulyatsiya tushunchasi bo'lib, bu obyektning amalga oshirish tafsilotlari ushbu obyektni ishlatadigan kod uchun ochiq bo'lmasligini anglatadi. Shuning uchun, obyekt bilan o'zaro ta'sir qilishning yagona usuli uning ommaviy APIi orqali amalga oshiriladi; obyektni ishlatadigan kod obyektning ichki qismlariga kirib, ma'lumotlar yoki xatti-harakatlarni bevosita o'zgartira olmaydi. Bu dasturchiga obyektning ichki qismlarini o'zgartirish va refaktor qilish imkonini beradi, obyektdan foydalanadigan kodni o'zgartirmasdan.
7-bobda inkapsulyatsiyani qanday boshqarish mumkinligini muhokama qildik: biz pub kalit so'zidan foydalanib, kodimizdagi qaysi modullar, turlar,
funksiyalar va metodlar ommaviy bo'lishi kerakligini va standart bo'lib hamma narsalar xususiy ekanligini hal qilishimiz mumkin. Masalan,
AveragedCollection deb nomlangan structni aniqlashimiz mumkin, u i32 qiymatlarining vektorini o'z ichiga oladi. Struct shuningdek, vektordagi
qiymatlarning o'rtacha qiymatini o'z ichiga oluvchi maydonga ham ega bo'lishi mumkin, ya'ni o'rtacha qiymatga har safar ehtiyoj tug'ilganda hisoblanishi
shart emas. Boshqacha qilib aytganda, AveragedCollection biz uchun hisoblangan o'rtacha qiymatni keshlaydi. 17-1 ro'yxatda AveragedCollection
structining ta'rifi keltirilgan:
Fayl nomi: src/lib.rs
pub struct AveragedCollection {
list: Vec<i32>,
average: f64,
}Ro'yxat 17-1: AveragedCollection structi, integerlar ro'yxatini va yig'indi elementlarning o'rtacha qiymatini saqlaydi
Struct pub deb belgilangan, shuning uchun boshqa kodlar uni ishlatishi mumkin, lekin struct ichidagi maydonlar xususiy bo'lib qoladi. Bu holda bu
muhim, chunki biz ro'yxatga qiymat qo'shilgan yoki o'chirilganida o'rtacha qiymat ham yangilanishini ta'minlamoqchimiz. Buni biz add, remove va
average metodlarini structga tatbiq etish orqali amalga oshiramiz, bu 17-2 ro'yxatda ko'rsatilgan:
Fayl nomi: src/lib.rs
pub struct AveragedCollection {
list: Vec<i32>,
average: f64,
}
impl AveragedCollection {
pub fn add(&mut self, value: i32) {
self.list.push(value);
self.update_average();
}
pub fn remove(&mut self) -> Option<i32> {
let result = self.list.pop();
match result {
Some(value) => {
self.update_average();
Some(value)
}
None => None,
}
}
pub fn average(&self) -> f64 {
self.average
}
fn update_average(&mut self) {
let total: i32 = self.list.iter().sum();
self.average = total as f64 / self.list.len() as f64;
}
}Ro'yxat 17-2: AveragedCollection ustida ommaviy add, remove va average metodlarining amalga oshirilishi
add, remove va average ommaviy metodlar AveragedCollection nusxasidagi ma'lumotlarni kirish yoki o'zgartirishning yagona usuli. Element ro'yxatga
add metodi orqali qo'shilganda yoki remove metodi orqali olib tashlanganda, har biri average maydonini yangilash bilan shug'ullanadigan xususiy
update_average metodini chaqiradi.
list va average maydonlarini xususiy qilib qoldiramiz, shunda tashqi kod list maydoniga elementlar qo'shish yoki olib tashlash imkoniga ega
bo'lmaydi; aks holda, average maydoni list o'zgarganda sinxronlashdan chiqib ketishi mumkin.
average metodi average maydonidagi qiymatni qaytaradi, tashqi kodga averageni o'qish imkonini beradi, lekin uni o'zgartirish imkonini bermaydi.
Biz AveragedCollection structining amalga oshirish tafsilotlarini inkapsulyatsiya qilganimiz sababli, kelajakda uning jihatlarini osonlik bilan
o'zgartirishimiz mumkin. Masalan, list maydoni uchun Vec<i32> o'rniga HashSet<i32> dan foydalanishimiz mumkin. add, remove va average ommaviy
metodlarining imzolari o'zgarmagan holda, AveragedCollectiondan foydalanadigan kodni o'zgartirish kerak bo'lmaydi. Agar listni ommaviy qilsak, bu har
doim ham shunday bo'lmaydi: HashSet<i32> va Vec<i32> elementlarni qo'shish va olib tashlash uchun turli xil metodlarga ega, shuning uchun listni
to'g'ridan-to'g'ri o'zgartirayotgan tashqi kod o'zgartirilishi kerak bo'ladi.
Agar inkapsulyatsiya tilni obyektga yo'naltirilgan deb hisoblash uchun zaruriy xususiyat bo'lsa, Rust bu talabga javob beradi. Kodning turli qismlari
uchun pubdan foydalanish yoki foydalanmaslik imkoniyati amalga oshirish tafsilotlarini inkapsulyatsiya qilish imkonini beradi.
Merozdan foydalanish Tizimi va Kodni Ulashish Sifatida
Meros olish bu mexanizm bo'lib, bunda obyekt boshqa obyektning ta'rifidan elementlarni meros qilib oladi va shunday qilib, ota obyektning ma'lumotlari va xatti-harakatlarini qayta ta'riflashsiz oladi.
Agar til obyektga yo'naltirilgan til deb hisoblanishi uchun meros olishga ega bo'lishi kerak bo'lsa, Rust bunday til emas. Ota structning maydonlari va metodlarini makrosiz meros qilib olishning hech qanday yo'li yo'q.
Biroq, agar siz dasturlash vositangizda meros olishga ega bo'lishga odatlangan bo'lsangiz, Rustda boshqa echimlardan foydalanishingiz mumkin, bu meros olishga erishmoqchi bo'lgan sababingizga qarab o'zgaradi.
Meros olishni tanlashning ikki asosiy sababi bor. Biri kodni qayta ishlatish uchun: siz bir tur uchun ma'lum xatti-harakatni amalga oshirishingiz mumkin
va meros olish bu amalga oshirishni boshqa tur uchun qayta ishlatishga imkon beradi. Rust kodida siz buni cheklangan tarzda trait metodlari uchun
standart amalga oshirishlar yordamida amalga oshirishingiz mumkin, bu 10-14 ro'yxatda Summary traitida summarize metodining standart amalga
oshirilishini qo'shganimizda ko'rsatilgan.
Summary traitini amalga oshirgan har qanday tur summarize metodiga ega bo'ladi, hech qanday qo'shimcha kod yozmasdan. Bu ota sinfning metodini
amalga oshirishiga va meros qilib olingan bola sinfining metodni amalga oshirishiga o'xshaydi. Summary traitini amalga oshirganimizda summarize
metodining standart amalga oshirilishini ham bekor qilishimiz mumkin, bu meros qilib olingan bola sinfi ota sinfdan meros qilib olingan metodni amalga
oshirishini bekor qilishga o'xshaydi.
Meros olishdan foydalanishning boshqa sababi turi tizimiga bog'liq: bola turini ota turi bilan bir xil joylarda ishlatishga imkon berish. Bu shuningdek polimorfizm deb ataladi, bu bir-birini almashtirish imkonini beradi, agar ular ma'lum xususiyatlarga ega bo'lsa.
Polimorfizm
Ko'pchilik uchun polimorfizm meros olish bilan sinonimdir. Ammo bu aslida ko'proq umumiy tushuncha bo'lib, u turli turlardagi ma'lumotlar bilan ishlaydigan kodni anglatadi. Meros olish uchun bu turlar odatda quyi sinflardir.
Rust esa o'rniga turli xil turlar ustida abstraksiya qilish uchun generiklardan va bu turlarning nimani ta'minlashi kerakligini cheklash uchun trait cheklovlaridan foydalanadi. Bu ba'zan cheklangan parametrik polimorfizm deb ataladi.
Meros olish ko'pincha dastur dizayn yechimi sifatida ko'plab dasturlash tillarida sevilmay qoldi, chunki u ko'pincha kerakli koddan ko'proq kodni ulash xavfini tug'diradi. Quyi sinflar har doim ham ota sinfining barcha xususiyatlarini ulashmasligi kerak, ammo meros olishda shunday bo'ladi. Bu dastur dizaynini kamroq moslashuvchan qiladi. Shuningdek, bu quyi sinfda metodlarni chaqirish imkoniyatini beradi, bu metodlar quyi sinfga mos kelmasligi yoki xatolarga olib kelishi mumkin, chunki metodlar quyi sinfga tatbiq etilmaydi. Bundan tashqari, ba'zi tillar faqat yagona meros olishga ruxsat beradi (bu quyi sinf faqat bitta sinfdan meros olishi mumkinligini anglatadi), bu esa dastur dizaynining moslashuvchanligini yanada cheklaydi.
Ushbu sabablarga ko'ra, Rust meros olish o'rniga trait obyektlaridan foydalanish yo'lini tanlaydi. Keling, Rustda trait obyektlari qanday qilib polimorfizmni ta'minlashini ko'rib chiqaylik.
Turli xildagi qiymatlarni qabul qila oladigan Trait ya'ni xususiyat obyektlaridan foydalanish
8-bobda vektorlarning faqat bir turdagi elementlarni saqlash imkoniyatiga ega ekanligini ta’kidlagan edik. 8-9-ro‘yxatda butun sonlar, kasr sonlar va matnlarni saqlash uchun variantlarga ega bo‘lgan ’SpreadsheetCell’ nomli sanab o‘tish turini yaratib, bu muammoni hal qilish ko'rsatilgan edi. Bu usul har bir katakda turli xil ma’lumotlarni saqlash va shu bilan birga kataklar qatorini ifodalovchi vektorga ega bo‘lish imkonini berdi. Agar o‘zaro almashtirilishi mumkin bo‘lgan elementlarni kodda tuzilayotgan paytda ma’lum bo‘lgan turlarning belgilangan to‘plamidan iborat bo‘lsa, bu juda yaxshi yechim hisoblanadi.
Biroq, ba’zida kutubxonamiz foydalanuvchisi o‘zi uchun mos bo‘lgan, muayyan vaziyatda
ishlatilishi mumkin bo‘lgan turlar to‘plamini kengaytira olishini xohlaymiz. Bu qanday
amalga oshirilishini ko‘rsatish uchun, grafik foydalanuvchi interfeysi (GUI) vositasi
misolini yaratamiz. Ushbu vosita elementlar ro‘yxatidan o‘tadi va har bir element uchun
draw metodini chaqiradi. Bu GUI vositalarida keng qo‘llaniladigan uslubdir.gui
nomli kutubxona crate yaratiladi. Ushbu crate GUI kutubxonasining asosiy tuzilmasini o‘z
ichiga oladi. Unda, masalan, Button yoki TextField kabi foydalanishga tayyor ayrim
turlarni taqdim qilishi mumkin. Shu bilan birga, gui foydalanuvchilari o‘zlarining
chizilishi mumkin bo‘lgan turlarini ham yaratmoqchi bo‘lishadi: masalan, bir dasturchi
Image turini qo‘shsa, boshqasi SelectBox turini qo‘shishi mumkin.
Ushbu misolda to‘laqonli grafik interfeyslik (GUI) kutubxona yozilmaydi lekin
qismlar bir-biri bilan qanday ulanishini ko‘rsatiladi. Kutubxona yozish vaqtida
boshqa dasturchilar nima va qanday qilib yozishini oldindan bilib bo‘lmaydi.
Lekin bilamizki, gui imkon qadar ko‘p turlar qiymatidan xabardor bo‘lishi
kerak, va u draw (ya’ni chizish) metodini ana shu turlarning har birida
chaqirishi lozim. draw metodini chaqirgan vaqtida aynan nima ish sodir
bo‘lishini gui bilishi kerak emas, faqatgina draw metodi chaqirish uchun
mavjudligini biladi xolos.
Obyektga yo‘naltirilgan tillarda (misol uchun Java, C# va h.k.), Component nomli
klass ichida draw nomli metod bilan ifoda etiladi. Button, Image va
SelectBox kabi klasslar Componentdan nasil olishadi va shu tufayli ular
ham draw metodini ifodalashadi. Ular, albatta, o‘zgacha draw metodini
e’lon qilishlari mumkin lekin dasturlash tili ularni xuddi Componentdek
ko‘rishadi va drawni chaqira olishadi. Rust dasturlash tilida nasl olish
imkoniyati yo‘q, vaholanki gui kutubxonasi foydalanuvchilari uni
kengaytira olishi uchun kutubxona boshqacha tuzilishi lozim.
Umumiy xatti-harakatlar uchun Trait ni aniqlash ya'ni xususiyatni
Gui uchun kerakli xatti-harakatni amalga oshirish maqsadida, Draw nomli
trait'ni belgilaymiz. Bu trait draw deb nomlangan yagona usulni o‘z ichiga
oladi. Shundan so‘ng trait object ni qabul qiladigan vektorni aniqlash mumkin.
Trait obyekti ko‘rsatilgan xususiyatni amalga oshiruvchi turning nusxasiga ham,
ishlash vaqtida ushbu turdagi trait usullarini qidirish uchun ishlatiladigan
jadvalga ham ishora qiladi. Qandaydir ko‘rsatkichni, masalan & havola yoki
Box<T> aqlli ko‘rsatkichni, so‘ngra dyn kalit so‘zini va tegishli trait'ni
ko‘rsatish orqali trait obyektini yaratamiz. (Trait obyektlarining nima uchun
ko‘rsatkich ishlatishi kerakligi haqida 19-bobning
["Dinamik o‘lchamliturlar va ’Sized’ belgisi"][dinamik-olchamli]
obyektlarini generic ya'ni turdosh yoki aniq tur o‘rnida ishlatishimiz mumkin.
Trait obyektini qayerda ishlatishimizdan qat'iy nazar, Rustning turlar tizimi
kompilyatsiya vaqtida ushbu kontekstda ishlatiladigan har qanday qiymat
trait obyektining trait'ini amalga oshirishini ta’minlaydi. Natijada
kompilyatsiya vaqtida barcha mumkin bo‘lgan turlarni bilish shart emas.
Rust dasturlash tilida structlar va enumlar “obyekt” deb atalmaydi.
Bunday yondashuv, ularni boshqa dasturlash tillaridagi obyekt tushunchasidan
farqlash maqsadida qo‘llaniladi. Rust tilida struct yoki enum tarkibidagi
ma’lumotlar (ya’ni, maydonlar) va xatti-harakatlar impl bloklarida
alohida saqlanadi. Aksariyat boshqa dasturlash tillarida esa ma’lumotlar va
xatti-harakatlar yagona tuzilma sifatida birlashtirilib, odatda “obyekt” deb
ataladi. Biroq trait obyektlar (trait objects) boshqa dasturlash tillaridagi
obyektlarga o‘xshashlik kasb etadi. Chunki ular ma’lumot va xatti-harakatni
birgalikda ifodalash imkonini beradi. Shunga qaramay, trait obyektlar an’anaviy
obyektlardan farq qiladi: ular tarkibiga yangi ma’lumotlar qo‘shishga imkon
bermaydi. Shu bois, trait obyektlar boshqa tillardagi obyektlar kabi keng
maqsadlarda emas, balki faqat umumiy xatti-harakatni abstraktsiyalash,
ya’ni umumiy funksionallik asosida turli obyektlar bilan ishlash imkoniyatini
yaratish uchun qo‘llaniladi.
17-3-ro'yxat Draw trait'ini draw metodi bilan birga ta'riflash ko'rsatib beradi:
Fayl nomi: src/lib.rs
pub trait Draw {
fn draw(&self);
}Ro'yxat 17-3: Draw trait'ining ta'rifi
Ushbu sintaksis bizning 10-bo'limda bo'lib o'tgan Traitlarni joriy etish
suhbatimizdan keyin tanish bo'lishi kerak. Keyingisi esa yana yangi sintaksis:
17-4-ro'yxat Screen nomli components nomi ostidagi vekotr o'z ichiga olgan
structni ta'riflaydi. Ushbu vektor Box<dyn Draw> turidan, ya'ni trait obyekt (bu
Box ichida Draw tratini joriy etuvchi istalgan turga solishtiriluvchi).
Fayl nomi: src/lib.rs
pub trait Draw {
fn draw(&self);
}
pub struct Screen {
pub components: Vec<Box<dyn Draw>>,
}Ro'yxat 17-4: Screen structidagi components maydoni
bir vektorda joylashgan va Draw tratini joriy etgan obyektlarni ushlab turibdi
Screen struktida, biz 17-5-ro'yxatda ko'rsatilganiday, draw metodini har
bir components ustidan chaqiradigan run nomli metod yaratamiz:
Fayl nomi: src/lib.rs
pub trait Draw {
fn draw(&self);
}
pub struct Screen {
pub components: Vec<Box<dyn Draw>>,
}
impl Screen {
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}Ro'yxat 17-5: Screen da har bir komponent ustidan
draw metodini chaqiradigan run metodi
Bu generik tur ko'rsatkichi va trait cheklanmalardan farqli boshqacha
ishlaydi. Generik tur parametr bir vaqt o'zida faqat bitta tur qabul qiladi,
trait obyektlar esa boshqa tarafdan ko'plab konkret turlar ishlash vaqtidagi
trait obyektlarni to'ldirib berish uchun ishlatsa bo'ladi. Misol uchun,
Screen struktini 17-6-ro'yxatda ko'rsatilganiday generik tur va trait
cheklanmalari bilan ta'riflasa bo'ladi:
Fayl nomi: src/lib.rs
pub trait Draw {
fn draw(&self);
}
pub struct Screen<T: Draw> {
pub components: Vec<T>,
}
impl<T> Screen<T>
where
T: Draw,
{
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}Ro'yxat 17-6: Screen strukti va uning run metodining
generik va trait cheklanmalarini ishlatgandagi alternativ ta'rifi.
Bu faqat Button yoki faqat TextField turidagi komponentlar ro‘yxatiga
ega bo‘lgan Screen nusxasi bilan cheklaydi. Agar sizda faqat bir xil
to‘plamlar bo‘lsa, generic umumiy va trait xususiyat chegaralaridan
foydalanish afzalroq, chunki aniq turlardan foydalanish uchun ta’riflar
tuzish vaqtida har bir tur uchun birlashtiradi.
Boshqa tomondan, trait obyektlaridan foydalanadigan usul bilan bitta
Screen nusxasi Box<Button>, shuningdek Box<TextField> ni o‘z ichiga
olgan Vec<T> ni saqlash imkoniyatiga ega bo‘ladi. Keling, bu qanday
ishlashini ko‘rib chiqaylik, so‘ngra dasturning ishlash vaqtidagi
unumdorlik ta’sirlari haqida suhbatlashamiz.
Traitni amalga oshirish
Endi Draw traitini amalga oshiradigan ba'zi turlarni qo‘shamiz. Button
turini taqdim etamiz. Yana, haqiqiy GUI kutubxonasini yaratish kitobimiz
doirasidan tashqarida, shuning uchun draw metodi tanasida hech qanday
foydali amalga oshirish bo‘lmaydi. Amalga oshirish qanday ko‘rinishi
mumkinligini tasavvur qilish uchun, Button tuzilmasi width (kenglik),
height (bo‘yi) va label (yorliq) kabi maydonlarga ega bo‘lishi mumkin,
bu 17-7 ro'yxatdada ko‘rsatilgan:
Faylnomi: src/lib.rs
pub trait Draw {
fn draw(&self);
}
pub struct Screen {
pub components: Vec<Box<dyn Draw>>,
}
impl Screen {
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}
pub struct Button {
pub width: u32,
pub height: u32,
pub label: String,
}
impl Draw for Button {
fn draw(&self) {
// code to actually draw a button
}
}Ro'yxat 17-7: Draw traitini amalga oshiradigan Button strukti
Buttonning width, height va label maydonlari boshqa komponentlarga
nisbatan farq qiladi; misol uchun TextFieldning turi avvalgi maydonlar va
qo‘shimcha placeholder maydonidan tashkil topgan bo‘lishi mumkin. Har bir
ekranga chizilishi kerak bo‘lgan turlar Draw trait’ini joriy qilishadi ammo
ularning draw metodlari bir-birlaridan farq qiladi chunki har bir turning
o‘ziga xos shakli yoki boshqa xususiyati chizilishi mumkin. Misol uchun
Button bosganda sodir bo‘ladigan metod impl bloki ichida qo‘shimcha
kiritilishi mumkin. TextField uchun esa bunday funksional talab etilmaydi.
width, height va options maydonlardan tashkil topgan SelectBoxni
amalga oshirmoqchi bo‘lgan dasturchi SelectBox uchun Draw trait’ini
ham Ro‘yxat 17-8 da ko‘rsatilgandek yozishi kerak bo‘ladi:
Fayl nomi: src/main.rs
use gui::Draw;
struct SelectBox {
width: u32,
height: u32,
options: Vec<String>,
}
impl Draw for SelectBox {
fn draw(&self) {
// code to actually draw a select box
}
}
fn main() {}Ro‘yxat 17-8: guidan foydalanuvchi va undagi Draw
trait’ini SelectBox struct’i uchun amalga oshiradigan crate
Kutubxona foydalanuvchisi endi o‘z main funksiyasi ichida Screen nusxasini
yaratish imkoniga ega. Screen nusxasiga foydalanuvchi SelectBox va Button
nusxalarini har birini Box<T> ichiga joylash orqali ularni trait’ga o‘girib
qo‘shib chiqishi mumkin. Undan keyin Screen nusxasida run metodi chaqirgan
vaqtda har bir ichki komponentlarning draw metodi birma-bir chaqiriladi.
Ro‘yxat 17-9 xuddi shuni namoyish etadi:
Fayl nomi: src/main.rs
use gui::Draw;
struct SelectBox {
width: u32,
height: u32,
options: Vec<String>,
}
impl Draw for SelectBox {
fn draw(&self) {
// code to actually draw a select box
}
}
use gui::{Button, Screen};
fn main() {
let screen = Screen {
components: vec![
Box::new(SelectBox {
width: 75,
height: 10,
options: vec![
String::from("Yes"),
String::from("Maybe"),
String::from("No"),
],
}),
Box::new(Button {
width: 50,
height: 10,
label: String::from("OK"),
}),
],
};
screen.run();
}Ro‘yxat 17-9: Bir trait’ni amalga oshiruvchi turli xil turlarni saqlash uchun trait obyektlar ishlatilishi
When we wrote the library, we didn’t know that someone might add the
SelectBox type, but our Screen implementation was able to operate on the
new type and draw it because SelectBox implements the Draw trait, which
means it implements the draw method.
Bu tushuncha — ya’ni, qiymatning aniq tipi emas, balki qanday xabarlarga
javob bera olishi muhim bo‘lishi — dinamik tiplangan tillardagi duck typing
tushunchasiga o‘xshaydi: agar u o‘rdakdek yursa va o‘rdakdek ovoz chiqarsa,
demak u o‘rdak! 17-5-ro‘yxatdagi Screen uchun run funksiyasi
implementatsiyasida run har bir komponentning aniq tipi nima ekanini
bilishga muhtoj emas. Komponent Button yoki SelectBox ekanligini
tekshirmaydi, shunchaki uning draw metodini chaqiradi. components vektoridagi
qiymatlar turi sifatida Box<dyn Draw>ni ko‘rsatish orqali,Screendan draw
metodini chaqira olishimiz mumkin bo‘lgan qiymatlarni talab qiladigan qilib belgiladik.
Trait obyektlar va Rustning turlar tizimidan foydalanib, duck typing uslubiga
o‘xshash kod yozishning afzalligi shundaki, qiymatning ma’lum bir usulni
bajarishini ishga tushirish vaqtida tekshirishimiz shart emas. Bundan tashqari,
agar qiymat usulni amalga oshirmasa-yu, lekin u chaqirilsa ham, xatolar yuzaga
kelishidan xavotirlanishimizga hojat yo‘q. Agar qiymatlar trait obyektlariga
kerak bo'lgan trait'larni amalga oshirmasa, Rust bu kodni kompilatsiya qilmaydi.
Masalan, 17-10-ro'yxatda String komponentli Screen yaratishga harakat
qilsa, nima sodir bo‘lishi ko‘rsatilgan:
Fayl nomi: src/main.rs
use gui::Screen;
fn main() {
let screen = Screen {
components: vec![Box::new(String::from("Salom"))],
};
screen.run();
}17-10-ro'yxat: Trait obyektining xususiyatini amalga oshirmaydigan turdan foydalanishga urinish
String funksiyasi Draw trait'ni amalga oshirmagani uchun quyidagi xatolik yuz berdi:
$ cargo run
Compiling gui v0.1.0 (file:///projects/gui)
error[E0277]: the trait bound `String: Draw` is not satisfied
--> src/main.rs:5:26
|
5 | components: vec![Box::new(String::from("Hi"))],
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^ the trait `Draw` is not implemented for `String`
|
= help: the trait `Draw` is implemented for `Button`
= note: required for the cast from `String` to the object type `dyn Draw`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `gui` due to previous error
Bu xato quyidagi ikki holatdan birini ko‘rsatadi: yoki o‘tkazmoqchi
bo‘lmagan biror narsani Screenga o‘tkazilayapti va shuning uchun boshqa turda
o‘tkazish kerak, yoki Stringga Drawni amalga oshirishimiz kerak, shunda
Screen drawni chaqira oladi.
Trait Objects Perform Dynamic Dispatch
"Generiklar yordamida kodning ishlashi" bo‘limidagi muhokamadagi kompilyator monomorfizatsiya qismini eslaymiz. Kompilyator umumiy turlarning trait chegaralari ustida ishlash jarayonida u har bir umumiy tur o‘rnida ishlatilgan aniq turlarni funksiya va metodlarga joriy etadi. Monomorfizatsiya natijasidagi kod static dispatch (ya’ni statik yo‘naltirish) deb ataladi. Bu degani kompilyatsiya vaqtida kompilyator qaysi turga oid funksiya yoki metod qayerda chaqirilishini biladi. Kompilyator bilmagan holat esa dynamic dispatch (ya’ni dinamik yo‘naltirish) deb ataladi va kompilyatsiya jarayonida dastur o‘zi ishga tushish vaqtida yo‘naltira oladigan kod yaratiladi.
Rust-da trait obyektlaridan foydalanganda, dinamik dispatch ishlatiladi. Kompilyator kodda qaysi turdagi qiymatlar ishlatilishini oldindan bilmaydi, shuning uchun qaysi turdagi metod chaqirilishini ham bilmaydi. Buning o‘rniga, bajarilish vaqtida (runtime) Rust trait obyektining ichidagi ko‘rsatkichlardan (pointer) qaysi metodni chaqirish kerakligini aniqlaydi. Bu esa statik dispatchiga nisbatan bajarilish vaqtida qo‘shimcha xarajatlarni keltirib chiqaradi. Shuningdek, dinamik dispatchi kompilyatorga metod kodini inline qilish imkonini bermaydi, bu esa ba’zi optimallashtirishlarni cheklaydi. Biroq, biz ro‘yxat 17-5 yozgan kodimizda qo‘shimcha moslashuvchanlikka ega bo‘ldik va ro‘yxat 17-9 da qo‘llab-quvvatlay oldik, shuning uchun buni hisobga olish kerak.
Implementing an Object-Oriented Design Pattern
The state pattern is an object-oriented design pattern. The crux of the pattern is that we define a set of states a value can have internally. The states are represented by a set of state objects, and the value’s behavior changes based on its state. We’re going to work through an example of a blog post struct that has a field to hold its state, which will be a state object from the set "draft", "review", or "published".
Rust dasturlash tilida dasturiy holat obyektlari funksionalini bo‘lishish uchun obyektga yo‘naltirilgan dasturlash tillariga nisbatan albatta struct va trait’lar ishlatiladi. Har bir dastur holat obyekti o‘z xatti-harakati va qachon boshqa holatga o‘tishi kerakligini boshqarishi uchun javobgardir. Uning qiymati boshqa obyektlar xatti-harakati yoki holat o‘zgaruvi haqida hech nima bilmaydi.
The advantage of using the state pattern is that, when the business requirements of the program change, we won’t need to change the code of the value holding the state or the code that uses the value. We’ll only need to update the code inside one of the state objects to change its rules or perhaps add more state objects.
Birinchidan,state namunasini an’anaviy obyektga yo‘naltirilgan tarzda amalga
oshib, so‘ng Rustda yanada tabiiyroq bo‘lgan yondashuvdan foydalanish mumkun.
Keling, blog post yozish jarayonini state qonuniyatidan foydalangan holda
bosqichma-bosqich amalga oshirishni ko‘rib chiqaylik.
The final functionality will look like this:
- A blog post starts as an empty draft.
- When the draft is done, a review of the post is requested.
- When the post is approved, it gets published.
- Only published blog posts return content to print, so unapproved posts can’t accidentally be published.
Any other changes attempted on a post should have no effect. For example, if we try to approve a draft blog post before we’ve requested a review, the post should remain an unpublished draft.
Ro‘yxat 17-11 da ko‘rsatilgan ish jarayoni: blog nomli kutubxona crate’ni
joriy etish arafasida. blog joriy etilmaganligi sababli ushbu kod kompilyatsiya
bo‘lmaydi
Fayl nomi: src/main.rs
use blog::Post;
fn main() {
let mut post = Post::new();
post.add_text("I ate a salad for lunch today");
assert_eq!("", post.content());
post.request_review();
assert_eq!("", post.content());
post.approve();
assert_eq!("I ate a salad for lunch today", post.content());
}Ro’yxat 17-11: blog crate’dan kutilayotgan
xatti-harakat namoyish etilgan.
We want to allow the user to create a new draft blog post with Post::new. We
want to allow text to be added to the blog post. If we try to get the post’s
content immediately, before approval, we shouldn’t get any text because the
post is still a draft. We’ve added assert_eq! in the code for demonstration
purposes. An excellent unit test for this would be to assert that a draft blog
post returns an empty string from the content method, but we’re not going to
write tests for this example.
Next, we want to enable a request for a review of the post, and we want
content to return an empty string while waiting for the review. When the post
receives approval, it should get published, meaning the text of the post will
be returned when content is called.
E’tibor bering, biz crate ichidan faqat bitta tur (type) bilan ishlayapmiz - bu
Post turi. Ushbu tur holat (state) andozasi (pattern) dan foydalanadi va u
postning uch xil holatidan birini ifodalovchi obyekt qiymatini saqlaydi:
qoralama (draft), ko‘rib chiqishni kutayotgan (waiting for review) yoki nashr
qilingan (published).
Bir holatdan boshqasiga o‘tish jarayoni Post turining o‘zida ichki tarzda
boshqariladi. Holatlar, kutubxonamiz foydalanuvchilari Post obyektida
metodlarni chaqirganida o‘zgaradi, lekin foydalanuvchilar bu holat
almashuvlarini bevosita boshqarishga majbur emaslar. Bundan tashqari,
foydalanuvchilar holatlar bilan xato qilolmaydi, masalan, postni
tekshirilmasdan turib nashr qilish kabi.
Post ni aniqlash va qoralama holatida yangi nusxa yaratish
Keling, kutubxona implementatsiyasini boshlaymiz! Umumiy (public) Post
strukturasiga ehtiyoj borligini bilamiz, u kontentni saqlaydi. Shunday ekan,
avval Post strukturasini va unga bog‘langan umumiy new funksiyasini
ta’riflashdan boshlaymiz. Ushbu funksiya Post ning yangi nusxasini yaratadi
(rasmda ko‘rsatilganidek — Listing 17-12). Bundan tashqari, xususiy (private)
State trait'ini ham yaratamiz. Bu trait Post uchun barcha holat obyektlari
bajarishi kerak bo‘lgan xatti-harakatlarni belgilab beradi.
Keyin ’Post’ o‘z ichida ’state’ nomli maxfiy maydonida ’Option
Fayl nomi: src/lib.rs
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
}
trait State {}
struct Draft {}
impl State for Draft {}17-12-ro‘yxat: Post strukturasi va yangi Post
namunasini yaratuvchi new funksiyasi, State interfeysi hamda Draft
strukturasining ta’rifi
The State trait defines the behavior shared by different post states. The
state objects are Draft, PendingReview, and Published, and they will all
implement the State trait. For now, the trait doesn’t have any methods, and
we’ll start by defining just the Draft state because that is the state we
want a post to start in.
When we create a new Post, we set its state field to a Some value that
holds a Box. This Box points to a new instance of the Draft struct.
This ensures whenever we create a new instance of Post, it will start out as
a draft. Because the state field of Post is private, there is no way to
create a Post in any other state! In the Post::new function, we set the
content field to a new, empty String.
Storing the Text of the Post Content
We saw in Listing 17-11 that we want to be able to call a method named
add_text and pass it a &str that is then added as the text content of the
blog post. We implement this as a method, rather than exposing the content
field as pub, so that later we can implement a method that will control how
the content field’s data is read. The add_text method is pretty
straightforward, so let’s add the implementation in Listing 17-13 to the impl Post block:
Filename: src/lib.rs
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
}
trait State {}
struct Draft {}
impl State for Draft {}Listing 17-13: Implementing the add_text method to add
text to a post’s content
The add_text method takes a mutable reference to self, because we’re
changing the Post instance that we’re calling add_text on. We then call
push_str on the String in content and pass the text argument to add to
the saved content. This behavior doesn’t depend on the state the post is in,
so it’s not part of the state pattern. The add_text method doesn’t interact
with the state field at all, but it is part of the behavior we want to
support.
Ensuring the Content of a Draft Post Is Empty
Even after we’ve called add_text and added some content to our post, we still
want the content method to return an empty string slice because the post is
still in the draft state, as shown on line 7 of Listing 17-11. For now, let’s
implement the content method with the simplest thing that will fulfill this
requirement: always returning an empty string slice. We’ll change this later
once we implement the ability to change a post’s state so it can be published.
So far, posts can only be in the draft state, so the post content should always
be empty. Listing 17-14 shows this placeholder implementation:
Filename: src/lib.rs
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
""
}
}
trait State {}
struct Draft {}
impl State for Draft {}Listing 17-14: Adding a placeholder implementation for
the content method on Post that always returns an empty string slice
With this added content method, everything in Listing 17-11 up to line 7
works as intended.
Requesting a Review of the Post Changes Its State
Next, we need to add functionality to request a review of a post, which should
change its state from Draft to PendingReview. Listing 17-15 shows this code:
Filename: src/lib.rs
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
""
}
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
}
trait State {
fn request_review(self: Box<Self>) -> Box<dyn State>;
}
struct Draft {}
impl State for Draft {
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
}
struct PendingReview {}
impl State for PendingReview {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
}Listing 17-15: Implementing request_review methods on
Post and the State trait
We give Post a public method named request_review that will take a mutable
reference to self. Then we call an internal request_review method on the
current state of Post, and this second request_review method consumes the
current state and returns a new state.
We add the request_review method to the State trait; all types that
implement the trait will now need to implement the request_review method.
Note that rather than having self, &self, or &mut self as the first
parameter of the method, we have self: Box<Self>. This syntax means the
method is only valid when called on a Box holding the type. This syntax takes
ownership of Box<Self>, invalidating the old state so the state value of the
Post can transform into a new state.
To consume the old state, the request_review method needs to take ownership
of the state value. This is where the Option in the state field of Post
comes in: we call the take method to take the Some value out of the state
field and leave a None in its place, because Rust doesn’t let us have
unpopulated fields in structs. This lets us move the state value out of
Post rather than borrowing it. Then we’ll set the post’s state value to the
result of this operation.
We need to set state to None temporarily rather than setting it directly
with code like self.state = self.state.request_review(); to get ownership of
the state value. This ensures Post can’t use the old state value after
we’ve transformed it into a new state.
The request_review method on Draft returns a new, boxed instance of a new
PendingReview struct, which represents the state when a post is waiting for a
review. The PendingReview struct also implements the request_review method
but doesn’t do any transformations. Rather, it returns itself, because when we
request a review on a post already in the PendingReview state, it should stay
in the PendingReview state.
Now we can start seeing the advantages of the state pattern: the
request_review method on Post is the same no matter its state value. Each
state is responsible for its own rules.
We’ll leave the content method on Post as is, returning an empty string
slice. We can now have a Post in the PendingReview state as well as in the
Draft state, but we want the same behavior in the PendingReview state.
Listing 17-11 now works up to line 10!
Adding approve to Change the Behavior of content
The approve method will be similar to the request_review method: it will
set state to the value that the current state says it should have when that
state is approved, as shown in Listing 17-16:
Filename: src/lib.rs
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
""
}
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
pub fn approve(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.approve())
}
}
}
trait State {
fn request_review(self: Box<Self>) -> Box<dyn State>;
fn approve(self: Box<Self>) -> Box<dyn State>;
}
struct Draft {}
impl State for Draft {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}
struct PendingReview {}
impl State for PendingReview {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
Box::new(Published {})
}
}
struct Published {}
impl State for Published {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}Listing 17-16: Implementing the approve method on
Post and the State trait
We add the approve method to the State trait and add a new struct that
implements State, the Published state.
Similar to the way request_review on PendingReview works, if we call the
approve method on a Draft, it will have no effect because approve will
return self. When we call approve on PendingReview, it returns a new,
boxed instance of the Published struct. The Published struct implements the
State trait, and for both the request_review method and the approve
method, it returns itself, because the post should stay in the Published
state in those cases.
Now we need to update the content method on Post. We want the value
returned from content to depend on the current state of the Post, so we’re
going to have the Post delegate to a content method defined on its state,
as shown in Listing 17-17:
Filename: src/lib.rs
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
self.state.as_ref().unwrap().content(self)
}
// --snip--
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
pub fn approve(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.approve())
}
}
}
trait State {
fn request_review(self: Box<Self>) -> Box<dyn State>;
fn approve(self: Box<Self>) -> Box<dyn State>;
}
struct Draft {}
impl State for Draft {
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}
struct PendingReview {}
impl State for PendingReview {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
Box::new(Published {})
}
}
struct Published {}
impl State for Published {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}Listing 17-17: Updating the content method on Post to
delegate to a content method on State
Because the goal is to keep all these rules inside the structs that implement
State, we call a content method on the value in state and pass the post
instance (that is, self) as an argument. Then we return the value that’s
returned from using the content method on the state value.
We call the as_ref method on the Option because we want a reference to the
value inside the Option rather than ownership of the value. Because state
is an Option<Box<dyn State>>, when we call as_ref, an Option<&Box<dyn State>> is returned. If we didn’t call as_ref, we would get an error because
we can’t move state out of the borrowed &self of the function parameter.
We then call the unwrap method, which we know will never panic, because we
know the methods on Post ensure that state will always contain a Some
value when those methods are done. This is one of the cases we talked about in
the “Cases In Which You Have More Information Than the
Compiler” section of Chapter 9 when we
know that a None value is never possible, even though the compiler isn’t able
to understand that.
At this point, when we call content on the &Box<dyn State>, deref coercion
will take effect on the & and the Box so the content method will
ultimately be called on the type that implements the State trait. That means
we need to add content to the State trait definition, and that is where
we’ll put the logic for what content to return depending on which state we
have, as shown in Listing 17-18:
Filename: src/lib.rs
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
self.state.as_ref().unwrap().content(self)
}
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
pub fn approve(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.approve())
}
}
}
trait State {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State>;
fn approve(self: Box<Self>) -> Box<dyn State>;
fn content<'a>(&self, post: &'a Post) -> &'a str {
""
}
}
// --snip--
struct Draft {}
impl State for Draft {
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}
struct PendingReview {}
impl State for PendingReview {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
Box::new(Published {})
}
}
struct Published {}
impl State for Published {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
fn content<'a>(&self, post: &'a Post) -> &'a str {
&post.content
}
}Listing 17-18: Adding the content method to the State
trait
We add a default implementation for the content method that returns an empty
string slice. That means we don’t need to implement content on the Draft
and PendingReview structs. The Published struct will override the content
method and return the value in post.content.
Note that we need lifetime annotations on this method, as we discussed in
Chapter 10. We’re taking a reference to a post as an argument and returning a
reference to part of that post, so the lifetime of the returned reference is
related to the lifetime of the post argument.
And we’re done—all of Listing 17-11 now works! We’ve implemented the state
pattern with the rules of the blog post workflow. The logic related to the
rules lives in the state objects rather than being scattered throughout Post.
Why Not An Enum?
You may have been wondering why we didn’t use an
enumwith the different possible post states as variants. That’s certainly a possible solution, try it and compare the end results to see which you prefer! One disadvantage of using an enum is every place that checks the value of the enum will need amatchexpression or similar to handle every possible variant. This could get more repetitive than this trait object solution.
Trade-offs of the State Pattern
We’ve shown that Rust is capable of implementing the object-oriented state
pattern to encapsulate the different kinds of behavior a post should have in
each state. The methods on Post know nothing about the various behaviors. The
way we organized the code, we have to look in only one place to know the
different ways a published post can behave: the implementation of the State
trait on the Published struct.
If we were to create an alternative implementation that didn’t use the state
pattern, we might instead use match expressions in the methods on Post or
even in the main code that checks the state of the post and changes behavior
in those places. That would mean we would have to look in several places to
understand all the implications of a post being in the published state! This
would only increase the more states we added: each of those match expressions
would need another arm.
With the state pattern, the Post methods and the places we use Post don’t
need match expressions, and to add a new state, we would only need to add a
new struct and implement the trait methods on that one struct.
The implementation using the state pattern is easy to extend to add more functionality. To see the simplicity of maintaining code that uses the state pattern, try a few of these suggestions:
- Add a
rejectmethod that changes the post’s state fromPendingReviewback toDraft. - Require two calls to
approvebefore the state can be changed toPublished. - Allow users to add text content only when a post is in the
Draftstate. Hint: have the state object responsible for what might change about the content but not responsible for modifying thePost.
One downside of the state pattern is that, because the states implement the
transitions between states, some of the states are coupled to each other. If we
add another state between PendingReview and Published, such as Scheduled,
we would have to change the code in PendingReview to transition to
Scheduled instead. It would be less work if PendingReview didn’t need to
change with the addition of a new state, but that would mean switching to
another design pattern.
Another downside is that we’ve duplicated some logic. To eliminate some of the
duplication, we might try to make default implementations for the
request_review and approve methods on the State trait that return self;
however, this would violate object safety, because the trait doesn’t know what
the concrete self will be exactly. We want to be able to use State as a
trait object, so we need its methods to be object safe.
Other duplication includes the similar implementations of the request_review
and approve methods on Post. Both methods delegate to the implementation of
the same method on the value in the state field of Option and set the new
value of the state field to the result. If we had a lot of methods on Post
that followed this pattern, we might consider defining a macro to eliminate the
repetition (see the “Macros” section in Chapter 19).
By implementing the state pattern exactly as it’s defined for object-oriented
languages, we’re not taking as full advantage of Rust’s strengths as we could.
Let’s look at some changes we can make to the blog crate that can make
invalid states and transitions into compile time errors.
Encoding States and Behavior as Types
We’ll show you how to rethink the state pattern to get a different set of trade-offs. Rather than encapsulating the states and transitions completely so outside code has no knowledge of them, we’ll encode the states into different types. Consequently, Rust’s type checking system will prevent attempts to use draft posts where only published posts are allowed by issuing a compiler error.
Let’s consider the first part of main in Listing 17-11:
Filename: src/main.rs
use blog::Post;
fn main() {
let mut post = Post::new();
post.add_text("I ate a salad for lunch today");
assert_eq!("", post.content());
post.request_review();
assert_eq!("", post.content());
post.approve();
assert_eq!("I ate a salad for lunch today", post.content());
}We still enable the creation of new posts in the draft state using Post::new
and the ability to add text to the post’s content. But instead of having a
content method on a draft post that returns an empty string, we’ll make it so
draft posts don’t have the content method at all. That way, if we try to get
a draft post’s content, we’ll get a compiler error telling us the method
doesn’t exist. As a result, it will be impossible for us to accidentally
display draft post content in production, because that code won’t even compile.
Listing 17-19 shows the definition of a Post struct and a DraftPost struct,
as well as methods on each:
Filename: src/lib.rs
pub struct Post {
content: String,
}
pub struct DraftPost {
content: String,
}
impl Post {
pub fn new() -> DraftPost {
DraftPost {
content: String::new(),
}
}
pub fn content(&self) -> &str {
&self.content
}
}
impl DraftPost {
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
}Listing 17-19: A Post with a content method and a
DraftPost without a content method
Both the Post and DraftPost structs have a private content field that
stores the blog post text. The structs no longer have the state field because
we’re moving the encoding of the state to the types of the structs. The Post
struct will represent a published post, and it has a content method that
returns the content.
We still have a Post::new function, but instead of returning an instance of
Post, it returns an instance of DraftPost. Because content is private
and there aren’t any functions that return Post, it’s not possible to create
an instance of Post right now.
The DraftPost struct has an add_text method, so we can add text to
content as before, but note that DraftPost does not have a content method
defined! So now the program ensures all posts start as draft posts, and draft
posts don’t have their content available for display. Any attempt to get around
these constraints will result in a compiler error.
Implementing Transitions as Transformations into Different Types
So how do we get a published post? We want to enforce the rule that a draft
post has to be reviewed and approved before it can be published. A post in the
pending review state should still not display any content. Let’s implement
these constraints by adding another struct, PendingReviewPost, defining the
request_review method on DraftPost to return a PendingReviewPost, and
defining an approve method on PendingReviewPost to return a Post, as
shown in Listing 17-20:
Filename: src/lib.rs
pub struct Post {
content: String,
}
pub struct DraftPost {
content: String,
}
impl Post {
pub fn new() -> DraftPost {
DraftPost {
content: String::new(),
}
}
pub fn content(&self) -> &str {
&self.content
}
}
impl DraftPost {
// --snip--
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn request_review(self) -> PendingReviewPost {
PendingReviewPost {
content: self.content,
}
}
}
pub struct PendingReviewPost {
content: String,
}
impl PendingReviewPost {
pub fn approve(self) -> Post {
Post {
content: self.content,
}
}
}Listing 17-20: A PendingReviewPost that gets created by
calling request_review on DraftPost and an approve method that turns a
PendingReviewPost into a published Post
The request_review and approve methods take ownership of self, thus
consuming the DraftPost and PendingReviewPost instances and transforming
them into a PendingReviewPost and a published Post, respectively. This way,
we won’t have any lingering DraftPost instances after we’ve called
request_review on them, and so forth. The PendingReviewPost struct doesn’t
have a content method defined on it, so attempting to read its content
results in a compiler error, as with DraftPost. Because the only way to get a
published Post instance that does have a content method defined is to call
the approve method on a PendingReviewPost, and the only way to get a
PendingReviewPost is to call the request_review method on a DraftPost,
we’ve now encoded the blog post workflow into the type system.
But we also have to make some small changes to main. The request_review and
approve methods return new instances rather than modifying the struct they’re
called on, so we need to add more let post = shadowing assignments to save
the returned instances. We also can’t have the assertions about the draft and
pending review posts’ contents be empty strings, nor do we need them: we can’t
compile code that tries to use the content of posts in those states any longer.
The updated code in main is shown in Listing 17-21:
Filename: src/main.rs
use blog::Post;
fn main() {
let mut post = Post::new();
post.add_text("I ate a salad for lunch today");
let post = post.request_review();
let post = post.approve();
assert_eq!("I ate a salad for lunch today", post.content());
}Listing 17-21: Modifications to main to use the new
implementation of the blog post workflow
The changes we needed to make to main to reassign post mean that this
implementation doesn’t quite follow the object-oriented state pattern anymore:
the transformations between the states are no longer encapsulated entirely
within the Post implementation. However, our gain is that invalid states are
now impossible because of the type system and the type checking that happens at
compile time! This ensures that certain bugs, such as display of the content of
an unpublished post, will be discovered before they make it to production.
Try the tasks suggested at the start of this section on the blog crate as it
is after Listing 17-21 to see what you think about the design of this version
of the code. Note that some of the tasks might be completed already in this
design.
We’ve seen that even though Rust is capable of implementing object-oriented design patterns, other patterns, such as encoding state into the type system, are also available in Rust. These patterns have different trade-offs. Although you might be very familiar with object-oriented patterns, rethinking the problem to take advantage of Rust’s features can provide benefits, such as preventing some bugs at compile time. Object-oriented patterns won’t always be the best solution in Rust due to certain features, like ownership, that object-oriented languages don’t have.
Summary
No matter whether or not you think Rust is an object-oriented language after reading this chapter, you now know that you can use trait objects to get some object-oriented features in Rust. Dynamic dispatch can give your code some flexibility in exchange for a bit of runtime performance. You can use this flexibility to implement object-oriented patterns that can help your code’s maintainability. Rust also has other features, like ownership, that object-oriented languages don’t have. An object-oriented pattern won’t always be the best way to take advantage of Rust’s strengths, but is an available option.
Next, we’ll look at patterns, which are another of Rust’s features that enable lots of flexibility. We’ve looked at them briefly throughout the book but haven’t seen their full capability yet. Let’s go!
Patternlar va matching
Pattern (namuna, andaza) — Rust dasturlash tilida kodning biron qismini
maʼlum bir tuzilma yoki qiymatga moslashtirish uchun ishlatiladigan maxsus
sintaksis. Patternlarni match bilan birga ishlatish orqali siz dasturning
ishlash jarayonini yana ham yaxshiroq boshqara olishingiz mumkin. Patternlar
quyidagi kombinatsiyalardan iborat boʼlishi mumkin:
- Literallar
- Qayta strukturalangan arrayʼlar, enumʼlar, structlʼar yoki tupleʼlar
- Oʼzgaruvchilar
- Pastki chiziqcha (yohud Wildcards,
_koʼrinishida yoziladi) - Toʼldiruvchilar
Ushbu kombinatsiyalarga misol qilib x, (a, 3) va Some(Color::Red) larni
koʼrsatishimiz mumkin. Ushbu kombinatsiyalar maʼlumotning tuzilishini ifoda
etadi. Dasturimiz biron maʼlumotni ushbu kombinatsiyalarga solishtirib koʼradi
va maʼlumotimizning turi aynan biz istagan shaklda ekani yoki yoʼqligini
tekshiradi. Maʼlumot tekshirilgach, dasturni davom ettirish mumkin boʼladi.
Patternni ishlatish uchun, biz uni biron maʼlumot bilan solishtiramiz. Agar
pattern maʼlumot bilan mos kelsa, biz u maʼlumotni kodning qolgan qismida
ishlatishimiz mumkin boʼladi. 6-boʼlimdagi tangalarni tartiblovchi mashina
misolini yodga oladigan boʼlsak, u yerda match ishlatilganiga guvoh boʼlamiz.
Agar qiymat pattern bilan mos kelsa, biz uni ishlatishimiz mumkin. Aks holda,
patternning qolgan qismi ishlamaydi.
Ushbu boʼlim patternlarga tegishli barcha maʼlumotlar uchun manba hisoblanadi. Ushbu boʼlimda biz patternlarni qanday toʼgʼri ishlatish, aniq va noaniq patternlar oʼrtasidagi farq hamda patternlarning turli xil sintaks shakldagi koʼrinishlarini oʼrganamiz. Ushbu boʼlim yakunida siz patternlarni oʼz dasturlaringizdagi turli konseptsiyalarni sodda va oson yoʼl bilan ishlatishni boshlaysiz.
Qoliplar qoʻllaniladigan barcha oʻrinlar
Rust tilida, qoliplarga bir qancha joylarda duch kelish mumkin, va shu paytgacha, oʻzingiz sezmagan holda, ulardan foydalanib kelayotgan edingiz! Bu boʻlim qoliplapdan foydalanish joiz boʻlgan barcha oʻrinlar haqida soʻz yuritadi.
match qoʻllari
6-bobda aytganimizdek, qoliplarni match ifodasining qoʻllarida ishlatamiz.
Rasman, match quyidagilar bilan ifodalanadi: match kalitsoʻzi,
qolipga solinayotgan qiymat, va qolip va unga qiymat mos tushganda bajariladigan
ifodadan iborat bir yoki bir nechta match qoʻllari. Buni siz quyidagi misolda
koʻrishingiz mumkin:
match QIYMAT {
QOLIP => IFODA, // birinchi qoʻl
QOLIP => IFODA, // ikkinchi qoʻl
QOLIP => IFODA, // uchinchi qoʻl
}
For example, here's the match expression from Listing 6-5 that matches on an
Option<i32> value in the variable x:
match x {
None => None,
Some(i) => Some(i + 1),
}The patterns in this match expression are the None and Some(i) on the
left of each arrow.
One requirement for match expressions is that they need to be exhaustive in
the sense that all possibilities for the value in the match expression must
be accounted for. One way to ensure you’ve covered every possibility is to have
a catchall pattern for the last arm: for example, a variable name matching any
value can never fail and thus covers every remaining case.
The particular pattern _ will match anything, but it never binds to a
variable, so it’s often used in the last match arm. The _ pattern can be
useful when you want to ignore any value not specified, for example. We’ll
cover the _ pattern in more detail in the “Ignoring Values in a
Pattern” section later in this
chapter.
Conditional if let Expressions
In Chapter 6 we discussed how to use if let expressions mainly as a shorter
way to write the equivalent of a match that only matches one case.
Optionally, if let can have a corresponding else containing code to run if
the pattern in the if let doesn’t match.
Listing 18-1 shows that it’s also possible to mix and match if let, else if, and else if let expressions. Doing so gives us more flexibility than a
match expression in which we can express only one value to compare with the
patterns. Also, Rust doesn't require that the conditions in a series of if let, else if, else if let arms relate to each other.
The code in Listing 18-1 determines what color to make your background based on a series of checks for several conditions. For this example, we’ve created variables with hardcoded values that a real program might receive from user input.
Filename: src/main.rs
fn main() { let favorite_color: Option<&str> = None; let is_tuesday = false; let age: Result<u8, _> = "34".parse(); if let Some(color) = favorite_color { println!("Using your favorite color, {color}, as the background"); } else if is_tuesday { println!("Tuesday is green day!"); } else if let Ok(age) = age { if age > 30 { println!("Using purple as the background color"); } else { println!("Using orange as the background color"); } } else { println!("Using blue as the background color"); } }
Listing 18-1: Mixing if let, else if, else if let,
and else
If the user specifies a favorite color, that color is used as the background. If no favorite color is specified and today is Tuesday, the background color is green. Otherwise, if the user specifies their age as a string and we can parse it as a number successfully, the color is either purple or orange depending on the value of the number. If none of these conditions apply, the background color is blue.
This conditional structure lets us support complex requirements. With the
hardcoded values we have here, this example will print Using purple as the background color.
You can see that if let can also introduce shadowed variables in the same way
that match arms can: the line if let Ok(age) = age introduces a new
shadowed age variable that contains the value inside the Ok variant. This
means we need to place the if age > 30 condition within that block: we can’t
combine these two conditions into if let Ok(age) = age && age > 30. The
shadowed age we want to compare to 30 isn’t valid until the new scope starts
with the curly bracket.
The downside of using if let expressions is that the compiler doesn’t check
for exhaustiveness, whereas with match expressions it does. If we omitted the
last else block and therefore missed handling some cases, the compiler would
not alert us to the possible logic bug.
while let Conditional Loops
Similar in construction to if let, the while let conditional loop allows a
while loop to run for as long as a pattern continues to match. In Listing
18-2 we code a while let loop that uses a vector as a stack and prints the
values in the vector in the opposite order in which they were pushed.
fn main() { let mut stack = Vec::new(); stack.push(1); stack.push(2); stack.push(3); while let Some(top) = stack.pop() { println!("{}", top); } }
Listing 18-2: Using a while let loop to print values
for as long as stack.pop() returns Some
This example prints 3, 2, and then 1. The pop method takes the last element
out of the vector and returns Some(value). If the vector is empty, pop
returns None. The while loop continues running the code in its block as
long as pop returns Some. When pop returns None, the loop stops. We can
use while let to pop every element off our stack.
for Loops
In a for loop, the value that directly follows the keyword for is a
pattern. For example, in for x in y the x is the pattern. Listing 18-3
demonstrates how to use a pattern in a for loop to destructure, or break
apart, a tuple as part of the for loop.
fn main() { let v = vec!['a', 'b', 'c']; for (index, value) in v.iter().enumerate() { println!("{} is at index {}", value, index); } }
Listing 18-3: Using a pattern in a for loop to
destructure a tuple
The code in Listing 18-3 will print the following:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
Finished dev [unoptimized + debuginfo] target(s) in 0.52s
Running `target/debug/patterns`
a is at index 0
b is at index 1
c is at index 2
We adapt an iterator using the enumerate method so it produces a value and
the index for that value, placed into a tuple. The first value produced is the
tuple (0, 'a'). When this value is matched to the pattern (index, value),
index will be 0 and value will be 'a', printing the first line of the
output.
let Statements
Prior to this chapter, we had only explicitly discussed using patterns with
match and if let, but in fact, we’ve used patterns in other places as well,
including in let statements. For example, consider this straightforward
variable assignment with let:
#![allow(unused)] fn main() { let x = 5; }
Every time you've used a let statement like this you've been using patterns,
although you might not have realized it! More formally, a let statement looks
like this:
let PATTERN = EXPRESSION;
In statements like let x = 5; with a variable name in the PATTERN slot, the
variable name is just a particularly simple form of a pattern. Rust compares
the expression against the pattern and assigns any names it finds. So in the
let x = 5; example, x is a pattern that means “bind what matches here to
the variable x.” Because the name x is the whole pattern, this pattern
effectively means “bind everything to the variable x, whatever the value is.”
To see the pattern matching aspect of let more clearly, consider Listing
18-4, which uses a pattern with let to destructure a tuple.
fn main() { let (x, y, z) = (1, 2, 3); }
Listing 18-4: Using a pattern to destructure a tuple and create three variables at once
Here, we match a tuple against a pattern. Rust compares the value (1, 2, 3)
to the pattern (x, y, z) and sees that the value matches the pattern, so Rust
binds 1 to x, 2 to y, and 3 to z. You can think of this tuple
pattern as nesting three individual variable patterns inside it.
If the number of elements in the pattern doesn’t match the number of elements in the tuple, the overall type won’t match and we’ll get a compiler error. For example, Listing 18-5 shows an attempt to destructure a tuple with three elements into two variables, which won’t work.
fn main() {
let (x, y) = (1, 2, 3);
}Listing 18-5: Incorrectly constructing a pattern whose variables don’t match the number of elements in the tuple
Attempting to compile this code results in this type error:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
error[E0308]: mismatched types
--> src/main.rs:2:9
|
2 | let (x, y) = (1, 2, 3);
| ^^^^^^ --------- this expression has type `({integer}, {integer}, {integer})`
| |
| expected a tuple with 3 elements, found one with 2 elements
|
= note: expected tuple `({integer}, {integer}, {integer})`
found tuple `(_, _)`
For more information about this error, try `rustc --explain E0308`.
error: could not compile `patterns` due to previous error
To fix the error, we could ignore one or more of the values in the tuple using
_ or .., as you’ll see in the “Ignoring Values in a
Pattern” section. If the problem
is that we have too many variables in the pattern, the solution is to make the
types match by removing variables so the number of variables equals the number
of elements in the tuple.
Function Parameters
Function parameters can also be patterns. The code in Listing 18-6, which
declares a function named foo that takes one parameter named x of type
i32, should by now look familiar.
fn foo(x: i32) { // code goes here } fn main() {}
Listing 18-6: A function signature uses patterns in the parameters
The x part is a pattern! As we did with let, we could match a tuple in a
function’s arguments to the pattern. Listing 18-7 splits the values in a tuple
as we pass it to a function.
Filename: src/main.rs
fn print_coordinates(&(x, y): &(i32, i32)) { println!("Current location: ({}, {})", x, y); } fn main() { let point = (3, 5); print_coordinates(&point); }
Listing 18-7: A function with parameters that destructure a tuple
This code prints Current location: (3, 5). The values &(3, 5) match the
pattern &(x, y), so x is the value 3 and y is the value 5.
We can also use patterns in closure parameter lists in the same way as in function parameter lists, because closures are similar to functions, as discussed in Chapter 13.
At this point, you’ve seen several ways of using patterns, but patterns don’t work the same in every place we can use them. In some places, the patterns must be irrefutable; in other circumstances, they can be refutable. We’ll discuss these two concepts next.
Refutability: Whether a Pattern Might Fail to Match
Patterns come in two forms: refutable and irrefutable. Patterns that will match
for any possible value passed are irrefutable. An example would be x in the
statement let x = 5; because x matches anything and therefore cannot fail
to match. Patterns that can fail to match for some possible value are
refutable. An example would be Some(x) in the expression if let Some(x) = a_value because if the value in the a_value variable is None rather than
Some, the Some(x) pattern will not match.
Function parameters, let statements, and for loops can only accept
irrefutable patterns, because the program cannot do anything meaningful when
values don’t match. The if let and while let expressions accept
refutable and irrefutable patterns, but the compiler warns against
irrefutable patterns because by definition they’re intended to handle possible
failure: the functionality of a conditional is in its ability to perform
differently depending on success or failure.
In general, you shouldn’t have to worry about the distinction between refutable and irrefutable patterns; however, you do need to be familiar with the concept of refutability so you can respond when you see it in an error message. In those cases, you’ll need to change either the pattern or the construct you’re using the pattern with, depending on the intended behavior of the code.
Let’s look at an example of what happens when we try to use a refutable pattern
where Rust requires an irrefutable pattern and vice versa. Listing 18-8 shows a
let statement, but for the pattern we’ve specified Some(x), a refutable
pattern. As you might expect, this code will not compile.
fn main() {
let some_option_value: Option<i32> = None;
let Some(x) = some_option_value;
}Listing 18-8: Attempting to use a refutable pattern with
let
If some_option_value was a None value, it would fail to match the pattern
Some(x), meaning the pattern is refutable. However, the let statement can
only accept an irrefutable pattern because there is nothing valid the code can
do with a None value. At compile time, Rust will complain that we’ve tried to
use a refutable pattern where an irrefutable pattern is required:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
error[E0005]: refutable pattern in local binding: `None` not covered
--> src/main.rs:3:9
|
3 | let Some(x) = some_option_value;
| ^^^^^^^ pattern `None` not covered
|
= note: `let` bindings require an "irrefutable pattern", like a `struct` or an `enum` with only one variant
= note: for more information, visit https://doc.rust-lang.org/book/ch18-02-refutability.html
note: `Option<i32>` defined here
--> /rustc/d5a82bbd26e1ad8b7401f6a718a9c57c96905483/library/core/src/option.rs:518:1
|
= note:
/rustc/d5a82bbd26e1ad8b7401f6a718a9c57c96905483/library/core/src/option.rs:522:5: not covered
= note: the matched value is of type `Option<i32>`
help: you might want to use `if let` to ignore the variant that isn't matched
|
3 | let x = if let Some(x) = some_option_value { x } else { todo!() };
| ++++++++++ ++++++++++++++++++++++
help: alternatively, you might want to use let else to handle the variant that isn't matched
|
3 | let Some(x) = some_option_value else { todo!() };
| ++++++++++++++++
For more information about this error, try `rustc --explain E0005`.
error: could not compile `patterns` due to previous error
Because we didn’t cover (and couldn’t cover!) every valid value with the
pattern Some(x), Rust rightfully produces a compiler error.
If we have a refutable pattern where an irrefutable pattern is needed, we can
fix it by changing the code that uses the pattern: instead of using let, we
can use if let. Then if the pattern doesn’t match, the code will just skip
the code in the curly brackets, giving it a way to continue validly. Listing
18-9 shows how to fix the code in Listing 18-8.
fn main() { let some_option_value: Option<i32> = None; if let Some(x) = some_option_value { println!("{}", x); } }
Listing 18-9: Using if let and a block with refutable
patterns instead of let
We’ve given the code an out! This code is perfectly valid, although it means we
cannot use an irrefutable pattern without receiving an error. If we give if let a pattern that will always match, such as x, as shown in Listing 18-10,
the compiler will give a warning.
fn main() { if let x = 5 { println!("{}", x); }; }
Listing 18-10: Attempting to use an irrefutable pattern
with if let
Rust complains that it doesn’t make sense to use if let with an irrefutable
pattern:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
warning: irrefutable `if let` pattern
--> src/main.rs:2:8
|
2 | if let x = 5 {
| ^^^^^^^^^
|
= note: this pattern will always match, so the `if let` is useless
= help: consider replacing the `if let` with a `let`
= note: `#[warn(irrefutable_let_patterns)]` on by default
warning: `patterns` (bin "patterns") generated 1 warning
Finished dev [unoptimized + debuginfo] target(s) in 0.39s
Running `target/debug/patterns`
5
For this reason, match arms must use refutable patterns, except for the last
arm, which should match any remaining values with an irrefutable pattern. Rust
allows us to use an irrefutable pattern in a match with only one arm, but
this syntax isn’t particularly useful and could be replaced with a simpler
let statement.
Now that you know where to use patterns and the difference between refutable and irrefutable patterns, let’s cover all the syntax we can use to create patterns.
Pattern Syntax
In this section, we gather all the syntax valid in patterns and discuss why and when you might want to use each one.
Matching Literals
As you saw in Chapter 6, you can match patterns against literals directly. The following code gives some examples:
fn main() { let x = 1; match x { 1 => println!("one"), 2 => println!("two"), 3 => println!("three"), _ => println!("anything"), } }
This code prints one because the value in x is 1. This syntax is useful
when you want your code to take an action if it gets a particular concrete
value.
Matching Named Variables
Named variables are irrefutable patterns that match any value, and we’ve used
them many times in the book. However, there is a complication when you use
named variables in match expressions. Because match starts a new scope,
variables declared as part of a pattern inside the match expression will
shadow those with the same name outside the match construct, as is the case
with all variables. In Listing 18-11, we declare a variable named x with the
value Some(5) and a variable y with the value 10. We then create a
match expression on the value x. Look at the patterns in the match arms and
println! at the end, and try to figure out what the code will print before
running this code or reading further.
Filename: src/main.rs
fn main() { let x = Some(5); let y = 10; match x { Some(50) => println!("Got 50"), Some(y) => println!("Matched, y = {y}"), _ => println!("Default case, x = {:?}", x), } println!("at the end: x = {:?}, y = {y}", x); }
Listing 18-11: A match expression with an arm that
introduces a shadowed variable y
Let’s walk through what happens when the match expression runs. The pattern
in the first match arm doesn’t match the defined value of x, so the code
continues.
The pattern in the second match arm introduces a new variable named y that
will match any value inside a Some value. Because we’re in a new scope inside
the match expression, this is a new y variable, not the y we declared at
the beginning with the value 10. This new y binding will match any value
inside a Some, which is what we have in x. Therefore, this new y binds to
the inner value of the Some in x. That value is 5, so the expression for
that arm executes and prints Matched, y = 5.
If x had been a None value instead of Some(5), the patterns in the first
two arms wouldn’t have matched, so the value would have matched to the
underscore. We didn’t introduce the x variable in the pattern of the
underscore arm, so the x in the expression is still the outer x that hasn’t
been shadowed. In this hypothetical case, the match would print Default case, x = None.
When the match expression is done, its scope ends, and so does the scope of
the inner y. The last println! produces at the end: x = Some(5), y = 10.
To create a match expression that compares the values of the outer x and
y, rather than introducing a shadowed variable, we would need to use a match
guard conditional instead. We’ll talk about match guards later in the “Extra
Conditionals with Match Guards” section.
Multiple Patterns
In match expressions, you can match multiple patterns using the | syntax,
which is the pattern or operator. For example, in the following code we match
the value of x against the match arms, the first of which has an or option,
meaning if the value of x matches either of the values in that arm, that
arm’s code will run:
fn main() { let x = 1; match x { 1 | 2 => println!("one or two"), 3 => println!("three"), _ => println!("anything"), } }
This code prints one or two.
Matching Ranges of Values with ..=
The ..= syntax allows us to match to an inclusive range of values. In the
following code, when a pattern matches any of the values within the given
range, that arm will execute:
fn main() { let x = 5; match x { 1..=5 => println!("one through five"), _ => println!("something else"), } }
If x is 1, 2, 3, 4, or 5, the first arm will match. This syntax is more
convenient for multiple match values than using the | operator to express the
same idea; if we were to use | we would have to specify 1 | 2 | 3 | 4 | 5.
Specifying a range is much shorter, especially if we want to match, say, any
number between 1 and 1,000!
The compiler checks that the range isn’t empty at compile time, and because the
only types for which Rust can tell if a range is empty or not are char and
numeric values, ranges are only allowed with numeric or char values.
Here is an example using ranges of char values:
fn main() { let x = 'c'; match x { 'a'..='j' => println!("early ASCII letter"), 'k'..='z' => println!("late ASCII letter"), _ => println!("something else"), } }
Rust can tell that 'c' is within the first pattern’s range and prints early ASCII letter.
Destructuring to Break Apart Values
We can also use patterns to destructure structs, enums, and tuples to use different parts of these values. Let’s walk through each value.
Destructuring Structs
Listing 18-12 shows a Point struct with two fields, x and y, that we can
break apart using a pattern with a let statement.
Filename: src/main.rs
struct Point { x: i32, y: i32, } fn main() { let p = Point { x: 0, y: 7 }; let Point { x: a, y: b } = p; assert_eq!(0, a); assert_eq!(7, b); }
Listing 18-12: Destructuring a struct’s fields into separate variables
This code creates the variables a and b that match the values of the x
and y fields of the p struct. This example shows that the names of the
variables in the pattern don’t have to match the field names of the struct.
However, it’s common to match the variable names to the field names to make it
easier to remember which variables came from which fields. Because of this
common usage, and because writing let Point { x: x, y: y } = p; contains a
lot of duplication, Rust has a shorthand for patterns that match struct fields:
you only need to list the name of the struct field, and the variables created
from the pattern will have the same names. Listing 18-13 behaves in the same
way as the code in Listing 18-12, but the variables created in the let
pattern are x and y instead of a and b.
Filename: src/main.rs
struct Point { x: i32, y: i32, } fn main() { let p = Point { x: 0, y: 7 }; let Point { x, y } = p; assert_eq!(0, x); assert_eq!(7, y); }
Listing 18-13: Destructuring struct fields using struct field shorthand
This code creates the variables x and y that match the x and y fields
of the p variable. The outcome is that the variables x and y contain the
values from the p struct.
We can also destructure with literal values as part of the struct pattern rather than creating variables for all the fields. Doing so allows us to test some of the fields for particular values while creating variables to destructure the other fields.
In Listing 18-14, we have a match expression that separates Point values
into three cases: points that lie directly on the x axis (which is true when
y = 0), on the y axis (x = 0), or neither.
Filename: src/main.rs
struct Point { x: i32, y: i32, } fn main() { let p = Point { x: 0, y: 7 }; match p { Point { x, y: 0 } => println!("On the x axis at {x}"), Point { x: 0, y } => println!("On the y axis at {y}"), Point { x, y } => { println!("On neither axis: ({x}, {y})"); } } }
Listing 18-14: Destructuring and matching literal values in one pattern
The first arm will match any point that lies on the x axis by specifying that
the y field matches if its value matches the literal 0. The pattern still
creates an x variable that we can use in the code for this arm.
Similarly, the second arm matches any point on the y axis by specifying that
the x field matches if its value is 0 and creates a variable y for the
value of the y field. The third arm doesn’t specify any literals, so it
matches any other Point and creates variables for both the x and y fields.
In this example, the value p matches the second arm by virtue of x
containing a 0, so this code will print On the y axis at 7.
Remember that a match expression stops checking arms once it has found the
first matching pattern, so even though Point { x: 0, y: 0} is on the x axis
and the y axis, this code would only print On the x axis at 0.
Destructuring Enums
We've destructured enums in this book (for example, Listing 6-5 in Chapter 6),
but haven’t yet explicitly discussed that the pattern to destructure an enum
corresponds to the way the data stored within the enum is defined. As an
example, in Listing 18-15 we use the Message enum from Listing 6-2 and write
a match with patterns that will destructure each inner value.
Filename: src/main.rs
enum Message { Quit, Move { x: i32, y: i32 }, Write(String), ChangeColor(i32, i32, i32), } fn main() { let msg = Message::ChangeColor(0, 160, 255); match msg { Message::Quit => { println!("The Quit variant has no data to destructure."); } Message::Move { x, y } => { println!("Move in the x direction {x} and in the y direction {y}"); } Message::Write(text) => { println!("Text message: {text}"); } Message::ChangeColor(r, g, b) => { println!("Change the color to red {r}, green {g}, and blue {b}",) } } }
Listing 18-15: Destructuring enum variants that hold different kinds of values
This code will print Change the color to red 0, green 160, and blue 255. Try
changing the value of msg to see the code from the other arms run.
For enum variants without any data, like Message::Quit, we can’t destructure
the value any further. We can only match on the literal Message::Quit value,
and no variables are in that pattern.
For struct-like enum variants, such as Message::Move, we can use a pattern
similar to the pattern we specify to match structs. After the variant name, we
place curly brackets and then list the fields with variables so we break apart
the pieces to use in the code for this arm. Here we use the shorthand form as
we did in Listing 18-13.
For tuple-like enum variants, like Message::Write that holds a tuple with one
element and Message::ChangeColor that holds a tuple with three elements, the
pattern is similar to the pattern we specify to match tuples. The number of
variables in the pattern must match the number of elements in the variant we’re
matching.
Destructuring Nested Structs and Enums
So far, our examples have all been matching structs or enums one level deep,
but matching can work on nested items too! For example, we can refactor the
code in Listing 18-15 to support RGB and HSV colors in the ChangeColor
message, as shown in Listing 18-16.
enum Color { Rgb(i32, i32, i32), Hsv(i32, i32, i32), } enum Message { Quit, Move { x: i32, y: i32 }, Write(String), ChangeColor(Color), } fn main() { let msg = Message::ChangeColor(Color::Hsv(0, 160, 255)); match msg { Message::ChangeColor(Color::Rgb(r, g, b)) => { println!("Change color to red {r}, green {g}, and blue {b}"); } Message::ChangeColor(Color::Hsv(h, s, v)) => { println!("Change color to hue {h}, saturation {s}, value {v}") } _ => (), } }
Listing 18-16: Matching on nested enums
The pattern of the first arm in the match expression matches a
Message::ChangeColor enum variant that contains a Color::Rgb variant; then
the pattern binds to the three inner i32 values. The pattern of the second
arm also matches a Message::ChangeColor enum variant, but the inner enum
matches Color::Hsv instead. We can specify these complex conditions in one
match expression, even though two enums are involved.
Destructuring Structs and Tuples
We can mix, match, and nest destructuring patterns in even more complex ways. The following example shows a complicated destructure where we nest structs and tuples inside a tuple and destructure all the primitive values out:
fn main() { struct Point { x: i32, y: i32, } let ((feet, inches), Point { x, y }) = ((3, 10), Point { x: 3, y: -10 }); }
This code lets us break complex types into their component parts so we can use the values we’re interested in separately.
Destructuring with patterns is a convenient way to use pieces of values, such as the value from each field in a struct, separately from each other.
Ignoring Values in a Pattern
You’ve seen that it’s sometimes useful to ignore values in a pattern, such as
in the last arm of a match, to get a catchall that doesn’t actually do
anything but does account for all remaining possible values. There are a few
ways to ignore entire values or parts of values in a pattern: using the _
pattern (which you’ve seen), using the _ pattern within another pattern,
using a name that starts with an underscore, or using .. to ignore remaining
parts of a value. Let’s explore how and why to use each of these patterns.
Ignoring an Entire Value with _
We’ve used the underscore as a wildcard pattern that will match any value but
not bind to the value. This is especially useful as the last arm in a match
expression, but we can also use it in any pattern, including function
parameters, as shown in Listing 18-17.
Filename: src/main.rs
fn foo(_: i32, y: i32) { println!("This code only uses the y parameter: {}", y); } fn main() { foo(3, 4); }
Listing 18-17: Using _ in a function signature
This code will completely ignore the value 3 passed as the first argument,
and will print This code only uses the y parameter: 4.
In most cases when you no longer need a particular function parameter, you would change the signature so it doesn’t include the unused parameter. Ignoring a function parameter can be especially useful in cases when, for example, you're implementing a trait when you need a certain type signature but the function body in your implementation doesn’t need one of the parameters. You then avoid getting a compiler warning about unused function parameters, as you would if you used a name instead.
Ignoring Parts of a Value with a Nested _
We can also use _ inside another pattern to ignore just part of a value, for
example, when we want to test for only part of a value but have no use for the
other parts in the corresponding code we want to run. Listing 18-18 shows code
responsible for managing a setting’s value. The business requirements are that
the user should not be allowed to overwrite an existing customization of a
setting but can unset the setting and give it a value if it is currently unset.
fn main() { let mut setting_value = Some(5); let new_setting_value = Some(10); match (setting_value, new_setting_value) { (Some(_), Some(_)) => { println!("Can't overwrite an existing customized value"); } _ => { setting_value = new_setting_value; } } println!("setting is {:?}", setting_value); }
Listing 18-18: Using an underscore within patterns that
match Some variants when we don’t need to use the value inside the
Some
This code will print Can't overwrite an existing customized value and then
setting is Some(5). In the first match arm, we don’t need to match on or use
the values inside either Some variant, but we do need to test for the case
when setting_value and new_setting_value are the Some variant. In that
case, we print the reason for not changing setting_value, and it doesn’t get
changed.
In all other cases (if either setting_value or new_setting_value are
None) expressed by the _ pattern in the second arm, we want to allow
new_setting_value to become setting_value.
We can also use underscores in multiple places within one pattern to ignore particular values. Listing 18-19 shows an example of ignoring the second and fourth values in a tuple of five items.
fn main() { let numbers = (2, 4, 8, 16, 32); match numbers { (first, _, third, _, fifth) => { println!("Some numbers: {first}, {third}, {fifth}") } } }
Listing 18-19: Ignoring multiple parts of a tuple
This code will print Some numbers: 2, 8, 32, and the values 4 and 16 will be
ignored.
Ignoring an Unused Variable by Starting Its Name with _
If you create a variable but don’t use it anywhere, Rust will usually issue a warning because an unused variable could be a bug. However, sometimes it’s useful to be able to create a variable you won’t use yet, such as when you’re prototyping or just starting a project. In this situation, you can tell Rust not to warn you about the unused variable by starting the name of the variable with an underscore. In Listing 18-20, we create two unused variables, but when we compile this code, we should only get a warning about one of them.
Filename: src/main.rs
fn main() { let _x = 5; let y = 10; }
Listing 18-20: Starting a variable name with an underscore to avoid getting unused variable warnings
Here we get a warning about not using the variable y, but we don’t get a
warning about not using _x.
Note that there is a subtle difference between using only _ and using a name
that starts with an underscore. The syntax _x still binds the value to the
variable, whereas _ doesn’t bind at all. To show a case where this
distinction matters, Listing 18-21 will provide us with an error.
fn main() {
let s = Some(String::from("Hello!"));
if let Some(_s) = s {
println!("found a string");
}
println!("{:?}", s);
}Listing 18-21: An unused variable starting with an underscore still binds the value, which might take ownership of the value
We’ll receive an error because the s value will still be moved into _s,
which prevents us from using s again. However, using the underscore by itself
doesn’t ever bind to the value. Listing 18-22 will compile without any errors
because s doesn’t get moved into _.
fn main() { let s = Some(String::from("Hello!")); if let Some(_) = s { println!("found a string"); } println!("{:?}", s); }
Listing 18-22: Using an underscore does not bind the value
This code works just fine because we never bind s to anything; it isn’t moved.
Ignoring Remaining Parts of a Value with ..
With values that have many parts, we can use the .. syntax to use specific
parts and ignore the rest, avoiding the need to list underscores for each
ignored value. The .. pattern ignores any parts of a value that we haven’t
explicitly matched in the rest of the pattern. In Listing 18-23, we have a
Point struct that holds a coordinate in three-dimensional space. In the
match expression, we want to operate only on the x coordinate and ignore
the values in the y and z fields.
fn main() { struct Point { x: i32, y: i32, z: i32, } let origin = Point { x: 0, y: 0, z: 0 }; match origin { Point { x, .. } => println!("x is {}", x), } }
Listing 18-23: Ignoring all fields of a Point except
for x by using ..
We list the x value and then just include the .. pattern. This is quicker
than having to list y: _ and z: _, particularly when we’re working with
structs that have lots of fields in situations where only one or two fields are
relevant.
The syntax .. will expand to as many values as it needs to be. Listing 18-24
shows how to use .. with a tuple.
Filename: src/main.rs
fn main() { let numbers = (2, 4, 8, 16, 32); match numbers { (first, .., last) => { println!("Some numbers: {first}, {last}"); } } }
Listing 18-24: Matching only the first and last values in a tuple and ignoring all other values
In this code, the first and last value are matched with first and last. The
.. will match and ignore everything in the middle.
However, using .. must be unambiguous. If it is unclear which values are
intended for matching and which should be ignored, Rust will give us an error.
Listing 18-25 shows an example of using .. ambiguously, so it will not
compile.
Filename: src/main.rs
fn main() {
let numbers = (2, 4, 8, 16, 32);
match numbers {
(.., second, ..) => {
println!("Some numbers: {}", second)
},
}
}Listing 18-25: An attempt to use .. in an ambiguous
way
When we compile this example, we get this error:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
error: `..` can only be used once per tuple pattern
--> src/main.rs:5:22
|
5 | (.., second, ..) => {
| -- ^^ can only be used once per tuple pattern
| |
| previously used here
error: could not compile `patterns` due to previous error
It’s impossible for Rust to determine how many values in the tuple to ignore
before matching a value with second and then how many further values to
ignore thereafter. This code could mean that we want to ignore 2, bind
second to 4, and then ignore 8, 16, and 32; or that we want to ignore
2 and 4, bind second to 8, and then ignore 16 and 32; and so forth.
The variable name second doesn’t mean anything special to Rust, so we get a
compiler error because using .. in two places like this is ambiguous.
Extra Conditionals with Match Guards
A match guard is an additional if condition, specified after the pattern in
a match arm, that must also match for that arm to be chosen. Match guards are
useful for expressing more complex ideas than a pattern alone allows.
The condition can use variables created in the pattern. Listing 18-26 shows a
match where the first arm has the pattern Some(x) and also has a match
guard of if x % 2 == 0 (which will be true if the number is even).
fn main() { let num = Some(4); match num { Some(x) if x % 2 == 0 => println!("The number {} is even", x), Some(x) => println!("The number {} is odd", x), None => (), } }
Listing 18-26: Adding a match guard to a pattern
This example will print The number 4 is even. When num is compared to the
pattern in the first arm, it matches, because Some(4) matches Some(x). Then
the match guard checks whether the remainder of dividing x by 2 is equal to
0, and because it is, the first arm is selected.
If num had been Some(5) instead, the match guard in the first arm would
have been false because the remainder of 5 divided by 2 is 1, which is not
equal to 0. Rust would then go to the second arm, which would match because the
second arm doesn’t have a match guard and therefore matches any Some variant.
There is no way to express the if x % 2 == 0 condition within a pattern, so
the match guard gives us the ability to express this logic. The downside of
this additional expressiveness is that the compiler doesn't try to check for
exhaustiveness when match guard expressions are involved.
In Listing 18-11, we mentioned that we could use match guards to solve our
pattern-shadowing problem. Recall that we created a new variable inside the
pattern in the match expression instead of using the variable outside the
match. That new variable meant we couldn’t test against the value of the
outer variable. Listing 18-27 shows how we can use a match guard to fix this
problem.
Filename: src/main.rs
fn main() { let x = Some(5); let y = 10; match x { Some(50) => println!("Got 50"), Some(n) if n == y => println!("Matched, n = {n}"), _ => println!("Default case, x = {:?}", x), } println!("at the end: x = {:?}, y = {y}", x); }
Listing 18-27: Using a match guard to test for equality with an outer variable
This code will now print Default case, x = Some(5). The pattern in the second
match arm doesn’t introduce a new variable y that would shadow the outer y,
meaning we can use the outer y in the match guard. Instead of specifying the
pattern as Some(y), which would have shadowed the outer y, we specify
Some(n). This creates a new variable n that doesn’t shadow anything because
there is no n variable outside the match.
The match guard if n == y is not a pattern and therefore doesn’t introduce
new variables. This y is the outer y rather than a new shadowed y, and
we can look for a value that has the same value as the outer y by comparing
n to y.
You can also use the or operator | in a match guard to specify multiple
patterns; the match guard condition will apply to all the patterns. Listing
18-28 shows the precedence when combining a pattern that uses | with a match
guard. The important part of this example is that the if y match guard
applies to 4, 5, and 6, even though it might look like if y only
applies to 6.
fn main() { let x = 4; let y = false; match x { 4 | 5 | 6 if y => println!("yes"), _ => println!("no"), } }
Listing 18-28: Combining multiple patterns with a match guard
The match condition states that the arm only matches if the value of x is
equal to 4, 5, or 6 and if y is true. When this code runs, the
pattern of the first arm matches because x is 4, but the match guard if y
is false, so the first arm is not chosen. The code moves on to the second arm,
which does match, and this program prints no. The reason is that the if
condition applies to the whole pattern 4 | 5 | 6, not only to the last value
6. In other words, the precedence of a match guard in relation to a pattern
behaves like this:
(4 | 5 | 6) if y => ...
rather than this:
4 | 5 | (6 if y) => ...
After running the code, the precedence behavior is evident: if the match guard
were applied only to the final value in the list of values specified using the
| operator, the arm would have matched and the program would have printed
yes.
@ Bindings
The at operator @ lets us create a variable that holds a value at the same
time as we’re testing that value for a pattern match. In Listing 18-29, we want
to test that a Message::Hello id field is within the range 3..=7. We also
want to bind the value to the variable id_variable so we can use it in the
code associated with the arm. We could name this variable id, the same as the
field, but for this example we’ll use a different name.
fn main() { enum Message { Hello { id: i32 }, } let msg = Message::Hello { id: 5 }; match msg { Message::Hello { id: id_variable @ 3..=7, } => println!("Found an id in range: {}", id_variable), Message::Hello { id: 10..=12 } => { println!("Found an id in another range") } Message::Hello { id } => println!("Found some other id: {}", id), } }
Listing 18-29: Using @ to bind to a value in a pattern
while also testing it
This example will print Found an id in range: 5. By specifying id_variable @ before the range 3..=7, we’re capturing whatever value matched the range
while also testing that the value matched the range pattern.
In the second arm, where we only have a range specified in the pattern, the code
associated with the arm doesn’t have a variable that contains the actual value
of the id field. The id field’s value could have been 10, 11, or 12, but
the code that goes with that pattern doesn’t know which it is. The pattern code
isn’t able to use the value from the id field, because we haven’t saved the
id value in a variable.
In the last arm, where we’ve specified a variable without a range, we do have
the value available to use in the arm’s code in a variable named id. The
reason is that we’ve used the struct field shorthand syntax. But we haven’t
applied any test to the value in the id field in this arm, as we did with the
first two arms: any value would match this pattern.
Using @ lets us test a value and save it in a variable within one pattern.
Summary
Rust’s patterns are very useful in distinguishing between different kinds of
data. When used in match expressions, Rust ensures your patterns cover every
possible value, or your program won’t compile. Patterns in let statements and
function parameters make those constructs more useful, enabling the
destructuring of values into smaller parts at the same time as assigning to
variables. We can create simple or complex patterns to suit our needs.
Next, for the penultimate chapter of the book, we’ll look at some advanced aspects of a variety of Rust’s features.
Kengaytirilgan xususiyatlar
Hozirgacha Rust dasturlash tilining eng ko'p qo'llaniladigan qismlarini o'rgandingiz. 20-bobda yana bir loyihani amalga oshirishimizdan oldin, siz vaqti-vaqti bilan duch kelishingiz mumkin bo'lgan, lekin har doim ham ishlatilmaydigan Rust xususiyatlari haqida gaplashamiz. Qachondir tushunmovchiliklarga duch kelganingizda, ushbu bobdan qo'llanma sifatida foydalanishingiz mumkin. Bu yerda ko'rib chiqiladigan xususiyatlar, funksiyalar faqat muayyan vaziyatlardagina foydali bo'ladi. Garchi bu funksiyalarga tez-tez murojaat qilmasligingiz mumkin bo‘lsa-da, Rust tili taklif qiladigan barcha imkoniyatlarni tushunib olishingizni istaymiz.
Ushbu bobda biz quyidagilarni ko'rib chiqamiz:
-
Xavfsiz bo‘lmagan (Unsafe) Rust: Rustning ayrim kafolatlaridan qanday qilib voz kechish va bu kafolatlarni qo‘lda, ya’ni o‘zingiz mustaqil tarzda boshqarish mas’uliyatini qanday olishni ko‘rib chiqamiz.
-
Kengaytirilgan traitlar: bog‘langan turlar (associated types), standart tur parametrlari (default type parameters), to‘liq aniqlangan sintaksis (fully qualified syntax), supertraitlar (supertraits) va newtype namunasi (newtype pattern).
-
Kengaytirilgan turlar: newtype namunasi (newtype pattern), tur aliaslari (type aliases), hech qachon yuz bermaydigan tur (the never type — !) va dinamik o'lchamdagi turlar (dynamically sized types)
-
Kengaytirilgan funksiyalar va yopiq funksiyalar (Closures): funksiya ko'rsatkichlari (function pointers) va closure qaytaradigan funksiyalar (returning closures)
-
Andozalar (Macros): kodni jamlash (kompilyatsiya) vaqtida boshqa kodni aniqlovchi kodni yozish usullari.
Bu — har bir dasturchi uchun foydali bo'lgan Rust imkoniyatlarining to‘liq to‘plamidir! Keling, to'plamga sho'ng'iymiz!
Unsafe Rust
All the code we’ve discussed so far has had Rust’s memory safety guarantees enforced at compile time. However, Rust has a second language hidden inside it that doesn’t enforce these memory safety guarantees: it’s called unsafe Rust and works just like regular Rust, but gives us extra superpowers.
Unsafe Rust exists because, by nature, static analysis is conservative. When the compiler tries to determine whether or not code upholds the guarantees, it’s better for it to reject some valid programs than to accept some invalid programs. Although the code might be okay, if the Rust compiler doesn’t have enough information to be confident, it will reject the code. In these cases, you can use unsafe code to tell the compiler, “Trust me, I know what I’m doing.” Be warned, however, that you use unsafe Rust at your own risk: if you use unsafe code incorrectly, problems can occur due to memory unsafety, such as null pointer dereferencing.
Another reason Rust has an unsafe alter ego is that the underlying computer hardware is inherently unsafe. If Rust didn’t let you do unsafe operations, you couldn’t do certain tasks. Rust needs to allow you to do low-level systems programming, such as directly interacting with the operating system or even writing your own operating system. Working with low-level systems programming is one of the goals of the language. Let’s explore what we can do with unsafe Rust and how to do it.
Unsafe Superpowers
To switch to unsafe Rust, use the unsafe keyword and then start a new block
that holds the unsafe code. You can take five actions in unsafe Rust that you
can’t in safe Rust, which we call unsafe superpowers. Those superpowers
include the ability to:
- Dereference a raw pointer
- Call an unsafe function or method
- Access or modify a mutable static variable
- Implement an unsafe trait
- Access fields of
unions
It’s important to understand that unsafe doesn’t turn off the borrow checker
or disable any other of Rust’s safety checks: if you use a reference in unsafe
code, it will still be checked. The unsafe keyword only gives you access to
these five features that are then not checked by the compiler for memory
safety. You’ll still get some degree of safety inside of an unsafe block.
In addition, unsafe does not mean the code inside the block is necessarily
dangerous or that it will definitely have memory safety problems: the intent is
that as the programmer, you’ll ensure the code inside an unsafe block will
access memory in a valid way.
People are fallible, and mistakes will happen, but by requiring these five
unsafe operations to be inside blocks annotated with unsafe you’ll know that
any errors related to memory safety must be within an unsafe block. Keep
unsafe blocks small; you’ll be thankful later when you investigate memory
bugs.
To isolate unsafe code as much as possible, it’s best to enclose unsafe code
within a safe abstraction and provide a safe API, which we’ll discuss later in
the chapter when we examine unsafe functions and methods. Parts of the standard
library are implemented as safe abstractions over unsafe code that has been
audited. Wrapping unsafe code in a safe abstraction prevents uses of unsafe
from leaking out into all the places that you or your users might want to use
the functionality implemented with unsafe code, because using a safe
abstraction is safe.
Let’s look at each of the five unsafe superpowers in turn. We’ll also look at some abstractions that provide a safe interface to unsafe code.
Dereferencing a Raw Pointer
In Chapter 4, in the “Dangling References” section, we mentioned that the compiler ensures references are always
valid. Unsafe Rust has two new types called raw pointers that are similar to
references. As with references, raw pointers can be immutable or mutable and
are written as *const T and *mut T, respectively. The asterisk isn’t the
dereference operator; it’s part of the type name. In the context of raw
pointers, immutable means that the pointer can’t be directly assigned to
after being dereferenced.
Different from references and smart pointers, raw pointers:
- Are allowed to ignore the borrowing rules by having both immutable and mutable pointers or multiple mutable pointers to the same location
- Aren’t guaranteed to point to valid memory
- Are allowed to be null
- Don’t implement any automatic cleanup
By opting out of having Rust enforce these guarantees, you can give up guaranteed safety in exchange for greater performance or the ability to interface with another language or hardware where Rust’s guarantees don’t apply.
Listing 19-1 shows how to create an immutable and a mutable raw pointer from references.
fn main() { let mut num = 5; let r1 = &num as *const i32; let r2 = &mut num as *mut i32; }
Listing 19-1: Creating raw pointers from references
Notice that we don’t include the unsafe keyword in this code. We can create
raw pointers in safe code; we just can’t dereference raw pointers outside an
unsafe block, as you’ll see in a bit.
We’ve created raw pointers by using as to cast an immutable and a mutable
reference into their corresponding raw pointer types. Because we created them
directly from references guaranteed to be valid, we know these particular raw
pointers are valid, but we can’t make that assumption about just any raw
pointer.
To demonstrate this, next we’ll create a raw pointer whose validity we can’t be so certain of. Listing 19-2 shows how to create a raw pointer to an arbitrary location in memory. Trying to use arbitrary memory is undefined: there might be data at that address or there might not, the compiler might optimize the code so there is no memory access, or the program might error with a segmentation fault. Usually, there is no good reason to write code like this, but it is possible.
fn main() { let address = 0x012345usize; let r = address as *const i32; }
Listing 19-2: Creating a raw pointer to an arbitrary memory address
Recall that we can create raw pointers in safe code, but we can’t dereference
raw pointers and read the data being pointed to. In Listing 19-3, we use the
dereference operator * on a raw pointer that requires an unsafe block.
fn main() { let mut num = 5; let r1 = &num as *const i32; let r2 = &mut num as *mut i32; unsafe { println!("r1 is: {}", *r1); println!("r2 is: {}", *r2); } }
Listing 19-3: Dereferencing raw pointers within an
unsafe block
Creating a pointer does no harm; it’s only when we try to access the value that it points at that we might end up dealing with an invalid value.
Note also that in Listing 19-1 and 19-3, we created *const i32 and *mut i32
raw pointers that both pointed to the same memory location, where num is
stored. If we instead tried to create an immutable and a mutable reference to
num, the code would not have compiled because Rust’s ownership rules don’t
allow a mutable reference at the same time as any immutable references. With
raw pointers, we can create a mutable pointer and an immutable pointer to the
same location and change data through the mutable pointer, potentially creating
a data race. Be careful!
With all of these dangers, why would you ever use raw pointers? One major use case is when interfacing with C code, as you’ll see in the next section, “Calling an Unsafe Function or Method.” Another case is when building up safe abstractions that the borrow checker doesn’t understand. We’ll introduce unsafe functions and then look at an example of a safe abstraction that uses unsafe code.
Calling an Unsafe Function or Method
The second type of operation you can perform in an unsafe block is calling
unsafe functions. Unsafe functions and methods look exactly like regular
functions and methods, but they have an extra unsafe before the rest of the
definition. The unsafe keyword in this context indicates the function has
requirements we need to uphold when we call this function, because Rust can’t
guarantee we’ve met these requirements. By calling an unsafe function within an
unsafe block, we’re saying that we’ve read this function’s documentation and
take responsibility for upholding the function’s contracts.
Here is an unsafe function named dangerous that doesn’t do anything in its
body:
fn main() { unsafe fn dangerous() {} unsafe { dangerous(); } }
We must call the dangerous function within a separate unsafe block. If we
try to call dangerous without the unsafe block, we’ll get an error:
$ cargo run
Compiling unsafe-example v0.1.0 (file:///projects/unsafe-example)
error[E0133]: call to unsafe function is unsafe and requires unsafe function or block
--> src/main.rs:4:5
|
4 | dangerous();
| ^^^^^^^^^^^ call to unsafe function
|
= note: consult the function's documentation for information on how to avoid undefined behavior
For more information about this error, try `rustc --explain E0133`.
error: could not compile `unsafe-example` due to previous error
With the unsafe block, we’re asserting to Rust that we’ve read the function’s
documentation, we understand how to use it properly, and we’ve verified that
we’re fulfilling the contract of the function.
Bodies of unsafe functions are effectively unsafe blocks, so to perform other
unsafe operations within an unsafe function, we don’t need to add another
unsafe block.
Creating a Safe Abstraction over Unsafe Code
Just because a function contains unsafe code doesn’t mean we need to mark the
entire function as unsafe. In fact, wrapping unsafe code in a safe function is
a common abstraction. As an example, let’s study the split_at_mut function
from the standard library, which requires some unsafe code. We’ll explore how
we might implement it. This safe method is defined on mutable slices: it takes
one slice and makes it two by splitting the slice at the index given as an
argument. Listing 19-4 shows how to use split_at_mut.
fn main() { let mut v = vec![1, 2, 3, 4, 5, 6]; let r = &mut v[..]; let (a, b) = r.split_at_mut(3); assert_eq!(a, &mut [1, 2, 3]); assert_eq!(b, &mut [4, 5, 6]); }
Listing 19-4: Using the safe split_at_mut
function
We can’t implement this function using only safe Rust. An attempt might look
something like Listing 19-5, which won’t compile. For simplicity, we’ll
implement split_at_mut as a function rather than a method and only for slices
of i32 values rather than for a generic type T.
fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
let len = values.len();
assert!(mid <= len);
(&mut values[..mid], &mut values[mid..])
}
fn main() {
let mut vector = vec![1, 2, 3, 4, 5, 6];
let (left, right) = split_at_mut(&mut vector, 3);
}Listing 19-5: An attempted implementation of
split_at_mut using only safe Rust
This function first gets the total length of the slice. Then it asserts that the index given as a parameter is within the slice by checking whether it’s less than or equal to the length. The assertion means that if we pass an index that is greater than the length to split the slice at, the function will panic before it attempts to use that index.
Then we return two mutable slices in a tuple: one from the start of the
original slice to the mid index and another from mid to the end of the
slice.
When we try to compile the code in Listing 19-5, we’ll get an error.
$ cargo run
Compiling unsafe-example v0.1.0 (file:///projects/unsafe-example)
error[E0499]: cannot borrow `*values` as mutable more than once at a time
--> src/main.rs:6:31
|
1 | fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
| - let's call the lifetime of this reference `'1`
...
6 | (&mut values[..mid], &mut values[mid..])
| --------------------------^^^^^^--------
| | | |
| | | second mutable borrow occurs here
| | first mutable borrow occurs here
| returning this value requires that `*values` is borrowed for `'1`
For more information about this error, try `rustc --explain E0499`.
error: could not compile `unsafe-example` due to previous error
Rust’s borrow checker can’t understand that we’re borrowing different parts of the slice; it only knows that we’re borrowing from the same slice twice. Borrowing different parts of a slice is fundamentally okay because the two slices aren’t overlapping, but Rust isn’t smart enough to know this. When we know code is okay, but Rust doesn’t, it’s time to reach for unsafe code.
Listing 19-6 shows how to use an unsafe block, a raw pointer, and some calls
to unsafe functions to make the implementation of split_at_mut work.
use std::slice; fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) { let len = values.len(); let ptr = values.as_mut_ptr(); assert!(mid <= len); unsafe { ( slice::from_raw_parts_mut(ptr, mid), slice::from_raw_parts_mut(ptr.add(mid), len - mid), ) } } fn main() { let mut vector = vec![1, 2, 3, 4, 5, 6]; let (left, right) = split_at_mut(&mut vector, 3); }
Listing 19-6: Using unsafe code in the implementation of
the split_at_mut function
Recall from “The Slice Type” section in
Chapter 4 that slices are a pointer to some data and the length of the slice.
We use the len method to get the length of a slice and the as_mut_ptr
method to access the raw pointer of a slice. In this case, because we have a
mutable slice to i32 values, as_mut_ptr returns a raw pointer with the type
*mut i32, which we’ve stored in the variable ptr.
We keep the assertion that the mid index is within the slice. Then we get to
the unsafe code: the slice::from_raw_parts_mut function takes a raw pointer
and a length, and it creates a slice. We use this function to create a slice
that starts from ptr and is mid items long. Then we call the add
method on ptr with mid as an argument to get a raw pointer that starts at
mid, and we create a slice using that pointer and the remaining number of
items after mid as the length.
The function slice::from_raw_parts_mut is unsafe because it takes a raw
pointer and must trust that this pointer is valid. The add method on raw
pointers is also unsafe, because it must trust that the offset location is also
a valid pointer. Therefore, we had to put an unsafe block around our calls to
slice::from_raw_parts_mut and add so we could call them. By looking at
the code and by adding the assertion that mid must be less than or equal to
len, we can tell that all the raw pointers used within the unsafe block
will be valid pointers to data within the slice. This is an acceptable and
appropriate use of unsafe.
Note that we don’t need to mark the resulting split_at_mut function as
unsafe, and we can call this function from safe Rust. We’ve created a safe
abstraction to the unsafe code with an implementation of the function that uses
unsafe code in a safe way, because it creates only valid pointers from the
data this function has access to.
In contrast, the use of slice::from_raw_parts_mut in Listing 19-7 would
likely crash when the slice is used. This code takes an arbitrary memory
location and creates a slice 10,000 items long.
fn main() { use std::slice; let address = 0x01234usize; let r = address as *mut i32; let values: &[i32] = unsafe { slice::from_raw_parts_mut(r, 10000) }; }
Listing 19-7: Creating a slice from an arbitrary memory location
We don’t own the memory at this arbitrary location, and there is no guarantee
that the slice this code creates contains valid i32 values. Attempting to use
values as though it’s a valid slice results in undefined behavior.
Using extern Functions to Call External Code
Sometimes, your Rust code might need to interact with code written in another
language. For this, Rust has the keyword extern that facilitates the creation
and use of a Foreign Function Interface (FFI). An FFI is a way for a
programming language to define functions and enable a different (foreign)
programming language to call those functions.
Listing 19-8 demonstrates how to set up an integration with the abs function
from the C standard library. Functions declared within extern blocks are
always unsafe to call from Rust code. The reason is that other languages don’t
enforce Rust’s rules and guarantees, and Rust can’t check them, so
responsibility falls on the programmer to ensure safety.
Filename: src/main.rs
extern "C" { fn abs(input: i32) -> i32; } fn main() { unsafe { println!("Absolute value of -3 according to C: {}", abs(-3)); } }
Listing 19-8: Declaring and calling an extern function
defined in another language
Within the extern "C" block, we list the names and signatures of external
functions from another language we want to call. The "C" part defines which
application binary interface (ABI) the external function uses: the ABI
defines how to call the function at the assembly level. The "C" ABI is the
most common and follows the C programming language’s ABI.
Calling Rust Functions from Other Languages
We can also use
externto create an interface that allows other languages to call Rust functions. Instead of creating a wholeexternblock, we add theexternkeyword and specify the ABI to use just before thefnkeyword for the relevant function. We also need to add a#[no_mangle]annotation to tell the Rust compiler not to mangle the name of this function. Mangling is when a compiler changes the name we’ve given a function to a different name that contains more information for other parts of the compilation process to consume but is less human readable. Every programming language compiler mangles names slightly differently, so for a Rust function to be nameable by other languages, we must disable the Rust compiler’s name mangling.In the following example, we make the
call_from_cfunction accessible from C code, after it’s compiled to a shared library and linked from C:#![allow(unused)] fn main() { #[no_mangle] pub extern "C" fn call_from_c() { println!("Just called a Rust function from C!"); } }This usage of
externdoes not requireunsafe.
Accessing or Modifying a Mutable Static Variable
In this book, we’ve not yet talked about global variables, which Rust does support but can be problematic with Rust’s ownership rules. If two threads are accessing the same mutable global variable, it can cause a data race.
In Rust, global variables are called static variables. Listing 19-9 shows an example declaration and use of a static variable with a string slice as a value.
Filename: src/main.rs
static HELLO_WORLD: &str = "Hello, world!"; fn main() { println!("name is: {}", HELLO_WORLD); }
Listing 19-9: Defining and using an immutable static variable
Static variables are similar to constants, which we discussed in the
“Differences Between Variables and
Constants” section
in Chapter 3. The names of static variables are in SCREAMING_SNAKE_CASE by
convention. Static variables can only store references with the 'static
lifetime, which means the Rust compiler can figure out the lifetime and we
aren’t required to annotate it explicitly. Accessing an immutable static
variable is safe.
A subtle difference between constants and immutable static variables is that
values in a static variable have a fixed address in memory. Using the value
will always access the same data. Constants, on the other hand, are allowed to
duplicate their data whenever they’re used. Another difference is that static
variables can be mutable. Accessing and modifying mutable static variables is
unsafe. Listing 19-10 shows how to declare, access, and modify a mutable
static variable named COUNTER.
Filename: src/main.rs
static mut COUNTER: u32 = 0; fn add_to_count(inc: u32) { unsafe { COUNTER += inc; } } fn main() { add_to_count(3); unsafe { println!("COUNTER: {}", COUNTER); } }
Listing 19-10: Reading from or writing to a mutable static variable is unsafe
As with regular variables, we specify mutability using the mut keyword. Any
code that reads or writes from COUNTER must be within an unsafe block. This
code compiles and prints COUNTER: 3 as we would expect because it’s single
threaded. Having multiple threads access COUNTER would likely result in data
races.
With mutable data that is globally accessible, it’s difficult to ensure there are no data races, which is why Rust considers mutable static variables to be unsafe. Where possible, it’s preferable to use the concurrency techniques and thread-safe smart pointers we discussed in Chapter 16 so the compiler checks that data accessed from different threads is done safely.
Implementing an Unsafe Trait
We can use unsafe to implement an unsafe trait. A trait is unsafe when at
least one of its methods has some invariant that the compiler can’t verify. We
declare that a trait is unsafe by adding the unsafe keyword before trait
and marking the implementation of the trait as unsafe too, as shown in
Listing 19-11.
unsafe trait Foo { // methods go here } unsafe impl Foo for i32 { // method implementations go here } fn main() {}
Listing 19-11: Defining and implementing an unsafe trait
By using unsafe impl, we’re promising that we’ll uphold the invariants that
the compiler can’t verify.
As an example, recall the Sync and Send marker traits we discussed in the
“Extensible Concurrency with the Sync and Send
Traits”
section in Chapter 16: the compiler implements these traits automatically if
our types are composed entirely of Send and Sync types. If we implement a
type that contains a type that is not Send or Sync, such as raw pointers,
and we want to mark that type as Send or Sync, we must use unsafe. Rust
can’t verify that our type upholds the guarantees that it can be safely sent
across threads or accessed from multiple threads; therefore, we need to do
those checks manually and indicate as such with unsafe.
Accessing Fields of a Union
The final action that works only with unsafe is accessing fields of a
union. A union is similar to a struct, but only one declared field is
used in a particular instance at one time. Unions are primarily used to
interface with unions in C code. Accessing union fields is unsafe because Rust
can’t guarantee the type of the data currently being stored in the union
instance. You can learn more about unions in the Rust Reference.
When to Use Unsafe Code
Using unsafe to take one of the five actions (superpowers) just discussed
isn’t wrong or even frowned upon. But it is trickier to get unsafe code
correct because the compiler can’t help uphold memory safety. When you have a
reason to use unsafe code, you can do so, and having the explicit unsafe
annotation makes it easier to track down the source of problems when they occur.
Advanced Traits
We first covered traits in the “Traits: Defining Shared Behavior” section of Chapter 10, but we didn’t discuss the more advanced details. Now that you know more about Rust, we can get into the nitty-gritty.
Specifying Placeholder Types in Trait Definitions with Associated Types
Associated types connect a type placeholder with a trait such that the trait method definitions can use these placeholder types in their signatures. The implementor of a trait will specify the concrete type to be used instead of the placeholder type for the particular implementation. That way, we can define a trait that uses some types without needing to know exactly what those types are until the trait is implemented.
We’ve described most of the advanced features in this chapter as being rarely needed. Associated types are somewhere in the middle: they’re used more rarely than features explained in the rest of the book but more commonly than many of the other features discussed in this chapter.
One example of a trait with an associated type is the Iterator trait that the
standard library provides. The associated type is named Item and stands in
for the type of the values the type implementing the Iterator trait is
iterating over. The definition of the Iterator trait is as shown in Listing
19-12.
pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
}Listing 19-12: The definition of the Iterator trait
that has an associated type Item
The type Item is a placeholder, and the next method’s definition shows that
it will return values of type Option<Self::Item>. Implementors of the
Iterator trait will specify the concrete type for Item, and the next
method will return an Option containing a value of that concrete type.
Associated types might seem like a similar concept to generics, in that the
latter allow us to define a function without specifying what types it can
handle. To examine the difference between the two concepts, we’ll look at an
implementation of the Iterator trait on a type named Counter that specifies
the Item type is u32:
Filename: src/lib.rs
struct Counter {
count: u32,
}
impl Counter {
fn new() -> Counter {
Counter { count: 0 }
}
}
impl Iterator for Counter {
type Item = u32;
fn next(&mut self) -> Option<Self::Item> {
// --snip--
if self.count < 5 {
self.count += 1;
Some(self.count)
} else {
None
}
}
}This syntax seems comparable to that of generics. So why not just define the
Iterator trait with generics, as shown in Listing 19-13?
pub trait Iterator<T> {
fn next(&mut self) -> Option<T>;
}Listing 19-13: A hypothetical definition of the
Iterator trait using generics
The difference is that when using generics, as in Listing 19-13, we must
annotate the types in each implementation; because we can also implement
Iterator<String> for Counter or any other type, we could have multiple
implementations of Iterator for Counter. In other words, when a trait has a
generic parameter, it can be implemented for a type multiple times, changing
the concrete types of the generic type parameters each time. When we use the
next method on Counter, we would have to provide type annotations to
indicate which implementation of Iterator we want to use.
With associated types, we don’t need to annotate types because we can’t
implement a trait on a type multiple times. In Listing 19-12 with the
definition that uses associated types, we can only choose what the type of
Item will be once, because there can only be one impl Iterator for Counter.
We don’t have to specify that we want an iterator of u32 values everywhere
that we call next on Counter.
Associated types also become part of the trait’s contract: implementors of the trait must provide a type to stand in for the associated type placeholder. Associated types often have a name that describes how the type will be used, and documenting the associated type in the API documentation is good practice.
Default Generic Type Parameters and Operator Overloading
When we use generic type parameters, we can specify a default concrete type for
the generic type. This eliminates the need for implementors of the trait to
specify a concrete type if the default type works. You specify a default type
when declaring a generic type with the <PlaceholderType=ConcreteType> syntax.
A great example of a situation where this technique is useful is with operator
overloading, in which you customize the behavior of an operator (such as +)
in particular situations.
Rust doesn’t allow you to create your own operators or overload arbitrary
operators. But you can overload the operations and corresponding traits listed
in std::ops by implementing the traits associated with the operator. For
example, in Listing 19-14 we overload the + operator to add two Point
instances together. We do this by implementing the Add trait on a Point
struct:
Filename: src/main.rs
use std::ops::Add; #[derive(Debug, Copy, Clone, PartialEq)] struct Point { x: i32, y: i32, } impl Add for Point { type Output = Point; fn add(self, other: Point) -> Point { Point { x: self.x + other.x, y: self.y + other.y, } } } fn main() { assert_eq!( Point { x: 1, y: 0 } + Point { x: 2, y: 3 }, Point { x: 3, y: 3 } ); }
Listing 19-14: Implementing the Add trait to overload
the + operator for Point instances
The add method adds the x values of two Point instances and the y
values of two Point instances to create a new Point. The Add trait has an
associated type named Output that determines the type returned from the add
method.
The default generic type in this code is within the Add trait. Here is its
definition:
#![allow(unused)] fn main() { trait Add<Rhs=Self> { type Output; fn add(self, rhs: Rhs) -> Self::Output; } }
This code should look generally familiar: a trait with one method and an
associated type. The new part is Rhs=Self: this syntax is called default
type parameters. The Rhs generic type parameter (short for “right hand
side”) defines the type of the rhs parameter in the add method. If we don’t
specify a concrete type for Rhs when we implement the Add trait, the type
of Rhs will default to Self, which will be the type we’re implementing
Add on.
When we implemented Add for Point, we used the default for Rhs because we
wanted to add two Point instances. Let’s look at an example of implementing
the Add trait where we want to customize the Rhs type rather than using the
default.
We have two structs, Millimeters and Meters, holding values in different
units. This thin wrapping of an existing type in another struct is known as the
newtype pattern, which we describe in more detail in the “Using the Newtype
Pattern to Implement External Traits on External Types” section. We want to add values in millimeters to values in meters and have
the implementation of Add do the conversion correctly. We can implement Add
for Millimeters with Meters as the Rhs, as shown in Listing 19-15.
Filename: src/lib.rs
use std::ops::Add;
struct Millimeters(u32);
struct Meters(u32);
impl Add<Meters> for Millimeters {
type Output = Millimeters;
fn add(self, other: Meters) -> Millimeters {
Millimeters(self.0 + (other.0 * 1000))
}
}Listing 19-15: Implementing the Add trait on
Millimeters to add Millimeters to Meters
To add Millimeters and Meters, we specify impl Add<Meters> to set the
value of the Rhs type parameter instead of using the default of Self.
You’ll use default type parameters in two main ways:
- To extend a type without breaking existing code
- To allow customization in specific cases most users won’t need
The standard library’s Add trait is an example of the second purpose:
usually, you’ll add two like types, but the Add trait provides the ability to
customize beyond that. Using a default type parameter in the Add trait
definition means you don’t have to specify the extra parameter most of the
time. In other words, a bit of implementation boilerplate isn’t needed, making
it easier to use the trait.
The first purpose is similar to the second but in reverse: if you want to add a type parameter to an existing trait, you can give it a default to allow extension of the functionality of the trait without breaking the existing implementation code.
Fully Qualified Syntax for Disambiguation: Calling Methods with the Same Name
Nothing in Rust prevents a trait from having a method with the same name as another trait’s method, nor does Rust prevent you from implementing both traits on one type. It’s also possible to implement a method directly on the type with the same name as methods from traits.
When calling methods with the same name, you’ll need to tell Rust which one you
want to use. Consider the code in Listing 19-16 where we’ve defined two traits,
Pilot and Wizard, that both have a method called fly. We then implement
both traits on a type Human that already has a method named fly implemented
on it. Each fly method does something different.
Filename: src/main.rs
trait Pilot { fn fly(&self); } trait Wizard { fn fly(&self); } struct Human; impl Pilot for Human { fn fly(&self) { println!("This is your captain speaking."); } } impl Wizard for Human { fn fly(&self) { println!("Up!"); } } impl Human { fn fly(&self) { println!("*waving arms furiously*"); } } fn main() {}
Listing 19-16: Two traits are defined to have a fly
method and are implemented on the Human type, and a fly method is
implemented on Human directly
When we call fly on an instance of Human, the compiler defaults to calling
the method that is directly implemented on the type, as shown in Listing 19-17.
Filename: src/main.rs
trait Pilot { fn fly(&self); } trait Wizard { fn fly(&self); } struct Human; impl Pilot for Human { fn fly(&self) { println!("This is your captain speaking."); } } impl Wizard for Human { fn fly(&self) { println!("Up!"); } } impl Human { fn fly(&self) { println!("*waving arms furiously*"); } } fn main() { let person = Human; person.fly(); }
Listing 19-17: Calling fly on an instance of
Human
Running this code will print *waving arms furiously*, showing that Rust
called the fly method implemented on Human directly.
To call the fly methods from either the Pilot trait or the Wizard trait,
we need to use more explicit syntax to specify which fly method we mean.
Listing 19-18 demonstrates this syntax.
Filename: src/main.rs
trait Pilot { fn fly(&self); } trait Wizard { fn fly(&self); } struct Human; impl Pilot for Human { fn fly(&self) { println!("This is your captain speaking."); } } impl Wizard for Human { fn fly(&self) { println!("Up!"); } } impl Human { fn fly(&self) { println!("*waving arms furiously*"); } } fn main() { let person = Human; Pilot::fly(&person); Wizard::fly(&person); person.fly(); }
Listing 19-18: Specifying which trait’s fly method we
want to call
Specifying the trait name before the method name clarifies to Rust which
implementation of fly we want to call. We could also write
Human::fly(&person), which is equivalent to the person.fly() that we used
in Listing 19-18, but this is a bit longer to write if we don’t need to
disambiguate.
Running this code prints the following:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
Finished dev [unoptimized + debuginfo] target(s) in 0.46s
Running `target/debug/traits-example`
This is your captain speaking.
Up!
*waving arms furiously*
Because the fly method takes a self parameter, if we had two types that
both implement one trait, Rust could figure out which implementation of a
trait to use based on the type of self.
However, associated functions that are not methods don’t have a self
parameter. When there are multiple types or traits that define non-method
functions with the same function name, Rust doesn't always know which type you
mean unless you use fully qualified syntax. For example, in Listing 19-19 we
create a trait for an animal shelter that wants to name all baby dogs Spot.
We make an Animal trait with an associated non-method function baby_name.
The Animal trait is implemented for the struct Dog, on which we also
provide an associated non-method function baby_name directly.
Filename: src/main.rs
trait Animal { fn baby_name() -> String; } struct Dog; impl Dog { fn baby_name() -> String { String::from("Spot") } } impl Animal for Dog { fn baby_name() -> String { String::from("puppy") } } fn main() { println!("A baby dog is called a {}", Dog::baby_name()); }
Listing 19-19: A trait with an associated function and a type with an associated function of the same name that also implements the trait
We implement the code for naming all puppies Spot in the baby_name associated
function that is defined on Dog. The Dog type also implements the trait
Animal, which describes characteristics that all animals have. Baby dogs are
called puppies, and that is expressed in the implementation of the Animal
trait on Dog in the baby_name function associated with the Animal trait.
In main, we call the Dog::baby_name function, which calls the associated
function defined on Dog directly. This code prints the following:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
Finished dev [unoptimized + debuginfo] target(s) in 0.54s
Running `target/debug/traits-example`
A baby dog is called a Spot
This output isn’t what we wanted. We want to call the baby_name function that
is part of the Animal trait that we implemented on Dog so the code prints
A baby dog is called a puppy. The technique of specifying the trait name that
we used in Listing 19-18 doesn’t help here; if we change main to the code in
Listing 19-20, we’ll get a compilation error.
Filename: src/main.rs
trait Animal {
fn baby_name() -> String;
}
struct Dog;
impl Dog {
fn baby_name() -> String {
String::from("Spot")
}
}
impl Animal for Dog {
fn baby_name() -> String {
String::from("puppy")
}
}
fn main() {
println!("A baby dog is called a {}", Animal::baby_name());
}Listing 19-20: Attempting to call the baby_name
function from the Animal trait, but Rust doesn’t know which implementation to
use
Because Animal::baby_name doesn’t have a self parameter, and there could be
other types that implement the Animal trait, Rust can’t figure out which
implementation of Animal::baby_name we want. We’ll get this compiler error:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
error[E0790]: cannot call associated function on trait without specifying the corresponding `impl` type
--> src/main.rs:20:43
|
2 | fn baby_name() -> String;
| ------------------------- `Animal::baby_name` defined here
...
20 | println!("A baby dog is called a {}", Animal::baby_name());
| ^^^^^^^^^^^^^^^^^ cannot call associated function of trait
|
help: use the fully-qualified path to the only available implementation
|
20 | println!("A baby dog is called a {}", <Dog as Animal>::baby_name());
| +++++++ +
For more information about this error, try `rustc --explain E0790`.
error: could not compile `traits-example` due to previous error
To disambiguate and tell Rust that we want to use the implementation of
Animal for Dog as opposed to the implementation of Animal for some other
type, we need to use fully qualified syntax. Listing 19-21 demonstrates how to
use fully qualified syntax.
Filename: src/main.rs
trait Animal { fn baby_name() -> String; } struct Dog; impl Dog { fn baby_name() -> String { String::from("Spot") } } impl Animal for Dog { fn baby_name() -> String { String::from("puppy") } } fn main() { println!("A baby dog is called a {}", <Dog as Animal>::baby_name()); }
Listing 19-21: Using fully qualified syntax to specify
that we want to call the baby_name function from the Animal trait as
implemented on Dog
We’re providing Rust with a type annotation within the angle brackets, which
indicates we want to call the baby_name method from the Animal trait as
implemented on Dog by saying that we want to treat the Dog type as an
Animal for this function call. This code will now print what we want:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
Finished dev [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/traits-example`
A baby dog is called a puppy
In general, fully qualified syntax is defined as follows:
<Type as Trait>::function(receiver_if_method, next_arg, ...);For associated functions that aren’t methods, there would not be a receiver:
there would only be the list of other arguments. You could use fully qualified
syntax everywhere that you call functions or methods. However, you’re allowed
to omit any part of this syntax that Rust can figure out from other information
in the program. You only need to use this more verbose syntax in cases where
there are multiple implementations that use the same name and Rust needs help
to identify which implementation you want to call.
Using Supertraits to Require One Trait’s Functionality Within Another Trait
Sometimes, you might write a trait definition that depends on another trait: for a type to implement the first trait, you want to require that type to also implement the second trait. You would do this so that your trait definition can make use of the associated items of the second trait. The trait your trait definition is relying on is called a supertrait of your trait.
For example, let’s say we want to make an OutlinePrint trait with an
outline_print method that will print a given value formatted so that it's
framed in asterisks. That is, given a Point struct that implements the
standard library trait Display to result in (x, y), when we call
outline_print on a Point instance that has 1 for x and 3 for y, it
should print the following:
**********
* *
* (1, 3) *
* *
**********
In the implementation of the outline_print method, we want to use the
Display trait’s functionality. Therefore, we need to specify that the
OutlinePrint trait will work only for types that also implement Display and
provide the functionality that OutlinePrint needs. We can do that in the
trait definition by specifying OutlinePrint: Display. This technique is
similar to adding a trait bound to the trait. Listing 19-22 shows an
implementation of the OutlinePrint trait.
Filename: src/main.rs
use std::fmt; trait OutlinePrint: fmt::Display { fn outline_print(&self) { let output = self.to_string(); let len = output.len(); println!("{}", "*".repeat(len + 4)); println!("*{}*", " ".repeat(len + 2)); println!("* {} *", output); println!("*{}*", " ".repeat(len + 2)); println!("{}", "*".repeat(len + 4)); } } fn main() {}
Listing 19-22: Implementing the OutlinePrint trait that
requires the functionality from Display
Because we’ve specified that OutlinePrint requires the Display trait, we
can use the to_string function that is automatically implemented for any type
that implements Display. If we tried to use to_string without adding a
colon and specifying the Display trait after the trait name, we’d get an
error saying that no method named to_string was found for the type &Self in
the current scope.
Let’s see what happens when we try to implement OutlinePrint on a type that
doesn’t implement Display, such as the Point struct:
Filename: src/main.rs
use std::fmt;
trait OutlinePrint: fmt::Display {
fn outline_print(&self) {
let output = self.to_string();
let len = output.len();
println!("{}", "*".repeat(len + 4));
println!("*{}*", " ".repeat(len + 2));
println!("* {} *", output);
println!("*{}*", " ".repeat(len + 2));
println!("{}", "*".repeat(len + 4));
}
}
struct Point {
x: i32,
y: i32,
}
impl OutlinePrint for Point {}
fn main() {
let p = Point { x: 1, y: 3 };
p.outline_print();
}We get an error saying that Display is required but not implemented:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
error[E0277]: `Point` doesn't implement `std::fmt::Display`
--> src/main.rs:20:6
|
20 | impl OutlinePrint for Point {}
| ^^^^^^^^^^^^ `Point` cannot be formatted with the default formatter
|
= help: the trait `std::fmt::Display` is not implemented for `Point`
= note: in format strings you may be able to use `{:?}` (or {:#?} for pretty-print) instead
note: required by a bound in `OutlinePrint`
--> src/main.rs:3:21
|
3 | trait OutlinePrint: fmt::Display {
| ^^^^^^^^^^^^ required by this bound in `OutlinePrint`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `traits-example` due to previous error
To fix this, we implement Display on Point and satisfy the constraint that
OutlinePrint requires, like so:
Filename: src/main.rs
trait OutlinePrint: fmt::Display { fn outline_print(&self) { let output = self.to_string(); let len = output.len(); println!("{}", "*".repeat(len + 4)); println!("*{}*", " ".repeat(len + 2)); println!("* {} *", output); println!("*{}*", " ".repeat(len + 2)); println!("{}", "*".repeat(len + 4)); } } struct Point { x: i32, y: i32, } impl OutlinePrint for Point {} use std::fmt; impl fmt::Display for Point { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "({}, {})", self.x, self.y) } } fn main() { let p = Point { x: 1, y: 3 }; p.outline_print(); }
Then implementing the OutlinePrint trait on Point will compile
successfully, and we can call outline_print on a Point instance to display
it within an outline of asterisks.
Using the Newtype Pattern to Implement External Traits on External Types
In Chapter 10 in the “Implementing a Trait on a Type” section, we mentioned the orphan rule that states we’re only allowed to implement a trait on a type if either the trait or the type are local to our crate. It’s possible to get around this restriction using the newtype pattern, which involves creating a new type in a tuple struct. (We covered tuple structs in the “Using Tuple Structs without Named Fields to Create Different Types” section of Chapter 5.) The tuple struct will have one field and be a thin wrapper around the type we want to implement a trait for. Then the wrapper type is local to our crate, and we can implement the trait on the wrapper. Newtype is a term that originates from the Haskell programming language. There is no runtime performance penalty for using this pattern, and the wrapper type is elided at compile time.
As an example, let’s say we want to implement Display on Vec<T>, which the
orphan rule prevents us from doing directly because the Display trait and the
Vec<T> type are defined outside our crate. We can make a Wrapper struct
that holds an instance of Vec<T>; then we can implement Display on
Wrapper and use the Vec<T> value, as shown in Listing 19-23.
Filename: src/main.rs
use std::fmt; struct Wrapper(Vec<String>); impl fmt::Display for Wrapper { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "[{}]", self.0.join(", ")) } } fn main() { let w = Wrapper(vec![String::from("hello"), String::from("world")]); println!("w = {}", w); }
Listing 19-23: Creating a Wrapper type around
Vec<String> to implement Display
The implementation of Display uses self.0 to access the inner Vec<T>,
because Wrapper is a tuple struct and Vec<T> is the item at index 0 in the
tuple. Then we can use the functionality of the Display type on Wrapper.
The downside of using this technique is that Wrapper is a new type, so it
doesn’t have the methods of the value it’s holding. We would have to implement
all the methods of Vec<T> directly on Wrapper such that the methods
delegate to self.0, which would allow us to treat Wrapper exactly like a
Vec<T>. If we wanted the new type to have every method the inner type has,
implementing the Deref trait (discussed in Chapter 15 in the “Treating Smart
Pointers Like Regular References with the Deref
Trait” section) on the Wrapper to return
the inner type would be a solution. If we don’t want the Wrapper type to have
all the methods of the inner type—for example, to restrict the Wrapper type’s
behavior—we would have to implement just the methods we do want manually.
This newtype pattern is also useful even when traits are not involved. Let’s switch focus and look at some advanced ways to interact with Rust’s type system.
Advanced Types
The Rust type system has some features that we’ve so far mentioned but haven’t
yet discussed. We’ll start by discussing newtypes in general as we examine why
newtypes are useful as types. Then we’ll move on to type aliases, a feature
similar to newtypes but with slightly different semantics. We’ll also discuss
the ! type and dynamically sized types.
Using the Newtype Pattern for Type Safety and Abstraction
Note: This section assumes you’ve read the earlier section “Using the Newtype Pattern to Implement External Traits on External Types.”
The newtype pattern is also useful for tasks beyond those we’ve discussed so
far, including statically enforcing that values are never confused and
indicating the units of a value. You saw an example of using newtypes to
indicate units in Listing 19-15: recall that the Millimeters and Meters
structs wrapped u32 values in a newtype. If we wrote a function with a
parameter of type Millimeters, we couldn’t compile a program that
accidentally tried to call that function with a value of type Meters or a
plain u32.
We can also use the newtype pattern to abstract away some implementation details of a type: the new type can expose a public API that is different from the API of the private inner type.
Newtypes can also hide internal implementation. For example, we could provide a
People type to wrap a HashMap<i32, String> that stores a person’s ID
associated with their name. Code using People would only interact with the
public API we provide, such as a method to add a name string to the People
collection; that code wouldn’t need to know that we assign an i32 ID to names
internally. The newtype pattern is a lightweight way to achieve encapsulation
to hide implementation details, which we discussed in the “Encapsulation that
Hides Implementation
Details”
section of Chapter 17.
Creating Type Synonyms with Type Aliases
Rust provides the ability to declare a type alias to give an existing type
another name. For this we use the type keyword. For example, we can create
the alias Kilometers to i32 like so:
fn main() { type Kilometers = i32; let x: i32 = 5; let y: Kilometers = 5; println!("x + y = {}", x + y); }
Now, the alias Kilometers is a synonym for i32; unlike the Millimeters
and Meters types we created in Listing 19-15, Kilometers is not a separate,
new type. Values that have the type Kilometers will be treated the same as
values of type i32:
fn main() { type Kilometers = i32; let x: i32 = 5; let y: Kilometers = 5; println!("x + y = {}", x + y); }
Because Kilometers and i32 are the same type, we can add values of both
types and we can pass Kilometers values to functions that take i32
parameters. However, using this method, we don’t get the type checking benefits
that we get from the newtype pattern discussed earlier. In other words, if we
mix up Kilometers and i32 values somewhere, the compiler will not give us
an error.
The main use case for type synonyms is to reduce repetition. For example, we might have a lengthy type like this:
Box<dyn Fn() + Send + 'static>Writing this lengthy type in function signatures and as type annotations all over the code can be tiresome and error prone. Imagine having a project full of code like that in Listing 19-24.
fn main() { let f: Box<dyn Fn() + Send + 'static> = Box::new(|| println!("hi")); fn takes_long_type(f: Box<dyn Fn() + Send + 'static>) { // --snip-- } fn returns_long_type() -> Box<dyn Fn() + Send + 'static> { // --snip-- Box::new(|| ()) } }
Listing 19-24: Using a long type in many places
A type alias makes this code more manageable by reducing the repetition. In
Listing 19-25, we’ve introduced an alias named Thunk for the verbose type and
can replace all uses of the type with the shorter alias Thunk.
fn main() { type Thunk = Box<dyn Fn() + Send + 'static>; let f: Thunk = Box::new(|| println!("hi")); fn takes_long_type(f: Thunk) { // --snip-- } fn returns_long_type() -> Thunk { // --snip-- Box::new(|| ()) } }
Listing 19-25: Introducing a type alias Thunk to reduce
repetition
This code is much easier to read and write! Choosing a meaningful name for a type alias can help communicate your intent as well (thunk is a word for code to be evaluated at a later time, so it’s an appropriate name for a closure that gets stored).
Type aliases are also commonly used with the Result<T, E> type for reducing
repetition. Consider the std::io module in the standard library. I/O
operations often return a Result<T, E> to handle situations when operations
fail to work. This library has a std::io::Error struct that represents all
possible I/O errors. Many of the functions in std::io will be returning
Result<T, E> where the E is std::io::Error, such as these functions in
the Write trait:
use std::fmt;
use std::io::Error;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize, Error>;
fn flush(&mut self) -> Result<(), Error>;
fn write_all(&mut self, buf: &[u8]) -> Result<(), Error>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<(), Error>;
}The Result<..., Error> is repeated a lot. As such, std::io has this type
alias declaration:
use std::fmt;
type Result<T> = std::result::Result<T, std::io::Error>;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize>;
fn flush(&mut self) -> Result<()>;
fn write_all(&mut self, buf: &[u8]) -> Result<()>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<()>;
}Because this declaration is in the std::io module, we can use the fully
qualified alias std::io::Result<T>; that is, a Result<T, E> with the E
filled in as std::io::Error. The Write trait function signatures end up
looking like this:
use std::fmt;
type Result<T> = std::result::Result<T, std::io::Error>;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize>;
fn flush(&mut self) -> Result<()>;
fn write_all(&mut self, buf: &[u8]) -> Result<()>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<()>;
}The type alias helps in two ways: it makes code easier to write and it gives
us a consistent interface across all of std::io. Because it’s an alias, it’s
just another Result<T, E>, which means we can use any methods that work on
Result<T, E> with it, as well as special syntax like the ? operator.
The Never Type that Never Returns
Rust has a special type named ! that’s known in type theory lingo as the
empty type because it has no values. We prefer to call it the never type
because it stands in the place of the return type when a function will never
return. Here is an example:
fn bar() -> ! {
// --snip--
panic!();
}This code is read as “the function bar returns never.” Functions that return
never are called diverging functions. We can’t create values of the type !
so bar can never possibly return.
But what use is a type you can never create values for? Recall the code from Listing 2-5, part of the number guessing game; we’ve reproduced a bit of it here in Listing 19-26.
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Raqamni topish o'yini!");
let yashirin_raqam = rand::thread_rng().gen_range(1..=100);
println!("Yashirin raqam: {yashirin_raqam}");
loop {
println!("Iltimos, taxminingizni kiriting.");
let mut taxmin = String::new();
// --snip--
io::stdin()
.read_line(&mut taxmin)
.expect("Satrni o‘qib bo‘lmadi");
let taxmin: u32 = match taxmin.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("Sizning taxminingiz: {taxmin}");
// --snip--
match taxmin.cmp(&yashirin_raqam) {
Ordering::Less => println!("Raqam Kichik!"),
Ordering::Greater => println!("Raqam katta!"),
Ordering::Equal => {
println!("Siz yutdingiz!");
break;
}
}
}
}Listing 19-26: A match with an arm that ends in
continue
At the time, we skipped over some details in this code. In Chapter 6 in “The
match Control Flow Operator”
section, we discussed that match arms must all return the same type. So, for
example, the following code doesn’t work:
fn main() {
let guess = "3";
let guess = match guess.trim().parse() {
Ok(_) => 5,
Err(_) => "hello",
};
}The type of guess in this code would have to be an integer and a string,
and Rust requires that guess have only one type. So what does continue
return? How were we allowed to return a u32 from one arm and have another arm
that ends with continue in Listing 19-26?
As you might have guessed, continue has a ! value. That is, when Rust
computes the type of guess, it looks at both match arms, the former with a
value of u32 and the latter with a ! value. Because ! can never have a
value, Rust decides that the type of guess is u32.
The formal way of describing this behavior is that expressions of type ! can
be coerced into any other type. We’re allowed to end this match arm with
continue because continue doesn’t return a value; instead, it moves control
back to the top of the loop, so in the Err case, we never assign a value to
guess.
The never type is useful with the panic! macro as well. Recall the unwrap
function that we call on Option<T> values to produce a value or panic with
this definition:
enum Option<T> {
Some(T),
None,
}
use crate::Option::*;
impl<T> Option<T> {
pub fn unwrap(self) -> T {
match self {
Some(val) => val,
None => panic!("called `Option::unwrap()` on a `None` value"),
}
}
}In this code, the same thing happens as in the match in Listing 19-26: Rust
sees that val has the type T and panic! has the type !, so the result
of the overall match expression is T. This code works because panic!
doesn’t produce a value; it ends the program. In the None case, we won’t be
returning a value from unwrap, so this code is valid.
One final expression that has the type ! is a loop:
fn main() {
print!("forever ");
loop {
print!("and ever ");
}
}Here, the loop never ends, so ! is the value of the expression. However, this
wouldn’t be true if we included a break, because the loop would terminate
when it got to the break.
Dynamically Sized Types and the Sized Trait
Rust needs to know certain details about its types, such as how much space to allocate for a value of a particular type. This leaves one corner of its type system a little confusing at first: the concept of dynamically sized types. Sometimes referred to as DSTs or unsized types, these types let us write code using values whose size we can know only at runtime.
Let’s dig into the details of a dynamically sized type called str, which
we’ve been using throughout the book. That’s right, not &str, but str on
its own, is a DST. We can’t know how long the string is until runtime, meaning
we can’t create a variable of type str, nor can we take an argument of type
str. Consider the following code, which does not work:
fn main() {
let s1: str = "Hello there!";
let s2: str = "How's it going?";
}Rust needs to know how much memory to allocate for any value of a particular
type, and all values of a type must use the same amount of memory. If Rust
allowed us to write this code, these two str values would need to take up the
same amount of space. But they have different lengths: s1 needs 12 bytes of
storage and s2 needs 15. This is why it’s not possible to create a variable
holding a dynamically sized type.
So what do we do? In this case, you already know the answer: we make the types
of s1 and s2 a &str rather than a str. Recall from the “String
Slices” section of Chapter 4 that the slice data
structure just stores the starting position and the length of the slice. So
although a &T is a single value that stores the memory address of where the
T is located, a &str is two values: the address of the str and its
length. As such, we can know the size of a &str value at compile time: it’s
twice the length of a usize. That is, we always know the size of a &str, no
matter how long the string it refers to is. In general, this is the way in
which dynamically sized types are used in Rust: they have an extra bit of
metadata that stores the size of the dynamic information. The golden rule of
dynamically sized types is that we must always put values of dynamically sized
types behind a pointer of some kind.
We can combine str with all kinds of pointers: for example, Box<str> or
Rc<str>. In fact, you’ve seen this before but with a different dynamically
sized type: traits. Every trait is a dynamically sized type we can refer to by
using the name of the trait. In Chapter 17 in the “Using Trait Objects That
Allow for Values of Different
Types” section, we mentioned that to use traits as trait objects, we must
put them behind a pointer, such as &dyn Trait or Box<dyn Trait> (Rc<dyn Trait> would work too).
To work with DSTs, Rust provides the Sized trait to determine whether or not
a type’s size is known at compile time. This trait is automatically implemented
for everything whose size is known at compile time. In addition, Rust
implicitly adds a bound on Sized to every generic function. That is, a
generic function definition like this:
fn generic<T>(t: T) {
// --snip--
}is actually treated as though we had written this:
fn generic<T: Sized>(t: T) {
// --snip--
}By default, generic functions will work only on types that have a known size at compile time. However, you can use the following special syntax to relax this restriction:
fn generic<T: ?Sized>(t: &T) {
// --snip--
}A trait bound on ?Sized means “T may or may not be Sized” and this
notation overrides the default that generic types must have a known size at
compile time. The ?Trait syntax with this meaning is only available for
Sized, not any other traits.
Also note that we switched the type of the t parameter from T to &T.
Because the type might not be Sized, we need to use it behind some kind of
pointer. In this case, we’ve chosen a reference.
Next, we’ll talk about functions and closures!
Advanced Functions and Closures
This section explores some advanced features related to functions and closures, including function pointers and returning closures.
Function Pointers
We’ve talked about how to pass closures to functions; you can also pass regular
functions to functions! This technique is useful when you want to pass a
function you’ve already defined rather than defining a new closure. Functions
coerce to the type fn (with a lowercase f), not to be confused with the Fn
closure trait. The fn type is called a function pointer. Passing functions
with function pointers will allow you to use functions as arguments to other
functions.
The syntax for specifying that a parameter is a function pointer is similar to
that of closures, as shown in Listing 19-27, where we’ve defined a function
add_one that adds one to its parameter. The function do_twice takes two
parameters: a function pointer to any function that takes an i32 parameter
and returns an i32, and one i32 value. The do_twice function calls the
function f twice, passing it the arg value, then adds the two function call
results together. The main function calls do_twice with the arguments
add_one and 5.
Filename: src/main.rs
fn add_one(x: i32) -> i32 { x + 1 } fn do_twice(f: fn(i32) -> i32, arg: i32) -> i32 { f(arg) + f(arg) } fn main() { let answer = do_twice(add_one, 5); println!("The answer is: {}", answer); }
Listing 19-27: Using the fn type to accept a function
pointer as an argument
This code prints The answer is: 12. We specify that the parameter f in
do_twice is an fn that takes one parameter of type i32 and returns an
i32. We can then call f in the body of do_twice. In main, we can pass
the function name add_one as the first argument to do_twice.
Unlike closures, fn is a type rather than a trait, so we specify fn as the
parameter type directly rather than declaring a generic type parameter with one
of the Fn traits as a trait bound.
Function pointers implement all three of the closure traits (Fn, FnMut, and
FnOnce), meaning you can always pass a function pointer as an argument for a
function that expects a closure. It’s best to write functions using a generic
type and one of the closure traits so your functions can accept either
functions or closures.
That said, one example of where you would want to only accept fn and not
closures is when interfacing with external code that doesn’t have closures: C
functions can accept functions as arguments, but C doesn’t have closures.
As an example of where you could use either a closure defined inline or a named
function, let’s look at a use of the map method provided by the Iterator
trait in the standard library. To use the map function to turn a vector of
numbers into a vector of strings, we could use a closure, like this:
fn main() { let list_of_numbers = vec![1, 2, 3]; let list_of_strings: Vec<String> = list_of_numbers.iter().map(|i| i.to_string()).collect(); }
Or we could name a function as the argument to map instead of the closure,
like this:
fn main() { let list_of_numbers = vec![1, 2, 3]; let list_of_strings: Vec<String> = list_of_numbers.iter().map(ToString::to_string).collect(); }
Note that we must use the fully qualified syntax that we talked about earlier
in the “Advanced Traits” section because
there are multiple functions available named to_string. Here, we’re using the
to_string function defined in the ToString trait, which the standard
library has implemented for any type that implements Display.
Recall from the “Enum values” section of Chapter 6 that the name of each enum variant that we define also becomes an initializer function. We can use these initializer functions as function pointers that implement the closure traits, which means we can specify the initializer functions as arguments for methods that take closures, like so:
fn main() { enum Status { Value(u32), Stop, } let list_of_statuses: Vec<Status> = (0u32..20).map(Status::Value).collect(); }
Here we create Status::Value instances using each u32 value in the range
that map is called on by using the initializer function of Status::Value.
Some people prefer this style, and some people prefer to use closures. They
compile to the same code, so use whichever style is clearer to you.
Returning Closures
Closures are represented by traits, which means you can’t return closures
directly. In most cases where you might want to return a trait, you can instead
use the concrete type that implements the trait as the return value of the
function. However, you can’t do that with closures because they don’t have a
concrete type that is returnable; you’re not allowed to use the function
pointer fn as a return type, for example.
The following code tries to return a closure directly, but it won’t compile:
fn returns_closure() -> dyn Fn(i32) -> i32 {
|x| x + 1
}The compiler error is as follows:
$ cargo build
Compiling functions-example v0.1.0 (file:///projects/functions-example)
error[E0746]: return type cannot have an unboxed trait object
--> src/lib.rs:1:25
|
1 | fn returns_closure() -> dyn Fn(i32) -> i32 {
| ^^^^^^^^^^^^^^^^^^ doesn't have a size known at compile-time
|
= note: for information on `impl Trait`, see <https://doc.rust-lang.org/book/ch10-02-traits.html#returning-types-that-implement-traits>
help: use `impl Fn(i32) -> i32` as the return type, as all return paths are of type `[closure@src/lib.rs:2:5: 2:8]`, which implements `Fn(i32) -> i32`
|
1 | fn returns_closure() -> impl Fn(i32) -> i32 {
| ~~~~~~~~~~~~~~~~~~~
For more information about this error, try `rustc --explain E0746`.
error: could not compile `functions-example` due to previous error
The error references the Sized trait again! Rust doesn’t know how much space
it will need to store the closure. We saw a solution to this problem earlier.
We can use a trait object:
fn returns_closure() -> Box<dyn Fn(i32) -> i32> {
Box::new(|x| x + 1)
}This code will compile just fine. For more about trait objects, refer to the section “Using Trait Objects That Allow for Values of Different Types” in Chapter 17.
Next, let’s look at macros!
Macros
We’ve used macros like println! throughout this book, but we haven’t fully
explored what a macro is and how it works. The term macro refers to a family
of features in Rust: declarative macros with macro_rules! and three kinds
of procedural macros:
- Custom
#[derive]macros that specify code added with thederiveattribute used on structs and enums - Attribute-like macros that define custom attributes usable on any item
- Function-like macros that look like function calls but operate on the tokens specified as their argument
We’ll talk about each of these in turn, but first, let’s look at why we even need macros when we already have functions.
The Difference Between Macros and Functions
Fundamentally, macros are a way of writing code that writes other code, which
is known as metaprogramming. In Appendix C, we discuss the derive
attribute, which generates an implementation of various traits for you. We’ve
also used the println! and vec! macros throughout the book. All of these
macros expand to produce more code than the code you’ve written manually.
Metaprogramming is useful for reducing the amount of code you have to write and maintain, which is also one of the roles of functions. However, macros have some additional powers that functions don’t.
A function signature must declare the number and type of parameters the
function has. Macros, on the other hand, can take a variable number of
parameters: we can call println!("hello") with one argument or
println!("hello {}", name) with two arguments. Also, macros are expanded
before the compiler interprets the meaning of the code, so a macro can, for
example, implement a trait on a given type. A function can’t, because it gets
called at runtime and a trait needs to be implemented at compile time.
The downside to implementing a macro instead of a function is that macro definitions are more complex than function definitions because you’re writing Rust code that writes Rust code. Due to this indirection, macro definitions are generally more difficult to read, understand, and maintain than function definitions.
Another important difference between macros and functions is that you must define macros or bring them into scope before you call them in a file, as opposed to functions you can define anywhere and call anywhere.
Declarative Macros with macro_rules! for General Metaprogramming
The most widely used form of macros in Rust is the declarative macro. These
are also sometimes referred to as “macros by example,” “macro_rules! macros,”
or just plain “macros.” At their core, declarative macros allow you to write
something similar to a Rust match expression. As discussed in Chapter 6,
match expressions are control structures that take an expression, compare the
resulting value of the expression to patterns, and then run the code associated
with the matching pattern. Macros also compare a value to patterns that are
associated with particular code: in this situation, the value is the literal
Rust source code passed to the macro; the patterns are compared with the
structure of that source code; and the code associated with each pattern, when
matched, replaces the code passed to the macro. This all happens during
compilation.
To define a macro, you use the macro_rules! construct. Let’s explore how to
use macro_rules! by looking at how the vec! macro is defined. Chapter 8
covered how we can use the vec! macro to create a new vector with particular
values. For example, the following macro creates a new vector containing three
integers:
#![allow(unused)] fn main() { let v: Vec<u32> = vec![1, 2, 3]; }
We could also use the vec! macro to make a vector of two integers or a vector
of five string slices. We wouldn’t be able to use a function to do the same
because we wouldn’t know the number or type of values up front.
Listing 19-28 shows a slightly simplified definition of the vec! macro.
Filename: src/lib.rs
#[macro_export]
macro_rules! vec {
( $( $x:expr ),* ) => {
{
let mut temp_vec = Vec::new();
$(
temp_vec.push($x);
)*
temp_vec
}
};
}Listing 19-28: A simplified version of the vec! macro
definition
Note: The actual definition of the
vec!macro in the standard library includes code to preallocate the correct amount of memory up front. That code is an optimization that we don’t include here to make the example simpler.
The #[macro_export] annotation indicates that this macro should be made
available whenever the crate in which the macro is defined is brought into
scope. Without this annotation, the macro can’t be brought into scope.
We then start the macro definition with macro_rules! and the name of the
macro we’re defining without the exclamation mark. The name, in this case
vec, is followed by curly brackets denoting the body of the macro definition.
The structure in the vec! body is similar to the structure of a match
expression. Here we have one arm with the pattern ( $( $x:expr ),* ),
followed by => and the block of code associated with this pattern. If the
pattern matches, the associated block of code will be emitted. Given that this
is the only pattern in this macro, there is only one valid way to match; any
other pattern will result in an error. More complex macros will have more than
one arm.
Valid pattern syntax in macro definitions is different than the pattern syntax covered in Chapter 18 because macro patterns are matched against Rust code structure rather than values. Let’s walk through what the pattern pieces in Listing 19-28 mean; for the full macro pattern syntax, see the Rust Reference.
First, we use a set of parentheses to encompass the whole pattern. We use a
dollar sign ($) to declare a variable in the macro system that will contain
the Rust code matching the pattern. The dollar sign makes it clear this is a
macro variable as opposed to a regular Rust variable. Next comes a set of
parentheses that captures values that match the pattern within the parentheses
for use in the replacement code. Within $() is $x:expr, which matches any
Rust expression and gives the expression the name $x.
The comma following $() indicates that a literal comma separator character
could optionally appear after the code that matches the code in $(). The *
specifies that the pattern matches zero or more of whatever precedes the *.
When we call this macro with vec![1, 2, 3];, the $x pattern matches three
times with the three expressions 1, 2, and 3.
Now let’s look at the pattern in the body of the code associated with this arm:
temp_vec.push() within $()* is generated for each part that matches $()
in the pattern zero or more times depending on how many times the pattern
matches. The $x is replaced with each expression matched. When we call this
macro with vec![1, 2, 3];, the code generated that replaces this macro call
will be the following:
{
let mut temp_vec = Vec::new();
temp_vec.push(1);
temp_vec.push(2);
temp_vec.push(3);
temp_vec
}We’ve defined a macro that can take any number of arguments of any type and can generate code to create a vector containing the specified elements.
To learn more about how to write macros, consult the online documentation or other resources, such as “The Little Book of Rust Macros” started by Daniel Keep and continued by Lukas Wirth.
Procedural Macros for Generating Code from Attributes
The second form of macros is the procedural macro, which acts more like a function (and is a type of procedure). Procedural macros accept some code as an input, operate on that code, and produce some code as an output rather than matching against patterns and replacing the code with other code as declarative macros do. The three kinds of procedural macros are custom derive, attribute-like, and function-like, and all work in a similar fashion.
When creating procedural macros, the definitions must reside in their own crate
with a special crate type. This is for complex technical reasons that we hope
to eliminate in the future. In Listing 19-29, we show how to define a
procedural macro, where some_attribute is a placeholder for using a specific
macro variety.
Filename: src/lib.rs
use proc_macro;
#[some_attribute]
pub fn some_name(input: TokenStream) -> TokenStream {
}Listing 19-29: An example of defining a procedural macro
The function that defines a procedural macro takes a TokenStream as an input
and produces a TokenStream as an output. The TokenStream type is defined by
the proc_macro crate that is included with Rust and represents a sequence of
tokens. This is the core of the macro: the source code that the macro is
operating on makes up the input TokenStream, and the code the macro produces
is the output TokenStream. The function also has an attribute attached to it
that specifies which kind of procedural macro we’re creating. We can have
multiple kinds of procedural macros in the same crate.
Let’s look at the different kinds of procedural macros. We’ll start with a custom derive macro and then explain the small dissimilarities that make the other forms different.
How to Write a Custom derive Macro
Let’s create a crate named hello_macro that defines a trait named
HelloMacro with one associated function named hello_macro. Rather than
making our users implement the HelloMacro trait for each of their types,
we’ll provide a procedural macro so users can annotate their type with
#[derive(HelloMacro)] to get a default implementation of the hello_macro
function. The default implementation will print Hello, Macro! My name is TypeName! where TypeName is the name of the type on which this trait has
been defined. In other words, we’ll write a crate that enables another
programmer to write code like Listing 19-30 using our crate.
Filename: src/main.rs
use hello_macro::HelloMacro;
use hello_macro_derive::HelloMacro;
#[derive(HelloMacro)]
struct Pancakes;
fn main() {
Pancakes::hello_macro();
}Listing 19-30: The code a user of our crate will be able to write when using our procedural macro
This code will print Hello, Macro! My name is Pancakes! when we’re done. The
first step is to make a new library crate, like this:
$ cargo new hello_macro --lib
Next, we’ll define the HelloMacro trait and its associated function:
Filename: src/lib.rs
pub trait HelloMacro {
fn hello_macro();
}We have a trait and its function. At this point, our crate user could implement the trait to achieve the desired functionality, like so:
use hello_macro::HelloMacro;
struct Pancakes;
impl HelloMacro for Pancakes {
fn hello_macro() {
println!("Hello, Macro! My name is Pancakes!");
}
}
fn main() {
Pancakes::hello_macro();
}However, they would need to write the implementation block for each type they
wanted to use with hello_macro; we want to spare them from having to do this
work.
Additionally, we can’t yet provide the hello_macro function with default
implementation that will print the name of the type the trait is implemented
on: Rust doesn’t have reflection capabilities, so it can’t look up the type’s
name at runtime. We need a macro to generate code at compile time.
The next step is to define the procedural macro. At the time of this writing,
procedural macros need to be in their own crate. Eventually, this restriction
might be lifted. The convention for structuring crates and macro crates is as
follows: for a crate named foo, a custom derive procedural macro crate is
called foo_derive. Let’s start a new crate called hello_macro_derive inside
our hello_macro project:
$ cargo new hello_macro_derive --lib
Our two crates are tightly related, so we create the procedural macro crate
within the directory of our hello_macro crate. If we change the trait
definition in hello_macro, we’ll have to change the implementation of the
procedural macro in hello_macro_derive as well. The two crates will need to
be published separately, and programmers using these crates will need to add
both as dependencies and bring them both into scope. We could instead have the
hello_macro crate use hello_macro_derive as a dependency and re-export the
procedural macro code. However, the way we’ve structured the project makes it
possible for programmers to use hello_macro even if they don’t want the
derive functionality.
We need to declare the hello_macro_derive crate as a procedural macro crate.
We’ll also need functionality from the syn and quote crates, as you’ll see
in a moment, so we need to add them as dependencies. Add the following to the
Cargo.toml file for hello_macro_derive:
Filename: hello_macro_derive/Cargo.toml
[lib]
proc-macro = true
[dependencies]
syn = "1.0"
quote = "1.0"
To start defining the procedural macro, place the code in Listing 19-31 into
your src/lib.rs file for the hello_macro_derive crate. Note that this code
won’t compile until we add a definition for the impl_hello_macro function.
Filename: hello_macro_derive/src/lib.rs
use proc_macro::TokenStream;
use quote::quote;
use syn;
#[proc_macro_derive(HelloMacro)]
pub fn hello_macro_derive(input: TokenStream) -> TokenStream {
// Construct a representation of Rust code as a syntax tree
// that we can manipulate
let ast = syn::parse(input).unwrap();
// Build the trait implementation
impl_hello_macro(&ast)
}Listing 19-31: Code that most procedural macro crates will require in order to process Rust code
Notice that we’ve split the code into the hello_macro_derive function, which
is responsible for parsing the TokenStream, and the impl_hello_macro
function, which is responsible for transforming the syntax tree: this makes
writing a procedural macro more convenient. The code in the outer function
(hello_macro_derive in this case) will be the same for almost every
procedural macro crate you see or create. The code you specify in the body of
the inner function (impl_hello_macro in this case) will be different
depending on your procedural macro’s purpose.
We’ve introduced three new crates: proc_macro, syn, and quote. The
proc_macro crate comes with Rust, so we didn’t need to add that to the
dependencies in Cargo.toml. The proc_macro crate is the compiler’s API that
allows us to read and manipulate Rust code from our code.
The syn crate parses Rust code from a string into a data structure that we
can perform operations on. The quote crate turns syn data structures back
into Rust code. These crates make it much simpler to parse any sort of Rust
code we might want to handle: writing a full parser for Rust code is no simple
task.
The hello_macro_derive function will be called when a user of our library
specifies #[derive(HelloMacro)] on a type. This is possible because we’ve
annotated the hello_macro_derive function here with proc_macro_derive and
specified the name HelloMacro, which matches our trait name; this is the
convention most procedural macros follow.
The hello_macro_derive function first converts the input from a
TokenStream to a data structure that we can then interpret and perform
operations on. This is where syn comes into play. The parse function in
syn takes a TokenStream and returns a DeriveInput struct representing the
parsed Rust code. Listing 19-32 shows the relevant parts of the DeriveInput
struct we get from parsing the struct Pancakes; string:
DeriveInput {
// --snip--
ident: Ident {
ident: "Pancakes",
span: #0 bytes(95..103)
},
data: Struct(
DataStruct {
struct_token: Struct,
fields: Unit,
semi_token: Some(
Semi
)
}
)
}Listing 19-32: The DeriveInput instance we get when
parsing the code that has the macro’s attribute in Listing 19-30
The fields of this struct show that the Rust code we’ve parsed is a unit struct
with the ident (identifier, meaning the name) of Pancakes. There are more
fields on this struct for describing all sorts of Rust code; check the syn
documentation for DeriveInput for more information.
Soon we’ll define the impl_hello_macro function, which is where we’ll build
the new Rust code we want to include. But before we do, note that the output
for our derive macro is also a TokenStream. The returned TokenStream is
added to the code that our crate users write, so when they compile their crate,
they’ll get the extra functionality that we provide in the modified
TokenStream.
You might have noticed that we’re calling unwrap to cause the
hello_macro_derive function to panic if the call to the syn::parse function
fails here. It’s necessary for our procedural macro to panic on errors because
proc_macro_derive functions must return TokenStream rather than Result to
conform to the procedural macro API. We’ve simplified this example by using
unwrap; in production code, you should provide more specific error messages
about what went wrong by using panic! or expect.
Now that we have the code to turn the annotated Rust code from a TokenStream
into a DeriveInput instance, let’s generate the code that implements the
HelloMacro trait on the annotated type, as shown in Listing 19-33.
Filename: hello_macro_derive/src/lib.rs
use proc_macro::TokenStream;
use quote::quote;
use syn;
#[proc_macro_derive(HelloMacro)]
pub fn hello_macro_derive(input: TokenStream) -> TokenStream {
// Construct a representation of Rust code as a syntax tree
// that we can manipulate
let ast = syn::parse(input).unwrap();
// Build the trait implementation
impl_hello_macro(&ast)
}
fn impl_hello_macro(ast: &syn::DeriveInput) -> TokenStream {
let name = &ast.ident;
let gen = quote! {
impl HelloMacro for #name {
fn hello_macro() {
println!("Hello, Macro! My name is {}!", stringify!(#name));
}
}
};
gen.into()
}Listing 19-33: Implementing the HelloMacro trait using
the parsed Rust code
We get an Ident struct instance containing the name (identifier) of the
annotated type using ast.ident. The struct in Listing 19-32 shows that when
we run the impl_hello_macro function on the code in Listing 19-30, the
ident we get will have the ident field with a value of "Pancakes". Thus,
the name variable in Listing 19-33 will contain an Ident struct instance
that, when printed, will be the string "Pancakes", the name of the struct in
Listing 19-30.
The quote! macro lets us define the Rust code that we want to return. The
compiler expects something different to the direct result of the quote!
macro’s execution, so we need to convert it to a TokenStream. We do this by
calling the into method, which consumes this intermediate representation and
returns a value of the required TokenStream type.
The quote! macro also provides some very cool templating mechanics: we can
enter #name, and quote! will replace it with the value in the variable
name. You can even do some repetition similar to the way regular macros work.
Check out the quote crate’s docs for a thorough introduction.
We want our procedural macro to generate an implementation of our HelloMacro
trait for the type the user annotated, which we can get by using #name. The
trait implementation has the one function hello_macro, whose body contains the
functionality we want to provide: printing Hello, Macro! My name is and then
the name of the annotated type.
The stringify! macro used here is built into Rust. It takes a Rust
expression, such as 1 + 2, and at compile time turns the expression into a
string literal, such as "1 + 2". This is different than format! or
println!, macros which evaluate the expression and then turn the result into
a String. There is a possibility that the #name input might be an
expression to print literally, so we use stringify!. Using stringify! also
saves an allocation by converting #name to a string literal at compile time.
At this point, cargo build should complete successfully in both hello_macro
and hello_macro_derive. Let’s hook up these crates to the code in Listing
19-30 to see the procedural macro in action! Create a new binary project in
your projects directory using cargo new pancakes. We need to add
hello_macro and hello_macro_derive as dependencies in the pancakes
crate’s Cargo.toml. If you’re publishing your versions of hello_macro and
hello_macro_derive to crates.io, they would be regular
dependencies; if not, you can specify them as path dependencies as follows:
hello_macro = { path = "../hello_macro" }
hello_macro_derive = { path = "../hello_macro/hello_macro_derive" }
Put the code in Listing 19-30 into src/main.rs, and run cargo run: it
should print Hello, Macro! My name is Pancakes! The implementation of the
HelloMacro trait from the procedural macro was included without the
pancakes crate needing to implement it; the #[derive(HelloMacro)] added the
trait implementation.
Next, let’s explore how the other kinds of procedural macros differ from custom derive macros.
Attribute-like macros
Attribute-like macros are similar to custom derive macros, but instead of
generating code for the derive attribute, they allow you to create new
attributes. They’re also more flexible: derive only works for structs and
enums; attributes can be applied to other items as well, such as functions.
Here’s an example of using an attribute-like macro: say you have an attribute
named route that annotates functions when using a web application framework:
#[route(GET, "/")]
fn index() {This #[route] attribute would be defined by the framework as a procedural
macro. The signature of the macro definition function would look like this:
#[proc_macro_attribute]
pub fn route(attr: TokenStream, item: TokenStream) -> TokenStream {Here, we have two parameters of type TokenStream. The first is for the
contents of the attribute: the GET, "/" part. The second is the body of the
item the attribute is attached to: in this case, fn index() {} and the rest
of the function’s body.
Other than that, attribute-like macros work the same way as custom derive
macros: you create a crate with the proc-macro crate type and implement a
function that generates the code you want!
Function-like macros
Function-like macros define macros that look like function calls. Similarly to
macro_rules! macros, they’re more flexible than functions; for example, they
can take an unknown number of arguments. However, macro_rules! macros can be
defined only using the match-like syntax we discussed in the section
“Declarative Macros with macro_rules! for General
Metaprogramming” earlier. Function-like macros take a
TokenStream parameter and their definition manipulates that TokenStream
using Rust code as the other two types of procedural macros do. An example of a
function-like macro is an sql! macro that might be called like so:
let sql = sql!(SELECT * FROM posts WHERE id=1);This macro would parse the SQL statement inside it and check that it’s
syntactically correct, which is much more complex processing than a
macro_rules! macro can do. The sql! macro would be defined like this:
#[proc_macro]
pub fn sql(input: TokenStream) -> TokenStream {This definition is similar to the custom derive macro’s signature: we receive the tokens that are inside the parentheses and return the code we wanted to generate.
Summary
Whew! Now you have some Rust features in your toolbox that you likely won’t use often, but you’ll know they’re available in very particular circumstances. We’ve introduced several complex topics so that when you encounter them in error message suggestions or in other peoples’ code, you’ll be able to recognize these concepts and syntax. Use this chapter as a reference to guide you to solutions.
Next, we’ll put everything we’ve discussed throughout the book into practice and do one more project!
So'ngi Loyiha: Ko'p oqimli (Multithreaded) Veb Server qurish
Bu uzoq safar bo‘ldi, lekin nihoyat kitobning oxiriga yetdik. Ushbu bobda biz yakuniy boblarda o‘rganilgan ba’zi tushunchalarni amalda qo‘llash uchun yana bir loyihani birga quramiz, shuningdek, avvalgi darslarni ham eslab o‘tamiz.
Yakuniy loyihamizda biz “salom” deb javob beradigan va veb-brauzerda 20-1-rasmga o‘xshash ko‘rinadigan veb-server yaratamiz.
20-rasm: Bizning yakuniy umumiy loyihamiz
Veb-serverni yaratish bo‘yicha rejamiz quyidagicha:
- TCP va HTTP haqida biroz ma’lumot olish.
- Soket orqali TCP ulanishlarini tinglash.
- Bir nechta HTTP so‘rovlarini tahlil qilish.
- To‘g‘ri HTTP javobini (response) yaratish.
- Serverimiz unumdorligini oqimlar to‘plami (thread pool) yordamida oshirish.
Boshlashdan oldin bir narsani aytib o‘tishimiz kerak: biz foydalanadigan usul Rust tilida veb-server qurishning eng yaxshi usuli bo‘lmaydi. Rust hamjamiyati crates.io saytida chop etilgan, to‘liq funksiyali veb-server va oqimlar to‘plami (thread pool) kutubxonalarini yaratgan. Bu kutubxonalar biz quradigan versiyadan ko‘ra ancha mukammal. Biroq, ushbu bobdagi maqsadimiz – sizni o‘rgatish, eng oson yo‘lni tanlash emas. Rust tizim dasturlash tili bo‘lganligi sababli, biz o‘zimiz ishlamoqchi bo‘lgan abstraktsiya darajasini tanlashimiz mumkin va boshqa tillarda amalga oshirish qiyin yoki imkonsiz bo‘lgan chuqur darajadagi ishlarni bajarish imkoniyatiga egamiz. Shuning uchun biz HTTP server va oqimlar to‘plamini qo‘lda yozamiz, shunda siz kelajakda foydalanishingiz mumkin bo‘lgan kutubxonalar ortida qanday g‘oya va texnikalar yotganini tushunib olasiz.
Bitta oqimli (single-threaded) veb-server yaratish
Avval bitta oqimli veb-serverni ishga tushirishdan boshlaymiz. Ishni boshlashdan oldin, veb-serverlarni qurishda ishtirok etadigan protokollar haqida qisqacha ko‘rib chiqamiz. Ushbu protokollarning batafsil tafsilotlari ushbu kitob doirasidan tashqarida, ammo qisqacha tushuntirish sizga zarur bo‘lgan asosiy ma’lumotlarni beradi.
Veb-serverlarda ishtirok etadigan ikkita asosiy protokol bu Gipermatn uzatish protokoli (HTTP) va Uzatishni boshqarish protokoli (TCP) hisoblanadi. Har ikkala protokol ham so‘rov-javob (request-response) protokollari bo‘lib, bunda mijoz (client) so‘rov yuboradi, server esa bu so‘rovlarni tinglaydi va mijozga javob qaytaradi. Ushbu so‘rovlar va javoblarning mazmuni protokollar tomonidan aniqlanadi.
TCP bu past darajadagi (lower-level) protokol bo‘lib, ma’lumotlar bir serverdan boshqasiga qanday uzatilishini belgilaydi, lekin bu ma’lumotlarning mazmuni qanday bo‘lishi kerakligini aniqlamaydi. HTTP esa TCP ustida qurilgan bo‘lib, so‘rovlar va javoblarning tarkibini belgilaydi. Texnik jihatdan HTTP’ni boshqa protokollar bilan ham ishlatish mumkin, ammo aksariyat hollarda HTTP o‘z ma’lumotlarini TCP orqali uzatadi. Biz esa TCP va HTTP so‘rov hamda javoblarining xom baytlari (raw bytes) bilan ishlaymiz.
TCP ulanishni tinglash
Veb-serverimiz TCP ulanishini tinglashi kerak, shuning uchun birinchi navbatda
shu qism ustida ishlaymiz. Rust’ning standart kutubxonasi buni amalga oshirish
imkonini beruvchi std::net modulini taklif qiladi. Keling, odatdagidek yangi
loyiha yaratamiz:
$ cargo new salom
Created binary (application) `salom` project
$ cd salom
Endi src/main.rs fayliga 20-1 ro‘yxatdagi (Listing 20-1) kodni kiriting. Bu
kod 127.0.0.1:7878 lokal manzilida kiruvchi TCP oqimlarini tinglaydi. Har
safar yangi oqim kelganda, Connection established! (Ulanish o‘rnatildi!) deb
chop etadi.
Filename: src/main.rs
use std::net::TcpListener; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); println!("Connection established!"); } }
20-1 ro‘yxat: Kiruvchi oqimlarni tinglash va oqim qabul qilinganda xabar chop etish
TcpListener yordamida 127.0.0.1:7878 manzilida TCP ulanishlarini
tinglashimiz mumkin. Manzilda ikki nuqtadan (:) oldingi qism — bu
kompyuteringizni ifodalovchi IP manzil (bu barcha kompyuterlarda bir xil
bo‘ladi va mualliflarning kompyuteriga xos emas), 7878 esa port raqami. Bu
portni ikki sababga ko‘ra tanladik: odatda HTTP bu portda ishlatilmaydi,
shuning uchun serverimiz kompyuteringizda ishlayotgan boshqa veb-serverlar
bilan to‘qnash kelmaydi; ikkinchidan, telefon klaviaturasida rust so‘zini
terishda 7878 raqamlari ishlatiladi.
Ushbu holatda bind funksiyasi new funksiyasiga o‘xshab ishlaydi, ya’ni u
yangi TcpListener obyektini qaytaradi. Funksiya bind deb nomlangan, chunki
tarmoqlarda portga ulanib tinglash jarayoni “portga bog‘lanish” (binding) deb
ataladi.
bind funksiyasi Result<T, E> turini qaytaradi, bu esa bog‘lanish (binding)
muvaffaqiyatsiz bo‘lishi mumkinligini bildiradi. Masalan, 80-portga ulanish
uchun administrator huquqlari talab qilinadi (administrator bo‘lmagan
foydalanuvchilar faqat 1023 dan yuqori portlarni tinglashi mumkin). Shuning
uchun, agar biz administrator bo‘lmasak va 80-portga ulanishga harakat qilsak,
bog‘lanish amalga oshmaydi. Bundan tashqari, agar dasturimizning ikkita
nusxasini ishga tushirsak va ular bir xil portda tinglashga harakat qilsa,
bog‘lanish yana amalga oshmaydi. Bu yerda faqat o‘rganish maqsadida oddiy
server yozayotganimiz uchun bunday xatoliklarni oldini olish haqida hozircha
qayg‘urmaymiz; uning o‘rniga dasturimizda xatolik yuz bersa dasturni
to'xtatadigan unwrap funksiyasidan foydalanamiz.
TcpListener ustidagi incoming metodi oqimlar ketma-ketligini (ya’ni,
TcpStream turidagi oqimlar) taqdim etuvchi iteratorni qaytaradi. Har bir
oqim (stream) mijoz (client) va server o‘rtasidagi ochiq ulanishni
ifodalaydi. Ulanish (connection) deganda, mijoz serverga ulanadigan, server
javob tayyorlab qaytaradigan va so‘ng ulanishni yopadigan to‘liq so‘rov-javob
(request response) jarayoni tushuniladi. Shunday ekan, TcpStream dan o‘qib,
mijoz nimani yuborganini bilamiz va javobimizni aynan shu oqim orqali yozib,
mijozga yuboramiz. Umuman olganda, bu for sikli har bir ulanishni navbati
bilan qayta ishlaydi va bizga boshqarish uchun bir nechta oqimlar beradi.
Hozircha oqim (stream) bilan ishlashimiz, agar oqimda xatolar bo‘lsa,
dasturimizni tugatish uchun unwrap funcsiyasini chaqirishdan iborat; xatolik
bo‘lmasa, dastur xabar chop etadi. Kelasi ro‘yxatda muvaffaqiyatli holatlar
uchun ko‘proq funksionallik qo‘shamiz. Mijoz serverga ulanganida incoming
metodidan xatoliklar chiqishi mumkin, chunki biz aslida ulanishlarning o‘zini
emas, ulanishga urinishlarni (connection attemps) ko‘rib chiqayapmiz
(iterating). Har bir urinish muvaffaqiyatli bo‘lavermasligi mumkin, va buning
sabablari ko‘pincha operatsion tizimga bog‘liq bo‘ladi. Masalan, ko‘plab
operatsion tizimlarda bir vaqtning o‘zida ochiq bo‘lishi mumkin bo‘lgan
ulanishlar soni cheklangan bo‘ladi; bu limitdan oshib ketilganida, yangi
ulanishga urinishlar xatolik chiqaradi, toki mavjud ulanishlardan ba’zilari
yopilmaguncha.
Keling, ushbu kodni ishga tushirib ko‘ramiz! Terminalda cargo run buyrug‘ini
invoke qiling (yurg'azing) va so‘ng brauzeringizda 127.0.0.1:7878 manzilini
oching. Brauzer “Connection reset” (Ulanish tiklandi) kabi xatolik xabarini
ko‘rsatishi mumkin, chunki hozircha server hech qanday ma’lumot qaytarayotgani
yo‘q. Biroq terminalingizga qarasangiz, brauzer serverga ulanganida chiqarilgan
bir nechta xabarlarni ko‘rishingiz mumkin bo‘ladi!
Running `target/debug/salom`
Connection established!
Connection established!
Connection established!
Ba’zan brauzerning bitta so‘rovi uchun bir nechta xabarlar chiqishini ko‘rishingiz mumkin; buning sababi shundaki, brauzer sahifa uchun so‘rov yuborish bilan birga, brauzer tabi da (yorlig‘ida) ko‘rinadigan favicon.ico kabi boshqa resurslar uchun ham so‘rov yuboradi.
Brauzer bir necha marta serverga ulanishga harakat qilayotgan bo'lishi ham
mumkin, chunki server hech qanday ma'lumot yubormayapti. stream sikl oxirida
ko‘lam (scope) dan chiqib ketganda, drop implementatsiyasi orqali ulanish
yopiladi. Brauzerlar ba’zida yopilgan ulanishlarga qayta urinish qiladi, chunki
muammo vaqtincha bo‘lishi mumkin. Muhim jihati shuki - TCP ulanishni
muvaffaqiyatli qo‘lga kiritdik!
Dasturdan foydalanishni tugatganingizda, uni ctrl-c tugmalari yordamida to‘xtatishni unutmang.
Har safar kodga o‘zgartirish kiritganingizdan so‘ng, eng so‘nggi versiyasi
ishga tushirilayotganiga ishonch hosil qilish uchun cargo run buyrug‘ini
qayta ishga tushuring.
So'rovni o'qish (Reading the request!)
Brauzerdan yuborilgan so‘rovni o‘qish funksiyasini ishlab chiqamiz! Avval
ulanishni (connection) qabul qilish va keyin ular bilan ishlash bosqichlarini
bir-biridan ajratish uchun, ulanishni qayta ishlovchi yangi funksiya yozamiz.
Bu yangi handle_connection funksiyasida TCP oqimidan (stream) ma’lumotlarni
o‘qiymiz va brauzer yuborayotgan ma’lumotlarni ko‘rish uchun ularni chop
etamiz. Kodni 20-02 ro‘yxatdagidek qilib o‘zgartiring.
Filename: src/main.rs
use std::{ io::{prelude::*, BufReader}, net::{TcpListener, TcpStream}, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } fn handle_connection(mut stream: TcpStream) { let buf_reader = BufReader::new(&mut stream); let http_request: Vec<_> = buf_reader .lines() .map(|result| result.unwrap()) .take_while(|line| !line.is_empty()) .collect(); println!("Request: {:#?}", http_request); }
20-02 ro‘yxat: TcpStream dan o‘qish va yuborilgan ma’lumotni chop etish
std::io::prelude va std::io::BufReader ni ko‘lamga (scope) olib kiramiz -
bu oqimdan (streamdan) o‘qish va yozish imkonini beradigan hislat (trait) va
xillardan (tiplardan) foydalanish imkonini beradi. Endi main funksiyasidagi
for siklida ulanish o‘rnatilgani haqida xabar chiqarish o‘rniga, yangi
handle_connection funksiyasini chaqiramiz va unga oqimni (streamni)
uzatamiz.
handle_connection funksiyasida biz oqimga (streamga) o‘zgaruvchan (mutable)
murojaatni o‘rab oladigan yangi BufReader obyektini yaratamiz. BufReader
buferlashni qo‘shadi - ya’ni u std::io::Read hislatining (traitining)
metodlariga murojaat qilishni boshqaradi.
Brauzer serverimizga yuboradigan so‘rov satrlarini yig‘ish uchun http_request
nomli o‘zgaruvchi yaratamiz. Bu satrlarni vektor ko‘rinishida yig‘moqchi
ekanligimizni ko‘rsatish uchun Vec<_> xil (type) annotatsiyasini qo‘shamiz.
BufReader std::io::BufRead xususiyatini (traitini) amalga oshiradi va shu
orqali lines metodini taqdim etadi. Lines metodi har gal yangi qatordan
ajratib, oqimdagi ma’lumotlarni Result<String, std::io::Error> ko‘rinishidagi
iterator sifatida qaytaradi. Har bir String qiymatni olish uchun har bir natija
(result) ustida map va unwrap funksiyalarini ishga tushuramiz. Agar
ma’lumotlar yaroqsiz UTF-8 formatida bo‘lsa yoki oqimdan o‘qishda muammo yuz
bersa, natija (result) xatolik (error) bo‘lishi mumkin. Ishlab chiqarish
(Production) darajasidagi dastur bu xatolarni ancha ehtiyotkorlik bilan
boshqarishi kerak, ammo soddalashtirish uchun biz bu yerda xatolik yuz bersa,
dasturni to‘xtatamiz.
The browser signals the end of an HTTP request by sending two newline characters in a row, so to get one request from the stream, we take lines until we get a line that is the empty string. Once we’ve collected the lines into the vector, we’re printing them out using pretty debug formatting so we can take a look at the instructions the web browser is sending to our server.
Let’s try this code! Start the program and make a request in a web browser again. Note that we’ll still get an error page in the browser, but our program’s output in the terminal will now look similar to this:
$ cargo run
Compiling hello v0.1.0 (file:///projects/hello)
Finished dev [unoptimized + debuginfo] target(s) in 0.42s
Running `target/debug/hello`
Request: [
"GET / HTTP/1.1",
"Host: 127.0.0.1:7878",
"User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:99.0) Gecko/20100101 Firefox/99.0",
"Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
"Accept-Language: en-US,en;q=0.5",
"Accept-Encoding: gzip, deflate, br",
"DNT: 1",
"Connection: keep-alive",
"Upgrade-Insecure-Requests: 1",
"Sec-Fetch-Dest: document",
"Sec-Fetch-Mode: navigate",
"Sec-Fetch-Site: none",
"Sec-Fetch-User: ?1",
"Cache-Control: max-age=0",
]
Depending on your browser, you might get slightly different output. Now that
we’re printing the request data, we can see why we get multiple connections
from one browser request by looking at the path after GET in the first line
of the request. If the repeated connections are all requesting /, we know the
browser is trying to fetch / repeatedly because it’s not getting a response
from our program.
Let’s break down this request data to understand what the browser is asking of our program.
A Closer Look at an HTTP Request
HTTP is a text-based protocol, and a request takes this format:
Method Request-URI HTTP-Version CRLF
headers CRLF
message-body
The first line is the request line that holds information about what the
client is requesting. The first part of the request line indicates the method
being used, such as GET or POST, which describes how the client is making
this request. Our client used a GET request, which means it is asking for
information.
The next part of the request line is /, which indicates the Uniform Resource Identifier (URI) the client is requesting: a URI is almost, but not quite, the same as a Uniform Resource Locator (URL). The difference between URIs and URLs isn’t important for our purposes in this chapter, but the HTTP spec uses the term URI, so we can just mentally substitute URL for URI here.
The last part is the HTTP version the client uses, and then the request line
ends in a CRLF sequence. (CRLF stands for carriage return and line feed,
which are terms from the typewriter days!) The CRLF sequence can also be
written as \r\n, where \r is a carriage return and \n is a line feed. The
CRLF sequence separates the request line from the rest of the request data.
Note that when the CRLF is printed, we see a new line start rather than \r\n.
Looking at the request line data we received from running our program so far,
we see that GET is the method, / is the request URI, and HTTP/1.1 is the
version.
After the request line, the remaining lines starting from Host: onward are
headers. GET requests have no body.
Try making a request from a different browser or asking for a different address, such as 127.0.0.1:7878/test, to see how the request data changes.
Now that we know what the browser is asking for, let’s send back some data!
Writing a Response
We’re going to implement sending data in response to a client request. Responses have the following format:
HTTP-Version Status-Code Reason-Phrase CRLF
headers CRLF
message-body
The first line is a status line that contains the HTTP version used in the response, a numeric status code that summarizes the result of the request, and a reason phrase that provides a text description of the status code. After the CRLF sequence are any headers, another CRLF sequence, and the body of the response.
Here is an example response that uses HTTP version 1.1, has a status code of 200, an OK reason phrase, no headers, and no body:
HTTP/1.1 200 OK\r\n\r\n
The status code 200 is the standard success response. The text is a tiny
successful HTTP response. Let’s write this to the stream as our response to a
successful request! From the handle_connection function, remove the
println! that was printing the request data and replace it with the code in
Listing 20-3.
Filename: src/main.rs
use std::{ io::{prelude::*, BufReader}, net::{TcpListener, TcpStream}, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } fn handle_connection(mut stream: TcpStream) { let buf_reader = BufReader::new(&mut stream); let http_request: Vec<_> = buf_reader .lines() .map(|result| result.unwrap()) .take_while(|line| !line.is_empty()) .collect(); let response = "HTTP/1.1 200 OK\r\n\r\n"; stream.write_all(response.as_bytes()).unwrap(); }
Listing 20-3: Writing a tiny successful HTTP response to the stream
The first new line defines the response variable that holds the success
message’s data. Then we call as_bytes on our response to convert the string
data to bytes. The write_all method on stream takes a &[u8] and sends
those bytes directly down the connection. Because the write_all operation
could fail, we use unwrap on any error result as before. Again, in a real
application you would add error handling here.
With these changes, let’s run our code and make a request. We’re no longer printing any data to the terminal, so we won’t see any output other than the output from Cargo. When you load 127.0.0.1:7878 in a web browser, you should get a blank page instead of an error. You’ve just hand-coded receiving an HTTP request and sending a response!
Returning Real HTML
Let’s implement the functionality for returning more than a blank page. Create the new file hello.html in the root of your project directory, not in the src directory. You can input any HTML you want; Listing 20-4 shows one possibility.
Filename: hello.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hello!</title>
</head>
<body>
<h1>Hello!</h1>
<p>Hi from Rust</p>
</body>
</html>
Listing 20-4: A sample HTML file to return in a response
This is a minimal HTML5 document with a heading and some text. To return this
from the server when a request is received, we’ll modify handle_connection as
shown in Listing 20-5 to read the HTML file, add it to the response as a body,
and send it.
Filename: src/main.rs
use std::{ fs, io::{prelude::*, BufReader}, net::{TcpListener, TcpStream}, }; // --snip-- fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } fn handle_connection(mut stream: TcpStream) { let buf_reader = BufReader::new(&mut stream); let http_request: Vec<_> = buf_reader .lines() .map(|result| result.unwrap()) .take_while(|line| !line.is_empty()) .collect(); let status_line = "HTTP/1.1 200 OK"; let contents = fs::read_to_string("hello.html").unwrap(); let length = contents.len(); let response = format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"); stream.write_all(response.as_bytes()).unwrap(); }
Listing 20-5: Sending the contents of hello.html as the body of the response
We’ve added fs to the use statement to bring the standard library’s
filesystem module into scope. The code for reading the contents of a file to a
string should look familiar; we used it in Chapter 12 when we read the contents
of a file for our I/O project in Listing 12-4.
Next, we use format! to add the file’s contents as the body of the success
response. To ensure a valid HTTP response, we add the Content-Length header
which is set to the size of our response body, in this case the size of
hello.html.
Run this code with cargo run and load 127.0.0.1:7878 in your browser; you
should see your HTML rendered!
Currently, we’re ignoring the request data in http_request and just sending
back the contents of the HTML file unconditionally. That means if you try
requesting 127.0.0.1:7878/something-else in your browser, you’ll still get
back this same HTML response. At the moment, our server is very limited and
does not do what most web servers do. We want to customize our responses
depending on the request and only send back the HTML file for a well-formed
request to /.
Validating the Request and Selectively Responding
Right now, our web server will return the HTML in the file no matter what the
client requested. Let’s add functionality to check that the browser is
requesting / before returning the HTML file and return an error if the
browser requests anything else. For this we need to modify handle_connection,
as shown in Listing 20-6. This new code checks the content of the request
received against what we know a request for / looks like and adds if and
else blocks to treat requests differently.
Filename: src/main.rs
use std::{ fs, io::{prelude::*, BufReader}, net::{TcpListener, TcpStream}, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } // --snip-- fn handle_connection(mut stream: TcpStream) { let buf_reader = BufReader::new(&mut stream); let request_line = buf_reader.lines().next().unwrap().unwrap(); if request_line == "GET / HTTP/1.1" { let status_line = "HTTP/1.1 200 OK"; let contents = fs::read_to_string("hello.html").unwrap(); let length = contents.len(); let response = format!( "{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}" ); stream.write_all(response.as_bytes()).unwrap(); } else { // some other request } }
Listing 20-6: Handling requests to / differently from other requests
We’re only going to be looking at the first line of the HTTP request, so rather
than reading the entire request into a vector, we’re calling next to get the
first item from the iterator. The first unwrap takes care of the Option and
stops the program if the iterator has no items. The second unwrap handles the
Result and has the same effect as the unwrap that was in the map added in
Listing 20-2.
Next, we check the request_line to see if it equals the request line of a GET
request to the / path. If it does, the if block returns the contents of our
HTML file.
If the request_line does not equal the GET request to the / path, it
means we’ve received some other request. We’ll add code to the else block in
a moment to respond to all other requests.
Run this code now and request 127.0.0.1:7878; you should get the HTML in hello.html. If you make any other request, such as 127.0.0.1:7878/something-else, you’ll get a connection error like those you saw when running the code in Listing 20-1 and Listing 20-2.
Now let’s add the code in Listing 20-7 to the else block to return a response
with the status code 404, which signals that the content for the request was
not found. We’ll also return some HTML for a page to render in the browser
indicating the response to the end user.
Filename: src/main.rs
use std::{ fs, io::{prelude::*, BufReader}, net::{TcpListener, TcpStream}, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } fn handle_connection(mut stream: TcpStream) { let buf_reader = BufReader::new(&mut stream); let request_line = buf_reader.lines().next().unwrap().unwrap(); if request_line == "GET / HTTP/1.1" { let status_line = "HTTP/1.1 200 OK"; let contents = fs::read_to_string("hello.html").unwrap(); let length = contents.len(); let response = format!( "{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}" ); stream.write_all(response.as_bytes()).unwrap(); // --snip-- } else { let status_line = "HTTP/1.1 404 NOT FOUND"; let contents = fs::read_to_string("404.html").unwrap(); let length = contents.len(); let response = format!( "{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}" ); stream.write_all(response.as_bytes()).unwrap(); } }
Listing 20-7: Responding with status code 404 and an error page if anything other than / was requested
Here, our response has a status line with status code 404 and the reason phrase
NOT FOUND. The body of the response will be the HTML in the file 404.html.
You’ll need to create a 404.html file next to hello.html for the error
page; again feel free to use any HTML you want or use the example HTML in
Listing 20-8.
Filename: 404.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hello!</title>
</head>
<body>
<h1>Oops!</h1>
<p>Sorry, I don't know what you're asking for.</p>
</body>
</html>
Listing 20-8: Sample content for the page to send back with any 404 response
With these changes, run your server again. Requesting 127.0.0.1:7878 should return the contents of hello.html, and any other request, like 127.0.0.1:7878/foo, should return the error HTML from 404.html.
A Touch of Refactoring
At the moment the if and else blocks have a lot of repetition: they’re both
reading files and writing the contents of the files to the stream. The only
differences are the status line and the filename. Let’s make the code more
concise by pulling out those differences into separate if and else lines
that will assign the values of the status line and the filename to variables;
we can then use those variables unconditionally in the code to read the file
and write the response. Listing 20-9 shows the resulting code after replacing
the large if and else blocks.
Filename: src/main.rs
use std::{ fs, io::{prelude::*, BufReader}, net::{TcpListener, TcpStream}, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } // --snip-- fn handle_connection(mut stream: TcpStream) { // --snip-- let buf_reader = BufReader::new(&mut stream); let request_line = buf_reader.lines().next().unwrap().unwrap(); let (status_line, filename) = if request_line == "GET / HTTP/1.1" { ("HTTP/1.1 200 OK", "hello.html") } else { ("HTTP/1.1 404 NOT FOUND", "404.html") }; let contents = fs::read_to_string(filename).unwrap(); let length = contents.len(); let response = format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"); stream.write_all(response.as_bytes()).unwrap(); }
Listing 20-9: Refactoring the if and else blocks to
contain only the code that differs between the two cases
Now the if and else blocks only return the appropriate values for the
status line and filename in a tuple; we then use destructuring to assign these
two values to status_line and filename using a pattern in the let
statement, as discussed in Chapter 18.
The previously duplicated code is now outside the if and else blocks and
uses the status_line and filename variables. This makes it easier to see
the difference between the two cases, and it means we have only one place to
update the code if we want to change how the file reading and response writing
work. The behavior of the code in Listing 20-9 will be the same as that in
Listing 20-8.
Awesome! We now have a simple web server in approximately 40 lines of Rust code that responds to one request with a page of content and responds to all other requests with a 404 response.
Currently, our server runs in a single thread, meaning it can only serve one request at a time. Let’s examine how that can be a problem by simulating some slow requests. Then we’ll fix it so our server can handle multiple requests at once.
Turning Our Single-Threaded Server into a Multithreaded Server
Right now, the server will process each request in turn, meaning it won’t process a second connection until the first is finished processing. If the server received more and more requests, this serial execution would be less and less optimal. If the server receives a request that takes a long time to process, subsequent requests will have to wait until the long request is finished, even if the new requests can be processed quickly. We’ll need to fix this, but first, we’ll look at the problem in action.
Simulating a Slow Request in the Current Server Implementation
We’ll look at how a slow-processing request can affect other requests made to our current server implementation. Listing 20-10 implements handling a request to /sleep with a simulated slow response that will cause the server to sleep for 5 seconds before responding.
Filename: src/main.rs
use std::{ fs, io::{prelude::*, BufReader}, net::{TcpListener, TcpStream}, thread, time::Duration, }; // --snip-- fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } fn handle_connection(mut stream: TcpStream) { // --snip-- let buf_reader = BufReader::new(&mut stream); let request_line = buf_reader.lines().next().unwrap().unwrap(); let (status_line, filename) = match &request_line[..] { "GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"), "GET /sleep HTTP/1.1" => { thread::sleep(Duration::from_secs(5)); ("HTTP/1.1 200 OK", "hello.html") } _ => ("HTTP/1.1 404 NOT FOUND", "404.html"), }; // --snip-- let contents = fs::read_to_string(filename).unwrap(); let length = contents.len(); let response = format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"); stream.write_all(response.as_bytes()).unwrap(); }
Listing 20-10: Simulating a slow request by sleeping for 5 seconds
We switched from if to match now that we have three cases. We need to
explicitly match on a slice of request_line to pattern match against the
string literal values; match doesn’t do automatic referencing and
dereferencing like the equality method does.
The first arm is the same as the if block from Listing 20-9. The second arm
matches a request to /sleep. When that request is received, the server will
sleep for 5 seconds before rendering the successful HTML page. The third arm is
the same as the else block from Listing 20-9.
You can see how primitive our server is: real libraries would handle the recognition of multiple requests in a much less verbose way!
Start the server using cargo run. Then open two browser windows: one for
http://127.0.0.1:7878/ and the other for http://127.0.0.1:7878/sleep. If
you enter the / URI a few times, as before, you’ll see it respond quickly.
But if you enter /sleep and then load /, you’ll see that / waits until
sleep has slept for its full 5 seconds before loading.
There are multiple techniques we could use to avoid requests backing up behind a slow request; the one we’ll implement is a thread pool.
Improving Throughput with a Thread Pool
A thread pool is a group of spawned threads that are waiting and ready to handle a task. When the program receives a new task, it assigns one of the threads in the pool to the task, and that thread will process the task. The remaining threads in the pool are available to handle any other tasks that come in while the first thread is processing. When the first thread is done processing its task, it’s returned to the pool of idle threads, ready to handle a new task. A thread pool allows you to process connections concurrently, increasing the throughput of your server.
We’ll limit the number of threads in the pool to a small number to protect us from Denial of Service (DoS) attacks; if we had our program create a new thread for each request as it came in, someone making 10 million requests to our server could create havoc by using up all our server’s resources and grinding the processing of requests to a halt.
Rather than spawning unlimited threads, then, we’ll have a fixed number of
threads waiting in the pool. Requests that come in are sent to the pool for
processing. The pool will maintain a queue of incoming requests. Each of the
threads in the pool will pop off a request from this queue, handle the request,
and then ask the queue for another request. With this design, we can process up
to N requests concurrently, where N is the number of threads. If each
thread is responding to a long-running request, subsequent requests can still
back up in the queue, but we’ve increased the number of long-running requests
we can handle before reaching that point.
This technique is just one of many ways to improve the throughput of a web server. Other options you might explore are the fork/join model, the single-threaded async I/O model, or the multi-threaded async I/O model. If you’re interested in this topic, you can read more about other solutions and try to implement them; with a low-level language like Rust, all of these options are possible.
Before we begin implementing a thread pool, let’s talk about what using the pool should look like. When you’re trying to design code, writing the client interface first can help guide your design. Write the API of the code so it’s structured in the way you want to call it; then implement the functionality within that structure rather than implementing the functionality and then designing the public API.
Similar to how we used test-driven development in the project in Chapter 12, we’ll use compiler-driven development here. We’ll write the code that calls the functions we want, and then we’ll look at errors from the compiler to determine what we should change next to get the code to work. Before we do that, however, we’ll explore the technique we’re not going to use as a starting point.
Spawning a Thread for Each Request
First, let’s explore how our code might look if it did create a new thread for
every connection. As mentioned earlier, this isn’t our final plan due to the
problems with potentially spawning an unlimited number of threads, but it is a
starting point to get a working multithreaded server first. Then we’ll add the
thread pool as an improvement, and contrasting the two solutions will be
easier. Listing 20-11 shows the changes to make to main to spawn a new thread
to handle each stream within the for loop.
Filename: src/main.rs
use std::{ fs, io::{prelude::*, BufReader}, net::{TcpListener, TcpStream}, thread, time::Duration, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); thread::spawn(|| { handle_connection(stream); }); } } fn handle_connection(mut stream: TcpStream) { let buf_reader = BufReader::new(&mut stream); let request_line = buf_reader.lines().next().unwrap().unwrap(); let (status_line, filename) = match &request_line[..] { "GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"), "GET /sleep HTTP/1.1" => { thread::sleep(Duration::from_secs(5)); ("HTTP/1.1 200 OK", "hello.html") } _ => ("HTTP/1.1 404 NOT FOUND", "404.html"), }; let contents = fs::read_to_string(filename).unwrap(); let length = contents.len(); let response = format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"); stream.write_all(response.as_bytes()).unwrap(); }
Listing 20-11: Spawning a new thread for each stream
As you learned in Chapter 16, thread::spawn will create a new thread and then
run the code in the closure in the new thread. If you run this code and load
/sleep in your browser, then / in two more browser tabs, you’ll indeed see
that the requests to / don’t have to wait for /sleep to finish. However, as
we mentioned, this will eventually overwhelm the system because you’d be making
new threads without any limit.
Creating a Finite Number of Threads
We want our thread pool to work in a similar, familiar way so switching from
threads to a thread pool doesn’t require large changes to the code that uses
our API. Listing 20-12 shows the hypothetical interface for a ThreadPool
struct we want to use instead of thread::spawn.
Filename: src/main.rs
use std::{
fs,
io::{prelude::*, BufReader},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming() {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&mut stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}Listing 20-12: Our ideal ThreadPool interface
We use ThreadPool::new to create a new thread pool with a configurable number
of threads, in this case four. Then, in the for loop, pool.execute has a
similar interface as thread::spawn in that it takes a closure the pool should
run for each stream. We need to implement pool.execute so it takes the
closure and gives it to a thread in the pool to run. This code won’t yet
compile, but we’ll try so the compiler can guide us in how to fix it.
Building ThreadPool Using Compiler Driven Development
Make the changes in Listing 20-12 to src/main.rs, and then let’s use the
compiler errors from cargo check to drive our development. Here is the first
error we get:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0433]: failed to resolve: use of undeclared type `ThreadPool`
--> src/main.rs:11:16
|
11 | let pool = ThreadPool::new(4);
| ^^^^^^^^^^ use of undeclared type `ThreadPool`
For more information about this error, try `rustc --explain E0433`.
error: could not compile `hello` due to previous error
Great! This error tells us we need a ThreadPool type or module, so we’ll
build one now. Our ThreadPool implementation will be independent of the kind
of work our web server is doing. So, let’s switch the hello crate from a
binary crate to a library crate to hold our ThreadPool implementation. After
we change to a library crate, we could also use the separate thread pool
library for any work we want to do using a thread pool, not just for serving
web requests.
Create a src/lib.rs that contains the following, which is the simplest
definition of a ThreadPool struct that we can have for now:
Filename: src/lib.rs
pub struct ThreadPool;Then edit main.rs file to bring ThreadPool into scope from the library
crate by adding the following code to the top of src/main.rs:
Filename: src/main.rs
use hello::ThreadPool;
use std::{
fs,
io::{prelude::*, BufReader},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming() {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&mut stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}This code still won’t work, but let’s check it again to get the next error that we need to address:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0599]: no function or associated item named `new` found for struct `ThreadPool` in the current scope
--> src/main.rs:12:28
|
12 | let pool = ThreadPool::new(4);
| ^^^ function or associated item not found in `ThreadPool`
For more information about this error, try `rustc --explain E0599`.
error: could not compile `hello` due to previous error
This error indicates that next we need to create an associated function named
new for ThreadPool. We also know that new needs to have one parameter
that can accept 4 as an argument and should return a ThreadPool instance.
Let’s implement the simplest new function that will have those
characteristics:
Filename: src/lib.rs
pub struct ThreadPool;
impl ThreadPool {
pub fn new(size: usize) -> ThreadPool {
ThreadPool
}
}We chose usize as the type of the size parameter, because we know that a
negative number of threads doesn’t make any sense. We also know we’ll use this
4 as the number of elements in a collection of threads, which is what the
usize type is for, as discussed in the “Integer Types” section of Chapter 3.
Let’s check the code again:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0599]: no method named `execute` found for struct `ThreadPool` in the current scope
--> src/main.rs:17:14
|
17 | pool.execute(|| {
| ^^^^^^^ method not found in `ThreadPool`
For more information about this error, try `rustc --explain E0599`.
error: could not compile `hello` due to previous error
Now the error occurs because we don’t have an execute method on ThreadPool.
Recall from the “Creating a Finite Number of
Threads” section that we
decided our thread pool should have an interface similar to thread::spawn. In
addition, we’ll implement the execute function so it takes the closure it’s
given and gives it to an idle thread in the pool to run.
We’ll define the execute method on ThreadPool to take a closure as a
parameter. Recall from the “Moving Captured Values Out of the Closure and the
Fn Traits” section in Chapter 13 that we can take
closures as parameters with three different traits: Fn, FnMut, and
FnOnce. We need to decide which kind of closure to use here. We know we’ll
end up doing something similar to the standard library thread::spawn
implementation, so we can look at what bounds the signature of thread::spawn
has on its parameter. The documentation shows us the following:
pub fn spawn<F, T>(f: F) -> JoinHandle<T>
where
F: FnOnce() -> T,
F: Send + 'static,
T: Send + 'static,The F type parameter is the one we’re concerned with here; the T type
parameter is related to the return value, and we’re not concerned with that. We
can see that spawn uses FnOnce as the trait bound on F. This is probably
what we want as well, because we’ll eventually pass the argument we get in
execute to spawn. We can be further confident that FnOnce is the trait we
want to use because the thread for running a request will only execute that
request’s closure one time, which matches the Once in FnOnce.
The F type parameter also has the trait bound Send and the lifetime bound
'static, which are useful in our situation: we need Send to transfer the
closure from one thread to another and 'static because we don’t know how long
the thread will take to execute. Let’s create an execute method on
ThreadPool that will take a generic parameter of type F with these bounds:
Filename: src/lib.rs
pub struct ThreadPool;
impl ThreadPool {
// --snip--
pub fn new(size: usize) -> ThreadPool {
ThreadPool
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}We still use the () after FnOnce because this FnOnce represents a closure
that takes no parameters and returns the unit type (). Just like function
definitions, the return type can be omitted from the signature, but even if we
have no parameters, we still need the parentheses.
Again, this is the simplest implementation of the execute method: it does
nothing, but we’re trying only to make our code compile. Let’s check it again:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
Finished dev [unoptimized + debuginfo] target(s) in 0.24s
It compiles! But note that if you try cargo run and make a request in the
browser, you’ll see the errors in the browser that we saw at the beginning of
the chapter. Our library isn’t actually calling the closure passed to execute
yet!
Note: A saying you might hear about languages with strict compilers, such as Haskell and Rust, is “if the code compiles, it works.” But this saying is not universally true. Our project compiles, but it does absolutely nothing! If we were building a real, complete project, this would be a good time to start writing unit tests to check that the code compiles and has the behavior we want.
Validating the Number of Threads in new
We aren’t doing anything with the parameters to new and execute. Let’s
implement the bodies of these functions with the behavior we want. To start,
let’s think about new. Earlier we chose an unsigned type for the size
parameter, because a pool with a negative number of threads makes no sense.
However, a pool with zero threads also makes no sense, yet zero is a perfectly
valid usize. We’ll add code to check that size is greater than zero before
we return a ThreadPool instance and have the program panic if it receives a
zero by using the assert! macro, as shown in Listing 20-13.
Filename: src/lib.rs
pub struct ThreadPool;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
ThreadPool
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}Listing 20-13: Implementing ThreadPool::new to panic if
size is zero
We’ve also added some documentation for our ThreadPool with doc comments.
Note that we followed good documentation practices by adding a section that
calls out the situations in which our function can panic, as discussed in
Chapter 14. Try running cargo doc --open and clicking the ThreadPool struct
to see what the generated docs for new look like!
Instead of adding the assert! macro as we’ve done here, we could change new
into build and return a Result like we did with Config::build in the I/O
project in Listing 12-9. But we’ve decided in this case that trying to create a
thread pool without any threads should be an unrecoverable error. If you’re
feeling ambitious, try to write a function named build with the following
signature to compare with the new function:
pub fn build(size: usize) -> Result<ThreadPool, PoolCreationError> {Creating Space to Store the Threads
Now that we have a way to know we have a valid number of threads to store in
the pool, we can create those threads and store them in the ThreadPool struct
before returning the struct. But how do we “store” a thread? Let’s take another
look at the thread::spawn signature:
pub fn spawn<F, T>(f: F) -> JoinHandle<T>
where
F: FnOnce() -> T,
F: Send + 'static,
T: Send + 'static,The spawn function returns a JoinHandle<T>, where T is the type that the
closure returns. Let’s try using JoinHandle too and see what happens. In our
case, the closures we’re passing to the thread pool will handle the connection
and not return anything, so T will be the unit type ().
The code in Listing 20-14 will compile but doesn’t create any threads yet.
We’ve changed the definition of ThreadPool to hold a vector of
thread::JoinHandle<()> instances, initialized the vector with a capacity of
size, set up a for loop that will run some code to create the threads, and
returned a ThreadPool instance containing them.
Filename: src/lib.rs
use std::thread;
pub struct ThreadPool {
threads: Vec<thread::JoinHandle<()>>,
}
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let mut threads = Vec::with_capacity(size);
for _ in 0..size {
// create some threads and store them in the vector
}
ThreadPool { threads }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}Listing 20-14: Creating a vector for ThreadPool to hold
the threads
We’ve brought std::thread into scope in the library crate, because we’re
using thread::JoinHandle as the type of the items in the vector in
ThreadPool.
Once a valid size is received, our ThreadPool creates a new vector that can
hold size items. The with_capacity function performs the same task as
Vec::new but with an important difference: it preallocates space in the
vector. Because we know we need to store size elements in the vector, doing
this allocation up front is slightly more efficient than using Vec::new,
which resizes itself as elements are inserted.
When you run cargo check again, it should succeed.
A Worker Struct Responsible for Sending Code from the ThreadPool to a Thread
We left a comment in the for loop in Listing 20-14 regarding the creation of
threads. Here, we’ll look at how we actually create threads. The standard
library provides thread::spawn as a way to create threads, and
thread::spawn expects to get some code the thread should run as soon as the
thread is created. However, in our case, we want to create the threads and have
them wait for code that we’ll send later. The standard library’s
implementation of threads doesn’t include any way to do that; we have to
implement it manually.
We’ll implement this behavior by introducing a new data structure between the
ThreadPool and the threads that will manage this new behavior. We’ll call
this data structure Worker, which is a common term in pooling
implementations. The Worker picks up code that needs to be run and runs the
code in the Worker’s thread. Think of people working in the kitchen at a
restaurant: the workers wait until orders come in from customers, and then
they’re responsible for taking those orders and fulfilling them.
Instead of storing a vector of JoinHandle<()> instances in the thread pool,
we’ll store instances of the Worker struct. Each Worker will store a single
JoinHandle<()> instance. Then we’ll implement a method on Worker that will
take a closure of code to run and send it to the already running thread for
execution. We’ll also give each worker an id so we can distinguish between
the different workers in the pool when logging or debugging.
Here is the new process that will happen when we create a ThreadPool. We’ll
implement the code that sends the closure to the thread after we have Worker
set up in this way:
- Define a
Workerstruct that holds anidand aJoinHandle<()>. - Change
ThreadPoolto hold a vector ofWorkerinstances. - Define a
Worker::newfunction that takes anidnumber and returns aWorkerinstance that holds theidand a thread spawned with an empty closure. - In
ThreadPool::new, use theforloop counter to generate anid, create a newWorkerwith thatid, and store the worker in the vector.
If you’re up for a challenge, try implementing these changes on your own before looking at the code in Listing 20-15.
Ready? Here is Listing 20-15 with one way to make the preceding modifications.
Filename: src/lib.rs
use std::thread;
pub struct ThreadPool {
workers: Vec<Worker>,
}
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id));
}
ThreadPool { workers }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize) -> Worker {
let thread = thread::spawn(|| {});
Worker { id, thread }
}
}Listing 20-15: Modifying ThreadPool to hold Worker
instances instead of holding threads directly
We’ve changed the name of the field on ThreadPool from threads to workers
because it’s now holding Worker instances instead of JoinHandle<()>
instances. We use the counter in the for loop as an argument to
Worker::new, and we store each new Worker in the vector named workers.
External code (like our server in src/main.rs) doesn’t need to know the
implementation details regarding using a Worker struct within ThreadPool,
so we make the Worker struct and its new function private. The
Worker::new function uses the id we give it and stores a JoinHandle<()>
instance that is created by spawning a new thread using an empty closure.
Note: If the operating system can’t create a thread because there aren’t enough system resources,
thread::spawnwill panic. That will cause our whole server to panic, even though the creation of some threads might succeed. For simplicity’s sake, this behavior is fine, but in a production thread pool implementation, you’d likely want to usestd::thread::Builderand itsspawnmethod that returnsResultinstead.
This code will compile and will store the number of Worker instances we
specified as an argument to ThreadPool::new. But we’re still not processing
the closure that we get in execute. Let’s look at how to do that next.
Sending Requests to Threads via Channels
The next problem we’ll tackle is that the closures given to thread::spawn do
absolutely nothing. Currently, we get the closure we want to execute in the
execute method. But we need to give thread::spawn a closure to run when we
create each Worker during the creation of the ThreadPool.
We want the Worker structs that we just created to fetch the code to run from
a queue held in the ThreadPool and send that code to its thread to run.
The channels we learned about in Chapter 16—a simple way to communicate between
two threads—would be perfect for this use case. We’ll use a channel to function
as the queue of jobs, and execute will send a job from the ThreadPool to
the Worker instances, which will send the job to its thread. Here is the plan:
- The
ThreadPoolwill create a channel and hold on to the sender. - Each
Workerwill hold on to the receiver. - We’ll create a new
Jobstruct that will hold the closures we want to send down the channel. - The
executemethod will send the job it wants to execute through the sender. - In its thread, the
Workerwill loop over its receiver and execute the closures of any jobs it receives.
Let’s start by creating a channel in ThreadPool::new and holding the sender
in the ThreadPool instance, as shown in Listing 20-16. The Job struct
doesn’t hold anything for now but will be the type of item we’re sending down
the channel.
Filename: src/lib.rs
use std::{sync::mpsc, thread};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
struct Job;
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id));
}
ThreadPool { workers, sender }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize) -> Worker {
let thread = thread::spawn(|| {});
Worker { id, thread }
}
}Listing 20-16: Modifying ThreadPool to store the
sender of a channel that transmits Job instances
In ThreadPool::new, we create our new channel and have the pool hold the
sender. This will successfully compile.
Let’s try passing a receiver of the channel into each worker as the thread pool
creates the channel. We know we want to use the receiver in the thread that the
workers spawn, so we’ll reference the receiver parameter in the closure. The
code in Listing 20-17 won’t quite compile yet.
Filename: src/lib.rs
use std::{sync::mpsc, thread};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
struct Job;
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, receiver));
}
ThreadPool { workers, sender }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
// --snip--
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: mpsc::Receiver<Job>) -> Worker {
let thread = thread::spawn(|| {
receiver;
});
Worker { id, thread }
}
}Listing 20-17: Passing the receiver to the workers
We’ve made some small and straightforward changes: we pass the receiver into
Worker::new, and then we use it inside the closure.
When we try to check this code, we get this error:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0382]: use of moved value: `receiver`
--> src/lib.rs:26:42
|
21 | let (sender, receiver) = mpsc::channel();
| -------- move occurs because `receiver` has type `std::sync::mpsc::Receiver<Job>`, which does not implement the `Copy` trait
...
26 | workers.push(Worker::new(id, receiver));
| ^^^^^^^^ value moved here, in previous iteration of loop
For more information about this error, try `rustc --explain E0382`.
error: could not compile `hello` due to previous error
The code is trying to pass receiver to multiple Worker instances. This
won’t work, as you’ll recall from Chapter 16: the channel implementation that
Rust provides is multiple producer, single consumer. This means we can’t
just clone the consuming end of the channel to fix this code. We also don’t
want to send a message multiple times to multiple consumers; we want one list
of messages with multiple workers such that each message gets processed once.
Additionally, taking a job off the channel queue involves mutating the
receiver, so the threads need a safe way to share and modify receiver;
otherwise, we might get race conditions (as covered in Chapter 16).
Recall the thread-safe smart pointers discussed in Chapter 16: to share
ownership across multiple threads and allow the threads to mutate the value, we
need to use Arc<Mutex<T>>. The Arc type will let multiple workers own the
receiver, and Mutex will ensure that only one worker gets a job from the
receiver at a time. Listing 20-18 shows the changes we need to make.
Filename: src/lib.rs
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
// --snip--
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
struct Job;
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
// --snip--
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
// --snip--
let thread = thread::spawn(|| {
receiver;
});
Worker { id, thread }
}
}Listing 20-18: Sharing the receiver among the workers
using Arc and Mutex
In ThreadPool::new, we put the receiver in an Arc and a Mutex. For each
new worker, we clone the Arc to bump the reference count so the workers can
share ownership of the receiver.
With these changes, the code compiles! We’re getting there!
Implementing the execute Method
Let’s finally implement the execute method on ThreadPool. We’ll also change
Job from a struct to a type alias for a trait object that holds the type of
closure that execute receives. As discussed in the “Creating Type Synonyms
with Type Aliases”
section of Chapter 19, type aliases allow us to make long types shorter for
ease of use. Look at Listing 20-19.
Filename: src/lib.rs
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
// --snip--
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
// --snip--
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(|| {
receiver;
});
Worker { id, thread }
}
}Listing 20-19: Creating a Job type alias for a Box
that holds each closure and then sending the job down the channel
After creating a new Job instance using the closure we get in execute, we
send that job down the sending end of the channel. We’re calling unwrap on
send for the case that sending fails. This might happen if, for example, we
stop all our threads from executing, meaning the receiving end has stopped
receiving new messages. At the moment, we can’t stop our threads from
executing: our threads continue executing as long as the pool exists. The
reason we use unwrap is that we know the failure case won’t happen, but the
compiler doesn’t know that.
But we’re not quite done yet! In the worker, our closure being passed to
thread::spawn still only references the receiving end of the channel.
Instead, we need the closure to loop forever, asking the receiving end of the
channel for a job and running the job when it gets one. Let’s make the change
shown in Listing 20-20 to Worker::new.
Filename: src/lib.rs
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
// --snip--
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
});
Worker { id, thread }
}
}Listing 20-20: Receiving and executing the jobs in the worker’s thread
Here, we first call lock on the receiver to acquire the mutex, and then we
call unwrap to panic on any errors. Acquiring a lock might fail if the mutex
is in a poisoned state, which can happen if some other thread panicked while
holding the lock rather than releasing the lock. In this situation, calling
unwrap to have this thread panic is the correct action to take. Feel free to
change this unwrap to an expect with an error message that is meaningful to
you.
If we get the lock on the mutex, we call recv to receive a Job from the
channel. A final unwrap moves past any errors here as well, which might occur
if the thread holding the sender has shut down, similar to how the send
method returns Err if the receiver shuts down.
The call to recv blocks, so if there is no job yet, the current thread will
wait until a job becomes available. The Mutex<T> ensures that only one
Worker thread at a time is trying to request a job.
Our thread pool is now in a working state! Give it a cargo run and make some
requests:
$ cargo run
Compiling hello v0.1.0 (file:///projects/hello)
warning: field is never read: `workers`
--> src/lib.rs:7:5
|
7 | workers: Vec<Worker>,
| ^^^^^^^^^^^^^^^^^^^^
|
= note: `#[warn(dead_code)]` on by default
warning: field is never read: `id`
--> src/lib.rs:48:5
|
48 | id: usize,
| ^^^^^^^^^
warning: field is never read: `thread`
--> src/lib.rs:49:5
|
49 | thread: thread::JoinHandle<()>,
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
warning: `hello` (lib) generated 3 warnings
Finished dev [unoptimized + debuginfo] target(s) in 1.40s
Running `target/debug/hello`
Worker 0 got a job; executing.
Worker 2 got a job; executing.
Worker 1 got a job; executing.
Worker 3 got a job; executing.
Worker 0 got a job; executing.
Worker 2 got a job; executing.
Worker 1 got a job; executing.
Worker 3 got a job; executing.
Worker 0 got a job; executing.
Worker 2 got a job; executing.
Success! We now have a thread pool that executes connections asynchronously. There are never more than four threads created, so our system won’t get overloaded if the server receives a lot of requests. If we make a request to /sleep, the server will be able to serve other requests by having another thread run them.
Note: if you open /sleep in multiple browser windows simultaneously, they might load one at a time in 5 second intervals. Some web browsers execute multiple instances of the same request sequentially for caching reasons. This limitation is not caused by our web server.
After learning about the while let loop in Chapter 18, you might be wondering
why we didn’t write the worker thread code as shown in Listing 20-21.
Filename: src/lib.rs
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
// --snip--
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
while let Ok(job) = receiver.lock().unwrap().recv() {
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}Listing 20-21: An alternative implementation of
Worker::new using while let
This code compiles and runs but doesn’t result in the desired threading
behavior: a slow request will still cause other requests to wait to be
processed. The reason is somewhat subtle: the Mutex struct has no public
unlock method because the ownership of the lock is based on the lifetime of
the MutexGuard<T> within the LockResult<MutexGuard<T>> that the lock
method returns. At compile time, the borrow checker can then enforce the rule
that a resource guarded by a Mutex cannot be accessed unless we hold the
lock. However, this implementation can also result in the lock being held
longer than intended if we aren’t mindful of the lifetime of the
MutexGuard<T>.
The code in Listing 20-20 that uses let job = receiver.lock().unwrap().recv().unwrap(); works because with let, any
temporary values used in the expression on the right hand side of the equals
sign are immediately dropped when the let statement ends. However, while let (and if let and match) does not drop temporary values until the end of
the associated block. In Listing 20-21, the lock remains held for the duration
of the call to job(), meaning other workers cannot receive jobs.
Graceful Shutdown and Cleanup
The code in Listing 20-20 is responding to requests asynchronously through the
use of a thread pool, as we intended. We get some warnings about the workers,
id, and thread fields that we’re not using in a direct way that reminds us
we’re not cleaning up anything. When we use the less elegant ctrl-c method to halt the main thread, all other
threads are stopped immediately as well, even if they’re in the middle of
serving a request.
Next, then, we’ll implement the Drop trait to call join on each of the
threads in the pool so they can finish the requests they’re working on before
closing. Then we’ll implement a way to tell the threads they should stop
accepting new requests and shut down. To see this code in action, we’ll modify
our server to accept only two requests before gracefully shutting down its
thread pool.
Implementing the Drop Trait on ThreadPool
Let’s start with implementing Drop on our thread pool. When the pool is
dropped, our threads should all join to make sure they finish their work.
Listing 20-22 shows a first attempt at a Drop implementation; this code won’t
quite work yet.
Filename: src/lib.rs
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
});
Worker { id, thread }
}
}Listing 20-22: Joining each thread when the thread pool goes out of scope
First, we loop through each of the thread pool workers. We use &mut for
this because self is a mutable reference, and we also need to be able to
mutate worker. For each worker, we print a message saying that this
particular worker is shutting down, and then we call join on that worker’s
thread. If the call to join fails, we use unwrap to make Rust panic and go
into an ungraceful shutdown.
Here is the error we get when we compile this code:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0507]: cannot move out of `worker.thread` which is behind a mutable reference
--> src/lib.rs:52:13
|
52 | worker.thread.join().unwrap();
| ^^^^^^^^^^^^^ ------ `worker.thread` moved due to this method call
| |
| move occurs because `worker.thread` has type `JoinHandle<()>`, which does not implement the `Copy` trait
|
note: this function takes ownership of the receiver `self`, which moves `worker.thread`
--> /rustc/d5a82bbd26e1ad8b7401f6a718a9c57c96905483/library/std/src/thread/mod.rs:1581:17
For more information about this error, try `rustc --explain E0507`.
error: could not compile `hello` due to previous error
The error tells us we can’t call join because we only have a mutable borrow
of each worker and join takes ownership of its argument. To solve this
issue, we need to move the thread out of the Worker instance that owns
thread so join can consume the thread. We did this in Listing 17-15: if
Worker holds an Option<thread::JoinHandle<()>> instead, we can call the
take method on the Option to move the value out of the Some variant and
leave a None variant in its place. In other words, a Worker that is running
will have a Some variant in thread, and when we want to clean up a
Worker, we’ll replace Some with None so the Worker doesn’t have a
thread to run.
So we know we want to update the definition of Worker like this:
Filename: src/lib.rs
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: Option<thread::JoinHandle<()>>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
});
Worker { id, thread }
}
}Now let’s lean on the compiler to find the other places that need to change. Checking this code, we get two errors:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0599]: no method named `join` found for enum `Option` in the current scope
--> src/lib.rs:52:27
|
52 | worker.thread.join().unwrap();
| ^^^^ method not found in `Option<JoinHandle<()>>`
|
note: the method `join` exists on the type `JoinHandle<()>`
--> /rustc/d5a82bbd26e1ad8b7401f6a718a9c57c96905483/library/std/src/thread/mod.rs:1581:5
help: consider using `Option::expect` to unwrap the `JoinHandle<()>` value, panicking if the value is an `Option::None`
|
52 | worker.thread.expect("REASON").join().unwrap();
| +++++++++++++++++
error[E0308]: mismatched types
--> src/lib.rs:72:22
|
72 | Worker { id, thread }
| ^^^^^^ expected enum `Option`, found struct `JoinHandle`
|
= note: expected enum `Option<JoinHandle<()>>`
found struct `JoinHandle<_>`
help: try wrapping the expression in `Some`
|
72 | Worker { id, thread: Some(thread) }
| +++++++++++++ +
Some errors have detailed explanations: E0308, E0599.
For more information about an error, try `rustc --explain E0308`.
error: could not compile `hello` due to 2 previous errors
Let’s address the second error, which points to the code at the end of
Worker::new; we need to wrap the thread value in Some when we create a
new Worker. Make the following changes to fix this error:
Filename: src/lib.rs
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: Option<thread::JoinHandle<()>>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
// --snip--
let thread = thread::spawn(move || loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
});
Worker {
id,
thread: Some(thread),
}
}
}The first error is in our Drop implementation. We mentioned earlier that we
intended to call take on the Option value to move thread out of worker.
The following changes will do so:
Filename: src/lib.rs
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
if let Some(thread) = worker.thread.take() {
thread.join().unwrap();
}
}
}
}
struct Worker {
id: usize,
thread: Option<thread::JoinHandle<()>>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
});
Worker {
id,
thread: Some(thread),
}
}
}As discussed in Chapter 17, the take method on Option takes the Some
variant out and leaves None in its place. We’re using if let to destructure
the Some and get the thread; then we call join on the thread. If a worker’s
thread is already None, we know that worker has already had its thread
cleaned up, so nothing happens in that case.
Signaling to the Threads to Stop Listening for Jobs
With all the changes we’ve made, our code compiles without any warnings.
However, the bad news is this code doesn’t function the way we want it to yet.
The key is the logic in the closures run by the threads of the Worker
instances: at the moment, we call join, but that won’t shut down the threads
because they loop forever looking for jobs. If we try to drop our
ThreadPool with our current implementation of drop, the main thread will
block forever waiting for the first thread to finish.
To fix this problem, we’ll need a change in the ThreadPool drop
implementation and then a change in the Worker loop.
First, we’ll change the ThreadPool drop implementation to explicitly drop
the sender before waiting for the threads to finish. Listing 20-23 shows the
changes to ThreadPool to explicitly drop sender. We use the same Option
and take technique as we did with the thread to be able to move sender out
of ThreadPool:
Filename: src/lib.rs
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: Option<mpsc::Sender<Job>>,
}
// --snip--
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
// --snip--
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool {
workers,
sender: Some(sender),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.sender.take());
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
if let Some(thread) = worker.thread.take() {
thread.join().unwrap();
}
}
}
}
struct Worker {
id: usize,
thread: Option<thread::JoinHandle<()>>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
});
Worker {
id,
thread: Some(thread),
}
}
}Listing 20-23: Explicitly drop sender before joining
the worker threads
Dropping sender closes the channel, which indicates no more messages will be
sent. When that happens, all the calls to recv that the workers do in the
infinite loop will return an error. In Listing 20-24, we change the Worker
loop to gracefully exit the loop in that case, which means the threads will
finish when the ThreadPool drop implementation calls join on them.
Filename: src/lib.rs
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: Option<mpsc::Sender<Job>>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool {
workers,
sender: Some(sender),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.sender.take());
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
if let Some(thread) = worker.thread.take() {
thread.join().unwrap();
}
}
}
}
struct Worker {
id: usize,
thread: Option<thread::JoinHandle<()>>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || loop {
let message = receiver.lock().unwrap().recv();
match message {
Ok(job) => {
println!("Worker {id} got a job; executing.");
job();
}
Err(_) => {
println!("Worker {id} disconnected; shutting down.");
break;
}
}
});
Worker {
id,
thread: Some(thread),
}
}
}Listing 20-24: Explicitly break out of the loop when
recv returns an error
To see this code in action, let’s modify main to accept only two requests
before gracefully shutting down the server, as shown in Listing 20-25.
Filename: src/main.rs
use hello::ThreadPool;
use std::fs;
use std::io::prelude::*;
use std::net::TcpListener;
use std::net::TcpStream;
use std::thread;
use std::time::Duration;
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming().take(2) {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
println!("Shutting down.");
}
fn handle_connection(mut stream: TcpStream) {
let mut buffer = [0; 1024];
stream.read(&mut buffer).unwrap();
let get = b"GET / HTTP/1.1\r\n";
let sleep = b"GET /sleep HTTP/1.1\r\n";
let (status_line, filename) = if buffer.starts_with(get) {
("HTTP/1.1 200 OK", "hello.html")
} else if buffer.starts_with(sleep) {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
} else {
("HTTP/1.1 404 NOT FOUND", "404.html")
};
let contents = fs::read_to_string(filename).unwrap();
let response = format!(
"{}\r\nContent-Length: {}\r\n\r\n{}",
status_line,
contents.len(),
contents
);
stream.write_all(response.as_bytes()).unwrap();
stream.flush().unwrap();
}Listing 20-25: Shut down the server after serving two requests by exiting the loop
You wouldn’t want a real-world web server to shut down after serving only two requests. This code just demonstrates that the graceful shutdown and cleanup is in working order.
The take method is defined in the Iterator trait and limits the iteration
to the first two items at most. The ThreadPool will go out of scope at the
end of main, and the drop implementation will run.
Start the server with cargo run, and make three requests. The third request
should error, and in your terminal you should see output similar to this:
$ cargo run
Compiling hello v0.1.0 (file:///projects/hello)
Finished dev [unoptimized + debuginfo] target(s) in 1.0s
Running `target/debug/hello`
Worker 0 got a job; executing.
Shutting down.
Shutting down worker 0
Worker 3 got a job; executing.
Worker 1 disconnected; shutting down.
Worker 2 disconnected; shutting down.
Worker 3 disconnected; shutting down.
Worker 0 disconnected; shutting down.
Shutting down worker 1
Shutting down worker 2
Shutting down worker 3
You might see a different ordering of workers and messages printed. We can see
how this code works from the messages: workers 0 and 3 got the first two
requests. The server stopped accepting connections after the second connection,
and the Drop implementation on ThreadPool starts executing before worker 3
even starts its job. Dropping the sender disconnects all the workers and
tells them to shut down. The workers each print a message when they disconnect,
and then the thread pool calls join to wait for each worker thread to finish.
Notice one interesting aspect of this particular execution: the ThreadPool
dropped the sender, and before any worker received an error, we tried to join
worker 0. Worker 0 had not yet gotten an error from recv, so the main thread
blocked waiting for worker 0 to finish. In the meantime, worker 3 received a
job and then all threads received an error. When worker 0 finished, the main
thread waited for the rest of the workers to finish. At that point, they had
all exited their loops and stopped.
Congrats! We’ve now completed our project; we have a basic web server that uses a thread pool to respond asynchronously. We’re able to perform a graceful shutdown of the server, which cleans up all the threads in the pool.
Here’s the full code for reference:
Filename: src/main.rs
use hello::ThreadPool;
use std::fs;
use std::io::prelude::*;
use std::net::TcpListener;
use std::net::TcpStream;
use std::thread;
use std::time::Duration;
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming().take(2) {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
println!("Shutting down.");
}
fn handle_connection(mut stream: TcpStream) {
let mut buffer = [0; 1024];
stream.read(&mut buffer).unwrap();
let get = b"GET / HTTP/1.1\r\n";
let sleep = b"GET /sleep HTTP/1.1\r\n";
let (status_line, filename) = if buffer.starts_with(get) {
("HTTP/1.1 200 OK", "hello.html")
} else if buffer.starts_with(sleep) {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
} else {
("HTTP/1.1 404 NOT FOUND", "404.html")
};
let contents = fs::read_to_string(filename).unwrap();
let response = format!(
"{}\r\nContent-Length: {}\r\n\r\n{}",
status_line,
contents.len(),
contents
);
stream.write_all(response.as_bytes()).unwrap();
stream.flush().unwrap();
}Filename: src/lib.rs
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: Option<mpsc::Sender<Job>>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool {
workers,
sender: Some(sender),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.sender.take());
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
if let Some(thread) = worker.thread.take() {
thread.join().unwrap();
}
}
}
}
struct Worker {
id: usize,
thread: Option<thread::JoinHandle<()>>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || loop {
let message = receiver.lock().unwrap().recv();
match message {
Ok(job) => {
println!("Worker {id} got a job; executing.");
job();
}
Err(_) => {
println!("Worker {id} disconnected; shutting down.");
break;
}
}
});
Worker {
id,
thread: Some(thread),
}
}
}We could do more here! If you want to continue enhancing this project, here are some ideas:
- Add more documentation to
ThreadPooland its public methods. - Add tests of the library’s functionality.
- Change calls to
unwrapto more robust error handling. - Use
ThreadPoolto perform some task other than serving web requests. - Find a thread pool crate on crates.io and implement a similar web server using the crate instead. Then compare its API and robustness to the thread pool we implemented.
Summary
Well done! You’ve made it to the end of the book! We want to thank you for joining us on this tour of Rust. You’re now ready to implement your own Rust projects and help with other peoples’ projects. Keep in mind that there is a welcoming community of other Rustaceans who would love to help you with any challenges you encounter on your Rust journey.
Ilova
Quyidagi bo'limlarda siz o'zingiz uchun foydali bo'lishi mumkin bo'lgan ma'lumotnomalar mavjud Rust sayohati.
Ilova A: Kalit so'zlar
Quyidagi ro'yxatda Rust tili tomonidan joriy yoki kelajakda foydalanish uchun ajratilgan kalit so'zlar mavjud. Shunday qilib, ularni identifikator sifatida ishlatib bo'lmaydi (raw identifikatorlar bo'limida muhokama qilinadigan “Raw identifikatorlardan” tashqari) Identifikatorlar - bu funksiyalar, o'zgaruvchilar, parametrlar, struct field, modullar, cratelar, konstantalar, macroslar, statik qiymatlar, atributlar, turlar, traitlar yoki lifetimelarining nomlari.
Hozirda foydalanilayotgan kalit so'zlar
Quyida hozirda foydalanilayotgan kalit so‘zlar ro‘yxati keltirilgan, ularning funksiyalari tasvirlangan.
as- primitiv castingni amalga oshiring, elementni o'z ichiga olgan o'ziga xos traitni ajrating yokiusestatementaridagi elementlarning nomini o'zgartiringasync- joriy threadni bloklash o'rnigaFutureni return qilingawait-Futurenatijasi tayyor bo'lgunga qadar executionni to'xtatib turingbreak- zudlik bilan loopdan chiqingconst- konstanta elementlarni yoki konstanta raw pointerlarni aniqlangcontinue- keyingi sikl iteratsiyasiga davom etingcrate- modul yo'lida, crate rootga ishora qiladidyn- trait objectga dinamik jo'natishelse-ifvaif letuchun zaxira control flow konstruksiyalarienum- enumerationni aniqlashextern- tashqi funksiya yoki o‘zgaruvchini bog‘lashfalse- Boolean false(noto'g'ri) so'zfn- funksiya yoki funktsiya pointer turini aniqlangfor- iteratordagi elementlarni ko'rib chiqing, implement trait yoki yuqori darajali lifetimeni belgilangif- shartli expression natijasiga asoslangan branchimpl- o'ziga inherent yoki trait funksionalligini implementin-forsikl sintaksisining bir qismilet- o'zgaruvchini bog'lashloop- shartsiz loopmatch- qiymatni patternlarga moslashtirishmod- modulni aniqlashmove- make a closure take ownership of all its capturesmut- reference, raw pointerlar yoki pattern bindingdagi o'zgaruvchanlikni bildiradipub- struct fieldlarida,implbloklarida yoki modullarda ommaviy ko'rinishni bildiradiref- reference orqali bog'lashreturn- funksiyadan qaytish(return)Self- biz belgilayotgan yoki implement qilayotgan tur uchun turdagi aliasself- metod mavzusi yoki joriy modulstatic- global o'zgaruvchi yoki butun dasturning bajarilishi uchun lifetimestruct- structurani aniqlashsuper- joriy modulning parent modulitrait- traitni aniqlashtrue- Boolean true(to'g'ri) so'ztype- turdagi alias yoki associated turni aniqlashunion- define a union; is only a keyword when used in a union declarationunsafe- xavfli kod, funksiyalar, traitlar yoki implementationlarni bildiradiuse- bring symbols into scopewhere- denote clauses that constrain a typewhile- expression natijasi asosida shartli ravishda sikl
Kelajakda foydalanish uchun ajratilgan kalit so'zlar
Quyidagi kalit so'zlar hali hech qanday funksiyaga ega emas, lekin kelajakda foydalanish uchun Rust tomonidan zahiralangan.
abstractbecomeboxdofinalmacrooverrideprivtrytypeofunsizedvirtualyield
Raw identifikatorlar
Raw identifikatorlar odatda ruxsat berilmaydigan kalit so'zlardan foydalanish imkonini beruvchi sintaksisdir. Kalit so‘z oldiga r# qo‘yish orqali raw identifikatordan foydalanasiz.
Masalan, match kalit so'zdir. Agar siz o'z nomi sifatida match dan foydalanadigan quyidagi funksiyani kompilyatsiya qilmoqchi bo'lsangiz:
Fayl nomi: src/main.rs
fn match(needle: &str, haystack: &str) -> bool {
haystack.contains(needle)
}you’ll get this error:
error: expected identifier, found keyword `match`
--> src/main.rs:4:4
|
4 | fn match(needle: &str, haystack: &str) -> bool {
| ^^^^^ expected identifier, found keyword
Xato, funksiya identifikatori sifatida match kalit so‘zidan foydalana olmasligingizni ko‘rsatadi. Funksiya nomi sifatida match dan foydalanish uchun siz raw identifikator sintaksisidan foydalanishingiz kerak, masalan:
Fayl nomi: src/main.rs
fn r#match(needle: &str, haystack: &str) -> bool { haystack.contains(needle) } fn main() { assert!(r#match("foo", "foobar")); }
Ushbu kod hech qanday xatosiz kompilyatsiya qilinadi. Funksiya nomidagi r# prefiksi uning taʼrifida, shuningdek, funksiya mainda chaqirilgan joyiga eʼtibor bering.
Raw identifikatorlari identifikator sifatida tanlagan har qanday so'zdan foydalanishga imkon beradi, hatto bu so'z zahiradagi kalit so'z bo'lsa ham. Bu bizga identifikator nomlarini tanlashda ko'proq erkinlik beradi, shuningdek, bu so'zlar kalit so'zlar bo'lmagan tilda yozilgan dasturlar bilan integratsiyalashish imkonini beradi. Bunga qo'shimcha ravishda, raw identifikatorlar sizga cratetagidan boshqa Rust nashrida yozilgan kutubxonalardan foydalanish imkonini beradi. Misol uchun, try 2015 yilgi nashrda kalit so'z emas, balki 2018 yilgi nashrda mavjud. Agar siz 2015-yil nashri yordamida yozilgan kutubxonaga bogʻliq boʻlsangiz va try funksiyasiga ega boʻlsangiz, bu funksiyani 2018-yilgi nashr kodingizdan chaqirish uchun r#try raw identifikator sintaksisidan foydalanishingiz kerak boʻladi.
Nashrlar haqida qo'shimcha ma'lumot E ilovasiga qarang.
B-ilova: Operatorlar va Belgilar
Ushbu qo'shimchada Rust sintaksisining lug'ati, shu jumladan o'z-o'zidan yoki yo'llar (paths), umumlashmalar (generiklar), turlar, makroslar, atributlar, sharhlar, katakchalar (tuples) va qavslar kontekstida paydo bo'ladigan operatorlar va boshqa belgilar mavjud.
Operatorlar
B-1 jadvalida Rust tili operatorlari, operator qanday kontekstda ko'rinishi, qisqa tushuntirish va ushbu operator yuklanishi mumkinmi (overload) yoki yo'qmi ko'rsatilgan. Agar operator yuklanishi mumkin bo'lsa, bu operatorni yuklash uchun foydalanish kerak bo'lgan tegishli trait keltirilgan.
Jadval B-1: Operatorlar
| Operator | Misol | Tushuntirish | Yuklanishi mumkinmi? |
|---|---|---|---|
! | ident!(...), ident!{...}, ident![...] | Makros chaqiruvi | |
! | !expr | Bit yoki mantiqiy inkor | Not |
!= | expr != expr | Tengsizlik taqqoslash | PartialEq |
% | expr % expr | Bo'linishning qolg'i | Rem |
%= | var %= expr | Bo'linishning qolg'i va tayinlash | RemAssign |
& | &expr, &mut expr | Qarz olish | |
& | &type, &mut type, &'a type, &'a mut type | Ushbu tur qarzga olinganligini ko'rsatadi | |
& | expr & expr | Bitlik VA | BitAnd |
&= | var &= expr | Bitlik VA va tayinlash | BitAndAssign |
&& | expr && expr | Mantiqiy VA | |
* | expr * expr | Arifmetik ko'paytirish | Mul |
*= | var *= expr | Arifmetik ko'paytirish va tayinlash | MulAssign |
* | *expr | Havolani bekor qilish | Deref |
* | *const type, *mut type | Ushbu tur xom ko'rsatkich ekanligini ko'rsatadi | |
+ | trait + trait, 'a + trait | Murakkab turdagi cheklov | |
+ | expr + expr | Arifmetik qo'shish | Add |
+= | var += expr | Arifmetik qo'shish va tayinlash | AddAssign |
, | expr, expr | Argument va element ajratuvchisi | |
- | - expr | Arifmetik inkor | Neg |
- | expr - expr | Arifmetik ayirish | Sub |
-= | var -= expr | Arifmetik ayirish va tayinlash | SubAssign |
-> | fn(...) -> type, |...| -> type | Funktsiya va yopilishning qaytish turi | |
. | expr.ident | A'zoga (elementga) kirish | |
.. | .., expr.., ..expr, expr..expr | O'ngdan tashqari raqamlar oralig'ini bildiradi | PartialOrd |
..= | ..=expr, expr..=expr | Raqamlar oralig'ini, shu jumladan o'ng tomonni bildiradi | PartialOrd |
.. | ..expr | Strukturani yangilash sintaksisi | |
.. | variant(x, ..), struct_type { x, .. } | "Va boshqa hamma narsa"ni bog'lash | |
... | expr...expr | (Eskirgan, yangi sintaksisdan foydalaning ..= ) Inklyuziv diapazonni aniqlashda ishlatiladi | |
/ | expr / expr | Arifmetik bo'lish | Div |
/= | var /= expr | Arifmetik bo'lish va tayinlash | DivAssign |
: | pat: type, ident: type | Turlarning cheklovlari | |
: | ident: expr | Tuzilish maydonini ishga tushirish | |
: | 'a: loop {...} | Tsikl yorlig'i | |
; | expr; | Ko'rsatma va elementning oxiri belgisi | |
; | [...; len] | Qat'iy o'lchamdagi massiv sintaksisining qismi | |
<< | expr << expr | Bitlik chapga surish | Shl |
<<= | var <<= expr | Bitlik chapga surish va tayinlash | ShlAssign |
< | expr < expr | "Kamroq" taqqoslash | PartialOrd |
<= | expr <= expr | "Kamroq yoki teng" taqqoslash | PartialOrd |
= | var = expr, ident = type | Tayinlash/ekvivalentlik | |
== | expr == expr | Tenglik taqqoslash | PartialEq |
=> | pat => expr | Moslama qolipining qismi | |
> | expr > expr | "Kattaroq" taqqoslash | PartialOrd |
>= | expr >= expr | "Kattaroq yoki teng" taqqoslash | PartialOrd |
>> | expr >> expr | Bitlik o'ngga surish | Shr |
>>= | var >>= expr | Bitlik o'ngga surish va tayinlash | ShrAssign |
@ | ident @ pat | Naqshni bog'lash (Pattern binding) | |
^ | expr ^ expr | Bitlik istisno YOKI | BitXor |
^= | var ^= expr | Bitlik istisno YOKI va tayinlash | BitXorAssign |
| | pat | pat | Muqobil naqshlar | |
| | expr | expr | Bitlik YOKI | BitOr |
|= | var |= expr | Bitlik YOKI va tayinlash | BitOrAssign |
|| | expr || expr | Qisqa mantiqiy YOKI | |
? | expr? | Xato qaytarish |
Operator bo'lmagan Belgilar
Quyidagi ro'yxatda operator sifatida ishlamaydigan barcha belgilar mavjud; ya'ni ular funktsiya yoki usul chaqiruvi kabi harakat qilmaydi.
B-2 jadvali o'z-o'zidan paydo bo'ladigan va turli joylarda qabul qilinadigan belgilarni ko'rsatadi.
Jadval B-2: Mustaqil Sintaksis
| Belgi | Tushuntirish |
|---|---|
'ident | Nomlangan umrbod yoki tsikl yorlig'i |
...u8, ...i32, ...f64, ...usize, va h.k. | Ma'lum turdagi sonli literal |
"..." | Qator (String) literal |
r"...", r#"..."#, r##"..."##, va h.k. | Qochish belgilarini qayta ishlamaydigan xom satrli literal |
b"..." | Bayt string literal; string o'rniga bayt massivini hosil qiladi |
br"...", br#"..."#, br##"..."##, va h.k. | Xom satr baytli harf, xom va baytli harflarning kombinatsiyasi |
'...' | Belgilar literal |
b'...' | ASCII bayt literal |
|...| expr | Yopilish |
! | Har doim bo'sh pastki tur divergiruvchi funksiyalar uchun |
_ | “E'tiborsiz” pattern binding; shuningdek, butun sonli literalni o'qilishi uchun ishlatiladi |
Jadval B-3 modul ierarxiyasi orqali elementga yo'l kontekstida ko'rinadigan belgilarni ko'rsatadi.
Jadval B-3: Yo'lga Tegishli Sintaksis
| Belgi | Tushuntirish |
|---|---|
ident::ident | Nomlar maydoni yo'li |
::path | Crate ildiziga nisbatan yo'l (ya'ni, aniq absolyut yo'l) |
self::path | Joriy modulga nisbatan yo'l (ya'ni, aniq nisbiy yo'l) |
super::path | Joriy modulning ota moduliga nisbatan yo'l |
type::ident, <type as trait>::ident | Tegishli konstantalar, funksiyalar va turlar |
<type>::... | To'g'ridan-to'g'ri nomlanishi mumkin bo'lmagan turga tegishli element (masalan, <&T>::..., <[T]>::..., va hokazo.) |
trait::method(...) | Usul chaqiruvini aniqlashtirish uchun usulni aniqlagan traitni nomlash |
type::method(...) | Usul chaqiruvini aniqlashtirish uchun usul aniqlangan tur nomini ko'rsatish |
<type as trait>::method(...) | Usul chaqiruvini aniqlashtirish uchun trait va tur nomini ko'rsatish |
Jadval B-4 generik turdagi parametrlarni ishlatish kontekstida ko'rinadigan belgilarni ko'rsatadi.
Jadval B-4: Generiklar
| Belgi | Tushuntirish |
|---|---|
path<...> | Turdagi umumlashtirilgan parametrlar uchun parametrlarni belgilaydi (masalan, Vec<u8>) |
path::<...>, method::<...> | Ifodada generik tur, funksiya yoki usul parametrlari; ko'pincha turbofish deb ataladi (masalan, "42".parse::<i32>()) |
fn ident<...> ... | Umumlashtirilgan funksiyani aniqlash |
struct ident<...> ... | Umumlashtirilgan tuzilmani aniqlash |
enum ident<...> ... | Umumlashtirilgan enum aniqlash |
impl<...> ... | Umumlashtirilgan amalga oshirishning ta'rifi |
for<...> type | Yuqori darajadagi umrbod cheklovlar |
type<ident=type> | Bir yoki bir nechta tegishli turlarga aniq tayinlangan generik tur (masalan, Iterator<Item=T>) |
Jadval b-5 ko'rsatadi belgilar turi cheklangan umumlashtirilgan parametr turlaridan foydalanish kontekstida paydo bo'ladi
Jadval B-5: Trait Cheklovlari
| Belgi | Tushuntirish |
|---|---|
T: U | T Umumlashtirilgan parametri Uni amalga oshiruvchi turlar bilan cheklangan |
T: 'a | T Umumlashtirilgan turi a umrbodidan uzoqroq bo'lishi kerak (ya'ni, tur hech qanday adan qisqaroq bo'lgan ko'rsatkichlarga ega bo'lmasligi kerak) |
T: 'static | T Umumlashtirilgan turi faqat static umrbod ko'rsatkichlarini o'z ichiga oladi |
'b: 'a | 'b umrbodi a umrbodidan uzoqroq bo'lishi kerak |
T: ?Sized | Umumlashtirilgan tur parametri dinamik o'lchamli tur bo'lishiga ruxsat beradi |
'a + trait, trait + trait | Murakkab tur cheklovi |
Jadval B-6 makrolarni chaqirish yoki aniqlash va elementga atributlarni belgilash kontekstida ko'rinadigan belgilarni ko'rsatadi.
Jadval B-6: Makrolar va Atributlar
| Belgi | Tushuntirish |
|---|---|
#[meta] | Tashqi atribut |
#![meta] | Ichki atribut |
$ident | Makro almashtirish |
$ident:kind | Makro qo'lga olish |
$(…)… | Makro takrorlash |
ident!(...), ident!{...}, ident![...] | Makro chaqiruvi |
B-7 jadvalida sharhlar yaratadigan belgilar ko'rsatilgan.
Jadval B-7: Kommentariyalar
| Belgi | Tushuntirish |
|---|---|
// | Ichki bir qatorli hujjat sharhi |
//! | Tashqi bir qatorli hujjat sharhi |
/// | Tashqi chiziqli doc kommentariya |
/*...*/ | Ko'p qatorli sharh |
/*!...*/ | Ichki ko'p qatorli hujjat sharhi |
/**...*/ | Tashqi ko'p qatorli hujjat sharhi |
B-8 jadvalida katakchalardan (tuple-lardan) foydalanish kontekstida paydo bo'ladigan belgilar ko'rsatilgan.
Jadval B-8: Katakchalar (tuples)
| Belgi | Tushuntirish |
|---|---|
() | Bo'sh tupl (ya'ni, birlik), literal va tur |
(expr) | Qavs ichidagi ifoda |
(expr,) | Yagona elementli tupl ifodasi |
(type,) | Yagona elementli tupl turi |
(expr, ...) | Tupl ifodasi |
(type, ...) | Tupl turi |
expr(expr, ...) | Funksiya chaqiruvi ifodasi; shuningdek, tupl strukturasi va tupl enum variantlarini boshlash uchun ishlatiladi |
expr.0, expr.1, va h.k. | Tupl indekslash |
B-9 jadvali jingalak qavslardan ("{}") foydalanadigan kontekstlarni ko'rsatadi.
Jadval B-9: Jingalak Qavslar
| Kontekst | Tushuntirish |
|---|---|
{...} | Blok ifodasi |
Type {...} | struct literal |
Jadval B-10 to'rtburchak qavslar ishlatiladigan kontekstlarni ko'rsatadi.
Jadval B-10: To'rtburchak Qavslar
| Kontekst | Tushuntirish |
|---|---|
[...] | Array (yig'ilma) literal |
[expr; len] | len nusxalarini o'z ichiga olgan array literal |
[type; len] | len nusxalarini o'z ichiga olgan array turi |
expr[expr] | To'plamni indekslash. Yuklanishi mumkin (Index, IndexMut) |
expr[..], expr[a..], expr[..b], expr[a..b] | To'plamni kesishga o'xshash qilib indekslash, Range, RangeFrom, RangeTo yoki RangeFull ni "indeks" sifatida ishlatish |
Appendix C: Derivable Traits
In various places in the book, we’ve discussed the derive attribute, which
you can apply to a struct or enum definition. The derive attribute generates
code that will implement a trait with its own default implementation on the
type you’ve annotated with the derive syntax.
In this appendix, we provide a reference of all the traits in the standard
library that you can use with derive. Each section covers:
- What operators and methods deriving this trait will enable
- What the implementation of the trait provided by
derivedoes - What implementing the trait signifies about the type
- The conditions in which you’re allowed or not allowed to implement the trait
- Examples of operations that require the trait
If you want different behavior from that provided by the derive attribute,
consult the standard library documentation
for each trait for details of how to manually implement them.
These traits listed here are the only ones defined by the standard library that
can be implemented on your types using derive. Other traits defined in the
standard library don’t have sensible default behavior, so it’s up to you to
implement them in the way that makes sense for what you’re trying to accomplish.
An example of a trait that can’t be derived is Display, which handles
formatting for end users. You should always consider the appropriate way to
display a type to an end user. What parts of the type should an end user be
allowed to see? What parts would they find relevant? What format of the data
would be most relevant to them? The Rust compiler doesn’t have this insight, so
it can’t provide appropriate default behavior for you.
The list of derivable traits provided in this appendix is not comprehensive:
libraries can implement derive for their own traits, making the list of
traits you can use derive with truly open-ended. Implementing derive
involves using a procedural macro, which is covered in the
“Macros” section of Chapter 19.
Debug for Programmer Output
The Debug trait enables debug formatting in format strings, which you
indicate by adding :? within {} placeholders.
The Debug trait allows you to print instances of a type for debugging
purposes, so you and other programmers using your type can inspect an instance
at a particular point in a program’s execution.
The Debug trait is required, for example, in use of the assert_eq! macro.
This macro prints the values of instances given as arguments if the equality
assertion fails so programmers can see why the two instances weren’t equal.
PartialEq and Eq for Equality Comparisons
The PartialEq trait allows you to compare instances of a type to check for
equality and enables use of the == and != operators.
Deriving PartialEq implements the eq method. When PartialEq is derived on
structs, two instances are equal only if all fields are equal, and the
instances are not equal if any fields are not equal. When derived on enums,
each variant is equal to itself and not equal to the other variants.
The PartialEq trait is required, for example, with the use of the
assert_eq! macro, which needs to be able to compare two instances of a type
for equality.
The Eq trait has no methods. Its purpose is to signal that for every value of
the annotated type, the value is equal to itself. The Eq trait can only be
applied to types that also implement PartialEq, although not all types that
implement PartialEq can implement Eq. One example of this is floating point
number types: the implementation of floating point numbers states that two
instances of the not-a-number (NaN) value are not equal to each other.
An example of when Eq is required is for keys in a HashMap<K, V> so the
HashMap<K, V> can tell whether two keys are the same.
PartialOrd and Ord for Ordering Comparisons
The PartialOrd trait allows you to compare instances of a type for sorting
purposes. A type that implements PartialOrd can be used with the <, >,
<=, and >= operators. You can only apply the PartialOrd trait to types
that also implement PartialEq.
Deriving PartialOrd implements the partial_cmp method, which returns an
Option<Ordering> that will be None when the values given don’t produce an
ordering. An example of a value that doesn’t produce an ordering, even though
most values of that type can be compared, is the not-a-number (NaN) floating
point value. Calling partial_cmp with any floating point number and the NaN
floating point value will return None.
When derived on structs, PartialOrd compares two instances by comparing the
value in each field in the order in which the fields appear in the struct
definition. When derived on enums, variants of the enum declared earlier in the
enum definition are considered less than the variants listed later.
The PartialOrd trait is required, for example, for the gen_range method
from the rand crate that generates a random value in the range specified by a
range expression.
The Ord trait allows you to know that for any two values of the annotated
type, a valid ordering will exist. The Ord trait implements the cmp method,
which returns an Ordering rather than an Option<Ordering> because a valid
ordering will always be possible. You can only apply the Ord trait to types
that also implement PartialOrd and Eq (and Eq requires PartialEq). When
derived on structs and enums, cmp behaves the same way as the derived
implementation for partial_cmp does with PartialOrd.
An example of when Ord is required is when storing values in a BTreeSet<T>,
a data structure that stores data based on the sort order of the values.
Clone and Copy for Duplicating Values
The Clone trait allows you to explicitly create a deep copy of a value, and
the duplication process might involve running arbitrary code and copying heap
data. See the “Ways Variables and Data Interact:
Clone” section in
Chapter 4 for more information on Clone.
Deriving Clone implements the clone method, which when implemented for the
whole type, calls clone on each of the parts of the type. This means all the
fields or values in the type must also implement Clone to derive Clone.
An example of when Clone is required is when calling the to_vec method on a
slice. The slice doesn’t own the type instances it contains, but the vector
returned from to_vec will need to own its instances, so to_vec calls
clone on each item. Thus, the type stored in the slice must implement Clone.
The Copy trait allows you to duplicate a value by only copying bits stored on
the stack; no arbitrary code is necessary. See the “Stack-Only Data:
Copy” section in Chapter 4 for more
information on Copy.
The Copy trait doesn’t define any methods to prevent programmers from
overloading those methods and violating the assumption that no arbitrary code
is being run. That way, all programmers can assume that copying a value will be
very fast.
You can derive Copy on any type whose parts all implement Copy. A type that
implements Copy must also implement Clone, because a type that implements
Copy has a trivial implementation of Clone that performs the same task as
Copy.
The Copy trait is rarely required; types that implement Copy have
optimizations available, meaning you don’t have to call clone, which makes
the code more concise.
Everything possible with Copy you can also accomplish with Clone, but the
code might be slower or have to use clone in places.
Hash for Mapping a Value to a Value of Fixed Size
The Hash trait allows you to take an instance of a type of arbitrary size and
map that instance to a value of fixed size using a hash function. Deriving
Hash implements the hash method. The derived implementation of the hash
method combines the result of calling hash on each of the parts of the type,
meaning all fields or values must also implement Hash to derive Hash.
An example of when Hash is required is in storing keys in a HashMap<K, V>
to store data efficiently.
Default for Default Values
The Default trait allows you to create a default value for a type. Deriving
Default implements the default function. The derived implementation of the
default function calls the default function on each part of the type,
meaning all fields or values in the type must also implement Default to
derive Default.
The Default::default function is commonly used in combination with the struct
update syntax discussed in the “Creating Instances From Other Instances With
Struct Update
Syntax”
section in Chapter 5. You can customize a few fields of a struct and then
set and use a default value for the rest of the fields by using
..Default::default().
The Default trait is required when you use the method unwrap_or_default on
Option<T> instances, for example. If the Option<T> is None, the method
unwrap_or_default will return the result of Default::default for the type
T stored in the Option<T>.
Appendix D - Useful Development Tools
In this appendix, we talk about some useful development tools that the Rust project provides. We’ll look at automatic formatting, quick ways to apply warning fixes, a linter, and integrating with IDEs.
Automatic Formatting with rustfmt
The rustfmt tool reformats your code according to the community code style.
Many collaborative projects use rustfmt to prevent arguments about which
style to use when writing Rust: everyone formats their code using the tool.
To install rustfmt, enter the following:
$ rustup component add rustfmt
This command gives you rustfmt and cargo-fmt, similar to how Rust gives you
both rustc and cargo. To format any Cargo project, enter the following:
$ cargo fmt
Running this command reformats all the Rust code in the current crate. This
should only change the code style, not the code semantics. For more information
on rustfmt, see its documentation.
Fix Your Code with rustfix
The rustfix tool is included with Rust installations and can automatically fix compiler warnings that have a clear way to correct the problem that’s likely what you want. It’s likely you’ve seen compiler warnings before. For example, consider this code:
Filename: src/main.rs
fn do_something() {} fn main() { for i in 0..100 { do_something(); } }
Here, we’re calling the do_something function 100 times, but we never use the
variable i in the body of the for loop. Rust warns us about that:
$ cargo build
Compiling myprogram v0.1.0 (file:///projects/myprogram)
warning: unused variable: `i`
--> src/main.rs:4:9
|
4 | for i in 0..100 {
| ^ help: consider using `_i` instead
|
= note: #[warn(unused_variables)] on by default
Finished dev [unoptimized + debuginfo] target(s) in 0.50s
The warning suggests that we use _i as a name instead: the underscore
indicates that we intend for this variable to be unused. We can automatically
apply that suggestion using the rustfix tool by running the command cargo fix:
$ cargo fix
Checking myprogram v0.1.0 (file:///projects/myprogram)
Fixing src/main.rs (1 fix)
Finished dev [unoptimized + debuginfo] target(s) in 0.59s
When we look at src/main.rs again, we’ll see that cargo fix has changed the
code:
Filename: src/main.rs
fn do_something() {} fn main() { for _i in 0..100 { do_something(); } }
The for loop variable is now named _i, and the warning no longer appears.
You can also use the cargo fix command to transition your code between
different Rust editions. Editions are covered in Appendix E.
More Lints with Clippy
The Clippy tool is a collection of lints to analyze your code so you can catch common mistakes and improve your Rust code.
To install Clippy, enter the following:
$ rustup component add clippy
To run Clippy’s lints on any Cargo project, enter the following:
$ cargo clippy
For example, say you write a program that uses an approximation of a mathematical constant, such as pi, as this program does:
Filename: src/main.rs
fn main() { let x = 3.1415; let r = 8.0; println!("the area of the circle is {}", x * r * r); }
Running cargo clippy on this project results in this error:
error: approximate value of `f{32, 64}::consts::PI` found
--> src/main.rs:2:13
|
2 | let x = 3.1415;
| ^^^^^^
|
= note: `#[deny(clippy::approx_constant)]` on by default
= help: consider using the constant directly
= help: for further information visit https://rust-lang.github.io/rust-clippy/master/index.html#approx_constant
This error lets you know that Rust already has a more precise PI constant
defined, and that your program would be more correct if you used the constant
instead. You would then change your code to use the PI constant. The
following code doesn’t result in any errors or warnings from Clippy:
Filename: src/main.rs
fn main() { let x = std::f64::consts::PI; let r = 8.0; println!("the area of the circle is {}", x * r * r); }
For more information on Clippy, see its documentation.
IDE Integration Using rust-analyzer
To help IDE integration, the Rust community recommends using
rust-analyzer. This tool is a set of
compiler-centric utilities that speaks the Language Server Protocol, which is a specification for IDEs and programming languages to
communicate with each other. Different clients can use rust-analyzer, such as
the Rust analyzer plug-in for Visual Studio Code.
Visit the rust-analyzer project’s home page
for installation instructions, then install the language server support in your
particular IDE. Your IDE will gain abilities such as autocompletion, jump to
definition, and inline errors.
Appendix E - Editions
In Chapter 1, you saw that cargo new adds a bit of metadata to your
Cargo.toml file about an edition. This appendix talks about what that means!
The Rust language and compiler have a six-week release cycle, meaning users get a constant stream of new features. Other programming languages release larger changes less often; Rust releases smaller updates more frequently. After a while, all of these tiny changes add up. But from release to release, it can be difficult to look back and say, “Wow, between Rust 1.10 and Rust 1.31, Rust has changed a lot!”
Every two or three years, the Rust team produces a new Rust edition. Each edition brings together the features that have landed into a clear package with fully updated documentation and tooling. New editions ship as part of the usual six-week release process.
Editions serve different purposes for different people:
- For active Rust users, a new edition brings together incremental changes into an easy-to-understand package.
- For non-users, a new edition signals that some major advancements have landed, which might make Rust worth another look.
- For those developing Rust, a new edition provides a rallying point for the project as a whole.
At the time of this writing, three Rust editions are available: Rust 2015, Rust 2018, and Rust 2021. This book is written using Rust 2021 edition idioms.
The edition key in Cargo.toml indicates which edition the compiler should
use for your code. If the key doesn’t exist, Rust uses 2015 as the edition
value for backward compatibility reasons.
Each project can opt in to an edition other than the default 2015 edition. Editions can contain incompatible changes, such as including a new keyword that conflicts with identifiers in code. However, unless you opt in to those changes, your code will continue to compile even as you upgrade the Rust compiler version you use.
All Rust compiler versions support any edition that existed prior to that compiler’s release, and they can link crates of any supported editions together. Edition changes only affect the way the compiler initially parses code. Therefore, if you’re using Rust 2015 and one of your dependencies uses Rust 2018, your project will compile and be able to use that dependency. The opposite situation, where your project uses Rust 2018 and a dependency uses Rust 2015, works as well.
To be clear: most features will be available on all editions. Developers using any Rust edition will continue to see improvements as new stable releases are made. However, in some cases, mainly when new keywords are added, some new features might only be available in later editions. You will need to switch editions if you want to take advantage of such features.
For more details, the Edition
Guide is a complete book
about editions that enumerates the differences between editions and explains
how to automatically upgrade your code to a new edition via cargo fix.
Ilova F: Kitobning tarjimalari
Ingliz tilidan boshqa tillardagi manbalar uchun.Ko'pchilik hali ham davom etmoqda; yordam berish yoki yangi tarjima haqida bizga xabar berish uchun Tarjimalar yorlig‘iga qarang!
- Português (BR)
- Português (PT)
- 简体中文
- 正體中文
- Українська
- Español, alternate
- Italiano
- Русский
- 한국어
- 日本語
- Français
- Polski
- Cebuano
- Tagalog
- Esperanto
- ελληνική
- Svenska
- Farsi
- Deutsch
- हिंदी
- ไทย
- Danske
- O'zbek
Appendix G - How Rust is Made and “Nightly Rust”
This appendix is about how Rust is made and how that affects you as a Rust developer.
Stability Without Stagnation
As a language, Rust cares a lot about the stability of your code. We want Rust to be a rock-solid foundation you can build on, and if things were constantly changing, that would be impossible. At the same time, if we can’t experiment with new features, we may not find out important flaws until after their release, when we can no longer change things.
Our solution to this problem is what we call “stability without stagnation”, and our guiding principle is this: you should never have to fear upgrading to a new version of stable Rust. Each upgrade should be painless, but should also bring you new features, fewer bugs, and faster compile times.
Choo, Choo! Release Channels and Riding the Trains
Rust development operates on a train schedule. That is, all development is
done on the master branch of the Rust repository. Releases follow a software
release train model, which has been used by Cisco IOS and other software
projects. There are three release channels for Rust:
- Nightly
- Beta
- Stable
Most Rust developers primarily use the stable channel, but those who want to try out experimental new features may use nightly or beta.
Here’s an example of how the development and release process works: let’s
assume that the Rust team is working on the release of Rust 1.5. That release
happened in December of 2015, but it will provide us with realistic version
numbers. A new feature is added to Rust: a new commit lands on the master
branch. Each night, a new nightly version of Rust is produced. Every day is a
release day, and these releases are created by our release infrastructure
automatically. So as time passes, our releases look like this, once a night:
nightly: * - - * - - *
Every six weeks, it’s time to prepare a new release! The beta branch of the
Rust repository branches off from the master branch used by nightly. Now,
there are two releases:
nightly: * - - * - - *
|
beta: *
Most Rust users do not use beta releases actively, but test against beta in their CI system to help Rust discover possible regressions. In the meantime, there’s still a nightly release every night:
nightly: * - - * - - * - - * - - *
|
beta: *
Let’s say a regression is found. Good thing we had some time to test the beta
release before the regression snuck into a stable release! The fix is applied
to master, so that nightly is fixed, and then the fix is backported to the
beta branch, and a new release of beta is produced:
nightly: * - - * - - * - - * - - * - - *
|
beta: * - - - - - - - - *
Six weeks after the first beta was created, it’s time for a stable release! The
stable branch is produced from the beta branch:
nightly: * - - * - - * - - * - - * - - * - * - *
|
beta: * - - - - - - - - *
|
stable: *
Hooray! Rust 1.5 is done! However, we’ve forgotten one thing: because the six
weeks have gone by, we also need a new beta of the next version of Rust, 1.6.
So after stable branches off of beta, the next version of beta branches
off of nightly again:
nightly: * - - * - - * - - * - - * - - * - * - *
| |
beta: * - - - - - - - - * *
|
stable: *
This is called the “train model” because every six weeks, a release “leaves the station”, but still has to take a journey through the beta channel before it arrives as a stable release.
Rust releases every six weeks, like clockwork. If you know the date of one Rust release, you can know the date of the next one: it’s six weeks later. A nice aspect of having releases scheduled every six weeks is that the next train is coming soon. If a feature happens to miss a particular release, there’s no need to worry: another one is happening in a short time! This helps reduce pressure to sneak possibly unpolished features in close to the release deadline.
Thanks to this process, you can always check out the next build of Rust and
verify for yourself that it’s easy to upgrade to: if a beta release doesn’t
work as expected, you can report it to the team and get it fixed before the
next stable release happens! Breakage in a beta release is relatively rare, but
rustc is still a piece of software, and bugs do exist.
Unstable Features
There’s one more catch with this release model: unstable features. Rust uses a
technique called “feature flags” to determine what features are enabled in a
given release. If a new feature is under active development, it lands on
master, and therefore, in nightly, but behind a feature flag. If you, as a
user, wish to try out the work-in-progress feature, you can, but you must be
using a nightly release of Rust and annotate your source code with the
appropriate flag to opt in.
If you’re using a beta or stable release of Rust, you can’t use any feature flags. This is the key that allows us to get practical use with new features before we declare them stable forever. Those who wish to opt into the bleeding edge can do so, and those who want a rock-solid experience can stick with stable and know that their code won’t break. Stability without stagnation.
This book only contains information about stable features, as in-progress features are still changing, and surely they’ll be different between when this book was written and when they get enabled in stable builds. You can find documentation for nightly-only features online.
Rustup and the Role of Rust Nightly
Rustup makes it easy to change between different release channels of Rust, on a global or per-project basis. By default, you’ll have stable Rust installed. To install nightly, for example:
$ rustup toolchain install nightly
You can see all of the toolchains (releases of Rust and associated
components) you have installed with rustup as well. Here’s an example on one
of your authors’ Windows computer:
> rustup toolchain list
stable-x86_64-pc-windows-msvc (default)
beta-x86_64-pc-windows-msvc
nightly-x86_64-pc-windows-msvc
As you can see, the stable toolchain is the default. Most Rust users use stable
most of the time. You might want to use stable most of the time, but use
nightly on a specific project, because you care about a cutting-edge feature.
To do so, you can use rustup override in that project’s directory to set the
nightly toolchain as the one rustup should use when you’re in that directory:
$ cd ~/projects/needs-nightly
$ rustup override set nightly
Now, every time you call rustc or cargo inside of
~/projects/needs-nightly, rustup will make sure that you are using nightly
Rust, rather than your default of stable Rust. This comes in handy when you
have a lot of Rust projects!
The RFC Process and Teams
So how do you learn about these new features? Rust’s development model follows a Request For Comments (RFC) process. If you’d like an improvement in Rust, you can write up a proposal, called an RFC.
Anyone can write RFCs to improve Rust, and the proposals are reviewed and discussed by the Rust team, which is comprised of many topic subteams. There’s a full list of the teams on Rust’s website, which includes teams for each area of the project: language design, compiler implementation, infrastructure, documentation, and more. The appropriate team reads the proposal and the comments, writes some comments of their own, and eventually, there’s consensus to accept or reject the feature.
If the feature is accepted, an issue is opened on the Rust repository, and
someone can implement it. The person who implements it very well may not be the
person who proposed the feature in the first place! When the implementation is
ready, it lands on the master branch behind a feature gate, as we discussed
in the “Unstable Features” section.
After some time, once Rust developers who use nightly releases have been able to try out the new feature, team members will discuss the feature, how it’s worked out on nightly, and decide if it should make it into stable Rust or not. If the decision is to move forward, the feature gate is removed, and the feature is now considered stable! It rides the trains into a new stable release of Rust.